Commit on 2025/06/19 周四 19:56:47.59
This commit is contained in:
parent
68c520ba76
commit
f39c9be12e
@ -1025,3 +1025,14 @@ $$
|
||||

|
||||
|
||||
估计带权邻接矩阵(存在量化误差),比较分布式算法的误差。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### TODO:
|
||||
|
||||
1.SNMF这里的 $\varepsilon$ 还需要额外讨论。
|
||||
|
||||
2.滤波误差没有考虑特征向量扰动误差
|
||||
|
||||
|
||||
130
科研/强化学习.md
130
科研/强化学习.md
@ -55,7 +55,7 @@ $$
|
||||
|
||||
训练结束后,表里每个状态 $s$ 下各动作的 Q 值都相对准确了,我们就可以直接读表来决策:
|
||||
$$
|
||||
\pi(s) = \arg\max_a Q(s,a)
|
||||
\pi(s) = \arg\max_a Q(s,a)
|
||||
$$
|
||||
即“在状态 $s$ 时,选 Q 值最高的动作”。
|
||||
|
||||
@ -342,6 +342,132 @@ $y_i=2.855$,后续会用它与主网络预测值 $Q(s_i,a_i;\theta)$ 计算均
|
||||
|
||||
**核心思路**:将团队 Q 函数写成各智能体局部 Q 的线性和 $Q_{tot}=\sum_{i=1}^{N}\tilde{Q}_i$,在训练时用全局奖励反传梯度,在执行时各智能体独立贪婪决策。
|
||||
|
||||
避免非平稳性:每个智能体看到的“环境”里不再包含 **其他正在同时更新的智能体**——因为所有参数其实在**同一次**反向传播里被一起更新,整体策略变化保持同步;对单个智能体而言,环境动态就不会呈现出随机漂移。
|
||||
|
||||
|
||||
CTDE 指 *Centralized Training, Decentralized Execution* —— **在训练阶段使用集中式的信息或梯度(可以看到全局状态、联合奖励、各智能体的隐藏变量等)来稳定、加速学习;而在执行阶段,每个智能体只依赖自身可获得的局部观测来独立决策**。
|
||||
|
||||
采用 CTDE 的好处:
|
||||
|
||||
部署高效、可扩展:运行时每个体只需本地观测,无需昂贵通信和同步,适合**大规模**或通信受限场景。
|
||||
|
||||
降低非平稳性:每个智能体看到的“环境”里不再包含 **其他正在同时更新的智能体**——因为所有参数其实在**同一次**反向传播里被一起更新,整体策略变化保持同步;对单个智能体而言,环境动态就不会呈现出随机漂移。
|
||||
|
||||
避免“懒惰智能体”:只要某个行动对团队回报有正贡献,它在梯度里就能拿到正向信号,不会因为某个体率先学到高收益行为而使其他个体“无所事事”。
|
||||
|
||||
|
||||
|
||||
### 核心公式与训练方法
|
||||
|
||||
1. **值分解假设**
|
||||
$$
|
||||
Q\bigl((h_1,\dots,h_d),(a_1,\dots,a_d)\bigr)\;\approx\;\sum_{i=1}^{d}\,\tilde{Q}_i(h_i,a_i)
|
||||
$$
|
||||
|
||||
其中 $h_i$ 为第 $i$ 个智能体的历史观测,$a_i$ 为其动作。每个 $\tilde{Q}_i$ 只使用局部信息;训练时通过对联合 $Q$ 的 TD 误差求梯度,再"顺着求和"回传到各 $\tilde{Q}_i$ 。这样既避免了为各智能体手工设计奖励,又天然解决了联合动作空间呈指数爆炸的问题。
|
||||
|
||||
2. **Q-learning 更新**
|
||||
$$
|
||||
Q_{t+1}(s_t,a_t)\;=\;(1-\eta_t)\,Q_{t}(s_t,a_t)\;+\;\eta_t\bigl[r_t+\gamma\max_{a}Q_{t}(s_{t+1},a)\bigr]
|
||||
$$
|
||||
|
||||
论文沿用经典 DQN 的 Q-learning 目标,对 **联合 Q 值** 计算 TD 误差,然后按上式更新;全局奖励 $r_t$ 会在反向传播时自动分摊到各 $\tilde{Q}_i$ 。
|
||||
|
||||
### 训练过程
|
||||
|
||||
使用LSTM:**让智能体在**「只有局部、瞬时观测」**的环境中**记住并利用过去若干步的信息。
|
||||
|
||||
#### 1. 初始化
|
||||
|
||||
| 组件 | 说明 |
|
||||
| :----------------: | :----------------------------------------------------------: |
|
||||
| **在线网络** | 为每个智能体 $i=1\ldots d$ 建立局部 $Q$ 网络 $\widetilde Q_i(h^i,a^i;\theta_i)$。最后一层是 **值分解层**:把所有 $\widetilde Q_i$ 相加得到联合 $Q=\sum_i\widetilde Q_i$ |
|
||||
| **目标网络** | 为每个体复制参数:$\theta_i^- \leftarrow \theta_i$,用于计算贝尔曼目标。 |
|
||||
| **经验回放缓冲区** | 存储元组 $(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$,其中 $\mathbf a_t=(a_t^1,\dots,a_t^d)$。 |
|
||||
| **超参数** | Adam 学习率 $1\times10^{-4}$,折扣 $\gamma$,BPTT 截断长度 8,Eligibility trace $\lambda=0.9$ ;小批量 $B$、目标同步周期 $C$、$\varepsilon$-greedy 初始值等。 |
|
||||
|
||||
> **网络骨架**:Linear (32) → ReLU → LSTM (32) → Dueling (Value + Advantage) 头产生 $\widetilde Q_i$ 。
|
||||
|
||||
---
|
||||
|
||||
#### 2. 与环境交互并存储经验
|
||||
|
||||
0. **局部隐藏状态更新(获得 $h_t^i$)**
|
||||
- **采样观测**
|
||||
$o_t^i \in \mathbb R^{3\times5\times5}$(RGB × 5 × 5 视野)
|
||||
- **线性嵌入 + ReLU**
|
||||
$x_t^i = \mathrm{ReLU}(W_o\,\text{vec}(o_t^i)+b_o),\; W_o\!\in\!\mathbb R^{32\times75}$
|
||||
- **递归更新 LSTM**
|
||||
$h_t^i,c_t^i = \text{LSTM}_{32}(x_t^i,\;h_{t-1}^i,c_{t-1}^i)$
|
||||
(初始 $h_0^i,c_0^i$ 置零;执行期只用本体状态即可)
|
||||
|
||||
1. **动作选择(分散执行)**
|
||||
$$
|
||||
a_t^i=\begin{cases}
|
||||
\text{随机动作}, & \text{概率 } \varepsilon,\\
|
||||
\arg\max_{a}\widetilde Q_i(h_t^i,a;\theta_i), & 1-\varepsilon.
|
||||
\end{cases}
|
||||
$$
|
||||
|
||||
2. **环境反馈**:执行联合动作 $\mathbf a_t$,获得单条 **团队奖励** $r_t$ 以及下一组局部观测 $o_{t+1}^i$。
|
||||
|
||||
- **重要**:此处不要直接把 $h_{t+1}^i$ 写入回放池,而是存下 $(h_t^i, a_t^i, r_t, o_{t+1}^i)$。
|
||||
之后在训练阶段再用同样的“Step 0” 方式,离线地把 $o_{t+1}^i\rightarrow h_{t+1}^i$。
|
||||
这样可避免把梯度依赖塞进经验池。
|
||||
|
||||
3. **写入回放池**:$(h_t, \mathbf a_t, r_t, o_{t+1}) \rightarrow \mathcal D$。
|
||||
|
||||
---
|
||||
|
||||
#### 3. 批量随机采样并联合训练
|
||||
|
||||
对缓冲区达到阈值后,每次更新步骤:
|
||||
|
||||
1. **采样** $B$ 条长度为 $L$ 的序列。
|
||||
|
||||
- 假设抽到第 $k$ 条序列的第一个索引是 $t$。
|
||||
|
||||
- 依次取出连续的 $(h_{t+j}, a_{t+j}, r_{t+j}, o_{t+j+1}), j=0, \ldots, L-1$。
|
||||
|
||||
- 先用存储的 $o_{t+j+1}$ 离线重放"Step 0"得到 $h_{t+j+1}$,这样序列就拥有 $(h_{t+j}, h_{t+j+1})$
|
||||
|
||||
|
||||
|
||||
2. **前向计算**
|
||||
$$
|
||||
\hat Q_i^{(k)} = \widetilde Q_i(h^{i,(k)}_t,a^{i,(k)}_t;\theta_i),
|
||||
\quad
|
||||
\hat Q^{(k)}=\sum_{i}\hat Q_i^{(k)} .
|
||||
$$
|
||||
|
||||
3. **贝尔曼目标(用目标网络)**
|
||||
$$
|
||||
y^{(k)} = r^{(k)} + \gamma \sum_{i}\max_{a}\widetilde Q_i(h^{i,(k)}_{t+1},a;\theta_i^-).
|
||||
$$
|
||||
|
||||
4. **损失**
|
||||
$$
|
||||
L=\frac1B\sum_{k=1}^{B}\bigl(y^{(k)}-\hat Q^{(k)}\bigr)^2 .
|
||||
$$
|
||||
|
||||
5. **梯度反传(自动信用分配)**
|
||||
因为 $\hat Q=\sum_i\widetilde Q_i$,对每个 $\widetilde Q_i$ 的梯度系数恒为 1,
|
||||
整个 **团队 TD 误差** 直接回流到各体网络,无需个体奖励设计 。
|
||||
|
||||
6. **参数更新**:$\theta_i \leftarrow \theta_i-\eta\nabla_{\theta_i}L$。
|
||||
|
||||
---
|
||||
|
||||
#### 4. 同步 / 软更新目标网络
|
||||
|
||||
- **硬同步**:每 $C$ 次梯度更新后执行 $\theta_i^- \leftarrow \theta_i$。
|
||||
- **软更新**:可选 $\theta_i^- \leftarrow \tau\theta_i+(1-\tau)\theta_i^-$。
|
||||
|
||||
---
|
||||
|
||||
#### 5. 重复直到收敛
|
||||
|
||||
持续循环步骤 2–4,逐步衰减 $\varepsilon$。
|
||||
训练完成后,**每个体只需本地 $\widetilde Q_i$ 就能独立决策**,与中心最大化 $\sum_i\widetilde Q_i$ 等价 。
|
||||
|
||||
|
||||
|
||||
|
||||
176
科研/草稿.md
176
科研/草稿.md
@ -1,157 +1,31 @@
|
||||
以下是修改后的内容,所有公式已用 `$` 或 `$$` 规范包裹:
|
||||
### GAT 在多智能体强化学习中的衔接方式
|
||||
|
||||
| 位置 | 作用 | 关键公式 / 流程 | 典型引文 |
|
||||
| --------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- |
|
||||
| **1. 把多智能体系统显式建模成图** | 训练时每一步根据空间/通信半径或 *k* 近邻规则,把 *N* 个智能体构成动态图 $G=(V,E)$;邻接矩阵 *A* 随场景变化而更新,从而刻画“谁会与谁交互” | – | – |
|
||||
| **2. 节点特征准备** | 每个智能体的原始观测 $o_i$ 先经类型专属投影矩阵 $M_{\varphi_i}$ 映射到统一特征空间,得到 $o'_i$ 作为 **节点特征**(后续注意力汇聚的输入) | $o'_i = M_{\varphi_i} \cdot o_i$ | |
|
||||
| **3. GAT 自适应信息融合** | 对每条边 $i\!\to\!j$ 计算注意力分数并 Soft-max 归一化 | $\alpha_{ij}=\mathrm{softmax}_j\bigl(\text{LeakyReLU}\,[W h_i \,\|\, W h_j]\bigr)$ | |
|
||||
| | 按权重聚合邻居特征,得到携带局部交互信息的 $v_i$: | $v_i=\sum_{j\in\mathcal N_i}\alpha_{ij}\,W\,o'_j$ | |
|
||||
| | 多头拼接 → 平均池化得到 **队伍级全局表示** $o_{\text{all}}$,每个智能体和后续 Critic 都可访问 | $o_{\text{all}}=\frac{1}{N}\sum_{i=1}^N\|_{h=1}^H v_i^{(h)}$ | |
|
||||
| **4. 融入 CTDE 训练管线** | *Agent Network*:每个智能体的 RNN/GRU 接收 $[o'_i,\,o_{\text{all}}]$,输出局部 $Q_i$。<br>*Mixing Network*:沿 QMIX 单调性约束,用 $o_{\text{all}}$(或全局状态 $s$)作为超网络条件,将 $\{Q_i\}$ 汇聚成联合 $Q_{\text{tot}}$ | $Q_{\text{tot}} = \text{Mix}\bigl(Q_1,\dots,Q_N;\,s\text{ 或 }o_{\text{all}}\bigr)$ | |
|
||||
| **5. 执行阶段** | 训练完毕后,每个智能体只保留依赖 $o_i$(或轻量通信)的策略参数,保持 **去中心化执行**;GAT 与联合 $Q$ 评估仅在集中式训练时使用 | – | – |
|
||||
|
||||
---
|
||||
|
||||
## VDN(Value-Decomposition Network)笔记
|
||||
> 参考你的 DQN 笔记格式,并在每一步里标出与 DQN 的主要差异
|
||||
#### 为什么 GAT 能显著提升 MARL 表现?
|
||||
|
||||
1. **可变拓扑的自适应感知**
|
||||
传统拼接/平均把所有邻居一视同仁;GAT 通过 $\alpha_{ij}$ 动态衡量邻居重要性,适应不断变化的通信或空间结构。
|
||||
|
||||
2. **减少信息冗余、突出关键交互**
|
||||
注意力权重抑制无关或冗余邻居特征,只保留对当前决策真正有影响的信息,在复杂异构场景中尤为有效。
|
||||
|
||||
3. **统一异构观测的自动融合**
|
||||
先投影再做图注意力,避免人工设计融合规则,支持 LiDAR、相机等多模态数据共存。
|
||||
|
||||
4. **更精确的联合 Q 估计 → 更快收敛**
|
||||
消融实验显示,加入 GAT 后在 SMAC 的复杂对抗场景中赢率提升且达到同等胜率所需样本显著减少,证明其降低了 Critic 估计方差,缓解了非平稳性。
|
||||
|
||||
---
|
||||
|
||||
### 核心思想
|
||||
|
||||
| DQN | VDN |
|
||||
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| 用单个深度网络近似 **单智能体** 的 Q-函数。 | 用 **多智能体** 框架下的"值分解"思想:把**联合 Q 值** 拆成各智能体局部 Q 值之和 |
|
||||
| $$ Q_{\text{team}}(h,a)\;\approx\;\sum_{i=1}^{n} Q_i(h_i,a_i) $$。 | |
|
||||
| 目标是让一个智能体学会最优策略。 | 目标是让 n 个协作智能体,在只拿到 **同一个团队奖赏** 的前提下,仍能各自学习并在推理阶段独立运行。 |
|
||||
|
||||
**好处**
|
||||
|
||||
1. **稳定性**:通过集中式回传梯度来训练,避免了纯独立学习时的非平稳性与"懒惰智能体"现象。
|
||||
2. **可扩展执行**:训练期需要集中,但执行期每个智能体只用自己的 $Q_i$,动作选择仍是局部、分布式的。
|
||||
3. **无需手工设计个体奖励**:VDN 直接把团队奖励拆解为梯度信号,由网络自动学习"谁贡献了多少"。
|
||||
|
||||
---
|
||||
|
||||
### 训练流程(对照 DQN,粗体为新增或改动部分)
|
||||
|
||||
#### 1. 初始化
|
||||
|
||||
1. **局部 Q 网络**(Online Networks)
|
||||
- 为**每个**智能体 $i$ 初始化参数 $\theta_i$,并定义局部 Q 函数 $Q_i(h_i,a_i;\theta_i)$。
|
||||
- **可选**:参数共享(所有 $Q_i$ 共用一套 $\theta$)+ 身份/角色 one-hot。
|
||||
|
||||
2. **目标网络**
|
||||
- 为每个智能体维护对应的 $\theta_i^{-}$,或共享式 $\theta^{-}$。
|
||||
|
||||
3. **经验回放**(Replay Buffer)
|
||||
|
||||
- **存储的是联合元组**
|
||||
$$
|
||||
(\,\mathbf h=(h_1,\dots,h_n),\; \mathbf a=(a_1,\dots,a_n),\; r,\; \mathbf h'\,)
|
||||
$$
|
||||
其中 $r$ 是唯一的团队奖励。
|
||||
|
||||
4. **超参数**
|
||||
- 同 DQN:$\eta,\gamma,\epsilon,B,C$ 等。
|
||||
- **新增:智能体数 n**、是否共享权重、是否启用通信通道等。
|
||||
|
||||
---
|
||||
|
||||
#### 2. 与环境交互并存储经验
|
||||
|
||||
对每个时间步 $t$:
|
||||
|
||||
| 步骤 | 与 DQN 的差异 |
|
||||
| -------------- | ------------------------------------------------------------ |
|
||||
| **动作选择** | 每个智能体独立实施 ε-greedy: $a_t^i = \arg\max_{a_i} Q_i(h_t^i,a_i)$ (或随机)。 |
|
||||
| **环境反馈** | 环境返回单一团队奖励 $r_t$ 与下一批局部观测 $\mathbf h_{t+1}$。 |
|
||||
| **存入缓冲区** | **存联合元组**,保证训练时能对齐多智能体的状态-动作。 |
|
||||
|
||||
---
|
||||
|
||||
#### 3. 批量随机采样并训练
|
||||
|
||||
**前提**:缓冲区样本 ≥ $N_{\min}$。
|
||||
|
||||
1. **采样小批量**
|
||||
$$
|
||||
\{\!(\mathbf h^{(k)},\mathbf a^{(k)},r^{(k)},\mathbf h'^{(k)})\!\}_{k=1}^{B}
|
||||
$$
|
||||
|
||||
2. **计算联合 TD 目标**
|
||||
- 先用**目标网络集合**求
|
||||
$$
|
||||
y^{(k)} = r^{(k)} + \gamma \max_{\mathbf a'}\sum_{i} Q_i^{-}\!\bigl(h_{i}'^{(k)},a_i';\theta_i^{-}\bigr)
|
||||
$$
|
||||
- **注意**:max 运算对 **联合动作 $\mathbf a'$** 求和后再取最大;避免了枚举指数级动作的方法通常使用 **分解后逐个最大化**\*:
|
||||
$$
|
||||
\max_{\mathbf a'}\sum_i Q_i^{-}(\cdot)\;=\;\sum_i\max_{a_i'} Q_i^{-}(\cdot)
|
||||
$$
|
||||
这是 VDN 能高效扩展到多智能体的关键假设。
|
||||
|
||||
3. **预测当前联合 Q 值**
|
||||
$$
|
||||
\hat Q^{(k)} = \sum_{i} Q_i\!\bigl(h_i^{(k)},a_i^{(k)};\theta_i\bigr)
|
||||
$$
|
||||
|
||||
4. **损失函数**
|
||||
$$
|
||||
L = \frac1B\sum_{k=1}^{B}\bigl(y^{(k)} - \hat Q^{(k)}\bigr)^2
|
||||
$$
|
||||
|
||||
5. **梯度更新**
|
||||
- 对每个 $\theta_i$ 反向传播同一个联合损失 $L$ 的梯度。
|
||||
- 若共享权重,则只更新 $\theta$ 一份。
|
||||
|
||||
---
|
||||
|
||||
#### 4. 同步目标网络
|
||||
|
||||
- **硬同步**:每 $C$ 次优化后令 $\theta_i^{-}\!\leftarrow\!\theta_i$。
|
||||
- **软更新**(可选):$\theta_i^{-} \leftarrow \tau\theta_i + (1-\tau)\theta_i^{-}$。
|
||||
|
||||
---
|
||||
|
||||
#### 5. 重复直到收敛
|
||||
|
||||
- 同 DQN,可线性或指数衰减 $\epsilon$。
|
||||
- 评估阶段,各智能体独立使用各自的 $Q_i$ 做贪婪动作,无需中心化。
|
||||
|
||||
---
|
||||
|
||||
### 与 DQN 的关键区别速查
|
||||
|
||||
| 位置 | DQN | VDN |
|
||||
| ------------ | ---------------------------- | ------------------------------------------------------------ |
|
||||
| **状态表示** | 单一 $s$ 或历史 $h$。 | **局部历史向量 $\{h_i\}$**。 |
|
||||
| **动作空间** | 单行动作 $a$。 | **联合动作 $\mathbf a$**,但执行时每人只管自己的 $a_i$。 |
|
||||
| **价值函数** | $Q(s,a)$。 | $Q_{\text{team}}(\mathbf h,\mathbf a)=\sum_i Q_i(h_i,a_i)$。 |
|
||||
| **TD 目标** | $r+\gamma\max_a Q^-(s',a)$。 | **对和取 TD**:$r+\gamma\max_{\mathbf a'}\sum_i Q_i^-(h_i',a_i')$。 |
|
||||
| **损失回传** | 单网络。 | **同一联合损失回传到多网络/共享网络**。 |
|
||||
| **执行** | 独立单体。 | **集中训练—分布执行(CTDE)**。 |
|
||||
|
||||
---
|
||||
|
||||
### (可选)示例小算例
|
||||
|
||||
设两个智能体 A、B 在同一回合内只会得到一次共同奖励:
|
||||
- A 拾取物品得 3 分
|
||||
- B 成功送回物品得 5 分
|
||||
|
||||
VDN 训练后通常学到:
|
||||
|
||||
| 时刻 | 预测 $Q_A$ | 预测 $Q_B$ | 合成 $\Sigma Q_i$ |
|
||||
| ---------- | ---------- | ---------- | ----------------- |
|
||||
| A 正要拾取 | **↑3.0** | ≈0 | ≈3 |
|
||||
| B 正要送回 | ≈0 | **↑5.0** | ≈5 |
|
||||
| 其它时刻 | ≈基线 | ≈基线 | ≈基线 |
|
||||
|
||||
> 这说明网络已自动把团队奖励"归因"到对应智能体的局部价值上,而无需显式个体奖励设计。
|
||||
|
||||
---
|
||||
|
||||
### 小结
|
||||
|
||||
- **VDN = DQN + 值分解 + 多智能体联合 TD**
|
||||
- 集中式梯度、分布式执行,天然适合合作任务。
|
||||
- 在确保分解假设(奖励/价值近似可加)成立时,VDN 能显著缓解联合动作维度爆炸与非平稳性问题,是协作 MARL 的入门基线之一。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**一句话**:在多智能体强化学习里,GAT 把“谁与谁交互、交互强弱”编码成可训练的图注意力权重,将各智能体局部观测融合成全局队伍表示,供集中式 Critic 精准估值;这样既不破坏去中心化执行,又显著提升协作效率与收敛速度。
|
||||
|
||||
11
自学/拼团交易系统.md
Normal file
11
自学/拼团交易系统.md
Normal file
@ -0,0 +1,11 @@
|
||||
# 拼团交易系统
|
||||
|
||||
## 系统设计
|
||||
|
||||
**功能流程**
|
||||
|
||||
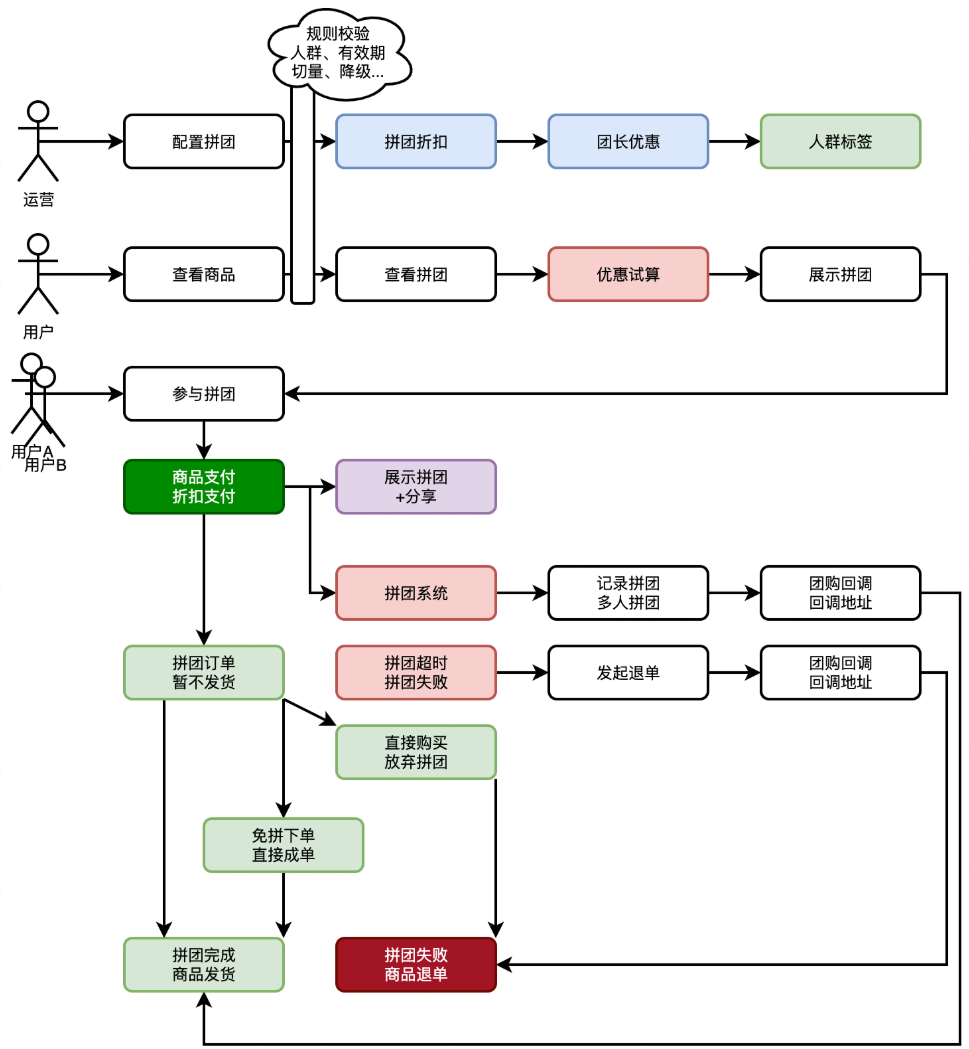
|
||||
|
||||
- 首先,由运营配置商品拼团活动,增加折扣方式。因为有人群标签的过滤,所以可以控制哪些人可参与拼团。
|
||||
- 之后,用户可见拼团商品并参与拼团。用户可自主分享拼团或者等待拼团。因为拼团有非常大的折扣刺激用户自主分享,以此可以节省营销推广费用。
|
||||
- 最后,拼团完成,触达商品发货。这里有两种,一种运营手段是拼团成团稀有性,必须打成拼团才可以。另外一种是虚拟拼团,无论是否打成,到时都完成拼团。
|
||||
@ -82,6 +82,24 @@ CDN内容分发,后期项目上线之后搞一下。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
图片编辑
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
AI扩图
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
|
||||
@ -127,6 +145,10 @@ private static final long serialVersionUID = -1321880859645675653L;
|
||||
|
||||
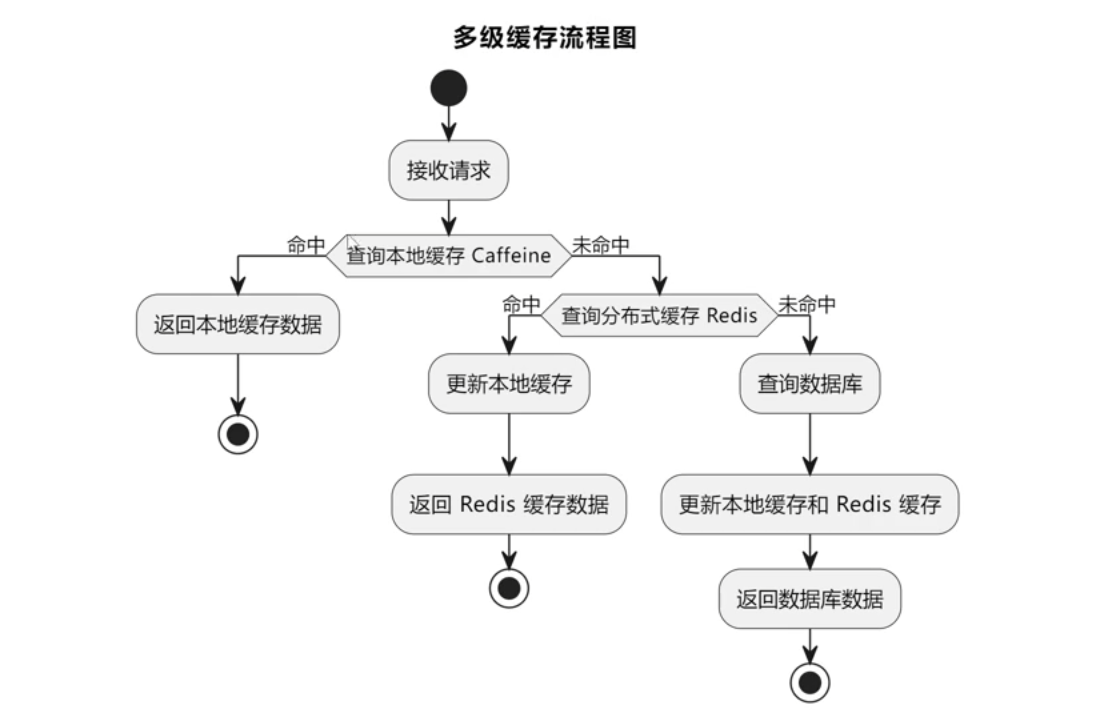
|
||||
|
||||
目前貌似没有使用缓存、@deprecated
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 收获
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user