diff --git a/科研/zy.md b/科研/zy.md
index f526541..e7eef50 100644
--- a/科研/zy.md
+++ b/科研/zy.md
@@ -1,9 +1,3 @@
-如何确定kmeans的簇数?节点之间的流量,空间转为时间的图。
-
-压缩感知 函数拟合 采样定理 傅里叶变换
-
-
-
流量单位时间内的流量
@@ -36,17 +30,17 @@
-需要解决的问题:确定Kmeans簇数、选取的特征值特征向量的维数。
-
-先研究0-1矩阵
-
-我现在有一个真实对称矩阵A,只有0-1元素,我对它的特征值和特征向量进行估计,可以得到n个特征值和特征向量,重构出 $\widetilde{A}$,但是我只选择了前r个特征值和特征向量进行谱分解重构,可以得到A_r,最后我对A_r使用kmeans量化的方法,得到A_final簇数为2,怎么进行误差分析,确定我这里的r,使得我最终得到的A_final可以满足精确重构A的要求。 这里可以假定得到n个特征值和特征向量这里的误差为\eta
-
特征值误差分析(方差)直接看李振河的,滤波误差看郭款
-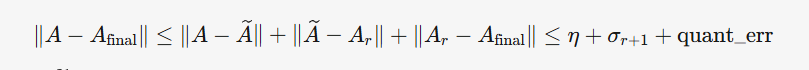
-$A-\tilde A$这里是滤波误差,是否包括特征值误差和**特征向量误差**?
+
+
+
+
+
+
+
+
diff --git a/科研/小论文.md b/科研/小论文.md
new file mode 100644
index 0000000..aa65915
--- /dev/null
+++ b/科研/小论文.md
@@ -0,0 +1,12 @@
+# 小论文
+
+1.背景意义这边需要改。
+
+2.卡尔曼滤波这边,Q、R不明确 / 真实若干时刻的测量值可以是真实值;但后面在线预测的时候仍然传的是真实值,事实上无法获取=》 考虑用三次指数平滑,对精确重构出来的矩阵谱分解,得到的特征值作为'真实值',代入指数平滑算法中进行在线更新,执行单步计算。
+
+3.所有特征值符号$\lambda$ 要改为奇异值 $σ$
+
+4.这块有问题,没提高秩性,没说除了ER模型外的移动模型如RWP
+
+
+
diff --git a/科研/草稿.md b/科研/草稿.md
index 76a2206..8e90644 100644
--- a/科研/草稿.md
+++ b/科研/草稿.md
@@ -1,31 +1,118 @@
-### GAT 在多智能体强化学习中的衔接方式
+根据您提供的图片内容和数学符号描述,当前的公式和符号使用**基本符合数学和论文规范**,但可以进一步优化以提高严谨性和可读性。以下是具体分析及建议:
-| 位置 | 作用 | 关键公式 / 流程 | 典型引文 |
-| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- |
-| **1. 把多智能体系统显式建模成图** | 训练时每一步根据空间/通信半径或 *k* 近邻规则,把 *N* 个智能体构成动态图 $G=(V,E)$;邻接矩阵 *A* 随场景变化而更新,从而刻画“谁会与谁交互” | – | – |
-| **2. 节点特征准备** | 每个智能体的原始观测 $o_i$ 先经类型专属投影矩阵 $M_{\varphi_i}$ 映射到统一特征空间,得到 $o'_i$ 作为 **节点特征**(后续注意力汇聚的输入) | $o'_i = M_{\varphi_i} \cdot o_i$ | |
-| **3. GAT 自适应信息融合** | 对每条边 $i\!\to\!j$ 计算注意力分数并 Soft-max 归一化 | $\alpha_{ij}=\mathrm{softmax}_j\bigl(\text{LeakyReLU}\,[W h_i \,\|\, W h_j]\bigr)$ | |
-| | 按权重聚合邻居特征,得到携带局部交互信息的 $v_i$: | $v_i=\sum_{j\in\mathcal N_i}\alpha_{ij}\,W\,o'_j$ | |
-| | 多头拼接 → 平均池化得到 **队伍级全局表示** $o_{\text{all}}$,每个智能体和后续 Critic 都可访问 | $o_{\text{all}}=\frac{1}{N}\sum_{i=1}^N\|_{h=1}^H v_i^{(h)}$ | |
-| **4. 融入 CTDE 训练管线** | *Agent Network*:每个智能体的 RNN/GRU 接收 $[o'_i,\,o_{\text{all}}]$,输出局部 $Q_i$。
*Mixing Network*:沿 QMIX 单调性约束,用 $o_{\text{all}}$(或全局状态 $s$)作为超网络条件,将 $\{Q_i\}$ 汇聚成联合 $Q_{\text{tot}}$ | $Q_{\text{tot}} = \text{Mix}\bigl(Q_1,\dots,Q_N;\,s\text{ 或 }o_{\text{all}}\bigr)$ | |
-| **5. 执行阶段** | 训练完毕后,每个智能体只保留依赖 $o_i$(或轻量通信)的策略参数,保持 **去中心化执行**;GAT 与联合 $Q$ 评估仅在集中式训练时使用 | – | – |
+------
----
+### **1. 邻接矩阵 `A` 的表示**
-#### 为什么 GAT 能显著提升 MARL 表现?
+- **当前表述**:
+ `A = a_{ij} \ (i,j \in 1,2,\ldots,n)`
+ **合理性**:
+ - 矩阵元素 `a_{ij}` 的下标范围明确(`i,j` 从 1 到 `n`)。
+ - 声明 `A` 为实对称矩阵(`a_{ij} = a_{ji}`)符合图的邻接矩阵定义。
+- **优化建议**:
+ - 若论文涉及离散时间或动态网络,建议将时间下标 `t` 包含在括号内,即 **`A_t = (a_{ij})_t`**,以强调时间依赖性(例如:`A_t` 是 `t` 时刻的邻接矩阵)。
+ - 如果时间 `t` 是次要因素,直接使用 `A` 或 `A(t)` 也可接受。
-1. **可变拓扑的自适应感知**
- 传统拼接/平均把所有邻居一视同仁;GAT 通过 $\alpha_{ij}$ 动态衡量邻居重要性,适应不断变化的通信或空间结构。
+------
-2. **减少信息冗余、突出关键交互**
- 注意力权重抑制无关或冗余邻居特征,只保留对当前决策真正有影响的信息,在复杂异构场景中尤为有效。
+### **2. 矩阵元素的定义式**
-3. **统一异构观测的自动融合**
- 先投影再做图注意力,避免人工设计融合规则,支持 LiDAR、相机等多模态数据共存。
+- **当前表述**:
-4. **更精确的联合 Q 估计 → 更快收敛**
- 消融实验显示,加入 GAT 后在 SMAC 的复杂对抗场景中赢率提升且达到同等胜率所需样本显著减少,证明其降低了 Critic 估计方差,缓解了非平稳性。
+ ```
+ a_{ij} = a_{ji} =
+ \begin{cases}
+ w_{ij}, & d_{ij} \leq r \\
+ 0, & d_{ij} > r \text{ or } i = j
+ \end{cases}
+ ```
----
+ **合理性**:
-**一句话**:在多智能体强化学习里,GAT 把“谁与谁交互、交互强弱”编码成可训练的图注意力权重,将各智能体局部观测融合成全局队伍表示,供集中式 Critic 精准估值;这样既不破坏去中心化执行,又显著提升协作效率与收敛速度。
+ - 分段函数形式清晰,逻辑完整(覆盖了通信半径 `r`、距离 `d_{ij}`、自环 `i=j` 的情况)。
+ - 权值 `w_{ij}` 的说明(如流量、带宽)符合实际应用场景。
+
+- **优化建议**:
+
+ - **符号一致性**:若 `w_{ij}` 是时变的,建议改为 `w_{ij}(t)`,与 `A_t` 保持一致。
+ - **自环明确性**:可补充说明“对角线元素 `a_{ii} = 0`”以避免歧义(部分文献允许自环权值非零)。
+
+------
+
+### **3. 时间下标的处理**
+
+-
+
+ 用户疑问
+
+ :是否将
+
+ ```
+ t
+ ```
+
+ 放在括号内(如
+
+ ```
+ \lambda_i(A_t)
+ ```
+
+ vs
+
+ ```
+ \lambda_i(A)_t
+ ```
+
+ )。
+
+ -
+
+ 推荐写法
+
+ :
+
+ - 特征值/奇异值:统一用 **`\lambda_i(A_t)`** 或 **`\sigma_i(A_t)`**,表示“矩阵 `A_t` 的第 `i` 个特征值/奇异值”。
+ - 避免 `\lambda_i(A)_t`,因其可能被误解为“对 `A` 求特征值后再取时间 `t` 的分量”。
+
+------
+
+### **4. 其他细节规范**
+
+-
+
+ 符号字体
+
+ :
+
+ - 矩阵 `A` 用大写斜体,向量 `\mathbf{v}` 用小写粗体,标量 `r, d_{ij}` 用普通斜体。
+ - 确保希腊字母(如 `\lambda, \sigma`)和下标(如 `\text{max}, \text{min}`)的格式正确。
+
+-
+
+ 文字说明
+
+ :
+
+ - 对通信半径 `r`、距离 `d_{ij}`、权值 `w_{ij}` 的定义清晰,符合论文要求。
+
+------
+
+### **5. 总结建议**
+
+- **动态网络场景**:
+
+ - 使用 `A_t` 和 `\lambda_i(A_t)`,保持时间下标在括号内。
+
+ - 示例修改:
+
+ > “动态网络的邻接矩阵序列 `\{A_t\}` 的特征值为 `\{\lambda_1(A_t), \ldots, \lambda_n(A_t)\}`。”
+
+- **静态网络场景**:
+
+ - 直接使用 `A` 和 `\lambda_i(A)`,无需时间下标。
+
+当前符号系统已足够规范,只需根据时间维度是否关键选择 **`A_t` 或 `A`**,并统一后续符号即可。
+
+
+
+$w_{ij}>0$
diff --git a/科研/郭款论文.md b/科研/郭款论文.md
index a47c64f..8735142 100644
--- a/科研/郭款论文.md
+++ b/科研/郭款论文.md
@@ -697,10 +697,16 @@ $$
+
+
+
+
#### 疑问
**!!!为什么采用SNMF?**
+得到可解释、非负的低维表示 $U$
+
卡尔曼滤波得到的特征值和特征向量存在噪声 直接进行谱分解重构会导致重构出来的矩阵不满足对称性。但是SNMF在迭代的过程中增加了**非负**且**对称**的约束!
可以确保 $A' = UU^{\mathsf T}$ 得到的重构矩阵是对称且非负的!!!
@@ -773,3 +779,7 @@ $$
- 优点:利用了特征分解,可以先一步把主要信息“压缩”进 $B$,后续只需解决“如何把负数修正掉”以及“如何微调逼近”。
- 缺点:需要先做特征分解,适合于对称矩阵或低秩场景。
+
+
+
+
diff --git a/科研/高飞论文.md b/科研/高飞论文.md
index 4649fd3..a9535f9 100644
--- a/科研/高飞论文.md
+++ b/科研/高飞论文.md
@@ -273,6 +273,197 @@ $$
+## 指数平滑法
+
+**指数平滑法(Single Exponential Smoothing)**
+
+指数平滑法是一种对时间序列进行平滑和短期预测的简单方法。它假设近期的数据比更久之前的数据具有更大权重,并用一个平滑常数 $\alpha$($0<\alpha\leq1$)来控制“记忆”长度。
+
+- **平滑方程:**
+ $$
+ S_t = \alpha\,x_t + (1-\alpha)\,S_{t-1}
+ $$
+
+ - $x_t$:时刻 $t$ 的实际值
+ - $S_t$:时刻 $t$ 的平滑值(也可作为对 $x_{t+1}$ 的预测)
+ - $S_1$ 的初始值一般取 $x_1$
+
+- **举例:**
+ 假设一产品过去 5 期的销量为 $[100,\;105,\;102,\;108,\;110]$,取 $\alpha=0.3$,初始平滑值取 $S_1=x_1=100$:
+
+ 1. $S_2=0.3\times105+0.7\times100=101.5$
+ 2. $S_3=0.3\times102+0.7\times101.5=101.65$
+ 3. $S_4=0.3\times108+0.7\times101.65\approx103.755$
+ 4. $S_5=0.3\times110+0.7\times103.755\approx106.379$
+
+ 因此,对第 6 期销量的预测就是 $S_5\approx106.38$。
+
+
+
+**二次指数平滑法(Holt’s Linear Method)**
+
+当序列存在趋势(Trend)时,单次平滑会落后。二次指数平滑(也称 Holt 线性方法)在单次平滑的基础上,额外对趋势项做平滑。
+
+- **水平和趋势平滑方程:**
+ $$
+ \begin{cases}
+ L_t = \alpha\,x_t + (1-\alpha)(L_{t-1}+T_{t-1}), \\[6pt]
+ T_t = \beta\,(L_t - L_{t-1}) + (1-\beta)\,T_{t-1},
+ \end{cases}
+ $$
+
+ - $L_t$:水平(level)
+ - $T_t$:趋势(trend)
+ - $\alpha, \beta$:平滑常数,通常 $0.1$–$0.3$
+
+- **预测公式:**
+ $$
+ \hat{x}_{t+m} = L_t + m\,T_t
+ $$
+ 其中 $m$ 为预测步数。
+
+- **举例:**
+ 用同样的数据 $[100,105,102,108,110]$,取 $\alpha=0.3,\;\beta=0.2$,初始化:
+
+ - $L_1 = x_1 = 100$
+ - $T_1 = x_2 - x_1 = 5$
+
+ 接下来计算:
+
+ 1. $t=2$:
+ $$
+ L_2=0.3\times105+0.7\times(100+5)=0.3\times105+0.7\times105=105
+ $$
+
+ $$
+ T_2=0.2\times(105-100)+0.8\times5=0.2\times5+4=5
+ $$
+
+ 2. $t=3$:
+ $$
+ L_3=0.3\times102+0.7\times(105+5)=0.3\times102+0.7\times110=106.4
+ $$
+
+ $$
+ T_3=0.2\times(106.4-105)+0.8\times5=0.2\times1.4+4=4.28
+ $$
+
+ 3. $t=4$:
+ $$
+ L_4=0.3\times108+0.7\times(106.4+4.28)\approx0.3\times108+0.7\times110.68\approx110.276
+ $$
+
+ $$
+ T_4=0.2\times(110.276-106.4)+0.8\times4.28\approx0.2\times3.876+3.424\approx4.199
+ $$
+
+ 4. $t=5$:
+ $$
+ L_5=0.3\times110+0.7\times(110.276+4.199)\approx0.3\times110+0.7\times114.475\approx112.133
+ $$
+
+ $$
+ T_5=0.2\times(112.133-110.276)+0.8\times4.199\approx0.2\times1.857+3.359\approx3.731
+ $$
+
+ **预测第 6 期** ($m=1$):
+ $$
+ \hat{x}_6 = L_5 + 1\times T_5 \approx 112.133 + 3.731 = 115.864
+ $$
+
+---
+
+**小结**
+
+- 单次指数平滑适用于无明显趋势的序列,简单易用。
+- 二次指数平滑(Holt 方法)在水平外加趋势成分,适合带线性趋势的数据,并可向未来多步预测。
+
+通过选择合适的平滑参数 $\alpha,\beta$ 并对初值进行合理设定,即可在实践中获得较好的短期预测效果。
+
+
+
+**三次指数平滑法概述**
+
+三次指数平滑法在二次(Holt)方法的基础上又加入了对季节成分的平滑,适用于同时存在趋势(Trend)和季节性(Seasonality)的时间序列。
+
+**主要参数及符号**
+
+- $m$:季节周期长度(例如季度数据 $m=4$,月度数据 $m=12$)。
+- $\alpha, \beta, \gamma$:水平、趋势、季节三项的平滑系数,均在 $(0,1]$ 之间。
+- $x_t$:时刻 $t$ 的实际值。
+- $L_t$:时刻 $t$ 的水平(level)平滑值。
+- $B_t$:时刻 $t$ 的趋势(trend)平滑值。
+- $S_t$:时刻 $t$ 的季节(seasonal)成分平滑值。
+- $\hat x_{t+h}$:时刻 $t+h$ 的 $h$ 步预测值。
+
+**平滑与预测公式(加法模型)**
+$$
+\begin{aligned}
+L_t &= \alpha\,(x_t - S_{t-m}) + (1-\alpha)\,(L_{t-1}+B_{t-1}),\\
+B_t &= \beta\,(L_t - L_{t-1}) + (1-\beta)\,B_{t-1},\\
+S_t &= \gamma\,(x_t - L_t) + (1-\gamma)\,S_{t-m},\\
+\hat x_{t+h} &= L_t + h\,B_t + S_{t-m+h_m},\quad\text{其中 }h_m=((h-1)\bmod m)+1.
+\end{aligned}
+$$
+
+- **加法模型** 适用于季节波动幅度与水平无关的情况;
+- **乘法模型** 则把"$x_t - S_{t-m}$"改为"$x_t / S_{t-m}$"、"$S_t$"改为"$\gamma\,(x_t/L_t)+(1-\gamma)\,S_{t-m}$"并在预测中用乘法。
+
+---
+
+**计算示例**
+
+假设我们有一个周期为 $m=4$ 的序列,前 8 期观测值:
+$$
+x = [110,\;130,\;150,\;95,\;120,\;140,\;160,\;100].
+$$
+取参数 $\alpha=0.5,\;\beta=0.3,\;\gamma=0.2$。
+初始值按常见做法设定为:
+
+- $L_0 = \frac{1}{m}\sum_{i=1}^m x_i = \tfrac{110+130+150+95}{4}=121.25$.
+
+- 趋势初值
+ $$
+ B_0 = \frac{1}{m^2}\sum_{i=1}^m (x_{m+i}-x_i)
+ = \frac{(120-110)+(140-130)+(160-150)+(100-95)}{4\cdot4}
+ = \frac{35}{16} \approx 2.1875.
+ $$
+
+- 季节初值 $S_i = x_i - L_0$,即
+ $[-11.25,\;8.75,\;28.75,\;-26.25]$ 对应 $i=1,2,3,4$。
+
+下面我们演示第 5 期($t=5$)的更新与对第 6 期的预测。
+
+| $t$ | $x_t$ | 计算细节 | 结果 |
+| -------------- | ----- | ---------------------------------------------------- | ----------------- |
+| | | **已知初值** | |
+| 0 | – | $L_0=121.25,\;B_0=2.1875$ | |
+| 1–4 | – | $S_{1\ldots4}=[-11.25,\,8.75,\,28.75,\,-26.25]$ | |
+| **5** | 120 | $L_5=0.5(120-(-11.25)) +0.5(121.25+2.1875)$ | $\approx127.3438$ |
+| | | $B_5=0.3(127.3438-121.25)+0.7\cdot2.1875$ | $\approx3.3594$ |
+| | | $S_5=0.2(120-127.3438)+0.8\cdot(-11.25)$ | $\approx-10.4688$ |
+| **预测** $h=1$ | – | $\hat x_6 = L_5 + 1\cdot B_5 + S_{6-4}\;(=S_2=8.75)$ | $\approx139.45$ |
+
+**解读:**
+
+1. 期 5 时,剔除上周期季节影响后平滑得到新的水平 $L_5$;
+2. 由水平变化量给出趋势 $B_5$;
+3. 更新第 5 期的季节因子 $S_5$;
+4. 期 6 的一步预测综合了最新水平、趋势和对应的季节因子,得 $\hat x_6\approx139.45$。
+
+
+
+### 总结思考
+
+- 如果你把预测值 $\hat x_{t+1}$ 当作"新观测"再去更新状态,然后再预测 $\hat x_{t+2}$,这种"预测—更新—预测"的迭代方式会让模型把自身的预测误差也当作输入,不断放大误差。
+- 正确做法是——在时刻 $t$ 得到 $L_t,B_t,S_t$ 后,用上面的直接公式一次算出**所有未来** $\hat x_{t+1},\hat x_{t+2},\dots$,这样并不会"反馈"误差,也就没有累积放大的问题。
+
+或者,根据精确重构出来的矩阵谱分解,得到的特征值作为'真实值',进行在线更新,执行单步计算。
+
+
+
+
+
## 特征值精度预估
### 1. 噪声随机变量与协方差
@@ -405,6 +596,12 @@ $$
+
+
+
+
+
+
## 基于时空特征的节点位置预测
在本模型中,整个预测流程分为两大模块:
diff --git a/自学/DDD领域驱动设计.md b/自学/DDD领域驱动设计.md
new file mode 100644
index 0000000..9a08ed7
--- /dev/null
+++ b/自学/DDD领域驱动设计.md
@@ -0,0 +1,294 @@
+# DDD领域驱动设计
+
+## 什么是 DDD?
+
+DDD(领域驱动设计,Domain-Driven Design)是一种软件开发方法论和设计思想。**为了确定业务和应用的边界**,保证业务模型和代码模型的一致性。
+
+**DDD 与微服务架构的关系**
+
+因为 DDD **主要应用在微服务架构**场景,所以想要更好的理解 DDD 的概念,需要结合微服务架构来看:
+
+- DDD 是一种设计思想,确定业务和应用的边界
+- 微服务架构需要 **将系统拆分为多个小而独立的服务**
+
+**DDD 的价值**
+
+1. 根据领域模型确定业务的边界
+2. 划分出应用的边界
+3. 最终落实成服务的边界、代码的边界
+
+## DDD概念理论
+
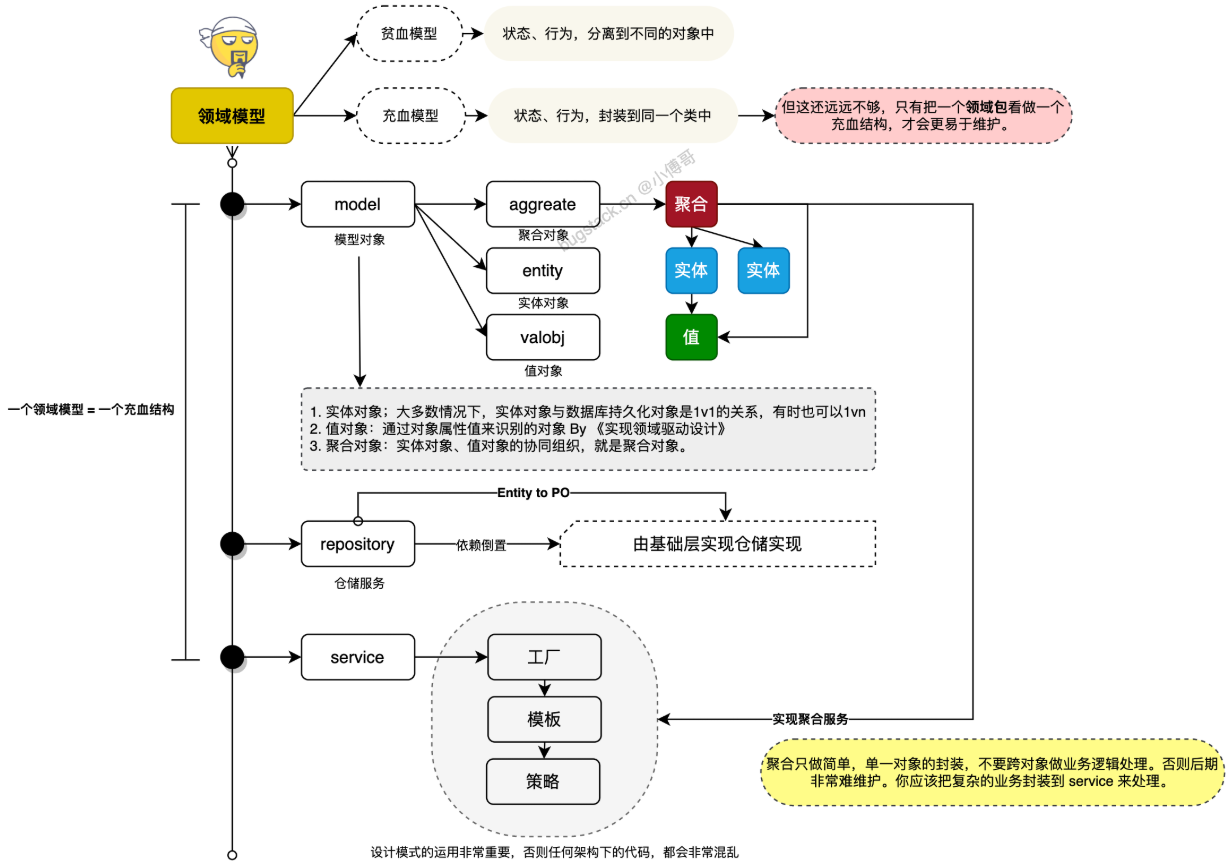
+### 充血模型 vs 贫血模型
+
+**定义**
+
+- **贫血模型**:对象仅包含数据属性和简单的 `getter/setter`,业务逻辑由外部服务处理。
+- **充血模型**:对象既包含数据,也封装相关业务逻辑,符合面向对象设计原则。
+
+| 特点 | 贫血模型 | 充血模型 |
+| ------------ | -------------------------------- | -------------------------------- |
+| 封装性 | 数据和逻辑分离 | 数据和逻辑封装在同一对象内 |
+| 职责分离 | 服务类负责业务逻辑,对象负责数据 | 对象同时负责数据和自身的业务逻辑 |
+| 适用场景 | 简单的增删改查、DTO 传输对象 | 复杂的领域逻辑和业务建模 |
+| 优点 | 简单易用,职责清晰 | 高内聚,符合面向对象设计思想 |
+| 缺点 | 服务层臃肿,领域模型弱化 | 复杂度增加,不适合简单场景 |
+| 面向对象原则 | 违反封装原则 | 符合封装原则 |
+
+充血模型:
+
+```java
+public class Order {
+ private String orderId;
+ private double totalAmount;
+ private boolean isPaid;
+
+ public Order(String orderId, double totalAmount) {
+ this.orderId = orderId;
+ this.totalAmount = totalAmount;
+ this.isPaid = false;
+ }
+
+ public void pay() {
+ if (this.isPaid) {
+ throw new IllegalStateException("Order is already paid");
+ }
+ this.isPaid = true;
+ }
+
+ public void cancel() {
+ if (this.isPaid) {
+ throw new IllegalStateException("Cannot cancel a paid order");
+ }
+ // Perform cancellation logic
+ }
+
+ public boolean isPaid() {
+ return isPaid;
+ }
+
+ public double getTotalAmount() {
+ return totalAmount;
+ }
+}
+```
+
+但不要只是把充血模型,仅限于一个类的设计和一个类内的方法设计。充血还可以是整个包结构,一个包下包括了用于实现此包 Service 服务所需的各类零部件(模型、仓储、工厂),也可以被看做充血模型。
+
+
+
+### 限界上下文
+
+限界上下文是指一个明确的边界,规定了某个子领域的业务模型和语言,确保在该上下文内的术语、规则、模型不与其他上下文混淆。
+
+| 表达 | 语义环境 | 实际含义 |
+| -------------------------------- | -------- | ---------------------- |
+| "我吃得很饱,现在不能动了" | 日常用餐 | 字面意思:吃到肚子很满 |
+| "我吃得很饱,今天的演讲让人充实" | 知识分享 | 比喻:得到了很大满足 |
+
+**限界上下文的作用**
+
+1. **定义业务边界**:类似于语义环境,为通用语言划定范围
+2. **消除歧义**:确保团队对领域对象、事件的认知一致
+3. **领域转换**:同一对象在不同上下文有不同名称(goods在电商称"商品",运输称"货物")
+4. **模型隔离**:防止不同业务领域的模型相互干扰
+
+
+
+### 领域模型
+
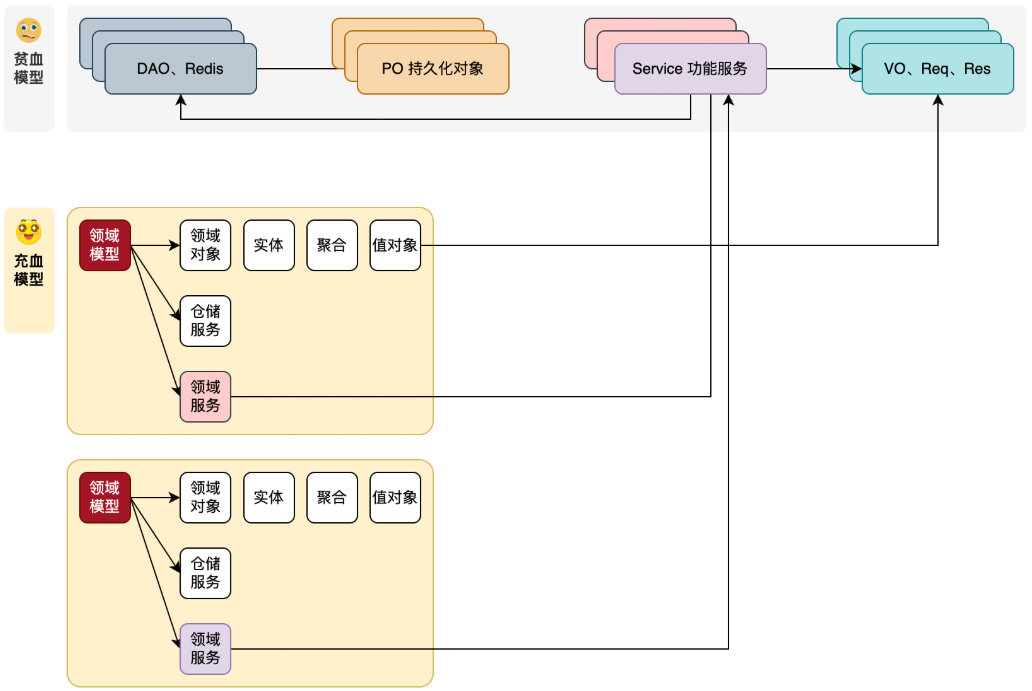
+指特定业务领域内,业务规则、策略以及业务流程的抽象和封装。在设计手段上,通过风暴模型拆分领域模块,形成界限上下文。最大的区别在于把原有的`众多 Service + 数据模型`的方式,拆分为独立的有边界的领域模块。每个领域内创建自身所属的;领域对象(实体、聚合、值对象)、仓储服务(DAO 操作)、工厂、端口适配器Port(调用外部接口的手段)等。
+
+
+
+- 在原本的 Service + 贫血的数据模型开发指导下,Service 串联调用每一个功能模块。这些基础设施(对象、方法、接口)是被相互调用的。这也是因为贫血模型并没有面向对象的设计,所有的需求开发只有详细设计。
+- 换到充血模型下,现在我们以一个领域功能为聚合,拆分一个领域内所需的 Service 为领域服务,VO、Req、Res 重新设计为领域对象,DAO、Redis 等持久化操作为仓储等。举例:一套账户服务中的,授信认证、开户、提额降额等,每一个都是一个独立的领域,在每个独立的领域内,创建自身领域所需的各项信息。
+- 领域模型还有一个特点,它自身只关注业务功能实现,不与外部任何接口和服务直连。如;不会直接调用 DAO 操作库,也不会调用缓存操作 Redis,更不会直接引入 RPC 连接其他微服务。而是通过仓库和端口适配器,定义调用外部数据的含有出入参对象的接口标准,让基础设施层做具体的调用实现——通过这样的方式让领域只关心业务实现,同时做好防腐。
+
+
+
+### 领域服务
+
+**一组**无状态**的业务操作,封装那些“不属于任何单个实体/聚合”的领域逻辑。**
+
+**职责**
+
+- 执行**跨聚合**、跨实体的业务场景——比如“为多个订单一次性计算优惠”、“在用户和仓库之间做一次库存预占”。
+- 协调仓储接口、调用多个聚合根的方法,但本身不持有长期状态,也不了解持久化细节。
+
+**典型示例**
+
+**订单支付功能**:
+涉及订单、用户账户、支付信息等**多个实体**,适合放在领域服务中实现
+
+```java
+public class PaymentService {
+ public void processPayment(Order order, PaymentDetails paymentDetails, Account account) {
+ // 处理支付逻辑
+ // 调用多个实体方法来处理支付过程
+ }
+}
+```
+
+
+
+### 领域对象
+
+#### 实体
+
+实体是指具有唯一标识的业务对象。在代码中,唯一标识通常表现为ID属性,例如:
+
+- 订单实体:订单ID
+- 用户实体:用户ID
+
+**核心特征**
+
+- 实体的属性可以随时间变化
+- 唯一标识(ID)始终保持不变
+
+实体映射到代码中就是实体类,通常采用**充血模型**实现,即与这个实体相关的所有业务逻辑都写在实体类中。
+
+
+
+#### 值对象
+
+值对象是没有唯一标识的业务对象,具有以下特征:
+
+1. 创建后不可修改(immutable)
+2. 只能通过**整体替换**来更新
+3. 通常用于描述实体的属性和特征
+
+在开发值对象的时候,通常**不会提供 setter 方法**,而是提供构造函数或者 Builder 方法来实例化对象。这个对象通常不会独立作为方法的入参对象,但做可以独立**作为出参对象**使用。
+
+
+
+#### 聚合与聚合根(Aggregate & Aggregate Root)
+
+在 DDD 中,**聚合**是一组相关的实体(Entity)和值对象(Value Object)的集合,它们共同承担一个业务功能,并作为一个**事务与一致性边界**被一起管理;而**聚合根**则是这整个聚合对外的唯一入口和“带头人”。
+
+**聚合(Aggregate)**
+
+- **一致性边界**:聚合内的所有变更要么全部成功,要么全部失败,保证内部数据始终保持不变式(Invariant)。
+- **事务边界**:一次事务只能跨越一个聚合,聚合内部的操作在同一事务中完成。
+- **边界保护**:禁止外部直接操作聚合内除根实体之外的对象,所有访问和变更都必须通过聚合根。
+
+**聚合根(Aggregate Root)**
+
+- **唯一入口**:每个聚合只能有一个根实体;外部只能通过它来查找、添加、修改或删除聚合内的对象。
+- **实体身份**:聚合根本身是一个拥有全局唯一标识(ID)的实体,封装聚合内部所有业务逻辑与校验。
+- **操作封装**:聚合根提供方法(如 `addItem()`、`updateAddress()`)来维护内部实体和值对象的一致性,不暴露内部结构。
+- **跨聚合关联**:与其他聚合交互时,仅通过 ID 或专门的领域服务进行,无直接对象引用,防止耦合越界。
+
+```java
+public class Order { // ← 聚合根(Aggregate Root)
+ private final OrderId id; // 根实体,带全局唯一 ID
+ private List items; // 聚合内实体
+ private ShippingAddress address; // 聚合内值对象
+
+ public void addItem(Product p, int qty) {
+ // 校验库存、价格等业务规则
+ items.add(new OrderItem(p.getId(), p.getPrice(), qty));
+ // 校验聚合不变式:总金额 = 明细之和
+ }
+
+ public List getItems() {
+ return Collections.unmodifiableList(items);
+ }
+
+ public void updateAddress(ShippingAddress addr) {
+ // 校验地址合法性
+ this.address = addr;
+ }
+ // … 其它业务方法 …
+}
+
+```
+
+**聚合**:订单聚合**包含** `OrderItem`(实体)和 `ShippingAddress`(值对象),它们在同一事务中一起保存或回滚。
+
+**聚合根**:即`Order` 类,对外暴露操作接口,封装内部状态与一致性,不允许直接操作 `OrderItem` 或地址。
+
+
+
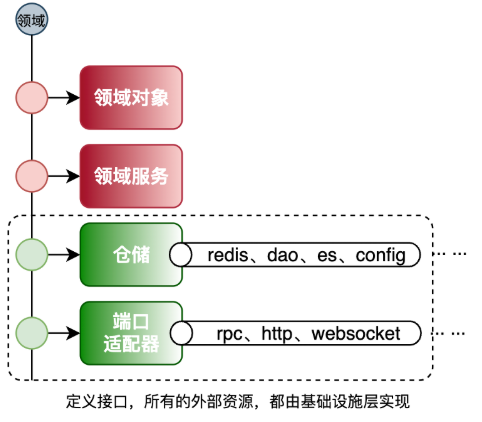
+### 仓储服务
+
+**特征**
+
+- 封装持久化操作:Repository负责封装所有与数据源交互的操作,如**创建、读取、更新和删除(CRUD)操作**。这样,领域层的代码就可以避免直接处理数据库或其他存储机制的复杂性。
+- 领域对象的集合管理:Repository通常被视为领域对象的集合,提供了查询和过滤这些对象的方法,使得领域对象的获取和管理更加方便。
+- 抽象接口:Repository定义了一个与持久化机制无关的接口,这使得领域层的代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑。
+
+
+
+**职责分离**
+
+- **领域层** 只定义 **Repository 接口**,关注“需要做哪些数据操作”(增删改查、复杂查询),不关心具体实现。
+- **基础设施层** 实现这些接口(ORM、JDBC、Redis、ES、RPC、HTTP、MQ 推送等),封装所有外部资源的访问细节。
+
+仓储解耦的手段使用了依赖倒置的设计。
+
+ +
+**示例:** 只定义接口,由基础设施层来实现。
+
+```java
+public interface IActivityRepository {
+
+ GroupBuyActivityDiscountVO queryGroupBuyActivityDiscountVO(String source, String channel);
+
+ SkuVO querySkuByGoodsId(String goodsId);
+
+}
+```
+
+
+
+### 聚合和领域服务的区别
+
+| 特性 | 聚合(Aggregate) | 领域服务(Domain Service) |
+| ------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| **本质** | **一组相关**实体和值对象的组合,形成一个事务与一致性边界 | 无状态的业务逻辑单元,封装**跨实体或跨聚合**的操作 |
+| **状态** | 有状态——包含实体/值对象,维护自身的数据和不变式 | 无状态——只定义行为,不保存对象状态 |
+| **职责** | 1. 维护内部对象的一致性2. 提供对外唯一入口(聚合根)3. 定义事务边界 | 1. 执行不适合归入任何单一聚合的方法2. 协调多个聚合或实体完成一段业务流程 |
+| **边界** | 聚合边界内的所有操作要么全部成功要么全部失败 | 没有一致性边界,只是一段可复用的业务流程 |
+| **典型用法** | `Order.addItem()`、`Order.updateAddress()` 等,操作聚合根来修改内部状态 | `PricingService.calculateFinalPrice(order, coupons)`
+
+**示例:** 只定义接口,由基础设施层来实现。
+
+```java
+public interface IActivityRepository {
+
+ GroupBuyActivityDiscountVO queryGroupBuyActivityDiscountVO(String source, String channel);
+
+ SkuVO querySkuByGoodsId(String goodsId);
+
+}
+```
+
+
+
+### 聚合和领域服务的区别
+
+| 特性 | 聚合(Aggregate) | 领域服务(Domain Service) |
+| ------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| **本质** | **一组相关**实体和值对象的组合,形成一个事务与一致性边界 | 无状态的业务逻辑单元,封装**跨实体或跨聚合**的操作 |
+| **状态** | 有状态——包含实体/值对象,维护自身的数据和不变式 | 无状态——只定义行为,不保存对象状态 |
+| **职责** | 1. 维护内部对象的一致性2. 提供对外唯一入口(聚合根)3. 定义事务边界 | 1. 执行不适合归入任何单一聚合的方法2. 协调多个聚合或实体完成一段业务流程 |
+| **边界** | 聚合边界内的所有操作要么全部成功要么全部失败 | 没有一致性边界,只是一段可复用的业务流程 |
+| **典型用法** | `Order.addItem()`、`Order.updateAddress()` 等,操作聚合根来修改内部状态 | `PricingService.calculateFinalPrice(order, coupons)`
`InventoryService.reserveStock(order)` |
+
+
+
+**总结:**可以通过“开公司”的比喻来帮助大家理解 DDD。领域就像公司的行业,决定了公司所从事的核心业务;限界上下文是公司内部的各个部门,每个部门有独立的职责和规则;实体是公司中的员工,具有唯一标识和生命周期;值对象是员工的地址或电话等属性,只有值的意义,没有独立的身份;聚合是部门,由多个实体和值对象组成,聚合根(如部门经理)是部门的入口,确保部门内部的一致性;领域服务则是跨部门的职能服务,比如 HR 或 IT 服务,为各部门提供支持和协作。
+
+
+
+## DDD架构设计
+
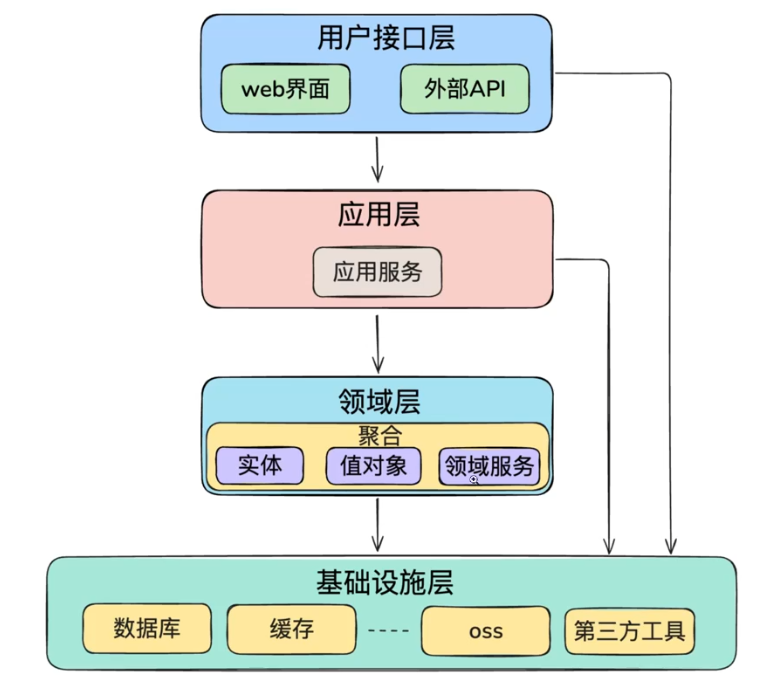
+### 四层架构
+
+1. **用户接口层interface**:处理用户交互和展示
+2. **应用层application**:协调领域对象完成业务用例
+3. **领域层domain**:包含核心业务逻辑和领域模型
+4. **基础设施层infrastructure**:提供技术实现支持
+
+ +
+**如何从MVC架构映射到DDD架构?**
+
+
+
+**如何从MVC架构映射到DDD架构?**
+
+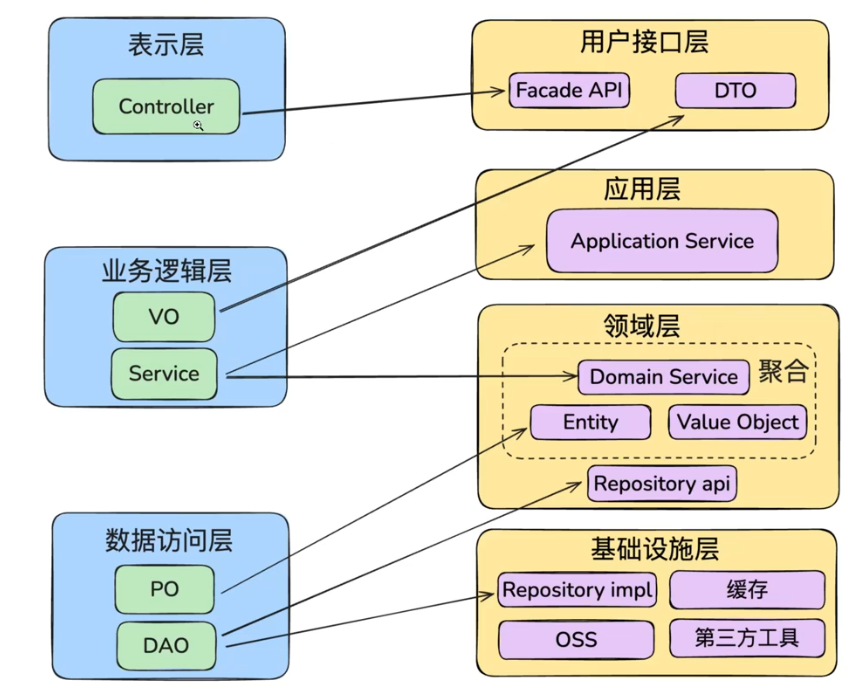 +
+
+
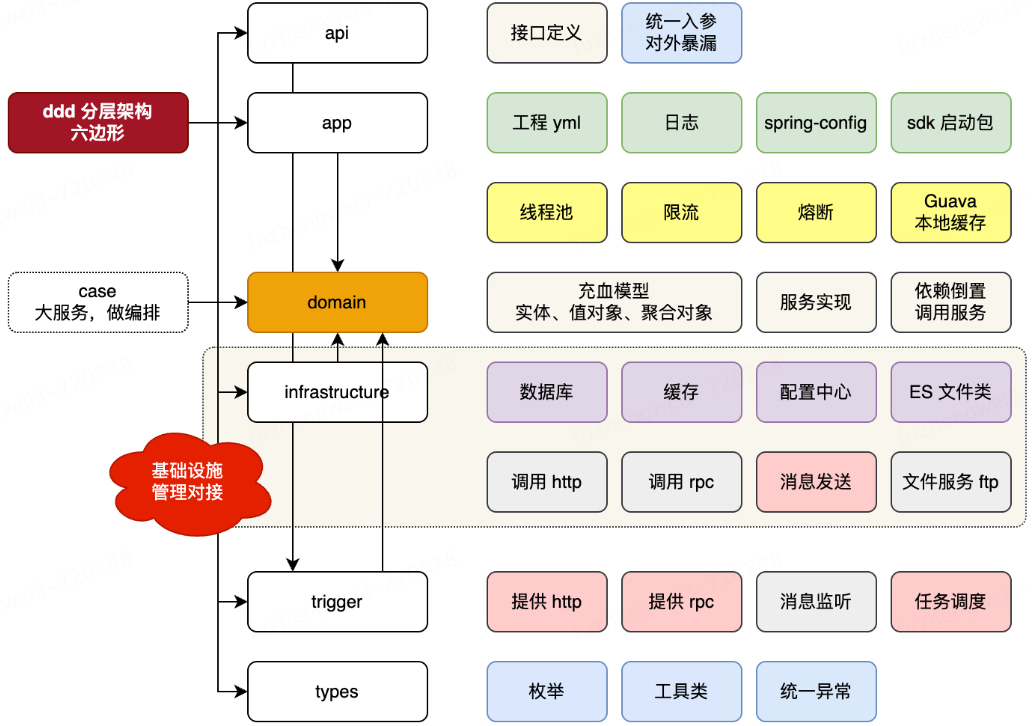
+### 六边形架构
+
+
+
+
+
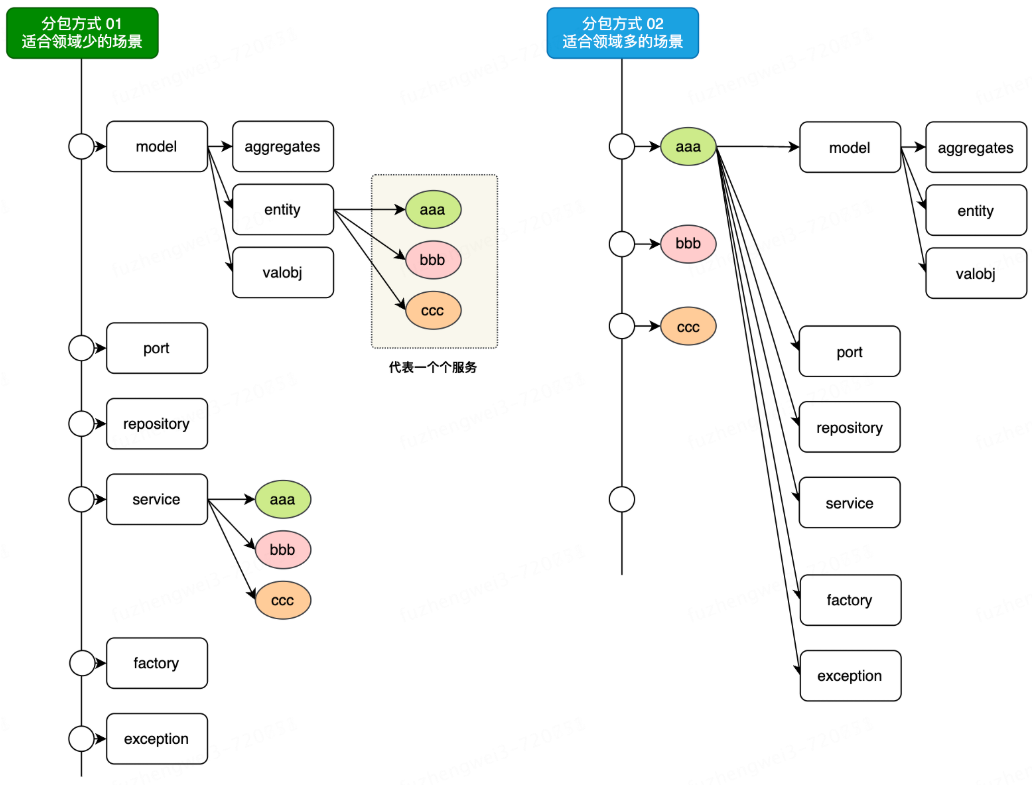
+### 领域模型设计
+
+
+
+- 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。
+- 方式2;业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。
+
+
+
+
diff --git a/自学/JavaWeb——后端.md b/自学/JavaWeb——后端.md
index 5e256c9..1bdae7f 100644
--- a/自学/JavaWeb——后端.md
+++ b/自学/JavaWeb——后端.md
@@ -736,6 +736,25 @@ public class OrderService {
+controller层应注入接口类,而不是子类,如果只有一个子类实现类,那么直接注入即可,否则需要指定注入哪一个
+
+```java
+@Service("categoryServiceImplV1")
+public class CategoryServiceImplV1 implements CategoryService { … }
+
+@Service("categoryServiceImplV2")
+public class CategoryServiceImplV2 implements CategoryService { … }
+
+@RestController
+@RequiredArgsConstructor // 推荐构造器注入
+public class CategoryController {
+
+ @Qualifier("categoryServiceImplV2") // 指定注入 V2
+ private final CategoryService categoryService;
+}
+
+```
+
### 配置文件
diff --git a/自学/Java笔记本.md b/自学/Java笔记本.md
index 57e3739..aea702b 100644
--- a/自学/Java笔记本.md
+++ b/自学/Java笔记本.md
@@ -563,7 +563,9 @@ public class OuterClass {
修改限制:不能有任何静态成员。
-用途:适用于创建一次性使用的实例,通常用于**接口或抽象类**的实现。
+用途:适用于创建一次性使用的实例,通常用于**接口或抽象类**的实现。但**匿名内部类**并不限于接口或抽象类,只要是**非 `final` 的普通类**,都有机会通过匿名内部类来“现场”创建一个**它的子类实例**。
+
+
```java
abstract class Animal {
@@ -614,7 +616,7 @@ public class Main {
#### Lambda表达式
-函数式接口:只有**单一抽象方法**的接口。
+函数式接口:有且仅有一个**抽象方法**的接口。
**`@FunctionalInterface` 注解**:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。
@@ -764,6 +766,8 @@ public class Main {
**1.静态初始化块(Static Initialization Block)**
+例1:
+
```java
public class MyClass {
static int num1, num2;
@@ -799,6 +803,18 @@ main方法执行
**说明:**
类加载时依次执行所有静态代码块,然后执行 `main` 方法。
+例2:
+
+```java
+public static final SpaceUserAuthConfig SPACE_USER_AUTH_CONFIG;
+static {
+ String json = ResourceUtil.readUtf8Str("biz/spaceUserAuthConfig.json");
+ SPACE_USER_AUTH_CONFIG = JSONUtil.toBean(json, SpaceUserAuthConfig.class);
+}
+```
+
+静态初始化块会在类第一次加载到 JVM 时执行一次,用于对静态变量做复杂的初始化。
+
**2.在声明时直接初始化**
@@ -1103,12 +1119,17 @@ Java继承了父类**非私有**的成员变量和成员方法,但是请注意
-#### 抽象类
+#### 抽象类和接口
+
+**抽象类:**
+
+可以包含抽象方法(`abstract`)和具体方法(有方法体)。但至少有一个抽象方法。
+
+**注意:** 抽象类不能被实例化。抽象类中的抽象方法必须显式地用 `abstract` 关键字来声明。而接口中的方法不用`abstract` 。抽象类可以 `implements` 接口,此时无需定义自己的抽象方法也可以。
+
+抽象类可以实现接口中的所有方法,此时它也可以继续保持 `abstract`
-抽象类是包含至少一个抽象方法的类。抽象方法没有实现,只定义了方法的签名。
-**注意:** 抽象类不能被实例化。
-**必须实现抽象方法**
如果一个子类继承了抽象类,通常必须实现抽象类中的所有抽象方法,否则该子类也必须声明为抽象类。例如:
```java
@@ -1135,6 +1156,7 @@ class Dog extends Animal {
```
**如何使用抽象类**
+
由于抽象类不能直接实例化,我们通常有两种方法来使用抽象类:
1. **定义一个新的子类**
@@ -1160,34 +1182,38 @@ class Dog extends Animal {
+**如何算作实现抽象方法**
+
+```java
+public interface StrategyHandler {
+ StrategyHandler DEFAULT = (T, D) -> null;
+ R apply(T requestParameter, D dynamicContext) throws Exception;
+}
+
+public abstract class AbstractStrategyRouter implements StrategyMapper, StrategyHandler {
+
+ @Getter
+ @Setter
+ protected StrategyHandler defaultStrategyHandler = StrategyHandler.DEFAULT;
+
+ public R router(T requestParameter, D dynamicContext) throws Exception {
+ StrategyHandler strategyHandler = get(requestParameter, dynamicContext);
+ if(null != strategyHandler) return strategyHandler.apply(requestParameter, dynamicContext);
+ return defaultStrategyHandler.apply(requestParameter, dynamicContext);
+ }
+
+}
+```
+
+这里 `AbstractStrategyRouter` 属于是定义了普通方法 `router` ,但是 从接口继承下来的 `apply` 和 `get` 方法扔没有实现,将交由继承AbstractStrategyRouter的非抽象子类来实现。
+
+
+
-#### 接口
**接口(Interface)**:
定义了一组方法的规范,侧重于行为的约定。接口中的所有方法默认是抽象的(Java 8 之后可包含默认方法和静态方法),不包含成员变量(除了常量)。
-**抽象类(Abstract Class)**:
-可以包含抽象方法和具体实现的方法,还可以拥有成员变量和构造方法,适用于需要部分通用实现的情况。
-
-1. *方法实现*:
-
- *接口*:
-
- - Java 8 前:所有方法都是抽象方法,只包含方法声明。
- - Java 8 及以后:可包含默认方法(default methods)和静态方法。
-
- *抽象类*:
-
- - 可以同时包含抽象方法(不提供实现)和具体方法(提供实现)。
-2. *继承:*
-
- - 类实现接口时,使用关键字 `implements`。
- - 类继承抽象类时,使用关键字 `extends`。
-3. *多继承*:
-
- - 类可以实现多个接口(多继承)。
- - 类只能继承一个抽象类(单继承)。
-
```java
// 定义接口
interface Flyable {
@@ -1226,6 +1252,31 @@ public class Main {
+**抽象类和接口的区别**
+
+1. *方法实现*:
+
+ *接口*:
+
+ - Java 8 前:所有方法都是抽象方法,只包含方法声明。
+ - Java 8 及以后:可包含默认方法(default methods)和静态方法。
+
+ *抽象类*:
+
+ - 可以同时包含抽象方法(不提供实现)和具体方法(提供实现)。
+2. *继承:*
+
+ - 类实现接口时,使用关键字 `implements`。
+ - 类继承抽象类时,使用关键字 `extends`。
+3. *多继承*:
+
+ - 类可以实现多个接口(多继承)。
+ - 类**只能继承一个抽象类**(单继承)。
+
+
+
+
+
### 容器
#### Collection
@@ -2024,3 +2075,39 @@ Employee employee = Employee.builder()
.build();
```
+
+
+## Java 8 Stream API
+
+```java
+SpaceUserRole role = SPACE_USER_AUTH_CONFIG.getRoles()
+ .stream() // 1
+ .filter(r -> r.getKey().equals(spaceUserRole)) // 2
+ .findFirst() // 3
+ .orElse(null); // 4
+```
+
+**`stream()`**
+把 `List` 转换成一个 `Stream`,Stream 是 Java 8 引入的对集合进行函数式操作的管道。
+
+**`.filter(r -> r.getKey().equals(spaceUserRole))`**
+`filter` 接受一个 `Predicate`(这里是从每个 `SpaceUserRole r` 中调用 `r.getKey().equals(...)`),只保留“满足该条件”的元素,其余都丢弃。
+
+**`.findFirst()`**
+在过滤后的流中,取第一个元素,返回一个 `Optional`。即使流是空的,它也会返回一个空的 `Optional`,而不会抛异常。
+
+**`.orElse(null)`**
+从 `Optional` 中取值:如果存在就返回该值,不存在就返回 `null`。
+
+等价于下面的老式写法(Java 7 及以前):
+
+```java
+SpaceUserRole role = null;
+for (SpaceUserRole r : SPACE_USER_AUTH_CONFIG.getRoles()) {
+ if (r.getKey().equals(spaceUserRole)) {
+ role = r;
+ break;
+ }
+}
+```
+
diff --git a/自学/力扣Hot 100题.md b/自学/力扣Hot 100题.md
index 5283b7a..0b8edab 100644
--- a/自学/力扣Hot 100题.md
+++ b/自学/力扣Hot 100题.md
@@ -1498,7 +1498,7 @@ public class ComparatorSortExample {
-### 列表
+### 链表
“头插法”本质上就是把新节点“插”到已构建链表的头部
@@ -1525,6 +1525,39 @@ ListNode buildList(int[] arr) {
+#### Floyd判环法:快慢指针
+
+```java
+public boolean hasCycle(ListNode head) {
+ if (head == null) return false;
+
+ // 快慢指针都从 head 出发
+ ListNode slow = head;
+ ListNode fast = head;
+
+ // 当 fast 或 fast.next 为 null 时,说明已经到链表末尾,无环
+ while (fast != null && fast.next != null) {
+ slow = slow.next; // 慢指针走一步
+ fast = fast.next.next; // 快指针走两步
+
+ // 每走一步就检查一次相遇
+ if (slow == fast) {
+ return true; // 相遇则有环
+ }
+ }
+
+ return false; // 跳出循环说明没有环
+}
+```
+
+
+
+#### 何时需要定义dummy节点?
+
+当你的操作**有可能“改”到原始的头节点**(插入到最前面,或删除掉第一个节点)时,就定义一个 `dummy`,把它挂在 `head` 之前,之后所有插入/删除都操作 `dummy.next` 及其后继,最后返回 `dummy.next`。
+
+
+
### 哈希
**问题分析**:
diff --git a/自学/拼团交易系统.md b/自学/拼团交易系统.md
index 03985f3..745a4af 100644
--- a/自学/拼团交易系统.md
+++ b/自学/拼团交易系统.md
@@ -2,10 +2,572 @@
## 系统设计
-**功能流程**
+### **功能流程**
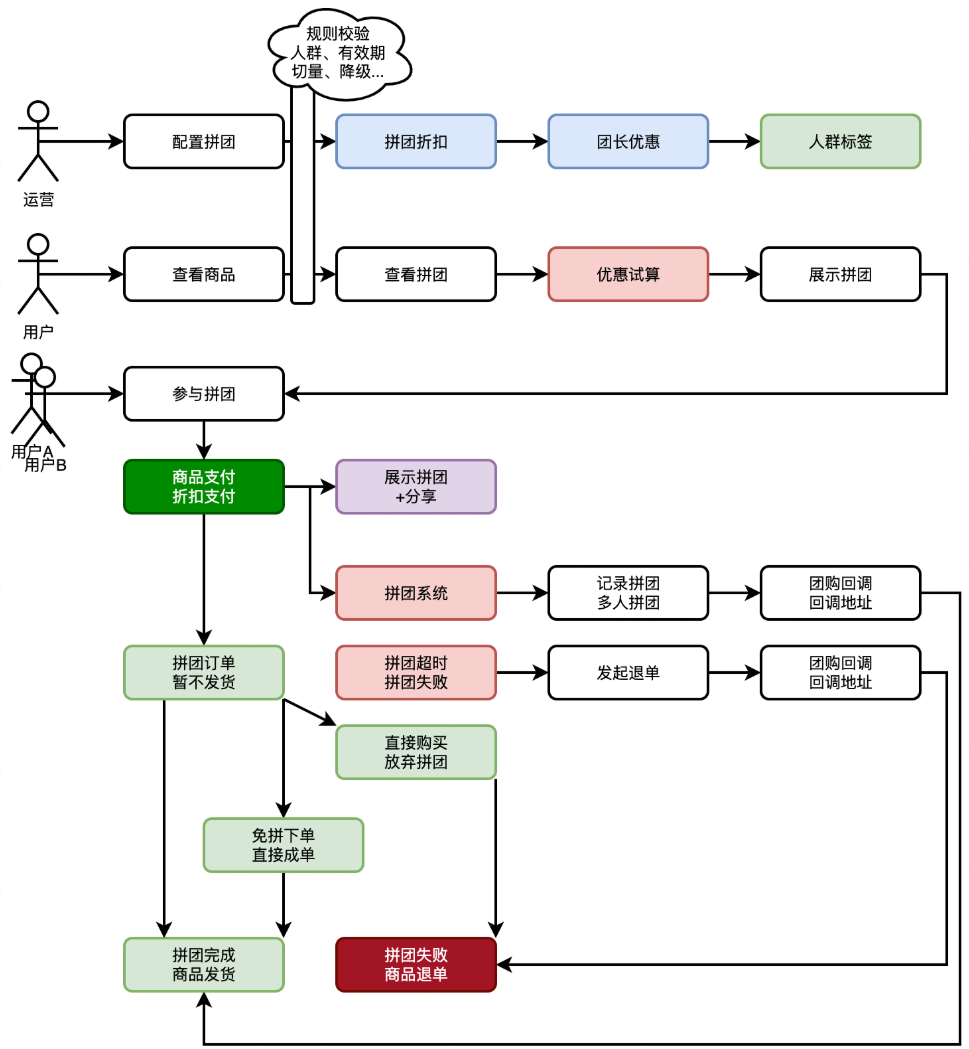
-- 首先,由运营配置商品拼团活动,增加折扣方式。因为有人群标签的过滤,所以可以控制哪些人可参与拼团。
-- 之后,用户可见拼团商品并参与拼团。用户可自主分享拼团或者等待拼团。因为拼团有非常大的折扣刺激用户自主分享,以此可以节省营销推广费用。
-- 最后,拼团完成,触达商品发货。这里有两种,一种运营手段是拼团成团稀有性,必须打成拼团才可以。另外一种是虚拟拼团,无论是否打成,到时都完成拼团。
\ No newline at end of file
+
+
+### **库表设计**
+
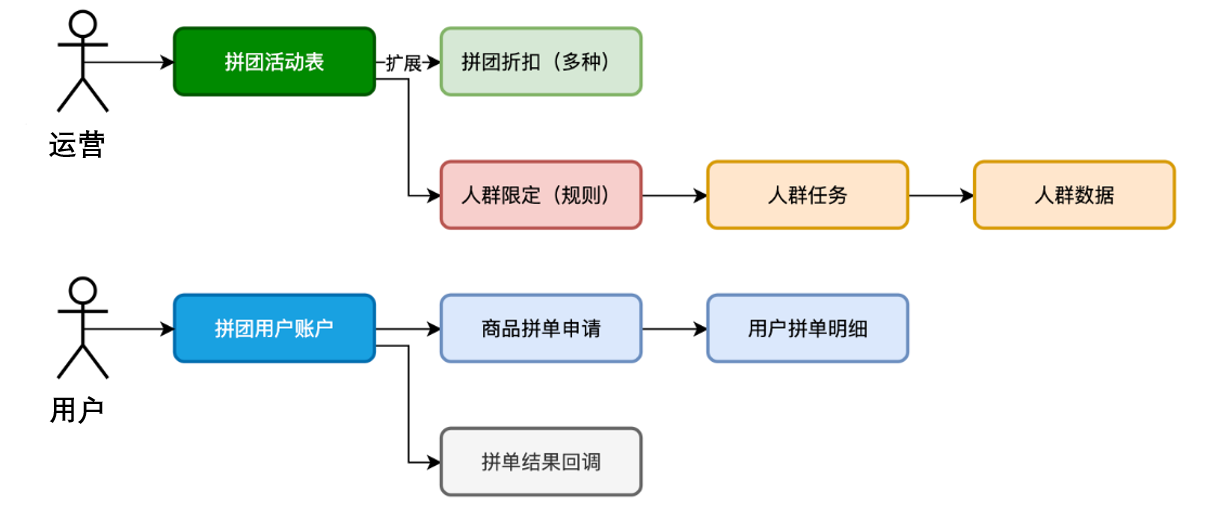
+
+
+- 首先,站在**运营**的角度,要为这次拼团配置对应的**拼团活动**。那么就会涉及到;给哪个渠道的**什么商品**ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商**品所提供的规则信息**,包括:折扣、起止时间、人数等。还要拿到折扣的一个**试算金额**。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。
+- 之后,站在**用户**的角度,是参与拼团。首次**发起一个拼团**或者**参与已存在的拼团**进行数据的记录,达成拼团约定拼团人数后,开始进行**通知**。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
+- 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Redis,并为这批用户打上可配置的**人群标签**。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。
+- 那么,拼团活动表,为什么会把**折扣拆分**出来呢。因为这里的折扣**可能有多种**迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。
+
+
+
+**(一)拼团配置表**
+
+group_buy_activity 拼团活动
+
+| 字段名 | 说明 |
+| ---------------- | -------------------------------------------------------- |
+| id | 自增ID |
+| activity_id | 活动ID |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| discount_id | 折扣ID |
+| group_type | 成团方式【0自动成团(到时间后自动成团)、1达成目标成团】 |
+| take_limit_count | 拼团次数限制 |
+| target | 达成目标(3人单、5人单) |
+| valid_time | 拼单时长(20分钟),未完成拼团则=》自动成功or失败 |
+| status | 活动状态 (活动是否有效,运营可临时设置为失效) |
+| start_time | 活动开始时间 |
+| end_time | 活动结束时间 |
+| tag_id | 人群标签规则标识 |
+| tag_scope | 人群标签规则范围【多选;可见、参与】 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_discount 折扣配置
+
+| 字段名 | 说明 |
+| ------------- | --------------------------------- |
+| id | 自增ID |
+| discount_id | 折扣ID |
+| discount_name | 折扣标题 |
+| discount_desc | 折扣描述 |
+| discount_type | 类型【base、tag】 |
+| market_plan | 营销优惠计划【直减、满减、N元购】 |
+| market_expr | 营销优惠表达式 |
+| tag_id | 人群标签,特定优惠限定 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags 人群标签
+
+| 字段名 | 说明 |
+| ----------- | ----------------------------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| tag_name | 标签名称 |
+| tag_desc | 标签描述 |
+| statistics | 人群标签统计量 200\10万\100万 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags_detail 人群标签明细(写入缓存)
+
+| 字段名 | 说明 |
+| ----------- | -------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| user_id | 用户ID |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags_job 人群标签任务
+
+| 字段名 | 说明 |
+| --------------- | ---------------------------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| batch_id | 批次ID |
+| tag_type | 标签类型【参与量、消费金额】 |
+| tag_rule | 标签规则【限定参与N次】 |
+| stat_start_time | 统计开始时间 |
+| stat_end_time | 统计结束时间 |
+| status | 计划、重置、完成 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+
+
+- 拼团活动表:设定了拼团的成团规则,人群标签的使用可以限定哪些人可见,哪些人可参与。
+- 折扣配置表:拆分出拼团优惠到一个新的表进行多条配置。如果折扣还有更多的复杂规则,则可以配置新的折扣规则表进行处理。
+- 人群标签表:专门来做人群设计记录的,这3张表就是为了把符合规则的人群ID,也就是用户ID,全部跑任务到一个记录下进行使用。比如黑玫瑰人群、高净值人群、拼团履约率90%以上的人群等。
+
+
+
+**(二)参与拼团表**
+
+group_buy_account 拼团账户
+
+| 字段名 | 说明 |
+| --------------------- | ------------ |
+| id | 自增ID |
+| user_id | 用户ID |
+| activity_id | 活动ID |
+| take_limit_count | 拼团次数限制 |
+| take_limit_count_used | 拼团次数消耗 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_order 用户拼单
+
+| 字段名 | 说明 |
+| ---------------------- | ------------------------ |
+| id | 自增ID |
+| activity_id | 活动ID |
+| group_order_id | 拼单ID 【多少人参与】 |
+| group_order_start_time | 拼单开始时间 |
+| group_order_end_time | 拼单结束时间 |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| original_price | 原始价格 |
+| deduction_price | 抵扣价格(各类优惠加成) |
+| pay_amount | 实际支付价格 |
+| target_count | 目标数量 |
+| complete_count | 完成数量 |
+| status | 状态(拼单中/完成/失败) |
+| notify_url | 回调接口 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_order_list 用户拼单明细
+
+| 字段名 | 说明 |
+| -------------- | ---------------------- |
+| id | |
+| activity_id | 活动ID |
+| group_order_id | 拼单ID |
+| user_id | 用户id |
+| user_type | 团长/团员 |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| out_trade_no | 外部交易单号,唯一幂等 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+notify_task 回调任务
+
+| 字段名 | 说明 |
+| -------------- | ---------------------------------- |
+| id | 自增ID |
+| activity_id | 活动ID |
+| order_id | 拼单ID |
+| notify_url | 回调接口 |
+| notify_count | 回调次数(3-5次) |
+| notify_status | 回调状态【初始、完成、重试、失败】 |
+| parameter_json | 参数对象 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+- 拼团账户表:记录用户的拼团参与数据,一个是为了限制用户的参与拼团次数,另外是为了人群标签任务统计数据。
+- 用户拼单表:当有用户发起首次拼单的时候,产生拼单id,并记录所需成团的拼单记录,另外是写上拼团的状态、唯一索引、回调接口等。这样拼团完成就可以回调对接的平台,通知完成了。【微信支付也是这样的设计,回调支付结果,这样的设计可以方便平台化对接】当再有用户参与后,则写入用户拼单明细表。直至达成拼团。
+- 回调任务表:当拼团完成后,要做回调处理。但可能会有失败,所以加入任务的方式进行补偿。如果仍然失败,则需要对接的平台,自己查询拼团结果。
+
+
+
+### 架构设计
+
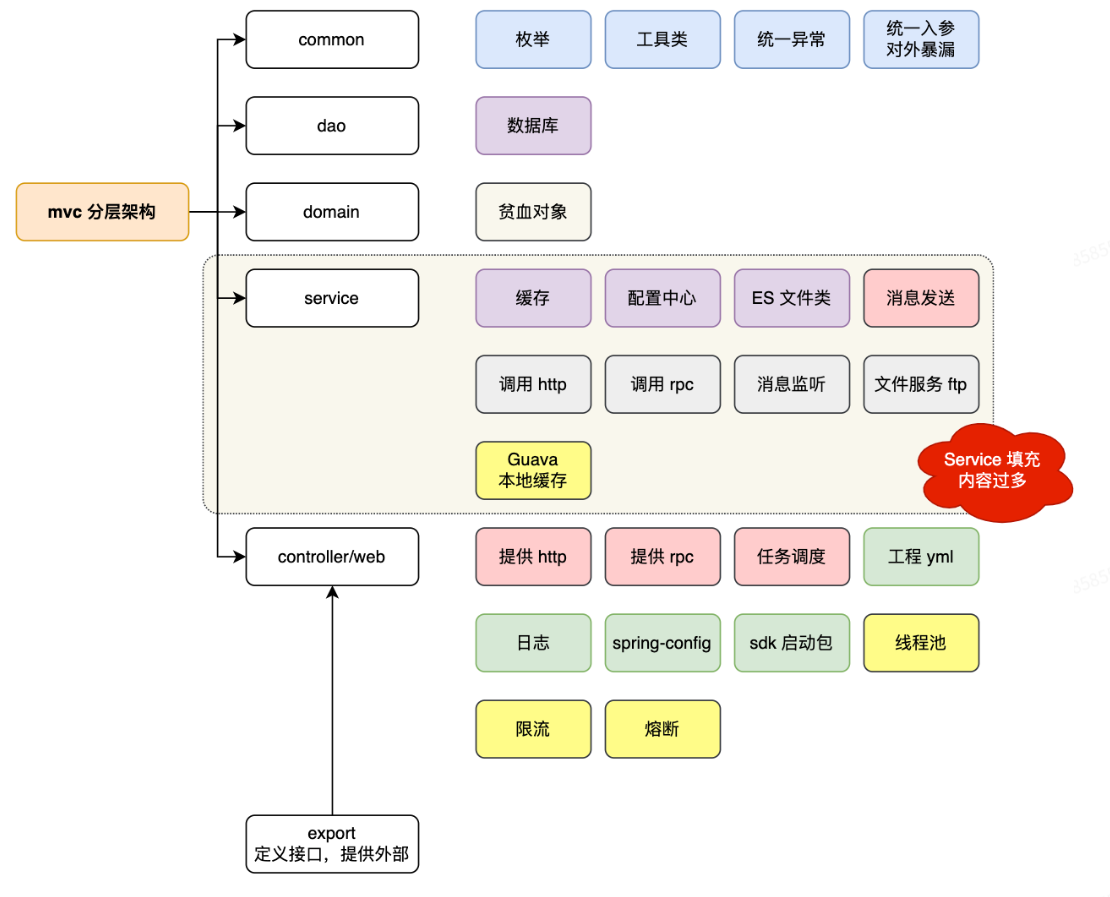
+**MVC架构:**
+
+
+
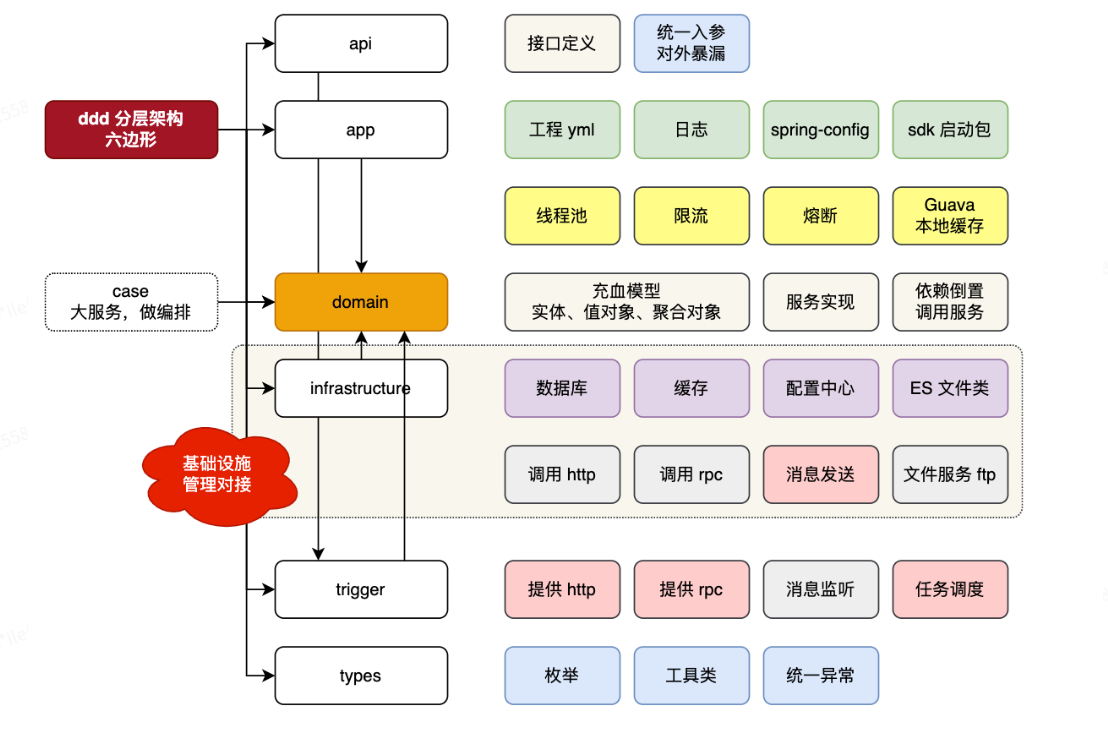
+**DDD架构:**
+
+
+
+
+
+## 价格试算
+
+```java
+@Service
+@RequiredArgsConstructor
+public class IndexGroupBuyMarketServiceImpl implements IIndexGroupBuyMarketService {
+
+ private final DefaultActivityStrategyFactory defaultActivityStrategyFactory;
+
+ @Override
+ public TrialBalanceEntity indexMarketTrial(MarketProductEntity marketProductEntity) throws Exception {
+
+ StrategyHandler strategyHandler = defaultActivityStrategyFactory.strategyHandler();
+
+ TrialBalanceEntity trialBalanceEntity = strategyHandler.apply(marketProductEntity, new DefaultActivityStrategyFactory.DynamicContext());
+
+ return trialBalanceEntity;
+ }
+
+}
+```
+
+```text
+IndexGroupBuyMarketService
+ │
+ │ indexMarketTrial()
+ ▼
+DefaultActivityStrategyFactory
+ │ (return rootNode)
+ ▼
+RootNode.apply()
+ │ doApply() (执行)
+ │ router() (路由到下一node)
+ ▼
+SwitchNode.apply()
+ │ ...
+ ▼
+... (可能还有其他节点)
+ ▼
+EndNode.apply() → 组装结果并返回 TrialBalanceEntity
+ ▲
+ └────────── 最终一路向上 return
+
+```
+
+`IndexGroupBuyMarketService` 是领域服务,整个价格试算的入口
+
+`DefaultActivityStrategyFactory` 帮你拿到 *根节点*,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。
+
+`DynamicContext` 是一次性创建的共享上下文:谁需要谁就往里放
+
+
+
+## 人群标签数据采集
+
+| 步骤 | 目的 | 说明 |
+| ------------------- | ----------------------------------------------- | ------------------------------------------------------------ |
+| **1. 记录日志** | 标明本次批次任务的开始 | 方便后续排查、链路追踪 |
+| **2. 读取批次配置** | 拿到该批次**统计范围、规则、时间窗**等 | 若返回 `null` 通常代表批次号错误或已被清理 |
+| **3. 采集候选用户** | 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 | 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 |
+| **4. 双写标签明细** | 将每个用户与标签的关系永久化 & 提供实时校验能力 | 方法内部两件事:• 插入 `crowd_tags_detail` 表•
+
+
+
+### 六边形架构
+
+
+
+
+
+### 领域模型设计
+
+
+
+- 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。
+- 方式2;业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。
+
+
+
+
diff --git a/自学/JavaWeb——后端.md b/自学/JavaWeb——后端.md
index 5e256c9..1bdae7f 100644
--- a/自学/JavaWeb——后端.md
+++ b/自学/JavaWeb——后端.md
@@ -736,6 +736,25 @@ public class OrderService {
+controller层应注入接口类,而不是子类,如果只有一个子类实现类,那么直接注入即可,否则需要指定注入哪一个
+
+```java
+@Service("categoryServiceImplV1")
+public class CategoryServiceImplV1 implements CategoryService { … }
+
+@Service("categoryServiceImplV2")
+public class CategoryServiceImplV2 implements CategoryService { … }
+
+@RestController
+@RequiredArgsConstructor // 推荐构造器注入
+public class CategoryController {
+
+ @Qualifier("categoryServiceImplV2") // 指定注入 V2
+ private final CategoryService categoryService;
+}
+
+```
+
### 配置文件
diff --git a/自学/Java笔记本.md b/自学/Java笔记本.md
index 57e3739..aea702b 100644
--- a/自学/Java笔记本.md
+++ b/自学/Java笔记本.md
@@ -563,7 +563,9 @@ public class OuterClass {
修改限制:不能有任何静态成员。
-用途:适用于创建一次性使用的实例,通常用于**接口或抽象类**的实现。
+用途:适用于创建一次性使用的实例,通常用于**接口或抽象类**的实现。但**匿名内部类**并不限于接口或抽象类,只要是**非 `final` 的普通类**,都有机会通过匿名内部类来“现场”创建一个**它的子类实例**。
+
+
```java
abstract class Animal {
@@ -614,7 +616,7 @@ public class Main {
#### Lambda表达式
-函数式接口:只有**单一抽象方法**的接口。
+函数式接口:有且仅有一个**抽象方法**的接口。
**`@FunctionalInterface` 注解**:这是一个可选的注解,用于表示接口是一个函数式接口。虽然不是强制的,但它可以帮助编译器识别意图,并检查接口是否确实只有一个抽象方法。
@@ -764,6 +766,8 @@ public class Main {
**1.静态初始化块(Static Initialization Block)**
+例1:
+
```java
public class MyClass {
static int num1, num2;
@@ -799,6 +803,18 @@ main方法执行
**说明:**
类加载时依次执行所有静态代码块,然后执行 `main` 方法。
+例2:
+
+```java
+public static final SpaceUserAuthConfig SPACE_USER_AUTH_CONFIG;
+static {
+ String json = ResourceUtil.readUtf8Str("biz/spaceUserAuthConfig.json");
+ SPACE_USER_AUTH_CONFIG = JSONUtil.toBean(json, SpaceUserAuthConfig.class);
+}
+```
+
+静态初始化块会在类第一次加载到 JVM 时执行一次,用于对静态变量做复杂的初始化。
+
**2.在声明时直接初始化**
@@ -1103,12 +1119,17 @@ Java继承了父类**非私有**的成员变量和成员方法,但是请注意
-#### 抽象类
+#### 抽象类和接口
+
+**抽象类:**
+
+可以包含抽象方法(`abstract`)和具体方法(有方法体)。但至少有一个抽象方法。
+
+**注意:** 抽象类不能被实例化。抽象类中的抽象方法必须显式地用 `abstract` 关键字来声明。而接口中的方法不用`abstract` 。抽象类可以 `implements` 接口,此时无需定义自己的抽象方法也可以。
+
+抽象类可以实现接口中的所有方法,此时它也可以继续保持 `abstract`
-抽象类是包含至少一个抽象方法的类。抽象方法没有实现,只定义了方法的签名。
-**注意:** 抽象类不能被实例化。
-**必须实现抽象方法**
如果一个子类继承了抽象类,通常必须实现抽象类中的所有抽象方法,否则该子类也必须声明为抽象类。例如:
```java
@@ -1135,6 +1156,7 @@ class Dog extends Animal {
```
**如何使用抽象类**
+
由于抽象类不能直接实例化,我们通常有两种方法来使用抽象类:
1. **定义一个新的子类**
@@ -1160,34 +1182,38 @@ class Dog extends Animal {
+**如何算作实现抽象方法**
+
+```java
+public interface StrategyHandler {
+ StrategyHandler DEFAULT = (T, D) -> null;
+ R apply(T requestParameter, D dynamicContext) throws Exception;
+}
+
+public abstract class AbstractStrategyRouter implements StrategyMapper, StrategyHandler {
+
+ @Getter
+ @Setter
+ protected StrategyHandler defaultStrategyHandler = StrategyHandler.DEFAULT;
+
+ public R router(T requestParameter, D dynamicContext) throws Exception {
+ StrategyHandler strategyHandler = get(requestParameter, dynamicContext);
+ if(null != strategyHandler) return strategyHandler.apply(requestParameter, dynamicContext);
+ return defaultStrategyHandler.apply(requestParameter, dynamicContext);
+ }
+
+}
+```
+
+这里 `AbstractStrategyRouter` 属于是定义了普通方法 `router` ,但是 从接口继承下来的 `apply` 和 `get` 方法扔没有实现,将交由继承AbstractStrategyRouter的非抽象子类来实现。
+
+
+
-#### 接口
**接口(Interface)**:
定义了一组方法的规范,侧重于行为的约定。接口中的所有方法默认是抽象的(Java 8 之后可包含默认方法和静态方法),不包含成员变量(除了常量)。
-**抽象类(Abstract Class)**:
-可以包含抽象方法和具体实现的方法,还可以拥有成员变量和构造方法,适用于需要部分通用实现的情况。
-
-1. *方法实现*:
-
- *接口*:
-
- - Java 8 前:所有方法都是抽象方法,只包含方法声明。
- - Java 8 及以后:可包含默认方法(default methods)和静态方法。
-
- *抽象类*:
-
- - 可以同时包含抽象方法(不提供实现)和具体方法(提供实现)。
-2. *继承:*
-
- - 类实现接口时,使用关键字 `implements`。
- - 类继承抽象类时,使用关键字 `extends`。
-3. *多继承*:
-
- - 类可以实现多个接口(多继承)。
- - 类只能继承一个抽象类(单继承)。
-
```java
// 定义接口
interface Flyable {
@@ -1226,6 +1252,31 @@ public class Main {
+**抽象类和接口的区别**
+
+1. *方法实现*:
+
+ *接口*:
+
+ - Java 8 前:所有方法都是抽象方法,只包含方法声明。
+ - Java 8 及以后:可包含默认方法(default methods)和静态方法。
+
+ *抽象类*:
+
+ - 可以同时包含抽象方法(不提供实现)和具体方法(提供实现)。
+2. *继承:*
+
+ - 类实现接口时,使用关键字 `implements`。
+ - 类继承抽象类时,使用关键字 `extends`。
+3. *多继承*:
+
+ - 类可以实现多个接口(多继承)。
+ - 类**只能继承一个抽象类**(单继承)。
+
+
+
+
+
### 容器
#### Collection
@@ -2024,3 +2075,39 @@ Employee employee = Employee.builder()
.build();
```
+
+
+## Java 8 Stream API
+
+```java
+SpaceUserRole role = SPACE_USER_AUTH_CONFIG.getRoles()
+ .stream() // 1
+ .filter(r -> r.getKey().equals(spaceUserRole)) // 2
+ .findFirst() // 3
+ .orElse(null); // 4
+```
+
+**`stream()`**
+把 `List` 转换成一个 `Stream`,Stream 是 Java 8 引入的对集合进行函数式操作的管道。
+
+**`.filter(r -> r.getKey().equals(spaceUserRole))`**
+`filter` 接受一个 `Predicate`(这里是从每个 `SpaceUserRole r` 中调用 `r.getKey().equals(...)`),只保留“满足该条件”的元素,其余都丢弃。
+
+**`.findFirst()`**
+在过滤后的流中,取第一个元素,返回一个 `Optional`。即使流是空的,它也会返回一个空的 `Optional`,而不会抛异常。
+
+**`.orElse(null)`**
+从 `Optional` 中取值:如果存在就返回该值,不存在就返回 `null`。
+
+等价于下面的老式写法(Java 7 及以前):
+
+```java
+SpaceUserRole role = null;
+for (SpaceUserRole r : SPACE_USER_AUTH_CONFIG.getRoles()) {
+ if (r.getKey().equals(spaceUserRole)) {
+ role = r;
+ break;
+ }
+}
+```
+
diff --git a/自学/力扣Hot 100题.md b/自学/力扣Hot 100题.md
index 5283b7a..0b8edab 100644
--- a/自学/力扣Hot 100题.md
+++ b/自学/力扣Hot 100题.md
@@ -1498,7 +1498,7 @@ public class ComparatorSortExample {
-### 列表
+### 链表
“头插法”本质上就是把新节点“插”到已构建链表的头部
@@ -1525,6 +1525,39 @@ ListNode buildList(int[] arr) {
+#### Floyd判环法:快慢指针
+
+```java
+public boolean hasCycle(ListNode head) {
+ if (head == null) return false;
+
+ // 快慢指针都从 head 出发
+ ListNode slow = head;
+ ListNode fast = head;
+
+ // 当 fast 或 fast.next 为 null 时,说明已经到链表末尾,无环
+ while (fast != null && fast.next != null) {
+ slow = slow.next; // 慢指针走一步
+ fast = fast.next.next; // 快指针走两步
+
+ // 每走一步就检查一次相遇
+ if (slow == fast) {
+ return true; // 相遇则有环
+ }
+ }
+
+ return false; // 跳出循环说明没有环
+}
+```
+
+
+
+#### 何时需要定义dummy节点?
+
+当你的操作**有可能“改”到原始的头节点**(插入到最前面,或删除掉第一个节点)时,就定义一个 `dummy`,把它挂在 `head` 之前,之后所有插入/删除都操作 `dummy.next` 及其后继,最后返回 `dummy.next`。
+
+
+
### 哈希
**问题分析**:
diff --git a/自学/拼团交易系统.md b/自学/拼团交易系统.md
index 03985f3..745a4af 100644
--- a/自学/拼团交易系统.md
+++ b/自学/拼团交易系统.md
@@ -2,10 +2,572 @@
## 系统设计
-**功能流程**
+### **功能流程**

-- 首先,由运营配置商品拼团活动,增加折扣方式。因为有人群标签的过滤,所以可以控制哪些人可参与拼团。
-- 之后,用户可见拼团商品并参与拼团。用户可自主分享拼团或者等待拼团。因为拼团有非常大的折扣刺激用户自主分享,以此可以节省营销推广费用。
-- 最后,拼团完成,触达商品发货。这里有两种,一种运营手段是拼团成团稀有性,必须打成拼团才可以。另外一种是虚拟拼团,无论是否打成,到时都完成拼团。
\ No newline at end of file
+
+
+### **库表设计**
+
+
+
+- 首先,站在**运营**的角度,要为这次拼团配置对应的**拼团活动**。那么就会涉及到;给哪个渠道的**什么商品**ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商**品所提供的规则信息**,包括:折扣、起止时间、人数等。还要拿到折扣的一个**试算金额**。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。
+- 之后,站在**用户**的角度,是参与拼团。首次**发起一个拼团**或者**参与已存在的拼团**进行数据的记录,达成拼团约定拼团人数后,开始进行**通知**。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
+- 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Redis,并为这批用户打上可配置的**人群标签**。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。
+- 那么,拼团活动表,为什么会把**折扣拆分**出来呢。因为这里的折扣**可能有多种**迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。
+
+
+
+**(一)拼团配置表**
+
+group_buy_activity 拼团活动
+
+| 字段名 | 说明 |
+| ---------------- | -------------------------------------------------------- |
+| id | 自增ID |
+| activity_id | 活动ID |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| discount_id | 折扣ID |
+| group_type | 成团方式【0自动成团(到时间后自动成团)、1达成目标成团】 |
+| take_limit_count | 拼团次数限制 |
+| target | 达成目标(3人单、5人单) |
+| valid_time | 拼单时长(20分钟),未完成拼团则=》自动成功or失败 |
+| status | 活动状态 (活动是否有效,运营可临时设置为失效) |
+| start_time | 活动开始时间 |
+| end_time | 活动结束时间 |
+| tag_id | 人群标签规则标识 |
+| tag_scope | 人群标签规则范围【多选;可见、参与】 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_discount 折扣配置
+
+| 字段名 | 说明 |
+| ------------- | --------------------------------- |
+| id | 自增ID |
+| discount_id | 折扣ID |
+| discount_name | 折扣标题 |
+| discount_desc | 折扣描述 |
+| discount_type | 类型【base、tag】 |
+| market_plan | 营销优惠计划【直减、满减、N元购】 |
+| market_expr | 营销优惠表达式 |
+| tag_id | 人群标签,特定优惠限定 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags 人群标签
+
+| 字段名 | 说明 |
+| ----------- | ----------------------------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| tag_name | 标签名称 |
+| tag_desc | 标签描述 |
+| statistics | 人群标签统计量 200\10万\100万 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags_detail 人群标签明细(写入缓存)
+
+| 字段名 | 说明 |
+| ----------- | -------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| user_id | 用户ID |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+crowd_tags_job 人群标签任务
+
+| 字段名 | 说明 |
+| --------------- | ---------------------------- |
+| id | 自增ID |
+| tag_id | 标签ID |
+| batch_id | 批次ID |
+| tag_type | 标签类型【参与量、消费金额】 |
+| tag_rule | 标签规则【限定参与N次】 |
+| stat_start_time | 统计开始时间 |
+| stat_end_time | 统计结束时间 |
+| status | 计划、重置、完成 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+
+
+- 拼团活动表:设定了拼团的成团规则,人群标签的使用可以限定哪些人可见,哪些人可参与。
+- 折扣配置表:拆分出拼团优惠到一个新的表进行多条配置。如果折扣还有更多的复杂规则,则可以配置新的折扣规则表进行处理。
+- 人群标签表:专门来做人群设计记录的,这3张表就是为了把符合规则的人群ID,也就是用户ID,全部跑任务到一个记录下进行使用。比如黑玫瑰人群、高净值人群、拼团履约率90%以上的人群等。
+
+
+
+**(二)参与拼团表**
+
+group_buy_account 拼团账户
+
+| 字段名 | 说明 |
+| --------------------- | ------------ |
+| id | 自增ID |
+| user_id | 用户ID |
+| activity_id | 活动ID |
+| take_limit_count | 拼团次数限制 |
+| take_limit_count_used | 拼团次数消耗 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_order 用户拼单
+
+| 字段名 | 说明 |
+| ---------------------- | ------------------------ |
+| id | 自增ID |
+| activity_id | 活动ID |
+| group_order_id | 拼单ID 【多少人参与】 |
+| group_order_start_time | 拼单开始时间 |
+| group_order_end_time | 拼单结束时间 |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| original_price | 原始价格 |
+| deduction_price | 抵扣价格(各类优惠加成) |
+| pay_amount | 实际支付价格 |
+| target_count | 目标数量 |
+| complete_count | 完成数量 |
+| status | 状态(拼单中/完成/失败) |
+| notify_url | 回调接口 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+group_buy_order_list 用户拼单明细
+
+| 字段名 | 说明 |
+| -------------- | ---------------------- |
+| id | |
+| activity_id | 活动ID |
+| group_order_id | 拼单ID |
+| user_id | 用户id |
+| user_type | 团长/团员 |
+| source | 来源 |
+| channel | 渠道 |
+| goods_id | 商品ID |
+| out_trade_no | 外部交易单号,唯一幂等 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+notify_task 回调任务
+
+| 字段名 | 说明 |
+| -------------- | ---------------------------------- |
+| id | 自增ID |
+| activity_id | 活动ID |
+| order_id | 拼单ID |
+| notify_url | 回调接口 |
+| notify_count | 回调次数(3-5次) |
+| notify_status | 回调状态【初始、完成、重试、失败】 |
+| parameter_json | 参数对象 |
+| create_time | 创建时间 |
+| update_time | 更新时间 |
+
+- 拼团账户表:记录用户的拼团参与数据,一个是为了限制用户的参与拼团次数,另外是为了人群标签任务统计数据。
+- 用户拼单表:当有用户发起首次拼单的时候,产生拼单id,并记录所需成团的拼单记录,另外是写上拼团的状态、唯一索引、回调接口等。这样拼团完成就可以回调对接的平台,通知完成了。【微信支付也是这样的设计,回调支付结果,这样的设计可以方便平台化对接】当再有用户参与后,则写入用户拼单明细表。直至达成拼团。
+- 回调任务表:当拼团完成后,要做回调处理。但可能会有失败,所以加入任务的方式进行补偿。如果仍然失败,则需要对接的平台,自己查询拼团结果。
+
+
+
+### 架构设计
+
+**MVC架构:**
+
+
+
+**DDD架构:**
+
+
+
+
+
+## 价格试算
+
+```java
+@Service
+@RequiredArgsConstructor
+public class IndexGroupBuyMarketServiceImpl implements IIndexGroupBuyMarketService {
+
+ private final DefaultActivityStrategyFactory defaultActivityStrategyFactory;
+
+ @Override
+ public TrialBalanceEntity indexMarketTrial(MarketProductEntity marketProductEntity) throws Exception {
+
+ StrategyHandler strategyHandler = defaultActivityStrategyFactory.strategyHandler();
+
+ TrialBalanceEntity trialBalanceEntity = strategyHandler.apply(marketProductEntity, new DefaultActivityStrategyFactory.DynamicContext());
+
+ return trialBalanceEntity;
+ }
+
+}
+```
+
+```text
+IndexGroupBuyMarketService
+ │
+ │ indexMarketTrial()
+ ▼
+DefaultActivityStrategyFactory
+ │ (return rootNode)
+ ▼
+RootNode.apply()
+ │ doApply() (执行)
+ │ router() (路由到下一node)
+ ▼
+SwitchNode.apply()
+ │ ...
+ ▼
+... (可能还有其他节点)
+ ▼
+EndNode.apply() → 组装结果并返回 TrialBalanceEntity
+ ▲
+ └────────── 最终一路向上 return
+
+```
+
+`IndexGroupBuyMarketService` 是领域服务,整个价格试算的入口
+
+`DefaultActivityStrategyFactory` 帮你拿到 *根节点*,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。
+
+`DynamicContext` 是一次性创建的共享上下文:谁需要谁就往里放
+
+
+
+## 人群标签数据采集
+
+| 步骤 | 目的 | 说明 |
+| ------------------- | ----------------------------------------------- | ------------------------------------------------------------ |
+| **1. 记录日志** | 标明本次批次任务的开始 | 方便后续排查、链路追踪 |
+| **2. 读取批次配置** | 拿到该批次**统计范围、规则、时间窗**等 | 若返回 `null` 通常代表批次号错误或已被清理 |
+| **3. 采集候选用户** | 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 | 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 |
+| **4. 双写标签明细** | 将每个用户与标签的关系永久化 & 提供实时校验能力 | 方法内部两件事:• 插入 `crowd_tags_detail` 表•
在 Redis **BitMap** 中把该用户对应位设为 1(幂等处理冲突) |
+| **5. 更新统计量** | 维护标签当前命中人数,用于运营看板 | 这里简单按“新增条数”累加,也可改为重新 `count(*)` 全量回填 |
+| **6. 结束** | 方法返回 void | 如果过程抛异常,调度系统可重试/报警 |
+
+> **一句话总结**
+> 这是一个被定时器或消息触发的**离线批量打标签任务**:
+> 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。
+> 之后业务系统就能用位图做到毫秒级 `isUserInTag(userId, tagId)` 判断,实现精准运营投放。
+
+
+
+### Bitmap(位图)
+
+**概念**
+
+- Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。
+- 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。
+
+**为什么用 Bitmap?**
+
+- **超高空间效率**:1000 万个用户,只需要约 10 MB(1000 万 / 8)。
+- **超快操作**:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。
+
+**典型场景**
+
+- **用户标签 / 权限判断**:把符合某个条件的用户的索引位置设置为 1,以后实时判断“用户 X 是否在标签 A 中?”就只需读一个 bit。
+- **海量去重 / 布隆过滤器**:在超大流量场景下判断“URL 是否已访问过”、“手机号是否已注册”等。
+- **统计分析**:快速统计某个条件下有多少个用户/对象符合(BITCOUNT)。
+
+
+
+## 收获
+
+### 模板方法
+
+**核心思想**:
+在抽象父类中定义**算法骨架**(固定执行顺序),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。
+
+```text
+ Client ───▶ AbstractClass
+ ├─ templateMethod() ←—— 固定流程
+ │ step1()
+ │ step2() ←—— 抽象,可变
+ │ step3()
+ └─ hookMethod() ←—— 可选覆盖
+ ▲
+ │ extends
+ ┌──────────┴──────────┐
+ │ ConcreteClassA/B… │
+
+```
+
+**示例:**
+
+```java
+// 1. 抽象模板
+public abstract class AbstractDialog {
+
+ // 模板方法:固定调用顺序,设为 final 防止子类改流程
+ public final void show() {
+ initLayout();
+ bindEvent();
+ beforeDisplay(); // 钩子,可选
+ display();
+ afterDisplay(); // 钩子,可选
+ }
+
+ // 具体公共步骤
+ private void initLayout() {
+ System.out.println("加载通用布局文件");
+ }
+
+ // 需要子类实现的抽象步骤
+ protected abstract void bindEvent();
+
+ // 钩子方法,默认空实现
+ protected void beforeDisplay() {}
+ protected void afterDisplay() {}
+
+ private void display() {
+ System.out.println("弹出对话框");
+ }
+}
+
+// 2. 子类:登录对话框
+public class LoginDialog extends AbstractDialog {
+ @Override
+ protected void bindEvent() {
+ System.out.println("绑定登录按钮事件");
+ }
+ @Override
+ protected void afterDisplay() {
+ System.out.println("focus 到用户名输入框");
+ }
+}
+
+// 3. 调用
+public class Demo {
+ public static void main(String[] args) {
+ AbstractDialog dialog = new LoginDialog();
+ dialog.show();
+ /* 输出:
+ 加载通用布局文件
+ 绑定登录按钮事件
+ 弹出对话框
+ focus 到用户名输入框
+ */
+ }
+}
+```
+
+**要点**
+
+- **复用公共流程**:`initLayout()`、`display()` 写一次即可。
+- **限制流程顺序**:`show()` 定为 `final`,防止子类乱改步骤。
+- **钩子方法**:子类可选择性覆盖(如 `beforeDisplay`)。
+
+
+
+### 规则树流程
+
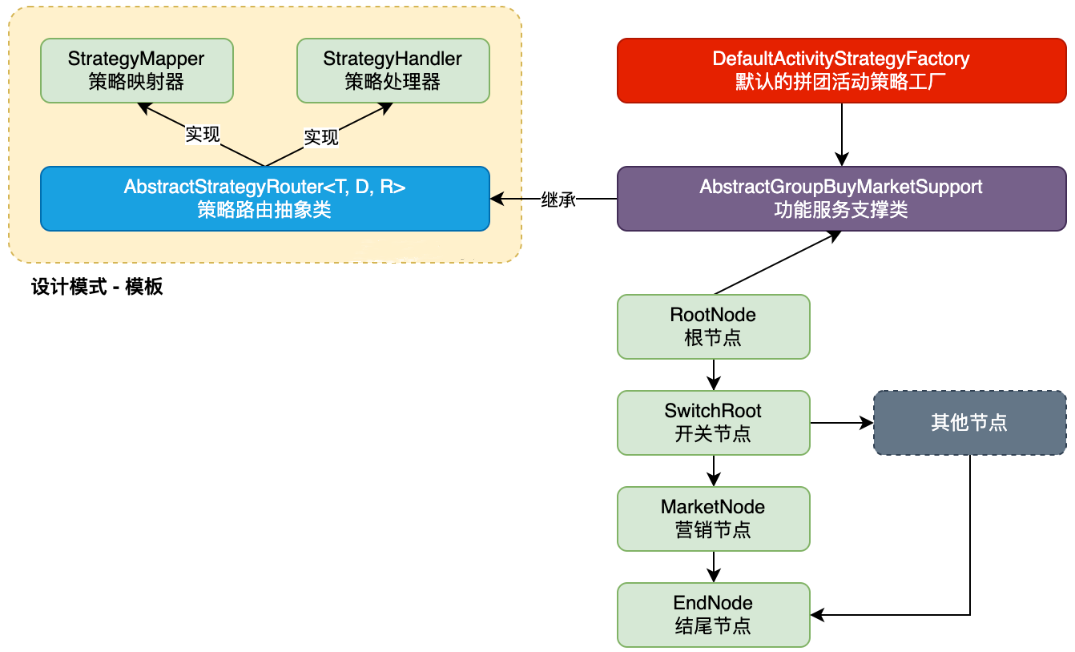
+
+
+**整体分层思路**
+
+| 分层 | 作用 | 关键对象 |
+| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| **通用模板层** | 抽象出与具体业务无关的「规则树」骨架,解决 *如何找到并执行策略* 的共性问题 | `StrategyMapper`、`StrategyHandler`、`AbstractStrategyRouter` |
+| **业务装配层** | 基于模板,自由拼装出 *一棵* 贴合业务流程的策略树 | `RootNode / SwitchRoot / MarketNode / EndNode …` |
+| **对外暴露层** | 通过 **工厂 + 服务支持类** 将整棵树封装成一个可直接调用的 `StrategyHandler`,并交给 Spring 整体托管 | `DefaultActivityStrategyFactory`、`AbstractGroupBuyMarketSupport` |
+
+**通用模板层:规则树的“骨架”**
+
+| 角色 | 职责 | 关系 |
+| ------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| `StrategyMapper` | **映射器**:依据 `requestParameter + dynamicContext` 选出 *下一个* 策略节点 | 被 `AbstractStrategyRouter` 调用 |
+| `StrategyHandler` | **处理器**:真正执行业务逻辑;`apply` 结束后可返回结果或继续路由 | 节点本身 / 路由器本身都是它的实现 |
+| `AbstractStrategyRouter` | **路由模板**:① 调用 `get(...)` 找到合适的 `StrategyHandler`;② 调用该 handler 的 `apply(...)`;③ 若未命中则走 `defaultStrategyHandler` | 同时实现 `StrategyMapper` 与 `StrategyHandler`,但自身保持 *抽象*,把细节延迟到子类 |
+
+**业务装配层:一棵可编排的策略树**
+
+```text
+RootNode -> SwitchRoot -> MarketNode -> EndNode
+ ↘︎ OtherNode ...
+```
+
+- 每个节点
+
+ 继承 `AbstractStrategyRouter`
+
+ - 实现 `get(...)`:决定当前节点的下一跳是哪一个节点
+ - 实现 `apply(...)`:实现节点自身应做的业务动作(或继续下钻)
+
+- 组合方式
+
+ 比责任链更灵活:
+
+ - 一个节点既可以“继续路由”也可以“自己处理完直接返回”
+ - 可以随时插拔 / 替换子节点,形成多分支、循环、早停等复杂流转
+
+**对外暴露层:工厂 + 服务支持类**
+
+| 组件 | 主要职责 |
+| --------------------------------------------- | ------------------------------------------------------------ |
+| `DefaultActivityStrategyFactory` (`@Service`) | **工厂**:1. 在 Spring 启动时注入根节点 `RootNode`;2. 暴露**统一入口** `strategyHandler()` → 返回整个策略树顶点(一个 `StrategyHandler` 实例) |
+| `AbstractGroupBuyMarketSupport` | **业务服务基类**:封装拼团场景下共用的查询、工具方法;供每个**节点**继承使用 |
+
+这样,调用方只需
+
+```java
+TrialBalanceEntity result =
+ factory.strategyHandler().apply(product, new DynamicContext(vo1, vo2));
+```
+
+就能驱动整棵策略树,而**完全不用关心**节点搭建、依赖注入等细节。
+
+
+
+### 策略模式
+
+**核心思想**:
+把可互换的算法/行为抽成独立策略类,运行时由“上下文”对象选择合适的策略;对调用方来说,只关心统一接口,而非具体实现。
+
+```text
+┌───────────────┐
+│ Client │
+└─────▲─────────┘
+ │ has-a
+┌─────┴─────────┐ implements
+│ Context │────────────┐ ┌──────────────┐
+│ (使用者) │ strategy └─▶│ Strategy A │
+└───────────────┘ ├──────────────┤
+ │ Strategy B │
+ └──────────────┘
+
+```
+
+#### 集合自动注入
+
+常见于策略/工厂/插件场景。
+
+```java
+@Autowired
+private Map discountCalculateServiceMap;
+```
+
+**字段类型**:`Map`
+
+- key—— Bean 的名字
+ - 默认是类名首字母小写 (`mjCalculateService`)
+ - 或者你在实现类上显式写的 `@Service("MJ")`
+- **value** —— 那个实现类对应的实例
+- **Spring 机制**:
+ 1. 启动时扫描所有实现 `IDiscountCalculateService` 的 Bean。
+ 2. 把它们按 “BeanName → Bean 实例” 的映射注入到这张 `Map` 里。
+ 3. 你一次性就拿到了“策略字典”。
+
+**示例:**
+
+```java
+@Service("MJ") // ★ 关键:Bean 名即策略键
+public class MJCalculateService extends IDiscountCalculateService {
+
+ @Override
+ protected BigDecimal Calculate(String userId, BigDecimal originalPrice,
+ GroupBuyActivityDiscountVO.GroupBuyDiscount groupBuyDiscount) {
+ //忽略实现细节
+}
+
+@Component
+@RequiredArgsConstructor // 构造器注入更推荐
+public class DiscountContext {
+
+ private final Map discountServiceMap;
+
+ public BigDecimal calc(String strategyKey,
+ String userId,
+ BigDecimal originalPrice,
+ GroupBuyActivityDiscountVO.GroupBuyDiscount plan) {
+ //strategyKey可以是"MJ" ..
+ IDiscountCalculateService strategy = discountServiceMap.get(strategyKey);
+ if (strategy == null) {
+ throw new IllegalArgumentException("无匹配折扣类型: " + strategyKey);
+ }
+ return strategy.calculate(userId, originalPrice, plan);
+ }
+}
+```
+
+
+
+
+
+### 多线程异步调用
+
+```java
+// Runnable ➞ 只能 run(),没有返回值
+public interface Runnable {
+ void run();
+}
+
+// Callable ➞ call() 能返回 V,也能抛检查型异常
+public interface Callable {
+ V call() throws Exception;
+}
+```
+
+```java
+public class MyTask implements Callable {
+ private final String name;
+ public MyTask(String name) {
+ this.name = name;
+ }
+ @Override
+ public String call() throws Exception {
+ // 模拟耗时操作
+ TimeUnit.MILLISECONDS.sleep(300);
+ return "任务[" + name + "]的执行结果";
+ }
+}
+```
+
+```java
+public class SimpleAsyncDemo {
+ public static void main(String[] args) {
+ // 创建大小为 2 的线程池
+ ExecutorService pool = Executors.newFixedThreadPool(2);
+
+ try {
+ // 构造两个任务
+ MyTask task1 = new MyTask("A");
+ MyTask task2 = new MyTask("B");
+
+ // 用 FutureTask 包装 Callable
+ FutureTask future1 = new FutureTask<>(task1);
+ FutureTask future2 = new FutureTask<>(task2);
+
+ // 提交给线程池异步执行
+ pool.execute(future1);
+ pool.execute(future2);
+
+ // 主线程可以先做别的事…
+ System.out.println("主线程正在做其他事情…");
+
+ // ③ 在需要的时候再获取结果(可加超时)
+ String result1 = future1.get(1, TimeUnit.SECONDS); //设置超时时间1秒
+ String result2 = future2.get(); //无超时时间
+
+ System.out.println("拿到结果1 → " + result1);
+ System.out.println("拿到结果2 → " + result2);
+
+ } catch (InterruptedException e) {
+ Thread.currentThread().interrupt();
+ } catch (ExecutionException e) {
+ System.err.println("任务执行中出错: " + e.getCause());
+ } catch (TimeoutException e) {
+ System.err.println("等待结果超时");
+ } finally {
+ pool.shutdown();
+ }
+ }
+}
+```
+
diff --git a/自学/智能协同云图库.md b/自学/智能协同云图库.md
index b8609b7..f0b8158 100644
--- a/自学/智能协同云图库.md
+++ b/自学/智能协同云图库.md
@@ -100,7 +100,40 @@ AI扩图
+**创建图片的业务流程**
+创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
+有两种常见的处理方式:
+
+1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的**url存储地址**;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
+2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
+当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
+
+
+
+## 优化
+
+
+
+
+
+协同编辑:
+扩展
+1、为防止消息丢失,可以使用 Redis 等高性能存储保存执行的操作记录。
+
+目前如果图片已经被编辑了,新用户加入编辑时没办法查看到已编辑的状态,这一点也可以利用 Redis 保存操作记录来解决,新用户加入编辑时读取 Redis 的操作记录即可。
+
+2、每种类型的消息处理可以封装为独立的 Handler 处理器类,也就是采用策略模式。
+
+3、支持分布式 WebSocket。实现思路很简单,只需要保证要编辑同一图片的用户连接的是相同的服务器即可,和游戏分服务器大区、聊天室分房间是类似的原理。
+
+4、一些小问题的优化:比如 WebSocket 连接建立之后,如果用户退出了登录,这时 WebSocket 的连接是没有断开的。不过影响并不大,可以思考下怎么处理。
+
+
+
+## 收获
+
+### MybatisX插件简化开发
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
@@ -122,27 +155,6 @@ private static final long serialVersionUID = -1321880859645675653L;
-**创建图片的业务流程**
-创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
-
-有两种常见的处理方式:
-
-1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的**url存储地址**;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
-2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
-当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
-
-
-
-## 优化
-
-
-
-
-
-
-
-## 收获
-
### 胡图工具类hutool
`ObjUtil.isNotNull(Object obj)`,仅判断对象是否 **不为 `null`**,不关心对象内容是否为空,比如空字符串 `""`、空集合 `[]`、数字 `0` 等都算是“非 null”。
@@ -168,6 +180,38 @@ private static final long serialVersionUID = -1321880859645675653L;
`CollUtil.isNotEmpty(Collection coll)`用于判断 **集合(Collection)是否非空**,功能类似于 `ObjUtil.isNotEmpty(...)`
+
+
+`BeanUtil.toBean` :用来**把一个 Map、JSONObject 或者另一个对象快速转换成你的目标 JavaBean**
+
+```java
+public class BeanUtilExample {
+ public static class User {
+ private String name;
+ private Integer age;
+ // 省略 getter/setter
+ }
+
+ public static void main(String[] args) {
+ // 1. 从 Map 转 Bean
+ Map data = new HashMap<>();
+ data.put("name", "Alice");
+ data.put("age", 30);
+ User user1 = BeanUtil.toBean(data, User.class);
+ System.out.println(user1.getName()); // Alice
+
+ // 2. 从另一个对象转 Bean
+ class Temp { public String name = "Bob"; public int age = 25; }
+ Temp temp = new Temp();
+ User user2 = BeanUtil.toBean(temp, User.class);
+ System.out.println(user2.getAge()); // 25
+ }
+}
+
+```
+
+
+
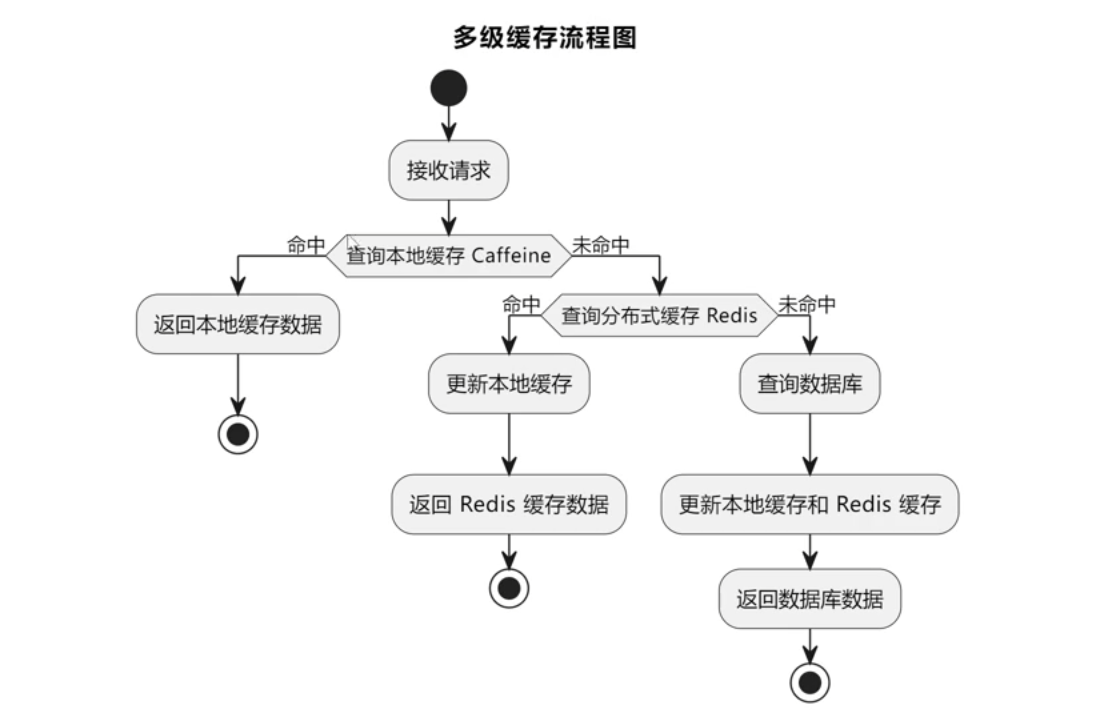
### 多级缓存
@@ -259,6 +303,35 @@ server:
+
+
+团队空间
+
+空间和用户是多对多的关系,还要同时记录用户在某空间的角色,所以需要新建关联表
+
+```sql
+-- 空间成员表
+create table if not exists space_user
+(
+ id bigint auto_increment comment 'id' primary key,
+ spaceId bigint not null comment '空间 id',
+ userId bigint not null comment '用户 id',
+ spaceRole varchar(128) default 'viewer' null comment '空间角色:viewer/editor/admin',
+ createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
+ updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
+ -- 索引设计
+ UNIQUE KEY uk_spaceId_userId (spaceId, userId), -- 唯一索引,用户在一个空间中只能有一个角色
+ INDEX idx_spaceId (spaceId), -- 提升按空间查询的性能
+ INDEX idx_userId (userId) -- 提升按用户查询的性能
+) comment '空间用户关联' collate = utf8mb4_unicode_ci;
+```
+
+
+
+
+
+
+
### RBAC模型
团队空间:
@@ -303,6 +376,246 @@ RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限
+### Sa-Token
+
+#### 快速入门
+
+1)引入:
+
+```xml
+
+
+ cn.dev33
+ sa-token-spring-boot-starter
+ 1.39.0
+
+```
+
+2)让 `Sa-Token` 整合 `Redis`,将用户的登录态等内容保存在` Redis` 中。
+
+```xml
+
+
+ cn.dev33
+ sa-token-redis-jackson
+ 1.39.0
+
+
+
+ org.apache.commons
+ commons-pool2
+
+```
+
+3)基本用法
+
+`StpUtil` 是 Sa-Token 提供的全局静态工具。
+
+用户登录时调用 `login `方法,产生一个新的会话:
+
+```java
+StpUtil.login(10001);
+```
+
+还可以给会话保存一些信息,比如登录用户的信息:
+
+```java
+StpUtil.getSession().set("user", user)
+```
+
+接下来就可以判断用户是否登录、获取用户信息了,可以通过代码进行判断:
+
+```java
+// 检验当前会话是否已经登录, 如果未登录,则抛出异常:`NotLoginException`
+StpUtil.checkLogin();
+// 获取用户信息
+StpUtil.getSession().get("user");
+```
+
+也可以参考 [官方文档](https://sa-token.cc/doc.html#/use/at-check),使用注解进行鉴权:
+
+```java
+// 登录校验:只有登录之后才能进入该方法
+@SaCheckLogin
+@RequestMapping("info")
+public String info() {
+ return "查询用户信息";
+}
+```
+
+#### 多账号体系
+
+若项目中存在两套权限校验体系。一套是 user 表的,分为普通用户和管理员;另一套是对团队空间的权限进行校验。
+
+为了更轻松地扩展项目,减少对原有代码的改动,我们原有的 user 表权限校验依然使用自定义注解 + AOP 的方式实现。而团队空间权限校验,采用 Sa-Token 来管理。
+
+这种同一项目有多账号体系的情况下,不建议使用 Sa-Token 默认的账号体系,而是使用 Sa-Token 提供的多账号认证特性,可以将多套账号的授权给区分开,让它们互不干扰。
+
+使用 [Kit 模式](https://sa-token.cc/doc.html#/up/many-account?id=_5、kit模式) 实现多账号认证
+
+```java
+/**
+ * StpLogic 门面类,管理项目中所有的 StpLogic 账号体系
+ * 添加 @Component 注解的目的是确保静态属性 DEFAULT 和 SPACE 被初始化
+ */
+@Component
+public class StpKit {
+
+ public static final String SPACE_TYPE = "space";
+
+ /**
+ * 默认原生会话对象,项目中目前没使用到
+ */
+ public static final StpLogic DEFAULT = StpUtil.stpLogic;
+
+ /**
+ * Space 会话对象,管理 Space 表所有账号的登录、权限认证
+ */
+ public static final StpLogic SPACE = new StpLogic(SPACE_TYPE);
+}
+```
+
+修改用户服务的` userLogin` 方法,用户登录成功后,保存登录态到` Sa-Token` 的空间账号体系中:
+
+```java
+//记录用户的登录态
+request.getSession().setAttribute(USER_LOGIN_STATE, user);
+//记录用户登录态到 Sa-token,便于空间鉴权时使用,注意保证该用户信息与 SpringSession 中的信息过期时间一致
+StpKit.SPACE.login(user.getId());
+StpKit.SPACE.getSession().set(USER_LOGIN_STATE, user);
+return this.getLoginUserVO(user);
+```
+
+之后就可以在代码中使用账号体系
+
+```java
+// 检测当前会话是否以 Space 账号登录,并具有 picture:edit 权限
+StpKit.SPACE.checkPermission("picture:edit");
+
+// 获取当前 Space 会话的 Session 对象,并进行写值操作
+StpKit.SPACE.getSession().set("user", "zy123");
+```
+
+
+
+#### 权限认证逻辑
+
+`Sa-Token` 开发的核心是**编写权限认证类**,我们需要在该类中实现 “如何根据登录**用户 `id`** 获取到用户**已有的角色和权限列表**” 方法。当要判断某用户是否有某个角色或权限时,`Sa-Token` 会先执行我们编写的方法,得到该用户的角色或权限列表,然后跟需要的角色权限进行**比对**。
+
+参考 [官方文档](https://sa-token.cc/doc.html#/use/jur-auth),示例权限认证类如下:
+
+```java
+/**
+ * 自定义权限加载接口实现类
+ */
+@Component // 保证此类被 SpringBoot 扫描,完成 Sa-Token 的自定义权限验证扩展
+public class StpInterfaceImpl implements StpInterface {
+
+ /**
+ * 返回一个账号所拥有的权限码集合
+ */
+ @Override
+ public List getPermissionList(Object loginId, String loginType) {
+ // 本 list 仅做模拟,实际项目中要根据具体业务逻辑来查询权限
+ List list = new ArrayList();
+ list.add("user.add");
+ list.add("user.update");
+ list.add("user.get");
+ list.add("art.*");
+ return list;
+ }
+
+ /**
+ * 返回一个账号所拥有的角色标识集合 (权限与角色可分开校验)
+ */
+ @Override
+ public List getRoleList(Object loginId, String loginType) {
+ // 本 list 仅做模拟,实际项目中要根据具体业务逻辑来查询权限
+ List list = new ArrayList();
+ list.add("admin");
+ list.add("super-admin");
+ return list;
+ }
+}
+```
+
+`Sa-Token` 支持按照角色和权限校验,对于权限不多的项目,基于角色校验即可;对于权限较多的项目,建议根据权限校验。二选一即可,最好不要混用!
+
+
+
+关键问题:如何在 `Sa-Token `中获取当前请求操作的参数?
+
+使用 Sa-Token 有 2 种方式 —— **注解式和编程式** ,但**都要实现**上面的StpInterface接口。
+
+如果使用**注解式**,那么在接口被调用时就会立刻触发 Sa-Token 的权限校验,此时参数只能通过 Servlet 的**请求对象**传递,必须具有指定权限才能进入该方法!
+
+使用[ 注解合并](https://sa-token.cc/doc.html#/up/many-account?id=_7、使用注解合并简化代码) 简化代码。
+
+```java
+@SaSpaceCheckPermission(value = SpaceUserPermissionConstant.PICTURE_UPLOAD)
+public BaseResponse uploadPicture() {
+}
+```
+
+
+
+如果使用**编程式**,可以在函数内的任意位置执行权限校验,只要在执行前将参数放到当前线程的上下文 ThreadLocal 对象中,就能在鉴权时获取到了。
+
+**注意,只要加上了` Sa-Token` 注解,框架就会强制要求用户登录,未登录会抛出异常。**所以针对未登录也可以调用的接口,需要改为编程式权限校验
+
+```java
+@GetMapping("/get/vo")
+public BaseResponse getPictureVOById(long id, HttpServletRequest request) {
+ ThrowUtils.throwIf(id <= 0, ErrorCode.PARAMS_ERROR);
+ // 查询数据库
+ Picture picture = pictureService.getById(id);
+ ThrowUtils.throwIf(picture == null, ErrorCode.NOT_FOUND_ERROR);
+ // 空间的图片,需要校验权限
+ Space space = null;
+ Long spaceId = picture.getSpaceId();
+ if (spaceId != null) {
+ boolean hasPermission = StpKit.SPACE.hasPermission(SpaceUserPermissionConstant.PICTURE_VIEW);
+ ThrowUtils.throwIf(!hasPermission, ErrorCode.NO_AUTH_ERROR);
+ }
+ PictureVO pictureVO = pictureService.getPictureVO(picture, request);
+ // 获取封装类
+ return ResultUtils.success(pictureVO);
+}
+```
+
+
+
+### 循环依赖问题
+
+```text
+PictureController
+ ↓ 注入 PictureServiceImpl
+PictureServiceImpl
+ ↓ 注入 SpaceServiceImpl
+SpaceServiceImpl
+ ↓ 注入 SpaceUserServiceImpl
+SpaceUserServiceImpl
+ ↓ 注入 SpaceServiceImpl ←—— 又回到 SpaceServiceImpl
+```
+
+解决办法:将一方改成 setter 注入并加上 `@Lazy`注解
+
+如在`SpaceUserServiceImpl`中
+
+```java
+import org.springframework.context.annotation.Lazy;
+
+@Resource
+@Lazy
+private SpaceService spaceService;
+```
+
+@Lazy为懒加载,直到真正第一次使用它时才去创建或注入。且这里**不能用构造器注入**的方式!!!
+
+这里有个坑: `import groovy.lang.Lazy;` 导入这个包的@lazy注解就无效!
+
+
+
### 分库分表
如果某团队空间的图片数量比较多,可以对其数据进行单独的管理。
@@ -315,5 +628,262 @@ RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限
已经实现隔离,存到COS上的不同桶内。
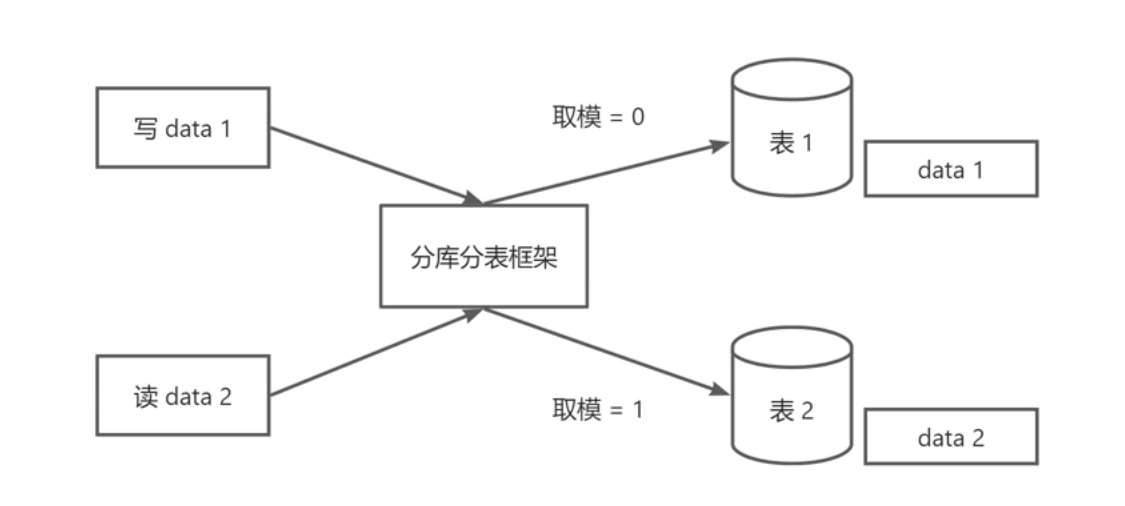
+
+
+思路主要是基于业务需求设计**数据分片规则**,将数据按一定策略(如取模、哈希、范围或时间)分散存储到多个库或表中,同时开发路由逻辑来决定查询或写入操作的目标库表。
+
+
+
+#### ShardingSphere 分库分表
+
+```xml
+
+
+ org.apache.shardingsphere
+ shardingsphere-jdbc-core-spring-boot-starter
+ 5.2.0
+
+```
+
+分库分表的策略总体分为 2 类:静态分表和动态分表
+
+#### 分库分表策略 - 静态分表
+
+静态分表:在设计阶段,分表的数量和规则就是固定的,不会根据业务增长动态调整,比如 picture_0、picture_1。
+
+分片规则通常基于某一字段(如图片 id)通过简单规则(如取模、范围)来决定数据存储在哪个表或库中。
+
+这种方式的优点是简单、好理解;缺点是不利于扩展,随着数据量增长,可能需要手动调整分表数量并迁移数据。
+
+举个例子,图片表按图片` id` 对 3 取模拆分:
+
+```java
+String tableName = "picture_" + (picture_id % 3) // picture_0 ~ picture_2
+```
+
+静态分表的实现很简单,直接在 `application.yml `中编写 `ShardingSphere` 的配置就能完成分库分表,比如:
+
+```yml
+rules:
+ sharding:
+ tables:
+ picture:
+ actualDataNodes: ds0.picture_${0..2} # 3张分表:picture_0, picture_1, picture_2
+ tableStrategy:
+ standard:
+ shardingColumn: picture_id # 按 pictureId 分片
+ shardingAlgorithmName: pictureIdMod
+ shardingAlgorithms:
+ pictureIdMod:
+ type: INLINE #内置实现,直接在配置类中写规则,即下面的algorithm-expression
+ props:
+ algorithm-expression: picture_${pictureId % 3} # 分片表达式
+```
+
+甚至不需要修改任何业务代码,在查询`picture`表(一般叫逻辑表)时,框架会自动帮你修改 `SQL`,根据 `pictureId `将查询请求路由到不同的表中。
+
+
+
+#### 分库分表策略 - 动态分表
+
+动态分表是指分表的数量可以根据业务需求或数据量动态增加,表的结构和规则是运行时动态生成的。举个例子,根据时间动态创建 `picture_2025_03、picture_2025_04`。
+
+```java
+String tableName = "picture_" + LocalDate.now().format(
+ DateTimeFormatter.ofPattern("yyyy_MM")
+);
+```
+
+```yml
+spring:
+ shardingsphere:
+ datasource:
+ names: smile-picture
+ smile-picture:
+ type: com.zaxxer.hikari.HikariDataSource
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ url: jdbc:mysql://localhost:3306/smile-picture
+ username: root
+ password: 123456
+ rules:
+ sharding:
+ tables:
+ picture: #逻辑表名(业务层永远只写 picture)
+ actual-data-nodes: smile-picture.picture # 逻辑表对应的真实节点
+ table-strategy:
+ standard:
+ sharding-column: space_id #分片列(字段)
+ sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法
+ sharding-algorithms:
+ picture_sharding_algorithm:
+ type: CLASS_BASED
+ props:
+ strategy: standard
+ algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm
+ props:
+ sql-show: true
+```
+
+**需要实现自定义算法类:**
+
+```java
+public class PictureShardingAlgorithm implements StandardShardingAlgorithm {
+
+ @Override
+ public String doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue) {
+ // 编写分表逻辑,返回实际要查询的表名
+ // picture_0 物理表,picture 逻辑表
+ }
+
+ @Override
+ public Collection doSharding(Collection collection, RangeShardingValue rangeShardingValue) {
+ return new ArrayList<>();
+ }
+
+ @Override
+ public Properties getProps() {
+ return null;
+ }
+
+ @Override
+ public void init(Properties properties) {
+
+ }
+}
+```
+
+
+
+#### **本项目分表总体思路:**
+
+对 `picture` 进行分表
+
+**一张 逻辑表 `picture`**
+
+- 业务代码永远只写 `picture`,不用关心落到哪张真实表。
+
+**两类真实表**
+
+| 类型 | 存谁的数据 | 例子 |
+| ---------- | ----------------------------- | --------------------------------------- |
+| **公共表** | 普通 / 进阶 / 专业版空间 | `picture` |
+| **分片表** | *旗舰版* 空间(每个空间一张) | `picture_`,如 `picture_30001` |
+
+**自定义分片算法**:
+
+- 传入 space_id 时
+
+ - 如果是旗舰,会自动路由到 `picture_`;否则回落到公共表 `picture`。
+
+- 没有 space_id 时
+
+ (例如后台批量报表):
+
+ - 广播到 **所有** `picture_` + `picture` 并做汇聚。
+
+
+
+| 操作 | **必须**带分片键? | 若缺少分片键会发生什么 |
+| ---------- | ------------------ | ------------------------------------------------------------ |
+| **INSERT** | **是** | - 中间件不知道该落到哪张实际表- **直接抛异常**:`Could not determine actual data nodes` / `Table xxx route result is empty` |
+| **UPDATE** | **强烈建议** | - ShardingSphere 会把 SQL **广播到所有分表** ,再分别执行- 表越多、数据越大,锁持有时间越长,性能急剧下降- 若所有表都无匹配行,会返回 0,但成本已付出 |
+| **DELETE** | 同上 | 同 UPDATE,且更危险:一次误写可能删光全部分表的数据 |
+| **SELECT** | 同上 | 没分片键就会全表扫描后聚合,数据量大时查询极慢、内存占用高 |
+
+因此,项目中的业务代码中,对Picture表进行增删查改时,必须确保space_id非空。
+
+
+
+### 协同编辑
+
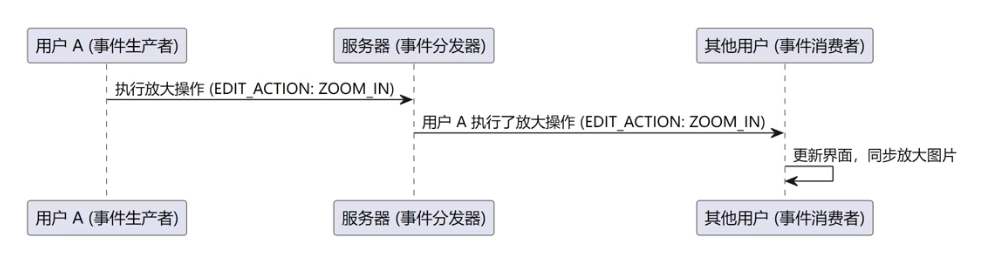
+
+
+相比于生产者直接调用消费者,事件驱动模型的主要优点在于**解耦和异步性**。在事件驱动模型中,生产者和消费者不需要直接依赖于彼此的实现,生产者只需触发事件并将其发送到事件分发器,消费者则根据事件类型处理逻辑。此外,事件驱动还可以**提升系统的 并发性 和 实时性**,可以理解为多引入了一个中介来帮忙,通过异步消息传递,**减少了阻塞和等待**,能够更高效地处理多个并发任务。
+
+#### **如何解决协同冲突?**
+
+法一:约定 **同一时刻只允许一位用户进入编辑图片的状态**,此时其他用户只能实时浏览到修改效果,但不能参与编辑;进入编辑状态的用户可以退出编辑,其他用户才可以进入编辑状态。
+
+| 事件触发者(用户 A 的动作) | 事件类型(发送消息) | 事件消费者(其他用户的处理) |
+| --------------------------- | -------------------- | --------------------------------------------------- |
+| 用户 A 建立连接,加入编辑 | INFO | 显示"用户 A 加入编辑"的通知 |
+| 用户 A 进入编辑状态 | ENTER_EDIT | 其他用户界面显示"用户 A 开始编辑图片",锁定编辑状态 |
+| 用户 A 执行编辑操作 | EDIT_ACTION | 放大/缩小/左旋/右旋当前图片 |
+| 用户 A 退出编辑状态 | EXIT_EDIT | 解锁编辑状态,提示其他用户可以进入编辑状态 |
+| 用户 A 断开连接,离开编辑 | INFO | 显示"用户 A 离开编辑"的通知,并释放编辑状态 |
+| 用户 A 发送了错误的消息 | ERROR | 显示错误消息的通知 |
+
+法二:实时协同 `OT `算法(`Operational Transformation`),广泛应用于在线文档协作等场景。
+
+**操作** (Operation):表示用户对协作内容的修改,比如插入字符、删除字符等。
+
+**转化 (Transformation)**:当多个用户同时编辑内容时,OT 会根据操作的上下文将它们转化,使得这些操作可以按照不同的顺序应用而结果保持一致。
+
+**因果一致性**:OT 算法确保操作按照用户看到的顺序被正确执行,即每个用户的操作基于最新的内容状态。
+
+**举一个简单的例子**,假设初始内容是 "abc",用户 A 和 B 同时进行编辑:
+
+用户 A 在位置 1 插入 "x"
+
+用户 B 在位置 2 删除 "b" 如果不使用 OT 算法,结果是:
+
+用户 A 操作后,内容变为 "axbc"
+
+用户 B 操作后,内容变为 "ac" 如果直接应用 B 的操作到 A 的结果,得到的是 "ac",对于 A 来说,相当于删除了 "b",A 会感到一脸懵逼。
+
+如果使用 `OT` 算法,结果是:
+
+1. 用户 A 的操作,应用后内容为 "axbc"
+2. 用户 B 的操作经过 OT 转化为删除 "b" 在 "axbc" 中的新位置 最终用户 `A` 和 `B` 的内容都一致为 "axc",符合预期。`OT` 算法确保无论用户编辑的顺序如何,**最终内容是一致的**。
+
+`OT `算法的难点在于设计如何转化各个用户的操作。
+
+
+
+#### 业务流程图
+
+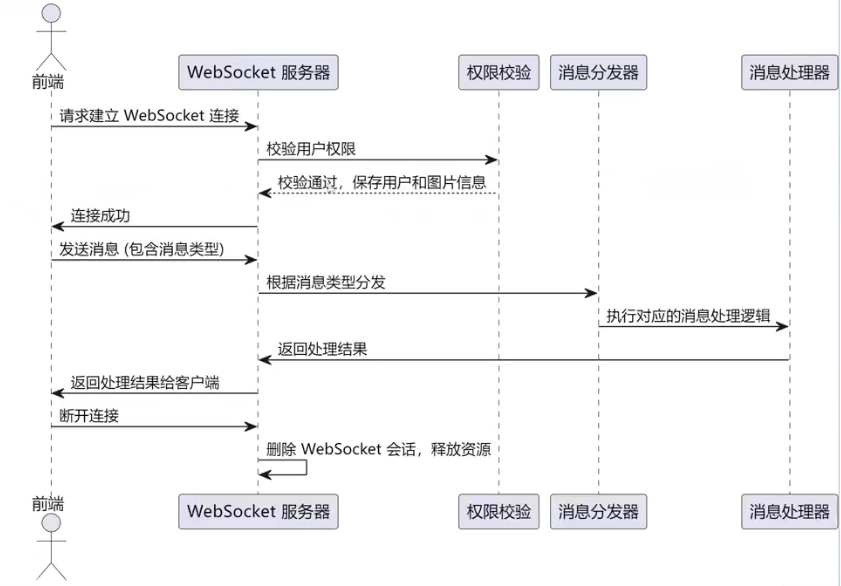
+
+```java
+// key: pictureId,value: 这张图下所有活跃的 Session(即各个用户的连接)
+Map> pictureSessions;
+```
+
+当用户 A 在浏览器里打开了 pictureId=123 的编辑页面,就产生了一个 Session;
+如果同一个浏览器又开了一个标签页编辑同一张图,或者不同的浏览器/设备打开,同样又会分别产生新的 Session。
+
+假设有两张图,ID 是 100 和 200:
+
+| pictureId | pictureSessions.get(pictureId) |
+| --------- | ------------------------------------------- |
+| 100 | { sessionA, sessionB } (用户 A、B 的连接) |
+| 200 | { sessionC } (只有用户 C 的连接) |
+
+
+
+### Disruptor 优化
+
+调用 `Spring MVC `的某个接口时,如果该接口内部的耗时较长,请求线程就会一直阻塞,最终导致` Tomcat` 请求连接数耗尽(默认值 **200**)。
+
+大多数请求是快请求,毫秒级别,直接在请求线程里完成;若有个慢请求,执行一次需要几秒,那么必须将它放入异步线程中执行。
+
+`Disruptor` 是一种高性能的并发框架,它是一种 **无锁的环形队列** 数据结构,用于解决高吞吐量和低延迟场景中的并发问题。
+
+Disruptor 的工作流程:
+
+1)环形队列初始化:创建一个固定大小为 8 的 RingBuffer(索引范围 0-7),每个格子存储一个可复用的事件对象,序号初始为 0。
+
+2)生产者写入数据:生产者申请索引 0(序号 0),将数据 "A" 写入事件对象,提交后序号递增为 1,下一个写入索引变为 1。
+
+3)消费者读取数据:消费者检查索引 0(序号 0),读取数据 "A",处理后提交,序号递增为 1,下一个读取索引变为 1。
+
+4)环形队列循环使用:当生产者写入到索引 7(序号 7)后,索引回到 0(序号 8),形成循环存储,但序号会持续自增以区分数据的先后顺序。
+
+5)防止数据覆盖:如果生产者追上消费者,消费者尚未处理完数据,生产者会等待,确保数据不被覆盖。
+
+
+
+基于 `Disruptor` 的异步消息处理机制,可以将原有的同步消息分发逻辑改造为高效解耦的异步处理模型。因为websockt接收到请求,直接往队列里面提交任务,Disruptor的消费者来负责按顺序进行处理。
+
diff --git a/自学/苍穹外卖.md b/自学/苍穹外卖.md
index abd0155..c7621a6 100644
--- a/自学/苍穹外卖.md
+++ b/自学/苍穹外卖.md
@@ -2126,6 +2126,12 @@ http://localhost:8080/ws/12345
3). 导入WebSocket服务端组件WebSocketServer,用于和客户端通信(比较固定,建立连接、接收消息、关闭连接、发送消息)
+基于 **JSR-356(Java WebSocket API)** 的“注解型”实现
+
+`@ServerEndpoint("/ws/{sid}")` 来声明一个 WebSocket 端点,容器(如 Tomcat/Jetty)或 Spring 的 `ServerEndpointExporter` 会扫描并注册它。
+
+`@OnOpen`、`@OnMessage`、`@OnClose`、`@OnError` 等标注的方法,分别对应连接建立、收到消息、连接关闭和出错时的回调。
+
```java
/**
* WebSocket服务
diff --git a/自学/草稿.md b/自学/草稿.md
index 752d64f..227d799 100644
--- a/自学/草稿.md
+++ b/自学/草稿.md
@@ -1,44 +1,159 @@
-主要区别在于它们的**用途**和**能执行的操作**不同:
+### 一、策略模式 (Strategy)
-| 特性 | `lambdaQuery()` | `lambdaUpdate()` |
-| -------------- | --------------------------------------------------------- | --------------------------------------------------------- |
-| **主要用途** | 构造查询条件,执行 `SELECT` 操作 | 构造更新条件,执行 `UPDATE`(或逻辑删除)操作 |
-| **返回类型** | `LambdaQueryChainWrapper` 或 `LambdaQueryWrapper` | `LambdaUpdateChainWrapper` 或 `LambdaUpdateWrapper` |
-| **支持的方法** | `.eq()`, `.like()`, `.gt()`, `.orderBy()`, `.select()` 等 | `.eq()`, `.lt()`, `.set()`, `.setSql()` 等 |
-| **执行方法** | `.list()`, `.one()`, `.page()` 等 | `.update()`, `.remove()`(逻辑删除) |
+**核心思想**:
+ 把可互换的算法/行为抽成独立策略类,运行时由“上下文”对象选择合适的策略;对调用方来说,只关心统一接口,而非具体实现。
+
+```
+┌───────────────┐
+│ Client │
+└─────▲─────────┘
+ │ has-a
+┌─────┴─────────┐ implements
+│ Context │────────────┐ ┌──────────────┐
+│ (使用者) │ strategy └─▶│ Strategy A │
+└───────────────┘ ├──────────────┤
+ │ Strategy B │
+ └──────────────┘
+```
+
+#### Demo:支付策略(Java)
+
+```java
+// 1. 抽象策略
+public interface PayStrategy {
+ void pay(int cents);
+}
+
+// 2. 具体策略
+public class AliPay implements PayStrategy {
+ public void pay(int cents) { System.out.println("Alipay ¥" + cents / 100.0); }
+}
+public class WxPay implements PayStrategy {
+ public void pay(int cents) { System.out.println("WeChat Pay ¥" + cents / 100.0); }
+}
+
+// 3. 上下文
+public class PaymentService {
+ private final PayStrategy strategy;
+ public PaymentService(PayStrategy strategy) { this.strategy = strategy; }
+ public void checkout(int cents) { strategy.pay(cents); }
+}
+
+// 4. 运行时选择策略
+public class Demo {
+ public static void main(String[] args) {
+ PaymentService ps1 = new PaymentService(new AliPay());
+ ps1.checkout(2599); // Alipay ¥25.99
+
+ PaymentService ps2 = new PaymentService(new WxPay());
+ ps2.checkout(4999); // WeChat Pay ¥49.99
+ }
+}
+```
+
+**要点**
+
+- **开放封闭**:新增 PayPal 只需实现 `PayStrategy`,无须改 `PaymentService`。
+- **运行期切换**:可根据配置、用户偏好等动态注入不同策略。
------
-### 举例对比
+### 二、模板方法模式 (Template Method)
-1. **查询:`lambdaQuery()`**
+**核心思想**:
+ 在抽象父类中定义**算法骨架**(固定执行顺序),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。
- ```java
- // 查出状态为 1,名字中含 “张”,并按年龄降序的前 10 条用户
- List list = userService.lambdaQuery()
- .eq(User::getStatus, 1)
- .like(User::getName, "张")
- .orderByDesc(User::getAge)
- .last("LIMIT 10")
- .list();
- ```
+```
+ Client ───▶ AbstractClass
+ ├─ templateMethod() ←—— 固定流程
+ │ step1()
+ │ step2() ←—— 抽象,可变
+ │ step3()
+ └─ hookMethod() ←—— 可选覆盖
+ ▲
+ │ extends
+ ┌──────────┴──────────┐
+ │ ConcreteClassA/B… │
+```
-2. **更新:`lambdaUpdate()`**
+#### Demo:弹窗加载流程(Java)
- ```java
- // 把状态为 0,且注册时间超过两年的用户标记为状态 2
- boolean ok = userService.lambdaUpdate()
- .eq(User::getStatus, 0)
- .lt(User::getRegisterTime, LocalDate.now().minusYears(2))
- .set(User::getStatus, 2)
- .update();
- ```
+```java
+// 1. 抽象模板
+public abstract class AbstractDialog {
+
+ // 模板方法:固定调用顺序,设为 final 防止子类改流程
+ public final void show() {
+ initLayout();
+ bindEvent();
+ beforeDisplay(); // 钩子,可选
+ display();
+ afterDisplay(); // 钩子,可选
+ }
+
+ // 具体公共步骤
+ private void initLayout() {
+ System.out.println("加载通用布局文件");
+ }
+
+ // 需要子类实现的抽象步骤
+ protected abstract void bindEvent();
+
+ // 钩子方法,默认空实现
+ protected void beforeDisplay() {}
+ protected void afterDisplay() {}
+
+ private void display() {
+ System.out.println("弹出对话框");
+ }
+}
+
+// 2. 子类:登录对话框
+public class LoginDialog extends AbstractDialog {
+ @Override
+ protected void bindEvent() {
+ System.out.println("绑定登录按钮事件");
+ }
+ @Override
+ protected void afterDisplay() {
+ System.out.println("focus 到用户名输入框");
+ }
+}
+
+// 3. 调用
+public class Demo {
+ public static void main(String[] args) {
+ AbstractDialog dialog = new LoginDialog();
+ dialog.show();
+ /* 输出:
+ 加载通用布局文件
+ 绑定登录按钮事件
+ 弹出对话框
+ focus 到用户名输入框
+ */
+ }
+}
+```
+
+**要点**
+
+- **复用公共流程**:`initLayout()`、`display()` 写一次即可。
+- **限制流程顺序**:`show()` 定为 `final`,防止子类乱改步骤。
+- **钩子方法**:子类可选择性覆盖(如 `beforeDisplay`)。
------
-#### 小结
+### 关键区别 & 组合用法
-- 用 `lambdaQuery()` 构造查询条件,只做 **读** 操作。
-- 用 `lambdaUpdate()` 构造更新条件,结合 `.set()` 指定要修改的字段,做 **改**(或 “逻辑删”)操作。
+| | **策略模式** | **模板方法模式** |
+| ---------------- | ---------------------------------- | ---------------------------------------- |
+| **目的** | **横向**扩展——允许算法**并列互换** | **纵向**复用——抽取算法**骨架**,固定顺序 |
+| **实现方式** | 组合 + 接口 | 继承 + 抽象父类 |
+| **行为选择时机** | 运行时由外部注入 | 编译期由继承确定 |
+| **常组合** | 与 **工厂模式**配合选择策略 | 与 **钩子方法**、**回调**一起用 |
-它们都是为了解决写 SQL 时硬编码字段名的问题,通过 `User::getXxx` 方法引用,保证 **类型安全**、**重构无忧**。
\ No newline at end of file
+在实际项目中,两者经常**组合**:
+
+> 折扣计算 **Strategy** → 公共过滤 & 日志 **Template Method** → Spring 容器负责策略注册/发现。
+
+这样即可同时获得“纵向流程复用”+“横向算法可插拔”的双重优势。