Commit on 2025/06/11 周三 10:48:37.56
This commit is contained in:
parent
56cfcca6e1
commit
14fe9cdfa5
@ -1,3 +1,28 @@
|
||||
多智能体随机网络的全局知识对其模型收敛性影响的研究
|
||||
|
||||
|
||||
|
||||
1. 智能体网络的现状、包括网络结构(和现有互联网、物联网的差异)、通信协议(A2A(agent)、MCP成为主流,为了智能体之间的通信)传统的协议已经慢慢被替代,不止是传统互联网应用-》大模型
|
||||
2. 多智能体随机网络与传统互联网不一样,结构基于随机网络(有什么作用,举一些具体的例子),通信协议(没有专门的协议,我们工作的出发点)、应用(联邦学习、图神经网络、强化学习)
|
||||
3. 网络模型的收敛性,怎么定义收敛性?收敛速度、收敛效率(考虑代价)、收敛的稳定性(换了个环境变化大),联邦学习、强化学习收敛性的问题,和哪些因素有关,网络全局结构对它的影响;推理阶段也有收敛性,多智能体推理结果是否一致;图神经网络推理结果是否一致。
|
||||
4. 多智能体随机网络全局知识的获取(分布式、集中式)
|
||||
|
||||
|
||||
|
||||
多智能体随机机会网络、动态谱参数估算、网络重构算法、聚类量化算法、联邦学习、图神经网络
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
如何确定kmeans的簇数?节点之间的流量,空间转为时间的图。
|
||||
|
||||
压缩感知 函数拟合 采样定理 傅里叶变换
|
||||
|
||||
32
科研/mermaid画图.md
Normal file
32
科研/mermaid画图.md
Normal file
@ -0,0 +1,32 @@
|
||||
# mermaid画图
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
A[多智能体随机网络结构分析] --> B[多智能体协同学习与推理]
|
||||
|
||||
A --> A1["谱参数实时估算"]
|
||||
A1 --> A11["卡尔曼滤波"]
|
||||
A1 --> A12["矩阵扰动理论"]
|
||||
A1 --> A13["输出:谱参数"]
|
||||
A --> A2["网络拓扑重构"]
|
||||
A2 --> A21["低秩分解重构"]
|
||||
A2 --> A22["聚类量化"]
|
||||
A2 --> A23["输出:邻接矩阵、特征矩阵"]
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
B[多智能体协同学习与推理]
|
||||
B --> B1["联邦学习、强化学习"]
|
||||
B1 --> B11["谱驱动学习率调整"]
|
||||
B1 --> B12["自适应节点选择策略"]
|
||||
B --> B2["动态图神经网络"]
|
||||
B2 --> B21["动态图卷积设计"]
|
||||
B2 --> B22["一致性推理"]
|
||||
```
|
||||
|
||||
72
科研/草稿.md
72
科研/草稿.md
@ -1,52 +1,24 @@
|
||||
**肯定有,而且一旦你能在分布式/隐私受限场景下拿到「全局网络的谱参数」(如 Laplacian / Adjacency 矩阵的特征值、特征向量或奇异值),在三条研究线上都能直接落地:**
|
||||
```mermaid
|
||||
graph TD
|
||||
A[动态网络谱分析与重构] --> B[多智能体协同学习与推理]
|
||||
|
||||
A --> A1["谱参数实时估算"]
|
||||
A1 --> A11["卡尔曼滤波"]
|
||||
A1 --> A12["矩阵扰动理论"]
|
||||
A1 --> A13["输出:谱参数"]
|
||||
A --> A2["网络拓扑重构"]
|
||||
A2 --> A21["低秩分解重构"]
|
||||
A2 --> A22["聚类量化"]
|
||||
A2 --> A23["输出:邻接矩阵、特征矩阵"]
|
||||
|
||||
B --> B1["联邦学习优化"]
|
||||
B1 --> B11["谱驱动学习率调整"]
|
||||
B1 --> B12["节点选择策略"]
|
||||
B --> B2["动态图神经网络"]
|
||||
B2 --> B21["动态图卷积设计"]
|
||||
B2 --> B22["一致性推理"]
|
||||
|
||||
|
||||
------
|
||||
|
||||
```
|
||||
|
||||
## 1 联邦学习(FL)
|
||||
|
||||
| 用途 | 关键想法 | 为什么谱信息有用 |
|
||||
| ------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| **① 自适应通信与收敛分析** | 用全局**谱隙 (λ₂)** 来动态调节局部迭代步长、通信轮次或拓扑重连 | 谱隙越大、网络混合越快→理论与实验证明可显著提升去中心化 SGD/FedAvg 的收敛速率 citeturn0search0turn0search6 |
|
||||
| **② 客户端谱聚类 / 个性化联邦** | 先用特征向量做**谱嵌入**→聚类→组内共享模型、组间异步 | 典型工作 FedSpectral / FedSpectral⁺ 把全局谱计算移到服务器侧,在保护隐私的同时得到近乎中心化的聚类质量,进而加速收敛、降低异质性影响 citeturn0search1turn0search4 |
|
||||
| **③ 谱正则化的模型聚合** | 把全局 Laplacian 引入损失或梯度校正项(Graph-FedAvg/FedGCN 思路) | 让跨客户端的“邻边”显式参与参数更新,可保留跨域关联信息,减少过拟合 citeturn0search3 |
|
||||
| **④ 通信压缩 / 子空间同步** | 只同步低频(低阶特征向量)系数,忽略高频噪声 | 保持主要结构信息同时大幅减通信量;已在分布式 PCA、图信号处理里验证可行 |
|
||||
|
||||
------
|
||||
|
||||
## 2 联邦蒸馏(含模型蒸馏 & 数据蒸馏)
|
||||
|
||||
| 场景 | 谱参数的切入点 | 预期收益 |
|
||||
| ------------------------ | ------------------------------------------------------------ | ---------------------------------------------- |
|
||||
| **教师权重自适应** | 以节点中心性或谱嵌入距离为权重,给“信息量大”的客户端更高蒸馏系数 | 提升学生模型收敛速度与公平性 |
|
||||
| **知识子空间蒸馏** | 仅在**低频谱子空间**聚合 logits / representations | 去噪声、避免隐私泄漏(高频往往包含可识别细节) |
|
||||
| **跨客户端软标签一致性** | 在谱域里做对齐损失(例如 KL or MSE on Laplacian-filtered logits) | 比直接对齐原始输出更稳健,抗异构数据分布 |
|
||||
|
||||
------
|
||||
|
||||
## 3 强化学习(RL / MARL)
|
||||
|
||||
| 应用类别 | 机制 | 谱信息带来的好处 |
|
||||
| -------------------------------------------- | ------------------------------------------------ | -------------------------------------------------------- |
|
||||
| **多智能体共识策略梯度** | 利用谱隙设计**共识速率**或自适应邻域 | 谱隙大→梯度共识快→更稳健收敛 citeturn0search2 |
|
||||
| **图拉普拉斯基表示 / Proto-Value Functions** | 把 Laplacian 特征向量作为状态特征或 value 基函数 | 改善探索、加速值逼近;在图状/离散大状态空间尤其有效 |
|
||||
| **信用分配与奖励塑形** | 根据节点中心性或谱分量对局部奖励重加权 | 避免“边缘”智能体被忽略,提升团队协作效率 |
|
||||
| **谱驱动的通信拓扑优化** | 用全局谱优化连边(如增大 λ₂、降低最大度) | 在保持低通信成本的同时最小化非平稳性 citeturn0search5 |
|
||||
|
||||
------
|
||||
|
||||
## 4 研究落点与可行实现
|
||||
|
||||
1. 集中式谱估计 + 去中心化应用
|
||||
- 服务器用一次安全多方计算 (SMPC) 或差分隐私聚合奇异值 → 客户端只需取回少量谱系数。
|
||||
2. 在线谱跟踪
|
||||
- 在训练过程中增量维护前 k 个特征向量,配合 FL 训练轮同步。
|
||||
3. 谱-aware 自适应调度器
|
||||
- 把 λ₂、节点特征向量 norm 等指标作为调度信号(何时重连、何时蒸馏)。
|
||||
4. 跨领域验证
|
||||
- **医疗影像 FL**:用谱聚类把医院分群;**车联网 RL**:用谱隙调整车-路协同频率;**隐私推荐**:用低频谱蒸馏稳定用户兴趣漂移。
|
||||
|
||||
------
|
||||
|
||||
### 一句话结论
|
||||
|
||||
> **只要能掌握全局谱参数,你就能在 FL、联邦蒸馏和强化学习里**——调速收敛、做隐私友好的聚类、设计更稳健的蒸馏权重,以及加速多智能体共识 —— **这些都是现有文献已验证或正快速演化的活跃方向**。把谱信息当作“全局结构先验”,可以显著提升分布式学习系统的效率与鲁棒性。
|
||||
|
||||
@ -1344,7 +1344,7 @@ public class SpringbootWebConfig2Application {
|
||||
|
||||
|
||||
|
||||
**Cookie**
|
||||
#### **Cookie**
|
||||
|
||||
**原理**:会话数据**存储在客户端浏览器**中,通过浏览器自动管理。
|
||||
|
||||
@ -1356,10 +1356,52 @@ public class SpringbootWebConfig2Application {
|
||||
|
||||
|
||||
|
||||
**Session**
|
||||
#### **Session**
|
||||
|
||||
**原理**:**服务端存储**会话数据(如内存、Redis),客户端**只保存**会话 ID。
|
||||
|
||||
1)**服务器内建一张 Map**(或 Redis 等持久化存储),大致结构:
|
||||
|
||||
```text
|
||||
{ "abc123" -> HttpSession 实例 }
|
||||
```
|
||||
|
||||
2)`HttpSession` 自身又是一个 KV 容器,结构类似:
|
||||
|
||||
```text
|
||||
HttpSession
|
||||
├─ id = "abc123"
|
||||
├─ creationTime = ...
|
||||
├─ lastAccessedTime = ...
|
||||
└─ attributes
|
||||
└─ "USER_LOGIN_STATE" -> user 实体对象
|
||||
|
||||
```
|
||||
|
||||
3)请求流程
|
||||
|
||||
```text
|
||||
┌───────────────┐ (带 Cookie JSESSIONID=abc123)
|
||||
│ Browser │ ───────►│ Tomcat │
|
||||
└───────────────┘ └──────────┘
|
||||
│
|
||||
│ 用 abc123 做 key
|
||||
▼
|
||||
{abc123 → HttpSession} ← 找到
|
||||
│
|
||||
▼
|
||||
取 attributes["USER_LOGIN_STATE"] → 得到 user
|
||||
|
||||
```
|
||||
|
||||
```java
|
||||
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
|
||||
```
|
||||
|
||||
后端代码的`request.getSession()`能**自动获取**当前请求所对应的HttpSession 实例!!!
|
||||
|
||||
|
||||
|
||||
Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也有。
|
||||
|
||||
- 优点:Session是存储在服务端的,安全。会话数据存在客户端有篡改的风险。
|
||||
@ -1374,40 +1416,19 @@ Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也
|
||||
|
||||
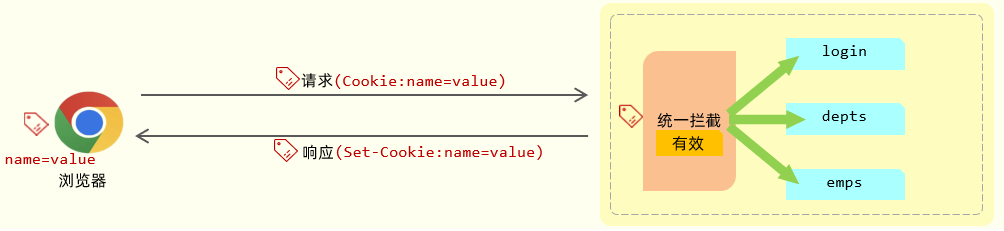
|
||||
|
||||
1.**当用户登录时**,客户端(浏览器)向服务器发送请求(如用户名和密码)。
|
||||
|
||||
服务器验证用户身份,如果身份验证成功,服务器会生成一个 **唯一标识符**(例如 `userId` 或 `authToken`),并将其存储在 **Cookie** 中。服务器会通过 **`Set-Cookie`** HTTP 响应头将这个信息发送到浏览器:如:
|
||||
|
||||
```text
|
||||
Set-Cookie: userId=12345; Path=/; HttpOnly; Secure; Max-Age=3600;
|
||||
```
|
||||
|
||||
`userId=12345` 是服务器返回的标识符。
|
||||
|
||||
`Path=/` 表示此 Cookie 对整个网站有效。
|
||||
|
||||
`HttpOnly` 限制客户端 JavaScript 访问该 Cookie,提高安全性。
|
||||
|
||||
`Secure` 指示该 Cookie 仅通过 HTTPS 协议传输。
|
||||
|
||||
`Max-Age=3600` 设置 Cookie 的有效期为一小时。
|
||||
|
||||
2.**浏览器存储 Cookie**:
|
||||
|
||||
- 浏览器收到 `Set-Cookie` 响应头后,会自动将 **`userId`** 存储在客户端的 Cookie 中。
|
||||
- **`userId`** 会在 **本地存储**,并在浏览器的后续请求中自动携带。
|
||||
|
||||
3.**后续请求发送 Cookie**
|
||||
|
||||
- 当浏览器再次向服务器发送请求时,它会自动在 HTTP 请求头中附带之前存储的 Cookie。
|
||||
|
||||
4.**服务器识别用户**
|
||||
|
||||
- 服务器通过读取请求中的 `Cookie`,获取 **`userId`**(或其他标识符),然后可以从数据库或缓存中获取对应的用户信息。
|
||||
1. **首次请求时**(无 `JSESSIONID` Cookie):
|
||||
- `request.getSession()` 会 **自动创建新 Session**,生成一个随机 `JSESSIONID`(如 `abc123`)。
|
||||
- 服务器通过响应头 `Set-Cookie: JSESSIONID=abc123; Path=/; HttpOnly` 将 `JSESSIONID` 发给浏览器。
|
||||
- 用户数据 `user` 被保存在服务器端,键为 `USER_LOGIN_STATE`,与 `JSESSIONID` 绑定。
|
||||
2. **后续请求时**:
|
||||
- 浏览器自动携带 `Cookie: JSESSIONID=abc123`。
|
||||
- 服务器用 `JSESSIONID` 找到对应的 `HttpSession`,再通过 `getAttribute("USER_LOGIN_STATE")` 取出用户数据。
|
||||
|
||||
|
||||
|
||||
**令牌(推荐)**
|
||||
#### **令牌JWT(推荐)**
|
||||
|
||||
- 优点:
|
||||
- 支持PC端、移动端
|
||||
@ -1949,6 +1970,10 @@ logging:
|
||||
|
||||
**AOP**(Aspect-Oriented Programming,面向切面编程)是一种编程思想,旨在将横切关注点(如日志、性能监控等)从核心业务逻辑中分离出来。简单来说,AOP 是通过对特定方法的增强(如统计方法执行耗时)来实现**代码复用**和关注点分离。
|
||||
|
||||
|
||||
|
||||
### 快速入门
|
||||
|
||||
**实现业务方法执行耗时统计的步骤**
|
||||
|
||||
1. 定义模板方法:将记录方法执行耗时的公共逻辑提取到**模板方法**中。
|
||||
@ -1958,10 +1983,6 @@ logging:
|
||||
|
||||
通过 AOP,我们可以在不修改原有业务代码的情况下,完成对方法执行耗时的统计。
|
||||
|
||||
|
||||
|
||||
### 快速入门
|
||||
|
||||
**实现步骤:**
|
||||
|
||||
1. 导入依赖:在pom.xml中导入AOP的依赖
|
||||
@ -2062,6 +2083,10 @@ public class MyAspect {
|
||||
|
||||
|
||||
|
||||
只有@Around需要在通知中**主动执行**方法,其他通知只能获取目标方法的参数等。
|
||||
|
||||
|
||||
|
||||
**通知执行顺序**
|
||||
|
||||
1. 默认情况下,不同切面类的通知执行顺序由**类名的字母顺序**决定。
|
||||
@ -2113,29 +2138,6 @@ public class AspectTwo {
|
||||
1. execution(……):根据方法的签名来匹配
|
||||
2. @annotation(……) :根据注解匹配
|
||||
|
||||
#### 公共表示@Pointcut
|
||||
|
||||
使用 `@Pointcut` 注解可以将切点表达式提取到一个独立的方法中,提高代码复用性和可维护性。
|
||||
|
||||
```java
|
||||
@Aspect
|
||||
@Component
|
||||
public class LoggingAspect {
|
||||
|
||||
// 定义一个切点,匹配com.example.service包下 UserService 类的所有方法
|
||||
@Pointcut("execution(public * com.example.service.UserService.*(..))")
|
||||
public void userServiceMethods() {
|
||||
// 该方法仅用来作为切点标识,无需实现任何内容
|
||||
}
|
||||
|
||||
// 在目标方法执行前执行通知,引用上面的切点
|
||||
@Before("userServiceMethods()")
|
||||
public void beforeUserServiceMethods() {
|
||||
System.out.println("【日志】即将执行 UserService 中的方法");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### execution
|
||||
@ -2198,6 +2200,31 @@ execution(* com.example.service.UserService.*(..))
|
||||
|
||||
|
||||
|
||||
#### 公共表示@Pointcut
|
||||
|
||||
使用 `@Pointcut` 注解可以将切点表达式提取到一个独立的方法中,提高代码复用性和可维护性。
|
||||
|
||||
```java
|
||||
@Aspect
|
||||
@Component
|
||||
public class LoggingAspect {
|
||||
|
||||
// 定义一个切点,匹配com.example.service包下 UserService 类的所有方法
|
||||
@Pointcut("execution(public * com.example.service.UserService.*(..))")
|
||||
public void userServiceMethods() {
|
||||
// 该方法仅用来作为切点标识,无需实现任何内容
|
||||
}
|
||||
|
||||
// 在目标方法执行前执行通知,引用上面的切点
|
||||
@Before("userServiceMethods()")
|
||||
public void beforeUserServiceMethods() {
|
||||
System.out.println("【日志】即将执行 UserService 中的方法");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### annotation
|
||||
|
||||
那么如果我们要匹配多个无规则的方法,比如:list()和 delete()这**两个**方法。我们可以借助于另一种切入点表达式annotation来描述这一类的切入点,从而来简化切入点表达式的书写。
|
||||
|
||||
317
自学/Java笔记本.md
317
自学/Java笔记本.md
@ -430,17 +430,17 @@ public class OuterClass {
|
||||
|
||||
下面是四种内部类(成员内部类、局部内部类、静态内部类和匿名内部类)的示例代码,展示了如何用每一种方式来实现`Runnable`的`run()`方法并创建线程。
|
||||
|
||||
1. **成员内部类**
|
||||
**1) 成员内部类**
|
||||
|
||||
定义位置:成员内部类定义在外部类的**成员位置**。
|
||||
定义位置:成员内部类定义在外部类的**成员位置**。
|
||||
|
||||
访问权限:可以无限制地访问外部类的所有成员,**包括私有成员**。
|
||||
访问权限:可以无限制地访问外部类的所有成员,**包括私有成员**。
|
||||
|
||||
实例化方式:需要先创建外部类的实例,然后才能创建内部类的实例。
|
||||
实例化方式:需要先创建外部类的实例,然后才能创建内部类的实例。
|
||||
|
||||
修改限制:不能有静态字段和静态方法(除非声明为常量`final static`)。**成员内部类属于外部类的一个实例,不能独立存在于类级别上。**
|
||||
修改限制:不能有静态字段和静态方法(除非声明为常量`final static`)。**成员内部类属于外部类的一个实例,不能独立存在于类级别上。**
|
||||
|
||||
用途:适用于内部类与外部类关系密切,需要频繁访问外部类成员的情况。
|
||||
用途:适用于内部类与外部类关系密切,需要频繁访问外部类成员的情况。
|
||||
|
||||
```java
|
||||
public class OuterClass {
|
||||
@ -466,17 +466,19 @@ public class OuterClass {
|
||||
|
||||
```
|
||||
|
||||
2. **局部内部类**
|
||||
|
||||
定义位置:局部内部类定义在**一个方法或任何块内**(如:if语句、循环语句内)。
|
||||
|
||||
访问权限:只能访问**所在方法**的`final`或事实上的`final`(即不被后续修改的)局部变量和外部类的成员变量(同成员内部类)。
|
||||
**2.局部内部类**
|
||||
|
||||
实例化方式:只能在定义它们的块中创建实例。
|
||||
定义位置:局部内部类定义在**一个方法或任何块内**(如:if语句、循环语句内)。
|
||||
|
||||
修改限制:同样不能有静态字段和方法。
|
||||
访问权限:只能访问**所在方法**的`final`或事实上的`final`(即不被后续修改的)局部变量和外部类的成员变量(同成员内部类)。
|
||||
|
||||
用途:适用于只在方法或代码块中使用的类,有助于将实现细节隐藏在方法内部。
|
||||
实例化方式:只能在定义它们的块中创建实例。
|
||||
|
||||
修改限制:同样不能有静态字段和方法。
|
||||
|
||||
用途:适用于只在方法或代码块中使用的类,有助于将实现细节隐藏在方法内部。
|
||||
|
||||
```java
|
||||
public class OuterClass {
|
||||
@ -499,17 +501,19 @@ public class OuterClass {
|
||||
|
||||
```
|
||||
|
||||
3. **静态内部类**
|
||||
|
||||
定义位置:定义在外部类内部,但使用`static`修饰。
|
||||
|
||||
访问权限:只能直接访问外部类的静态成员,访问非静态成员需要通过外部类实例。
|
||||
**3.静态内部类**
|
||||
|
||||
实例化方式:**可以直接创建,不需要外部类的实例**。
|
||||
定义位置:定义在外部类内部,但使用`static`修饰。
|
||||
|
||||
修改限制:可以有自己的静态成员。
|
||||
访问权限:只能直接访问外部类的静态成员,访问非静态成员需要通过外部类实例。
|
||||
|
||||
用途:适合当内部类工作不依赖外部类实例时使用,常用于实现与外部类关系不那么密切的帮助类。
|
||||
实例化方式:**可以直接创建,不需要外部类的实例**。
|
||||
|
||||
修改限制:可以有自己的静态成员。
|
||||
|
||||
用途:适合当内部类工作不依赖外部类实例时使用,常用于实现与外部类关系不那么密切的帮助类。
|
||||
|
||||
```java
|
||||
public class OuterClass {
|
||||
@ -541,95 +545,77 @@ public class OuterClass {
|
||||
|
||||
```
|
||||
|
||||
4. **匿名内部类**
|
||||
|
||||
使用匿名内部类实现抽象类相当于临时创建了一个**未命名的子类**,并且立即实例化了这个子类的对象。
|
||||
|
||||
定义位置:在需要使用它的地方立即定义和实例化。
|
||||
**4.匿名内部类**
|
||||
|
||||
访问权限:类似局部内部类,只能访问`final`或事实上的`final`局部变量。
|
||||
**在定义的同时直接实例化**,而不需要显式地声明一个子类的名称。
|
||||
|
||||
实例化方式:在定义时就实例化,不能显式地命名构造器。
|
||||
定义位置:在需要使用它的地方立即**定义**和**实例化**。
|
||||
|
||||
修改限制:不能有任何静态成员。
|
||||
访问权限:类似局部内部类,只能访问`final`或事实上的`final`局部变量。
|
||||
|
||||
用途:适用于创建一次性使用的实例,通常用于接口或抽象类的实现。
|
||||
实例化方式:在定义时就实例化,不能显式地命名构造器。
|
||||
|
||||
修改限制:不能有任何静态成员。
|
||||
|
||||
用途:适用于创建一次性使用的实例,通常用于**接口或抽象类**的实现。
|
||||
|
||||
```java
|
||||
//eg1
|
||||
public class OuterClass {
|
||||
abstract class Animal {
|
||||
public abstract void makeSound();
|
||||
}
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Runnable runnable = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("匿名内部类中的线程正在运行...");
|
||||
// 匿名内部类:临时创建一个 Animal 的子类并实例化
|
||||
Animal dog = new Animal() { // 注意这里的 new Animal() { ... }
|
||||
@Override
|
||||
public void makeSound() {
|
||||
System.out.println("汪汪汪!");
|
||||
}
|
||||
};
|
||||
Thread thread = new Thread(runnable);
|
||||
thread.start();
|
||||
|
||||
dog.makeSound(); // 输出:汪汪汪!
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
如何理解?可以对比**普通子类(显式定义)**,即显示定义了**Dog**来继承Animal
|
||||
|
||||
```java
|
||||
// 抽象类或接口
|
||||
abstract class Animal {
|
||||
public abstract void makeSound();
|
||||
}
|
||||
|
||||
// 显式定义一个具名的子类
|
||||
class Dog extends Animal {
|
||||
@Override
|
||||
public void makeSound() {
|
||||
System.out.println("汪汪汪!");
|
||||
}
|
||||
}
|
||||
|
||||
//eg2 安卓开发中用过很多次!
|
||||
import javax.swing.*;
|
||||
import java.awt.event.*;
|
||||
|
||||
public class GUIApp {
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
JFrame frame = new JFrame("Demo");
|
||||
JButton button = new JButton("Click Me!");
|
||||
|
||||
// 匿名内部类用于事件监听
|
||||
button.addActionListener(new ActionListener() {
|
||||
public void actionPerformed(ActionEvent e) {
|
||||
System.out.println("Button was clicked!");
|
||||
}
|
||||
});
|
||||
|
||||
frame.add(button);
|
||||
frame.setSize(300, 200);
|
||||
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
|
||||
frame.setVisible(true);
|
||||
// 实例化具名的子类
|
||||
Animal dog = new Dog();
|
||||
dog.makeSound(); // 输出:汪汪汪!
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
1. 创建`ActionListener`实例
|
||||
|
||||
```java
|
||||
new ActionListener() {
|
||||
public void actionPerformed(ActionEvent e) {
|
||||
System.out.println("Button was clicked!");
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这部分代码是匿名内部类的核心。这里发生的事情包括:
|
||||
|
||||
- **`new ActionListener()`**:这表示创建了`ActionListener`接口的一个实现。由于`ActionListener`是一个接口,我们不能直接实例化它,而是需要提供该接口的一个**具体实现**。在这种情况下,我们通过创建一个匿名内部类来提供实现。
|
||||
- **大括号 `{ ... }`**:在这对大括号内,我们定义了接口中需要实现的方法。对于`ActionListener`接口,必须实现`actionPerformed(ActionEvent e)`方法。
|
||||
- **方法实现**:
|
||||
- **`public void actionPerformed(ActionEvent e)`**:这是`ActionListener`接口要求实现的方法,用于响应事件。这里的方法定义了当事件发生时(例如,用户点击按钮)执行的操作。
|
||||
- **`System.out.println("Button was clicked!");`**:这是`actionPerformed`方法的具体实现,即当按钮被点击时,控制台将输出一条消息。
|
||||
|
||||
2. 将匿名内部类添加为事件监听器
|
||||
|
||||
```java
|
||||
button.addActionListener(...);
|
||||
```
|
||||
|
||||
**`button.addActionListener(EventListener)`**:这是`JButton`类的一个方法,用于添加事件监听器。这个方法的参数是`ActionListener`类型的对象,这里传入的正是我们刚刚创建的匿名内部类的实例。
|
||||
|
||||
|
||||
|
||||
#### Lambda表达式
|
||||
|
||||
Lambda表达式特别适用于**只有单一抽象方法**的接口(也即**函数式接口**)。lambda 表达式主要用于**实现**函数式接口。
|
||||
函数式接口:只有**单一抽象方法**的接口。
|
||||
|
||||
**`@FunctionalInterface` 注解**:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。
|
||||
|
||||
这个时候可以用Lambda代替匿名内部类!!!
|
||||
|
||||
```java
|
||||
public class LambdaExample {
|
||||
// 定义函数式接口,doSomething 有两个参数
|
||||
@ -637,6 +623,16 @@ public class LambdaExample {
|
||||
interface MyInterface {
|
||||
void doSomething(int a, int b);
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
// 使用匿名内部类实现接口方法
|
||||
MyInterface obj = new MyInterface() {
|
||||
@Override
|
||||
public void doSomething(int a, int b) {
|
||||
System.out.println("参数a: " + a + ", 参数b: " + b);
|
||||
}
|
||||
};
|
||||
obj.doSomething(5, 10);
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 使用 Lambda 表达式实现接口方法
|
||||
@ -648,23 +644,35 @@ public class LambdaExample {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**lambda表达式格式**:`(参数列表) -> { 代码块 }`
|
||||
|
||||
或 (参数列表) ->表达式;
|
||||
或 `(参数列表) ->表达式`
|
||||
|
||||
在上述Lambda表达式中,因为`MyInterface`接口的`doSomething()`方法不接受任何参数并且没有返回值,所以Lambda表达式的参数列表为空(`()`),后面跟的是执行的代码块。
|
||||
如果上述`MyInterface`接口的`doSomething()`方法不接受任何参数并且没有返回值:
|
||||
|
||||
```java
|
||||
// Lambda 表达式(无参数)
|
||||
MyInterface obj = () -> {
|
||||
System.out.println("doSomething 被调用,无参数!");
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
|
||||
**以下是lambda表达式的重要特征:**
|
||||
|
||||
可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
|
||||
|
||||
可选的参数圆括号:**一个参数无需定义圆括号**,但无参数或多个参数需要定义圆括号。
|
||||
可选的大括号:如果主体只有一个语句,可以不使用大括号。
|
||||
|
||||
可选的大括号:如果主体**只有一个语句,可以不使用大括号**。
|
||||
|
||||
可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,使用大括号需显示retrun;如果函数是void则不需要返回值。
|
||||
|
||||
```java
|
||||
// 定义一个函数式接口
|
||||
// 定义一个函数式接口,只有一个抽象方法
|
||||
interface Calculator {
|
||||
int add(int a, int b);
|
||||
}
|
||||
@ -682,7 +690,6 @@ public class LambdaReturnExample {
|
||||
System.out.println("calc2: " + calc2.add(5, 3)); // 输出:8
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -692,14 +699,18 @@ public class LambdaReturnExample {
|
||||
`list.forEach`这个方法接受一个**函数式接口**作为参数。它只有一个抽象方法 `accept(T t)`因此,可以使用 lambda 表达式来**实现**。
|
||||
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
import java.util.List;
|
||||
@FunctionalInterface
|
||||
public interface Consumer<T> {
|
||||
void accept(T t);
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
List<String> list = Arrays.asList("Apple", "Banana", "Cherry", "Date");
|
||||
|
||||
// 使用 Lambda 表达式迭代列表
|
||||
// 使用 Lambda 表达式迭代列表,这段 lambda,就是在“实现” void accept(String item) 这个方法——把每个元素传给 accept,然后打印它。
|
||||
list.forEach(item -> System.out.println(item));
|
||||
}
|
||||
}
|
||||
@ -708,17 +719,18 @@ public class Main {
|
||||
|
||||
|
||||
|
||||
示例2:
|
||||
示例2:为什么可以使用 **Lambda 表达式自定义排序**?
|
||||
|
||||
`Collections.sort` 方法用于对列表进行排序,它接受两个参数
|
||||
因为**`Comparator<T>` 是一个函数式接口**,**只有一个抽象方法 `compare(T o1, T o2)`**
|
||||
|
||||
第一个参数:要排序的列表(这里是一个 `List<String>`)。
|
||||
|
||||
第二个参数:一个实现了 `Comparator` 接口的比较器,用于指定排序规则。
|
||||
|
||||
如果返回负数,表示 `a` 应该排在 `b` 的前面;
|
||||
|
||||
如果返回正数,则 `a` 应该排在 `b` 的后面。
|
||||
```java
|
||||
@FunctionalInterface
|
||||
public interface Comparator<T> {
|
||||
int compare(T o1, T o2); // 唯一的抽象方法
|
||||
|
||||
// 其他方法(如 thenComparing、reversed)都是默认方法或静态方法,不影响函数式接口特性
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
@ -730,7 +742,7 @@ public class Main {
|
||||
List<String> names = Arrays.asList("John", "Jane", "Adam", "Dana");
|
||||
|
||||
// 使用Lambda表达式排序
|
||||
Collections.sort(names, (String a, String b) -> a.compareTo(b));
|
||||
Collections.sort(names, (a, b) -> a.compareTo(b));
|
||||
|
||||
// 输出排序结果
|
||||
names.forEach(name -> System.out.println(name));
|
||||
@ -817,9 +829,10 @@ System.out.println("obj.num1 = " + obj.staticVariable); #通过示例访问也
|
||||
- 类中的其他静态成员变量。
|
||||
- 类中的静态方法。
|
||||
|
||||
**不能直接访问:**
|
||||
- **不能直接访问:**
|
||||
|
||||
- 非静态成员变量。
|
||||
|
||||
- 非静态方法(必须通过对象实例访问)。
|
||||
|
||||
```java
|
||||
@ -858,80 +871,64 @@ MyClass.staticMethod(); // 通过类名直接调用静态方法
|
||||
|
||||
`super` 关键字有两种主要的使用方法:访问父类的成员和调用父类的构造方法。
|
||||
|
||||
1. 访问父类的成员
|
||||
1)访问父类的成员
|
||||
|
||||
可以使用 `super` 关键字来引用父类的字段或方法。这在子类中**存在同名的字段或方法**时特别有用。
|
||||
可以使用 `super` 关键字来引用父类的字段或方法。这在子类中**存在同名的字段或方法**时特别有用。
|
||||
|
||||
因为父类的成员变量和方法都是默认的访问修饰符,可以继承给子类,而子类也定义了同名的xxx,发生了**变量隐藏**(shadowing)。
|
||||
因为父类的成员变量和方法都是默认的访问修饰符,可以继承给子类,而子类也定义了同名的xxx,发生了**变量隐藏**(shadowing)。
|
||||
|
||||
```java
|
||||
class Parent {
|
||||
int num = 10;
|
||||
void display() {
|
||||
System.out.println("Parent class method");
|
||||
}
|
||||
}
|
||||
|
||||
class Child extends Parent {
|
||||
int num = 20;
|
||||
void display() {
|
||||
System.out.println("Child class method");
|
||||
}
|
||||
void print() {
|
||||
System.out.println("Child class num: " + num); // 访问子类中的num
|
||||
System.out.println("Parent class num: " + super.num); // 使用super关键字访问父类中的num
|
||||
super.display(); // 调用父类中的display方法
|
||||
}
|
||||
}
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Child obj = new Child();
|
||||
obj.print();
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```java
|
||||
Child class num: 20
|
||||
Parent class num: 10
|
||||
Parent class method
|
||||
```
|
||||
|
||||
2. 调用父类的构造方法
|
||||
2)调用父类的构造方法
|
||||
|
||||
可以使用 `super` 关键字调用父类的构造方法。这通常在子类的构造方法中使用,用于显式地调用父类的构造方法。
|
||||
|
||||
```java
|
||||
class Parent {
|
||||
int num = 10; // 父类字段
|
||||
|
||||
Parent() {
|
||||
System.out.println("Parent class constructor");
|
||||
}
|
||||
|
||||
void display() {
|
||||
System.out.println("Parent class method");
|
||||
}
|
||||
}
|
||||
|
||||
class Child extends Parent {
|
||||
int num = 20; // 子类同名字段,隐藏了父类的 num
|
||||
|
||||
Child() {
|
||||
super(); // 调用父类的构造方法
|
||||
super(); // 调用父类构造方法
|
||||
System.out.println("Child class constructor");
|
||||
}
|
||||
|
||||
void print() {
|
||||
System.out.println("Child class num: " + num); // 访问子类字段
|
||||
System.out.println("Parent class num: " + super.num); // 访问父类被隐藏的字段
|
||||
display(); // 调用子类重写的方法
|
||||
super.display(); // 明确调用父类的方法
|
||||
}
|
||||
}
|
||||
|
||||
public class Main {
|
||||
public static void main(String[] args) {
|
||||
Child obj = new Child();
|
||||
System.out.println("---- Now calling print() ----");
|
||||
obj.print();
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
运行结果:
|
||||
|
||||
```java
|
||||
Parent class constructor
|
||||
Child class constructor
|
||||
---- Now calling print() ----
|
||||
Child class num: 20
|
||||
Parent class num: 10
|
||||
Parent class method
|
||||
Parent class method
|
||||
```
|
||||
|
||||
|
||||
@ -964,7 +961,7 @@ protected static volatile int counter; #定义成员变量
|
||||
|
||||
#### 全限定名
|
||||
|
||||
全限定名(Fully Qualified Name,简称 FQN)指的是一个类或接口在 Java 中的完整名称,包括它所在的包名。例如:
|
||||
全限定名(Fully Qualified Name,简称 FQN)指的是一个**类或接口**在 Java 中的完整名称,**包括它所在的包名**。例如:
|
||||
|
||||
- 对于类 `Integer`,其全限定名是 `java.lang.Integer`。
|
||||
- 对于自定义的类 `DeptServiceImpl`,如果它位于包 `edu.zju.zy123.service.impl` 中,那么它的全限定名就是 `edu.zju.zy123.service.impl.DeptServiceImpl`。
|
||||
@ -1087,24 +1084,23 @@ Java继承了父类**非私有**的成员变量和成员方法,但是请注意
|
||||
|
||||
- **重载**发生在同一个类中,与继承无关;
|
||||
- **重写**发生在子类中,依赖继承关系,实现运行时多态。
|
||||
|
||||
```java
|
||||
class Calculator {
|
||||
int add(int a, int b) {
|
||||
return a + b;
|
||||
}
|
||||
|
||||
double add(double a, double b) {
|
||||
return a + b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
```java
|
||||
class Calculator {
|
||||
int add(int a, int b) {
|
||||
return a + b;
|
||||
}
|
||||
|
||||
double add(double a, double b) {
|
||||
return a + b;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 抽象类
|
||||
|
||||
**定义**
|
||||
抽象类是包含至少一个抽象方法的类。抽象方法没有实现,只定义了方法的签名。
|
||||
**注意:** 抽象类不能被实例化。
|
||||
|
||||
@ -1156,7 +1152,6 @@ class Dog extends Animal {
|
||||
}
|
||||
};
|
||||
animal.makeSound(); // 输出:Anonymous animal sound
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -354,7 +354,16 @@ git config --global credential.helper store //将凭据保存到磁盘上(明
|
||||
|
||||
### .gitignore(忽略某些文件)
|
||||
|
||||
**如果不小心commit了如何撤销?**
|
||||

|
||||
|
||||
**`.gitignore` 的生效规则**
|
||||
|
||||
- **对未跟踪的文件**:
|
||||
被标记的文件会被忽略,不会出现在 Git 提交列表中(IDEA 中会显示为灰色或隐藏)。
|
||||
- **对已跟踪的文件**:
|
||||
如果 `application-local.yml` **之前已经被 Git 跟踪过**(即曾经提交过),`.gitignore` 不会自动将其从版本控制中移除。它仍会出现在提交列表中。
|
||||
|
||||
**如果不小心`commit`了或者`git add`(暂存但未提交)如何撤销?**
|
||||
|
||||
例:如果在添加`.gitignore`文件前不小心提交了`.idea`文件夹,到项目根目录,git bash here
|
||||
|
||||
@ -365,26 +374,22 @@ git commit -m "Remove .idea from tracking"
|
||||
|
||||
|
||||
|
||||
在.gitignore文件进行添加
|
||||
|
||||
**为什么`.gitignore`文件不放在`.git`文件夹中?**
|
||||
|
||||
- **用途不同**:`.git`文件夹由Git自动创建,用于存储Git的内部数据,包括所有提交记录、配置和对象等。用户一般不需要手动修改这个文件夹里的内容。而`.gitignore`文件是用户创建和维护的,用于定义哪些文件和目录应被Git忽略。
|
||||
- **便于版本控制**:`.gitignore`文件放在项目的根目录中,可以和项目代码一起被版本控制,这样其他协作开发者也能看到和使用相同的忽略规则。如果把`.gitignore`放在`.git`文件夹中,它就不会被版本控制系统追踪到。
|
||||
**便于版本控制**:`.gitignore`文件放在项目的**根目录**中,可以和项目代码一起被版本控制,这样其他协作开发者也能看到和使用相同的忽略规则。如果把`.gitignore`放在`.git`文件夹中,它就不会被版本控制系统追踪到。
|
||||
|
||||
|
||||
|
||||
### 撤销Git版本控制
|
||||
|
||||
直接把项目文件夹中的.git文件夹删除即可(开启查看隐藏文件夹可看到)
|
||||
|
||||
若idea/pycharm报错:
|
||||
|
||||
COVID-19-Detector is registered as a Git root, but no Git repositories were found there.
|
||||
|
||||

|
||||
1.直接把项目文件夹中的.git文件夹删除即可(开启查看隐藏文件夹可看到)
|
||||
|
||||
2:使用 Git 命令(保留文件,仅移除版本控制)
|
||||
|
||||
```shell
|
||||
git init # 重新初始化(可选,非必须)
|
||||
git rm -r --cached . # 移除所有文件的跟踪状态
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
@ -280,7 +280,7 @@ public static List<String> splitBySpace(String s) {
|
||||
在指定位置插入字符串。(有妙用,**头插法**可以实现倒序)`insert(0,str)`
|
||||
|
||||
3.**`delete(int start, int end)`**
|
||||
删除从 `start` 到 `end` 索引之间的字符。
|
||||
删除从 `start` 到 `end` 索引之间的字符。(包括start,不包括end)
|
||||
|
||||
4.**`deleteCharAt(int index)`**
|
||||
删除指定位置的字符。
|
||||
|
||||
80
自学/微服务.md
80
自学/微服务.md
@ -2,6 +2,86 @@
|
||||
|
||||
## 踩坑总结
|
||||
|
||||
### Mybatis-PLUS
|
||||
|
||||
分页不生效,因为mybatis-plus自3.5.9起,默认不包含分页插件,需要自己引入。
|
||||
|
||||
```xml
|
||||
<dependencyManagement>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>com.baomidou</groupId>
|
||||
<artifactId>mybatis-plus-bom</artifactId>
|
||||
<version>3.5.9</version>
|
||||
<type>pom</type>
|
||||
<scope>import</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</dependencyManagement>
|
||||
```
|
||||
|
||||
```xml
|
||||
<!-- MyBatis Plus 分页插件 -->
|
||||
<dependency>
|
||||
<groupId>com.baomidou</groupId>
|
||||
<artifactId>mybatis-plus-jsqlparser-4.9</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
config包下新建:
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
@MapperScan("edu.whut.smilepicturebackend.mapper")
|
||||
public class MybatisPlusConfig {
|
||||
|
||||
/**
|
||||
* 拦截器配置
|
||||
*
|
||||
* @return {@link MybatisPlusInterceptor}
|
||||
*/
|
||||
@Bean
|
||||
public MybatisPlusInterceptor mybatisPlusInterceptor() {
|
||||
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
|
||||
// 分页插件
|
||||
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
|
||||
return interceptor;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 雪花算法表示精度问题
|
||||
|
||||
“雪花算法”(Snowflake)生成的 ID 本质上是一个 64 位的整数(Java等后端里通常对应 `long` ),而浏览器端的 JavaScript `Number` 类型只能安全地表示到 2^53−1 以内的整数,超出这个范围就会出现 “精度丢失”──即低位那几位数字可能会被四舍五入掉,导致 ID 读取或比对出错。因此,最佳实践是:
|
||||
|
||||
1. **后端依然用 `long`(或等价的 64 位整数)存储和处理雪花 ID。**
|
||||
2. **对外接口(REST/graphQL 等)返回时,将这类超出 JS 安全范围的整数序列化为字符串**,比如:
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
public class JacksonConfig {
|
||||
|
||||
private static final String DATE_FORMAT = "yyyy-MM-dd";
|
||||
private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
|
||||
private static final String TIME_FORMAT = "HH:mm:ss";
|
||||
|
||||
@Bean
|
||||
public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() {
|
||||
return builder -> {
|
||||
// 将所有 long / Long 类型序列化成 String
|
||||
SimpleModule longToString = new SimpleModule();
|
||||
longToString.addSerializer(Long.class, ToStringSerializer.instance);
|
||||
longToString.addSerializer(Long.TYPE, ToStringSerializer.instance);
|
||||
builder.modules(longToString);
|
||||
};
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 包扫描问题(非常容易出错!)
|
||||
|
||||
以 Spring Boot 为例,框架默认会扫描启动类所在包及其子包中的组件(`@Component`/`@Service`/`@Repository`/`@Configuration` 等),将它们注册到 Spring 容器中。
|
||||
|
||||
@ -22,4 +22,17 @@
|
||||
private static final long serialVersionUID = -1321880859645675653L;
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
创建图片的业务流程
|
||||
创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
|
||||
|
||||
有两种常见的处理方式:
|
||||
|
||||
1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的url存储地址;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
|
||||
2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功南无就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
|
||||
当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user