1160 lines
36 KiB
Markdown
1160 lines
36 KiB
Markdown
|
|
## Mybatis
|
|||
|
|
|
|||
|
|
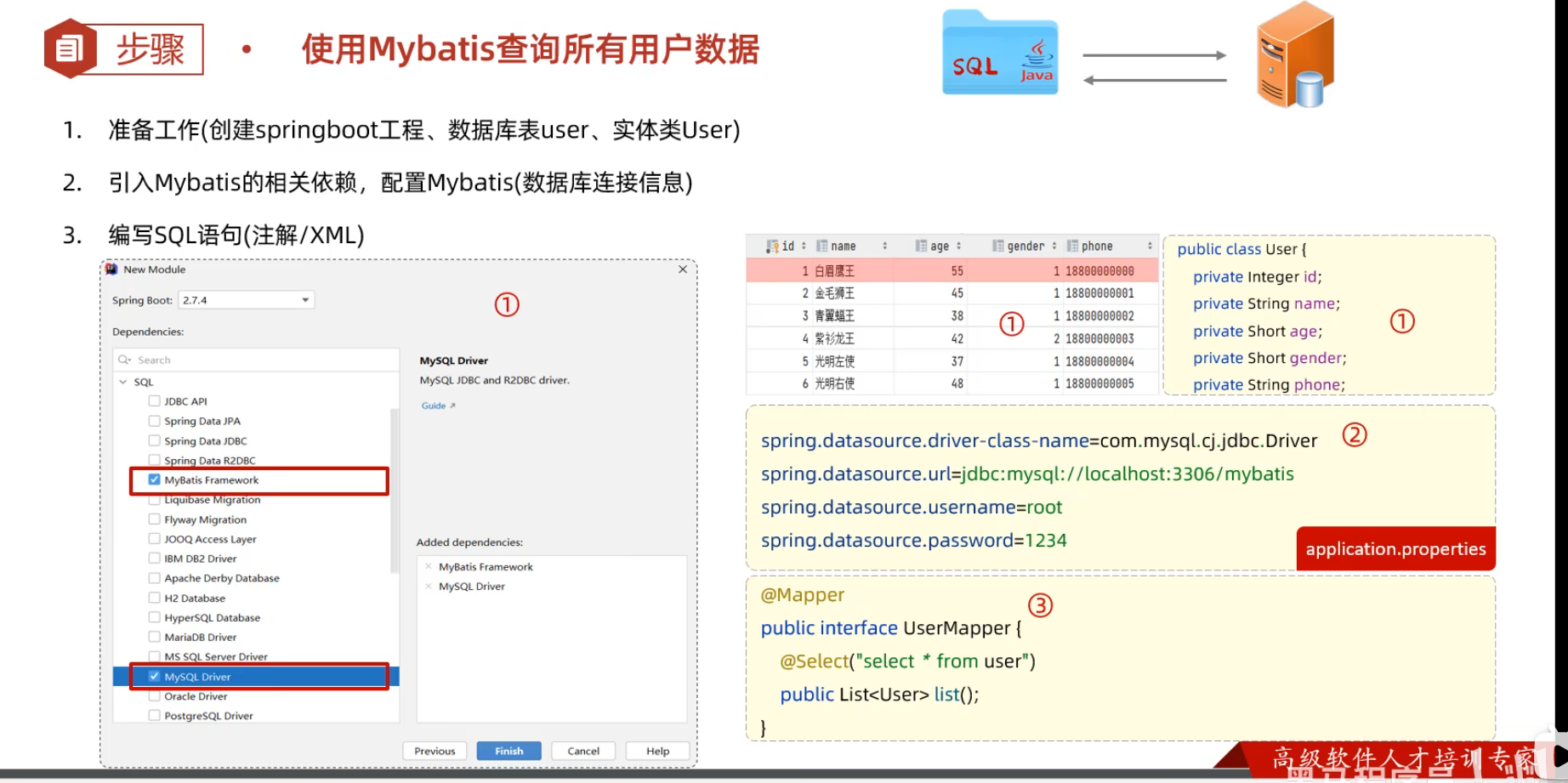
### 快速创建
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
1. 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User
|
|||
|
|
|
|||
|
|
|
|||
|
|
2. 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
#驱动类名称
|
|||
|
|
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
|
|||
|
|
#数据库连接的url
|
|||
|
|
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
|
|||
|
|
#连接数据库的用户名
|
|||
|
|
spring.datasource.username=root
|
|||
|
|
#连接数据库的密码
|
|||
|
|
spring.datasource.password=1234
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
3. 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
@Mapper注解:表示是mybatis中的Mapper接口
|
|||
|
|
|
|||
|
|
-程序运行时:框架会自动生成接口的**实现类对象(代理对象)**,并交给Spring的IOC容器管理
|
|||
|
|
|
|||
|
|
@Select注解:代表的就是select查询,用于书写select查询语句
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface UserMapper {
|
|||
|
|
//查询所有用户数据
|
|||
|
|
@Select("select * from user")
|
|||
|
|
public List<User> list();
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 数据库连接池
|
|||
|
|
|
|||
|
|
数据库连接池是一个容器,负责管理和分配数据库连接(`Connection`)。
|
|||
|
|
|
|||
|
|
- 在程序启动时,连接池会创建一定数量的数据库连接。
|
|||
|
|
- 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。
|
|||
|
|
- 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。
|
|||
|
|
|
|||
|
|
**优势**:避免频繁创建和销毁连接,提高数据库访问效率。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
Druid(德鲁伊)
|
|||
|
|
|
|||
|
|
* Druid连接池是阿里巴巴开源的数据库连接池项目
|
|||
|
|
|
|||
|
|
* 功能强大,性能优秀,是Java语言最好的数据库连接池之一
|
|||
|
|
|
|||
|
|
把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池:
|
|||
|
|
|
|||
|
|
1. 在pom.xml文件中引入依赖
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<dependency>
|
|||
|
|
<!-- Druid连接池依赖 -->
|
|||
|
|
<groupId>com.alibaba</groupId>
|
|||
|
|
<artifactId>druid-spring-boot-starter</artifactId>
|
|||
|
|
<version>1.2.8</version>
|
|||
|
|
</dependency>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
2. 在application.properties中引入数据库连接配置
|
|||
|
|
|
|||
|
|
```properties
|
|||
|
|
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
|
|||
|
|
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis
|
|||
|
|
spring.datasource.druid.username=root
|
|||
|
|
spring.datasource.druid.password=123456
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### SQL注入问题
|
|||
|
|
|
|||
|
|
SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。
|
|||
|
|
|
|||
|
|
在Mybatis中提供的参数占位符有两种:${...} 、#{...}
|
|||
|
|
|
|||
|
|
- #{...}
|
|||
|
|
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
|
|||
|
|
- 使用时机:参数传递,都使用#{…}
|
|||
|
|
|
|||
|
|
- ${...}
|
|||
|
|
- 拼接SQL。直接将参数拼接在SQL语句中,**存在SQL注入问题**
|
|||
|
|
- 使用时机:如果对表名、列表进行动态设置时使用
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 日志输出
|
|||
|
|
|
|||
|
|
只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果
|
|||
|
|
|
|||
|
|
1. 打开application.properties文件
|
|||
|
|
|
|||
|
|
2. 开启mybatis的日志,并指定输出到控制台
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
#指定mybatis输出日志的位置, 输出控制台
|
|||
|
|
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 驼峰命名法
|
|||
|
|
|
|||
|
|
在 Java 项目中,数据库表字段名一般使用 **下划线命名法**(snake_case),而 Java 中的变量名使用 **驼峰命名法**(camelCase)。
|
|||
|
|
|
|||
|
|
- [x] **小驼峰命名(lowerCamelCase)**:
|
|||
|
|
|
|||
|
|
- 第一个单词的首字母小写,后续单词的首字母大写。
|
|||
|
|
- **例子**:`firstName`, `userName`, `myVariable`
|
|||
|
|
|
|||
|
|
**大驼峰命名(UpperCamelCase)**:
|
|||
|
|
|
|||
|
|
- 每个单词的首字母都大写,通常用于类名或类型名。
|
|||
|
|
- **例子**:`MyClass`, `EmployeeData`, `OrderDetails`
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
表中查询的数据封装到实体类中
|
|||
|
|
|
|||
|
|
- 实体类属性名和数据库表查询返回的**字段名一致**,mybatis会自动封装。
|
|||
|
|
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
解决方法:
|
|||
|
|
|
|||
|
|
1. 起别名
|
|||
|
|
2. 结果映射
|
|||
|
|
3. **开启驼峰命名**
|
|||
|
|
4. **属性名和表中字段名保持一致**
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**开启驼峰命名(推荐)**:如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
|
|||
|
|
|
|||
|
|
> 驼峰命名规则: abc_xyz => abcXyz
|
|||
|
|
>
|
|||
|
|
> - 表中字段名:abc_xyz
|
|||
|
|
> - 类中属性名:abcXyz
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 推荐的完整配置:
|
|||
|
|
|
|||
|
|
```yaml
|
|||
|
|
mybatis:
|
|||
|
|
#mapper配置文件
|
|||
|
|
mapper-locations: classpath:mapper/*.xml
|
|||
|
|
type-aliases-package: com.sky.entity
|
|||
|
|
configuration:
|
|||
|
|
#开启驼峰命名
|
|||
|
|
map-underscore-to-camel-case: true
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
`type-aliases-package: com.sky.entity`把 `com.sky.entity` 包下的所有类都当作别名注册,XML 里就可以直接写 `<resultType="Dish">` 而不用写全限定名。可以多添加几个包,用逗号隔开。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 增删改
|
|||
|
|
|
|||
|
|
- **增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void!**
|
|||
|
|
|
|||
|
|
**作用于单个字段**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface EmpMapper {
|
|||
|
|
//SQL语句中的id值不能写成固定数值,需要变为动态的数值
|
|||
|
|
//解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
|
|||
|
|
/**
|
|||
|
|
* 根据id删除数据
|
|||
|
|
* @param id 用户id
|
|||
|
|
*/
|
|||
|
|
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
|
|||
|
|
public void delete(Integer id);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
上图参数值分离,有效防止SQL注入
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**作用于多个字段**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface EmpMapper {
|
|||
|
|
//会自动将生成的主键值,赋值给emp对象的id属性
|
|||
|
|
@Options(useGeneratedKeys = true,keyProperty = "id")
|
|||
|
|
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
|
|||
|
|
public void insert(Emp emp);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
在 **`@Insert`** 注解中使用 `#{}` 来引用 `Emp` 对象的属性,MyBatis 会自动从 `Emp` 对象中提取相应的字段并绑定到 SQL 语句中的占位符。
|
|||
|
|
|
|||
|
|
`@Options(useGeneratedKeys = true, keyProperty = "id")` 这行配置表示,插入时自动生成的主键会赋值给 `Emp` 对象的 `id` 属性。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
// 调用 mapper 执行插入操作
|
|||
|
|
empMapper.insert(emp);
|
|||
|
|
|
|||
|
|
// 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值
|
|||
|
|
System.out.println("Generated ID: " + emp.getId());
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 查
|
|||
|
|
|
|||
|
|
查询案例:
|
|||
|
|
|
|||
|
|
- **姓名:要求支持模糊匹配**
|
|||
|
|
- 性别:要求精确匹配
|
|||
|
|
- 入职时间:要求进行范围查询
|
|||
|
|
- 根据最后修改时间进行降序排序
|
|||
|
|
|
|||
|
|
重点在于模糊查询时where name like '%#{name}%' 会报错。
|
|||
|
|
|
|||
|
|
解决方案:
|
|||
|
|
|
|||
|
|
使用MySQL提供的字符串拼接函数:`concat('%' , '关键字' , '%')`
|
|||
|
|
|
|||
|
|
**`CONCAT()`** 如果其中任何一个参数为 **`NULL`**,`CONCAT()` 返回 **`NULL`**,`Like NULL`会导致查询不到任何结果!
|
|||
|
|
|
|||
|
|
`NULL`和`''`是完全不同的
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface EmpMapper {
|
|||
|
|
|
|||
|
|
@Select("select * from emp " +
|
|||
|
|
"where name like concat('%',#{name},'%') " +
|
|||
|
|
"and gender = #{gender} " +
|
|||
|
|
"and entrydate between #{begin} and #{end} " +
|
|||
|
|
"order by update_time desc")
|
|||
|
|
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### XML配置文件规范
|
|||
|
|
|
|||
|
|
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
|
|||
|
|
|
|||
|
|
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
|
|||
|
|
|
|||
|
|
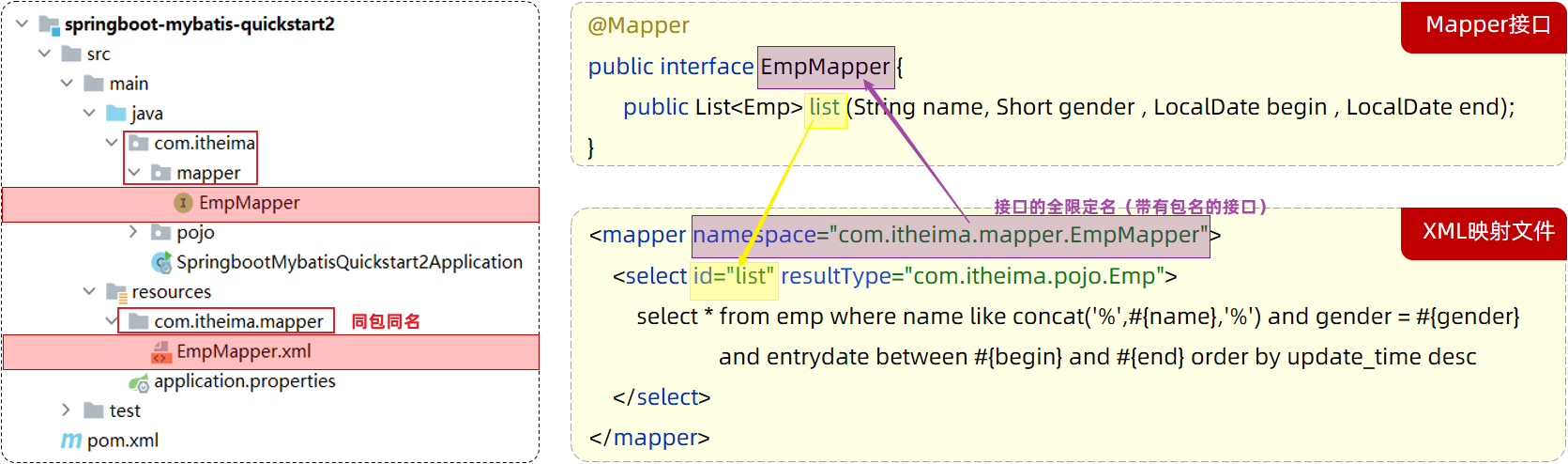
1. XML映射**文件的名称**与Mapper**接口名称**一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
|
|||
|
|
|
|||
|
|
2. XML映射文件的**namespace属性**为Mapper接口**全限定名**一致
|
|||
|
|
|
|||
|
|
3. XML映射文件中sql语句的**id**与Mapper接口中的**方法名**一致,并保持返回类型一致。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
\<select>标签:就是用于编写select查询语句的。
|
|||
|
|
|
|||
|
|
resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。
|
|||
|
|
|
|||
|
|
parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 `Dish` 或 `DishPageQueryDTO`)自动推断),POJO作为入参,需要使用全类名或是`type‑aliases‑package: com.sky.entity` 下注册的别名。
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
|
|||
|
|
<select id="pageQuery" resultType="com.sky.vo.DishVO">
|
|||
|
|
<select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish">
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**实现过程:**
|
|||
|
|
|
|||
|
|
1. resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
|
|||
|
|
|
|||
|
|
2. 配置Mapper文件
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<?xml version="1.0" encoding="UTF-8" ?>
|
|||
|
|
<!DOCTYPE mapper
|
|||
|
|
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
|
|||
|
|
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
|
|||
|
|
<mapper namespace="edu.whut.mapper.EmpMapper">
|
|||
|
|
<!-- SQL 查询语句写在这里 -->
|
|||
|
|
</mapper>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
`namespace` 属性指定了 **Mapper 接口的全限定名**(即包名 + 类名)。
|
|||
|
|
|
|||
|
|
3. 编写查询语句
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<select id="list" resultType="edu.whut.pojo.Emp">
|
|||
|
|
select * from emp
|
|||
|
|
where name like concat('%',#{name},'%')
|
|||
|
|
and gender = #{gender}
|
|||
|
|
and entrydate between #{begin} and #{end}
|
|||
|
|
order by update_time desc
|
|||
|
|
</select>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**`id="list"`**:指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。
|
|||
|
|
|
|||
|
|
**`resultType="edu.whut.pojo.Emp"`**:`resultType` 只在 **查询操作** 中需要指定。指定查询结果映射的对象类型,这里是 `Emp` 类。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这里有bug!!!
|
|||
|
|
|
|||
|
|
`concat('%',#{name},'%')`这里应该用`<where>` `<if>`标签对name是否为`NULL`或`''`进行判断
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 动态SQL
|
|||
|
|
|
|||
|
|
#### SQL-if,where
|
|||
|
|
|
|||
|
|
`<if>`:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
|
|||
|
|
|
|||
|
|
~~~xml
|
|||
|
|
<if test="条件表达式">
|
|||
|
|
要拼接的sql语句
|
|||
|
|
</if>
|
|||
|
|
~~~
|
|||
|
|
|
|||
|
|
`<where>`只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,**加了总比不加好**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
<select id="list" resultType="com.itheima.pojo.Emp">
|
|||
|
|
select * from emp
|
|||
|
|
<where>
|
|||
|
|
<!-- if做为where标签的子元素 -->
|
|||
|
|
<if test="name != null">
|
|||
|
|
and name like concat('%',#{name},'%')
|
|||
|
|
</if>
|
|||
|
|
<if test="gender != null">
|
|||
|
|
and gender = #{gender}
|
|||
|
|
</if>
|
|||
|
|
<if test="begin != null and end != null">
|
|||
|
|
and entrydate between #{begin} and #{end}
|
|||
|
|
</if>
|
|||
|
|
</where>
|
|||
|
|
order by update_time desc
|
|||
|
|
</select>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### SQL-foreach
|
|||
|
|
|
|||
|
|
Mapper 接口
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface EmpMapper {
|
|||
|
|
//批量删除
|
|||
|
|
public void deleteByIds(List<Integer> ids);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
XML 映射文件
|
|||
|
|
|
|||
|
|
`<foreach>` 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
|
|||
|
|
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
|
|||
|
|
</foreach>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
`open="("`:这个属性表示,在*生成的 SQL 语句开始*时添加一个 左括号 `(`。
|
|||
|
|
|
|||
|
|
`close=")"`:这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 `)`。
|
|||
|
|
|
|||
|
|
例:批量删除实现
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
<delete id="deleteByIds">
|
|||
|
|
DELETE FROM emp WHERE id IN
|
|||
|
|
<foreach collection="ids" item="id" separator="," open="(" close=")">
|
|||
|
|
#{id}
|
|||
|
|
</foreach>
|
|||
|
|
</delete>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
实现效果类似:`DELETE FROM emp WHERE id IN (1, 2, 3);`
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## Mybatis-Plus
|
|||
|
|
|
|||
|
|
MyBatis-Plus 的使命就是——在保留 MyBatis 灵活性的同时,大幅减少模板化、重复的代码编写,让增删改查、分页等常见场景“开箱即用”,以更少的配置、更少的样板文件、更高的开发效率,帮助团队快速交付高质量的数据库访问层。
|
|||
|
|
|
|||
|
|
### 快速开始
|
|||
|
|
|
|||
|
|
#### **1.引入依赖**
|
|||
|
|
|
|||
|
|
```XML
|
|||
|
|
<dependency>
|
|||
|
|
<groupId>com.baomidou</groupId>
|
|||
|
|
<artifactId>mybatis-plus-boot-starter</artifactId>
|
|||
|
|
<version>3.5.3.1</version>
|
|||
|
|
</dependency>
|
|||
|
|
<!-- <dependency>-->
|
|||
|
|
<!-- <groupId>org.mybatis.spring.boot</groupId>-->
|
|||
|
|
<!-- <artifactId>mybatis-spring-boot-starter</artifactId>-->
|
|||
|
|
<!-- <version>2.3.1</version>-->
|
|||
|
|
<!-- </dependency>-->
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
由于这个starter包含对mybatis的自动装配,因此完**全可以替换**掉Mybatis的starter。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### **2.定义mapper**
|
|||
|
|
|
|||
|
|
为了简化单表CRUD,MybatisPlus提供了一个基础的`BaseMapper`接口,其中已经实现了单表的**CRUD(增删查改)**:
|
|||
|
|
|
|||
|
|
<img src="https://pic.bitday.top/i/2025/05/18/shk22b-0.png" alt="image-20250518172250325" style="zoom:67%;" />
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
仅需让自定义的`UserMapper`接口,继承`BaseMapper`接口:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
public interface UserMapper extends BaseMapper<User> {
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
测试:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@SpringBootTest
|
|||
|
|
class UserMapperTest {
|
|||
|
|
|
|||
|
|
@Autowired
|
|||
|
|
private UserMapper userMapper;
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testInsert() {
|
|||
|
|
User user = new User();
|
|||
|
|
user.setId(5L);
|
|||
|
|
user.setUsername("Lucy");
|
|||
|
|
user.setPassword("123");
|
|||
|
|
user.setPhone("18688990011");
|
|||
|
|
user.setBalance(200);
|
|||
|
|
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
|
|||
|
|
user.setCreateTime(LocalDateTime.now());
|
|||
|
|
user.setUpdateTime(LocalDateTime.now());
|
|||
|
|
userMapper.insert(user);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testSelectById() {
|
|||
|
|
User user = userMapper.selectById(5L);
|
|||
|
|
System.out.println("user = " + user);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testSelectByIds() {
|
|||
|
|
List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L, 5L));
|
|||
|
|
users.forEach(System.out::println);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testUpdateById() {
|
|||
|
|
User user = new User();
|
|||
|
|
user.setId(5L);
|
|||
|
|
user.setBalance(20000);
|
|||
|
|
userMapper.updateById(user);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testDelete() {
|
|||
|
|
userMapper.deleteById(5L);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### **3.常见注解**
|
|||
|
|
|
|||
|
|
MybatisPlus如何知道我们要查询的是哪张表?表中有哪些字段呢?
|
|||
|
|
|
|||
|
|
**约定大于配置**
|
|||
|
|
|
|||
|
|
**泛型中的User**就是与数据库对应的PO.
|
|||
|
|
|
|||
|
|
MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下:
|
|||
|
|
|
|||
|
|
- MybatisPlus会把PO实体的**类名**驼峰转下划线作为**表名** `UserRecord->user_record`
|
|||
|
|
- MybatisPlus会把PO实体的所有**变量名**驼峰转下划线作为表的**字段名**,并根据变量类型推断字段类型
|
|||
|
|
- MybatisPlus会把名为**id**的字段作为**主键**
|
|||
|
|
|
|||
|
|
但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于我们声明表信息。
|
|||
|
|
|
|||
|
|
**@TableName**
|
|||
|
|
|
|||
|
|
- 描述:表名注解,标识实体类对应的表
|
|||
|
|
|
|||
|
|
**@TableId**
|
|||
|
|
|
|||
|
|
- 描述:主键注解,标识实体类中的主键字段
|
|||
|
|
|
|||
|
|
`TableId`注解支持两个属性:
|
|||
|
|
|
|||
|
|
| **属性** | **类型** | **必须指定** | **默认值** | **描述** |
|
|||
|
|
| :------- | :------- | :----------- | :---------- | :----------- |
|
|||
|
|
| value | String | 否 | "" | 主键字段名 |
|
|||
|
|
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@TableName("user_detail")
|
|||
|
|
public class User {
|
|||
|
|
@TableId(value="id_dd",type=IdType.AUTO)
|
|||
|
|
private Long id;
|
|||
|
|
private String name;
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这个例子会,映射到数据库中的user_detail表,主键为id_dd,并且插入时采用数据库自增,相当于开启`useGeneratedKeys=true`,执行完 `insert(user)` 后,`user.getId()` 就会是数据库分配的主键值,否则默认获得null,但不影响数据表中的内容。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**@TableField**
|
|||
|
|
|
|||
|
|
- 普通字段注解
|
|||
|
|
|
|||
|
|
一般情况下我们并不需要给字段添加`@TableField`注解,一些特殊情况除外:
|
|||
|
|
|
|||
|
|
- 成员变量名与数据库字段名不一致
|
|||
|
|
|
|||
|
|
- 成员变量是以`isXXX`命名,按照`JavaBean`的规范,`MybatisPlus`识别字段时会把`is`去除,这就导致与数据库不符。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
public class User {
|
|||
|
|
private Long id;
|
|||
|
|
private String name;
|
|||
|
|
private Boolean isActive; // 按 JavaBean 习惯,这里用 isActive,数据表是is_acitive,但MybatisPlus会识别为active
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
- 成员变量名与数据库一致,但是与数据库的**关键字(如order)**冲突。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
public class Order {
|
|||
|
|
private Long id;
|
|||
|
|
private Integer order; // 名字和 SQL 关键字冲突
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
默认MP会生成:`SELECT id, order FROM order;` 导致报错
|
|||
|
|
|
|||
|
|
- 一些字段不希望被映射到数据表中,不希望进行增删查改
|
|||
|
|
|
|||
|
|
解决办法:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@TableField("is_active")
|
|||
|
|
private Boolean isActive;
|
|||
|
|
@TableField("`order`") //添加转义字符
|
|||
|
|
private Integer order;
|
|||
|
|
@TableField(exist=false) //exist默认是true,
|
|||
|
|
private String address;
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### **4.常用配置**
|
|||
|
|
|
|||
|
|
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
|
|||
|
|
|
|||
|
|
- 实体类的别名扫描包
|
|||
|
|
- 全局id类型
|
|||
|
|
|
|||
|
|
要改也就改这两个即可
|
|||
|
|
|
|||
|
|
```YAML
|
|||
|
|
mybatis-plus:
|
|||
|
|
type-aliases-package: edu.whut.mp.domain.po
|
|||
|
|
global-config:
|
|||
|
|
db-config:
|
|||
|
|
id-type: auto # 全局id类型为自增长
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
作用:1.把`edu.whut.mp.domain.po `包下的所有 `PO` 类注册为 MyBatis 的 Type Alias。这样在你的 Mapper XML 里就可以直接写 `<resultType="User">`(或 `<parameterType="User">`)而不用写全限定类名 `edu.whut.mp.domain.po.User`
|
|||
|
|
|
|||
|
|
2.无需在每个 `@TableId` 上都写 `type = IdType.AUTO`,统一由全局配置管。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 核心功能
|
|||
|
|
|
|||
|
|
前面的例子都是**根据主键id**更新、修改、查询,无法支持复杂条件where。
|
|||
|
|
|
|||
|
|
#### 条件构造器
|
|||
|
|
|
|||
|
|
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法**除了以`id`作为`where`条件**以外,还支持**更加复杂的`where`条件**。
|
|||
|
|
|
|||
|
|
<img src="https://pic.bitday.top/i/2025/05/18/tyh7e3-0.png" alt="image-20250518181145318" style="zoom:67%;" />
|
|||
|
|
|
|||
|
|
`Wrapper`就是条件构造的抽象类,其下有很多默认实现,继承关系如图:
|
|||
|
|
|
|||
|
|
<img src="https://pic.bitday.top/i/2025/03/19/u7fwe0-2.png" alt="image-20240813112049624" style="zoom: 67%;" />
|
|||
|
|
|
|||
|
|
<img src="https://pic.bitday.top/i/2025/03/19/u7f24w-2.png" alt="image-20240813134824946" style="zoom:67%;" />
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**QueryWrapper**
|
|||
|
|
|
|||
|
|
在AbstractWrapper的基础上拓展了一个**select方法**,允许指定查询字段,无论是**修改、删除、查询**,都可以使用QueryWrapper来构建查询条件。
|
|||
|
|
|
|||
|
|
select方法只需用于 **查询** 时指定所需的**列**,完整查询不需要,用于update和delete不需要。
|
|||
|
|
|
|||
|
|
**注意:里面的字段都是数据表中真实的字段名,而不是类中自己定义的。**
|
|||
|
|
|
|||
|
|
eg: .select("id","username","info","balance")
|
|||
|
|
|
|||
|
|
**例1:**查询出名字中带o的,存款大于等于1000元的人的id,username,info,balance:
|
|||
|
|
|
|||
|
|
```Java
|
|||
|
|
/**
|
|||
|
|
* SELECT id,username,info,balance
|
|||
|
|
* FROM user
|
|||
|
|
* WHERE username LIKE ? AND balance >=?
|
|||
|
|
*/
|
|||
|
|
@Test
|
|||
|
|
void testQueryWrapper(){
|
|||
|
|
QueryWrapper<User> wrapper =new QueryWrapper<User>()
|
|||
|
|
.select("id","username","info","balance")
|
|||
|
|
.like("username","o")
|
|||
|
|
.ge("balance",1000);
|
|||
|
|
//查询
|
|||
|
|
List<User> users=userMapper.selectList(wrapper);
|
|||
|
|
users.forEach(System.out::println);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**例2:**更新用户名为jack的用户的余额为2000:
|
|||
|
|
|
|||
|
|
```Java
|
|||
|
|
|
|||
|
|
@Test
|
|||
|
|
void testUpdateByQueryWrapper() {
|
|||
|
|
// 1.构建查询条件 where name = "Jack"
|
|||
|
|
QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "Jack");
|
|||
|
|
// 2.更新数据,user中非null字段都会作为set语句
|
|||
|
|
User user = new User();
|
|||
|
|
user.setBalance(2000);
|
|||
|
|
userMapper.update(user, wrapper);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**UpdateWrapper**
|
|||
|
|
|
|||
|
|
基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。
|
|||
|
|
|
|||
|
|
**例1:** 例如:更新id为`1,2,4`的用户的余额,扣200,对应的SQL应该是:
|
|||
|
|
|
|||
|
|
```Java
|
|||
|
|
UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```Java
|
|||
|
|
@Test
|
|||
|
|
void testUpdateWrapper() {
|
|||
|
|
List<Long> ids = List.of(1L, 2L, 4L);
|
|||
|
|
// 1.生成SQL
|
|||
|
|
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
|
|||
|
|
.setSql("balance = balance - 200") // SET balance = balance - 200
|
|||
|
|
.in("id", ids); // WHERE id in (1, 2, 4)
|
|||
|
|
// 2.更新,注意第一个参数可以给null,告诉 MP:不要从实体里取任何字段值
|
|||
|
|
// 而是基于UpdateWrapper中的setSQL来更新
|
|||
|
|
userMapper.update(null, wrapper);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**例2:**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
// wrapper 只负责 WHERE 条件
|
|||
|
|
UpdateWrapper<User> wrapper = new UpdateWrapper<User>().eq("status","ACTIVE");
|
|||
|
|
|
|||
|
|
// 实体里所有非 null 字段都会拼到 SET
|
|||
|
|
User user = new User();
|
|||
|
|
user.setBalance(2000);
|
|||
|
|
user.setName("Alice");
|
|||
|
|
|
|||
|
|
userMapper.update(user, wrapper);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**LambdaQueryWrapper**
|
|||
|
|
|
|||
|
|
在使用传统的 `QueryWrapper` 或 `UpdateWrapper` 时,我们不得不把数据库字段名写成字符串常量,这种“魔法值”既不易维护,也无法在编译期发现错误。MyBatis-Plus 提供了两种基于 Lambda 的 Wrapper——`LambdaQueryWrapper` 和 `LambdaUpdateWrapper`——它们接收实体类的 getter 方法引用,通过反射自动解析对应的字段名。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Test
|
|||
|
|
void testLambdaQueryWrapper() {
|
|||
|
|
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
|
|||
|
|
.select(User::getId, User::getUsername, User::getInfo, User::getBalance)
|
|||
|
|
.like(User::getUsername, "o")
|
|||
|
|
.ge(User::getBalance, 1000);
|
|||
|
|
List<User> users = userMapper.selectList(wrapper);
|
|||
|
|
users.forEach(System.out::println);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 自定义sql
|
|||
|
|
|
|||
|
|
可以让我们利用Wrapper生成查询条件,再结合Mapper.xml编写SQL
|
|||
|
|
|
|||
|
|
**例1:**以 `UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)` 为例:
|
|||
|
|
|
|||
|
|
1.先在**业务层**利用wrapper创建条件,传递参数
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Test
|
|||
|
|
void testCustomWrapper() {
|
|||
|
|
// 1.准备自定义查询条件
|
|||
|
|
List<Long> ids = List.of(1L, 2L, 4L);
|
|||
|
|
QueryWrapper<User> wrapper = new QueryWrapper<User>().in("id", ids);
|
|||
|
|
// 2.调用mapper的自定义方法,直接传递Wrapper
|
|||
|
|
userMapper.deductBalanceByIds(200, wrapper);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
2. 自定义**mapper层**把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
public interface UserMapper extends BaseMapper<User> {
|
|||
|
|
/**
|
|||
|
|
* 注意:更新要用 @Update
|
|||
|
|
* - #{money} 会被替换为方法第一个参数 200
|
|||
|
|
* - ${ew.customSqlSegment} 会展开 wrapper 里的 WHERE 子句
|
|||
|
|
*/
|
|||
|
|
@Update("UPDATE user " +
|
|||
|
|
"SET balance = balance - #{money} " +
|
|||
|
|
"${ew.customSqlSegment}")
|
|||
|
|
void deductBalanceByIds(@Param("money") int money,
|
|||
|
|
@Param("ew") QueryWrapper<User> wrapper);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
@Param("ew")就是给这个方法参数在 MyBatis 的 SQL 映射里起一个别名—— `ew `, Mapper 的注解或 XML 里,MyBatis 想要拿到这个参数,就用它的 `@Param` 名称——也就是 **`ew`**:
|
|||
|
|
|
|||
|
|
@Param("ew")中ew是 MP 约定的别名!
|
|||
|
|
|
|||
|
|
`${ew.customSqlSegment}` 可以自动拼接传入的条件语句
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**例2:**查询出所有收货地址在北京的并且用户id在1、2、4之中的用户
|
|||
|
|
|
|||
|
|
普通mybatis:
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
<select id="queryUserByIdAndAddr" resultType="com.itheima.mp.domain.po.User">
|
|||
|
|
SELECT *
|
|||
|
|
FROM user u
|
|||
|
|
INNER JOIN address a ON u.id = a.user_id
|
|||
|
|
WHERE u.id
|
|||
|
|
<foreach collection="ids" separator="," item="id" open="IN (" close=")">
|
|||
|
|
#{id}
|
|||
|
|
</foreach>
|
|||
|
|
AND a.city = #{city}
|
|||
|
|
</select>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
mp方法:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Test
|
|||
|
|
void testCustomJoinWrapper() {
|
|||
|
|
// 1.准备自定义查询条件
|
|||
|
|
QueryWrapper<User> wrapper = new QueryWrapper<User>()
|
|||
|
|
.in("u.id", List.of(1L, 2L, 4L))
|
|||
|
|
.eq("a.city", "北京");
|
|||
|
|
|
|||
|
|
// 2.调用mapper的自定义方法
|
|||
|
|
List<User> users = userMapper.queryUserByWrapper(wrapper);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```xml
|
|||
|
|
@Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}")
|
|||
|
|
List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### Service层常用方法
|
|||
|
|
|
|||
|
|
**查询:**
|
|||
|
|
|
|||
|
|
selectById:根据主键 ID 查询单条记录。
|
|||
|
|
|
|||
|
|
selectBatchIds:根据主键 ID 批量查询记录。
|
|||
|
|
|
|||
|
|
selectOne:根据指定条件查询单条记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Service
|
|||
|
|
public class UserService {
|
|||
|
|
@Autowired
|
|||
|
|
private UserMapper userMapper;
|
|||
|
|
|
|||
|
|
public User findByUsername(String username) {
|
|||
|
|
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
|
|||
|
|
queryWrapper.eq("username", username);
|
|||
|
|
return userMapper.selectOne(queryWrapper);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
selectList:根据指定条件查询多条记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
|
|||
|
|
queryWrapper.ge("age", 18);
|
|||
|
|
List<User> users = userMapper.selectList(queryWrapper);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**插入:**
|
|||
|
|
|
|||
|
|
insert:插入一条记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
User user = new User();
|
|||
|
|
user.setUsername("alice");
|
|||
|
|
user.setAge(20);
|
|||
|
|
int rows = userMapper.insert(user);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**更新**
|
|||
|
|
|
|||
|
|
updateById:根据主键 ID 更新记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
User user = new User();
|
|||
|
|
user.setId(1L);
|
|||
|
|
user.setAge(25);
|
|||
|
|
int rows = userMapper.updateById(user);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
update:根据指定条件更新记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
|
|||
|
|
updateWrapper.eq("username", "alice");
|
|||
|
|
User user = new User();
|
|||
|
|
user.setAge(30);
|
|||
|
|
int rows = userMapper.update(user, updateWrapper);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**删除操作**
|
|||
|
|
|
|||
|
|
deleteById:根据主键 ID 删除记录。
|
|||
|
|
|
|||
|
|
deleteBatchIds:根据主键 ID 批量删除记录。
|
|||
|
|
|
|||
|
|
delete:根据指定条件删除记录。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
|
|||
|
|
queryWrapper.eq("username", "alice");
|
|||
|
|
int rows = userMapper.delete(queryWrapper);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### IService
|
|||
|
|
|
|||
|
|
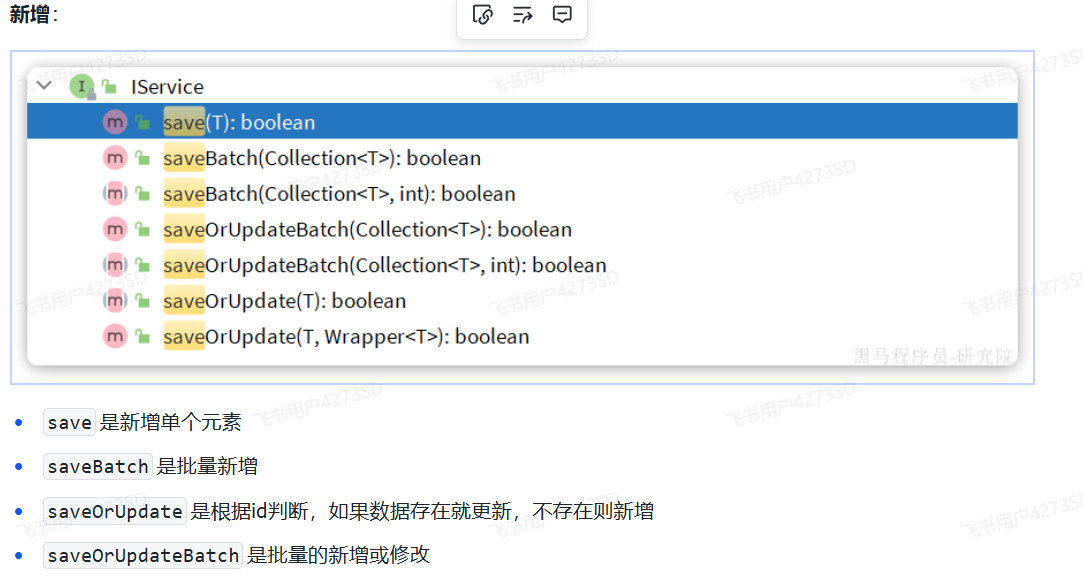
|
|||
|
|
|
|||
|
|
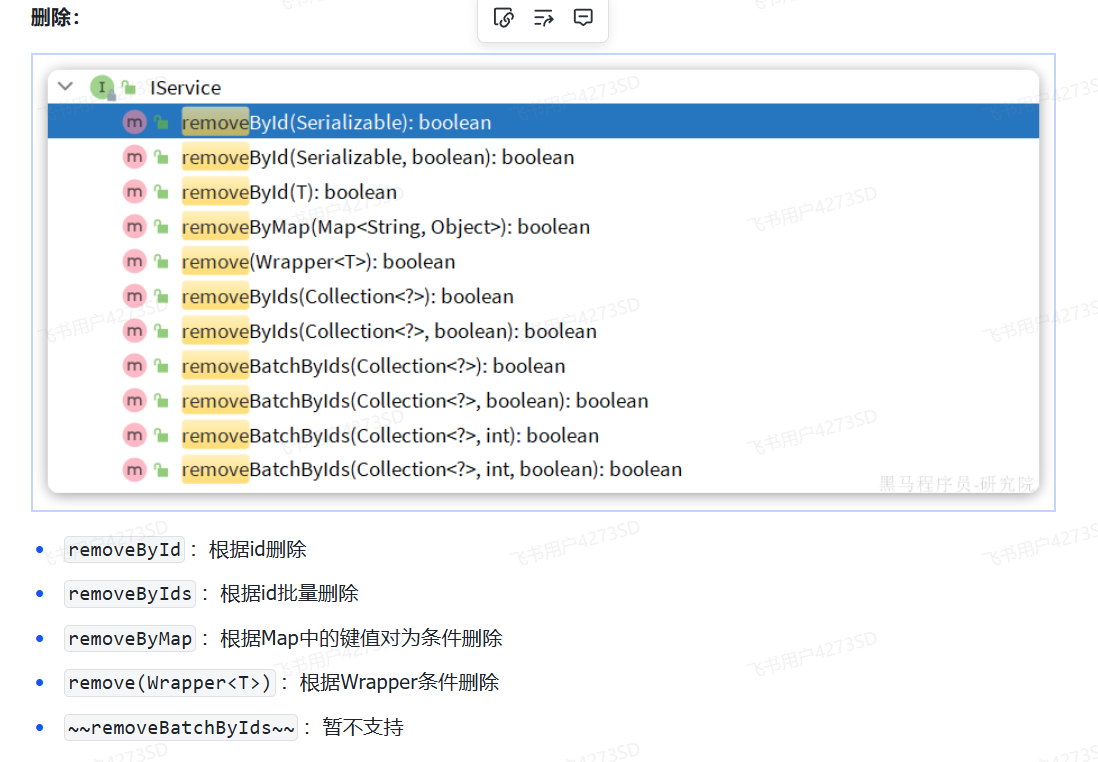
|
|||
|
|
|
|||
|
|
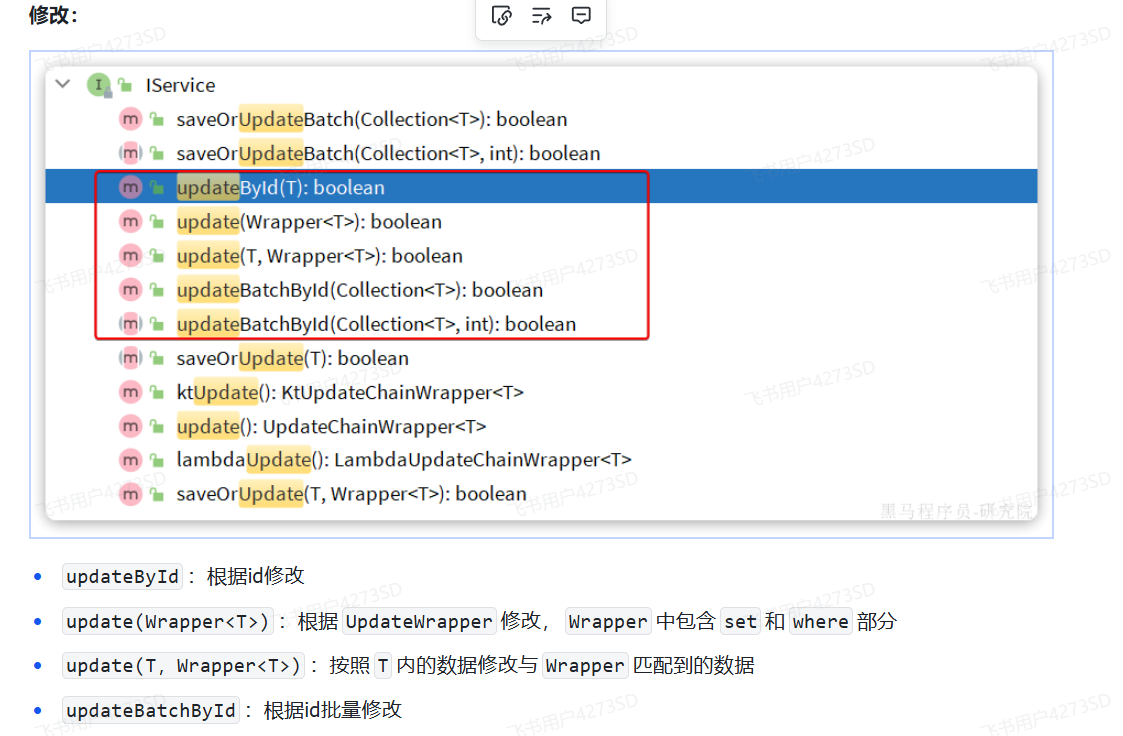
|
|||
|
|
|
|||
|
|
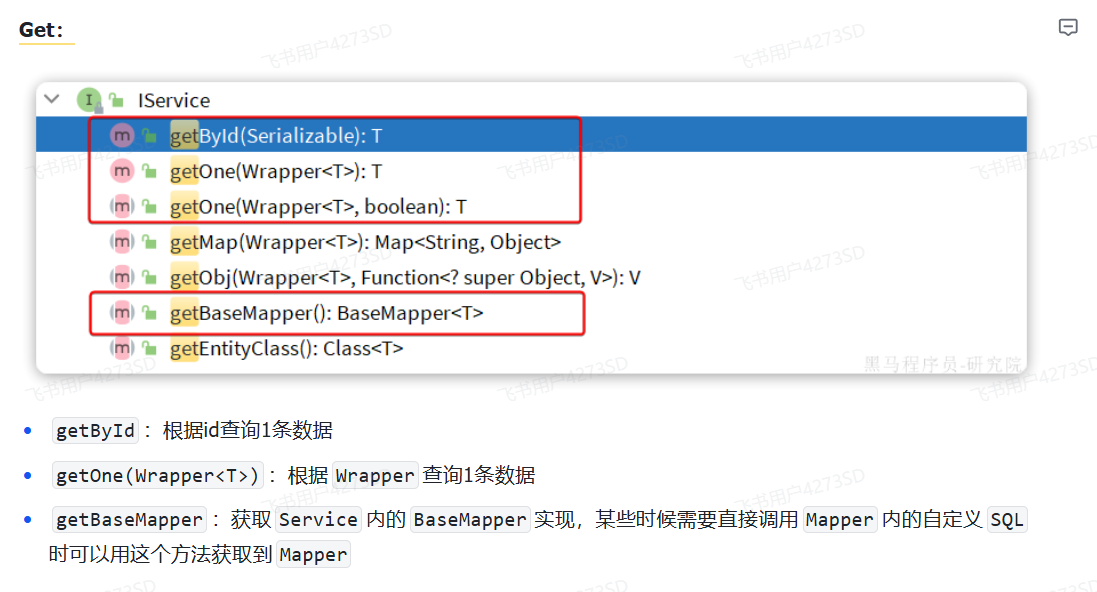
|
|||
|
|
|
|||
|
|
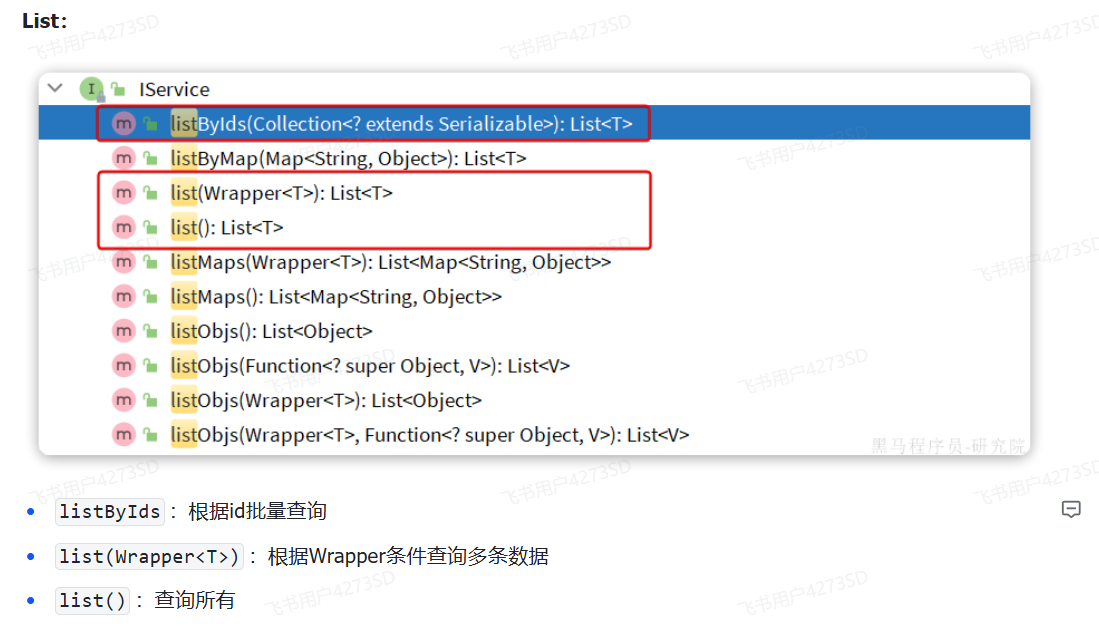
|
|||
|
|
|
|||
|
|
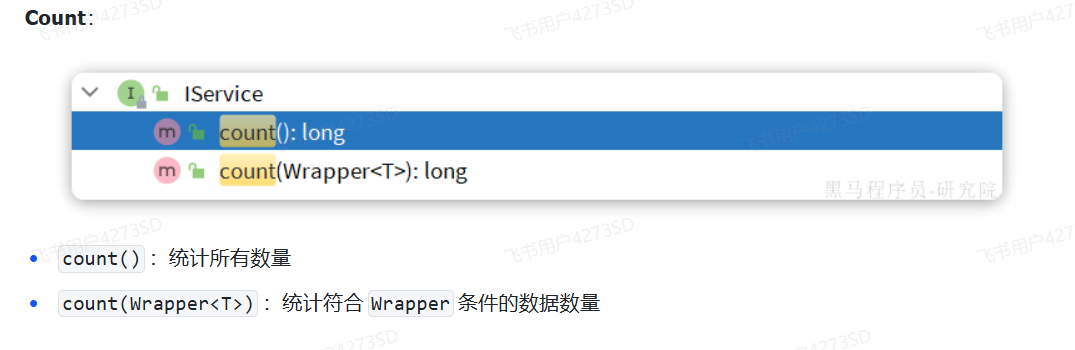
|
|||
|
|
|
|||
|
|
#### 基本使用
|
|||
|
|
|
|||
|
|
由于`Service`中经常需要定义与业务有关的自定义方法,因此我们不能直接使用`IService`,而是自定义`Service`接口,然后继承`IService`以拓展方法。同时,让自定义的`Service实现类`继承`ServiceImpl`,这样就不用自己实现`IService`中的接口了。
|
|||
|
|
|
|||
|
|
<img src="https://pic.bitday.top/i/2025/05/19/o3lyzl-0.png" alt="image-20250519145722328" style="zoom:67%;" />
|
|||
|
|
|
|||
|
|
首先,定义`IUserService`,继承`IService`:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
public interface IUserService extends IService<User> {
|
|||
|
|
// 拓展自定义方法
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
然后,编写`UserServiceImpl`类,继承`ServiceImpl`,实现`UserService`:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Service
|
|||
|
|
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
Controller层中写:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@RestController
|
|||
|
|
@RequestMapping("/users")
|
|||
|
|
@Slf4j
|
|||
|
|
@Api(tags = "用户管理接口")
|
|||
|
|
public class UserController {
|
|||
|
|
@Autowired
|
|||
|
|
private IUserService userService;
|
|||
|
|
|
|||
|
|
@PostMapping
|
|||
|
|
@ApiOperation("新增用户接口")
|
|||
|
|
public void saveUser(@RequestBody UserFormDTO userFormDTO){
|
|||
|
|
User user=new User();
|
|||
|
|
BeanUtils.copyProperties(userFormDTO, user);
|
|||
|
|
userService.save(user);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@DeleteMapping("{id}")
|
|||
|
|
@ApiOperation("删除用户接口")
|
|||
|
|
public void deleteUserById(@PathVariable Long id){
|
|||
|
|
userService.removeById(id);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@GetMapping("{id}")
|
|||
|
|
@ApiOperation("根据id查询接口")
|
|||
|
|
public UserVO queryUserById(@PathVariable Long id){
|
|||
|
|
User user=userService.getById(id);
|
|||
|
|
UserVO userVO=new UserVO();
|
|||
|
|
BeanUtils.copyProperties(user,userVO);
|
|||
|
|
return userVO;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
@PutMapping("/{id}/deduction/{money}")
|
|||
|
|
@ApiOperation("根据id扣减余额")
|
|||
|
|
public void updateBalance(@PathVariable Long id,@PathVariable Long money){
|
|||
|
|
userService.deductBalance(id,money);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
service层:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Service
|
|||
|
|
public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
|
|||
|
|
@Autowired
|
|||
|
|
private UserMapper userMapper;
|
|||
|
|
@Override
|
|||
|
|
public void deductBalance(Long id, Long money) {
|
|||
|
|
//1.查询用户
|
|||
|
|
User user=getById(id);
|
|||
|
|
if(user==null || user.getStatus()==2){
|
|||
|
|
throw new RuntimeException("用户状态异常!");
|
|||
|
|
}
|
|||
|
|
//2.查验余额
|
|||
|
|
if(user.getBalance()<money){
|
|||
|
|
throw new RuntimeException("用户余额不足!");
|
|||
|
|
}
|
|||
|
|
//3.扣除余额 update User set balance=balance-money where id=id
|
|||
|
|
userMapper.deductBalance(id,money);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
mapper层:
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Mapper
|
|||
|
|
public interface UserMapper extends BaseMapper<User> {
|
|||
|
|
@Update("update user set balance=balance-#{money} where id=#{id}")
|
|||
|
|
void deductBalance(Long id, Long money);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
总结:如果是简单查询,如用id来查询、删除,可以直接在Controller层用Iservice方法,否则自定义业务层Service实现具体任务。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### **Lambda**
|
|||
|
|
|
|||
|
|
IService中还提供了Lambda功能来简化我们的**复杂查询及更新功能**。
|
|||
|
|
|
|||
|
|
`lambdaQuery()` = `new LambdaQueryWrapper<>()` + 内置的执行方法(如 `.list()`、`.one()`)
|
|||
|
|
|
|||
|
|
| 特性 | `lambdaQuery()` | `lambdaUpdate()` |
|
|||
|
|
| -------------- | --------------------------------------------------------- | --------------------------------------------- |
|
|||
|
|
| **主要用途** | 构造查询条件,执行 `SELECT` 操作 | 构造更新条件,执行 `UPDATE`(或逻辑删除)操作 |
|
|||
|
|
| **支持的方法** | `.eq()`, `.like()`, `.gt()`, `.orderBy()`, `.select()` 等 | `.eq()`, `.lt()`, `.set()`, `.setSql()` 等 |
|
|||
|
|
| **执行方法** | `.list()`, `.one()`, `.page()` 等 | `.update()`, `.remove()`(逻辑删除 |
|
|||
|
|
|
|||
|
|
**案例一:**实现一个根据复杂条件查询用户的接口,查询条件如下:
|
|||
|
|
|
|||
|
|
- name:用户名关键字,可以为空
|
|||
|
|
- status:用户状态,可以为空
|
|||
|
|
- minBalance:最小余额,可以为空
|
|||
|
|
- maxBalance:最大余额,可以为空
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@GetMapping("/list")
|
|||
|
|
@ApiOperation("根据id集合查询用户")
|
|||
|
|
public List<UserVO> queryUsers(UserQuery query){
|
|||
|
|
// 1.组织条件
|
|||
|
|
String username = query.getName();
|
|||
|
|
Integer status = query.getStatus();
|
|||
|
|
Integer minBalance = query.getMinBalance();
|
|||
|
|
Integer maxBalance = query.getMaxBalance();
|
|||
|
|
// 2.查询用户
|
|||
|
|
List<User> users = userService.lambdaQuery()
|
|||
|
|
.like(username != null, User::getUsername, username)
|
|||
|
|
.eq(status != null, User::getStatus, status)
|
|||
|
|
.ge(minBalance != null, User::getBalance, minBalance)
|
|||
|
|
.le(maxBalance != null, User::getBalance, maxBalance)
|
|||
|
|
.list();
|
|||
|
|
// 3.处理vo
|
|||
|
|
return BeanUtil.copyToList(users, UserVO.class);
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
可以发现lambdaQuery方法中除了可以构建条件,还需要在链式编程的最后添加一个`list()`,这是在告诉MP我们的调用结果需要是一个list集合。这里不仅可以用`list()`,可选的方法有:
|
|||
|
|
|
|||
|
|
- `.one()`:最多1个结果
|
|||
|
|
- `.list()`:返回集合结果
|
|||
|
|
- `.count()`:返回计数结果
|
|||
|
|
|
|||
|
|
MybatisPlus会根据链式编程的最后一个方法来判断最终的返回结果。
|
|||
|
|
|
|||
|
|
这里不够规范,业务写在controller层中了。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
**案例二:**改造根据id修改用户余额的接口,如果扣减后余额为0,则将用户status修改为冻结状态(2)
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Override
|
|||
|
|
@Transactional
|
|||
|
|
public void deductBalance(Long id, Integer money) {
|
|||
|
|
// 1.查询用户
|
|||
|
|
User user = getById(id);
|
|||
|
|
// 2.校验用户状态
|
|||
|
|
if (user == null || user.getStatus() == 2) {
|
|||
|
|
throw new RuntimeException("用户状态异常!");
|
|||
|
|
}
|
|||
|
|
// 3.校验余额是否充足
|
|||
|
|
if (user.getBalance() < money) {
|
|||
|
|
throw new RuntimeException("用户余额不足!");
|
|||
|
|
}
|
|||
|
|
// 4.扣减余额 update tb_user set balance = balance - ?
|
|||
|
|
int remainBalance = user.getBalance() - money;
|
|||
|
|
lambdaUpdate()
|
|||
|
|
.set(User::getBalance, remainBalance) // 更新余额
|
|||
|
|
.set(remainBalance == 0, User::getStatus, 2) // 动态判断,是否更新status
|
|||
|
|
.eq(User::getId, id)
|
|||
|
|
.eq(User::getBalance, user.getBalance()) // 乐观锁
|
|||
|
|
.update();
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 批量新增
|
|||
|
|
|
|||
|
|
每 `batchSize` 条记录作为一个 JDBC batch 提交一次(1000 条就一次)
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
@Test
|
|||
|
|
void testSaveBatch() {
|
|||
|
|
// 准备10万条数据
|
|||
|
|
List<User> list = new ArrayList<>(1000);
|
|||
|
|
long b = System.currentTimeMillis();
|
|||
|
|
for (int i = 1; i <= 100000; i++) {
|
|||
|
|
list.add(buildUser(i));
|
|||
|
|
// 每1000条批量插入一次
|
|||
|
|
if (i % 1000 == 0) {
|
|||
|
|
userService.saveBatch(list);
|
|||
|
|
list.clear();
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
long e = System.currentTimeMillis();
|
|||
|
|
System.out.println("耗时:" + (e - b));
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
之所以把 100 000 条记录分成每 1 000 条一批来插,是为了兼顾 **性能**、**内存** 和 **数据库/JDBC 限制**。
|
|||
|
|
|
|||
|
|
**JDBC 或数据库参数限制**
|
|||
|
|
|
|||
|
|
- 很多数据库(MySQL、Oracle 等)对单条 SQL 里 `VALUES` 列表的长度有上限,一次性插入几十万行可能导致 SQL 过长、参数个数过多,被驱动或数据库拒绝。
|
|||
|
|
- 即使驱动不直接报错,也可能因为网络包(packet)过大而失败。
|
|||
|
|
|
|||
|
|
**内存占用和 GC 压力**
|
|||
|
|
|
|||
|
|
- JDBC 在执行 batch 时,会把所有要执行的 SQL 和参数暂存在客户端内存里。如果一次性缓存 100 000 条记录的参数(可能是几 MB 甚至十几 MB),容易触发 OOM 或者频繁 GC。
|
|||
|
|
|
|||
|
|
**事务日志和回滚压力**
|
|||
|
|
|
|||
|
|
- 一次性插入大量数据,数据库需要在事务日志里记录相应条目,回滚时也要一次性回滚所有操作,性能开销巨大。分批能让每次写入都较为“轻量”,回滚范围也更小。
|
|||
|
|
|
|||
|
|
这种本质上是**多条单行 INSERT**
|
|||
|
|
|
|||
|
|
```mysql
|
|||
|
|
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
|
|||
|
|
Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01
|
|||
|
|
Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01
|
|||
|
|
Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样:
|
|||
|
|
|
|||
|
|
```mysql
|
|||
|
|
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
|
|||
|
|
VALUES
|
|||
|
|
(user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01),
|
|||
|
|
(user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01),
|
|||
|
|
(user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01),
|
|||
|
|
(user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
需要修改项目中的application.yml文件,在jdbc的url后面添加参数`&rewriteBatchedStatements=true`:
|
|||
|
|
|
|||
|
|
`url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true`
|
|||
|
|
|
|||
|
|
**但是会存在上述上事务的问题!!!**
|