Commit on 2025/06/16 周一 19:37:23.09
This commit is contained in:
parent
14fe9cdfa5
commit
68c520ba76
347
科研/强化学习.md
Normal file
347
科研/强化学习.md
Normal file
@ -0,0 +1,347 @@
|
||||
# 强化学习
|
||||
|
||||
## Q-learning
|
||||
|
||||
**核心更新公式**
|
||||
$$
|
||||
\boxed{Q(s,a) \gets Q(s,a) + \alpha\left[r + \gamma\,\max_{a'}Q(s',a') - Q(s,a)\right]}
|
||||
$$
|
||||
- $s$:当前状态
|
||||
- $a$:当前动作
|
||||
- $r$:执行 $a$ 后获得的即时奖励
|
||||
- $s'$:执行后到达的新状态
|
||||
- $\alpha\in(0,1]$:学习率,决定“这次新信息”对旧值的影响力度
|
||||
- $\gamma\in[0,1)$:折扣因子,衡量对“后续奖励”的重视程度
|
||||
- $\max_{a'}Q(s',a')$:新状态下可选动作的最大估值,表示“后续能拿到的最大预期回报”
|
||||
|
||||
---
|
||||
|
||||
### 一般示例
|
||||
|
||||
**环境设定**
|
||||
|
||||
- 状态集合:$\{S_1, S_2\}$
|
||||
- 动作集合:$\{a_1, a_2\}$
|
||||
- 转移与奖励:
|
||||
- 在 $S_1$ 选 $a_1$ → 获得 $r=5$,转到 $S_2$
|
||||
- 在 $S_1$ 选 $a_2$ → 获得 $r=0$,转到 $S_2$
|
||||
- 在 $S_2$ 选 $a_1$ → 获得 $r=0$,转到 $S_1$
|
||||
- 在 $S_2$ 选 $a_2$ → 获得 $r=1$,转到 $S_1$
|
||||
|
||||
**超参数**:$\alpha=0.5$,$\gamma=0.9$
|
||||
**初始化**:所有 $Q(s,a)=0$
|
||||
|
||||
在 Q-Learning 里,智能体并不是“纯随机”地走,也不是“一开始就全凭 Q 表拿最高值”——而是常用一种叫 **$\epsilon$-greedy** 的策略来平衡:
|
||||
|
||||
- **探索(Exploration)**:以概率 $\epsilon$(比如 10%)随机选一个动作,帮助智能体发现还没试过、可能更优的路径;
|
||||
- **利用(Exploitation)**:以概率 $1-\epsilon$(比如 90%)选当前状态下 Q 值最高的动作,利用已有经验最大化回报。
|
||||
|
||||
下面按序进行 3 步“试—错”更新,并在表格中展示每一步后的 $Q$ 值。
|
||||
|
||||
| 步骤 | 状态 $s$ | 动作 $a$ | 奖励 $r$ | 到达 $s'$ | $\max_{a'}Q(s',a')$ | 更新后 $Q(s,a)$ | 当前 Q 表 |
|
||||
| :--: | :------: | :------: | :------: | :-------: | :----------------------------------------------: | :------------------------------------------: | :----------------------------------------------------------: |
|
||||
| 初始 | — | — | — | — | — | — | $Q(S_1,a_1)=0,\;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,\;Q(S_2,a_2)=0$ |
|
||||
| 1 | $S_1$ | $a_1$ | 5 | $S_2$ | 0 | $0+0.5\,(5+0-0)=2.5$ | $Q(S_1,a_1)=2.5,\;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,\;Q(S_2,a_2)=0$ |
|
||||
| 2 | $S_2$ | $a_2$ | 1 | $S_1$ | $到达S_1状态后选择最优动作:$$\max\{2.5,0\}=2.5$ | $0+0.5\,(1+0.9\cdot2.5-0)=1.625$ | $Q(S_1,a_1)=2.5,\;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,\;Q(S_2,a_2)=1.625$ |
|
||||
| 3 | $S_1$ | $a_1$ | 5 | $S_2$ | $\max\{0,1.625\}=1.625$ | $2.5+0.5\,(5+0.9\cdot1.625-2.5)\approx4.481$ | $Q(S_1,a_1)\approx4.481,\;Q(S_1,a_2)=0$ $Q(S_2,a_1)=0,\;Q(S_2,a_2)=1.625$ |
|
||||
|
||||
- **第1步**:从 $S_1$ 选 $a_1$,立即回报5,更新后 $Q(S_1,a_1)=2.5$。
|
||||
- **第2步**:从 $S_2$ 选 $a_2$,回报1,加上对 $S_1$ **后续最优值**的 $0.9$ 折扣,得到 $1+0.9\times2.5=3.25$,更新后 $Q(S_2,a_2)=1.625$。
|
||||
- **第3步**:再一次在 $S_1$ 选 $a_1$,这次考虑了 $S_2$ 的最新估值,最终把 $Q(S_1,a_1)$ 提升到约 4.481。
|
||||
|
||||
---
|
||||
|
||||
通过这样一步步的“试—错 + 贝尔曼更新”,Q-Learning 能不断逼近最优 $Q^*(s,a)$,从而让智能体在每个状态都学会选出长期回报最高的动作。
|
||||
|
||||
训练结束后,表里每个状态 $s$ 下各动作的 Q 值都相对准确了,我们就可以直接读表来决策:
|
||||
$$
|
||||
\pi(s) = \arg\max_a Q(s,a)
|
||||
$$
|
||||
即“在状态 $s$ 时,选 Q 值最高的动作”。
|
||||
|
||||
| 状态 \ 动作 | $a_1$ | $a_2$ |
|
||||
| ----------- | ----- | ----- |
|
||||
| $S_1$ | 4.481 | 0 |
|
||||
| $S_2$ | 0 | 1.625 |
|
||||
|
||||
|
||||
|
||||
## DQN
|
||||
|
||||
核心思想:用深度神经网络近似 Q 函数来取代表格,在高维输入上直接做 Q-learning,并通过 **经验回放(写进缓冲区 + 随机抽样训练”)** + **目标网络(Target Network)** 两个稳定化技巧,使 **时序差分(TD )学习**在非线性函数逼近下仍能收敛。
|
||||
|
||||
**TD 学习** = 用“即时奖励 + 折扣后的未来估值”作为目标,通过 TD 误差持续修正当前估计。
|
||||
|
||||
|
||||
|
||||
### 训练过程
|
||||
|
||||
#### 1. 初始化
|
||||
|
||||
1. **主网络(Online Network)**
|
||||
- 定义一个 Q 网络 $Q(s,a;\theta)$,随机初始化参数 $\theta$。
|
||||
|
||||
2. **目标网络(Target Network)**
|
||||
- 复制主网络参数,令 $\theta^- \leftarrow \theta$。
|
||||
- 目标网络用于计算贝尔曼目标值,短期内保持不变。
|
||||
|
||||
3. **经验回放缓冲区(Replay Buffer)**
|
||||
- 创建一个固定容量的队列 $\mathcal{D}$,用于存储交互样本 $(s,a,r,s')$。
|
||||
|
||||
4. **超参数设置**
|
||||
- 学习率 $\eta$
|
||||
- 折扣因子 $\gamma$
|
||||
- ε-greedy 探索率 $\epsilon$(初始值)
|
||||
- 最小训练样本数阈值 $N_{\min}$
|
||||
- 每次训练的小批量大小 $B$
|
||||
- 目标网络同步频率 $C$(梯度更新次数间隔)
|
||||
|
||||
---
|
||||
|
||||
#### 2. 与环境交互并存储经验
|
||||
|
||||
在每个时间步 $t$:
|
||||
|
||||
1. **动作选择**
|
||||
$$
|
||||
a_t =
|
||||
\begin{cases}
|
||||
\text{随机动作} & \text{以概率 }\epsilon,\\
|
||||
\arg\max_a Q(s_t,a;\theta) & \text{以概率 }1-\epsilon.
|
||||
\end{cases}
|
||||
$$
|
||||
|
||||
2. **环境反馈**
|
||||
执行动作 $a_t$,得到奖励 $r_t$ 和下一个状态 $s_{t+1}$。 (**需预先定义奖励函数**)
|
||||
|
||||
3. **存入缓冲区**
|
||||
将元组 $(s_t, a_t, r_t, s_{t+1})$ 存入 Replay Buffer $\mathcal{D}$。
|
||||
如果 $\mathcal{D}$ 已满,则丢弃最早的样本。
|
||||
|
||||
---
|
||||
|
||||
#### 3. 批量随机采样并训练
|
||||
|
||||
当缓冲区样本数 $\ge N_{\min}$ 时,每隔一次或多次环境交互,就进行一次训练更新:
|
||||
|
||||
1. **随机抽取小批量**
|
||||
从 $\mathcal{D}$ 中随机采样 $B$ 条过往经验:
|
||||
$$
|
||||
\{(s_i, a_i, r_i, s'_i)\}_{i=1}^B
|
||||
$$
|
||||
|
||||
2. **计算贝尔曼目标**
|
||||
对每条样本,用**目标网络** $\theta^-$ 计算:
|
||||
$$
|
||||
y_i = r_i + \gamma \max_{a'}Q(s'_i, a'; \theta^-)
|
||||
$$
|
||||
算的是:当前获得的即时奖励 $r_i$,加上“到了下一个状态后,做最优动作所能拿到的最大预期回报”
|
||||
|
||||
3. **预测当前 Q 值**
|
||||
将当前状态-动作对丢给**主网络** $\theta$,得到预测值:
|
||||
$$
|
||||
\hat Q_i = Q(s_i, a_i;\theta)
|
||||
$$
|
||||
算的是:在当前状态 $s_i$、选了样本里那个动作 $a_i$ 时,网络**现在**估计的价值
|
||||
|
||||
4. **构造损失函数**
|
||||
均方误差(MSE)损失:
|
||||
$$
|
||||
L(\theta) = \frac{1}{B}\sum_{i=1}^B\bigl(y_i - \hat Q_i\bigr)^2
|
||||
$$
|
||||
|
||||
5. **梯度下降更新主网络**
|
||||
$$
|
||||
\theta \gets \theta - \eta \nabla_\theta L(\theta)
|
||||
$$
|
||||
|
||||
---
|
||||
|
||||
#### 4. 同步/软更新目标网络
|
||||
|
||||
- **硬同步(Fixed Target)**:
|
||||
每做 $C$ 次梯度更新,就执行
|
||||
$$
|
||||
\theta^- \gets \theta
|
||||
$$
|
||||
|
||||
- **(可选)软更新**:
|
||||
用小步长 $\tau\ll1$ 平滑跟踪:
|
||||
$$
|
||||
\theta^- \gets \tau \theta + (1-\tau) \theta^-.
|
||||
$$
|
||||
|
||||
---
|
||||
|
||||
#### 5. 重复训练直至收敛
|
||||
|
||||
- 重复步骤 2-4 直至满足终止条件(如最大回合数或性能指标)。
|
||||
- 训练过程中可逐步衰减 $\epsilon$(ε-greedy),从更多探索过渡到更多利用。
|
||||
|
||||
|
||||
|
||||
### 示例
|
||||
|
||||
#### 假设设定
|
||||
|
||||
- **动作空间**:两个动作 $\{a_1,a_2\}$。
|
||||
|
||||
- **状态向量维度**:2 维,记作 $s=(s_1,s_2)$。
|
||||
|
||||
- **目标网络结构**(极简线性网络):
|
||||
$$
|
||||
Q(s;\theta^-) = W^-s + b^-,
|
||||
$$
|
||||
|
||||
- $W^-$ 是 $2\times2$ 的权重矩阵 (行数为动作数,列数为状态向量维数)
|
||||
- $b^-$ 是长度 2 的偏置向量
|
||||
|
||||
- **网络参数**(假定已初始化并被冻结):
|
||||
$$
|
||||
W^- =
|
||||
\begin{pmatrix}
|
||||
0.5 & -0.2\\
|
||||
0.1 & \;0.3
|
||||
\end{pmatrix},\quad
|
||||
b^- = \begin{pmatrix}0.1\\-0.1\end{pmatrix}.
|
||||
$$
|
||||
|
||||
- 折扣因子 $\gamma=0.9$。
|
||||
|
||||
#### 样本数据
|
||||
|
||||
假设我们抽到的一条经验是
|
||||
$$
|
||||
(s_i,a_i,r_i,s'_i) = \bigl((0.0,\;1.0),\;a_1,\;2,\;(1.5,\,-0.5)\bigr).
|
||||
$$
|
||||
|
||||
- 当前状态 $s_i=(0.0,1.0)$,当时选了动作 $a_1$ 并得到奖励 $r_i=2$。
|
||||
- 到达新状态 $s'_i=(1.5,-0.5)$。
|
||||
|
||||
#### 计算过程
|
||||
|
||||
1. **前向计算目标网络输出**
|
||||
$$
|
||||
Q(s'_i;\theta^-)
|
||||
= W^-\,s'_i + b^-
|
||||
=
|
||||
\begin{pmatrix}
|
||||
0.5 & -0.2\\
|
||||
0.1 & \;0.3
|
||||
\end{pmatrix}
|
||||
\begin{pmatrix}1.5\\-0.5\end{pmatrix}
|
||||
+
|
||||
\begin{pmatrix}0.1\\-0.1\end{pmatrix}
|
||||
=
|
||||
\begin{pmatrix}
|
||||
0.5\cdot1.5 + (-0.2)\cdot(-0.5) + 0.1 \\[4pt]
|
||||
0.1\cdot1.5 + \;0.3\cdot(-0.5) - 0.1
|
||||
\end{pmatrix}
|
||||
=
|
||||
\begin{pmatrix}
|
||||
0.75 + 0.10 + 0.1 \\[3pt]
|
||||
0.15 - 0.15 - 0.1
|
||||
\end{pmatrix}
|
||||
=
|
||||
\begin{pmatrix}
|
||||
0.95 \\[3pt]
|
||||
-0.10
|
||||
\end{pmatrix}.
|
||||
$$
|
||||
因此,
|
||||
$$
|
||||
Q(s'_i,a_1;\theta^-)=0.95,\quad
|
||||
Q(s'_i,a_2;\theta^-)= -0.10.
|
||||
$$
|
||||
|
||||
2. **取最大值**
|
||||
$$
|
||||
\max_{a'}Q(s'_i,a';\theta^-)
|
||||
= \max\{0.95,\,-0.10\}
|
||||
= 0.95.
|
||||
$$
|
||||
|
||||
3. **计算目标 $y_i$**
|
||||
$$
|
||||
y_i
|
||||
= r_i + \gamma \times 0.95
|
||||
= 2 + 0.9 \times 0.95
|
||||
= 2 + 0.855
|
||||
= 2.855.
|
||||
$$
|
||||
|
||||
---
|
||||
|
||||
这样,我们就得到了 **DQN** 中训练主网络时的"伪标签"
|
||||
$y_i=2.855$,后续会用它与主网络预测值 $Q(s_i,a_i;\theta)$ 计算均方误差,进而更新 $\theta$。
|
||||
|
||||
|
||||
|
||||
## 改进DQN:
|
||||
|
||||
#### 一、构造 n-step Transition
|
||||
|
||||
1. **维护一个长度为 n 的滑动队列**
|
||||
|
||||
- 每步交互(状态 → 动作 → 奖励 → 新状态)后,都向队列里添加这条"单步经验"。
|
||||
- 当队列中积累到 n 条经验时,就可以合并成一条"n-step transition"了。
|
||||
|
||||
2. **合并过程(一步一步累加)**
|
||||
|
||||
- **起始状态**:取队列里第 1 条记录中的状态 $s_t$
|
||||
|
||||
- **起始动作**:取第 1 条记录中的动作 $a_t$
|
||||
|
||||
- **累积奖励**:把队列中前 n 条经验的即时奖励按折扣因子 $\gamma$ 一步步加权累加:
|
||||
$$
|
||||
G_t^{(n)} = r_t + \gamma\,r_{t+1} + \gamma^2\,r_{t+2} + \cdots + \gamma^{n-1}r_{t+n-1}
|
||||
$$
|
||||
|
||||
3. **形成一条新样本**
|
||||
最终你得到一条合并后的样本:
|
||||
$$
|
||||
\bigl(s_t,\;a_t,\;G_t^{(n)},\;s_{t+n},\;\text{done}_{t+n}\bigr)
|
||||
$$
|
||||
然后把它存入主 Replay Buffer。
|
||||
**接着**,把滑动队列的最早一条经验丢掉,让它向前滑一格,继续接收下一步新经验。
|
||||
|
||||
#### 二、批量随机采样与训练
|
||||
|
||||
1. **随机抽取 n-step 样本**
|
||||
|
||||
- 训练时,不管它是来自哪一段轨迹,都从 Replay Buffer 里随机挑出一批已经合好的 n-step transition。
|
||||
- 每条样本就封装了"从 $s_t$ 出发,执行 $a_t$,经历 n 步后所累积的奖励加 bootstrap"以及到达的末状态。
|
||||
|
||||
2. **计算训练目标**
|
||||
|
||||
对于每条抽出的 n-step 样本
|
||||
$(s_t,a_t,G_t^{(n)},s_{t+n},\text{done}_{t+n})$,
|
||||
|
||||
- 如果 $\text{done}_{t+n}=\text{False}$,则
|
||||
$$
|
||||
y = G_t^{(n)} + \gamma^n\,\max_{a'}Q(s_{t+n},a';\theta^-);
|
||||
$$
|
||||
|
||||
- 如果 $\text{done}_{t+n}=\text{True}$,则
|
||||
$$
|
||||
y = G_t^{(n)}.
|
||||
$$
|
||||
|
||||
3. **主网络给出预测**
|
||||
|
||||
- 把样本中的起始状态-动作对 $(s_t,a_t)$ 丢给在线的 Q 网络,得到当前估计的 $\hat{Q}(s_t,a_t)$。
|
||||
|
||||
4. **更新网络**
|
||||
|
||||
- 用"目标值 $y$"和"预测值 $\hat{Q}$"之间的平方差,构造损失函数。
|
||||
- 对损失做梯度下降,调整在线网络参数,使得它的预测越来越贴近那条合并后的真实回报。
|
||||
|
||||
|
||||
|
||||
## VDN
|
||||
|
||||
**核心思路**:将团队 Q 函数写成各智能体局部 Q 的线性和 $Q_{tot}=\sum_{i=1}^{N}\tilde{Q}_i$,在训练时用全局奖励反传梯度,在执行时各智能体独立贪婪决策。
|
||||
|
||||
避免非平稳性:每个智能体看到的“环境”里不再包含 **其他正在同时更新的智能体**——因为所有参数其实在**同一次**反向传播里被一起更新,整体策略变化保持同步;对单个智能体而言,环境动态就不会呈现出随机漂移。
|
||||
|
||||
避免“懒惰智能体”:只要某个行动对团队回报有正贡献,它在梯度里就能拿到正向信号,不会因为某个体率先学到高收益行为而使其他个体“无所事事”。
|
||||
177
科研/草稿.md
177
科研/草稿.md
@ -1,24 +1,157 @@
|
||||
```mermaid
|
||||
graph TD
|
||||
A[动态网络谱分析与重构] --> B[多智能体协同学习与推理]
|
||||
|
||||
A --> A1["谱参数实时估算"]
|
||||
A1 --> A11["卡尔曼滤波"]
|
||||
A1 --> A12["矩阵扰动理论"]
|
||||
A1 --> A13["输出:谱参数"]
|
||||
A --> A2["网络拓扑重构"]
|
||||
A2 --> A21["低秩分解重构"]
|
||||
A2 --> A22["聚类量化"]
|
||||
A2 --> A23["输出:邻接矩阵、特征矩阵"]
|
||||
|
||||
B --> B1["联邦学习优化"]
|
||||
B1 --> B11["谱驱动学习率调整"]
|
||||
B1 --> B12["节点选择策略"]
|
||||
B --> B2["动态图神经网络"]
|
||||
B2 --> B21["动态图卷积设计"]
|
||||
B2 --> B22["一致性推理"]
|
||||
|
||||
以下是修改后的内容,所有公式已用 `$` 或 `$$` 规范包裹:
|
||||
|
||||
---
|
||||
|
||||
## VDN(Value-Decomposition Network)笔记
|
||||
> 参考你的 DQN 笔记格式,并在每一步里标出与 DQN 的主要差异
|
||||
|
||||
---
|
||||
|
||||
### 核心思想
|
||||
|
||||
| DQN | VDN |
|
||||
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| 用单个深度网络近似 **单智能体** 的 Q-函数。 | 用 **多智能体** 框架下的"值分解"思想:把**联合 Q 值** 拆成各智能体局部 Q 值之和 |
|
||||
| $$ Q_{\text{team}}(h,a)\;\approx\;\sum_{i=1}^{n} Q_i(h_i,a_i) $$。 | |
|
||||
| 目标是让一个智能体学会最优策略。 | 目标是让 n 个协作智能体,在只拿到 **同一个团队奖赏** 的前提下,仍能各自学习并在推理阶段独立运行。 |
|
||||
|
||||
**好处**
|
||||
|
||||
1. **稳定性**:通过集中式回传梯度来训练,避免了纯独立学习时的非平稳性与"懒惰智能体"现象。
|
||||
2. **可扩展执行**:训练期需要集中,但执行期每个智能体只用自己的 $Q_i$,动作选择仍是局部、分布式的。
|
||||
3. **无需手工设计个体奖励**:VDN 直接把团队奖励拆解为梯度信号,由网络自动学习"谁贡献了多少"。
|
||||
|
||||
---
|
||||
|
||||
### 训练流程(对照 DQN,粗体为新增或改动部分)
|
||||
|
||||
#### 1. 初始化
|
||||
|
||||
1. **局部 Q 网络**(Online Networks)
|
||||
- 为**每个**智能体 $i$ 初始化参数 $\theta_i$,并定义局部 Q 函数 $Q_i(h_i,a_i;\theta_i)$。
|
||||
- **可选**:参数共享(所有 $Q_i$ 共用一套 $\theta$)+ 身份/角色 one-hot。
|
||||
|
||||
2. **目标网络**
|
||||
- 为每个智能体维护对应的 $\theta_i^{-}$,或共享式 $\theta^{-}$。
|
||||
|
||||
3. **经验回放**(Replay Buffer)
|
||||
|
||||
- **存储的是联合元组**
|
||||
$$
|
||||
(\,\mathbf h=(h_1,\dots,h_n),\; \mathbf a=(a_1,\dots,a_n),\; r,\; \mathbf h'\,)
|
||||
$$
|
||||
其中 $r$ 是唯一的团队奖励。
|
||||
|
||||
4. **超参数**
|
||||
- 同 DQN:$\eta,\gamma,\epsilon,B,C$ 等。
|
||||
- **新增:智能体数 n**、是否共享权重、是否启用通信通道等。
|
||||
|
||||
---
|
||||
|
||||
#### 2. 与环境交互并存储经验
|
||||
|
||||
对每个时间步 $t$:
|
||||
|
||||
| 步骤 | 与 DQN 的差异 |
|
||||
| -------------- | ------------------------------------------------------------ |
|
||||
| **动作选择** | 每个智能体独立实施 ε-greedy: $a_t^i = \arg\max_{a_i} Q_i(h_t^i,a_i)$ (或随机)。 |
|
||||
| **环境反馈** | 环境返回单一团队奖励 $r_t$ 与下一批局部观测 $\mathbf h_{t+1}$。 |
|
||||
| **存入缓冲区** | **存联合元组**,保证训练时能对齐多智能体的状态-动作。 |
|
||||
|
||||
---
|
||||
|
||||
#### 3. 批量随机采样并训练
|
||||
|
||||
**前提**:缓冲区样本 ≥ $N_{\min}$。
|
||||
|
||||
1. **采样小批量**
|
||||
$$
|
||||
\{\!(\mathbf h^{(k)},\mathbf a^{(k)},r^{(k)},\mathbf h'^{(k)})\!\}_{k=1}^{B}
|
||||
$$
|
||||
|
||||
2. **计算联合 TD 目标**
|
||||
- 先用**目标网络集合**求
|
||||
$$
|
||||
y^{(k)} = r^{(k)} + \gamma \max_{\mathbf a'}\sum_{i} Q_i^{-}\!\bigl(h_{i}'^{(k)},a_i';\theta_i^{-}\bigr)
|
||||
$$
|
||||
- **注意**:max 运算对 **联合动作 $\mathbf a'$** 求和后再取最大;避免了枚举指数级动作的方法通常使用 **分解后逐个最大化**\*:
|
||||
$$
|
||||
\max_{\mathbf a'}\sum_i Q_i^{-}(\cdot)\;=\;\sum_i\max_{a_i'} Q_i^{-}(\cdot)
|
||||
$$
|
||||
这是 VDN 能高效扩展到多智能体的关键假设。
|
||||
|
||||
3. **预测当前联合 Q 值**
|
||||
$$
|
||||
\hat Q^{(k)} = \sum_{i} Q_i\!\bigl(h_i^{(k)},a_i^{(k)};\theta_i\bigr)
|
||||
$$
|
||||
|
||||
4. **损失函数**
|
||||
$$
|
||||
L = \frac1B\sum_{k=1}^{B}\bigl(y^{(k)} - \hat Q^{(k)}\bigr)^2
|
||||
$$
|
||||
|
||||
5. **梯度更新**
|
||||
- 对每个 $\theta_i$ 反向传播同一个联合损失 $L$ 的梯度。
|
||||
- 若共享权重,则只更新 $\theta$ 一份。
|
||||
|
||||
---
|
||||
|
||||
#### 4. 同步目标网络
|
||||
|
||||
- **硬同步**:每 $C$ 次优化后令 $\theta_i^{-}\!\leftarrow\!\theta_i$。
|
||||
- **软更新**(可选):$\theta_i^{-} \leftarrow \tau\theta_i + (1-\tau)\theta_i^{-}$。
|
||||
|
||||
---
|
||||
|
||||
#### 5. 重复直到收敛
|
||||
|
||||
- 同 DQN,可线性或指数衰减 $\epsilon$。
|
||||
- 评估阶段,各智能体独立使用各自的 $Q_i$ 做贪婪动作,无需中心化。
|
||||
|
||||
---
|
||||
|
||||
### 与 DQN 的关键区别速查
|
||||
|
||||
| 位置 | DQN | VDN |
|
||||
| ------------ | ---------------------------- | ------------------------------------------------------------ |
|
||||
| **状态表示** | 单一 $s$ 或历史 $h$。 | **局部历史向量 $\{h_i\}$**。 |
|
||||
| **动作空间** | 单行动作 $a$。 | **联合动作 $\mathbf a$**,但执行时每人只管自己的 $a_i$。 |
|
||||
| **价值函数** | $Q(s,a)$。 | $Q_{\text{team}}(\mathbf h,\mathbf a)=\sum_i Q_i(h_i,a_i)$。 |
|
||||
| **TD 目标** | $r+\gamma\max_a Q^-(s',a)$。 | **对和取 TD**:$r+\gamma\max_{\mathbf a'}\sum_i Q_i^-(h_i',a_i')$。 |
|
||||
| **损失回传** | 单网络。 | **同一联合损失回传到多网络/共享网络**。 |
|
||||
| **执行** | 独立单体。 | **集中训练—分布执行(CTDE)**。 |
|
||||
|
||||
---
|
||||
|
||||
### (可选)示例小算例
|
||||
|
||||
设两个智能体 A、B 在同一回合内只会得到一次共同奖励:
|
||||
- A 拾取物品得 3 分
|
||||
- B 成功送回物品得 5 分
|
||||
|
||||
VDN 训练后通常学到:
|
||||
|
||||
| 时刻 | 预测 $Q_A$ | 预测 $Q_B$ | 合成 $\Sigma Q_i$ |
|
||||
| ---------- | ---------- | ---------- | ----------------- |
|
||||
| A 正要拾取 | **↑3.0** | ≈0 | ≈3 |
|
||||
| B 正要送回 | ≈0 | **↑5.0** | ≈5 |
|
||||
| 其它时刻 | ≈基线 | ≈基线 | ≈基线 |
|
||||
|
||||
> 这说明网络已自动把团队奖励"归因"到对应智能体的局部价值上,而无需显式个体奖励设计。
|
||||
|
||||
---
|
||||
|
||||
### 小结
|
||||
|
||||
- **VDN = DQN + 值分解 + 多智能体联合 TD**
|
||||
- 集中式梯度、分布式执行,天然适合合作任务。
|
||||
- 在确保分解假设(奖励/价值近似可加)成立时,VDN 能显著缓解联合动作维度爆炸与非平稳性问题,是协作 MARL 的入门基线之一。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
23
科研/郭款论文.md
23
科研/郭款论文.md
@ -522,6 +522,7 @@ $$
|
||||
文献[60]提出一种基于**简化特征分解**和**整体旋转**的近似方法(reduced Eigenvalue Decomposition,rEVD):
|
||||
|
||||
1. 先通过截断特征值/向量,构造一个 $B = X \Lambda^{1/2}$;
|
||||
因此 $A\approx BB^T$
|
||||
2. 不断“旋转” $B$(乘以酉矩阵 $Q$)并对负值做截断,从而让最终的 $U$ 既接近 $B$ 又满足非负性。
|
||||
这相当于把一部分“逼近”工作用特征分解先做了,然后只用旋转矩阵 $Q$ 来调整局部负值,再配合 $\max(0,\cdot)$ 截断满足非负约束。
|
||||
|
||||
@ -672,24 +673,24 @@ $$
|
||||
|
||||
#### 重构误差分析
|
||||
|
||||
初始传入的**r个特征对**,这个r很关键。
|
||||
初始传入的 $\kappa$ 个特征对
|
||||
|
||||
| 参数 | 决定了什么 | 会发生什么事 |
|
||||
| ------------------------------ | -------------------------------------- | ------------------------------------------ |
|
||||
| **$r$(截断阶数 / 嵌入维度)** | 你允许模型用多少自由度来"拟合"原始矩阵 | 先天上把可达到的最小误差卡死在一个**下界** |
|
||||
| 参数 | 决定了什么 | 会发生什么事 |
|
||||
| ----------------------------------- | -------------------------------------- | ------------------------------------------ |
|
||||
| **$\kappa$(截断阶数 / 嵌入维度)** | 你允许模型用多少自由度来"拟合"原始矩阵 | 先天上把可达到的最小误差卡死在一个**下界** |
|
||||
|
||||
- **截断误差(不可避免)**
|
||||
只保留前 $r$ 条特征线以后,任何再聪明的算法都只能在这 **$r$ 维子空间** 里折腾;
|
||||
只保留前 $\kappa$ 条特征线以后,任何再聪明的算法都只能在这 **$r$ 维子空间** 里折腾;
|
||||
理论上最好的也就是
|
||||
$$
|
||||
\|A - X_r\Lambda_rX_r^{\!\top}\|_F^2 \;=\; \sum_{i=r+1}^{n}\lambda_i^2,
|
||||
\|A - X_{\kappa}\Lambda_{\kappa}rX_{\kappa}^{\!\top}\|_F^2 \;=\; \sum_{i={\kappa}+1}^{r}\lambda_i^2,
|
||||
$$
|
||||
|
||||
也就是把后面没选的特征值的平方加起来。
|
||||
$r$ 选小了,这个和就大——这是 **谱截断误差**,跟迭代多少次无关。
|
||||
$\kappa$ 选小了,这个和就大——这是 **谱截断误差**,跟迭代多少次无关。
|
||||
|
||||
- **优化误差(可迭代消除)**
|
||||
rEVD / SNMF 的迭代只是想在"既保持 $\text{rank} \leq r$, 又非负"这两个约束里,把误差降到 **谱截断极限之上最小**。
|
||||
rEVD / SNMF 的迭代只是想在"既保持 $\text{rank} \leq \kappa$, 又非负"这两个约束里,把误差降到 **谱截断极限之上最小**。
|
||||
迭代越多,这一部分误差会指数式衰减到机器精度;但它永远不可能穿透前面的"墙"。
|
||||
|
||||
> **一句话**:迭代能消掉"姿势不对"的误差,却消不掉"维度不够"的误差。
|
||||
@ -698,7 +699,11 @@ $$
|
||||
|
||||
#### 疑问
|
||||
|
||||
**!!!为什么采用SNMF?** 5.13日我的思考:卡尔曼滤波得到的特征值和特征向量存在噪声 直接进行谱分解重构会导致重构出来的矩阵不满足对称性。但是SNMF在迭代的过程中增加了**非负**且**对称**的约束!并且得到的U是个低维的,你可以仅在需要的时候进行重构,其他时候就保留U就行!!!
|
||||
**!!!为什么采用SNMF?**
|
||||
|
||||
卡尔曼滤波得到的特征值和特征向量存在噪声 直接进行谱分解重构会导致重构出来的矩阵不满足对称性。但是SNMF在迭代的过程中增加了**非负**且**对称**的约束!
|
||||
|
||||
可以确保 $A' = UU^{\mathsf T}$ 得到的重构矩阵是对称且非负的!!!
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1309,7 +1309,7 @@ public class SpringbootWebConfig2Application {
|
||||
}
|
||||
```
|
||||
|
||||
12. @RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端
|
||||
13. @RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端
|
||||
|
||||
```java
|
||||
@RestControllerAdvice
|
||||
@ -1322,10 +1322,39 @@ public class SpringbootWebConfig2Application {
|
||||
}
|
||||
}
|
||||
```
|
||||
12. `@Configuration`和`@Bean`配合使用,可以对第三方bean进行**集中**的配置管理,依赖注入!!`@Bean`用于方法上。加了`@Configuration`,当Spring Boot应用**启动时,它会执行**一系列的自动配置步骤。
|
||||
14. `@Configuration`和`@Bean`配合使用,可以对第三方bean进行**集中**的配置管理,依赖注入!!`@Bean`用于方法上。加了`@Configuration`,当Spring Boot应用**启动时,它会执行**一系列的自动配置步骤。
|
||||
|
||||
12. `@ComponentScan`指定了Spring应该在哪些包下搜索带有`@Component`、`@Service`、`@Repository`、`@Controller`等注解的类,以便将这些类自动注册为Spring容器管理的Bean.`@SpringBootApplication`它是一个便利的注解,组合了`@Configuration`、`@EnableAutoConfiguration`和`@ComponentScan`注解。
|
||||
15. `@ComponentScan`指定了Spring应该在哪些包下搜索带有`@Component`、`@Service`、`@Repository`、`@Controller`等注解的类,以便将这些类自动注册为Spring容器管理的Bean.`@SpringBootApplication`它是一个便利的注解,组合了`@Configuration`、`@EnableAutoConfiguration`和`@ComponentScan`注解。
|
||||
|
||||
16. @Async 注解,异步执行
|
||||
|
||||
1.在你的配置类或主启动类上添加:
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
@EnableAsync
|
||||
public class AsyncConfig {
|
||||
// 可以自定义线程池 Bean(可选)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
2.在你希望异步执行的方法或它所在的 Bean 上,添加 `@Async`
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class EmailService {
|
||||
|
||||
@Async
|
||||
public void sendWelcomeEmail(String userId) {
|
||||
// 这个方法会在独立线程中执行
|
||||
// 调用线程会立即返回,不会等待方法内部逻辑完成
|
||||
// … 发送邮件的耗时操作 …
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## 登录校验
|
||||
@ -1360,13 +1389,27 @@ public class SpringbootWebConfig2Application {
|
||||
|
||||
**原理**:**服务端存储**会话数据(如内存、Redis),客户端**只保存**会话 ID。
|
||||
|
||||
**第一次请求**
|
||||
|
||||
- 浏览器没有 `JSESSIONID` Cookie,服务端看到没有会话 ID,就调用 `createSession()` 生成一个新的会话 ID(通常是一个 UUID),并在响应头里带上。
|
||||
|
||||
**浏览器收到响应**
|
||||
|
||||
- 会把这个 `JSESSIONID` 写入本地 Cookie 存储(因为你配置了 `max-age=2592000`,即 30 天,它会落盘保存,浏览器关了再开也不会丢失)。
|
||||
|
||||
**后续请求**
|
||||
|
||||
- 浏览器会自动在请求头里带上 `Cookie: JSESSIONID=<新ID>`,服务端就能根据这个 ID 从 Redis 里拿到对应的 Session 数据,恢复用户状态。
|
||||
|
||||
|
||||
|
||||
1)**服务器内建一张 Map**(或 Redis 等持久化存储),大致结构:
|
||||
|
||||
```text
|
||||
{ "abc123" -> HttpSession 实例 }
|
||||
```
|
||||
|
||||
2)`HttpSession` 自身又是一个 KV 容器,结构类似:
|
||||
2)`HttpSession ` 实例 自身又是一个 KV 容器,结构类似:
|
||||
|
||||
```text
|
||||
HttpSession
|
||||
@ -1398,7 +1441,16 @@ HttpSession
|
||||
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
|
||||
```
|
||||
|
||||
后端代码的`request.getSession()`能**自动获取**当前请求所对应的HttpSession 实例!!!
|
||||
后端代码的`request.getSession()`能**自动获取**当前请求所对应的HttpSession 实例!!!再往里存user信息。
|
||||
|
||||
3)退出登录
|
||||
|
||||
```
|
||||
// 移除登录态
|
||||
request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE);
|
||||
```
|
||||
|
||||
此时,后端当前sessionId所对应的HttpSession 实例实例中的键"UserConstant.USER_LOGIN_STATE",它的值清零了(相当于用户信息删除了)。
|
||||
|
||||
|
||||
|
||||
@ -1406,7 +1458,7 @@ Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也
|
||||
|
||||
- 优点:Session是存储在服务端的,安全。会话数据存在客户端有篡改的风险。
|
||||
- 缺点:
|
||||
- 在分布式服务器集群环境下,Session 无法自动共享
|
||||
- 在分布式服务器集群环境下,Session 无法自动共享(可以共用redis解决)
|
||||
- 如果客户端禁用 Cookie,Session 会失效。
|
||||
- 需要在服务器端存储会话信息,可能带来性能压力,尤其是在高并发环境下。
|
||||
|
||||
|
||||
@ -11,13 +11,16 @@ Intellij Ideav创建Java项目:
|
||||
|
||||
IDEA快捷键:
|
||||
|
||||
| `Ctrl + Alt + L` | 格式化代码 |
|
||||
| ---------------- | ------------------------ |
|
||||
| `Ctrl + /` | 注释/取消注释当前行 |
|
||||
| `Ctrl + D` | 复制当前行或选中的代码块 |
|
||||
| `Ctrl + Y` | 删除当前行 |
|
||||
| `Ctrl + N` | 查找类 |
|
||||
| `Ctrl+shift+F` | 在文件中查找代码 |
|
||||
| `Ctrl + Alt + L` | 格式化代码 |
|
||||
| ---------------- | ------------------------- |
|
||||
| `Ctrl + /` | 注释/取消注释当前行 |
|
||||
| `Ctrl + D` | 复制当前行或选中的代码块 |
|
||||
| `Ctrl + Y` | 删除当前行 |
|
||||
| `Ctrl + N` | 查找类 |
|
||||
| `shift+shift` | 在文件中查找代码 |
|
||||
| `alt+回车` | service接口类跳转到实现类 |
|
||||
|
||||
|
||||
|
||||
调试快捷键:
|
||||
|
||||
@ -188,6 +191,7 @@ Math.min(a, b));
|
||||
#### 枚举
|
||||
|
||||
```java
|
||||
//纯状态枚举 常见于 switch-case、简单条件判断。
|
||||
public enum OperationType {
|
||||
|
||||
/**
|
||||
@ -220,9 +224,9 @@ public void execute(OperationType type, Object entity) {
|
||||
|
||||
|
||||
```java
|
||||
// 定义枚举类型
|
||||
// 携带数据的枚举, 适合“常量 + 不变数据”的场景,如 星期、货币、错误码等。
|
||||
public enum DayOfWeek {
|
||||
//创建7个 DayOfWeek 类型的对象,分别传入构造参数chineseName和dayNumber
|
||||
//创建7个 DayOfWeek 类型的对象,分别传入构造参数chineseName和dayNumber,它们叫“枚举常量”
|
||||
MONDAY("星期一", 1),
|
||||
TUESDAY("星期二", 2),
|
||||
WEDNESDAY("星期三", 3),
|
||||
|
||||
@ -619,7 +619,7 @@ mybatis-plus:
|
||||
|
||||
前面的例子都是**根据主键id**更新、修改、查询,无法支持复杂条件where。
|
||||
|
||||
#### 条件构造器
|
||||
#### 条件构造器Wrapper
|
||||
|
||||
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法**除了以`id`作为`where`条件**以外,还支持**更加复杂的`where`条件**。
|
||||
|
||||
@ -639,9 +639,15 @@ mybatis-plus:
|
||||
|
||||
select方法只需用于 **查询** 时指定所需的**列**,完整查询不需要,用于update和delete不需要。
|
||||
|
||||
**注意:里面的字段都是数据表中真实的字段名,而不是类中自己定义的。**
|
||||
`QueryWrapper` 里对 `like`、`eq`、`ge` 等方法都做了重载
|
||||
|
||||
```
|
||||
QueryWrapper<User> qw = new QueryWrapper<>();
|
||||
qw.like("name", name); //两参版本,第一个参数对应数据库中的列名,如果对应不上,就会报错!!!
|
||||
qw.like(StrUtil.isNotBlank(name), "name", name); //三参,多一个boolean condition 参数
|
||||
```
|
||||
|
||||
|
||||
eg: .select("id","username","info","balance")
|
||||
|
||||
**例1:**查询出名字中带o的,存款大于等于1000元的人的id,username,info,balance:
|
||||
|
||||
@ -663,21 +669,6 @@ void testQueryWrapper(){
|
||||
}
|
||||
```
|
||||
|
||||
**例2:**更新用户名为jack的用户的余额为2000:
|
||||
|
||||
```Java
|
||||
|
||||
@Test
|
||||
void testUpdateByQueryWrapper() {
|
||||
// 1.构建查询条件 where name = "Jack"
|
||||
QueryWrapper<User> wrapper = new QueryWrapper<User>().eq("username", "Jack");
|
||||
// 2.更新数据,user中非null字段都会作为set语句
|
||||
User user = new User();
|
||||
user.setBalance(2000);
|
||||
userMapper.update(user, wrapper);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
**UpdateWrapper**
|
||||
@ -707,44 +698,54 @@ void testUpdateWrapper() {
|
||||
**例2:**
|
||||
|
||||
```java
|
||||
// wrapper 只负责 WHERE 条件
|
||||
UpdateWrapper<User> wrapper = new UpdateWrapper<User>().eq("status","ACTIVE");
|
||||
// 用 UpdateWrapper 拼 WHERE + SET
|
||||
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
|
||||
// WHERE status = 'ACTIVE'
|
||||
.eq("status", "ACTIVE")
|
||||
// SET balance = 2000, name = 'Alice'
|
||||
.set("balance", 2000)
|
||||
.set("name", "Alice");
|
||||
|
||||
// 实体里所有非 null 字段都会拼到 SET
|
||||
User user = new User();
|
||||
user.setBalance(2000);
|
||||
user.setName("Alice");
|
||||
|
||||
userMapper.update(user, wrapper);
|
||||
// 把 entity 参数传 null,MyBatis-Plus 会只用 wrapper 里的 set/where
|
||||
userMapper.update(null, wrapper);
|
||||
```
|
||||
|
||||
|
||||
|
||||
**LambdaQueryWrapper**
|
||||
**LambdaQueryWrapper(推荐)**
|
||||
|
||||
在使用传统的 `QueryWrapper` 或 `UpdateWrapper` 时,我们不得不把数据库字段名写成字符串常量,这种“魔法值”既不易维护,也无法在编译期发现错误。MyBatis-Plus 提供了两种基于 Lambda 的 Wrapper——`LambdaQueryWrapper` 和 `LambdaUpdateWrapper`——它们接收实体类的 getter 方法引用,通过反射自动解析对应的字段名。
|
||||
是**QueryWrapper**和**UpdateWrapper**的上位选择!!!
|
||||
|
||||
传统的 `QueryWrapper`/`UpdateWrapper` 需要把数据库字段名写成**字符串常量**,既容易拼写出错,也无法在编译期校验。MyBatis-Plus 引入了两种基于 Lambda 的 Wrapper —— `LambdaQueryWrapper` 和 `LambdaUpdateWrapper` —— 通过传入实体类的 getter 方法引用,框架会自动解析并映射到对应的列,实现了类型安全和更高的可维护性。
|
||||
|
||||
```java
|
||||
@Test
|
||||
void testLambdaQueryWrapper() {
|
||||
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
|
||||
.select(User::getId, User::getUsername, User::getInfo, User::getBalance)
|
||||
.like(User::getUsername, "o")
|
||||
.ge(User::getBalance, 1000);
|
||||
List<User> users = userMapper.selectList(wrapper);
|
||||
users.forEach(System.out::println);
|
||||
// ——— 传统 QueryWrapper ———
|
||||
public User findByUsername(String username) {
|
||||
QueryWrapper<User> qw = new QueryWrapper<>();
|
||||
// 硬编码列名,拼写错了编译不过不了,会在运行时抛数据库异常
|
||||
qw.eq("user_name", username);
|
||||
return userMapper.selectOne(qw);
|
||||
}
|
||||
|
||||
// ——— LambdaQueryWrapper ———
|
||||
public User findByUsername(String username) {
|
||||
// 内部已注入实体 Class 和元数据,方法引用自动解析列名
|
||||
LambdaQueryWrapper<User> qw = Wrappers.lambdaQuery(User.class)
|
||||
.eq(User::getUserName, username);
|
||||
return userMapper.selectOne(qw);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 自定义sql
|
||||
|
||||
可以让我们利用Wrapper生成查询条件,再结合Mapper.xml编写SQL
|
||||
即自己编写Wrapper查询条件,再结合Mapper.xml编写SQL
|
||||
|
||||
**例1:**以 `UPDATE user SET balance = balance - 200 WHERE id in (1, 2, 4)` 为例:
|
||||
|
||||
1.先在**业务层**利用wrapper创建条件,传递参数
|
||||
1)先在**业务层**利用wrapper创建条件,传递参数
|
||||
|
||||
```java
|
||||
@Test
|
||||
@ -757,7 +758,7 @@ void testCustomWrapper() {
|
||||
}
|
||||
```
|
||||
|
||||
2. 自定义**mapper层**把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。
|
||||
2)自定义**mapper层**把wrapper和其他业务参数传进去,自定义sql语句书写sql的前半部分,后面拼接。
|
||||
|
||||
```java
|
||||
public interface UserMapper extends BaseMapper<User> {
|
||||
@ -821,7 +822,7 @@ List<User> queryUserByWrapper(@Param("ew")QueryWrapper<User> wrapper);
|
||||
|
||||
|
||||
|
||||
#### Service层常用方法
|
||||
#### Service层的常用方法
|
||||
|
||||
**查询:**
|
||||
|
||||
@ -1017,11 +1018,13 @@ public interface UserMapper extends BaseMapper<User> {
|
||||
|
||||
|
||||
|
||||
#### **Lambda**
|
||||
#### Service层的lambdaQuery
|
||||
|
||||
IService中还提供了Lambda功能来简化我们的**复杂查询及更新功能**。
|
||||
|
||||
`lambdaQuery()` = `new LambdaQueryWrapper<>()` + 内置的执行方法(如 `.list()`、`.one()`)
|
||||
相当于「条件构造」和「执行方法」写在一起
|
||||
|
||||
`this.lambdaQuery()` = `LambdaQueryWrapper` + 内置的执行方法(如 `.list()`、`.one()`)
|
||||
|
||||
| 特性 | `lambdaQuery()` | `lambdaUpdate()` |
|
||||
| -------------- | --------------------------------------------------------- | --------------------------------------------- |
|
||||
@ -1167,3 +1170,93 @@ VALUES
|
||||
`url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true`
|
||||
|
||||
**但是会存在上述上事务的问题!!!**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### MQ分页
|
||||
|
||||
**快速入门**
|
||||
|
||||
1)引入依赖
|
||||
|
||||
```xml
|
||||
<!-- 数据库操作:https://mp.baomidou.com/ -->
|
||||
<dependency>
|
||||
<groupId>com.baomidou</groupId>
|
||||
<artifactId>mybatis-plus-boot-starter</artifactId>
|
||||
<version>3.5.9</version>
|
||||
</dependency>
|
||||
|
||||
<!-- MyBatis Plus 分页插件 -->
|
||||
<dependency>
|
||||
<groupId>com.baomidou</groupId>
|
||||
<artifactId>mybatis-plus-jsqlparser-4.9</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
2)定义通用分页查询条件实体
|
||||
|
||||
```java
|
||||
@Data
|
||||
@ApiModel(description = "分页查询实体")
|
||||
public class PageQuery {
|
||||
@ApiModelProperty("页码")
|
||||
private Long pageNo;
|
||||
@ApiModelProperty("页码")
|
||||
private Long pageSize;
|
||||
@ApiModelProperty("排序字段")
|
||||
private String sortBy;
|
||||
@ApiModelProperty("是否升序")
|
||||
private Boolean isAsc;
|
||||
}
|
||||
```
|
||||
|
||||
3)新建一个 `UserQuery` 类,让它继承自你已有的 `PageQuery`
|
||||
|
||||
```java
|
||||
@Data
|
||||
@ApiModel(description = "用户分页查询实体")
|
||||
public class UserQuery extends PageQuery {
|
||||
@ApiModelProperty("用户名(模糊查询)")
|
||||
private String name;
|
||||
}
|
||||
```
|
||||
|
||||
4)Service里使用
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class UserService extends ServiceImpl<UserMapper, User> {
|
||||
|
||||
/**
|
||||
* 用户分页查询(带用户名模糊 + 动态排序)
|
||||
*
|
||||
* @param query 包含 pageNo、pageSize、sortBy、isAsc、name 等字段
|
||||
*/
|
||||
public Page<User> pageByQuery(UserQuery query) {
|
||||
// 1. 构造 Page 对象
|
||||
Page<User> page = new Page<>(
|
||||
query.getPageNo(),
|
||||
query.getPageSize()
|
||||
);
|
||||
|
||||
// 2. 构造查询条件
|
||||
LambdaQueryWrapper<User> qw = Wrappers.<User>lambdaQuery()
|
||||
// 当 name 非空时,加上 user_name LIKE '%name%'
|
||||
.like(StrUtil.isNotBlank(query.getName()), User::getUserName, query.getName());
|
||||
|
||||
// 3. 动态排序
|
||||
if (StrUtil.isNotBlank(query.getSortBy())) {
|
||||
String column = StrUtil.toUnderlineCase(query.getSortBy());
|
||||
boolean asc = Boolean.TRUE.equals(query.getIsAsc());
|
||||
qw.last("ORDER BY " + column + (asc ? " ASC" : " DESC"));
|
||||
}
|
||||
|
||||
// 4. 执行分页查询
|
||||
return this.page(page, qw);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -594,7 +594,7 @@ public class CustomPriorityQueue {
|
||||
}
|
||||
```
|
||||
|
||||
不用lambda版本:
|
||||
不用lambda版本(不推荐):
|
||||
|
||||
```java
|
||||
PriorityQueue<int[]> minHeap = new PriorityQueue<>(new Comparator<int[]>() {
|
||||
|
||||
184
自学/智能协同云图库.md
184
自学/智能协同云图库.md
@ -1,11 +1,89 @@
|
||||
# 智能协同云图库
|
||||
|
||||
## 待完善功能:
|
||||
|
||||
用户模块扩展功能:
|
||||
|
||||
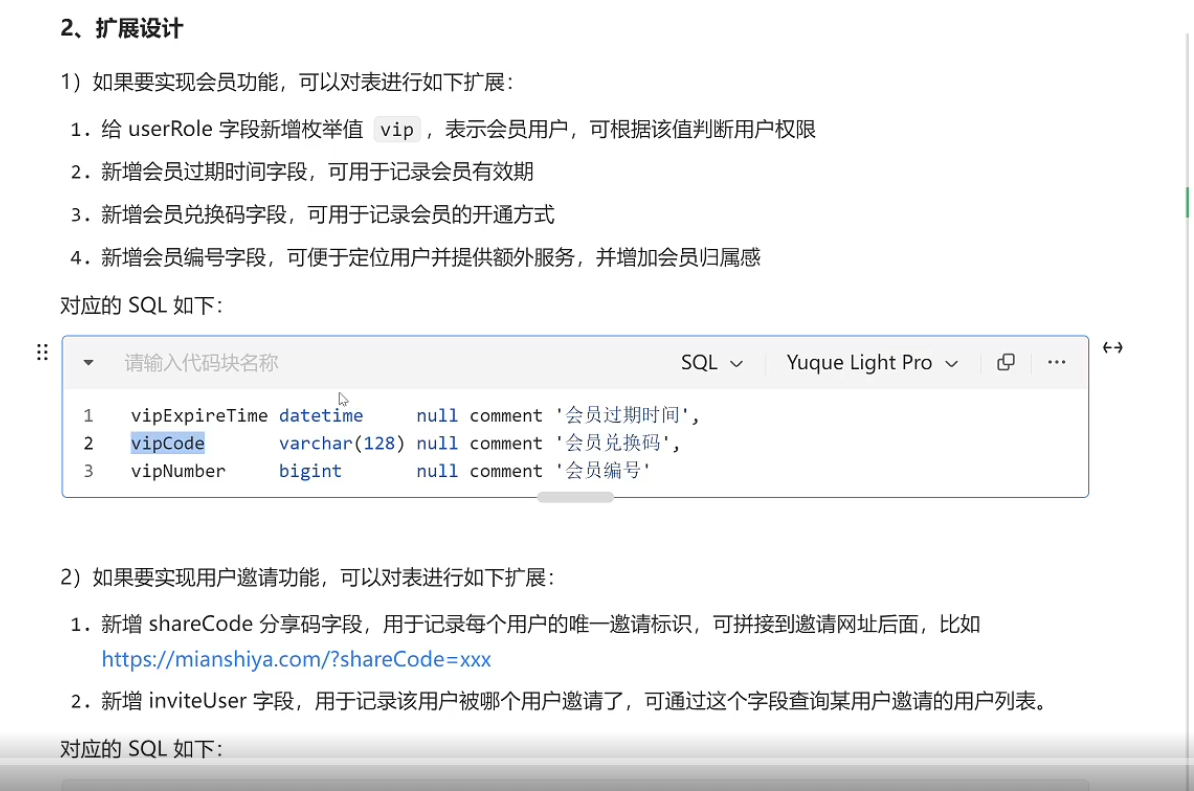
|
||||
|
||||
|
||||
|
||||
2.JWT校验,可能要同时改前端,把userId保存到ThreadLocal中
|
||||
|
||||
|
||||
|
||||
3.目前这些标签写死了,可以用redis、数据库进行动态设置。(根据点击次数)
|
||||
|
||||
```java
|
||||
@GetMapping("/tag_category")
|
||||
public BaseResponse<PictureTagCategory> listPictureTagCategory() {
|
||||
PictureTagCategory pictureTagCategory = new PictureTagCategory();
|
||||
List<String> tagList = Arrays.asList("热门", "搞笑", "生活", "高清", "艺术", "校园", "背景", "简历", "创意");
|
||||
List<String> categoryList = Arrays.asList("模板", "电商", "表情包", "素材", "海报");
|
||||
pictureTagCategory.setTagList(tagList);
|
||||
pictureTagCategory.setCategoryList(categoryList);
|
||||
return ResultUtils.success(pictureTagCategory);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
4.图片审核扩展
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
5.爬图扩展
|
||||
|
||||
2)记录从哪里爬的
|
||||
|
||||
4)bing直接搜可能也是缩略图,可能模拟手点一次图片,再爬会清晰一点
|
||||
|
||||

|
||||
|
||||
6.缓存扩展
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
图片压缩
|
||||
|
||||

|
||||
|
||||
文件秒传,md5校验,如果已有,直接返回url,不用重新上传(图片场景不必使用)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
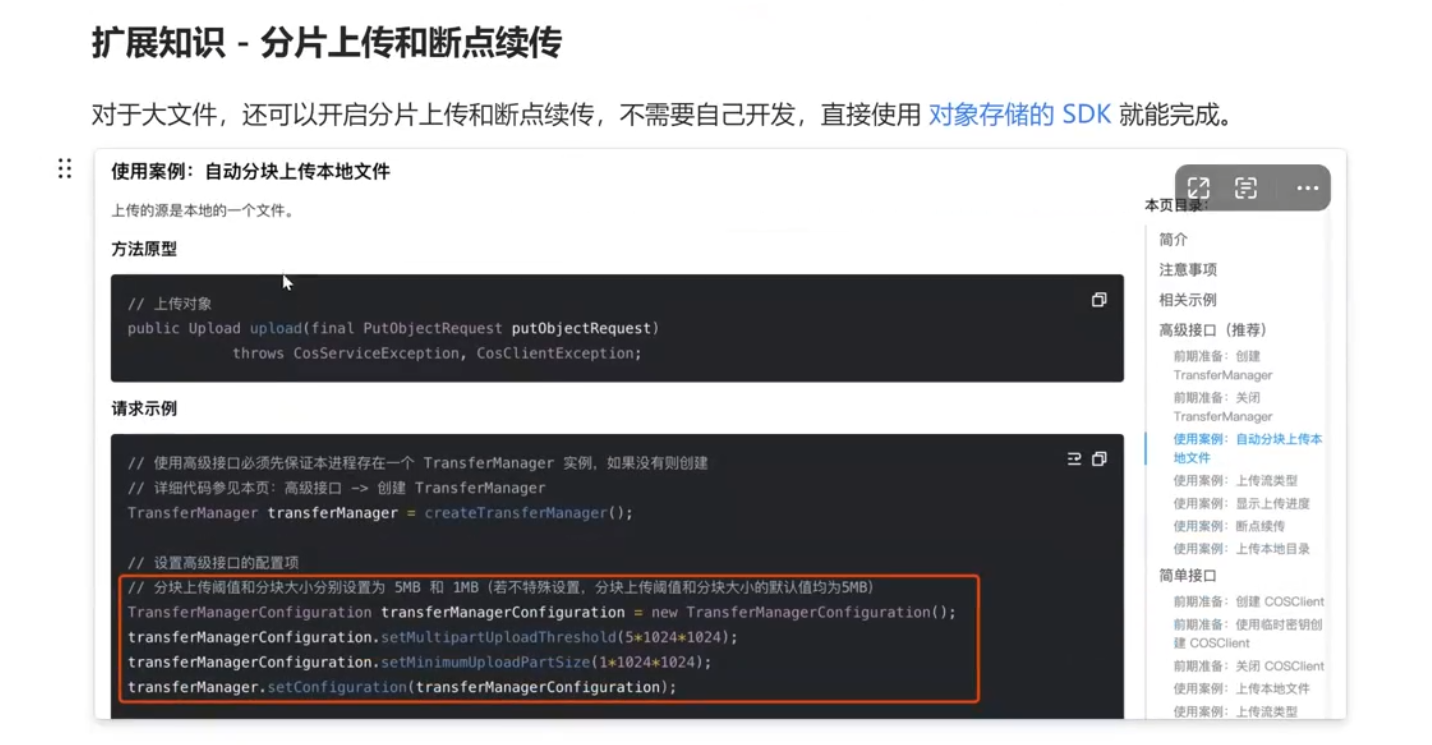
|
||||
|
||||
分片上传和断点续传:[对象存储 上传对象_腾讯云](https://cloud.tencent.com/document/product/436/65935#0c1fbdc5-64c1-4224-9aa5-92fbd0ae6780)
|
||||
|
||||
|
||||
|
||||
CDN内容分发,后期项目上线之后搞一下。
|
||||
|
||||
|
||||
|
||||
浏览器缓存
|
||||
|
||||
是服务器(或 CDN/静态文件服务器)在返回资源时下发给浏览器的。
|
||||
|
||||

|
||||
|
||||
用户空间扩展:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
|
||||
|
||||
注意,勾选Actual Column生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即user_name->userName
|
||||
@ -26,13 +104,113 @@ private static final long serialVersionUID = -1321880859645675653L;
|
||||
|
||||
|
||||
|
||||
创建图片的业务流程
|
||||
**创建图片的业务流程**
|
||||
创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
|
||||
|
||||
有两种常见的处理方式:
|
||||
|
||||
1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的url存储地址;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
|
||||
2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功南无就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
|
||||
1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的**url存储地址**;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
|
||||
2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
|
||||
当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
|
||||
|
||||
|
||||
|
||||
## 优化
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 多级缓存
|
||||
|
||||
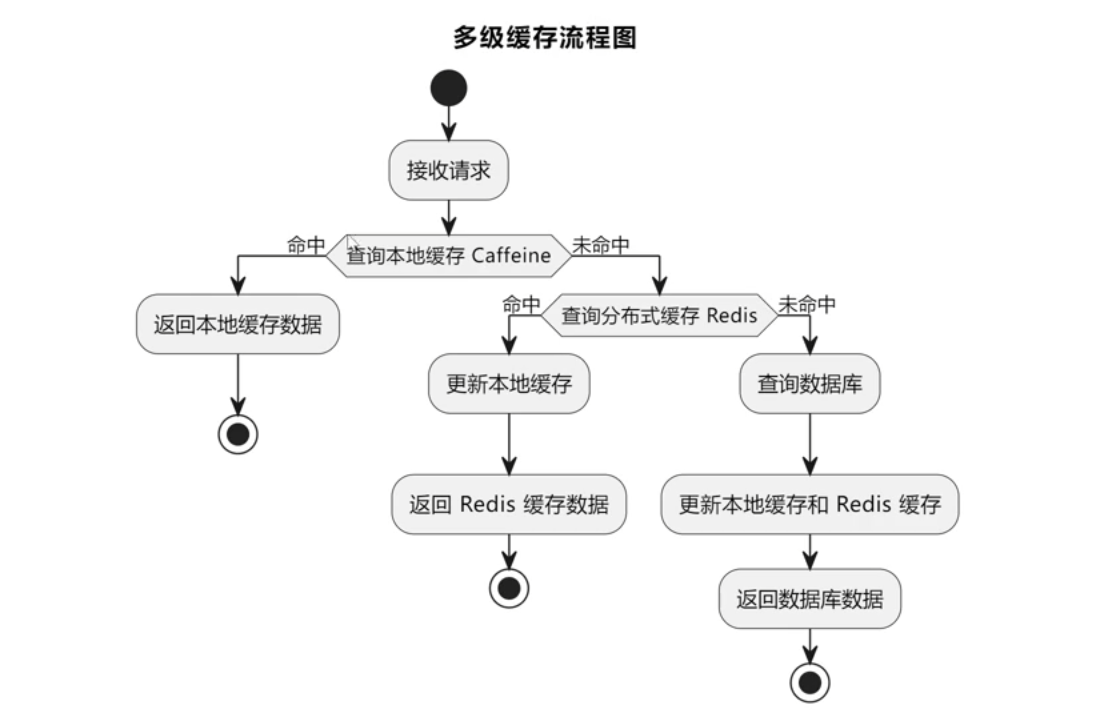
|
||||
|
||||
|
||||
|
||||
## 收获
|
||||
|
||||
### Redis+Session
|
||||
|
||||
之前我们每次重启服务器都要重新登陆,既然已经整合了 `Redis`,不妨使用 `Redis` 管理` Session`,更好地维护登录态。
|
||||
|
||||
1)先在 `Maven `中引入 `spring-session-data-redis` 库:
|
||||
|
||||
```xml
|
||||
<!-- Spring Session + Redis -->
|
||||
<dependency>
|
||||
<groupId>org.springframework.session</groupId>
|
||||
<artifactId>spring-session-data-redis</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
2)修改 `application.yml` 配置文件,更改`Session`的存储方式和过期时间:
|
||||
|
||||
既要设置redis能存30天,发给前端的cookie也要30天有效期。
|
||||
|
||||
```
|
||||
spring:
|
||||
# session 配置
|
||||
session:
|
||||
store-type: redis
|
||||
# session 30 天过期
|
||||
timeout: 2592000
|
||||
server:
|
||||
port: 8123
|
||||
servlet:
|
||||
context-path: /api
|
||||
# cookie 30 天过期
|
||||
session:
|
||||
cookie:
|
||||
max-age: 2592000
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 为什么用 `ConcurrentHashMap<Long,Object>` 管理锁更优?
|
||||
|
||||
1. **避免污染常量池**
|
||||
`String.intern()` 会把每一个不同的 `userId` 字符串都放到 JVM 的字符串常量池里,随着用户量增长,常量池里的内容会越来越多,可能导致元空间(MetaSpace)/永久代(PermGen)压力过大。
|
||||
2. **显式可控的锁生命周期**
|
||||
- 用 `ConcurrentHashMap` 明确地管理——「只要 map 里有这个 key,就有对应的锁对象;不需要时可以删掉。」
|
||||
- 相比之下,`intern()` 后的字符串对象由 JVM 常量池管理,代码里很难清理,存在内存泄漏风险。
|
||||
3. **高并发性能更好**
|
||||
- `ConcurrentHashMap` 内部采用分段锁或 Node 锁定(取决于 JDK 版本),即便高并发下往 map 里 `computeIfAbsent` 也能保持较高吞吐。
|
||||
- `synchronized (lock)` 本身只锁定单个用户对应的那把锁,不影响其他用户;结合 `ConcurrentHashMap` 的高并发特性,整体性能比直接在一个全局 `HashMap` + `synchronized` 好得多。
|
||||
|
||||
|
||||
|
||||
### 锁+事务可能出现的问题
|
||||
|
||||
**`@Transactional`(声明式)**
|
||||
|
||||
- 事务在方法入口打开,很可能在拿锁前就占用连接/数据库资源,导致“空跑事务”+“资源耗尽”。
|
||||
- 依赖代理,存在自调用失效的坑。
|
||||
|
||||
**`transactionTemplate.execute()`(编程式)**
|
||||
|
||||
- 锁先行→事务后发,确保高并发下只有一个连接/事务进数据库,极大降低资源竞争。
|
||||
- 全程显式,放到哪儿就是哪儿,杜绝自调用/代理链带来的隐患。
|
||||
|
||||
|
||||
|
||||
**锁+事务`@Transactional`一起可能出现问题:**
|
||||
|
||||
**线程 A**
|
||||
|
||||
- 进入方法,Spring AOP 拦截,**立即开启事务**
|
||||
- 走到 `synchronized(lock)`,拿到锁
|
||||
- 在锁里执行 `exists` → `save`(但真正的 “提交” 要等到方法返回后才做)
|
||||
- 退出 `synchronized` 块,方法继续执行(其实已经没别的逻辑了)
|
||||
- 方法返回,事务拦截器这时才 **提交**
|
||||
|
||||
**线程 B**(并发进来)
|
||||
|
||||
- 等待 AOP 代理,进入同一个方法,**也会马上开启自己的事务**
|
||||
- 在入口就拿到一个新的连接/事务上下文
|
||||
- 然后遇到 `synchronized(lock)`,**在这里阻塞** 等 A 释放锁
|
||||
- A 一旦走出 `synchronized`,B 立刻拿到锁——但此时 A **还没真正提交**(提交在方法尾被拦截器做)
|
||||
- B 在锁里执行 `exists`:因为 A 的改动还在 A 的未提交事务里,**默认隔离级别(READ_COMMITTED)下看不到**,所以 `exists` 会返回 `false`
|
||||
- B 就继续 `save`,结果就可能插入重复记录,或者引发唯一索引冲突
|
||||
|
||||
|
||||
@ -831,7 +831,7 @@ networks:
|
||||
4. 执行分页查询,例如,假设每页显示 10 条记录,你请求第 2 页数据,那么 SQL 语句会变成:
|
||||
|
||||
```mysql
|
||||
select * from emp limit 10, 10;
|
||||
select * from emp limit 10, 10; #跳过前10条数据,请求接下来的10条,即第2页数据
|
||||
```
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user