Commit on 2025/03/24 周一 16:34:35.02
This commit is contained in:
parent
c6f87f0fce
commit
84af1dfe8a
@ -1085,7 +1085,7 @@ public interface EmpMapper {
|
||||
|
||||
1. resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
|
||||
|
||||
2. ```
|
||||
2. ```text
|
||||
<?xml version="1.0" encoding="UTF-8" ?>
|
||||
<!DOCTYPE mapper
|
||||
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
|
||||
@ -1093,11 +1093,13 @@ public interface EmpMapper {
|
||||
<mapper namespace="edu.whut.mapper.EmpMapper">
|
||||
|
||||
</mapper>
|
||||
```text
|
||||
|
||||
|
||||
XML映射文件的namespace属性为Mapper接口**全限定名**(包+类名)
|
||||
```
|
||||
|
||||
3. ```
|
||||
|
||||
|
||||
3. ```text
|
||||
<select id="list" resultType="edu.whut.pojo.Emp">
|
||||
select * from emp
|
||||
where name like concat('%',#{name},'%')
|
||||
|
||||
@ -291,20 +291,18 @@ for (int i = 0; i < list.size(); i++) {
|
||||
|
||||
|
||||
|
||||
#### **二维数组**
|
||||
#### `二维数组`
|
||||
|
||||
```text
|
||||
int rows = 3;
|
||||
int cols = 3;
|
||||
int[][] array = new int[rows][cols];
|
||||
|
||||
// 填充数据
|
||||
for (int i = 0; i < rows; i++) {
|
||||
for (int j = 0; j < cols; j++) {
|
||||
array[i][j] = i * cols + j + 1;
|
||||
}
|
||||
}
|
||||
|
||||
//创建并初始化
|
||||
int[][] array = {
|
||||
{1, 2, 3},
|
||||
@ -312,7 +310,6 @@ int[][] array = {
|
||||
{7, 8, 9}
|
||||
};
|
||||
|
||||
|
||||
// 遍历二维数组,不知道几行几列
|
||||
public void setZeroes(int[][] matrix) {
|
||||
// 遍历每一行
|
||||
@ -328,6 +325,7 @@ public void setZeroes(int[][] matrix) {
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### **`HashSet`**
|
||||
|
||||
- 基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1)。
|
||||
|
||||
71
Java/草稿.md
71
Java/草稿.md
@ -18,7 +18,7 @@ git clone地址:http://47.98.59.178:3000/zy123/zbparse.git
|
||||
|
||||
## 项目启动与维护:
|
||||
|
||||
|
||||
|
||||
|
||||
.env存放一些密钥(大模型、textin等),它是gitignore忽略了,因此在服务器上git pull项目的时候,这个文件不会更新(因为密钥比较重要),需要手动维护服务器相应位置的.env。
|
||||
|
||||
@ -28,7 +28,7 @@ git clone地址:http://47.98.59.178:3000/zy123/zbparse.git
|
||||
|
||||
1. 进入项目文件夹
|
||||
|
||||

|
||||

|
||||
|
||||
**注意:**需要确认.env是否存在在服务器,默认是隐藏的
|
||||
输入cat .env
|
||||
@ -54,7 +54,7 @@ requirements.txt一般无需变动,除非代码中使用了新的库,也要
|
||||
|
||||
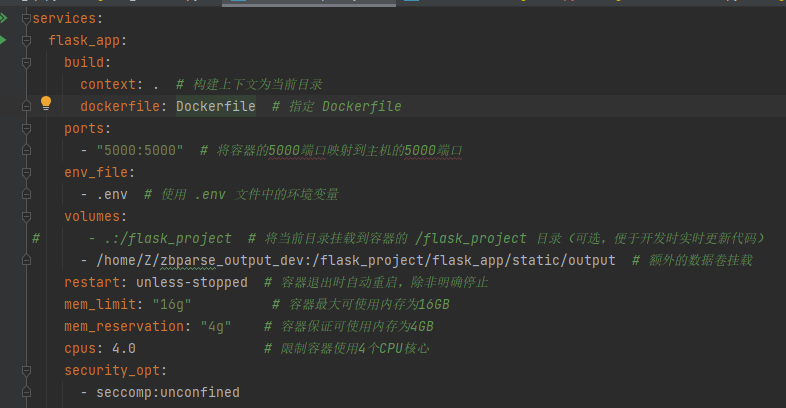
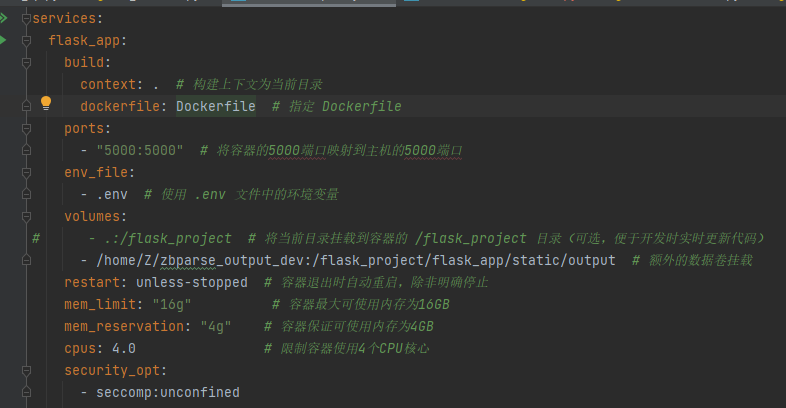
**docker-compose:**
|
||||
|
||||
|
||||
|
||||
|
||||
本项目为**单服务项目**,只有flask_app(服务名)
|
||||
|
||||
@ -67,7 +67,7 @@ build context(`context: .`):
|
||||
|
||||
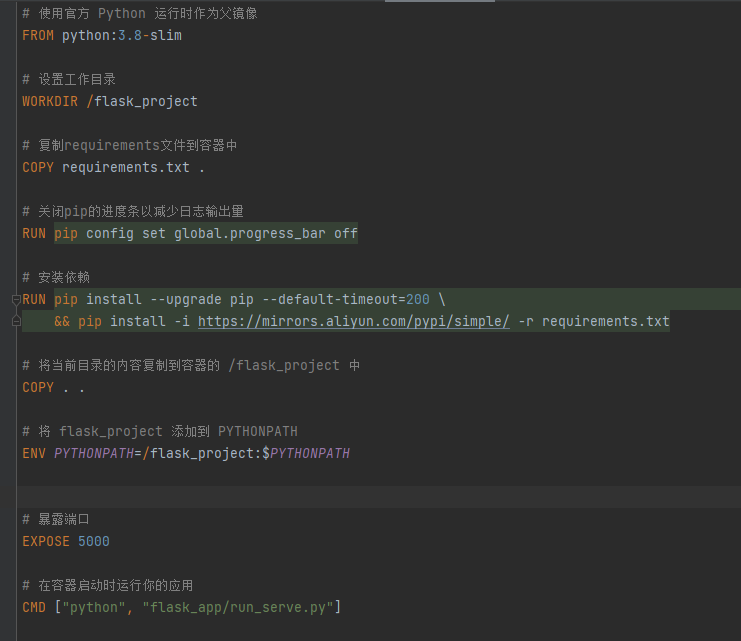
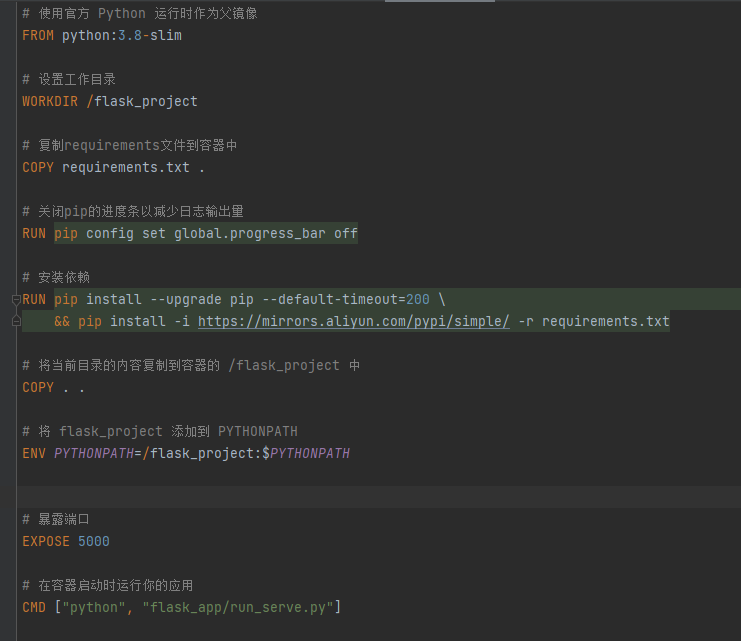
**dockerfile:**
|
||||
|
||||
|
||||
|
||||
|
||||
COPY . .(在 Dockerfile 中):
|
||||
这条指令会将构建上下文中的所有内容复制到镜像中的当前工作目录(这里是 `/flask_project`)。
|
||||
@ -138,7 +138,7 @@ docker image prune
|
||||
2. .env环境配好 (一般不需要在电脑环境变量中额外配置了,但是要在Pycharm中**安装插件**,使得项目在**启动时**能将env中的环境变量**自动配置**到系统环境变量中!!!)
|
||||
3. 点击下拉框,Edit configurations
|
||||
|
||||

|
||||

|
||||
|
||||
设置run_serve.py为启动脚本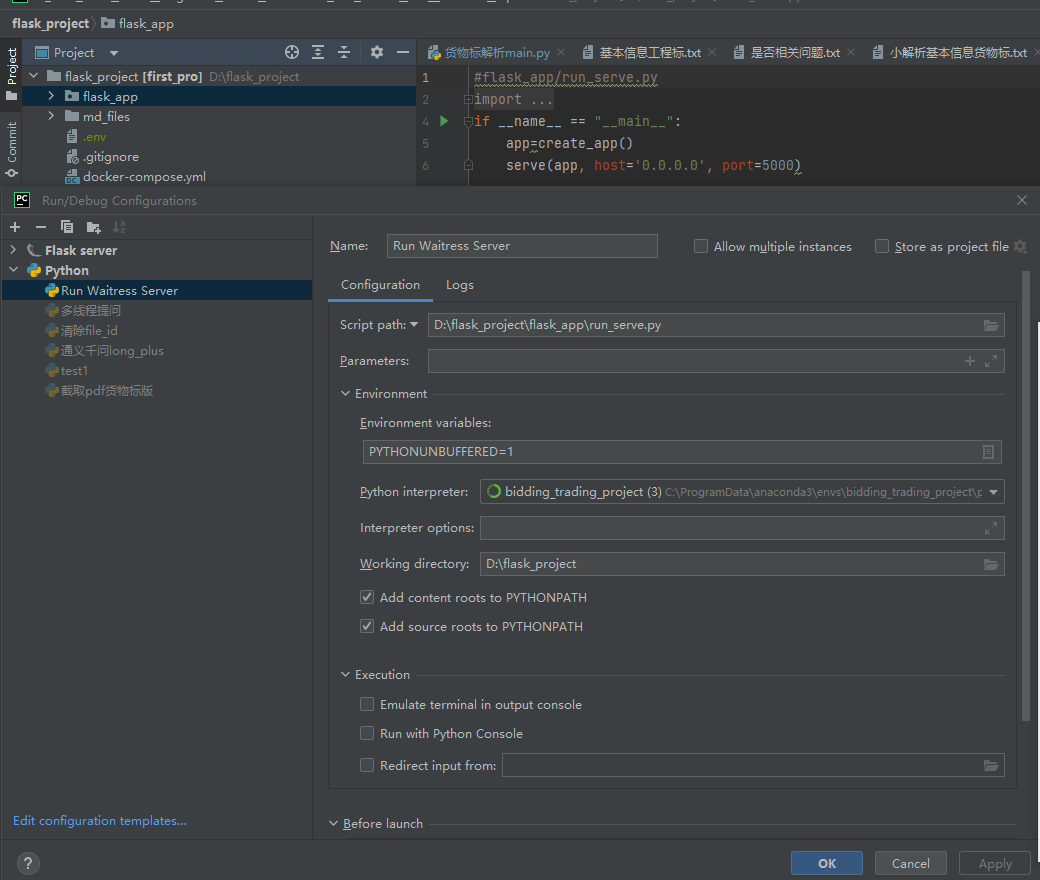
|
||||
注意这里的working directory要设置到最外层文件夹,而不是flask_app!!!
|
||||
@ -189,6 +189,7 @@ python flask_app\run_serve.py
|
||||
打开系统环境变量Path,添加一条:C:\ProgramData\anaconda3\condabin
|
||||
|
||||
或者 CMD 中 set PATH=%PATH%;新添加的路径
|
||||
```text
|
||||
```
|
||||
|
||||
- 重启终端可以刷新环境变量
|
||||
@ -290,7 +291,7 @@ sudo chmod +x ./clean_dir.sh
|
||||
sudo ./clean_dir.sh
|
||||
```
|
||||
|
||||
**4.以 root 用户的身份编辑 crontab 文件**,从而设置或修改系统定时任务(cron jobs)。每天零点10分清理
|
||||
**以 root 用户的身份编辑 crontab 文件**,从而设置或修改系统定时任务(cron jobs)。每天零点10分清理
|
||||
|
||||
```text
|
||||
sudo crontab -e
|
||||
@ -407,7 +408,7 @@ mem_after = memory_usage()[0]
|
||||
|
||||
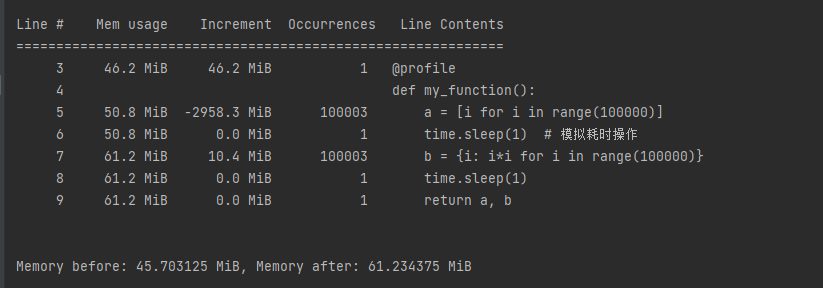
memory_usage()[0] 可以获取当前程序所占内存的**快照**
|
||||
|
||||
|
||||
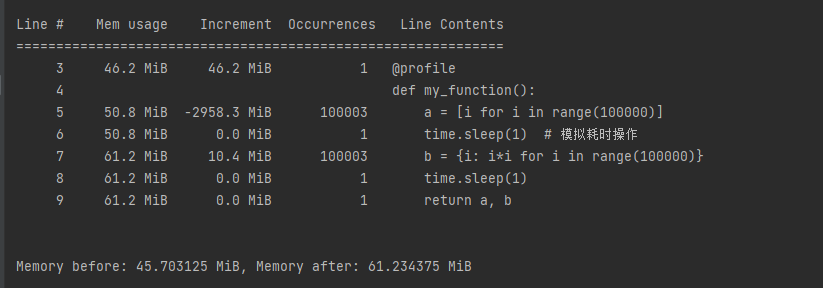
|
||||
|
||||
产生的数据都存到result变量-》内存中,这是正常的,因此my_function没有内存泄漏问题。
|
||||
**但是**
|
||||
@ -426,7 +427,7 @@ def extract_text_by_page(file_path):
|
||||
return ""
|
||||
```
|
||||
|
||||

|
||||
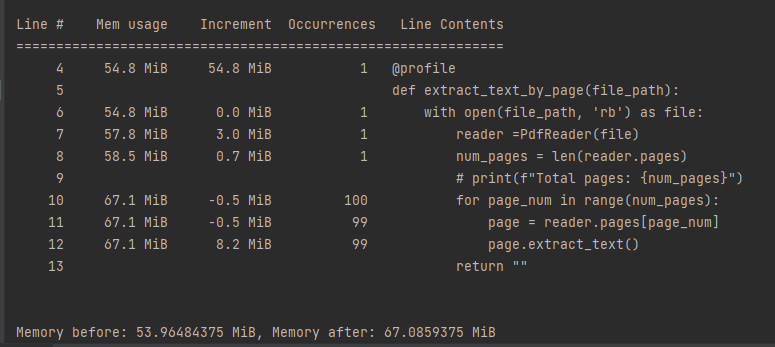
|
||||
|
||||
可以发现尽管我返回"",内存仍然没有释放!因为就是读取pdf这块发生了内存泄漏!
|
||||
|
||||
@ -464,7 +465,7 @@ for stat in stats[:10]:
|
||||
tracemalloc.stop()
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
tracemalloc能更深入的分析,不仅是自己写的代码,**调用的库函数**产生的内存也能分析出来。在这个例子中就是PyPDF2中的各个函数占用了大部分内存。
|
||||
|
||||
@ -565,7 +566,7 @@ def judge_zbfile_exec_sub(file_path):
|
||||
|
||||
但是存在一个问题:**第一次发送请求执行时间较慢!**
|
||||
|
||||
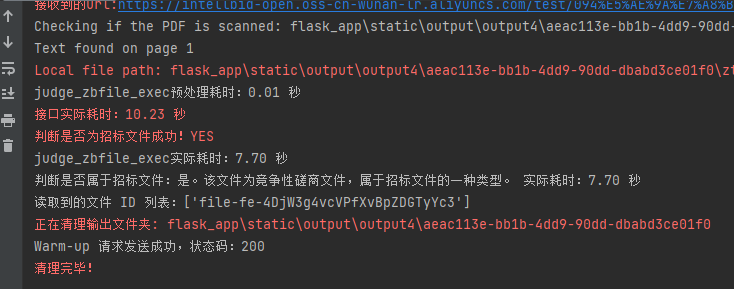
|
||||
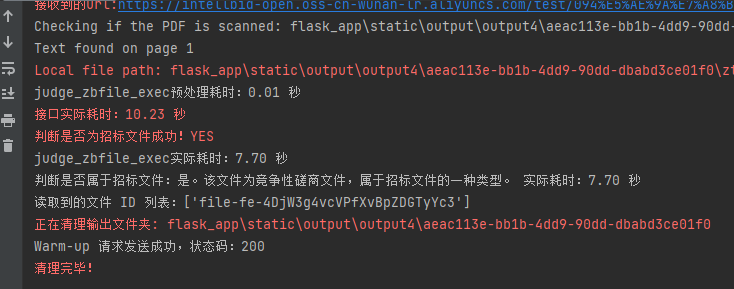
|
||||
|
||||
可以发现实际执行只需7.7s,但是接口实际耗时10.23秒,主要是因**懒加载或按需初始化**:有些模块或资源在子进程启动时并不会马上加载,而是在子进程首次真正执行任务时才进行初始化。
|
||||
|
||||
@ -596,7 +597,7 @@ threading.Thread(target=warmup_request, daemon=True).start()
|
||||
|
||||
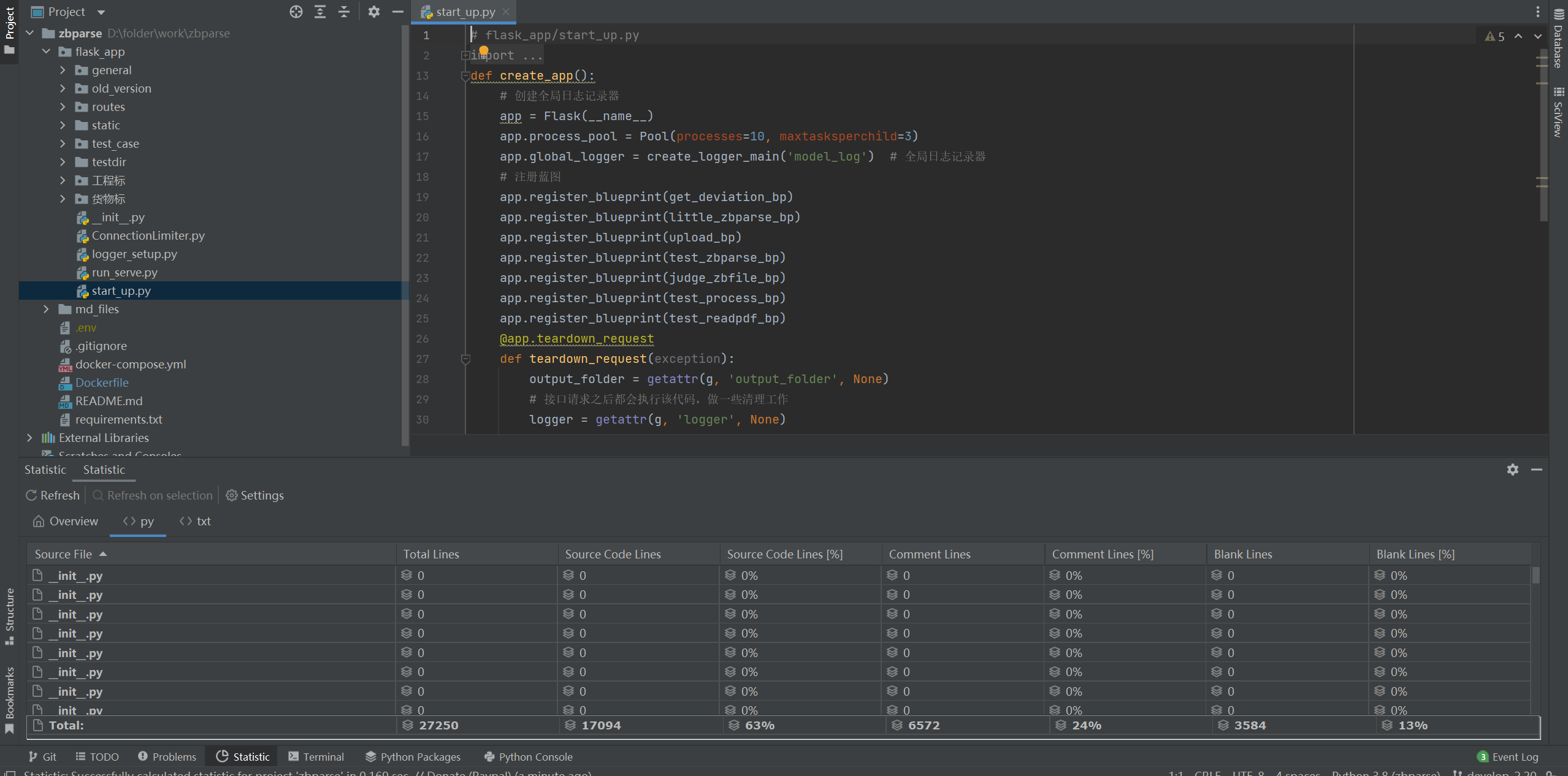
## flask_app结构介绍
|
||||
|
||||
<img src="https://pic.bitday.top/i/2025/03/24/io7n4q-2.png" alt="1" style="zoom:67%;" />
|
||||
<img src="https://pic.bitday.top/i/2025/03/24/qlfii1-0.png" alt="1" style="zoom:67%;" />
|
||||
|
||||
|
||||
|
||||
@ -696,7 +697,7 @@ app.connection_limiters['upload'] = ConnectionLimiter(max_connections=100)
|
||||
|
||||
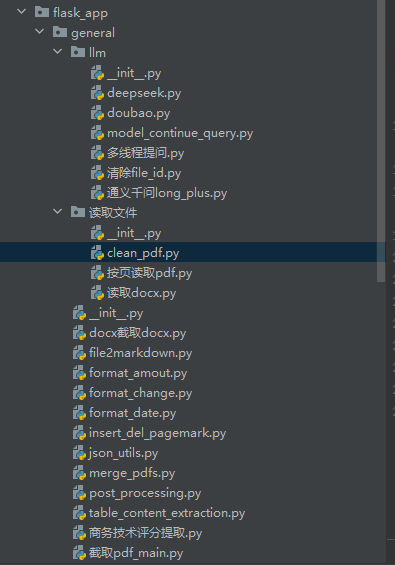
是公共函数存放的文件夹,llm下是各类大模型,读取文件下是docx pdf文件的读取以及文档清理clean_pdf,去页眉页脚页码
|
||||
|
||||
|
||||

|
||||
|
||||
general下的llm下的清除file_id.py 需要**每周运行至少一次**,防止file_id数量超出(我这边对每次请求结束都有file_id记录并清理,向应该还没加)
|
||||
|
||||
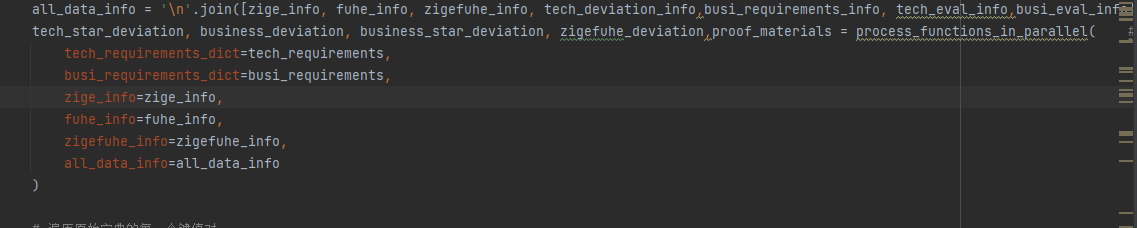
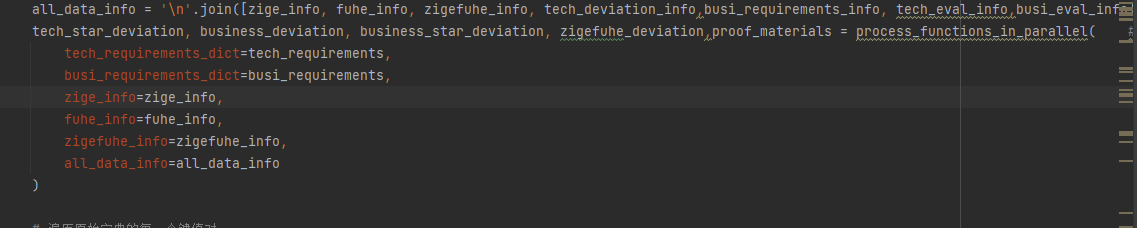
@ -724,7 +725,7 @@ post_processing中的**process_functions_in_parallel**提取
|
||||
|
||||
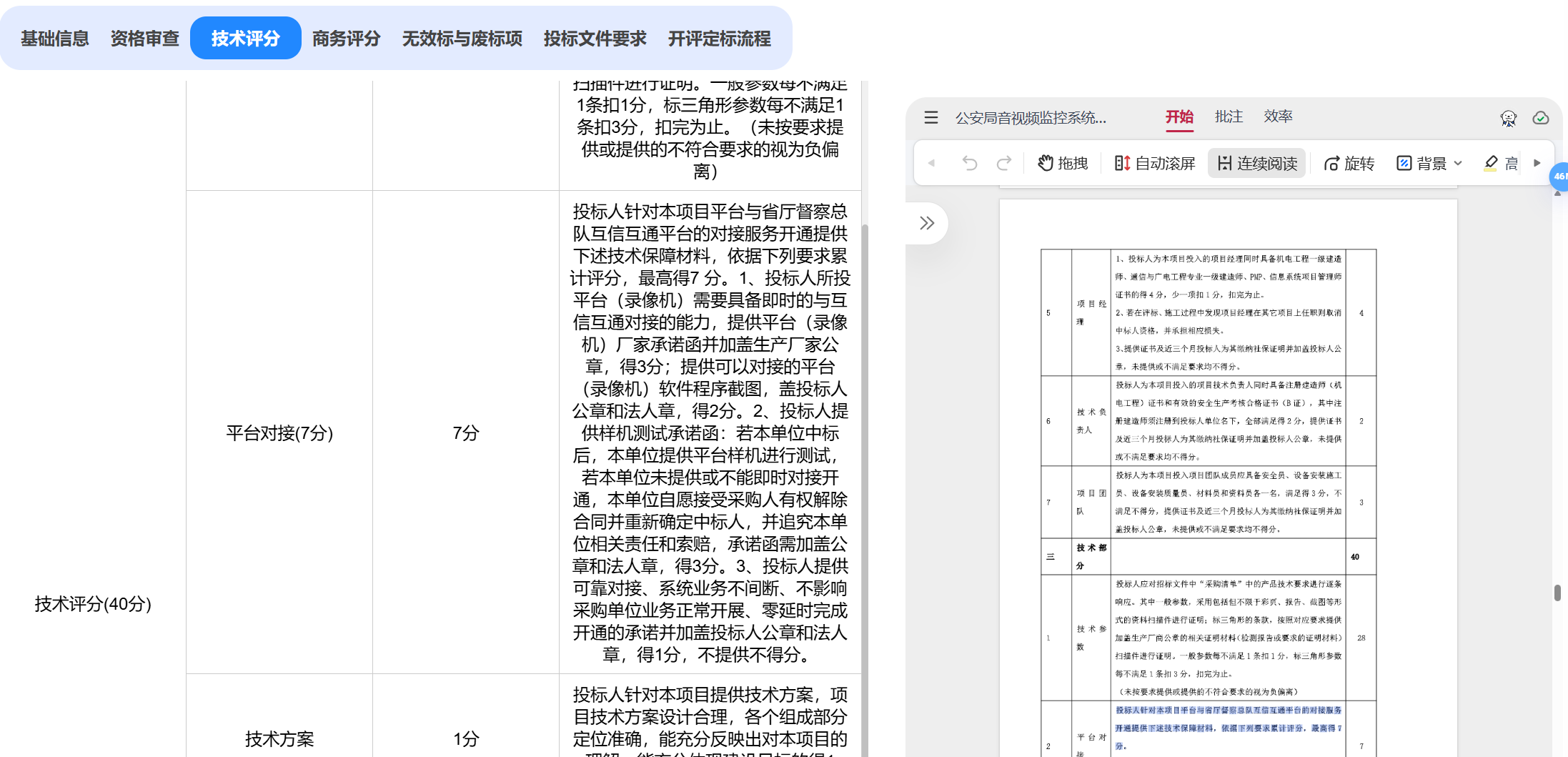
资格审查、技术偏离、 商务偏离、 所需提交的证明材料
|
||||
|
||||
|
||||
|
||||
|
||||
大解析upload用了post_processing完整版,
|
||||
|
||||
@ -754,9 +755,9 @@ get_deviation.py、偏离表数据解析main.py用了process_functions_in_parall
|
||||
|
||||
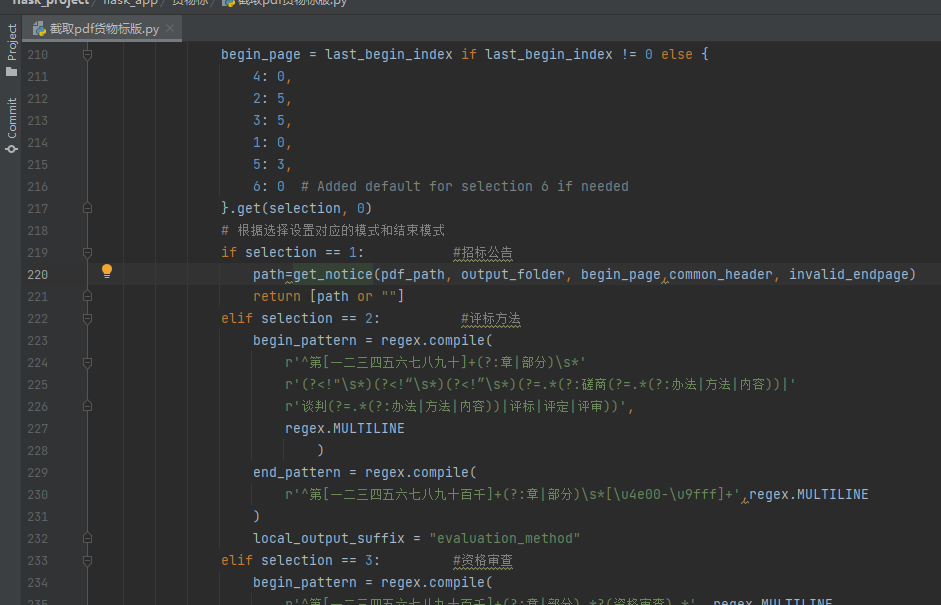
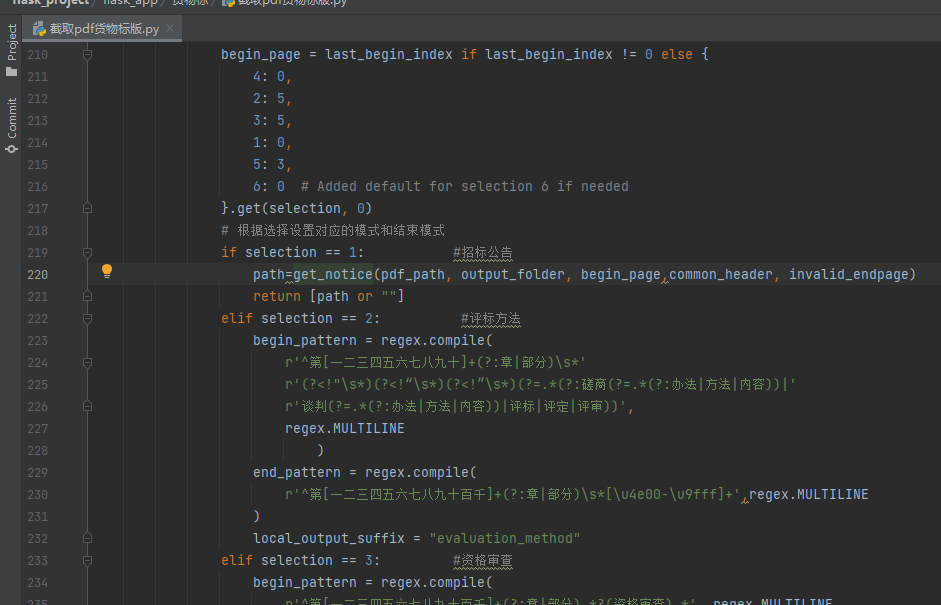
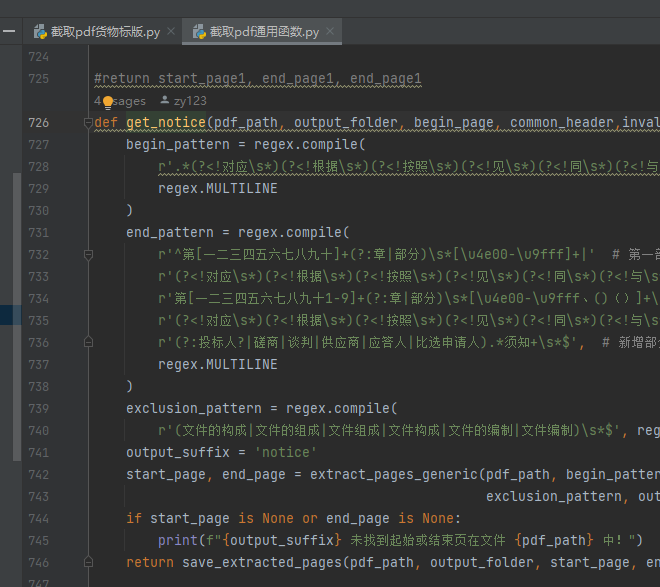
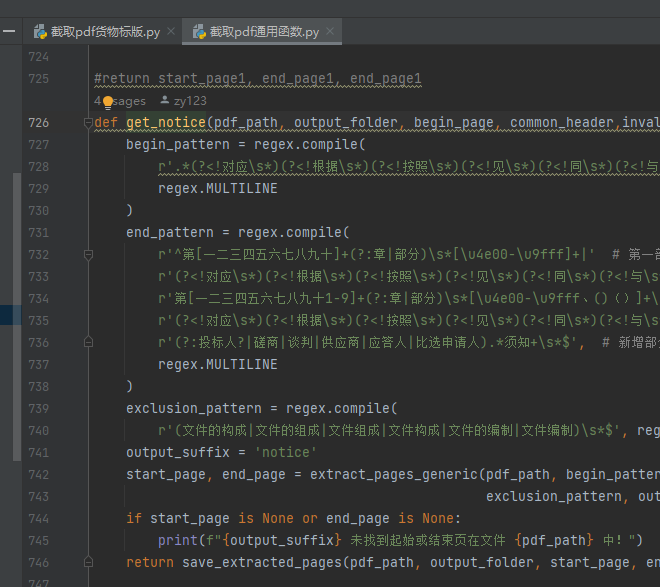
若开头没截准,就改begin_pattern,末尾没截准,就改end_pattern
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
另外:在*截取pdf货物标版*.py中,还有extract_pages_twice函数,即第一次没有切分到之后,会运行该函数,这边又有一套begin_pattern和end_pattern,即二次提取
|
||||
|
||||
@ -764,7 +765,7 @@ get_deviation.py、偏离表数据解析main.py用了process_functions_in_parall
|
||||
|
||||
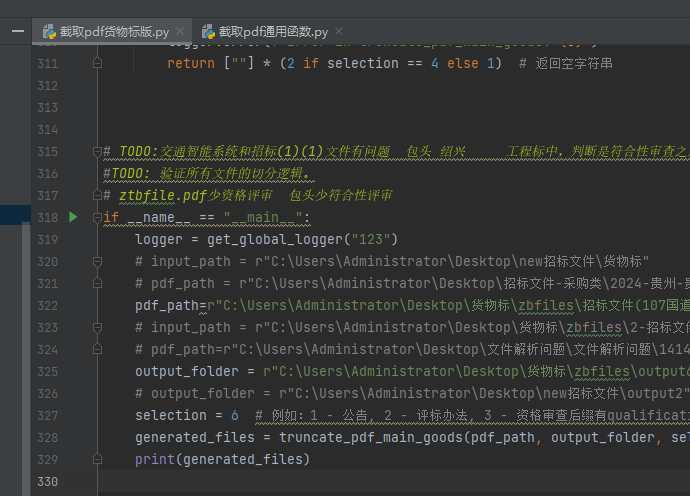
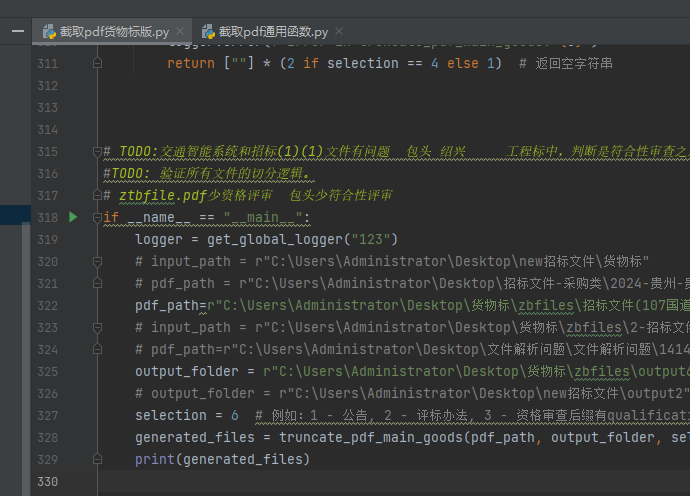
**如何测试?**
|
||||
|
||||
|
||||
|
||||
|
||||
输入pdf_path,和你要切分的序号,selection=1代表切公告,依次类推,可以看切出来的效果如何。
|
||||
|
||||
@ -777,7 +778,7 @@ get_deviation.py、偏离表数据解析main.py用了process_functions_in_parall
|
||||
|
||||
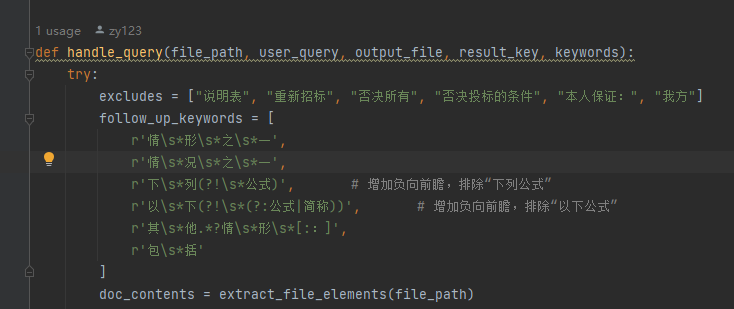
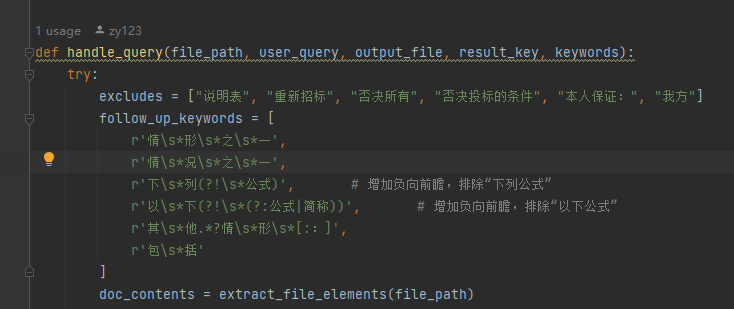
这里:如果段落中既被正则匹配,又被follow_up_keywords中的任意一个匹配,那么不会添加到temp中(即不会被大模型筛选),它会**直接添加**到最后的返回中!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -795,7 +796,7 @@ get_deviation.py、偏离表数据解析main.py用了process_functions_in_parall
|
||||
|
||||
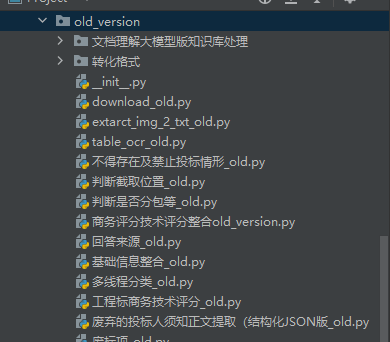
都是废弃文件代码,未在正式、测试环境中使用的,不用管
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -803,7 +804,7 @@ get_deviation.py、偏离表数据解析main.py用了process_functions_in_parall
|
||||
|
||||
是接口以及主要实现部分,一一对应
|
||||
|
||||
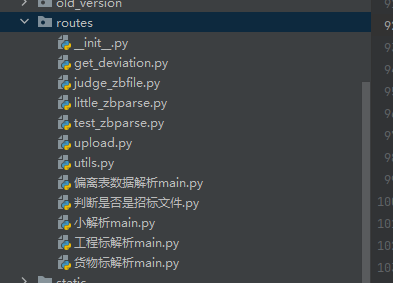
|
||||
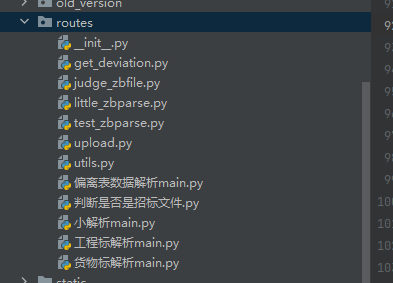
|
||||
|
||||
get_deviation对应偏离表数据解析main,获得偏离表数据
|
||||
|
||||
@ -823,7 +824,7 @@ upload对应工程标解析和货物标解析,即大解析
|
||||
|
||||
utils是接口这块的公共功能函数。其中validate_and_setup_logger函数对不同的接口请求对应到不同的output文件夹,如upload->output1。后续增加接口也可直接在这里写映射关系。
|
||||
|
||||
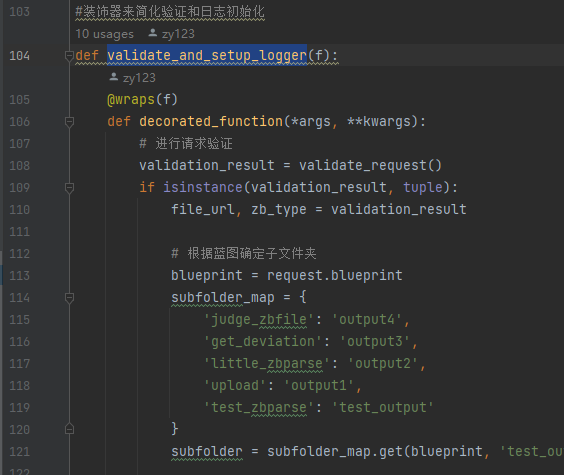
|
||||
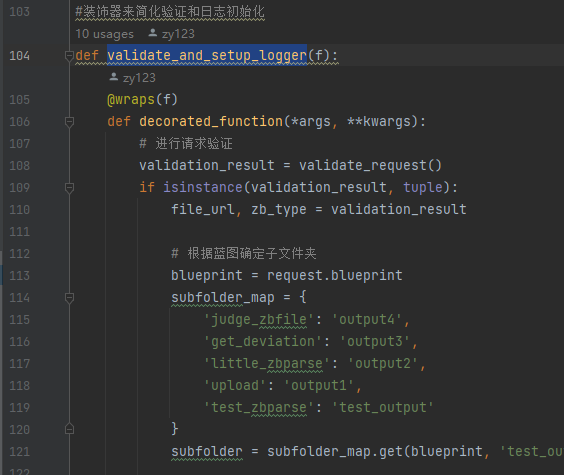
|
||||
|
||||
重点关注大解析:**upload.py**和**货物标解析main.py**
|
||||
|
||||
@ -837,7 +838,7 @@ utils是接口这块的公共功能函数。其中validate_and_setup_logger函
|
||||
|
||||
各个文件夹(output1 output2..)对应不同的接口请求
|
||||
|
||||
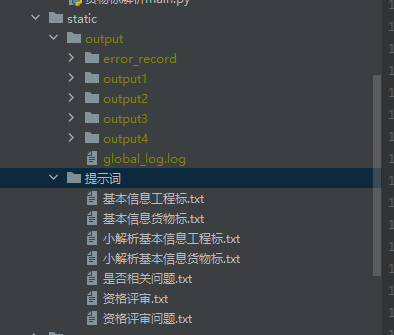
|
||||
|
||||
|
||||
|
||||
|
||||
@ -849,7 +850,7 @@ testdir是平时写代码的测试的地方
|
||||
|
||||
它们都不影响正式和测试环境的解析
|
||||
|
||||
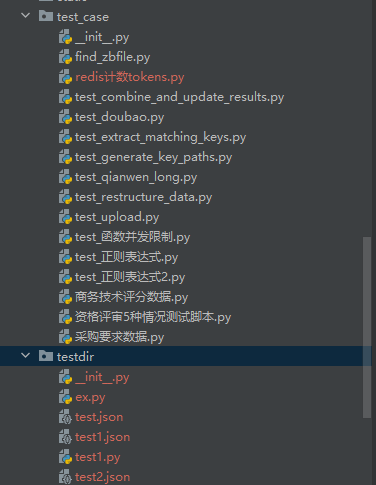
|
||||
|
||||
|
||||
|
||||
|
||||
@ -857,7 +858,7 @@ testdir是平时写代码的测试的地方
|
||||
|
||||
是两个解析流程中不一样的地方(一样的都写在**general**中了)
|
||||
|
||||
|
||||
|
||||
|
||||
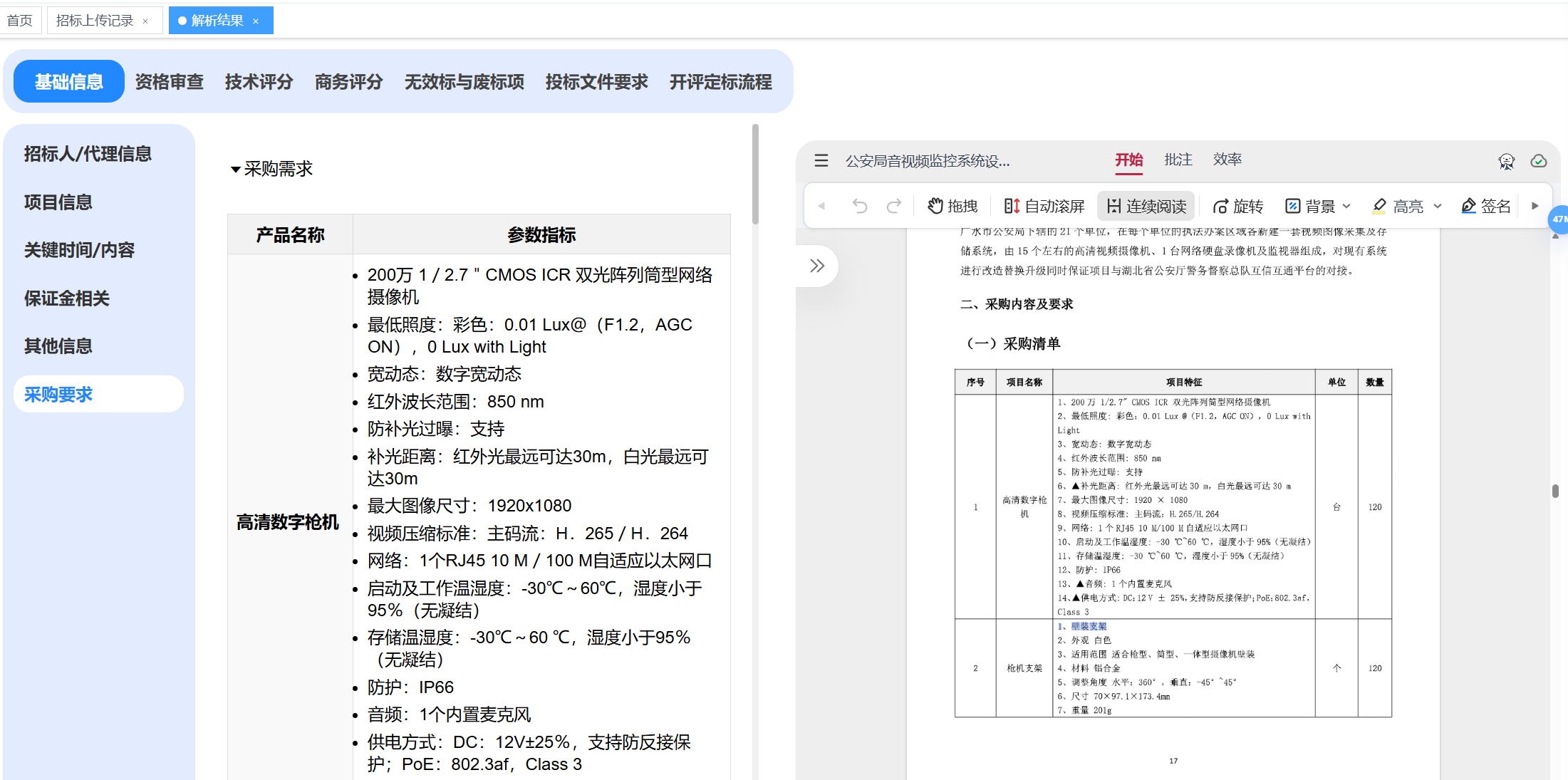
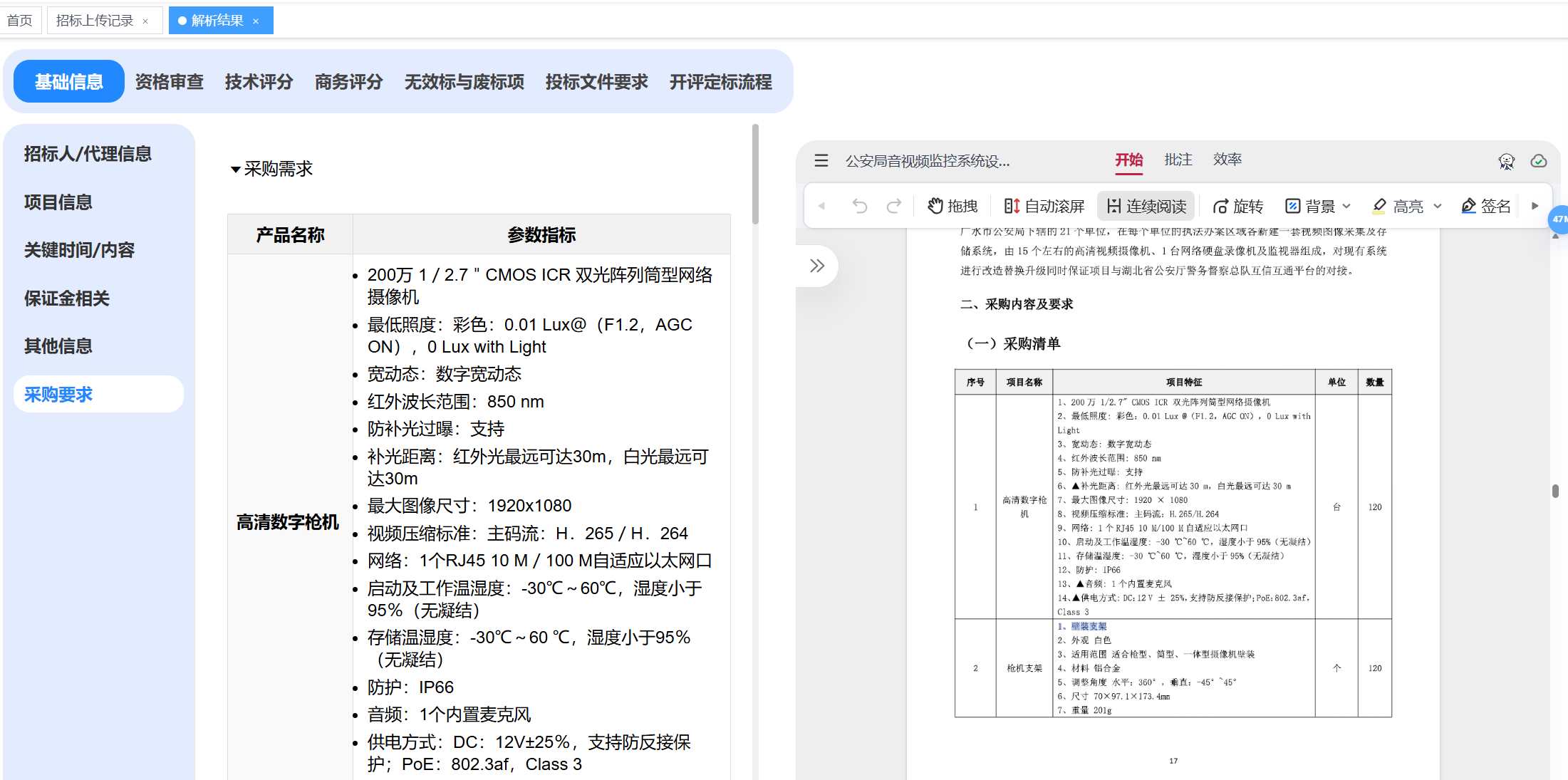
主要是货物标额外解析了采购要求(提取采购需求main+技术参数要求提取+商务服务其他要求提取)
|
||||
|
||||
@ -867,7 +868,7 @@ testdir是平时写代码的测试的地方
|
||||
|
||||
ConnectionLimiter.py定义了接口超时时间->超时后断开与后端的连接
|
||||
|
||||
|
||||
|
||||
|
||||
logger_setup.py 为每个请求创建单独的log,每个log对应一个log.txt
|
||||
|
||||
@ -893,13 +894,13 @@ start_up.py是启动脚本,run_serve也是启动脚本,是对start_up.py的
|
||||
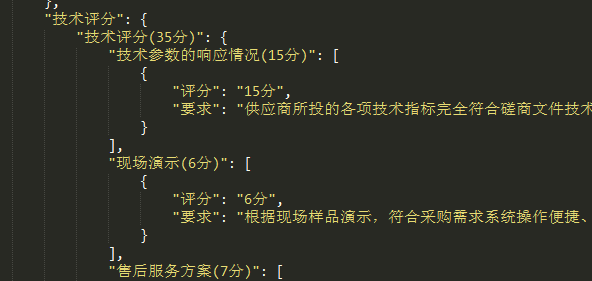
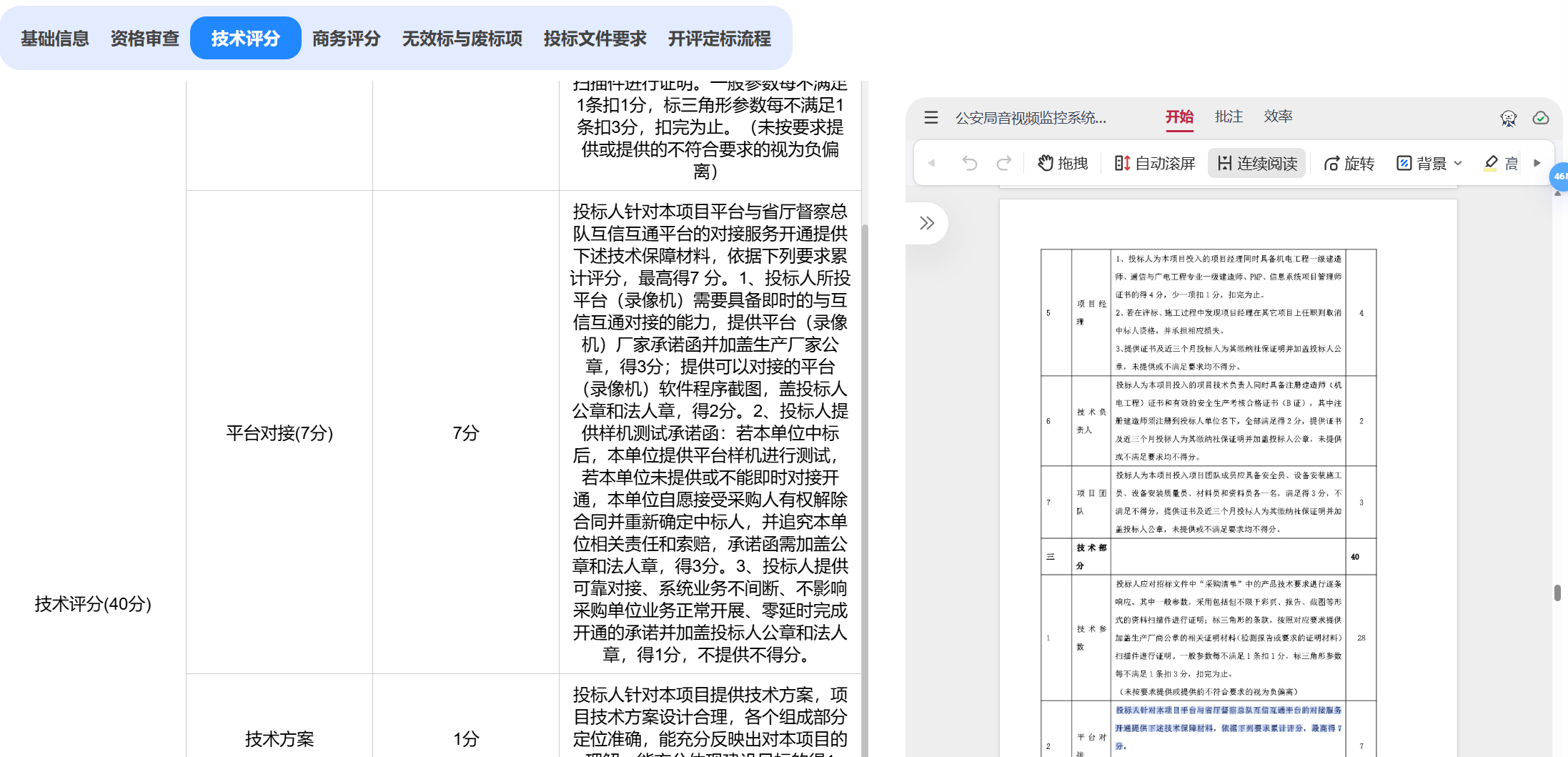
2. 大解析中返回了技术评分,后端接收后不仅显示给前端,还会返给向,用于生成技术偏离表
|
||||
3. 小解析时,get_deviation.py其实也可以返回技术评分,但是没有返回,因为没人和我对接,暂时注释了。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
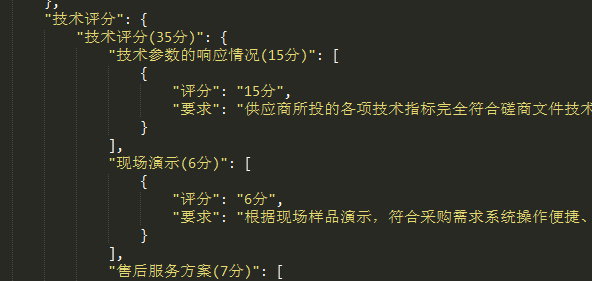
4.商务评议和技术评议偏离表,即评分细则的偏离表,暂时没做,但是**商务评分、技术评分**无论大解析还是小解析都解析了,稍微对该数据处理一下返回给后端就行。
|
||||
|
||||
|
||||
|
||||
|
||||
这个是解析得来的结果,适合给前端展示,但是要生成商务技术评议偏离表的话,需要再调一次大模型,对该数据进行重新归纳,以字符串列表为佳。再传给后端。(未做)
|
||||
|
||||
@ -1211,22 +1212,22 @@ if __name__ == '__main__':
|
||||
|
||||
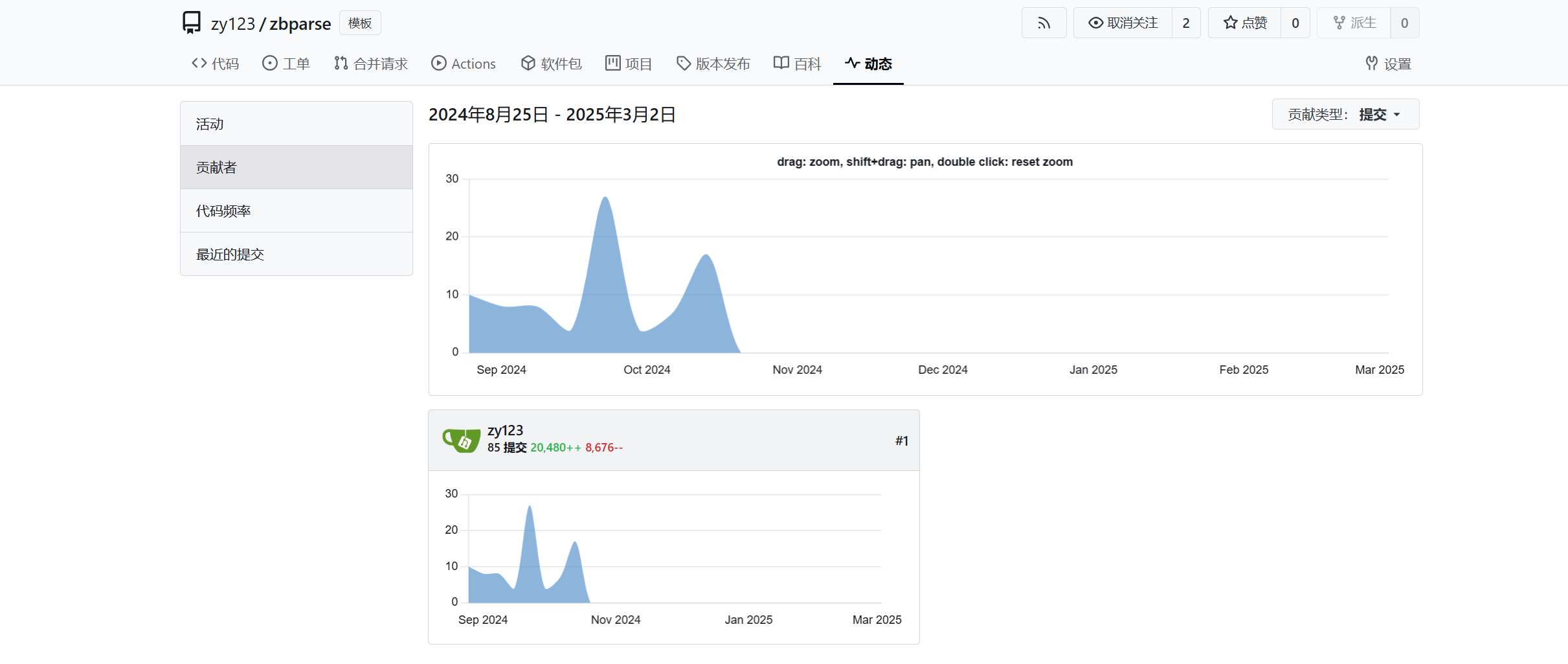
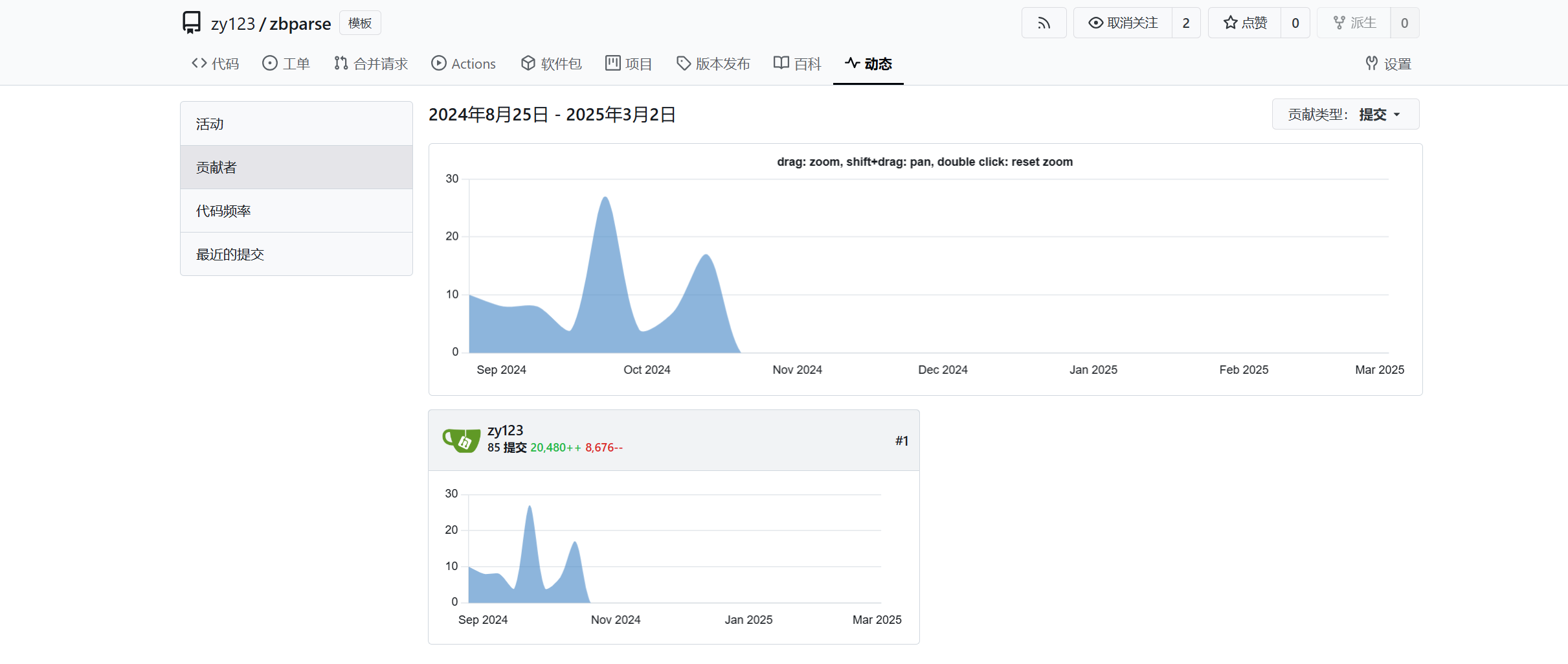
### 项目贡献
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
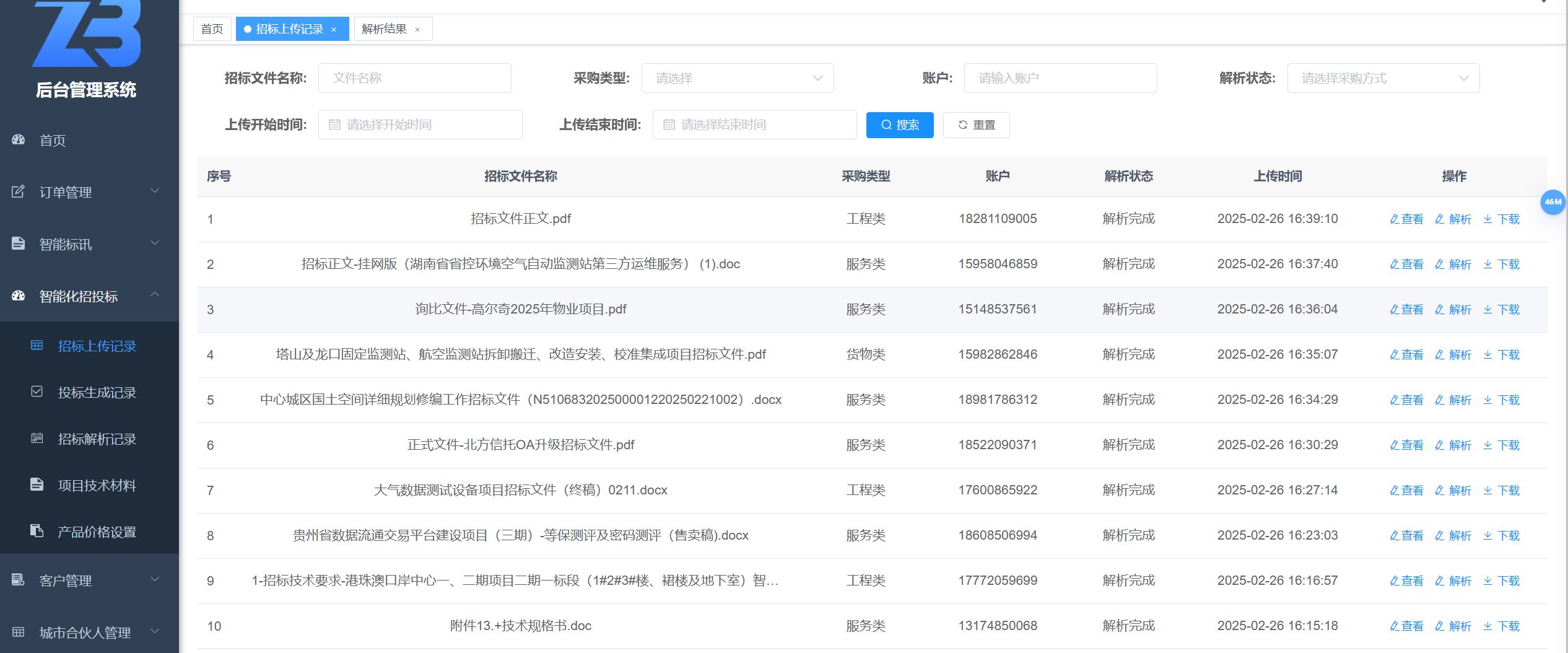
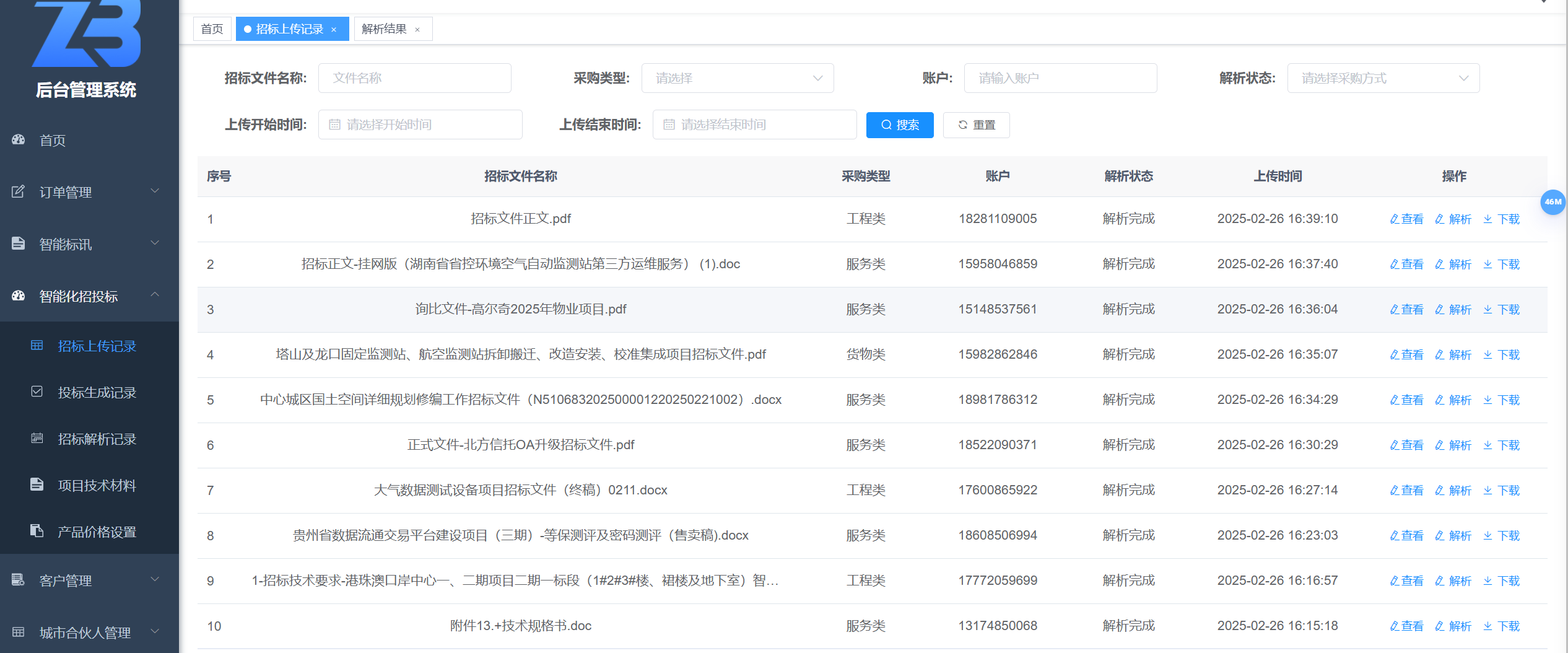
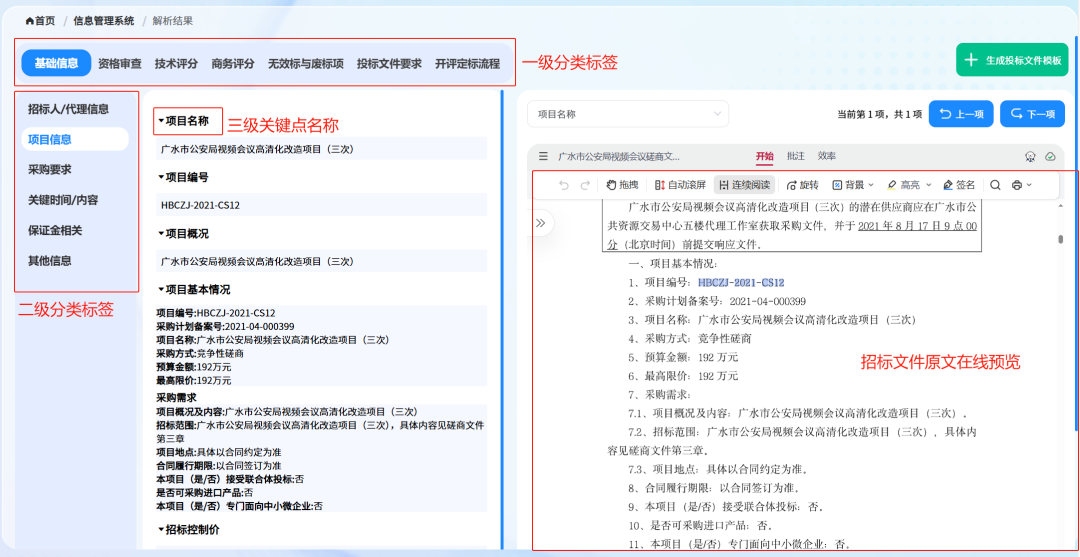
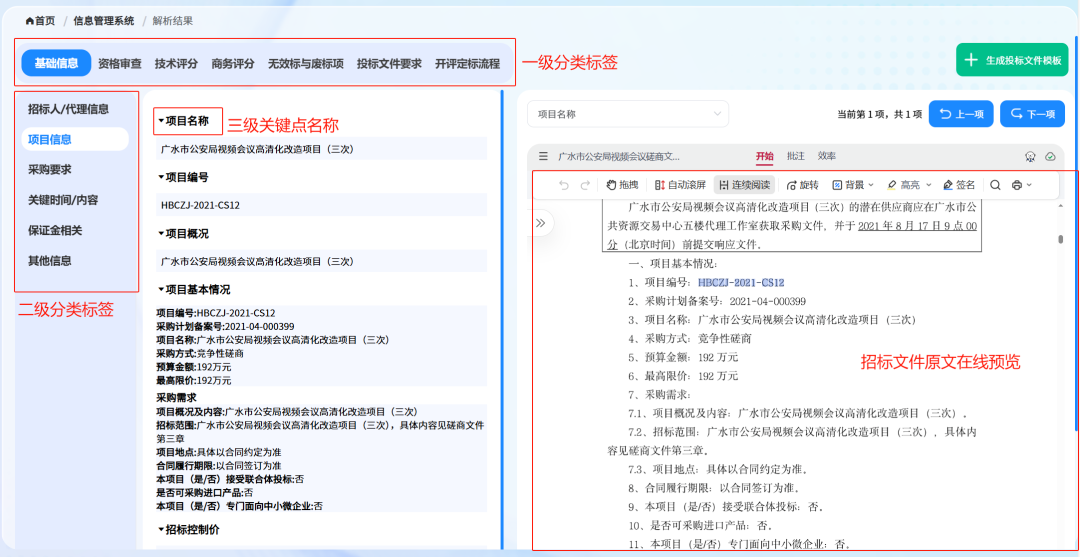
### 效果图
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user