diff --git a/Java/Docker指南.md b/自学/Docker指南.md
similarity index 100%
rename from Java/Docker指南.md
rename to 自学/Docker指南.md
diff --git a/Java/JavaWeb——前端.md b/自学/JavaWeb——前端.md
similarity index 100%
rename from Java/JavaWeb——前端.md
rename to 自学/JavaWeb——前端.md
diff --git a/Java/JavaWeb——后端.md b/自学/JavaWeb——后端.md
similarity index 91%
rename from Java/JavaWeb——后端.md
rename to 自学/JavaWeb——后端.md
index 88bd94d..117f5d2 100644
--- a/Java/JavaWeb——后端.md
+++ b/自学/JavaWeb——后端.md
@@ -73,8 +73,6 @@ Version:标识版本号(如 `1.0-SNAPSHOT`、`2.7.3`)
**导入Maven项目**
-
-
**(一)单独的Maven项目**
打开 IDEA,在主界面选择 Open(或者在菜单栏选择 File -> Open)。
@@ -93,6 +91,8 @@ IDEA 会自动解析 `pom.xml`,下载依赖并构建项目结构。
选择待导入项目的根目录(其中包含 `pom.xml`),IDEA 会将其导入为同一个工程下的另一个模块(Module)。
+它们 看起来在一个工程里了,但**仍然是两个独立的** Maven 模块。
+
**(三)两个模块有较强的关联**
@@ -309,6 +309,86 @@ A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被
| ==500== | **`Internal Server Error`** | **服务器发生不可预期的错误**。服务器出异常了,赶紧看日志去吧 |
| 503 | **`Service Unavailable`** | **服务器尚未准备好处理请求**,服务器刚刚启动,还未初始化好 |
+
+
+## 开发规范
+
+### REST风格
+
+在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
+
+什么是REST风格呢?
+
+- REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
+
+**传统URL风格如下:**
+
+```url
+http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
+http://localhost:8080/user/saveUser POST:新增用户
+http://localhost:8080/user/updateUser PUT:修改用户
+http://localhost:8080/user/deleteUser?id=1 DELETE:删除id为1的用户
+```
+
+我们看到,原始的传统URL,定义比较复杂,而且将资源的访问行为对外暴露出来了。
+
+**基于REST风格URL如下:**
+
+```text
+http://localhost:8080/users/1 GET:查询id为1的用户
+http://localhost:8080/users POST:新增用户
+http://localhost:8080/users PUT:修改用户
+http://localhost:8080/users/1 DELETE:删除id为1的用户
+```
+
+其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
+
+**REST风格后端代码:**
+
+```text
+@RestController
+@RequestMapping("/depts") //定义当前控制器的请求前缀
+public class DeptController {
+
+ // GET: 查询资源
+ @GetMapping("/{id}")
+ public Dept getDept(@PathVariable Long id) { ... }
+
+ // POST: 新增资源
+ @PostMapping
+ public void createDept(@RequestBody Dept dept) { ... }
+
+ // PUT: 更新资源
+ @PutMapping
+ public void updateDept(@RequestBody Dept dept) { ... }
+
+ // DELETE: 删除资源
+ @DeleteMapping("/{id}")
+ public void deleteDept(@PathVariable Long id) { ... }
+}
+
+```
+
+
+
+### 开发流程
+
+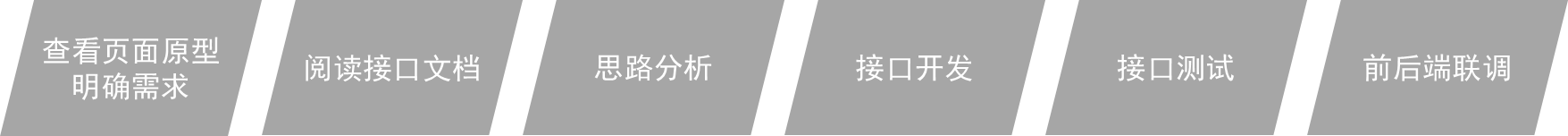
+
+1. 查看页面原型明确需求
+ - 根据页面原型和需求,进行表结构设计、编写接口文档(已提供)
+
+2. 阅读接口文档
+3. 思路分析
+4. 功能接口开发
+ - 就是开发后台的业务功能,一个业务功能,我们称为一个接口(Controller 中一个完整的处理请求的方法)
+5. 功能接口测试
+ - 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试
+6. 前后端联调测试
+ - 和前端开发人员开发好的前端工程一起测试
+
+
+
## SpringBoot
**SpringBoot的WEB默认内嵌了tomcat服务器,非常方便!!!**
@@ -387,9 +467,9 @@ public class RequestController {
- 如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗?
-解决方案:可以使用Spring提供的@RequestParam注解完成映射
+解决方案:可以使用Spring提供的`@RequestParam`注解完成映射
-在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下:
+在方法形参前面加上 `@RequestParam` 然后通过value属性执行请求参数名,从而完成映射。代码如下:
```text
@RestController
@@ -406,6 +486,8 @@ public class RequestController {
}
```
+
+
#### 实体参数
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
@@ -414,10 +496,12 @@ public class RequestController {
复杂实体对象的封装,需要遵守如下规则:
-- **请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。**
+- **请求参数名与形参对象属性名相同**,按照对象层次结构关系即可接收嵌套实体类属性参数。

+注意:这里User前面不能加`@RequestBody`是因为请求方式是 (表单)或 URL 参数;如果是JSON请求体就必须加。
+
```text
@RequestMapping("/complexpojo")
public String complexpojo(User user){
@@ -438,7 +522,6 @@ public class User {
```
```text
-package edu.whut.pojo;
@Data
@NoArgsConstructor
@AllArgsConstructor
@@ -448,9 +531,11 @@ public class Address {
}
```
+
+
#### 数组参数
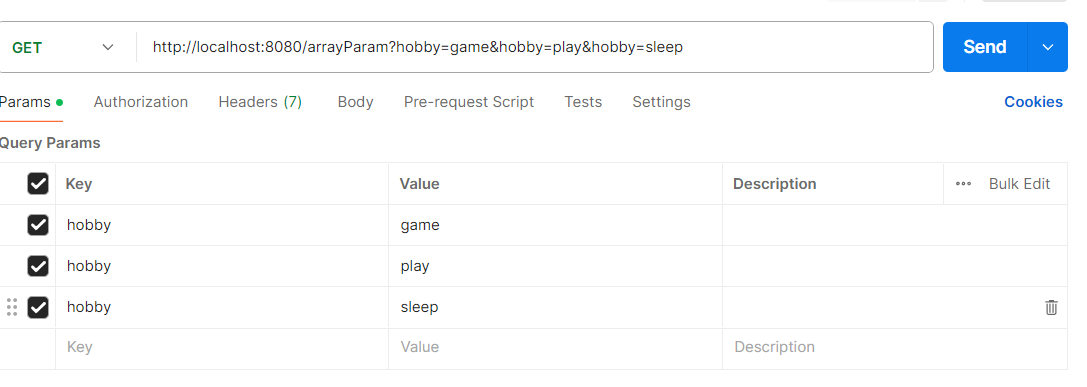
-数组参数:**请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数**
+数组参数:请求参数名与形参数组**名称相同**且请求参数为**多个**,定义数组类型形参即可接收参数
```text
@RestController
@@ -466,94 +551,20 @@ public class RequestController {
-#### JSON格式参数
-
-json数组:
-
-```text
-{
- "退还时间点": [
- "与中标人签订合同后 5日内",
- "投标截止时间前撤回投标文件并书面通知招标人的,2日内",
- "开标现场投标文件被拒收,开标结束后,2日内",
- "招标项目评标结果公示后,2日内退还未进入中标候选人排名的投标人",
- "招标失败需重新组织招标或不再招标的,评标结束后,2日内",
- "招标人与中标人签订书面合同并报市公共资源交易监督管理局备案后,2日内退还中标人及未中标候选人的"
- ],
- "employees": [
- { "firstName": "John", "lastName": "Doe" },
- { "firstName": "Anna", "lastName": "Smith" },
- { "firstName": "Peter", "lastName": "Jones" }
- ]
-}
-
-```
-
-#### JSON 格式的核心特征
-
-- **数据为键值对**:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如 `"firstName": "John"`。
-- **使用大括号表示对象**:JSON 使用大括号 `{}` 包围对象,对象可以包含多个键值对。
-- **使用方括号表示数组**:JSON 使用方括号 `[]` 表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在你的示例中,`"employees"` 是一个数组,数组中的每个元素都是一个对象。
-
-
-
-
-
-我们学习JSON格式参数,主要从以下两个方面着手:
-
-1. Postman在发送请求时,如何传递json格式的请求参数
-2. 在服务端的controller方法中,如何接收json格式的请求参数
-
-Postman发送JSON格式数据:
-
-
-
-服务端Controller方法接收JSON格式数据:
-
-- 传递json格式的参数,在Controller中会使用实体类进行封装。
-- 封装规则:**JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。**
-
-```text
-@RestController
-public class RequestController {
- //JSON参数
- @RequestMapping("/jsonParam")
- public String jsonParam(@RequestBody User user){
- System.out.println(user);
- return "OK";
- }
-}
-```
-
-
-
-#### JSON格式工具包
-
-//把Result对象转换为JSON格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
- String json = JSONObject.toJSONString(responseResult);
-
-```text
-
- com.alibaba
- fastjson
- 1.2.76
-
-```
-
#### 路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
-~~~
+~~~text
http://localhost:8080/user/1
http://localhost:880/user/1/0
~~~
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
-```text
+```java
@RestController
public class RequestController {
//路径参数
@@ -567,15 +578,128 @@ public class RequestController {
+#### JSON格式参数
+
+
+
+```java
+{
+ "backtime": [
+ "与中标人签订合同后 5日内",
+ "投标截止时间前撤回投标文件并书面通知招标人的,2日内",
+ "开标现场投标文件被拒收,开标结束后,2日内"
+ ],
+ "employees": [
+ { "firstName": "John", "lastName": "Doe" },
+ { "firstName": "Anna", "lastName": "Smith" },
+ { "firstName": "Peter", "lastName": "Jones" }
+ ]
+}
+
+```
+
+**JSON 格式的核心特征**
+
+- 数据为键值对:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如 `"firstName": "John"`。
+- 使用大括号表示对象:JSON 使用大括号 `{}` 包围对象,对象可以包含多个键值对。
+- 使用方括号表示数组:JSON 使用方括号 `[]` 表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在该示例中:`"employees"` 是一个对象数组,数组中的每个元素都是一个对象。
+
+
+
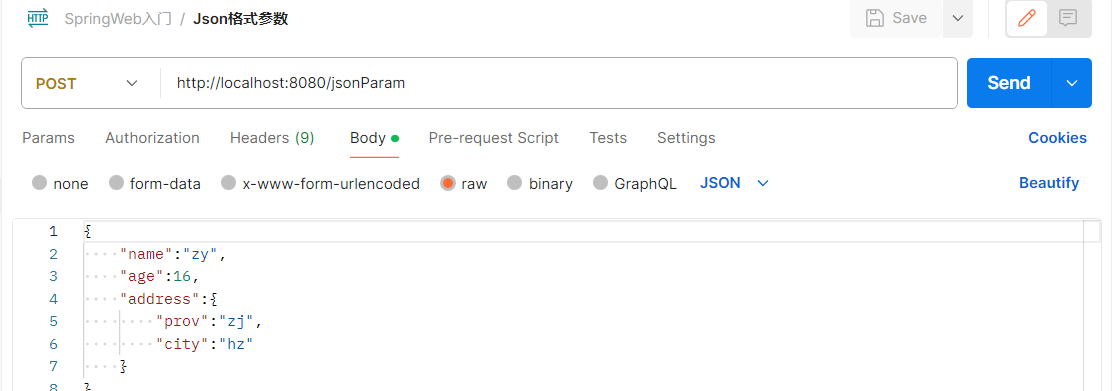
+Postman如何发送JSON格式数据:
+
+
+
+
+
+服务端Controller方法如何接收JSON格式数据:
+
+- 传递json格式的参数,在Controller中会使用实体类进行封装。
+- 封装规则:JSON数据**键名与形参对象属性名**相同,定义POJO类型形参即可接收参数。需要使用 `@RequestBody`标识。
+
+```java
+@Data
+@NoArgsConstructor
+@AllArgsConstructor
+public class DataDTO {
+ private List backtime;
+ private List employees;
+}
+```
+
+```java
+@Data
+@NoArgsConstructor
+@AllArgsConstructor
+public class Employee {
+ private String firstName;
+ private String lastName;
+}
+```
+
+```java
+@RestController
+public class DataController {
+
+ @PostMapping("/data")
+ public String receiveData(@RequestBody DataDTO data) {
+ System.out.println("Backtime: " + data.getBacktime());
+ System.out.println("Employees: " + data.getEmployees());
+ return "OK";
+ }
+}
+```
+
+
+
+**JSON格式工具包**
+
+用于高效地进行 JSON 与 Java 对象之间的序列化和反序列化操作。
+
+引入依赖:
+
+```text
+
+ com.alibaba
+ fastjson
+ 1.2.76
+
+```
+
+使用:
+
+```java
+import com.alibaba.fastjson.JSON;
+
+public class FastJsonDemo {
+ public static void main(String[] args) {
+ // 创建一个对象
+ User user = new User("Alice", 30);
+
+ // 对象转 JSON 字符串
+ String jsonString = JSON.toJSONString(user);
+ System.out.println("JSON String: " + jsonString);
+
+ // JSON 字符串转对象
+ User parsedUser = JSON.parseObject(jsonString, User.class);
+ System.out.println("Parsed User: " + parsedUser);
+ }
+}
+// JSON String: {"age":30,"name":"Alice"}
+// Parsed User: User(name=Alice, age=30)
+```
+
+
+
### SpringBoot响应
**@ResponseBody注解:**
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- - 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
+ - 如果返回值类型是实体对象/集合,将会**转换为JSON格式**后在响应给浏览器
-@RestController = @Controller + @ResponseBody
+`@RestController` = `@Controller` + `@ResponseBody`
@@ -585,7 +709,9 @@ public class RequestController {

-统一的返回结果使用类来描述,在这个结果中包含:
+
+
+**定义统一返回结果类**
- 响应状态码:当前请求是成功,还是失败
@@ -625,35 +751,71 @@ public class Result {
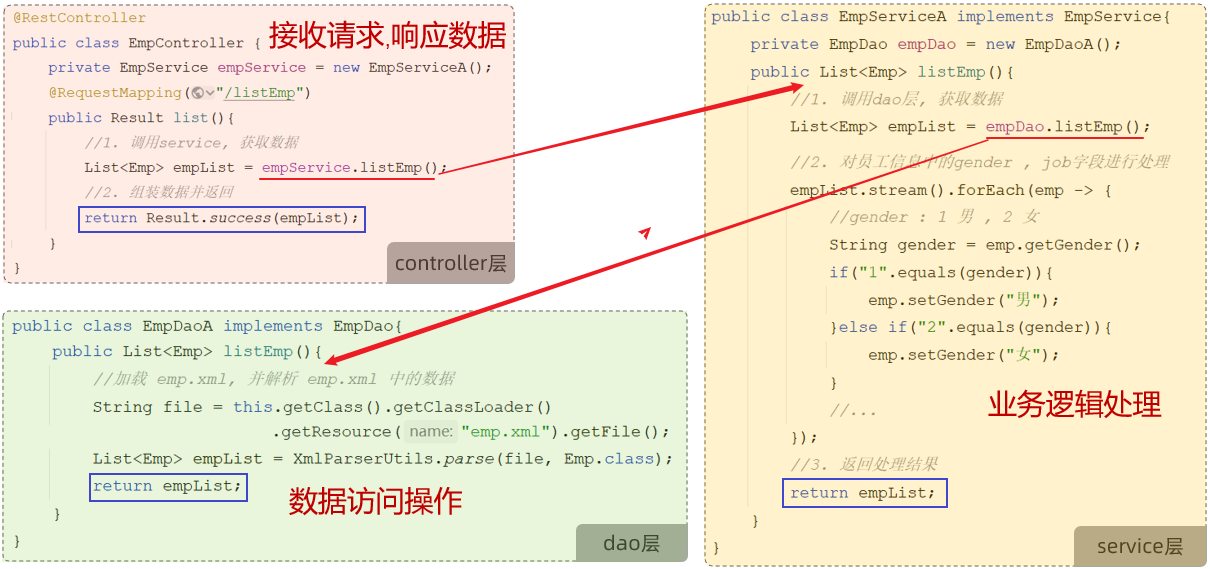
#### 三层架构
-Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程
+Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程。
-**但是**,这样每次要更换ServiceA->ServiceB时,需要修改Controller层的代码!
+传统模式:对象的创建、管理和依赖关系都由程序员手动编写代码完成,程序内部控制对象的生命周期。
-```text
-private EmpService empService=new EmpServiceA(); //原来
-private EmpService empService=new EmpServiceB(); //现在
+例如:
+
+```java
+public class A {
+ private B b;
+ public A() {
+ b = new B(); // A 自己创建并管理 B 的实例
+ }
+}
```
+假设有类 A 依赖类 B,在传统方式中,类 A 可能在构造方法或方法内部直接调用 `new B()` 来创建 B 的实例。
+
+如果 B 的创建方式发生变化,A 也需要修改代码。这就导致了耦合度较高。
+
+
+
**软件设计原则:高内聚低耦合。**
> 高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
>
> 低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
+
+
#### IOC&DI 分层解耦
+**外部容器**(例如 Spring 容器)是一个负责管理对象创建、配置和生命周期的软件系统。
+
+- 它扫描项目中的类,根据预先配置或注解,将这些类实例化为 Bean。
+- 它维护各个 Bean 之间的依赖关系,并在创建 Bean 时把它们所需的依赖“注入”进去。
+
+**依赖注入(DI)**:类 A 不再自己创建 B,而是声明自己需要一个 B,容器在创建 A 时会自动将 B 的实例提供给 A。
+
+```java
+public class A {
+ private B b;
+ // 通过构造器注入依赖
+ public A(B b) {
+ this.b = b;
+ }
+}
+```
+
+**Bean 对象**:在 Spring 中,被容器管理的对象称为 Bean。通过注解(如 `@Component`, `@Service`, `@Repository`, `@Controller`),可以将一个普通的 Java 类声明为 Bean,容器会负责它的创建、初始化以及生命周期管理。
+
+
+
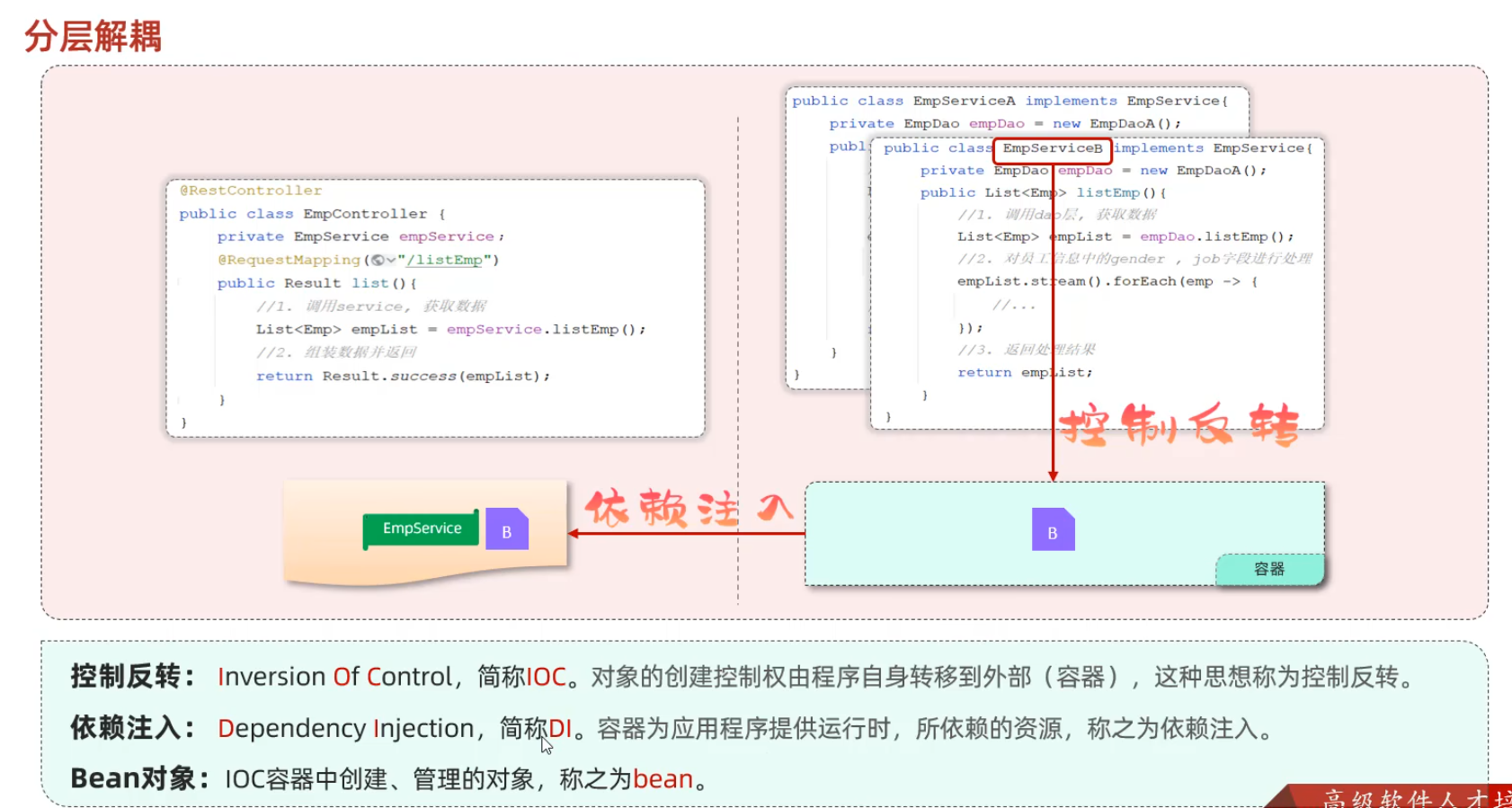
任务:完成Controller层、Service层、Dao层的代码解耦
-- 思路:
- 1. 删除Controller层、Service层中new对象的代码
- 2. Service层及Dao层的**实现类**,交给IOC容器管理
- 3. 为Controller及Service注入运行时依赖的对象
- - Controller程序中注入依赖的Service层对象
- - Service程序中注入依赖的Dao层对象
+思路:
+1. 删除Controller层、Service层中new对象的代码
+2. Service层及Dao层的**实现类**,交给IOC容器管理
+3. 为Controller及Service注入运行时依赖的对象
+ - Controller程序中注入依赖的Service层对象
+
+ - Service程序中注入依赖的Dao层对象
@@ -663,13 +825,13 @@ private EmpService empService=new EmpServiceB(); //现在
第2步:Service层及Dao层的实现类,交给IOC容器管理
-- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
+使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
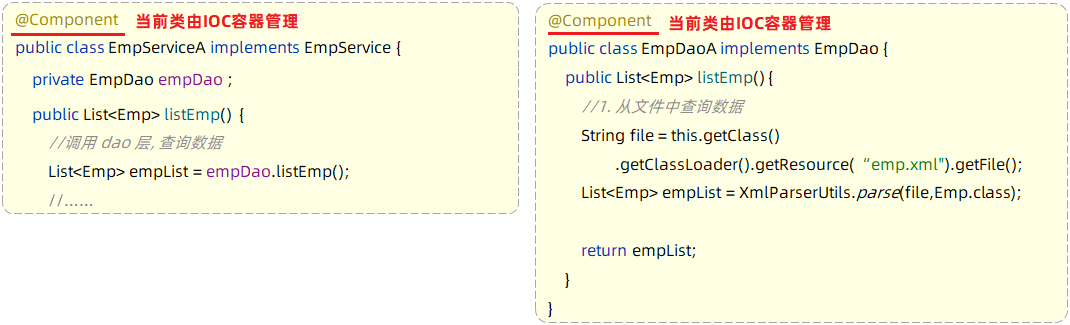
第3步:为Controller及Service注入运行时依赖的对象
-- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象
+使用Spring提供的注解:`@Autowired` ,就可以实现程序运行时IOC容器自动注入需要的依赖对象

@@ -691,11 +853,14 @@ Component衍生注解
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少)DAO |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
+注:@Mapper 注解本身并不是 Spring 框架提供的,是用于 *MyBatis* 数据层的接口标识,但效果类似。
+
## 常见的注解!!
-1. `@RequestMapping("/jsonParam")`:这是一个控制器方法级别的注解,用于将HTTP请求映射到相应的处理方法上。在这个例子中,它表示当收到路径为 "/jsonParam" 的HTTP请求时,应该调用这个方法来处理请求。`@RequestMapping` 注解可以用来指定路径、HTTP方法、请求参数等信息,以便Spring框架能够正确地将请求分发到对应的处理方法上。
+1. `@RequestMapping("/jsonParam")`:可以用于**控制器级别**,也可以用于**方法级别**。
+ 用于方法:HTTP 请求路径为 `/jsonParam` 的请求将调用该方法。
```text
@RequestMapping("/jsonParam")
@@ -705,13 +870,29 @@ Component衍生注解
}
```
+ 用于控制器: 所有方法的映射路径都会以这个前缀开始。
+
+ ```
+ @RestController
+ @RequestMapping("/depts")
+ public class DeptController {
+ @GetMapping("/{id}")
+ public Dept getDept(@PathVariable Long id) {
+ // 实现获取部门逻辑
+ }
+ @PostMapping
+ public void createDept(@RequestBody Dept dept) {
+ // 实现新增部门逻辑
+ }
+ }
+ ```
-2. `@RestController`:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与 `@Controller` 注解相比,`@RestController` 注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于**@ResponseBody** 。因此,`@RestController` 注解通常用于编写 RESTful Web 服务。
+1. `@RequestBody`:这是一个**方法参数级别**的注解,用于告诉Spring框架将请求体的内容**解析为指定的Java对象**。
+
+2. `@RestController`:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与 `@Controller` 注解相比,`@RestController` 注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于`@ResponseBody` 。
`@RestController = @Controller + @ResponseBody`
-3. `@RequestBody`:这是一个方法参数级别的注解,用于告诉Spring框架将请求体的内容解析为指定的Java对象。在这个例子中,`@RequestBody` 注解告诉Spring框架将HTTP请求的主体(即请求体)中的**JSON数据解析**为一个 `User` 对象,并传递给方法的参数 `user`。这样,在方法体内就可以直接使用这个 `User` 对象来处理请求中的数据了。
-
4. `@PathVariable` 注解用于将路径变量 `{id}` 的值绑定到方法的参数 `id` 上。当请求的路径是 "/path/123" 时,`@PathVariable` 会将路径中的 "123" 值绑定到方法的参数 `id` 上,使得方法能够获取到这个值。在这个例子中,方法的参数 `id` 的值将会是整数值 123。
```text
@@ -746,9 +927,9 @@ Component衍生注解
5. 控制反转与依赖注入:
- @Component ,控制反转
+ `@Component` ,控制反转
- @Autowired,依赖注入
+ `@Autowired`,依赖注入
6. **数据库相关。**@Mapper注解:表示是mybatis中的Mapper接口
@@ -758,7 +939,7 @@ Component衍生注解
7. @SpringBootTest:它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如**自动装配、依赖注入、配置加载**等。
-8. lombok的相关注解。非常实用的工具库。
+9. lombok的相关注解。非常实用的工具库。
| **注解** | **作用** |
| ------------------- | ------------------------------------------------------------ |
@@ -774,12 +955,13 @@ Component衍生注解
//equals 方法用于比较两个对象的内容是否相同
Address addr1 = new Address("SomeProvince", "SomeCity");
Address addr2 = new Address("SomeProvince", "SomeCity");
-
System.out.println(addr1.equals(addr2)); // 输出 true
```
-9. @Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法
-10. @Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用 `@Override` 注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。
+10. @Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法
+
+11. @Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用 `@Override` 注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。
+
11. @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,
将日期转化为指定的格式。Spring会尝试将接收到的**字符串参数**转换为控制器方法参数的相应类型。
@@ -793,70 +975,6 @@ Component衍生注解
-## 开发规范
-
-### REST风格
-
-在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
-
-什么是REST风格呢?
-
-- REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
-
-**传统URL风格如下:**
-
-```url
-http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
-http://localhost:8080/user/saveUser POST:新增用户
-http://localhost:8080/user/updateUser PUT:修改用户
-http://localhost:8080/user/deleteUser?id=1 GET:删除id为1的用户
-```
-
-我们看到,原始的传统URL呢,定义比较复杂,而且将资源的访问行为对外暴露出来了。
-
-**基于REST风格URL如下:**
-
-```text
-http://localhost:8080/users/1 GET:查询id为1的用户
-http://localhost:8080/users POST:新增用户
-http://localhost:8080/users PUT:修改用户
-http://localhost:8080/users/1 DELETE:删除id为1的用户
-```
-
-其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
-
-**在JAVA代码中如何区别不同的请求方式?**
-
-传统的是@RequestMapping("/depts"),现在:
-
-@GetMapping("/depts") =>GET请求
-
-@PostMapping("/depts") =》POST
-
-@PutMapping("/depts") =>PUT
-
-@DeleteMapping("/depts") =>DELETE
-
-
-
-### 开发流程
-
-
-
-1. 查看页面原型明确需求
- - 根据页面原型和需求,进行表结构设计、编写接口文档(已提供)
-
-2. 阅读接口文档
-3. 思路分析
-4. 功能接口开发
- - 就是开发后台的业务功能,一个业务功能,我们称为一个接口
-5. 功能接口测试
- - 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试
-6. 前后端联调测试
- - 和前端开发人员开发好的前端工程一起测试
-
-
-
## Mybatis
### 快速创建
diff --git a/Java/Java笔记本.md b/自学/Java笔记本.md
similarity index 99%
rename from Java/Java笔记本.md
rename to 自学/Java笔记本.md
index 73981f1..bcad734 100644
--- a/Java/Java笔记本.md
+++ b/自学/Java笔记本.md
@@ -114,7 +114,7 @@ IDEA快捷键:
public class Main {
public static void main(String[] args) {
Person person = new Person("Alice", 30);
- System.out.println(person);
+ System.out.println(person); //会自动调用对象的 toString() 方法
}
}
diff --git a/Java/Jupyter notebook快速上手.md b/自学/Jupyter notebook快速上手.md
similarity index 100%
rename from Java/Jupyter notebook快速上手.md
rename to 自学/Jupyter notebook快速上手.md
diff --git a/Java/Mysql数据库.md b/自学/Mysql数据库.md
similarity index 100%
rename from Java/Mysql数据库.md
rename to 自学/Mysql数据库.md
diff --git a/Java/Redis.md b/自学/Redis.md
similarity index 100%
rename from Java/Redis.md
rename to 自学/Redis.md
diff --git a/Java/anaconda基础命令.md b/自学/anaconda基础命令.md
similarity index 100%
rename from Java/anaconda基础命令.md
rename to 自学/anaconda基础命令.md
diff --git a/Java/git基本操作.md b/自学/git基本操作.md
similarity index 100%
rename from Java/git基本操作.md
rename to 自学/git基本操作.md
diff --git a/Java/jupyter笔记本.md b/自学/jupyter笔记本.md
similarity index 100%
rename from Java/jupyter笔记本.md
rename to 自学/jupyter笔记本.md
diff --git a/Java/linux服务器.md b/自学/linux服务器.md
similarity index 99%
rename from Java/linux服务器.md
rename to 自学/linux服务器.md
index 89f39fd..d093eeb 100644
--- a/Java/linux服务器.md
+++ b/自学/linux服务器.md
@@ -1082,11 +1082,11 @@ document.querySelector('.joe_detail__article').addEventListener('copy', () => {
markdown编辑器插件:https://xiamp.net/archives/aaeditor-is-another-typecho-editor-plugin.html
-- '开启公式显示!'
+- '开启公式解析!'
markdown解析器插件:[mrgeneralgoo/typecho-markdown: A markdown parse plugin for typecho.](https://github.com/mrgeneralgoo/typecho-markdown)
-- 有bug,暂时废弃。
+- 关闭公式解析,仅开启代码解析!
diff --git a/Java/mongodb_base.pdf b/自学/mongodb_base.pdf
similarity index 100%
rename from Java/mongodb_base.pdf
rename to 自学/mongodb_base.pdf
diff --git a/Java/test.md b/自学/test.md
similarity index 100%
rename from Java/test.md
rename to 自学/test.md
diff --git a/Java/力扣Hot 100题.md b/自学/力扣Hot 100题.md
similarity index 70%
rename from Java/力扣Hot 100题.md
rename to 自学/力扣Hot 100题.md
index edbe48b..ca4e56c 100644
--- a/Java/力扣Hot 100题.md
+++ b/自学/力扣Hot 100题.md
@@ -53,6 +53,8 @@ if (flag == false) { //更常用!
+
+
### 常用数据结构
#### `String`
@@ -93,237 +95,59 @@ String sortedStr = new String(charArray);
#### **`HashMap`**
- 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。
-
- 不保证元素的顺序。
-- ```text
- import java.util.HashMap;
- import java.util.Map;
-
- public class HashMapExample {
- public static void main(String[] args) {
- // 创建 HashMap
- Map map = new HashMap<>();
-
- // 添加键值对
- map.put("apple", 10);
- map.put("banana", 20);
- map.put("orange", 30);
-
- // 获取值
- int appleCount = map.get("apple"); //如果获取不存在的元素,返回null
- System.out.println("Apple count: " + appleCount); // 输出 10
-
- // 遍历 HashMap
- for (Map.Entry entry : map.entrySet()) {
- System.out.println(entry.getKey() + ": " + entry.getValue());
- }
- // 输出:
- // apple: 10
- // banana: 20
- // orange: 30
-
- // 检查是否包含某个键
- boolean containsBanana = map.containsKey("banana");
- System.out.println("Contains banana: " + containsBanana); // 输出 true
-
- // 删除键值对
- map.remove("orange"); //删除不存在的元素也不会报错
- System.out.println("After removal: " + map); // 输出 {apple=10, banana=20}
- }
- }
- ```
-
-
-
-#### **`ArrayList`**
-
-- 基于数组实现,支持动态扩展。
-
-- 访问元素的时间复杂度为 O(1),在末尾插入和删除的时间复杂度为 O(1)。
-
-- 在指定位置插入和删除O(n) `add(int index, E element)` `remove(int index)`
-
-- ```text
- import java.util.ArrayList;
- import java.util.List;
-
- public class ArrayListExample {
- public static void main(String[] args) {
- // 创建 ArrayList
- List list = new ArrayList<>();
-
- // 添加元素
- list.add(10);
- list.add(20);
- list.add(30);
-
- int size = list.size(); // 获取列表大小
- System.out.println("Size of list: " + size); // 输出 3
-
- // 获取元素
- int firstElement = list.get(0);
- System.out.println("First element: " + firstElement); // 输出 10
-
- // 修改元素
- list.set(1, 25); // 将第二个元素改为 25
- System.out.println("After modification: " + list); // 输出 [10, 25, 30]
-
- // 遍历 ArrayList
- for (int num : list) {
- System.out.println(num);
- }
- // 输出:
- // 10
- // 25
- // 30
-
- // 删除元素
- list.remove(2); // 删除第三个元素
- System.out.println("After removal: " + list); // 输出 [10, 25]
- }
- }
- ```
-
-**如果事先不知道嵌套列表的大小如何遍历呢?**
-
```text
-import java.util.ArrayList;
-import java.util.List;
+import java.util.HashMap;
+import java.util.Map;
-int rows = 3;
-int cols = 3;
-List> list = new ArrayList<>();
+public class HashMapExample {
+ public static void main(String[] args) {
+ // 创建 HashMap
+ Map map = new HashMap<>();
+ // 添加键值对
+ map.put("apple", 10);
+ map.put("banana", 20);
+ map.put("orange", 30);
-for (List row : list) {
- for (int num : row) {
- System.out.print(num + " ");
- }
- System.out.println(); // 换行
-}
-for (int i = 0; i < list.size(); i++) {
- List row = list.get(i);
- for (int j = 0; j < row.size(); j++) {
- System.out.print(row.get(j) + " ");
- }
- System.out.println(); // 换行
-}
-```
+ // 获取值
+ int appleCount = map.get("apple"); //如果获取不存在的元素,返回null
+ System.out.println("Apple count: " + appleCount); // 输出 10
-
-
-
-#### **`数组(Array)`**
-
-数组是一种固定长度的数据结构,用于存储相同类型的元素。数组的特点包括:
-
-- **固定长度**:数组的长度在创建时确定,无法动态扩展。
-
-- **快速访问**:通过索引访问元素的时间复杂度为 O(1)。
-
-- **连续内存**:数组的元素在内存中是连续存储的。
-
-- ```text
- public class ArrayExample {
- public static void main(String[] args) {
- // 创建数组
- int[] array = new int[5]; // 创建一个长度为 5 的整型数组
-
- // 添加元素
- array[0] = 10;
- array[1] = 20;
- array[2] = 30;
- array[3] = 40;
- array[4] = 50;
-
- // 获取元素
- int firstElement = array[0];
- System.out.println("First element: " + firstElement); // 输出 10
-
- // 修改元素
- array[1] = 25; // 将第二个元素改为 25
- System.out.println("After modification:");
- for (int num : array) {
- System.out.println(num);
- }
- // 输出:
- // 10
- // 25
- // 30
- // 40
- // 50
-
- // 遍历数组
- System.out.println("Iterating through array:");
- for (int i = 0; i < array.length; i++) {
- System.out.println("Index " + i + ": " + array[i]);
- }
- // 输出:
- // Index 0: 10
- // Index 1: 25
- // Index 2: 30
- // Index 3: 40
- // Index 4: 50
-
- // 删除元素(数组长度固定,无法直接删除,可以通过覆盖实现)
- int indexToRemove = 2; // 要删除的元素的索引
- for (int i = indexToRemove; i < array.length - 1; i++) {
- array[i] = array[i + 1]; // 将后面的元素向前移动
- }
- array[array.length - 1] = 0; // 最后一个元素置为 0(或其他默认值)
- System.out.println("After removal:");
- for (int num : array) {
- System.out.println(num);
- }
- // 输出:
- // 10
- // 25
- // 40
- // 50
- // 0
-
- // 数组长度
- int length = array.length;
- System.out.println("Array length: " + length); // 输出 5
- }
- }
-
-
-
-#### `二维数组`
-
-```text
-int rows = 3;
-int cols = 3;
-int[][] array = new int[rows][cols];
-// 填充数据
-for (int i = 0; i < rows; i++) {
- for (int j = 0; j < cols; j++) {
- array[i][j] = i * cols + j + 1;
- }
-}
-//创建并初始化
-int[][] array = {
- {1, 2, 3},
- {4, 5, 6},
- {7, 8, 9}
-};
-
-// 遍历二维数组,不知道几行几列
-public void setZeroes(int[][] matrix) {
- // 遍历每一行
- for (int i = 0; i < matrix.length; i++) {
- // 遍历当前行的每一列
- for (int j = 0; j < matrix[i].length; j++) {
- // 这里可以处理 matrix[i][j] 的元素
- System.out.print(matrix[i][j] + " ");
+ // 遍历 HashMap
+ for (Map.Entry entry : map.entrySet()) {
+ System.out.println(entry.getKey() + ": " + entry.getValue());
}
- System.out.println(); // 换行,便于输出格式化
+ // 输出:
+ // apple: 10
+ // banana: 20
+ // orange: 30
+
+ // 检查是否包含某个键
+ boolean containsBanana = map.containsKey("banana");
+ System.out.println("Contains banana: " + containsBanana); // 输出 true
+
+ // 删除键值对
+ map.remove("orange"); //删除不存在的元素也不会报错
+ System.out.println("After removal: " + map); // 输出 {apple=10, banana=20}
}
}
```
+记录二维数组中某元素是否被访问过,推荐使用:
+
+```text
+int m = grid.length;
+int n = grid[0].length;
+boolean[][] visited = new boolean[m][n];
+
+// 访问 (i, j) 时标记为已访问
+visited[i][j] = true;
+```
+
+而非创建自定义Pair二元组作为键用Map记录。
+
#### **`HashSet`**
@@ -372,17 +196,13 @@ public void setZeroes(int[][] matrix) {
#### `PriorityQueue`
- **基于优先堆(最小堆或最大堆)实现**,元素按优先级排序。
-
- **默认是最小堆**,即队首元素是最小的。
-
- **支持自定义排序规则**,通过 `Comparator` 实现。
-
- **常用操作的时间复杂度**:
- 插入元素:`O(log n)`
- 删除队首元素:`O(log n)`
- 查看队首元素:`O(1)`
-
- **常用方法**
1. **`add(E e)` / `offer(E e)`**:
@@ -401,56 +221,244 @@ public void setZeroes(int[][] matrix) {
6. **`clear()`**:
- 清空队列。
-- ```text
- import java.util.PriorityQueue;
- import java.util.Comparator;
-
- public class PriorityQueueExample {
- public static void main(String[] args) {
- // 创建 PriorityQueue(默认是最小堆)
- PriorityQueue minHeap = new PriorityQueue<>();
-
- // 添加元素
- minHeap.add(10);
- minHeap.add(20);
- minHeap.add(30);
- minHeap.add(5);
-
- // 查看队首元素
- System.out.println("队首元素: " + minHeap.peek()); // 输出 5
-
- // 遍历 PriorityQueue(注意:遍历顺序不保证有序)
- System.out.println("遍历 PriorityQueue:");
- for (int num : minHeap) {
- System.out.println(num);
- }
- // 输出:
- // 5
- // 10
- // 30
- // 20
-
- // 移除队首元素
- System.out.println("移除队首元素: " + minHeap.poll()); // 输出 5
-
- // 再次查看队首元素
- System.out.println("队首元素: " + minHeap.peek()); // 输出 10
-
- // 创建最大堆(通过自定义 Comparator)
- PriorityQueue maxHeap = new PriorityQueue<>(Comparator.reverseOrder());
- maxHeap.add(10);
- maxHeap.add(20);
- maxHeap.add(30);
- maxHeap.add(5);
-
- // 查看队首元素
- System.out.println("最大堆队首元素: " + maxHeap.peek()); // 输出 30
-
- // 清空队列
- minHeap.clear();
- System.out.println("队列是否为空: " + minHeap.isEmpty()); // 输出 true
- }
- }
+```text
+import java.util.PriorityQueue;
+import java.util.Comparator;
+
+public class PriorityQueueExample {
+ public static void main(String[] args) {
+ // 创建 PriorityQueue(默认是最小堆)
+ PriorityQueue minHeap = new PriorityQueue<>();
+
+ // 添加元素
+ minHeap.add(10);
+ minHeap.add(20);
+ minHeap.add(30);
+ minHeap.add(5);
+
+ // 查看队首元素
+ System.out.println("队首元素: " + minHeap.peek()); // 输出 5
+
+ // 遍历 PriorityQueue(注意:遍历顺序不保证有序)
+ System.out.println("遍历 PriorityQueue:");
+ for (int num : minHeap) {
+ System.out.println(num);
+ }
+ // 输出:
+ // 5
+ // 10
+ // 30
+ // 20
+
+ // 移除队首元素
+ System.out.println("移除队首元素: " + minHeap.poll()); // 输出 5
+
+ // 再次查看队首元素
+ System.out.println("队首元素: " + minHeap.peek()); // 输出 10
+
+ // 创建最大堆(通过自定义 Comparator)
+ PriorityQueue maxHeap = new PriorityQueue<>(Comparator.reverseOrder());
+ maxHeap.add(10);
+ maxHeap.add(20);
+ maxHeap.add(30);
+ maxHeap.add(5);
+
+ // 查看队首元素
+ System.out.println("最大堆队首元素: " + maxHeap.peek()); // 输出 30
+
+ // 清空队列
+ minHeap.clear();
+ System.out.println("队列是否为空: " + minHeap.isEmpty()); // 输出 true
+ }
+}
+```
+
+
+
+#### **`ArrayList`**
+
+- 基于数组实现,支持动态扩展。
+- 访问元素的时间复杂度为 O(1),在末尾插入和删除的时间复杂度为 O(1)。
+- 在指定位置插入和删除O(n) `add(int index, E element)` `remove(int index)`
+
+```text
+import java.util.ArrayList;
+import java.util.List;
+
+public class ArrayListExample {
+ public static void main(String[] args) {
+ // 创建 ArrayList
+ List list = new ArrayList<>();
+
+ // 添加元素
+ list.add(10);
+ list.add(20);
+ list.add(30);
+
+ int size = list.size(); // 获取列表大小
+ System.out.println("Size of list: " + size); // 输出 3
+
+ // 获取元素
+ int firstElement = list.get(0);
+ System.out.println("First element: " + firstElement); // 输出 10
+
+ // 修改元素
+ list.set(1, 25); // 将第二个元素改为 25
+ System.out.println("After modification: " + list); // 输出 [10, 25, 30]
+
+ // 遍历 ArrayList
+ for (int num : list) {
+ System.out.println(num);
+ }
+ // 输出:
+ // 10
+ // 25
+ // 30
+
+ // 删除元素
+ list.remove(2); // 删除第三个元素
+ System.out.println("After removal: " + list); // 输出 [10, 25]
+ }
+}
+```
+
+**如果事先不知道嵌套列表的大小如何遍历呢?**
+
+```text
+import java.util.ArrayList;
+import java.util.List;
+
+int rows = 3;
+int cols = 3;
+List> list = new ArrayList<>();
+
+
+for (List row : list) {
+ for (int num : row) {
+ System.out.print(num + " ");
+ }
+ System.out.println(); // 换行
+}
+for (int i = 0; i < list.size(); i++) {
+ List row = list.get(i);
+ for (int j = 0; j < row.size(); j++) {
+ System.out.print(row.get(j) + " ");
+ }
+ System.out.println(); // 换行
+}
+```
+
+
+
+
+#### **`数组(Array)`**
+
+数组是一种固定长度的数据结构,用于存储相同类型的元素。数组的特点包括:
+
+- **固定长度**:数组的长度在创建时确定,无法动态扩展。
+- **快速访问**:通过索引访问元素的时间复杂度为 O(1)。
+- **连续内存**:数组的元素在内存中是连续存储的。
+
+```text
+public class ArrayExample {
+ public static void main(String[] args) {
+ // 创建数组
+ int[] array = new int[5]; // 创建一个长度为 5 的整型数组
+
+ // 添加元素
+ array[0] = 10;
+ array[1] = 20;
+ array[2] = 30;
+ array[3] = 40;
+ array[4] = 50;
+
+ // 获取元素
+ int firstElement = array[0];
+ System.out.println("First element: " + firstElement); // 输出 10
+
+ // 修改元素
+ array[1] = 25; // 将第二个元素改为 25
+ System.out.println("After modification:");
+ for (int num : array) {
+ System.out.println(num);
+ }
+ // 输出:
+ // 10
+ // 25
+ // 30
+ // 40
+ // 50
+
+ // 遍历数组
+ System.out.println("Iterating through array:");
+ for (int i = 0; i < array.length; i++) {
+ System.out.println("Index " + i + ": " + array[i]);
+ }
+ // 输出:
+ // Index 0: 10
+ // Index 1: 25
+ // Index 2: 30
+ // Index 3: 40
+ // Index 4: 50
+
+ // 删除元素(数组长度固定,无法直接删除,可以通过覆盖实现)
+ int indexToRemove = 2; // 要删除的元素的索引
+ for (int i = indexToRemove; i < array.length - 1; i++) {
+ array[i] = array[i + 1]; // 将后面的元素向前移动
+ }
+ array[array.length - 1] = 0; // 最后一个元素置为 0(或其他默认值)
+ System.out.println("After removal:");
+ for (int num : array) {
+ System.out.println(num);
+ }
+ // 输出:
+ // 10
+ // 25
+ // 40
+ // 50
+ // 0
+
+ // 数组长度
+ int length = array.length;
+ System.out.println("Array length: " + length); // 输出 5
+ }
+}
+```
+
+
+
+#### `二维数组`
+
+```text
+int rows = 3;
+int cols = 3;
+int[][] array = new int[rows][cols];
+// 填充数据
+for (int i = 0; i < rows; i++) {
+ for (int j = 0; j < cols; j++) {
+ array[i][j] = i * cols + j + 1;
+ }
+}
+//创建并初始化
+int[][] array = {
+ {1, 2, 3},
+ {4, 5, 6},
+ {7, 8, 9}
+};
+
+// 遍历二维数组,不知道几行几列
+public void setZeroes(int[][] matrix) {
+ // 遍历每一行
+ for (int i = 0; i < matrix.length; i++) {
+ // 遍历当前行的每一列
+ for (int j = 0; j < matrix[i].length; j++) {
+ // 这里可以处理 matrix[i][j] 的元素
+ System.out.print(matrix[i][j] + " ");
+ }
+ System.out.println(); // 换行,便于输出格式化
+ }
+}
+```
@@ -828,4 +836,71 @@ public class IntervalSort {
- 遍历数组,每计算一个新的前缀和 `preSum`,就查看 `preSum - k` 是否在哈希表中。如果存在,则说明之前有一个前缀和等于 `preSum - k`,那么从该位置后一个位置到**当前索引**的子数组和为 k,累加其出现的次数。
4. **时间复杂度**
- 该方法只需要遍历数组一次,时间复杂度为 O(n)。
\ No newline at end of file
+ 该方法只需要遍历数组一次,时间复杂度为 O(n)。
+
+
+
+#### **遍历二叉树**
+
+*递归法中序*
+
+```java
+public void inOrderTraversal(TreeNode root, List list) {
+ if (root != null) {
+ inOrderTraversal(root.left, list); // 遍历左子树
+ list.add(root.val); // 访问当前节点
+ inOrderTraversal(root.right, list); // 遍历右子树
+ }
+}
+```
+
+*迭代法中序*
+
+```java
+public void inOrderTraversalIterative(TreeNode root, List list) {
+ Deque stack = new ArrayDeque<>();
+ TreeNode curr = root;
+
+ while (curr != null || !stack.isEmpty()) {
+ // 一路向左入栈
+ while (curr != null) {
+ stack.push(curr); // push = addFirst
+ curr = curr.left;
+ }
+
+ // 弹出栈顶并访问
+ curr = stack.pop(); // pop = removeFirst
+ list.add(curr.val);
+
+ // 转向右子树
+ curr = curr.right;
+ }
+}
+
+```
+
+*迭代法前序*
+
+```
+public void preOrderTraversalIterative(TreeNode root, List list) {
+ if (root == null) return;
+
+ Deque stack = new ArrayDeque<>();
+ stack.push(root);
+
+ while (!stack.isEmpty()) {
+ TreeNode node = stack.pop();
+ list.add(node.val); // 先访问当前节点
+
+ // 注意:先压右子节点,再压左子节点
+ // 因为栈是“后进先出”的,先弹出的是左子节点
+ if (node.right != null) {
+ stack.push(node.right);
+ }
+ if (node.left != null) {
+ stack.push(node.left);
+ }
+ }
+}
+```
+
diff --git a/Java/同步本地Markdown至Typecho站点.md b/自学/同步本地Markdown至Typecho站点.md
similarity index 87%
rename from Java/同步本地Markdown至Typecho站点.md
rename to 自学/同步本地Markdown至Typecho站点.md
index ac16b95..8c83469 100644
--- a/Java/同步本地Markdown至Typecho站点.md
+++ b/自学/同步本地Markdown至Typecho站点.md
@@ -5,11 +5,12 @@
实现效果:
- [x] 将markdown发布到typecho
-- [x] 发布前将markdown的图片资源上传到TencentCloud的COS中, 并替换markdown中的图片链接
-- [x] 将md所在的文件夹名称作为post的category(mysql发布可以插入category, xmlrpc接口暂时不支持category操作)
+- [x] 发布前将markdown中的公式块和代码块进行格式化,确保能适配md解析器。
+- [x] 发布前将markdown的图片资源上传到自己搭建的图床Easyimage中(自行替换成阿里云OSS等), 并替换markdown中的图片链接。
+- [x] 将md所在的文件夹名称作为post的category(mysql发布可以插入category, xmlrpc接口暂时不支持category操作)。
- [x] 以title和category作为文章的唯一标识,如果数据库中已有该数据,将会更新现有文章,否则新增文章。
-环境:Typecho1.2.1 php7.4.33
+环境:Typecho1.2.1 php8.1.0
### 项目目录
@@ -80,9 +81,9 @@ md_files
│ ├── file3.md
│ └── file4.md
└── output
- ├── image1.png
- ├── image2.jpg
- └── ... (其他图片文件)
+ ├── assets_type
+ ├── pics
+ └── updated_files
```
@@ -91,13 +92,14 @@ md_files
如果你现有的图片分散在系统中,可以使用 `transfer_md/transfer.py` 脚本来统一处理。该脚本需要传入三个参数:
- **input_path:** 指定包含 Markdown 文件的根目录(例如上例中的 `md_files`)。
-- **output_path:** 指定统一存放处理后图片的目标文件夹(例如上例中的 `output`)。
+- **output_path:** 输出文件夹(例如上例中的 `output`)。
- **type_value**:
- `1`:扫描 `input_path` 下所有 Markdown 文件,将其中引用的本地图片复制到 `output_path` 中,同时更新 Markdown 文件中的图片 URL 为 `output_path` 内的路径;
- - `2`:为每个 Markdown 文件建立单独的文件夹(以文件名命名),将 Markdown 文件及其依赖图片存入该文件夹中,图片存放在文件夹下的 `assets` 子目录中,整体保存在 `output_path` 内;
+ - `2`:为每个 Markdown 文件建立单独的文件夹(以文件名命名),图片存放在文件夹下的 `assets` 子目录中,整体存入`assets_type`文件夹中,;
- `3`:扫描 Markdown 文件中的本地图片,将其上传到图床(获取公网 URL),并将 Markdown 文件中对应的图片 URL 替换为公网地址。
+ - `4`:预处理Markdown 文件,将公式块和代码块格式化,以便于Markdown解析器解析(本地typora编辑器对于md格式比较宽容,但博客中使用的md解析器插件不一定能正确渲染!)
+
-对于本项目,需要将图片统一用公网URL表示。即`type_value=3`
@@ -121,6 +123,8 @@ git remote add origin http://xxx
**添加文件并提交**:
+注意,写一个.gitignore文件将output排除版本控制
+
```text
git add .
git commit -m "Initial commit"
@@ -319,9 +323,28 @@ SELECT COUNT(*) AS cnt FROM typecho_contents;
1.windows下写脚本自动/手动提交每日更新
-2.远程仓库监测到更新自动实现钩子脚本,更新md_files并执行脚本
+2.在 Linux 服务器上配置一个定时任务,定时执行 `git pull` 命令和启动脚本更新博客的命令。
+- 创建脚本`/home/zy123/typecho/deploy.sh`
+ ```text
+ #!/bin/bash
+ cd /home/zy123/md_files || exit
+ git pull
+ cd /home/zy123/typecho || exit
+ docker compose run --rm pyapp python typecho_markdown_upload/main.py
+ ```
+
+ 赋予可执行权限`chmod +x /home/zy123/deploy.sh`
+
+- 编辑 Crontab 安排任务(每天0点10分执行)
+ 打开 crontab 编辑器:$crontab -e$
+
+ ```
+ 10 0 * * * /home/zy123/typecho/deploy.sh >> /home/zy123/typecho/deploy.log 2>&1
+ ```
+
+
### TODO
diff --git a/Java/安卓开发.md b/自学/安卓开发.md
similarity index 97%
rename from Java/安卓开发.md
rename to 自学/安卓开发.md
index b262c09..a374886 100644
--- a/Java/安卓开发.md
+++ b/自学/安卓开发.md
@@ -31,9 +31,9 @@ implementation project(':hwtxtreaderlib')
- 在settings.gradle中,设置项目包括的模块
- ```text
- include ':app', ':hwtxtreaderlib'
- ```
+```
+include ':app', ':hwtxtreaderlib'
+```
- syn now! 同步一下,然后android studio中项目结构变成如下图
diff --git a/Java/微服务.md b/自学/微服务.md
similarity index 100%
rename from Java/微服务.md
rename to 自学/微服务.md
diff --git a/Java/招标文件解析.md b/自学/招标文件解析.md
similarity index 100%
rename from Java/招标文件解析.md
rename to 自学/招标文件解析.md
diff --git a/Java/苍穹外卖.md b/自学/苍穹外卖.md
similarity index 100%
rename from Java/苍穹外卖.md
rename to 自学/苍穹外卖.md
diff --git a/Java/草稿.md b/自学/草稿.md
similarity index 100%
rename from Java/草稿.md
rename to 自学/草稿.md