Commit on 2025/04/17 周四 18:55:50.30
This commit is contained in:
parent
09893030df
commit
46f7212b9d
@ -60,7 +60,7 @@ Docker是一个CS架构的程序,由两部分组成:
|
||||
|
||||
1. docker push,将本地镜像上传到远程仓库(例如 Docker Hub)
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker login #docker hub登录
|
||||
# 假设已有本地镜像 myimage,需要先打上标签:
|
||||
docker tag myimage yourusername/myimage:latest
|
||||
@ -70,34 +70,40 @@ docker push yourusername/myimage:latest
|
||||
|
||||
2. docker pull ,从远程仓库拉取镜像到本地。
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker pull yourusername/myimage:latest
|
||||
```
|
||||
|
||||
3. docker save,将本地镜像保存为 tar 文件,方便备份或传输
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker save -o myimage.tar yourusername/myimage:latest
|
||||
```
|
||||
|
||||
4. docker load,从 tar 文件中加载镜像到本地 Docker。
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker load -i myimage.tar
|
||||
```
|
||||
|
||||
5. docker images ,查看本地镜像
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker images
|
||||
```
|
||||
|
||||
6. docker build ,构建镜像 -t后面跟镜像名
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker build -t yourusername/myimage:latest .
|
||||
```
|
||||
|
||||
7. 清理悬空、无名镜像
|
||||
|
||||
```shell
|
||||
docker image prune
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 容器操作
|
||||
@ -855,33 +861,39 @@ build: ./web_app #两种写法是等效的
|
||||
|
||||
**构建镜像:**这个命令根据 docker-compose.yml 中各服务的配置构建镜像。如果你修改了 Dockerfile 或者项目代码需要打包进镜像时,就需要运行该命令来构建新的镜像。
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose build
|
||||
```
|
||||
|
||||
**启动容器:**这个命令用于启动服务,参数 `-d` 表示以后台守护进程的方式运行。如果镜像不存在,它会自动构建镜像;但如果镜像已经存在,则默认直接使用现有的镜像启动容器。
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
**进入容器:**
|
||||
|
||||
```shell
|
||||
docker compose exec -it filebrowser sh
|
||||
```
|
||||
|
||||
注意!一般进入数据卷挂载,直接在宿主机上操作容器内部就可以了!!!!!
|
||||
|
||||
**只针对 pyapp 服务进行重构和启动,不影响其他服务运行**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose build pyapp
|
||||
```
|
||||
|
||||
启动容器并进入bash
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker compose run --rm -it pyapp /bin/bash
|
||||
```
|
||||
|
||||
运行脚本
|
||||
|
||||
```text
|
||||
```shell
|
||||
python typecho_markdown_upload/main.py
|
||||
```
|
||||
|
||||
@ -889,7 +901,7 @@ python typecho_markdown_upload/main.py
|
||||
|
||||
**更新并重启容器**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose up --build -d
|
||||
```
|
||||
|
||||
@ -901,40 +913,40 @@ docker-compose up --build -d
|
||||
|
||||
**查看服务的日志输出**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose logs flask_app --since 1h #只显示最近 1 小时
|
||||
```
|
||||
|
||||
**停止并删除所有由 docker-compose 启动的容器、网络等(默认不影响挂载卷)。**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose down #不能单独指定
|
||||
```
|
||||
|
||||
**删除停止的容器**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose rm
|
||||
docker-compose rm flask_app
|
||||
```
|
||||
|
||||
**停止运行的容器**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose stop
|
||||
docker-compose stop flask_app #指定某个服务
|
||||
```
|
||||
|
||||
**启动服务**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose start #启动所有停止的..
|
||||
docker-compose start flask_app
|
||||
```
|
||||
|
||||
**重启服务(停止+启动)**
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose restart
|
||||
docker-compose restart flask_app #指定某个服务
|
||||
```
|
||||
@ -953,7 +965,7 @@ docker-compose up生成的容器名默认是 `项目名_服务名_索引号`
|
||||
|
||||
如
|
||||
|
||||
```text
|
||||
```shell
|
||||
docker-compose -p my_custom_project up -d
|
||||
```
|
||||
|
||||
|
||||
@ -43,251 +43,6 @@ Edit Configurations
|
||||
|
||||
|
||||
|
||||
## Maven
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Maven仓库分为:
|
||||
|
||||
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
|
||||
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
|
||||
- 远程仓库(私服):一般由公司团队搭建的私有仓库
|
||||
|
||||
POM文件导入依赖的时候,先看本地仓库有没有,没有就看私服,再没有就从中央仓库下载。
|
||||
|
||||
|
||||
|
||||
### Maven创建/导入项目
|
||||
|
||||
**创建Maven项目**
|
||||
|
||||

|
||||
|
||||
勾选 **Create from archetype**(可选),也可以选择 **maven-archetype-quickstart** 等模版。
|
||||
|
||||
点击 Next,填写 GAV 坐标 。
|
||||
|
||||
GroupId:标识组织或公司(通常使用域名反写,如 `com.example`)
|
||||
|
||||
ArtifactId:标识具体项目或模块(如 `my-app`、`spring-boot-starter-web`)。
|
||||
|
||||
Version:标识版本号(如 `1.0-SNAPSHOT`、`2.7.3`)
|
||||
|
||||
|
||||
|
||||
**导入Maven项目**
|
||||
|
||||
**(一)单独的Maven项目**
|
||||
|
||||
打开 IDEA,在主界面选择 Open(或者在菜单栏选择 File -> Open)。
|
||||
|
||||
在文件选择对话框中,定位到已有项目的根目录(包含 `pom.xml` 的目录)。
|
||||
|
||||
选择该目录后,IDEA 会检测到 `pom.xml` 并询问是否导入为 Maven 项目,点击 **OK** 或 **Import** 即可。
|
||||
|
||||
IDEA 会自动解析 `pom.xml`,下载依赖并构建项目结构。
|
||||
|
||||
|
||||
|
||||
**(二)在现有Maven项目中导入独立的Maven项目**
|
||||
|
||||
在已经打开的 IDEA 窗口中,使用 **File -> New -> Module from Existing Sources...**
|
||||
|
||||
选择待导入项目的根目录(其中包含 `pom.xml`),IDEA 会将其导入为同一个工程下的另一个模块(Module)。
|
||||
|
||||
它们 看起来在一个工程里了,但**仍然是两个独立的** Maven 模块。
|
||||
|
||||
|
||||
|
||||
**(三)两个模块有较强的关联**
|
||||
|
||||
1.新建一个上层目录,如下,MyProject1和MyProject2的内容拷贝过去。
|
||||
|
||||
```java
|
||||
ParentProject/
|
||||
├── pom.xml <-- 父模块(聚合模块)
|
||||
├── MyProject1/ <-- 子模块1
|
||||
│ └── pom.xml
|
||||
└── MyProject2/ <-- 子模块2
|
||||
└── pom.xml
|
||||
```
|
||||
|
||||
2.创建父级pom
|
||||
|
||||
父模块 `pom.xml` 示例:
|
||||
|
||||
```java
|
||||
<project>
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>ParentProject</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
<packaging>pom</packaging> //必写
|
||||
|
||||
<modules>
|
||||
<module>MyProject1</module> //必写
|
||||
<module>MyProject2</module>
|
||||
</modules>
|
||||
</project>
|
||||
|
||||
```
|
||||
|
||||
3.修改子模块 `pom.xml` ,加上:
|
||||
|
||||
```java
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>ParentProject</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
<relativePath>../pom.xml</relativePath> <!-- 可省略 -->
|
||||
</parent>
|
||||
```
|
||||
|
||||
如果子模块中无需与父级不同的配置,**可以不写**,就自动继承父级配置;若写了同名配置,则表示你想要**覆盖或合并**父级配置。
|
||||
|
||||
4.File -> Open选择父级的pom,会自动导入其下面两个项目。
|
||||
|
||||
|
||||
|
||||
**(四)通过 Maven 依赖引用(一般导入官方依赖)**
|
||||
|
||||
如果你的两个项目之间存在依赖关系(例如,第二个项目需要引用第一个项目打包后的 JAR),可以采用以下方式:
|
||||
|
||||
在第一个项目(被依赖项目)执行 `mvn install`
|
||||
|
||||
- 这会把打包后的产物安装到本地仓库(默认 `~/.m2/repository`)。
|
||||
|
||||
在第二个项目的 `pom.xml` 中添加依赖坐标
|
||||
|
||||
```java
|
||||
<dependency>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>my-first-project</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
</dependency>
|
||||
|
||||
```
|
||||
|
||||
Maven 重建
|
||||
|
||||
|
||||
|
||||
### Maven坐标
|
||||
|
||||
什么是坐标?
|
||||
|
||||
* Maven中的坐标是 == 资源的唯一标识 == 通过该坐标可以唯一定位资源位置
|
||||
* 使用坐标来定义项目或引入项目中需要的依赖
|
||||
|
||||
|
||||
|
||||
### 依赖管理
|
||||
|
||||
可以到mvn的中央仓库(https://mvnrepository.com/)中搜索获取依赖的坐标信息
|
||||
|
||||
```java
|
||||
<dependencies>
|
||||
<!-- 第1个依赖 : logback -->
|
||||
<dependency>
|
||||
<groupId>ch.qos.logback</groupId>
|
||||
<artifactId>logback-classic</artifactId>
|
||||
<version>1.2.11</version>
|
||||
</dependency>
|
||||
<!-- 第2个依赖 : junit -->
|
||||
<dependency>
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
<version>4.12</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
更改之后可以在界面上看到一个maven刷新按钮,点击一下就开始联网下载依赖了,成功后可以看到
|
||||
|
||||
|
||||
|
||||
#### 排除依赖
|
||||
|
||||
A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被排除的资源**无需指定版本**。
|
||||
|
||||
```java
|
||||
<dependency>
|
||||
<groupId>com.itheima</groupId>
|
||||
<artifactId>maven-projectB</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
|
||||
<!--排除依赖, 主动断开依赖的资源-->
|
||||
<exclusions>
|
||||
<exclusion>
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
</exclusion>
|
||||
</exclusions>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
#### 依赖范围
|
||||
|
||||
| **scope**值 | **主程序** | **测试程序** | **打包(运行)** | **范例** |
|
||||
| --------------- | ---------- | ------------ | ---------------- | ----------- |
|
||||
| compile(默认) | Y | Y | Y | log4j |
|
||||
| test | - | Y | - | junit |
|
||||
| provided | Y | Y | - | servlet-api |
|
||||
| runtime | - | Y | Y | jdbc驱动 |
|
||||
|
||||
注意!!!这里的scope如果是`test`,那么它的作用范围在`src/test/java`下,在`src/main/java`下无法导包!
|
||||
|
||||
|
||||
|
||||
### Maven生命周期
|
||||
|
||||
主要关注以下几个:
|
||||
|
||||
• clean:移除上一次构建生成的文件 (Target文件夹)
|
||||
|
||||
• compile:编译 `src/main/java` 中的 Java 源文件至 `target/classes`
|
||||
|
||||
• test:使用合适的单元测试框架运行测试(junit)
|
||||
|
||||
• package:将编译后的文件打包,如:jar、war等
|
||||
|
||||
• install:将打包后的产物(如 `jar`)安装到本地仓库
|
||||
|
||||
#### 单元测试
|
||||
|
||||
1. 导入依赖junit
|
||||
|
||||
```java
|
||||
<dependency>
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
<version>4.12</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
2. 在src/test/java下创建DemoTest类(*Test)
|
||||
|
||||
3. 创建test方法
|
||||
|
||||
```java
|
||||
@Test
|
||||
public void test1(){
|
||||
System.out.println("hello1");
|
||||
}
|
||||
@Test
|
||||
public void test2(){
|
||||
System.out.println("hello2");
|
||||
}
|
||||
```
|
||||
|
||||
4. 双击test生命周期
|
||||
|
||||
|
||||
|
||||
## HTTP协议
|
||||
|
||||
### 响应状态码
|
||||
@ -319,8 +74,6 @@ A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被
|
||||
|
||||
## 开发规范
|
||||
|
||||
|
||||
|
||||
### REST风格
|
||||
|
||||
在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
|
||||
@ -1518,412 +1271,6 @@ public class SpringbootWebConfig2Application {
|
||||
|
||||
|
||||
|
||||
## Mybatis
|
||||
|
||||
### 快速创建
|
||||
|
||||
|
||||
|
||||
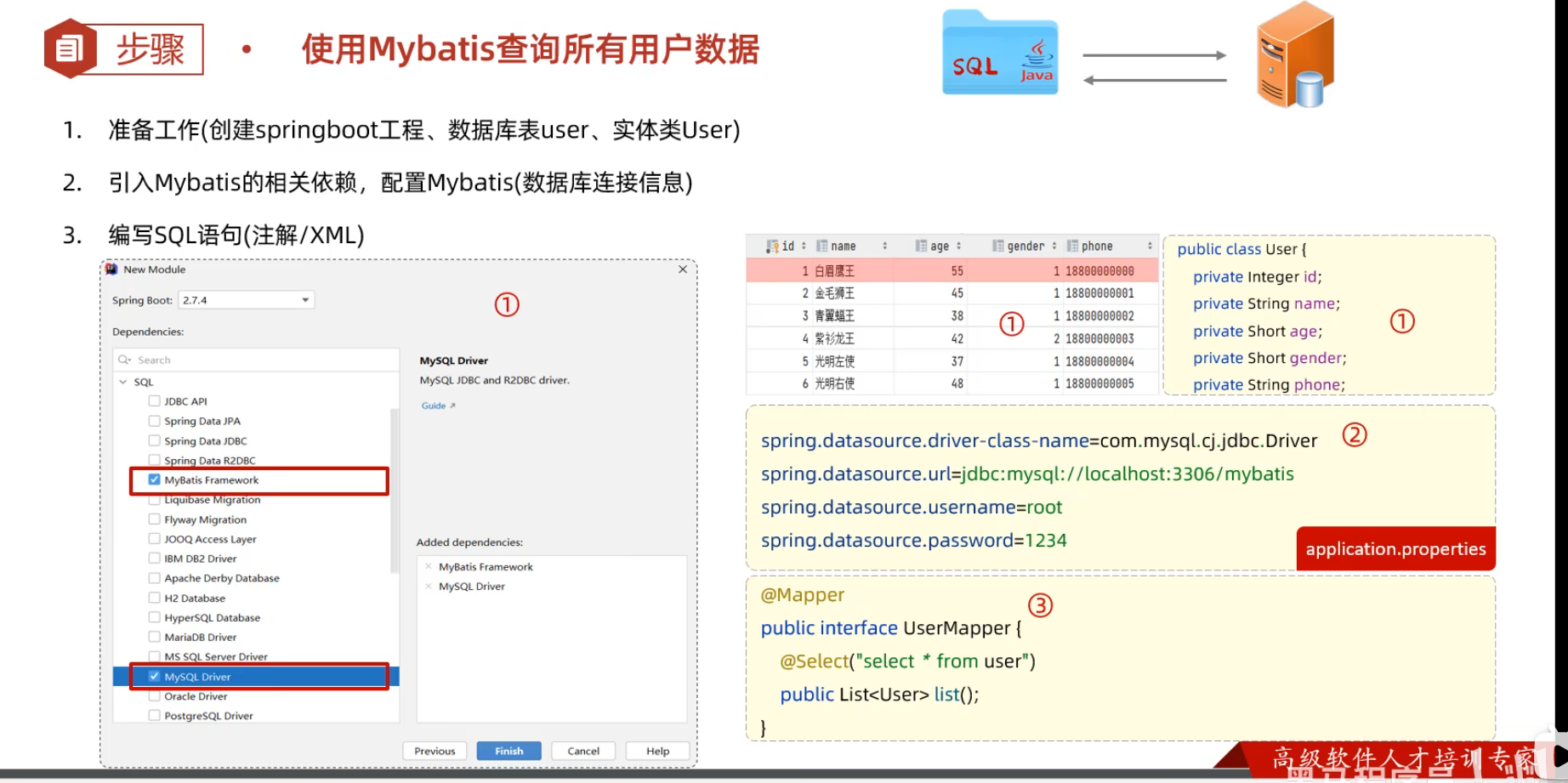
1. 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User
|
||||
|
||||
|
||||
2. 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。
|
||||
|
||||
```
|
||||
#驱动类名称
|
||||
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
|
||||
#数据库连接的url
|
||||
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
|
||||
#连接数据库的用户名
|
||||
spring.datasource.username=root
|
||||
#连接数据库的密码
|
||||
spring.datasource.password=1234
|
||||
```
|
||||
|
||||
3. 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper
|
||||
|
||||
|
||||
|
||||
@Mapper注解:表示是mybatis中的Mapper接口
|
||||
|
||||
-程序运行时:框架会自动生成接口的**实现类对象(代理对象)**,并交给Spring的IOC容器管理
|
||||
|
||||
@Select注解:代表的就是select查询,用于书写select查询语句
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface UserMapper {
|
||||
//查询所有用户数据
|
||||
@Select("select * from user")
|
||||
public List<User> list();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 数据库连接池
|
||||
|
||||
数据库连接池是一个容器,负责管理和分配数据库连接(`Connection`)。
|
||||
|
||||
- 在程序启动时,连接池会创建一定数量的数据库连接。
|
||||
- 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。
|
||||
- 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。
|
||||
|
||||
**优势**:避免频繁创建和销毁连接,提高数据库访问效率。
|
||||
|
||||
|
||||
|
||||
Druid(德鲁伊)
|
||||
|
||||
* Druid连接池是阿里巴巴开源的数据库连接池项目
|
||||
|
||||
* 功能强大,性能优秀,是Java语言最好的数据库连接池之一
|
||||
|
||||
把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池:
|
||||
|
||||
1. 在pom.xml文件中引入依赖
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<!-- Druid连接池依赖 -->
|
||||
<groupId>com.alibaba</groupId>
|
||||
<artifactId>druid-spring-boot-starter</artifactId>
|
||||
<version>1.2.8</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
2. 在application.properties中引入数据库连接配置
|
||||
|
||||
```properties
|
||||
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
|
||||
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis
|
||||
spring.datasource.druid.username=root
|
||||
spring.datasource.druid.password=123456
|
||||
```
|
||||
|
||||
|
||||
|
||||
### SQL注入问题
|
||||
|
||||
SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。
|
||||
|
||||
在Mybatis中提供的参数占位符有两种:${...} 、#{...}
|
||||
|
||||
- #{...}
|
||||
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
|
||||
- 使用时机:参数传递,都使用#{…}
|
||||
|
||||
- ${...}
|
||||
- 拼接SQL。直接将参数拼接在SQL语句中,**存在SQL注入问题**
|
||||
- 使用时机:如果对表名、列表进行动态设置时使用
|
||||
|
||||
|
||||
|
||||
### 日志输出
|
||||
|
||||
只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果
|
||||
|
||||
1. 打开application.properties文件
|
||||
|
||||
2. 开启mybatis的日志,并指定输出到控制台
|
||||
|
||||
```java
|
||||
#指定mybatis输出日志的位置, 输出控制台
|
||||
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 驼峰命名法
|
||||
|
||||
在 Java 项目中,数据库表字段名一般使用 **下划线命名法**(snake_case),而 Java 中的变量名使用 **驼峰命名法**(camelCase)。
|
||||
|
||||
- [x] **小驼峰命名(lowerCamelCase)**:
|
||||
|
||||
- 第一个单词的首字母小写,后续单词的首字母大写。
|
||||
- **例子**:`firstName`, `userName`, `myVariable`
|
||||
|
||||
**大驼峰命名(UpperCamelCase)**:
|
||||
|
||||
- 每个单词的首字母都大写,通常用于类名或类型名。
|
||||
- **例子**:`MyClass`, `EmployeeData`, `OrderDetails`
|
||||
|
||||
|
||||
|
||||
表中查询的数据封装到实体类中
|
||||
|
||||
- 实体类属性名和数据库表查询返回的**字段名一致**,mybatis会自动封装。
|
||||
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
|
||||
|
||||

|
||||
|
||||
解决方法:
|
||||
|
||||
1. 起别名
|
||||
2. 结果映射
|
||||
3. **开启驼峰命名**
|
||||
4. **属性名和表中字段名保持一致**
|
||||
|
||||
|
||||
|
||||
**开启驼峰命名(推荐)**:如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
|
||||
|
||||
> 驼峰命名规则: abc_xyz => abcXyz
|
||||
>
|
||||
> - 表中字段名:abc_xyz
|
||||
> - 类中属性名:abcXyz
|
||||
|
||||
|
||||
|
||||
### 推荐的完整配置:
|
||||
|
||||
```yaml
|
||||
mybatis:
|
||||
#mapper配置文件
|
||||
mapper-locations: classpath:mapper/*.xml
|
||||
type-aliases-package: com.sky.entity
|
||||
configuration:
|
||||
#开启驼峰命名
|
||||
map-underscore-to-camel-case: true
|
||||
```
|
||||
|
||||
`type-aliases-package: com.sky.entity`把 `com.sky.entity` 包下的所有类都当作别名注册,XML 里就可以直接写 `<resultType="Dish">` 而不用写全限定名。可以多添加几个包,用逗号隔开。
|
||||
|
||||
|
||||
|
||||
### 增删改
|
||||
|
||||
- **增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void!**
|
||||
|
||||
**作用于单个字段**
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//SQL语句中的id值不能写成固定数值,需要变为动态的数值
|
||||
//解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
|
||||
/**
|
||||
* 根据id删除数据
|
||||
* @param id 用户id
|
||||
*/
|
||||
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
|
||||
public void delete(Integer id);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
上图参数值分离,有效防止SQL注入
|
||||
|
||||
|
||||
|
||||
**作用于多个字段**
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//会自动将生成的主键值,赋值给emp对象的id属性
|
||||
@Options(useGeneratedKeys = true,keyProperty = "id")
|
||||
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
|
||||
public void insert(Emp emp);
|
||||
}
|
||||
```
|
||||
|
||||
在 **`@Insert`** 注解中使用 `#{}` 来引用 `Emp` 对象的属性,MyBatis 会自动从 `Emp` 对象中提取相应的字段并绑定到 SQL 语句中的占位符。
|
||||
|
||||
`@Options(useGeneratedKeys = true, keyProperty = "id")` 这行配置表示,插入时自动生成的主键会赋值给 `Emp` 对象的 `id` 属性。
|
||||
|
||||
```
|
||||
// 调用 mapper 执行插入操作
|
||||
empMapper.insert(emp);
|
||||
|
||||
// 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值
|
||||
System.out.println("Generated ID: " + emp.getId());
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 查
|
||||
|
||||
查询案例:
|
||||
|
||||
- **姓名:要求支持模糊匹配**
|
||||
- 性别:要求精确匹配
|
||||
- 入职时间:要求进行范围查询
|
||||
- 根据最后修改时间进行降序排序
|
||||
|
||||
重点在于模糊查询时where name like '%#{name}%' 会报错。
|
||||
|
||||
解决方案:
|
||||
|
||||
使用MySQL提供的字符串拼接函数:`concat('%' , '关键字' , '%')`
|
||||
|
||||
**`CONCAT()`** 如果其中任何一个参数为 **`NULL`**,`CONCAT()` 返回 **`NULL`**,`Like NULL`会导致查询不到任何结果!
|
||||
|
||||
`NULL`和`''`是完全不同的
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
|
||||
@Select("select * from emp " +
|
||||
"where name like concat('%',#{name},'%') " +
|
||||
"and gender = #{gender} " +
|
||||
"and entrydate between #{begin} and #{end} " +
|
||||
"order by update_time desc")
|
||||
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### XML配置文件规范
|
||||
|
||||
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
|
||||
|
||||
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
|
||||
|
||||
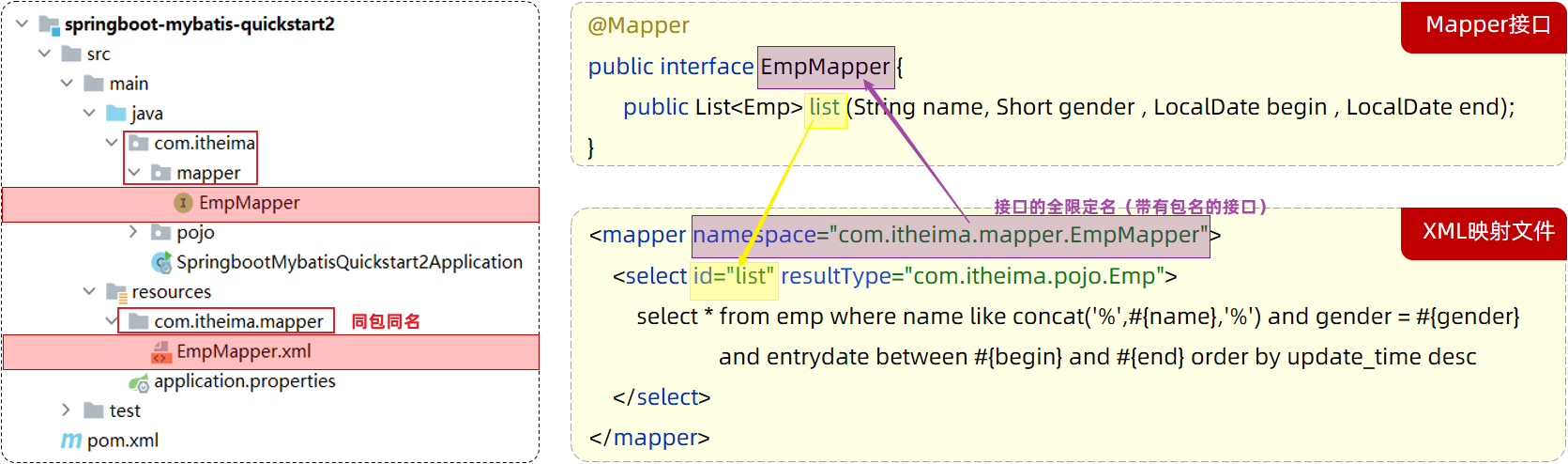
1. XML映射**文件的名称**与Mapper**接口名称**一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
|
||||
|
||||
2. XML映射文件的**namespace属性**为Mapper接口**全限定名**一致
|
||||
|
||||
3. XML映射文件中sql语句的**id**与Mapper接口中的**方法名**一致,并保持返回类型一致。
|
||||
|
||||
|
||||
|
||||
\<select>标签:就是用于编写select查询语句的。
|
||||
|
||||
resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。
|
||||
|
||||
parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 `Dish` 或 `DishPageQueryDTO`)自动推断),POJO作为入参,需要使用全类名或是`type‑aliases‑package: com.sky.entity` 下注册的别名。
|
||||
|
||||
```
|
||||
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
|
||||
<select id="pageQuery" resultType="com.sky.vo.DishVO">
|
||||
<select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish">
|
||||
```
|
||||
|
||||
|
||||
|
||||
**实现过程:**
|
||||
|
||||
1. resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
|
||||
|
||||
2. 配置Mapper文件
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8" ?>
|
||||
<!DOCTYPE mapper
|
||||
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
|
||||
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
|
||||
<mapper namespace="edu.whut.mapper.EmpMapper">
|
||||
<!-- SQL 查询语句写在这里 -->
|
||||
</mapper>
|
||||
```
|
||||
|
||||
`namespace` 属性指定了 **Mapper 接口的全限定名**(即包名 + 类名)。
|
||||
|
||||
3. 编写查询语句
|
||||
|
||||
```xml
|
||||
<select id="list" resultType="edu.whut.pojo.Emp">
|
||||
select * from emp
|
||||
where name like concat('%',#{name},'%')
|
||||
and gender = #{gender}
|
||||
and entrydate between #{begin} and #{end}
|
||||
order by update_time desc
|
||||
</select>
|
||||
```
|
||||
|
||||
**`id="list"`**:指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。
|
||||
|
||||
**`resultType="edu.whut.pojo.Emp"`**:`resultType` 只在 **查询操作** 中需要指定。指定查询结果映射的对象类型,这里是 `Emp` 类。
|
||||
|
||||
|
||||
|
||||
这里有bug!!!
|
||||
|
||||
`concat('%',#{name},'%')`这里应该用`<where>` `<if>`标签对name是否为`NULL`或`''`进行判断
|
||||
|
||||
|
||||
|
||||
### 动态SQL
|
||||
|
||||
#### SQL-if,where
|
||||
|
||||
`<if>`:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
|
||||
|
||||
~~~xml
|
||||
<if test="条件表达式">
|
||||
要拼接的sql语句
|
||||
</if>
|
||||
~~~
|
||||
|
||||
`<where>`只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,**加了总比不加好**
|
||||
|
||||
```java
|
||||
<select id="list" resultType="com.itheima.pojo.Emp">
|
||||
select * from emp
|
||||
<where>
|
||||
<!-- if做为where标签的子元素 -->
|
||||
<if test="name != null">
|
||||
and name like concat('%',#{name},'%')
|
||||
</if>
|
||||
<if test="gender != null">
|
||||
and gender = #{gender}
|
||||
</if>
|
||||
<if test="begin != null and end != null">
|
||||
and entrydate between #{begin} and #{end}
|
||||
</if>
|
||||
</where>
|
||||
order by update_time desc
|
||||
</select>
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### SQL-foreach
|
||||
|
||||
Mapper 接口
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//批量删除
|
||||
public void deleteByIds(List<Integer> ids);
|
||||
}
|
||||
```
|
||||
|
||||
XML 映射文件
|
||||
|
||||
`<foreach>` 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。
|
||||
|
||||
```java
|
||||
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
|
||||
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
|
||||
</foreach>
|
||||
```
|
||||
|
||||
`open="("`:这个属性表示,在*生成的 SQL 语句开始*时添加一个 左括号 `(`。
|
||||
|
||||
`close=")"`:这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 `)`。
|
||||
|
||||
例:批量删除实现
|
||||
|
||||
```java
|
||||
<delete id="deleteByIds">
|
||||
DELETE FROM emp WHERE id IN
|
||||
<foreach collection="ids" item="id" separator="," open="(" close=")">
|
||||
#{id}
|
||||
</foreach>
|
||||
</delete>
|
||||
```
|
||||
|
||||
实现效果类似:`DELETE FROM emp WHERE id IN (1, 2, 3);`
|
||||
|
||||
|
||||
|
||||
## 登录校验
|
||||
|
||||
### 会话技术
|
||||
|
||||
@ -1450,25 +1450,39 @@ public class Main {
|
||||
**类路径**是JVM在运行时用来查找类文件和资源文件的一组目录或JAR包。在许多项目(例如Maven或Gradle项目)中,`src/main/resources`目录下的内容在编译时会被复制到输出目录(如`target/classes`),`src/main/java` 下编译后的 class 文件也会放到这里。
|
||||
|
||||
```text
|
||||
MyProject/
|
||||
├── src/
|
||||
│ └── main/
|
||||
│ └── java/
|
||||
│ └── com/
|
||||
│ └── example/
|
||||
│ └── Main.java
|
||||
├── resources/
|
||||
│ ├── emp.xml
|
||||
src/
|
||||
├── main/
|
||||
│ ├── java/
|
||||
│ │ └── com/
|
||||
│ │ └── example/
|
||||
│ │ └── App.java
|
||||
│ └── resources/
|
||||
│ ├── application.yml
|
||||
│ └── static/
|
||||
│ └── logo.png
|
||||
└── test/
|
||||
├── java/
|
||||
│ └── com/
|
||||
│ └── example/
|
||||
│ └── AppTest.java
|
||||
└── resources/
|
||||
└── test-data.json
|
||||
|
||||
映射到 target/ 后:
|
||||
|
||||
target/
|
||||
├── classes/ ← 主代码和资源的输出根目录
|
||||
│ ├── com/
|
||||
│ │ └── example/
|
||||
│ │ └── App.class ← 编译自 src/main/java/com/example/App.java
|
||||
│ ├── application.yml ← 复制自 src/main/resources/application.yml
|
||||
│ └── static/
|
||||
│ └── tt.img
|
||||
└── target/
|
||||
└── classes/
|
||||
├── com/
|
||||
│ └── example/
|
||||
│ └── Main.class
|
||||
├── emp.xml
|
||||
└── static/
|
||||
└── tt.img
|
||||
│ └── logo.png ← 复制自 src/main/resources/static/logo.png
|
||||
└── test-classes/ ← 测试代码和测试资源的输出根目录
|
||||
├── com/
|
||||
│ └── example/
|
||||
│ └── AppTest.class ← 编译自 src/test/java/com/example/AppTest.java
|
||||
└── test-data.json ← 复制自 src/test/resources/test-data.json
|
||||
|
||||
```
|
||||
|
||||
|
||||
391
自学/Maven.md
Normal file
391
自学/Maven.md
Normal file
@ -0,0 +1,391 @@
|
||||
## Maven
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
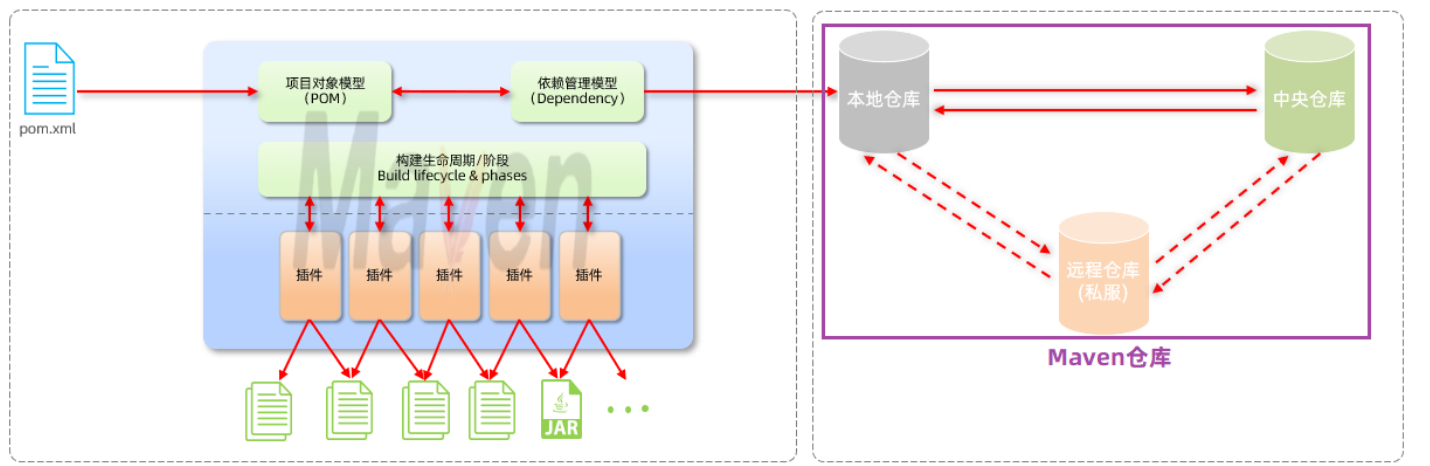
Maven仓库分为:
|
||||
|
||||
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
|
||||
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
|
||||
- 远程仓库(私服):一般由公司团队搭建的私有仓库
|
||||
|
||||
POM文件导入依赖的时候,先看本地仓库有没有,没有就看私服,再没有就从中央仓库下载。
|
||||
|
||||
|
||||
|
||||
### Maven创建/导入项目
|
||||
|
||||
#### **创建Maven项目**
|
||||
|
||||

|
||||
|
||||
勾选 **Create from archetype**(可选),也可以选择 **maven-archetype-quickstart** 等模版。
|
||||
|
||||
点击 Next,填写 GAV 坐标 。
|
||||
|
||||
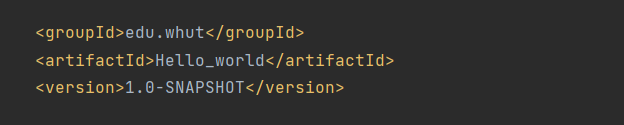
GroupId:标识组织或公司(通常使用域名反写,如 `com.example`)
|
||||
|
||||
ArtifactId:标识具体项目或模块(如 `my-app`、`spring-boot-starter-web`)。
|
||||
|
||||
Version:标识版本号(如 `1.0-SNAPSHOT`、`2.7.3`)
|
||||
|
||||
|
||||
|
||||
#### 导入Maven项目
|
||||
|
||||
**(一)单独的Maven项目**
|
||||
|
||||
打开 IDEA,在主界面选择 Open(或者在菜单栏选择 File -> Open)。
|
||||
|
||||
在文件选择对话框中,定位到已有项目的根目录(包含 `pom.xml` 的目录)。
|
||||
|
||||
选择该目录后,IDEA 会检测到 `pom.xml` 并询问是否导入为 Maven 项目,点击 **OK** 或 **Import** 即可。
|
||||
|
||||
IDEA 会自动解析 `pom.xml`,下载依赖并构建项目结构。
|
||||
|
||||
|
||||
|
||||
**(二)在现有Maven项目中导入独立的Maven项目**
|
||||
|
||||
在已经打开的 IDEA 窗口中,使用 **File -> New -> Module from Existing Sources...**
|
||||
|
||||
选择待导入项目的根目录(其中包含 `pom.xml`),IDEA 会将其导入为同一个工程下的另一个模块(Module)。
|
||||
|
||||
它们 看起来在一个工程里了,但**仍然是两个独立的** Maven 模块。
|
||||
|
||||
|
||||
|
||||
**(三)两个模块属于同一个工程下**
|
||||
|
||||
可以用一个父pom进行统一管理!
|
||||
|
||||
1.新建一个上层目录,如下,MyProject1和MyProject2的内容拷贝过去。
|
||||
|
||||
```xml
|
||||
ParentProject/
|
||||
├── pom.xml <-- 父模块(聚合模块)
|
||||
├── MyProject1/ <-- 子模块1
|
||||
│ └── pom.xml
|
||||
└── MyProject2/ <-- 子模块2
|
||||
└── pom.xml
|
||||
```
|
||||
|
||||
2.创建父级pom
|
||||
|
||||
父模块 `pom.xml` 示例:
|
||||
|
||||
```xml
|
||||
<project>
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>ParentProject</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
<packaging>pom</packaging> //必写
|
||||
|
||||
<modules>
|
||||
<module>MyProject1</module> //必写
|
||||
<module>MyProject2</module>
|
||||
</modules>
|
||||
</project>
|
||||
|
||||
```
|
||||
|
||||
3.修改子模块 `pom.xml` ,加上:
|
||||
|
||||
```xml
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>ParentProject</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
<relativePath>../pom.xml</relativePath> <!-- 可省略 -->
|
||||
</parent>
|
||||
```
|
||||
|
||||
如果子模块中无需与父级不同的配置,**可以不写**,就自动继承父级配置;若写了同名配置,则表示你想要**覆盖或合并**父级配置。
|
||||
|
||||
4.File -> Open选择父级的pom,会自动导入其下面两个项目。
|
||||
|
||||
**但是,仅仅这样无法让模块之间产生联动!需要在此基础上进行(四)的操作!**
|
||||
|
||||
|
||||
|
||||
**(四)通过 Maven 依赖引用**
|
||||
|
||||
如果你的两个模块之间存在依赖关系(如第一个模块需要使用第二个模块的类)还必须在 MyProject1 的 POM 里**显式声明**对 MyProject2 的依赖。
|
||||
|
||||
MyProject1的pom.xml:
|
||||
|
||||
```xml
|
||||
<project>
|
||||
<!-- 继承父 POM -->
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>ParentProject</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
<relativePath>../pom.xml</relativePath>
|
||||
</parent>
|
||||
|
||||
<artifactId>MyProject1</artifactId>
|
||||
<packaging>jar</packaging>
|
||||
|
||||
<dependencies>
|
||||
<!-- 显式依赖于 MyProject2 -->
|
||||
<dependency>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>MyProject2</artifactId>
|
||||
<!-- 不写 <version>,Maven 会自动用父 POM 的 version -->
|
||||
</dependency>
|
||||
<!-- 其他依赖… -->
|
||||
</dependencies>
|
||||
</project>
|
||||
```
|
||||
|
||||
**如何打包?**
|
||||
|
||||
- 在**父 POM 根目录**执行 `mvn clean package`/`mvn clean install`。
|
||||
- 先构建 MyProject2(因为 MyProject1 依赖它)
|
||||
|
||||
- 父 POM 自身不产物,模块的 JAR 都在各自的 `target/` 下。
|
||||
|
||||
|
||||
|
||||
### Maven坐标
|
||||
|
||||
什么是坐标?
|
||||
|
||||
* Maven中的坐标是 == 资源的唯一标识 == 通过该坐标可以唯一定位资源位置
|
||||
* 使用坐标来定义项目或引入项目中需要的依赖
|
||||
|
||||

|
||||
|
||||
### 依赖管理
|
||||
|
||||
可以到mvn的中央仓库(https://mvnrepository.com/)中搜索获取依赖的坐标信息
|
||||
|
||||
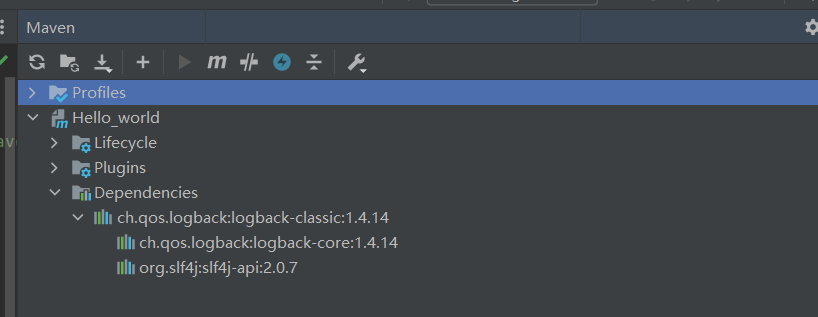
```xml
|
||||
<dependencies>
|
||||
<!-- 第1个依赖 : logback -->
|
||||
<dependency>
|
||||
<groupId>ch.qos.logback</groupId>
|
||||
<artifactId>logback-classic</artifactId>
|
||||
<version>1.2.11</version>
|
||||
</dependency>
|
||||
<!-- 第2个依赖 : junit -->
|
||||
<dependency>
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
<version>4.12</version>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
更改之后可以在界面上看到一个maven刷新按钮,点击一下就开始联网下载依赖了,成功后可以看到
|
||||
|
||||

|
||||
|
||||
#### 排除依赖
|
||||
|
||||
A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被排除的资源**无需指定版本**。
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.itheima</groupId>
|
||||
<artifactId>maven-projectB</artifactId>
|
||||
<version>1.0-SNAPSHOT</version>
|
||||
|
||||
<!--排除依赖, 主动断开依赖的资源-->
|
||||
<exclusions>
|
||||
<exclusion>
|
||||
<groupId>junit</groupId>
|
||||
<artifactId>junit</artifactId>
|
||||
</exclusion>
|
||||
</exclusions>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
#### 依赖范围
|
||||
|
||||
| **scope**值 | **主程序** | **测试程序** | **打包(运行)** | **范例** |
|
||||
| --------------- | ---------- | ------------ | ---------------- | ----------- |
|
||||
| compile(默认) | Y | Y | Y | log4j |
|
||||
| test | - | Y | - | junit |
|
||||
| provided | Y | Y | - | servlet-api |
|
||||
| runtime | - | Y | Y | jdbc驱动 |
|
||||
|
||||
注意!!!这里的scope如果是`test`,那么它的作用范围在`src/test/java`下,在`src/main/java`下无法导包!
|
||||
|
||||
|
||||
|
||||
### Maven 多模块工程
|
||||
|
||||
父 POM 用 `<dependencyManagement>` 锁版本,子模块按需在 `<dependencies>` 中声明自己用的依赖。对“真正所有模块都要”的依赖,可以放到父 POM 顶层 `<dependencies>`,让它们自动继承。
|
||||
|
||||
父 POM(pom.xml):
|
||||
|
||||
```xml
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
|
||||
http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>parent-project</artifactId>
|
||||
<version>1.0.0</version>
|
||||
<packaging>pom</packaging>
|
||||
|
||||
<!-- 声明所有子模块 -->
|
||||
<modules>
|
||||
<module>service-a</module>
|
||||
<module>service-b</module>
|
||||
</modules>
|
||||
|
||||
<!-- 1. 统一锁定版本号(子模块引用时不用写 <version>) -->
|
||||
<dependencyManagement>
|
||||
<dependencies>
|
||||
<!-- Spring Boot Web Starter -->
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
<version>2.7.3</version>
|
||||
</dependency>
|
||||
<!-- Lombok -->
|
||||
<dependency>
|
||||
<groupId>org.projectlombok</groupId>
|
||||
<artifactId>lombok</artifactId>
|
||||
<version>1.18.20</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</dependencyManagement>
|
||||
|
||||
<!-- 2. 所有模块都需要的“公共依赖”放这里,子模块自动继承 -->
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.projectlombok</groupId>
|
||||
<artifactId>lombok</artifactId>
|
||||
<!-- 不用写 <version>,会从上面 dependencyManagement 拿 -->
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</project>
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
子pom
|
||||
|
||||
```xml
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
|
||||
http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<!-- 继承父 POM -->
|
||||
<parent>
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>parent-project</artifactId>
|
||||
<version>1.0.0</version>
|
||||
<relativePath>../pom.xml</relativePath>
|
||||
</parent>
|
||||
|
||||
<artifactId>service-a</artifactId>
|
||||
<packaging>jar</packaging>
|
||||
|
||||
<dependencies>
|
||||
<!-- 1. 从父 dependencyManagement 拿版本,不需要写 <version> -->
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
|
||||
<!-- 2. lombok 已经在父 POM 顶层 dependencies 引入,这里如果要用,也可不再声明 -->
|
||||
</dependencies>
|
||||
</project>
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
父pom的`<packaging>pom</packaging>`表示它只是一个 POM 模块,不会产出任何可执行的 JAR。
|
||||
|
||||
子pom的`<relativePath>../pom.xml</relativePath>`告诉 Maven 去哪个相对路径找父 POM 文件
|
||||
|
||||
|
||||
|
||||
注意:如果子模块A依赖于B模块,那么B模块中的依赖会传递给A,比如B中引入了`org.apache.httpcomponents`,那么A模块的类中可以直接import这个库。反过来不行!大坑!
|
||||
|
||||
|
||||
|
||||
### Maven生命周期
|
||||
|
||||
主要关注以下几个:
|
||||
|
||||
• clean:移除上一次构建生成的文件 (Target文件夹)
|
||||
|
||||
• compile:编译 `src/main/java` 中的 Java 源文件至 `target/classes`
|
||||
|
||||
• test:使用合适的单元测试框架运行测试(junit)
|
||||
|
||||
• package:将编译后的文件打包,如:jar、war等
|
||||
|
||||
• install:将打包后的产物(如 `jar`)安装到本地仓库
|
||||
|
||||
**后面的生命周期执行的时候会自动执行前面所有生命周期!**
|
||||
|
||||
|
||||
|
||||
#### compile:
|
||||
|
||||
```text
|
||||
src/
|
||||
├── main/
|
||||
│ ├── java/
|
||||
│ │ └── com/
|
||||
│ │ └── example/
|
||||
│ │ └── App.java
|
||||
│ └── resources/
|
||||
│ ├── application.yml
|
||||
│ └── static/
|
||||
│ └── logo.png
|
||||
└── test/
|
||||
├── java/
|
||||
│ └── com/
|
||||
│ └── example/
|
||||
│ └── AppTest.java
|
||||
└── resources/
|
||||
└── test-data.json
|
||||
|
||||
映射到 target/ 后:
|
||||
|
||||
target/
|
||||
├── classes/ ← 主代码和资源的输出根目录
|
||||
│ ├── com/
|
||||
│ │ └── example/
|
||||
│ │ └── App.class ← 编译自 src/main/java/com/example/App.java
|
||||
│ ├── application.yml ← 复制自 src/main/resources/application.yml
|
||||
│ └── static/
|
||||
│ └── logo.png ← 复制自 src/main/resources/static/logo.png
|
||||
└── test-classes/ ← 测试代码和测试资源的输出根目录
|
||||
├── com/
|
||||
│ └── example/
|
||||
│ └── AppTest.class ← 编译自 src/test/java/com/example/AppTest.java
|
||||
└── test-data.json ← 复制自 src/test/resources/test-data.json
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### test:
|
||||
|
||||
**扫描** `src/test/java` 下所有符合默认命名规则的测试类:
|
||||
|
||||
- `**/Test*.java`
|
||||
- `**/*Test.java`
|
||||
- `**/*TestCase.java`
|
||||
|
||||
**编译** 这些测试类到 `target/test-classes`。
|
||||
|
||||
**逐个执行**(默认是串行)所有这些编译后的测试类。
|
||||
403
自学/Mybatis.md
Normal file
403
自学/Mybatis.md
Normal file
@ -0,0 +1,403 @@
|
||||
## Mybatis
|
||||
|
||||
### 快速创建
|
||||
|
||||

|
||||
|
||||
1. 创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User
|
||||

|
||||
|
||||
2. 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。
|
||||
|
||||
```
|
||||
#驱动类名称
|
||||
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
|
||||
#数据库连接的url
|
||||
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
|
||||
#连接数据库的用户名
|
||||
spring.datasource.username=root
|
||||
#连接数据库的密码
|
||||
spring.datasource.password=1234
|
||||
```
|
||||
|
||||
3. 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper
|
||||
|
||||

|
||||
|
||||
@Mapper注解:表示是mybatis中的Mapper接口
|
||||
|
||||
-程序运行时:框架会自动生成接口的**实现类对象(代理对象)**,并交给Spring的IOC容器管理
|
||||
|
||||
@Select注解:代表的就是select查询,用于书写select查询语句
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface UserMapper {
|
||||
//查询所有用户数据
|
||||
@Select("select * from user")
|
||||
public List<User> list();
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 数据库连接池
|
||||
|
||||
数据库连接池是一个容器,负责管理和分配数据库连接(`Connection`)。
|
||||
|
||||
- 在程序启动时,连接池会创建一定数量的数据库连接。
|
||||
- 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。
|
||||
- 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。
|
||||
|
||||
**优势**:避免频繁创建和销毁连接,提高数据库访问效率。
|
||||
|
||||
|
||||
|
||||
Druid(德鲁伊)
|
||||
|
||||
* Druid连接池是阿里巴巴开源的数据库连接池项目
|
||||
|
||||
* 功能强大,性能优秀,是Java语言最好的数据库连接池之一
|
||||
|
||||
把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池:
|
||||
|
||||
1. 在pom.xml文件中引入依赖
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<!-- Druid连接池依赖 -->
|
||||
<groupId>com.alibaba</groupId>
|
||||
<artifactId>druid-spring-boot-starter</artifactId>
|
||||
<version>1.2.8</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
2. 在application.properties中引入数据库连接配置
|
||||
|
||||
```properties
|
||||
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
|
||||
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis
|
||||
spring.datasource.druid.username=root
|
||||
spring.datasource.druid.password=123456
|
||||
```
|
||||
|
||||
|
||||
|
||||
### SQL注入问题
|
||||
|
||||
SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。
|
||||
|
||||
在Mybatis中提供的参数占位符有两种:${...} 、#{...}
|
||||
|
||||
- #{...}
|
||||
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
|
||||
- 使用时机:参数传递,都使用#{…}
|
||||
|
||||
- ${...}
|
||||
- 拼接SQL。直接将参数拼接在SQL语句中,**存在SQL注入问题**
|
||||
- 使用时机:如果对表名、列表进行动态设置时使用
|
||||
|
||||
|
||||
|
||||
### 日志输出
|
||||
|
||||
只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果
|
||||
|
||||
1. 打开application.properties文件
|
||||
|
||||
2. 开启mybatis的日志,并指定输出到控制台
|
||||
|
||||
```java
|
||||
#指定mybatis输出日志的位置, 输出控制台
|
||||
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 驼峰命名法
|
||||
|
||||
在 Java 项目中,数据库表字段名一般使用 **下划线命名法**(snake_case),而 Java 中的变量名使用 **驼峰命名法**(camelCase)。
|
||||
|
||||
- [x] **小驼峰命名(lowerCamelCase)**:
|
||||
|
||||
- 第一个单词的首字母小写,后续单词的首字母大写。
|
||||
- **例子**:`firstName`, `userName`, `myVariable`
|
||||
|
||||
**大驼峰命名(UpperCamelCase)**:
|
||||
|
||||
- 每个单词的首字母都大写,通常用于类名或类型名。
|
||||
- **例子**:`MyClass`, `EmployeeData`, `OrderDetails`
|
||||
|
||||
|
||||
|
||||
表中查询的数据封装到实体类中
|
||||
|
||||
- 实体类属性名和数据库表查询返回的**字段名一致**,mybatis会自动封装。
|
||||
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。
|
||||
|
||||

|
||||
|
||||
解决方法:
|
||||
|
||||
1. 起别名
|
||||
2. 结果映射
|
||||
3. **开启驼峰命名**
|
||||
4. **属性名和表中字段名保持一致**
|
||||
|
||||
|
||||
|
||||
**开启驼峰命名(推荐)**:如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
|
||||
|
||||
> 驼峰命名规则: abc_xyz => abcXyz
|
||||
>
|
||||
> - 表中字段名:abc_xyz
|
||||
> - 类中属性名:abcXyz
|
||||
|
||||
|
||||
|
||||
### 推荐的完整配置:
|
||||
|
||||
```yaml
|
||||
mybatis:
|
||||
#mapper配置文件
|
||||
mapper-locations: classpath:mapper/*.xml
|
||||
type-aliases-package: com.sky.entity
|
||||
configuration:
|
||||
#开启驼峰命名
|
||||
map-underscore-to-camel-case: true
|
||||
```
|
||||
|
||||
`type-aliases-package: com.sky.entity`把 `com.sky.entity` 包下的所有类都当作别名注册,XML 里就可以直接写 `<resultType="Dish">` 而不用写全限定名。可以多添加几个包,用逗号隔开。
|
||||
|
||||
|
||||
|
||||
### 增删改
|
||||
|
||||
- **增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void!**
|
||||
|
||||
**作用于单个字段**
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//SQL语句中的id值不能写成固定数值,需要变为动态的数值
|
||||
//解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
|
||||
/**
|
||||
* 根据id删除数据
|
||||
* @param id 用户id
|
||||
*/
|
||||
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
|
||||
public void delete(Integer id);
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
上图参数值分离,有效防止SQL注入
|
||||
|
||||
|
||||
|
||||
**作用于多个字段**
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//会自动将生成的主键值,赋值给emp对象的id属性
|
||||
@Options(useGeneratedKeys = true,keyProperty = "id")
|
||||
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
|
||||
public void insert(Emp emp);
|
||||
}
|
||||
```
|
||||
|
||||
在 **`@Insert`** 注解中使用 `#{}` 来引用 `Emp` 对象的属性,MyBatis 会自动从 `Emp` 对象中提取相应的字段并绑定到 SQL 语句中的占位符。
|
||||
|
||||
`@Options(useGeneratedKeys = true, keyProperty = "id")` 这行配置表示,插入时自动生成的主键会赋值给 `Emp` 对象的 `id` 属性。
|
||||
|
||||
```
|
||||
// 调用 mapper 执行插入操作
|
||||
empMapper.insert(emp);
|
||||
|
||||
// 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值
|
||||
System.out.println("Generated ID: " + emp.getId());
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 查
|
||||
|
||||
查询案例:
|
||||
|
||||
- **姓名:要求支持模糊匹配**
|
||||
- 性别:要求精确匹配
|
||||
- 入职时间:要求进行范围查询
|
||||
- 根据最后修改时间进行降序排序
|
||||
|
||||
重点在于模糊查询时where name like '%#{name}%' 会报错。
|
||||
|
||||
解决方案:
|
||||
|
||||
使用MySQL提供的字符串拼接函数:`concat('%' , '关键字' , '%')`
|
||||
|
||||
**`CONCAT()`** 如果其中任何一个参数为 **`NULL`**,`CONCAT()` 返回 **`NULL`**,`Like NULL`会导致查询不到任何结果!
|
||||
|
||||
`NULL`和`''`是完全不同的
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
|
||||
@Select("select * from emp " +
|
||||
"where name like concat('%',#{name},'%') " +
|
||||
"and gender = #{gender} " +
|
||||
"and entrydate between #{begin} and #{end} " +
|
||||
"order by update_time desc")
|
||||
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### XML配置文件规范
|
||||
|
||||
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
|
||||
|
||||
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
|
||||
|
||||
1. XML映射**文件的名称**与Mapper**接口名称**一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
|
||||
|
||||
2. XML映射文件的**namespace属性**为Mapper接口**全限定名**一致
|
||||
|
||||
3. XML映射文件中sql语句的**id**与Mapper接口中的**方法名**一致,并保持返回类型一致。
|
||||
|
||||

|
||||
|
||||
\<select>标签:就是用于编写select查询语句的。
|
||||
|
||||
resultType属性,指的是查询返回的单条记录所封装的类型(查询必须)。
|
||||
|
||||
parameterType属性(可选,MyBatis 会根据接口方法的入参类型(比如 `Dish` 或 `DishPageQueryDTO`)自动推断),POJO作为入参,需要使用全类名或是`type‑aliases‑package: com.sky.entity` 下注册的别名。
|
||||
|
||||
```
|
||||
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
|
||||
<select id="pageQuery" resultType="com.sky.vo.DishVO">
|
||||
<select id="list" resultType="com.sky.entity.Dish" parameterType="com.sky.entity.Dish">
|
||||
```
|
||||
|
||||
|
||||
|
||||
**实现过程:**
|
||||
|
||||
1. resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
|
||||
|
||||
2. 配置Mapper文件
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8" ?>
|
||||
<!DOCTYPE mapper
|
||||
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
|
||||
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
|
||||
<mapper namespace="edu.whut.mapper.EmpMapper">
|
||||
<!-- SQL 查询语句写在这里 -->
|
||||
</mapper>
|
||||
```
|
||||
|
||||
`namespace` 属性指定了 **Mapper 接口的全限定名**(即包名 + 类名)。
|
||||
|
||||
3. 编写查询语句
|
||||
|
||||
```xml
|
||||
<select id="list" resultType="edu.whut.pojo.Emp">
|
||||
select * from emp
|
||||
where name like concat('%',#{name},'%')
|
||||
and gender = #{gender}
|
||||
and entrydate between #{begin} and #{end}
|
||||
order by update_time desc
|
||||
</select>
|
||||
```
|
||||
|
||||
**`id="list"`**:指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。
|
||||
|
||||
**`resultType="edu.whut.pojo.Emp"`**:`resultType` 只在 **查询操作** 中需要指定。指定查询结果映射的对象类型,这里是 `Emp` 类。
|
||||
|
||||
|
||||
|
||||
这里有bug!!!
|
||||
|
||||
`concat('%',#{name},'%')`这里应该用`<where>` `<if>`标签对name是否为`NULL`或`''`进行判断
|
||||
|
||||
|
||||
|
||||
### 动态SQL
|
||||
|
||||
#### SQL-if,where
|
||||
|
||||
`<if>`:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
|
||||
|
||||
~~~xml
|
||||
<if test="条件表达式">
|
||||
要拼接的sql语句
|
||||
</if>
|
||||
~~~
|
||||
|
||||
`<where>`只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,**加了总比不加好**
|
||||
|
||||
```java
|
||||
<select id="list" resultType="com.itheima.pojo.Emp">
|
||||
select * from emp
|
||||
<where>
|
||||
<!-- if做为where标签的子元素 -->
|
||||
<if test="name != null">
|
||||
and name like concat('%',#{name},'%')
|
||||
</if>
|
||||
<if test="gender != null">
|
||||
and gender = #{gender}
|
||||
</if>
|
||||
<if test="begin != null and end != null">
|
||||
and entrydate between #{begin} and #{end}
|
||||
</if>
|
||||
</where>
|
||||
order by update_time desc
|
||||
</select>
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### SQL-foreach
|
||||
|
||||
Mapper 接口
|
||||
|
||||
```java
|
||||
@Mapper
|
||||
public interface EmpMapper {
|
||||
//批量删除
|
||||
public void deleteByIds(List<Integer> ids);
|
||||
}
|
||||
```
|
||||
|
||||
XML 映射文件
|
||||
|
||||
`<foreach>` 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。
|
||||
|
||||
```java
|
||||
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
|
||||
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
|
||||
</foreach>
|
||||
```
|
||||
|
||||
`open="("`:这个属性表示,在*生成的 SQL 语句开始*时添加一个 左括号 `(`。
|
||||
|
||||
`close=")"`:这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 `)`。
|
||||
|
||||
例:批量删除实现
|
||||
|
||||
```java
|
||||
<delete id="deleteByIds">
|
||||
DELETE FROM emp WHERE id IN
|
||||
<foreach collection="ids" item="id" separator="," open="(" close=")">
|
||||
#{id}
|
||||
</foreach>
|
||||
</delete>
|
||||
```
|
||||
|
||||
实现效果类似:`DELETE FROM emp WHERE id IN (1, 2, 3);`
|
||||
@ -748,6 +748,8 @@ kill xxx
|
||||
|
||||
## File Browser 文件分享
|
||||
|
||||
https://github.com/filebrowser/filebrowser
|
||||
|
||||
[Docker 部署 File Browser 文件管理系统_filebrowser docker-CSDN博客](https://blog.csdn.net/qq_41906909/article/details/144726676)
|
||||
|
||||
1.创建数据目录
|
||||
|
||||
256
自学/苍穹外卖.md
256
自学/苍穹外卖.md
@ -1,5 +1,9 @@
|
||||
# 苍穹外卖
|
||||
|
||||
## 踩坑总结
|
||||
|
||||
|
||||
|
||||
## 项目简介
|
||||
|
||||
### 整体介绍
|
||||
@ -593,64 +597,6 @@ public class EmpController {
|
||||
|
||||
### 文件上传
|
||||
|
||||
#### 本地存储
|
||||
|
||||
文件上传时在服务端会产生一个临时文件,请求响应完成之后,这个临时文件被自动删除,并没有进行保存。下面呢,我们就需要完成将上传的文件保存在服务器的本地磁盘上。
|
||||
|
||||
代码实现:
|
||||
|
||||
1. 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
|
||||
2. 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
|
||||
|
||||
> MultipartFile 常见方法:
|
||||
>
|
||||
> - String getOriginalFilename(); //获取原始文件名
|
||||
> - void transferTo(File dest); //将接收的文件转存到磁盘文件中
|
||||
> - long getSize(); //获取文件的大小,单位:字节
|
||||
> - byte[] getBytes(); //获取文件内容的字节数组
|
||||
> - InputStream getInputStream(); //获取接收到的文件内容的输入流
|
||||
|
||||
```java
|
||||
@Slf4j
|
||||
@RestController
|
||||
public class UploadController {
|
||||
|
||||
@PostMapping("/upload")
|
||||
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
|
||||
log.info("文件上传:{},{},{}",username,age,image);
|
||||
|
||||
//获取原始文件名
|
||||
String originalFilename = image.getOriginalFilename();
|
||||
|
||||
//构建新的文件名
|
||||
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
|
||||
String newFileName = UUID.randomUUID().toString()+extname;//随机名+文件扩展名
|
||||
|
||||
//将文件存储在服务器的磁盘目录
|
||||
image.transferTo(new File("E:/images/"+newFileName));
|
||||
|
||||
return Result.success();
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
在SpringBoot中,文件上传时默认单个文件最大大小为1M
|
||||
|
||||
那么如果需要上传大文件,可以在application.properties进行如下配置:
|
||||
|
||||
```java
|
||||
#配置单个文件最大上传大小
|
||||
spring.servlet.multipart.max-file-size=10MB
|
||||
|
||||
#配置单个请求最大上传大小(一次请求可以上传多个文件)
|
||||
spring.servlet.multipart.max-request-size=100MB
|
||||
```
|
||||
|
||||
**不推荐!**
|
||||
|
||||
|
||||
|
||||
#### 阿里云OSS存储
|
||||
|
||||
pom文件中添加如下依赖:
|
||||
@ -684,60 +630,65 @@ pom文件中添加如下依赖:
|
||||
上传文件的工具类
|
||||
|
||||
```java
|
||||
package edu.whut.utils;
|
||||
import com.aliyun.oss.OSS;
|
||||
import com.aliyun.oss.OSSClientBuilder;
|
||||
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
|
||||
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
|
||||
import com.aliyun.oss.model.PutObjectRequest;
|
||||
import com.aliyun.oss.model.PutObjectResult;
|
||||
import com.aliyuncs.exceptions.ClientException;
|
||||
import org.springframework.stereotype.Component;
|
||||
import org.springframework.web.multipart.MultipartFile;
|
||||
|
||||
import java.io.*;
|
||||
import java.util.UUID;
|
||||
|
||||
|
||||
/**
|
||||
* 阿里云 OSS 工具类
|
||||
*/
|
||||
@Component
|
||||
public class AliOSSUtils {
|
||||
public class AliOssUtil {
|
||||
|
||||
private String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
|
||||
private String bucketName = "zyjavaweb";
|
||||
private String endpoint;
|
||||
private String accessKeyId;
|
||||
private String accessKeySecret;
|
||||
private String bucketName;
|
||||
|
||||
/**
|
||||
* 实现上传图片到OSS
|
||||
* 文件上传
|
||||
*
|
||||
* @param bytes
|
||||
* @param objectName
|
||||
* @return
|
||||
*/
|
||||
public String upload(MultipartFile file) throws IOException, ClientException {
|
||||
public String upload(byte[] bytes, String objectName) {
|
||||
|
||||
InputStream inputStream = file.getInputStream();
|
||||
// 避免文件覆盖
|
||||
String originalFilename = file.getOriginalFilename();
|
||||
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
|
||||
String fileName = UUID.randomUUID().toString() + extname;
|
||||
// 创建OSSClient实例。
|
||||
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
|
||||
|
||||
//上传文件到 OSS
|
||||
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
|
||||
OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider);
|
||||
PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, fileName, inputStream);
|
||||
PutObjectResult result = ossClient.putObject(putObjectRequest);
|
||||
try {
|
||||
// 创建PutObject请求。
|
||||
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(bytes));
|
||||
} catch (OSSException oe) {
|
||||
System.out.println("Caught an OSSException, which means your request made it to OSS, "
|
||||
+ "but was rejected with an error response for some reason.");
|
||||
System.out.println("Error Message:" + oe.getErrorMessage());
|
||||
System.out.println("Error Code:" + oe.getErrorCode());
|
||||
System.out.println("Request ID:" + oe.getRequestId());
|
||||
System.out.println("Host ID:" + oe.getHostId());
|
||||
} catch (ClientException ce) {
|
||||
System.out.println("Caught an ClientException, which means the client encountered "
|
||||
+ "a serious internal problem while trying to communicate with OSS, "
|
||||
+ "such as not being able to access the network.");
|
||||
System.out.println("Error Message:" + ce.getMessage());
|
||||
} finally {
|
||||
if (ossClient != null) {
|
||||
ossClient.shutdown();
|
||||
}
|
||||
}
|
||||
|
||||
//文件访问路径
|
||||
String url = endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + fileName;
|
||||
// 关闭ossClient
|
||||
ossClient.shutdown();
|
||||
return url;// 把上传到oss的路径返回
|
||||
//文件访问路径规则 https://BucketName.Endpoint/ObjectName
|
||||
StringBuilder stringBuilder = new StringBuilder("https://");
|
||||
stringBuilder
|
||||
.append(bucketName)
|
||||
.append(".")
|
||||
.append(endpoint)
|
||||
.append("/")
|
||||
.append(objectName);
|
||||
|
||||
log.info("文件上传到:{}", stringBuilder.toString());
|
||||
|
||||
return stringBuilder.toString();
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
使用时传入MultipartFile类型的文件
|
||||
|
||||
|
||||
|
||||
### 加密算法
|
||||
@ -1256,54 +1207,97 @@ public class SpringDataRedisTest {
|
||||
- 在Java程序中发送HTTP请求
|
||||
- 接收响应数据
|
||||
|
||||
**HttpClient的maven坐标:**
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.apache.httpcomponents</groupId>
|
||||
<artifactId>httpclient</artifactId>
|
||||
<version>4.5.13</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
**HttpClient的核心API:**
|
||||
|
||||
- HttpClient:Http客户端对象类型,使用该类型对象可发起Http请求。
|
||||
- HttpClients:可认为是构建器,可创建HttpClient对象。
|
||||
- CloseableHttpClient:实现类,实现了HttpClient接口。
|
||||
- HttpGet:Get方式请求类型。
|
||||
- HttpPost:Post方式请求类型。
|
||||
|
||||
**HttpClient发送请求步骤:**
|
||||
|
||||
- 创建HttpClient对象
|
||||
- 创建Http请求对象
|
||||
- 调用HttpClient的execute方法发送请求
|
||||
|
||||
|
||||
**测试用例**
|
||||
|
||||
```java
|
||||
public static String doGet(String url,Map<String,String> paramMap){
|
||||
// 创建Httpclient对象
|
||||
@SpringBootTest
|
||||
public class HttpClientTest {
|
||||
|
||||
/**
|
||||
* 测试通过httpclient发送GET方式的请求
|
||||
*/
|
||||
@Test
|
||||
public void testGET() throws Exception{
|
||||
//创建httpclient对象
|
||||
CloseableHttpClient httpClient = HttpClients.createDefault();
|
||||
|
||||
String result = "";
|
||||
CloseableHttpResponse response = null;
|
||||
//创建请求对象
|
||||
HttpGet httpGet = new HttpGet("http://localhost:8080/user/shop/status");
|
||||
|
||||
try{
|
||||
URIBuilder builder = new URIBuilder(url);
|
||||
if(paramMap != null){
|
||||
for (String key : paramMap.keySet()) {
|
||||
builder.addParameter(key,paramMap.get(key)); //将传入的参数 `paramMap` 中的每一个键值对转换为 URL 的查询字符串形式
|
||||
}
|
||||
}
|
||||
URI uri = builder.build();
|
||||
//发送请求,接受响应结果
|
||||
CloseableHttpResponse response = httpClient.execute(httpGet);
|
||||
|
||||
//创建GET请求
|
||||
HttpGet httpGet = new HttpGet(uri);
|
||||
//获取服务端返回的状态码
|
||||
int statusCode = response.getStatusLine().getStatusCode();
|
||||
System.out.println("服务端返回的状态码为:" + statusCode);
|
||||
|
||||
//发送请求
|
||||
response = httpClient.execute(httpGet);
|
||||
HttpEntity entity = response.getEntity();
|
||||
String body = EntityUtils.toString(entity);
|
||||
System.out.println("服务端返回的数据为:" + body);
|
||||
|
||||
//判断响应状态
|
||||
if(response.getStatusLine().getStatusCode() == 200){
|
||||
result = EntityUtils.toString(response.getEntity(),"UTF-8");
|
||||
}
|
||||
}catch (Exception e){
|
||||
e.printStackTrace();
|
||||
}finally {
|
||||
try {
|
||||
response.close();
|
||||
httpClient.close();
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
return result;
|
||||
//关闭资源
|
||||
response.close();
|
||||
httpClient.close();
|
||||
}
|
||||
@Test
|
||||
public void testPOST() throws Exception{
|
||||
// 创建httpclient对象
|
||||
CloseableHttpClient httpClient = HttpClients.createDefault();
|
||||
|
||||
//创建请求对象
|
||||
HttpPost httpPost = new HttpPost("http://localhost:8080/admin/employee/login");
|
||||
|
||||
JSONObject jsonObject = new JSONObject();
|
||||
jsonObject.put("username","admin");
|
||||
jsonObject.put("password","123456");
|
||||
|
||||
StringEntity entity = new StringEntity(jsonObject.toString());
|
||||
//指定请求编码方式
|
||||
entity.setContentEncoding("utf-8");
|
||||
//数据格式
|
||||
entity.setContentType("application/json");
|
||||
httpPost.setEntity(entity);
|
||||
|
||||
//发送请求
|
||||
CloseableHttpResponse response = httpClient.execute(httpPost);
|
||||
|
||||
//解析返回结果
|
||||
int statusCode = response.getStatusLine().getStatusCode();
|
||||
System.out.println("响应码为:" + statusCode);
|
||||
|
||||
HttpEntity entity1 = response.getEntity();
|
||||
String body = EntityUtils.toString(entity1);
|
||||
System.out.println("响应数据为:" + body);
|
||||
|
||||
//关闭资源
|
||||
response.close();
|
||||
httpClient.close();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user