Commit on 2025/08/11 周一 21:40:36.39
This commit is contained in:
parent
2b7da7a785
commit
fc8081a132
@ -1444,31 +1444,25 @@ public class SpringbootWebConfig2Application {
|
|||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### **Session**
|
#### Session
|
||||||
|
|
||||||
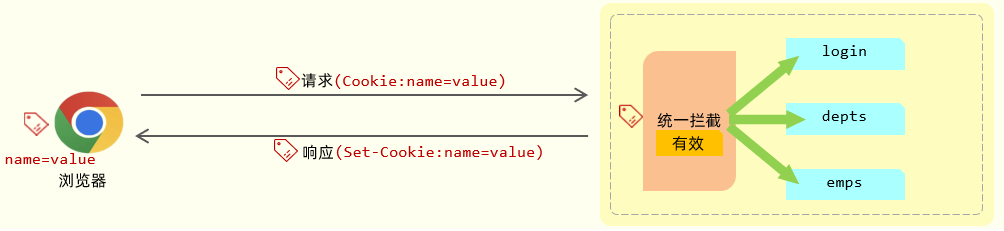
**原理**:**服务端存储**会话数据(如内存、Redis),客户端**只保存**会话 ID。
|
**1.基本原理**
|
||||||
|
|
||||||
**第一次请求**
|
**服务端**:存储会话数据(内存、Redis 等)。
|
||||||
|
|
||||||
- 浏览器没有 `JSESSIONID` Cookie,服务端看到没有会话 ID,就调用 `createSession()` 生成一个新的会话 ID(通常是一个 UUID),并在响应头里带上。
|
**客户端**:仅保存会话 ID(如 `JSESSIONID`),通常通过 Cookie 传递。
|
||||||
|
|
||||||
**浏览器收到响应**
|
|
||||||
|
|
||||||
- 会把这个 `JSESSIONID` 写入本地 Cookie 存储(因为你配置了 `max-age=2592000`,即 30 天,它会落盘保存,浏览器关了再开也不会丢失)。
|
|
||||||
|
|
||||||
**后续请求**
|
|
||||||
|
|
||||||
- 浏览器会自动在请求头里带上 `Cookie: JSESSIONID=<新ID>`,服务端就能根据这个 ID 从 Redis 里拿到对应的 Session 数据,恢复用户状态。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
1)**服务器内建一张 Map**(或 Redis 等持久化存储),大致结构:
|
**2.数据结构**
|
||||||
|
|
||||||
|
服务端会话存储(Map 或 Redis)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
{ "abc123" -> HttpSession 实例 }
|
{ "abc123" -> HttpSession 实例 }
|
||||||
```
|
```
|
||||||
|
|
||||||
2)`HttpSession ` 实例 自身又是一个 KV 容器,结构类似:
|
HttpSession 结构:
|
||||||
|
|
||||||
```text
|
```text
|
||||||
HttpSession
|
HttpSession
|
||||||
@ -1477,10 +1471,22 @@ HttpSession
|
|||||||
├─ lastAccessedTime = ...
|
├─ lastAccessedTime = ...
|
||||||
└─ attributes
|
└─ attributes
|
||||||
└─ "USER_LOGIN_STATE" -> user 实体对象
|
└─ "USER_LOGIN_STATE" -> user 实体对象
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
3)请求流程
|
|
||||||
|
|
||||||
|
**3.请求流程**
|
||||||
|
|
||||||
|
**首次请求**
|
||||||
|
|
||||||
|
1. 浏览器没有 `JSESSIONID`,服务端调用 `createSession()` 创建一个新会话(ID 通常是 UUID)。
|
||||||
|
2. 服务端返回响应头 `Set-Cookie: JSESSIONID=<新ID>; Max-Age=2592000`(30 天有效期)。
|
||||||
|
3. 浏览器将 `JSESSIONID` 写入本地 Cookie(持久化保存)。
|
||||||
|
|
||||||
|
**后续请求**
|
||||||
|
|
||||||
|
1. 浏览器自动在请求头中附带 `Cookie: JSESSIONID=<ID>`。
|
||||||
|
2. 服务端用该 ID 在会话存储中查找对应的 `HttpSession` 实例,恢复用户状态。
|
||||||
|
|
||||||
```text
|
```text
|
||||||
┌───────────────┐ (带 Cookie JSESSIONID=abc123)
|
┌───────────────┐ (带 Cookie JSESSIONID=abc123)
|
||||||
@ -1492,54 +1498,55 @@ HttpSession
|
|||||||
{abc123 → HttpSession} ← 找到
|
{abc123 → HttpSession} ← 找到
|
||||||
│
|
│
|
||||||
▼
|
▼
|
||||||
取 attributes["USER_LOGIN_STATE"] → 得到 user
|
取 attributes["USER_LOGIN_STATE"] → 得到
|
||||||
|
|
||||||
|
userrequest.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**4.后端使用示例**
|
||||||
|
|
||||||
|
**保存登录状态:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
|
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
|
||||||
```
|
```
|
||||||
|
|
||||||
后端代码的`request.getSession()`能**自动获取**当前请求所对应的HttpSession 实例!!!再往里存user信息。
|
`request.getSession()` 会自动获取当前请求关联的 `HttpSession` 实例。
|
||||||
|
|
||||||
3)退出登录
|
**获取登录状态:**
|
||||||
|
|
||||||
|
```java
|
||||||
|
User user = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE);
|
||||||
```
|
```
|
||||||
// 移除登录态
|
|
||||||
|
**退出登录:**
|
||||||
|
|
||||||
|
```java
|
||||||
request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE);
|
request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE);
|
||||||
```
|
```
|
||||||
|
|
||||||
此时,后端当前sessionId所对应的HttpSession 实例实例中的键"UserConstant.USER_LOGIN_STATE",它的值清零了(相当于用户信息删除了)。
|
相当于清空当前会话中的用户信息。浏览器本地的 `JSESSIONID` 依然存在,只不过后端啥也没了。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也有。
|
**优点**
|
||||||
|
|
||||||
- 优点:Session是存储在服务端的,安全。会话数据存在客户端有篡改的风险。
|
- 会话数据保存在服务端,相比直接将数据存储在客户端更安全(防篡改)。
|
||||||
- 缺点:
|
|
||||||
- 在分布式服务器集群环境下,Session 无法自动共享(可以共用redis解决)
|
**缺点**
|
||||||
- 如果客户端禁用 Cookie,Session 会失效。
|
|
||||||
- 需要在服务器端存储会话信息,可能带来性能压力,尤其是在高并发环境下。
|
- 分布式集群下 Session 无法自动共享(需借助 Redis 等集中存储)。
|
||||||
|
|
||||||
|
- 客户端禁用 Cookie 时,Session 会失效。
|
||||||
|
|
||||||
|
- 服务端需要维护会话数据,高并发环境下可能带来内存或性能压力。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**流程解析**
|
#### 令牌JWT(推荐)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
1. **首次请求时**(无 `JSESSIONID` Cookie):
|
|
||||||
- `request.getSession()` 会 **自动创建新 Session**,生成一个随机 `JSESSIONID`(如 `abc123`)。
|
|
||||||
- 服务器通过响应头 `Set-Cookie: JSESSIONID=abc123; Path=/; HttpOnly` 将 `JSESSIONID` 发给浏览器。
|
|
||||||
- 用户数据 `user` 被保存在服务器端,键为 `USER_LOGIN_STATE`,与 `JSESSIONID` 绑定。
|
|
||||||
2. **后续请求时**:
|
|
||||||
- 浏览器自动携带 `Cookie: JSESSIONID=abc123`。
|
|
||||||
- 服务器用 `JSESSIONID` 找到对应的 `HttpSession`,再通过 `getAttribute("USER_LOGIN_STATE")` 取出用户数据。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### **令牌JWT(推荐)**
|
|
||||||
|
|
||||||
- 优点:
|
- 优点:
|
||||||
- 支持PC端、移动端
|
- 支持PC端、移动端
|
||||||
|
|||||||
241
杂项/mermaid画图.md
241
杂项/mermaid画图.md
@ -205,27 +205,228 @@ sequenceDiagram
|
|||||||
|
|
||||||
|
|
||||||
```mermaid
|
```mermaid
|
||||||
classDiagram
|
flowchart LR
|
||||||
class Client
|
A[请求进入链头 Head] --> B[节点1: 日志LogLink]
|
||||||
class Context {
|
B -->|继续| C[节点2: 权限AuthLink]
|
||||||
- Strategy strategy
|
B -->|直接返回/终止| R1[返回结果]
|
||||||
+ execute()
|
|
||||||
}
|
|
||||||
class Strategy {
|
|
||||||
<<interface>>
|
|
||||||
+ execute()
|
|
||||||
}
|
|
||||||
class ConcreteStrategyA {
|
|
||||||
+ execute()
|
|
||||||
}
|
|
||||||
class ConcreteStrategyB {
|
|
||||||
+ execute()
|
|
||||||
}
|
|
||||||
|
|
||||||
Client --> Context
|
C -->|通过→继续| D[节点3: 审批ApproveLink]
|
||||||
Context --> Strategy
|
C -->|不通过→终止| R2[返回失败结果]
|
||||||
Strategy <|.. ConcreteStrategyA
|
|
||||||
Strategy <|.. ConcreteStrategyB
|
D --> R3[返回成功结果]
|
||||||
|
|
||||||
|
classDef node fill:#eef,stroke:#669;
|
||||||
|
classDef ret fill:#efe,stroke:#393;
|
||||||
|
class A,B,C,D node;
|
||||||
|
class R1,R2,R3 ret;
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
flowchart LR
|
||||||
|
subgraph mall["小型支付商城"]
|
||||||
|
style mall fill:#ffffff,stroke:#333,stroke-width:2
|
||||||
|
A[AliPayController<br/>发起退单申请]:::blue
|
||||||
|
C[订单状态扭转<br/>退单中]:::grey
|
||||||
|
E[RefundSuccessTopicListener<br/>接收MQ消息<br/>执行退款和订单状态变更]:::green
|
||||||
|
end
|
||||||
|
|
||||||
|
subgraph pdd["拼团系统"]
|
||||||
|
style pdd fill:#ffffff,stroke:#333,stroke-width:2
|
||||||
|
B[MarketTradeController<br/>接收退单申请]:::yellow
|
||||||
|
D[TradeRefundOrderService<br/>退单策略处理]:::red
|
||||||
|
F[TradeRepository<br/>发送MQ消息]:::purple
|
||||||
|
G([MQ消息队列<br/>退单成功消息]):::orange
|
||||||
|
H[RefundSuccessTopicListener<br/>接收MQ消息<br/>恢复库存]:::green
|
||||||
|
end
|
||||||
|
|
||||||
|
A -- "1. 发起退单请求" --> B
|
||||||
|
B -- "2. 处理退单" --> D
|
||||||
|
D -- "3. 发送MQ消息" --> F
|
||||||
|
F -- "4. 发布消息 (异步+本地消息表补偿)" --> G
|
||||||
|
F -- "5. 返回结果" --> C
|
||||||
|
G -- "6. 消费消息 (恢复库存)" --> H
|
||||||
|
G -. "7. 消费消息 (执行退款)" .-> E
|
||||||
|
|
||||||
|
classDef blue fill:#dbe9ff,stroke:#6fa1ff,stroke-width:1;
|
||||||
|
classDef grey fill:#e5e5e5,stroke:#9e9e9e,stroke-width:1;
|
||||||
|
classDef green fill:#d6f2d6,stroke:#76b076,stroke-width:1;
|
||||||
|
classDef yellow fill:#fef3cd,stroke:#f5c700,stroke-width:1;
|
||||||
|
classDef red fill:#f8d7da,stroke:#e55353,stroke-width:1;
|
||||||
|
classDef purple fill:#e4dbf9,stroke:#9370db,stroke-width:1;
|
||||||
|
classDef orange fill:#ffecca,stroke:#ffa500,stroke-width:1;
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
sequenceDiagram
|
||||||
|
participant Client as 前端
|
||||||
|
participant WS as WebSocket 服务器
|
||||||
|
participant Auth as 权限校验
|
||||||
|
participant Dispatcher as 消息分发器
|
||||||
|
participant Handler as 消息处理器
|
||||||
|
|
||||||
|
Client->>WS: 请求建立 WebSocket 连接
|
||||||
|
WS->>Auth: 校验用户权限
|
||||||
|
Auth-->>WS: 校验通过,保存用户和图片信息
|
||||||
|
WS-->>Client: 连接成功
|
||||||
|
|
||||||
|
Client->>WS: 发送消息(包含消息类型)
|
||||||
|
WS->>Dispatcher: 根据消息类型分发
|
||||||
|
Dispatcher->>Handler: 执行对应的消息处理逻辑
|
||||||
|
Handler-->>Dispatcher: 返回处理结果
|
||||||
|
Dispatcher-->>WS: 返回处理结果
|
||||||
|
WS-->>Client: 返回处理结果给客户端
|
||||||
|
|
||||||
|
Client->>WS: 断开连接
|
||||||
|
WS-->>Client: 删除 WebSocket 会话,释放资源
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
sequenceDiagram
|
||||||
|
participant Client as Client(浏览器)
|
||||||
|
participant WS as WebSocket Endpoint
|
||||||
|
participant Producer as PictureEditEventProducer
|
||||||
|
participant RB as RingBuffer
|
||||||
|
participant Worker as PictureEditEventWorkHandler
|
||||||
|
participant Handler as PictureEditHandler
|
||||||
|
|
||||||
|
Client->>WS: 发送 PictureEditRequestMessage
|
||||||
|
WS->>Producer: publishEvent(msg, session, user, pictureId)
|
||||||
|
Producer->>RB: next() 获取序号,写入事件字段
|
||||||
|
Producer->>RB: publish(sequence) 发布
|
||||||
|
RB-->>Worker: 回调 onEvent(event)
|
||||||
|
Worker->>Worker: 解析 type -> PictureEditMessageTypeEnum
|
||||||
|
alt ENTER_EDIT
|
||||||
|
Worker->>Handler: handleEnterEditMessage(...)
|
||||||
|
else EXIT_EDIT
|
||||||
|
Worker->>Handler: handleExitEditMessage(...)
|
||||||
|
else EDIT_ACTION
|
||||||
|
Worker->>Handler: handleEditActionMessage(...)
|
||||||
|
else 其他/异常
|
||||||
|
Worker->>WS: sendMessage(ERROR 响应)
|
||||||
|
end
|
||||||
|
Worker-->>Client: 业务处理后的响应(通过 WS)
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
sequenceDiagram
|
||||||
|
participant Client as WebSocket Client
|
||||||
|
participant IO as WebSocket I/O线程
|
||||||
|
participant Biz as 业务逻辑(耗时)
|
||||||
|
|
||||||
|
Client->>IO: 收到消息事件(onMessage)
|
||||||
|
IO->>Biz: 执行业务逻辑(耗时3s)
|
||||||
|
Biz-->>IO: 返回结果
|
||||||
|
IO->>Client: 发送响应
|
||||||
|
|
||||||
|
Note over IO: I/O线程被业务阻塞3s 不能处理其他连接的消息
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
sequenceDiagram
|
||||||
|
participant Client as WebSocket Client
|
||||||
|
participant IO as WebSocket I/O线程
|
||||||
|
participant Disruptor as RingBuffer队列
|
||||||
|
participant Worker as Disruptor消费者线程
|
||||||
|
participant Biz as 业务逻辑(耗时)
|
||||||
|
|
||||||
|
Client->>IO: 收到消息事件(onMessage)
|
||||||
|
IO->>Disruptor: 发布事件(快速)
|
||||||
|
Disruptor-->>IO: 立即返回
|
||||||
|
IO->>Client: (继续处理其他连接消息)
|
||||||
|
|
||||||
|
Worker->>Biz: 异步执行业务逻辑(耗时3s)
|
||||||
|
Biz-->>Worker: 返回结果
|
||||||
|
Worker->>Client: 通过WebSocket发送响应
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
flowchart TD
|
||||||
|
A[客户端发起WebSocket连接] --> B[HTTP握手阶段]
|
||||||
|
B --> C[WsHandshakeInterceptor.beforeHandshake]
|
||||||
|
C -->|校验失败| D[拒绝握手 连接关闭]
|
||||||
|
C -->|校验成功| E[建立WebSocket连接]
|
||||||
|
E --> F[PictureEditHandler]
|
||||||
|
F --> G[处理WebSocket消息 收发数据]
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
flowchart TD
|
||||||
|
A([接收请求]) --> B{查询本地缓存 Caffeine}
|
||||||
|
B -- 命中 --> C[返回本地缓存数据]
|
||||||
|
C --> End1(((结束)))
|
||||||
|
|
||||||
|
B -- 未命中 --> D{查询分布式缓存 Redis}
|
||||||
|
D -- 命中 --> E[更新本地缓存]
|
||||||
|
E --> F[返回 Redis 缓存数据]
|
||||||
|
F --> End2(((结束)))
|
||||||
|
|
||||||
|
D -- 未命中 --> G[查询数据库]
|
||||||
|
G --> H[更新本地缓存和 Redis 缓存]
|
||||||
|
H --> I[返回数据库数据]
|
||||||
|
I --> End3(((结束)))
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
classDiagram
|
||||||
|
class ImageSearchApiFacade {
|
||||||
|
+searchImage(localImagePath)
|
||||||
|
}
|
||||||
|
|
||||||
|
class GetImagePageUrlApi {
|
||||||
|
+getImagePageUrl(localImagePath)
|
||||||
|
}
|
||||||
|
|
||||||
|
class GetImageFirstUrlApi {
|
||||||
|
+getImageFirstUrl(imagePageUrl)
|
||||||
|
}
|
||||||
|
|
||||||
|
class GetImageListApi {
|
||||||
|
+getImageList(imageFirstUrl)
|
||||||
|
}
|
||||||
|
|
||||||
|
ImageSearchApiFacade --> GetImagePageUrlApi : Calls
|
||||||
|
ImageSearchApiFacade --> GetImageFirstUrlApi : Calls
|
||||||
|
ImageSearchApiFacade --> GetImageListApi : Calls
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```mermaid
|
||||||
|
erDiagram
|
||||||
|
用户 {
|
||||||
|
BIGINT 用户ID
|
||||||
|
VARCHAR 用户名
|
||||||
|
}
|
||||||
|
角色 {
|
||||||
|
BIGINT 角色ID
|
||||||
|
VARCHAR 角色名称
|
||||||
|
VARCHAR 描述
|
||||||
|
}
|
||||||
|
权限 {
|
||||||
|
BIGINT 权限ID
|
||||||
|
VARCHAR 权限名称
|
||||||
|
VARCHAR 描述
|
||||||
|
}
|
||||||
|
|
||||||
|
用户 }o--o{ 角色 : 拥有
|
||||||
|
角色 }o--o{ 权限 : 赋予
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
1672
项目/Smile云图库.md
Normal file
1672
项目/Smile云图库.md
Normal file
File diff suppressed because it is too large
Load Diff
10
项目/招标文件解析.md
10
项目/招标文件解析.md
@ -1,16 +1,16 @@
|
|||||||
产品官网:[智标领航 - 招投标AI解决方案](https://intellibid.cn/home)
|
产品官网:[智标领航 - 招投标AI解决方案](https://intellibid.cn/home)
|
||||||
|
|
||||||
产品后台:https://intellibid.cn:9091/login?redirect=%2Findex
|
产品后台:xxx
|
||||||
|
|
||||||
项目地址:[zy123/zbparse - zbparse - 智标领航代码仓库](http://47.98.59.178:3000/zy123/zbparse)
|
项目地址:xxx
|
||||||
|
|
||||||
git clone地址:http://47.98.59.178:3000/zy123/zbparse.git
|
git clone地址:xxx
|
||||||
|
|
||||||
选择develop分支,develop-xx 后面的xx越近越新。
|
选择develop分支,develop-xx 后面的xx越近越新。
|
||||||
|
|
||||||
正式环境:121.41.119.164:5000
|
正式环境:xxx
|
||||||
|
|
||||||
测试环境:47.98.58.178:5000
|
测试环境:xxx
|
||||||
|
|
||||||
大解析:指从招标文件解析入口进去,upload.py
|
大解析:指从招标文件解析入口进去,upload.py
|
||||||
|
|
||||||
|
|||||||
1354
项目/拼团交易系统.md
1354
项目/拼团交易系统.md
File diff suppressed because it is too large
Load Diff
914
项目/拼团设计模式.md
Normal file
914
项目/拼团设计模式.md
Normal file
@ -0,0 +1,914 @@
|
|||||||
|
## 设计模式
|
||||||
|
|
||||||
|
### 单例模式
|
||||||
|
|
||||||
|
#### 懒汉
|
||||||
|
|
||||||
|
```java
|
||||||
|
public class LazySingleton {
|
||||||
|
private static volatile LazySingleton instance;
|
||||||
|
|
||||||
|
private LazySingleton() {}
|
||||||
|
|
||||||
|
public static LazySingleton getInstance() {
|
||||||
|
if (instance == null) { // 第一次检查
|
||||||
|
synchronized (LazySingleton.class) {
|
||||||
|
if (instance == null) { // 第二次检查
|
||||||
|
instance = new LazySingleton();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return instance;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
第一次检查:防止重复实例化、以及进行synchronized同步块。
|
||||||
|
|
||||||
|
第二次检查:防止有多个线程同时通过第一次检查,然后依次进入同步块后,创建N个实例。
|
||||||
|
|
||||||
|
volatile:防止指令重排序,instance = new LazySingleton(); 正确顺序是:
|
||||||
|
|
||||||
|
**1.分配内存**
|
||||||
|
|
||||||
|
**2.调用构造函数,初始化对象**
|
||||||
|
|
||||||
|
**3.把引用赋给 `instance`**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 饿汉
|
||||||
|
|
||||||
|
```java
|
||||||
|
public class EagerSingleton {
|
||||||
|
// 类加载时就初始化实例
|
||||||
|
private static final EagerSingleton INSTANCE = new EagerSingleton();
|
||||||
|
|
||||||
|
// 私有构造函数
|
||||||
|
private EagerSingleton() {
|
||||||
|
// 防止反射创建实例
|
||||||
|
if (INSTANCE != null) {
|
||||||
|
throw new IllegalStateException("Singleton already initialized");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 全局访问点
|
||||||
|
public static EagerSingleton getInstance() {
|
||||||
|
return INSTANCE;
|
||||||
|
}
|
||||||
|
|
||||||
|
// 防止反序列化破坏单例
|
||||||
|
private Object readResolve() {
|
||||||
|
return INSTANCE;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 工厂模式
|
||||||
|
|
||||||
|
#### 简单工厂
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 产品接口
|
||||||
|
interface Product {
|
||||||
|
void use();
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体产品A
|
||||||
|
class ConcreteProductA implements Product {
|
||||||
|
@Override
|
||||||
|
public void use() {
|
||||||
|
System.out.println("使用产品A");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体产品B
|
||||||
|
class ConcreteProductB implements Product {
|
||||||
|
@Override
|
||||||
|
public void use() {
|
||||||
|
System.out.println("使用产品B");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
class SimpleFactory {
|
||||||
|
// 根据参数创建不同的产品
|
||||||
|
public static Product createProduct(String type) {
|
||||||
|
switch (type) {
|
||||||
|
case "A":
|
||||||
|
return new ConcreteProductA();
|
||||||
|
case "B":
|
||||||
|
return new ConcreteProductB();
|
||||||
|
default:
|
||||||
|
throw new IllegalArgumentException("未知产品类型");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public class Client {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 通过工厂创建产品
|
||||||
|
Product productA = SimpleFactory.createProduct("A");
|
||||||
|
productA.use(); // 输出: 使用产品A
|
||||||
|
|
||||||
|
Product productB = SimpleFactory.createProduct("B");
|
||||||
|
productB.use(); // 输出: 使用产品B
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
缺点:添加新产品需要修改工厂类(违反开闭原则)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 抽象工厂
|
||||||
|
|
||||||
|
抽象工厂模式是一种创建型设计模式,它提供一个接口用于创建相关或依赖对象的家族,而不需要明确指定具体类。
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 抽象产品接口
|
||||||
|
interface Button {
|
||||||
|
void render();
|
||||||
|
}
|
||||||
|
|
||||||
|
interface Checkbox {
|
||||||
|
void render();
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体产品实现 - Windows 风格
|
||||||
|
class WindowsButton implements Button {
|
||||||
|
@Override
|
||||||
|
public void render() {
|
||||||
|
System.out.println("渲染一个 Windows 风格的按钮");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
class WindowsCheckbox implements Checkbox {
|
||||||
|
@Override
|
||||||
|
public void render() {
|
||||||
|
System.out.println("渲染一个 Windows 风格的复选框");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体产品实现 - MacOS 风格
|
||||||
|
class MacOSButton implements Button {
|
||||||
|
@Override
|
||||||
|
public void render() {
|
||||||
|
System.out.println("渲染一个 MacOS 风格的按钮");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
class MacOSCheckbox implements Checkbox {
|
||||||
|
@Override
|
||||||
|
public void render() {
|
||||||
|
System.out.println("渲染一个 MacOS 风格的复选框");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 抽象工厂接口
|
||||||
|
interface GUIFactory {
|
||||||
|
Button createButton();
|
||||||
|
Checkbox createCheckbox();
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体工厂实现 - Windows
|
||||||
|
class WindowsFactory implements GUIFactory {
|
||||||
|
@Override
|
||||||
|
public Button createButton() {
|
||||||
|
return new WindowsButton();
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public Checkbox createCheckbox() {
|
||||||
|
return new WindowsCheckbox();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体工厂实现 - MacOS
|
||||||
|
class MacOSFactory implements GUIFactory {
|
||||||
|
@Override
|
||||||
|
public Button createButton() {
|
||||||
|
return new MacOSButton();
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public Checkbox createCheckbox() {
|
||||||
|
return new MacOSCheckbox();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 客户端代码
|
||||||
|
public class Application {
|
||||||
|
private Button button;
|
||||||
|
private Checkbox checkbox;
|
||||||
|
|
||||||
|
public Application(GUIFactory factory) {
|
||||||
|
button = factory.createButton();
|
||||||
|
checkbox = factory.createCheckbox();
|
||||||
|
}
|
||||||
|
|
||||||
|
public void render() {
|
||||||
|
button.render();
|
||||||
|
checkbox.render();
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 根据配置或环境选择工厂
|
||||||
|
GUIFactory factory;
|
||||||
|
|
||||||
|
String osName = System.getProperty("os.name").toLowerCase();
|
||||||
|
if (osName.contains("win")) {
|
||||||
|
factory = new WindowsFactory();
|
||||||
|
} else {
|
||||||
|
factory = new MacOSFactory();
|
||||||
|
}
|
||||||
|
|
||||||
|
Application app = new Application(factory);
|
||||||
|
app.render();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 模板方法
|
||||||
|
|
||||||
|
**核心思想**:
|
||||||
|
|
||||||
|
在抽象父类中定义**算法骨架**(固定**执行顺序**),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。
|
||||||
|
|
||||||
|
如果仅仅是把重复的方法抽取成公共函数,不叫模板方法!模板方法要设计算法骨架!!!
|
||||||
|
|
||||||
|
```text
|
||||||
|
Client ───▶ AbstractClass
|
||||||
|
├─ templateMethod() ←—— 固定流程
|
||||||
|
│ step1()
|
||||||
|
│ step2() ←—— 抽象,可变
|
||||||
|
│ step3()
|
||||||
|
└─ hookMethod() ←—— 可选覆盖
|
||||||
|
▲
|
||||||
|
│ extends
|
||||||
|
┌──────────┴──────────┐
|
||||||
|
│ ConcreteClassA/B… │
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
**示例:**
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 1. 抽象模板
|
||||||
|
public abstract class AbstractDialog {
|
||||||
|
|
||||||
|
// 模板方法:固定调用顺序,设为 final 防止子类改流程
|
||||||
|
public final void show() {
|
||||||
|
initLayout();
|
||||||
|
bindEvent();
|
||||||
|
beforeDisplay(); // 钩子,可选
|
||||||
|
display();
|
||||||
|
afterDisplay(); // 钩子,可选
|
||||||
|
}
|
||||||
|
|
||||||
|
// 具体公共步骤
|
||||||
|
private void initLayout() {
|
||||||
|
System.out.println("加载通用布局文件");
|
||||||
|
}
|
||||||
|
|
||||||
|
// 需要子类实现的抽象步骤
|
||||||
|
protected abstract void bindEvent();
|
||||||
|
|
||||||
|
// 钩子方法,默认空实现
|
||||||
|
protected void beforeDisplay() {}
|
||||||
|
protected void afterDisplay() {}
|
||||||
|
|
||||||
|
private void display() {
|
||||||
|
System.out.println("弹出对话框");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 2. 子类:登录对话框
|
||||||
|
public class LoginDialog extends AbstractDialog {
|
||||||
|
@Override
|
||||||
|
protected void bindEvent() {
|
||||||
|
System.out.println("绑定登录按钮事件");
|
||||||
|
}
|
||||||
|
@Override
|
||||||
|
protected void afterDisplay() {
|
||||||
|
System.out.println("focus 到用户名输入框");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 3. 调用
|
||||||
|
public class Demo {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
AbstractDialog dialog = new LoginDialog();
|
||||||
|
dialog.show();
|
||||||
|
/* 输出:
|
||||||
|
加载通用布局文件
|
||||||
|
绑定登录按钮事件
|
||||||
|
弹出对话框
|
||||||
|
focus 到用户名输入框
|
||||||
|
*/
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**要点**
|
||||||
|
|
||||||
|
- **复用公共流程**:`initLayout()`、`display()` 写一次即可。
|
||||||
|
- **限制流程顺序**:`show()` 定为 `final`,防止子类乱改步骤。
|
||||||
|
- **钩子方法**:子类可选择性覆盖(如 `beforeDisplay`)。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 策略模式
|
||||||
|
|
||||||
|
**核心思想**:
|
||||||
|
|
||||||
|
将可以互换的算法或行为抽象为独立的策略类,运行时由**上下文类(Context)**选择合适的策略对象去执行。调用方(Client)只依赖统一的接口,不关心具体实现。
|
||||||
|
|
||||||
|
```text
|
||||||
|
┌───────────────┐
|
||||||
|
│ Client │
|
||||||
|
└─────▲─────────┘
|
||||||
|
│ has-a
|
||||||
|
┌─────┴─────────┐ implements
|
||||||
|
│ Context │────────────┐ ┌──────────────┐
|
||||||
|
│ (使用者) │ strategy └─▶│ Strategy A │
|
||||||
|
└───────────────┘ ├──────────────┤
|
||||||
|
│ Strategy B │
|
||||||
|
└──────────────┘
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 策略接口
|
||||||
|
public interface PaymentStrategy {
|
||||||
|
void pay(int amount);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 策略A:微信支付
|
||||||
|
@Service("wechat")
|
||||||
|
public class WechatPay implements PaymentStrategy {
|
||||||
|
public void pay(int amount) {
|
||||||
|
System.out.println("使用微信支付 " + amount + " 元");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 策略B:支付宝支付
|
||||||
|
@Service("alipay")
|
||||||
|
public class Alipay implements PaymentStrategy {
|
||||||
|
public void pay(int amount) {
|
||||||
|
System.out.println("使用支付宝支付 " + amount + " 元");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 上下文类
|
||||||
|
public class PaymentContext {
|
||||||
|
private PaymentStrategy strategy;
|
||||||
|
|
||||||
|
public PaymentContext(PaymentStrategy strategy) {
|
||||||
|
this.strategy = strategy;
|
||||||
|
}
|
||||||
|
|
||||||
|
public void execute(int amount) {
|
||||||
|
strategy.pay(amount);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 调用方
|
||||||
|
public class Main {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
PaymentContext ctx = new PaymentContext(new WechatPay());
|
||||||
|
ctx.execute(100);
|
||||||
|
|
||||||
|
ctx = new PaymentContext(new Alipay());
|
||||||
|
ctx.execute(200);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
下面有更优雅的策略选择方式!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### Spring集合自动注入
|
||||||
|
|
||||||
|
在策略、工厂、插件等模式中,经常需要维护**“策略名 → 策略对象”**的映射。Spring 可以通过 `Map<String, 接口类型>` **一次性注入**所有实现类。
|
||||||
|
|
||||||
|
```java
|
||||||
|
@Resource
|
||||||
|
private Map<String, IDiscountCalculateService> discountCalculateServiceMap;
|
||||||
|
```
|
||||||
|
|
||||||
|
**字段类型**:`Map<String, IDiscountCalculateService>`
|
||||||
|
|
||||||
|
- key—— **Bean 的名字**
|
||||||
|
- 默认是类名首字母小写 (`mjCalculateService`)
|
||||||
|
- 或者你在实现类上显式写的 `@Service("MJ")`
|
||||||
|
- **value** —— 那个实现类对应的**实例**
|
||||||
|
- **Spring 机制**:
|
||||||
|
1. 启动时扫描所有实现 `IDiscountCalculateService` 的 Bean。
|
||||||
|
2. 把它们按 “BeanName → Bean 实例” 的映射注入到这张 `Map` 里。
|
||||||
|
3. 你一次性就拿到了“策略字典”。
|
||||||
|
|
||||||
|
**示例:**
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 上下文类:自动注入所有策略 Bean
|
||||||
|
@Component
|
||||||
|
@RequiredArgsConstructor
|
||||||
|
public class PaymentContext {
|
||||||
|
|
||||||
|
// key 为 Bean 名(如 "wechat"、"alipay"),value 为策略实例
|
||||||
|
private final Map<String, PaymentStrategy> paymentStrategyMap;
|
||||||
|
|
||||||
|
public void pay(String strategyKey, int amount) {
|
||||||
|
PaymentStrategy strategy = paymentStrategyMap.get(strategyKey);
|
||||||
|
if (strategy == null) {
|
||||||
|
throw new IllegalArgumentException("无匹配支付方式: " + strategyKey);
|
||||||
|
}
|
||||||
|
strategy.pay(amount);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 调用方示例
|
||||||
|
@Component
|
||||||
|
@RequiredArgsConstructor
|
||||||
|
public class PaymentService {
|
||||||
|
|
||||||
|
private final PaymentContext paymentContext;
|
||||||
|
|
||||||
|
public void process() {
|
||||||
|
paymentContext.pay("wechat", 100); // 输出:使用微信支付 100 元
|
||||||
|
paymentContext.pay("alipay", 200); // 输出:使用支付宝支付 200 元
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 模板方法+策略模式
|
||||||
|
|
||||||
|
本项目的价格试算同时用了策略模式 + 模板方法模式:
|
||||||
|
|
||||||
|
**策略模式(Strategy)**:
|
||||||
|
`IDiscountCalculateService` 是策略接口;`ZKCalculateService`、`ZJCalculateService` ...是**可替换的折扣策略**(@Service("ZK") / @Service("ZJ") 作为选择键)。外部可以根据活动配置里的类型码选哪个实现来算价——这就是“运行时可切换算法”。
|
||||||
|
|
||||||
|
**模板方法模式(Template Method)**:
|
||||||
|
`AbstractDiscountCalculateService#calculate(...)` 把**共同流程**固定下来(先进行人群校验 → 计算优惠后价格),并把“**真正的计算**”这一步**延迟到子类**通过 `doCalculate(...)` 实现。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 责任链
|
||||||
|
|
||||||
|
应用场景:日志系统、审批流程、权限校验——任何需要将请求按阶段传递、并由某一环节决定是否继续或终止处理的地方,都非常适合责链模式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
典型的责任链模式要点:
|
||||||
|
|
||||||
|
- **解耦请求发送者和处理者**:调用者只持有链头,不关心中间环节。
|
||||||
|
- **动态组装**:通过 `appendNext` 可以灵活地增加、删除或重排链上的节点。
|
||||||
|
- **可扩展**:新增处理逻辑只需继承 `AbstractLogicLink` 并实现 `apply`,不用改动已有代码。
|
||||||
|
|
||||||
|
#### 单实例链
|
||||||
|
|
||||||
|
可以理解成“**单向、单链表式**的链条”:每个节点只知道自己的下一个节点(`next`),链头只有一个入口。
|
||||||
|
你可以在启动或运行时**动态组装**:`head.appendNext(a).appendNext(b).appendNext(c);`
|
||||||
|
|
||||||
|
**T / D / R 是啥?**
|
||||||
|
|
||||||
|
- `T`:请求的**静态入参**(本次请求的主要数据)。
|
||||||
|
- `D`:**动态上下文**(链路里各节点共享、可读写的状态容器,比如日志收集、校验中间结果)。
|
||||||
|
- `R`:最终**返回结果**类型。
|
||||||
|
|
||||||
|
1)接口定义:`ILogicChainArmory<T, D, R>` 提供**添加**节点方法和**获取**节点
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 定义了“链条组装”的最小能力:能拿到下一个节点、也能把下一个节点接上去
|
||||||
|
public interface ILogicChainArmory<T, D, R> {
|
||||||
|
|
||||||
|
// 获取当前节点的“下一个”处理者
|
||||||
|
ILogicLink<T, D, R> next();
|
||||||
|
|
||||||
|
// 把新的处理者挂到当前节点后面,并返回它(方便链式 append)
|
||||||
|
ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
2)`ILogicLink<T, D, R>` 继承自 `ILogicChainArmory<T, D, R>`,并额外声明了**核心方法** `apply`
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 真正的“处理节点”接口:在具备链条组装能力的基础上,还要能“处理请求”
|
||||||
|
public interface ILogicLink<T, D, R> extends ILogicChainArmory<T, D, R> {
|
||||||
|
R apply(T requestParameter, D dynamicContext) throws Exception;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
3)抽象基类:`AbstractLogicLink`,提供了**责任链节点的通用骨架**,(保存 `next`、实现 `appendNext`/`next()`、以及一个便捷的 `protected next(...)`,这样具体的节点类就不用重复这些代码,真正的业务处理逻辑仍然交由子类去实现 `apply(...)`。
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 抽象基类:大多数节点都可以继承它,避免重复写“组装链”的样板代码
|
||||||
|
public abstract class AbstractLogicLink<T, D, R> implements ILogicLink<T, D, R> {
|
||||||
|
|
||||||
|
// 指向“下一个处理者”的引用
|
||||||
|
private ILogicLink<T, D, R> next;
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public ILogicLink<T, D, R> next() {
|
||||||
|
return next;
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next) {
|
||||||
|
this.next = next;
|
||||||
|
return next; // 返回 next 以便连续 append,类似 builder
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 便捷方法:当前节点决定“交给下一个处理者”
|
||||||
|
*/
|
||||||
|
protected R next(T requestParameter, D dynamicContext) throws Exception {
|
||||||
|
// 直接把请求丢给下一个节点继续处理
|
||||||
|
// 注意:这里假设 next 一定存在;实际项目里建议判空以免 NPE(见下文改进建议)
|
||||||
|
return next.apply(requestParameter, dynamicContext);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
子类只需要继承 `AbstractLogicLink` 并实现 `apply(...)`:
|
||||||
|
|
||||||
|
- **能处理就处理**(并可选择直接返回,终止链条)。
|
||||||
|
- **不处理或处理后仍需后续动作**,就 `return next(requestParameter, dynamicContext)` 继续传递。
|
||||||
|
|
||||||
|
4)实现子类
|
||||||
|
|
||||||
|
```java
|
||||||
|
@Component
|
||||||
|
public class AuthLink extends AbstractLogicLink<Request, Context, Response> {
|
||||||
|
@Override
|
||||||
|
public Response apply(Request req, Context ctx) throws Exception {
|
||||||
|
if (!ctx.isAuthenticated()) {
|
||||||
|
// 未认证:立刻终止;也可以在这里构造一个标准错误响应返回
|
||||||
|
throw new UnauthorizedException();
|
||||||
|
}
|
||||||
|
// 认证通过,继续下一个环节
|
||||||
|
return next(req, ctx);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
@Component
|
||||||
|
public class LoggingLink extends AbstractLogicLink<Request, Context, Response> {
|
||||||
|
@Override
|
||||||
|
public Response apply(Request req, Context ctx) throws Exception {
|
||||||
|
System.out.println("Request received: " + req);
|
||||||
|
return next(req, ctx);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
@Component
|
||||||
|
public class BusinessLogicLink extends AbstractLogicLink<Request, Context, Response> {
|
||||||
|
@Override
|
||||||
|
public Response apply(Request req, Context ctx) throws Exception {
|
||||||
|
// 业务逻辑...
|
||||||
|
return new Response(...);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
5)组装链
|
||||||
|
|
||||||
|
```java
|
||||||
|
@Configuration
|
||||||
|
@RequiredArgsConstructor
|
||||||
|
public class LogicChainFactory {
|
||||||
|
|
||||||
|
private final AuthLink authLink;
|
||||||
|
private final LoggingLink loggingLink;
|
||||||
|
private final BusinessLogicLink businessLogicLink;
|
||||||
|
|
||||||
|
@Bean
|
||||||
|
public ILogicLink<Request, Context, Response> logicChain() {
|
||||||
|
return authLink
|
||||||
|
.appendNext(loggingLink)
|
||||||
|
.appendNext(businessLogicLink);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
示例图:
|
||||||
|
|
||||||
|
```text
|
||||||
|
AuthLink.apply
|
||||||
|
└─▶ LoggingLink.apply
|
||||||
|
└─▶ BusinessLogicLink.apply
|
||||||
|
└─▶ 返回 Response
|
||||||
|
```
|
||||||
|
|
||||||
|
这种模式链上的每个节点都手动 `next()`到下一节点。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 多实例链1
|
||||||
|
|
||||||
|
以上是单例链,即只能创建一条链;比如A->B->C,不能创建别的链,因为节点Bean是单例的,如果创别的链会导致指针引用错误!!!
|
||||||
|
|
||||||
|
如果想变成多例链:
|
||||||
|
|
||||||
|
1)节点由默认的单例模式改为原型模式:
|
||||||
|
|
||||||
|
```java
|
||||||
|
@Component
|
||||||
|
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
|
||||||
|
public class A extends AbstractLogicLink<Req, Ctx, Resp> { ... }
|
||||||
|
```
|
||||||
|
|
||||||
|
2)组装链的时候注明不同链的bean名称:
|
||||||
|
|
||||||
|
```java
|
||||||
|
/** 全局唯一链:A -> B -> C */
|
||||||
|
@Bean("chainABC")
|
||||||
|
public ILogicLink<Req, Ctx, Resp> chainABC() {
|
||||||
|
A a = aProvider.getObject();
|
||||||
|
B b = bProvider.getObject();
|
||||||
|
C c = cProvider.getObject();
|
||||||
|
return a.appendNext(b).appendNext(c); // 返回链头 a
|
||||||
|
}
|
||||||
|
|
||||||
|
/** 全局唯一链:A -> C */
|
||||||
|
@Bean("chainAC")
|
||||||
|
public ILogicLink<Req, Ctx, Resp> chainAC() {
|
||||||
|
A a = aProvider.getObject();
|
||||||
|
C c = cProvider.getObject();
|
||||||
|
return a.appendNext(c); // 返回链头 a(另一套实例)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 多实例链2
|
||||||
|
|
||||||
|
```java
|
||||||
|
/**
|
||||||
|
* 通用逻辑处理器接口 —— 责任链中的「节点」要实现的核心契约。
|
||||||
|
*/
|
||||||
|
public interface ILogicHandler<T, D, R> {
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 默认的 next占位实现,方便节点若不需要向后传递时直接返回 null。
|
||||||
|
*/
|
||||||
|
default R next(T requestParameter, D dynamicContext) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 节点的核心处理方法。
|
||||||
|
*/
|
||||||
|
R apply(T requestParameter, D dynamicContext) throws Exception;
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
/**
|
||||||
|
* 业务链路容器 —— 双向链表实现,同时实现 ILogicHandler,从而可以被当作单个节点使用。
|
||||||
|
*/
|
||||||
|
public class BusinessLinkedList<T, D, R> extends LinkedList<ILogicHandler<T, D, R>> implements ILogicHandler<T, D, R>{
|
||||||
|
|
||||||
|
public BusinessLinkedList(String name) {
|
||||||
|
super(name);
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* BusinessLinkedList是头节点,它的apply方法就是循环调用后面的节点,直至返回。
|
||||||
|
* 遍历并执行链路。
|
||||||
|
*/
|
||||||
|
@Override
|
||||||
|
public R apply(T requestParameter, D dynamicContext) throws Exception {
|
||||||
|
Node<ILogicHandler<T, D, R>> current = this.first;
|
||||||
|
// 顺序执行,直到链尾或返回结果
|
||||||
|
while (current != null) {
|
||||||
|
ILogicHandler<T, D, R> handler = current.item;
|
||||||
|
R result = handler.apply(requestParameter, dynamicContext);
|
||||||
|
if (result != null) {
|
||||||
|
// 节点命中,立即返回
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
//result==null,则交给那一节点继续处理
|
||||||
|
current = current.next;
|
||||||
|
}
|
||||||
|
// 全链未命中
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
/**
|
||||||
|
* 链路装配工厂 —— 负责把一组 ILogicHandler 顺序注册到 BusinessLinkedList 中。
|
||||||
|
*/
|
||||||
|
public class LinkArmory<T, D, R> {
|
||||||
|
|
||||||
|
private final BusinessLinkedList<T, D, R> logicLink;
|
||||||
|
|
||||||
|
/**
|
||||||
|
* @param linkName 链路名称,便于日志排查
|
||||||
|
* @param logicHandlers 节点列表,按传入顺序链接
|
||||||
|
*/
|
||||||
|
@SafeVarargs
|
||||||
|
public LinkArmory(String linkName, ILogicHandler<T, D, R>... logicHandlers) {
|
||||||
|
logicLink = new BusinessLinkedList<>(linkName);
|
||||||
|
for (ILogicHandler<T, D, R> logicHandler: logicHandlers){
|
||||||
|
logicLink.add(logicHandler);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/** 返回组装完成的链路 */
|
||||||
|
public BusinessLinkedList<T, D, R> getLogicLink() {
|
||||||
|
return logicLink;
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
//工厂类,可以定义多条责任链,每条有自己的Bean名称区分。
|
||||||
|
@Bean("tradeRuleFilter")
|
||||||
|
public BusinessLinkedList<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> tradeRuleFilter(ActivityUsabilityRuleFilter activityUsabilityRuleFilter, UserTakeLimitRuleFilter userTakeLimitRuleFilter) {
|
||||||
|
// 1. 组装链
|
||||||
|
LinkArmory<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> linkArmory =
|
||||||
|
new LinkArmory<>("交易规则过滤链", activityUsabilityRuleFilter, userTakeLimitRuleFilter);
|
||||||
|
|
||||||
|
// 2. 返回链容器(即可作为责任链使用)
|
||||||
|
return linkArmory.getLogicLink();
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
示例图:
|
||||||
|
|
||||||
|
```text
|
||||||
|
BusinessLinkedList.apply ←─ 只有这一层在栈里
|
||||||
|
while 循环:
|
||||||
|
├─▶ 调用 ActivityUsability.apply → 返回 null → 继续
|
||||||
|
├─▶ 调用 UserTakeLimit.apply → 返回 null → 继续
|
||||||
|
└─▶ 调用 ... → 返回 Result → break
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
链头拿着“游标”一个个跑,节点只告诉“命中 / 未命中”。
|
||||||
|
|
||||||
|
这里无需把节点改为原型模式,也可以实现多例链,因为由双向链表`BusinessLinkedList` 负责**保存链路关系和推进执行**,而`ILogicHandler`节点本身**不再保存 `next` 指针**,所以它们之间没有共享可变状态。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
本项目中使用多实例链2,有以下场景:
|
||||||
|
|
||||||
|
**一、拼团「锁单前」校验链**
|
||||||
|
|
||||||
|
目标:在真正锁单前把“活动有效性 / 用户参与资格 / 可用库存”一口气校清楚,避免后续回滚。
|
||||||
|
|
||||||
|
1.活动有效性校验 `ActivityUsability` (当前时间是否早于活动截止时间)
|
||||||
|
|
||||||
|
2.用户可参与活动次数校验 `UserTakeLimitRuleFilter`(默认用户只可参与一次拼团)
|
||||||
|
|
||||||
|
3.剩余库存校验 `TeamStockOccupyRuleFilter`(可能同时有多人点击参与当前拼团,尝试抢占库存,仅部分人可通过校验。)
|
||||||
|
|
||||||
|
校验通过方可进行真正的锁单。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**二、交易结算校验链**
|
||||||
|
|
||||||
|
1.渠道黑名单校验 `SCRuleFilter`:某签约渠道下架/风控拦截,禁止结算。
|
||||||
|
|
||||||
|
2.外部单号校验 `OutTradeNoRuleFilter`:查营销订单;不存在或已退单(`CLOSE`)→ 不结算。
|
||||||
|
|
||||||
|
3.可结算时间校验 `SettableRuleFilter`:结算时间必须在拼团有效期内(`outTradeTime < team.validEndTime`),比如发起
|
||||||
|
|
||||||
|
拼团一个小时之内要结算完毕。
|
||||||
|
|
||||||
|
4.结束节点`EndRuleFilter`:整理上下文到返回对象,作为结算规则校验的产出。
|
||||||
|
|
||||||
|
检验通过方可进入真正的结算。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**三、交易退单执行链**
|
||||||
|
|
||||||
|
1.数据加载 `DataNodeFilter`:按 `userId + outTradeNo` 查询营销订单与拼团信息,写入上下文。
|
||||||
|
|
||||||
|
2.重复退单检查 `UniqueRefundNodeFilter`:订单已是 `CLOSE` → 视为幂等重复,直接返回。
|
||||||
|
|
||||||
|
3.退单策略执行 `RefundOrderNodeFilter`:依据“拼团态 + 订单态”选用具体退单策略 `IRefundOrderStrategy`,执行退款/解锁/改库并返回成功结果。
|
||||||
|
|
||||||
|
本身就是完整的退单流程。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 规则树流程
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**整体分层思路**
|
||||||
|
|
||||||
|
| 分层 | 作用 | 关键对象 |
|
||||||
|
| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||||
|
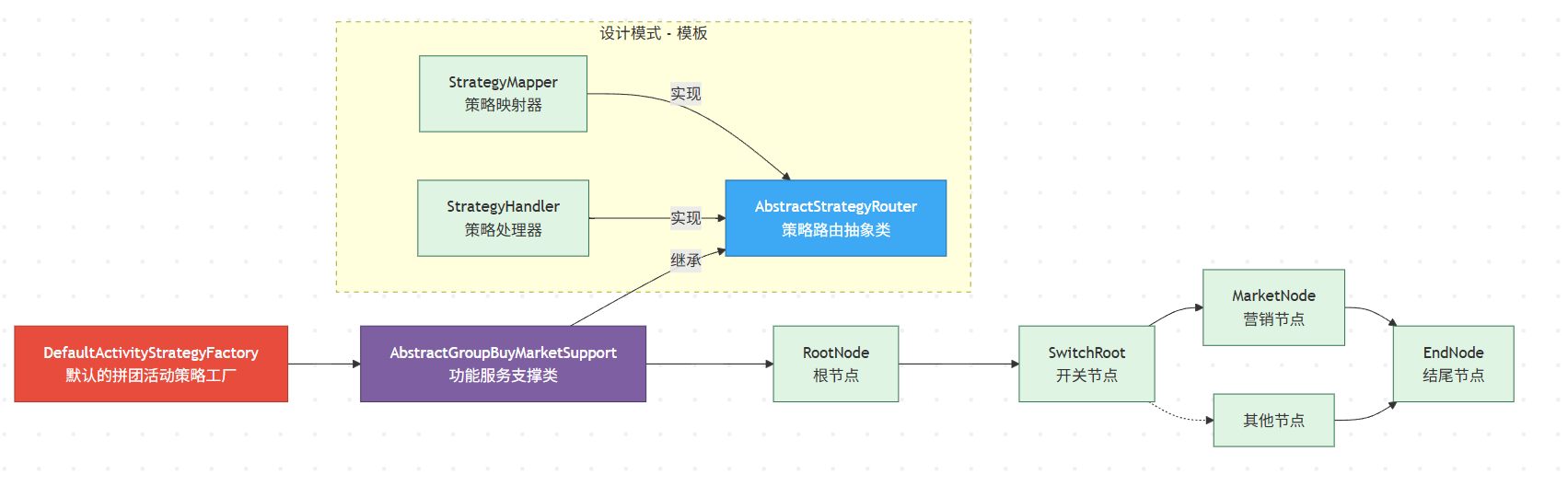
| **通用模板层** | 抽象出与具体业务无关的「规则树」骨架,解决 *如何找到并执行策略* 的共性问题 | `StrategyMapper`、`StrategyHandler`、`AbstractStrategyRouter<T,D,R>` |
|
||||||
|
| **业务装配层** | 基于模板,自由拼装出 *一棵* 贴合业务流程的策略树 | `RootNode / SwitchNode / MarketNode / EndNode …` |
|
||||||
|
| **对外暴露层** | 通过 **工厂 + 服务支持类** 将整棵树封装成一个可直接调用的 `StrategyHandler`,并交给 Spring 整体托管 | `DefaultActivityStrategyFactory`、`AbstractGroupBuyMarketSupport` |
|
||||||
|
|
||||||
|
**通用模板层:规则树的“骨架”**
|
||||||
|
|
||||||
|
| 角色 | 职责 | 关系 |
|
||||||
|
| ------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||||
|
| `StrategyMapper` | **映射器**:依据 `requestParameter + dynamicContext` 选出 *下一个* 策略节点 | 被 `AbstractStrategyRouter` 调用 |
|
||||||
|
| `StrategyHandler` | **处理器**:真正执行业务逻辑;`apply` 结束后可返回结果或继续路由 | 节点本身 / 路由器本身都是它的实现 |
|
||||||
|
| `AbstractStrategyRouter<T,D,R>` | **路由模板**:① 调用 `get(...)` 找到合适的 `StrategyHandler`;② 调用该 handler 的 `apply(...)`;③ 若未命中则走 `defaultStrategyHandler` | 同时实现 `StrategyMapper` 与 `StrategyHandler`,但自身保持 *抽象*,把细节延迟到子类 |
|
||||||
|
|
||||||
|
**业务装配层:一棵可编排的策略树**
|
||||||
|
|
||||||
|
```text
|
||||||
|
RootNode -> SwitchNode -> MarketNode -> EndNode
|
||||||
|
↘︎ OtherNode ...
|
||||||
|
```
|
||||||
|
|
||||||
|
- 每个节点
|
||||||
|
|
||||||
|
继承 `AbstractGroupBuyMarketSupport`(业务基类)
|
||||||
|
|
||||||
|
- 实现 `get(...)`:决定当前节点的下一跳是哪一个节点
|
||||||
|
- 实现 `apply(...)`:实现节点自身应做的业务动作(或继续下钻)
|
||||||
|
|
||||||
|
- 组合方式
|
||||||
|
|
||||||
|
- **路由是“数据驱动”的**:并非工厂把链写死,而是**节点在运行期**根据 `request + context` 决定下一跳(可能是ERROR_NODE或END_NODE),灵活插拔。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**对外暴露层:工厂 + 服务支持类**
|
||||||
|
|
||||||
|
| 组件 | 主要职责 |
|
||||||
|
| --------------------------------------------- | ------------------------------------------------------------ |
|
||||||
|
| `DefaultActivityStrategyFactory` (`@Service`) | 仅负责把 `RootNode` 暴露为 `StrategyHandler` 入口(交由 Spring 管理,方便注入)。 |
|
||||||
|
| `AbstractGroupBuyMarketSupport` | **业务服务基类**:封装拼团场景下**共用**的查询、工具方法;供每个**节点**继承使用 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
#### 本项目执行总览:
|
||||||
|
|
||||||
|
**调用入口**:`factory.strategyHandler()` → 返回 `RootNode`(实现了 `StrategyHandler`)。
|
||||||
|
|
||||||
|
**执行流程**:
|
||||||
|
|
||||||
|
`apply(...)`:模板入口,**先**跑 `multiThread(...)` 预取/并发任务,**再**跑 `doApply(...)`。
|
||||||
|
|
||||||
|
`doApply(...)`:每个节点自己的业务;**通常在末尾调用** `router(...)` 继续下一个节点(你现在就是这样写的:`return router(request, ctx);`)。也可以在某些节点“短路返回”,不再路由。
|
||||||
|
|
||||||
|
`router(...)`:内部调用当前节点的 `get(...)` 来**挑选下一节点**`next`,若存在就调用 `next.apply(...)` 递归推进;若不存在(或是到达 `EndNode`),则**收束返回**。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**RootNode**
|
||||||
|
|
||||||
|
- 校验必填:`userId/goodsId/source/channel`。
|
||||||
|
- 合法则路由到 `SwitchNode`;非法直接抛 `ILLEGAL_PARAMETER`。
|
||||||
|
|
||||||
|
**SwitchNode(总开关、不区分活动,做总体的降级限流)**
|
||||||
|
|
||||||
|
- 调用 `repository.downgradeSwitch()` 判断是否降级;是则抛 `E0003`。
|
||||||
|
- 调用 `repository.cutRange(userId)` 做切量;不在范围抛 `E0004`。
|
||||||
|
- 通过后路由到 `MarketNode`。
|
||||||
|
|
||||||
|
**MarketNode**
|
||||||
|
|
||||||
|
- **multiThread(...)** 中并发拉取:
|
||||||
|
- 拼团活动配置 `GroupBuyActivityDiscountVO`
|
||||||
|
- 商品信息 `SkuVO`
|
||||||
|
- 写入 `DynamicContext`
|
||||||
|
- **doApply(...)**
|
||||||
|
- 读取配置 + SKU,按 `marketPlan` 选 `IDiscountCalculateService`,计算 `payPrice` / `deductionPrice` 并写回上下文。
|
||||||
|
- 路由判定:
|
||||||
|
- 若配置/商品/`deductionPrice` 有缺失 → `ErrorNode`
|
||||||
|
- 否则 → `TagNode`
|
||||||
|
|
||||||
|
**TagNode(业务相关,部分人不在本次活动范围内!)**
|
||||||
|
|
||||||
|
- 若活动没配置 `tagId` → 视为不限定人群:`visible=true`、`enable=true`。
|
||||||
|
- 否则通过 `repository.isTagCrowdRange(tagId, userId)` 判断是否在人群内,并据此更新 `visible/enable`。
|
||||||
|
- 路由到 `EndNode`。
|
||||||
|
|
||||||
|
**EndNode**
|
||||||
|
|
||||||
|
- 从 `DynamicContext` 读取:`skuVO / payPrice / deductionPrice / groupBuyActivityDiscountVO / visible / enable`;
|
||||||
|
- **构建并返回**最终的 `TrialBalanceEntity`,链路终止。
|
||||||
|
|
||||||
|
**ErrorNode**
|
||||||
|
|
||||||
|
- 统一异常出口;若无配置/无商品,抛 `E0002`;否则可返回空结果作为兜底;
|
||||||
|
- 返回后走 `defaultStrategyHandler`(结束)。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
998
项目/智能协同云图库.md
998
项目/智能协同云图库.md
@ -1,998 +0,0 @@
|
|||||||
# 智能协同云图库
|
|
||||||
|
|
||||||
## 待完善功能:
|
|
||||||
|
|
||||||
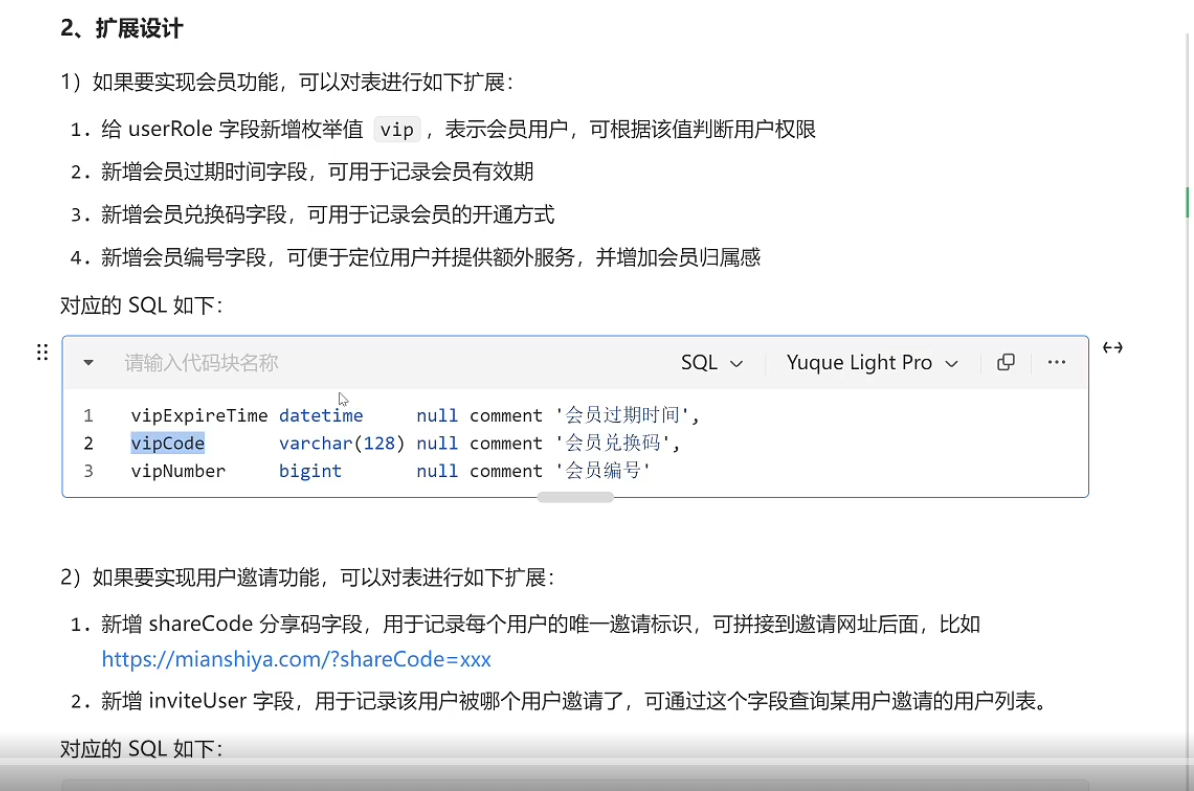
用户模块扩展功能:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
2.JWT校验,可能要同时改前端,把userId保存到ThreadLocal中
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
3.目前这些标签写死了,可以用redis、数据库进行动态设置。(根据点击次数)
|
|
||||||
|
|
||||||
```java
|
|
||||||
@GetMapping("/tag_category")
|
|
||||||
public BaseResponse<PictureTagCategory> listPictureTagCategory() {
|
|
||||||
PictureTagCategory pictureTagCategory = new PictureTagCategory();
|
|
||||||
List<String> tagList = Arrays.asList("热门", "搞笑", "生活", "高清", "艺术", "校园", "背景", "简历", "创意");
|
|
||||||
List<String> categoryList = Arrays.asList("模板", "电商", "表情包", "素材", "海报");
|
|
||||||
pictureTagCategory.setTagList(tagList);
|
|
||||||
pictureTagCategory.setCategoryList(categoryList);
|
|
||||||
return ResultUtils.success(pictureTagCategory);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
4.图片审核扩展
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
5.爬图扩展
|
|
||||||
|
|
||||||
2)记录从哪里爬的
|
|
||||||
|
|
||||||
4)bing直接搜可能也是缩略图,可能模拟手点一次图片,再爬会清晰一点
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
6.缓存扩展
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
图片压缩
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
文件秒传,md5校验,如果已有,直接返回url,不用重新上传(图片场景不必使用)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
分片上传和断点续传:[对象存储 上传对象_腾讯云](https://cloud.tencent.com/document/product/436/65935#0c1fbdc5-64c1-4224-9aa5-92fbd0ae6780)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
CDN内容分发,后期项目上线之后搞一下。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
浏览器缓存
|
|
||||||
|
|
||||||
是服务器(或 CDN/静态文件服务器)在返回资源时下发给浏览器的。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
用户空间扩展:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
图片编辑
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
AI扩图
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**创建图片的业务流程**
|
|
||||||
创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
|
|
||||||
|
|
||||||
有两种常见的处理方式:
|
|
||||||
|
|
||||||
1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的**url存储地址**;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。
|
|
||||||
2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。
|
|
||||||
当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 优化
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
协同编辑:
|
|
||||||
扩展
|
|
||||||
1、为防止消息丢失,可以使用 Redis 等高性能存储保存执行的操作记录。
|
|
||||||
|
|
||||||
目前如果图片已经被编辑了,新用户加入编辑时没办法查看到已编辑的状态,这一点也可以利用 Redis 保存操作记录来解决,新用户加入编辑时读取 Redis 的操作记录即可。
|
|
||||||
|
|
||||||
2、每种类型的消息处理可以封装为独立的 Handler 处理器类,也就是采用策略模式。
|
|
||||||
|
|
||||||
3、支持分布式 WebSocket。实现思路很简单,只需要保证要编辑同一图片的用户连接的是相同的服务器即可,和游戏分服务器大区、聊天室分房间是类似的原理。
|
|
||||||
|
|
||||||
4、一些小问题的优化:比如 WebSocket 连接建立之后,如果用户退出了登录,这时 WebSocket 的连接是没有断开的。不过影响并不大,可以思考下怎么处理。
|
|
||||||
|
|
||||||
## 踩坑
|
|
||||||
|
|
||||||
#### **精度损失和日期格式转换问题**
|
|
||||||
|
|
||||||
##### **前端 → 后端**
|
|
||||||
|
|
||||||
**日期**
|
|
||||||
|
|
||||||
前端把日期格式化成后端期待的纯日期**字符串**,例如 `"2025-08-14"`,后端 DTO 用 `LocalDate` 接收(配合 `@JsonFormat(pattern="yyyy-MM-dd")`),Jackson 反序列化成 `LocalDate`。
|
|
||||||
|
|
||||||
**精度:**
|
|
||||||
|
|
||||||
JavaScript 的 `number` 类型只能安全地表示到 2^53−1(约 9×10^15)的整数,超过这个范围就会丢失精度,用 `number` 传给后端时末尾只能补0;
|
|
||||||
|
|
||||||
解决办法:前端 ID 当做字符串传给后端。
|
|
||||||
|
|
||||||
Spring MVC 会自动调用 `Long.parseLong("1951619197178556418")` 并赋值给你方法签名里的 `long id`(即还是写作long来接收,不变)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
##### **后端 → 前端**
|
|
||||||
|
|
||||||
**日期:**
|
|
||||||
|
|
||||||
后端用 `LocalDate` / `LocalDateTime` 之类的 Java 8 类型,经过 Jackson 序列化为指定格式的字符串(比如 `"yyyy-MM-dd"` / `"yyyy-MM-dd HH:mm:ss"`)供前端消费,避免时间戳或默认格式的不一致。
|
|
||||||
|
|
||||||
**精度:**
|
|
||||||
|
|
||||||
Java 的 `long` 可能超过 JavaScript `number` 的安全范围(2^53−1),直接以数字输出会丢失精度。必须把 `long`/`Long` 序列化成**字符串**(例如 ID 输出为 `"1951648800160399362"`),前端拿到字符串再展示。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
对 Jackson 用作 Spring 的 HTTP 消息转换器的 `ObjectMapper` 进行配置(日期格式、Java 8 时间支持、Long 转字符串等)示例代码:
|
|
||||||
|
|
||||||
```java
|
|
||||||
@Configuration
|
|
||||||
public class JacksonConfig {
|
|
||||||
|
|
||||||
private static final String DATE_FORMAT = "yyyy-MM-dd";
|
|
||||||
private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
|
|
||||||
private static final String TIME_FORMAT = "HH:mm:ss";
|
|
||||||
|
|
||||||
@Bean
|
|
||||||
public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() {
|
|
||||||
return builder -> {
|
|
||||||
builder.featuresToDisable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
|
|
||||||
builder.simpleDateFormat(DATETIME_FORMAT);
|
|
||||||
builder.featuresToDisable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
|
|
||||||
|
|
||||||
JavaTimeModule javaTime = new JavaTimeModule();
|
|
||||||
javaTime.addSerializer(LocalDateTime.class,
|
|
||||||
new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT)));
|
|
||||||
javaTime.addSerializer(LocalDate.class,
|
|
||||||
new LocalDateSerializer(DateTimeFormatter.ofPattern(DATE_FORMAT)));
|
|
||||||
javaTime.addSerializer(LocalTime.class,
|
|
||||||
new LocalTimeSerializer(DateTimeFormatter.ofPattern(TIME_FORMAT)));
|
|
||||||
javaTime.addDeserializer(LocalDateTime.class,
|
|
||||||
new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT)));
|
|
||||||
javaTime.addDeserializer(LocalDate.class,
|
|
||||||
new LocalDateDeserializer(DateTimeFormatter.ofPattern(DATE_FORMAT)));
|
|
||||||
javaTime.addDeserializer(LocalTime.class,
|
|
||||||
new LocalTimeDeserializer(DateTimeFormatter.ofPattern(TIME_FORMAT)));
|
|
||||||
|
|
||||||
SimpleModule longToString = new SimpleModule();
|
|
||||||
longToString.addSerializer(Long.class, ToStringSerializer.instance);
|
|
||||||
longToString.addSerializer(Long.TYPE, ToStringSerializer.instance);
|
|
||||||
|
|
||||||
builder.modules(javaTime, longToString);
|
|
||||||
};
|
|
||||||
}
|
|
||||||
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**数据库密码加密**
|
|
||||||
|
|
||||||
加密存储确保即使数据库泄露,攻击者也不能轻易获取用户原始密码。
|
|
||||||
|
|
||||||
spring security中提供了一个加密类**BCryptPasswordEncoder**。
|
|
||||||
|
|
||||||
它采用[哈希算法](https://so.csdn.net/so/search?q=哈希算法&spm=1001.2101.3001.7020) SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种**可逆**的算法,而哈希算法是一种**不可逆**的算法。
|
|
||||||
|
|
||||||
因为有随机盐的存在,所以**相同的明文密码**经过加密后的密码是**不一样**的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的
|
|
||||||
|
|
||||||
验证密码 **matches**
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 使用 matches 方法来对比明文密码和存储的哈希密码
|
|
||||||
boolean judge= passwordEncoder.matches(rawPassword, user.getPassword());
|
|
||||||
```
|
|
||||||
|
|
||||||
注意,`matches`的第一个参数**必须** 是 “**原始明文**”,第二个参数 **必须** 是 “**已经加密过的密文**”!!!**顺序不能反!!!**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 收获
|
|
||||||
|
|
||||||
### MybatisX插件简化开发
|
|
||||||
|
|
||||||
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
|
|
||||||
|
|
||||||
注意,勾选Actual Column生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即user_name->userName
|
|
||||||
|
|
||||||
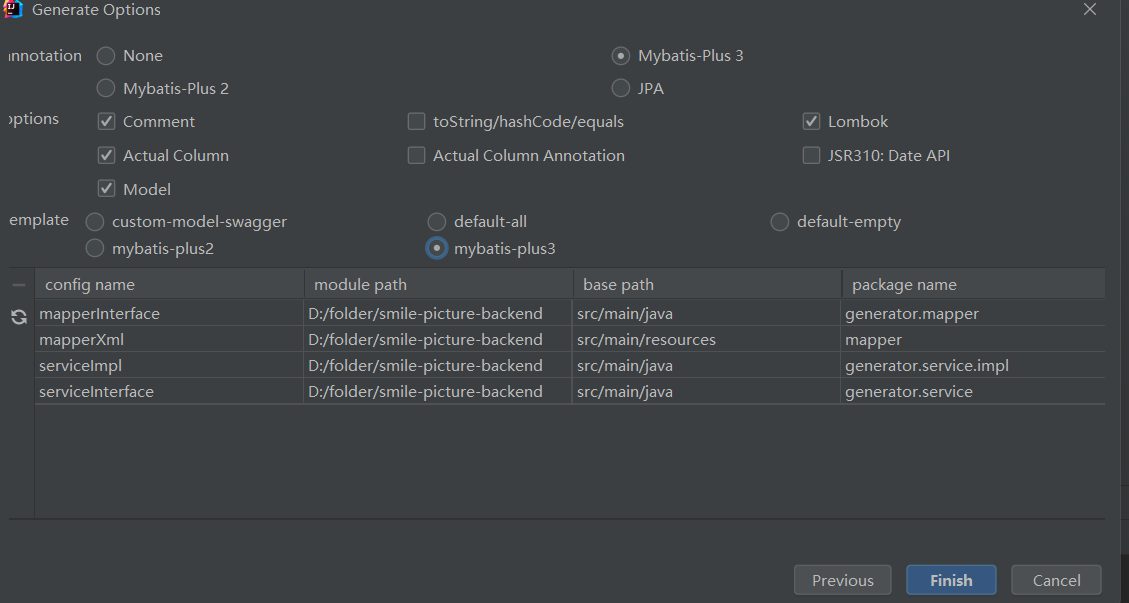
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
下载GenerateSerailVersionUID插件,可以右键->generate->生成序列ID:
|
|
||||||
|
|
||||||
```java
|
|
||||||
private static final long serialVersionUID = -1321880859645675653L;
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 胡图工具类hutool
|
|
||||||
|
|
||||||
**引入依赖**
|
|
||||||
|
|
||||||
```xml
|
|
||||||
<dependency>
|
|
||||||
<groupId>cn.hutool</groupId>
|
|
||||||
<artifactId>hutool-all</artifactId>
|
|
||||||
<version>5.8.26</version>
|
|
||||||
</dependency>
|
|
||||||
```
|
|
||||||
|
|
||||||
`ObjUtil.isNotNull(Object obj)`,仅判断对象是否 **不为 `null`**,不关心对象内容是否为空,比如空字符串 `""`、空集合 `[]`、数字 `0` 等都算是“非 null”。
|
|
||||||
|
|
||||||
`ObjUtil.isNotEmpty(Object obj)` 判断对象是否 **不为 null 且非“空”**
|
|
||||||
|
|
||||||
- 对不同类型的对象判断逻辑不同:
|
|
||||||
- `CharSequence`(String):长度大于 0
|
|
||||||
- `Collection`:size > 0
|
|
||||||
- `Map`:非空
|
|
||||||
- `Array`:长度 > 0
|
|
||||||
- 其它对象:只判断是否为 null(默认不认为“空”)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
`StrUtil.isNotEmpty(String str) `只要不是 `null` 且长度大于 0 就算“非空”。
|
|
||||||
|
|
||||||
`StrUtil.isNotBlank(String str)` 不仅要非 `null`,还要**不能只包含空格、换行、Tab 等空白字符**
|
|
||||||
|
|
||||||
`StrUtil.hasBlank(CharSequence... strs)`只要 **至少一个字符串是 blank(空或纯空格)**就返回 `true`,底层其实就是对每个参数调用 `StrUtil.isBlank(...)`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
`CollUtil.isNotEmpty(Collection<?> coll)`用于判断 **集合(Collection)是否非空**,功能类似于 `ObjUtil.isNotEmpty(...)`
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
`BeanUtil.toBean` :用来**把一个 Map、JSONObject 或者另一个对象快速转换成你的目标 JavaBean**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class BeanUtilExample {
|
|
||||||
public static class User {
|
|
||||||
private String name;
|
|
||||||
private Integer age;
|
|
||||||
// 省略 getter/setter
|
|
||||||
}
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
// 1. 从 Map 转 Bean
|
|
||||||
Map<String, Object> data = new HashMap<>();
|
|
||||||
data.put("name", "Alice");
|
|
||||||
data.put("age", 30);
|
|
||||||
User user1 = BeanUtil.toBean(data, User.class);
|
|
||||||
System.out.println(user1.getName()); // Alice
|
|
||||||
|
|
||||||
// 2. 从另一个对象转 Bean
|
|
||||||
class Temp { public String name = "Bob"; public int age = 25; }
|
|
||||||
Temp temp = new Temp();
|
|
||||||
User user2 = BeanUtil.toBean(temp, User.class);
|
|
||||||
System.out.println(user2.getAge()); // 25
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 多级缓存
|
|
||||||
|
|
||||||
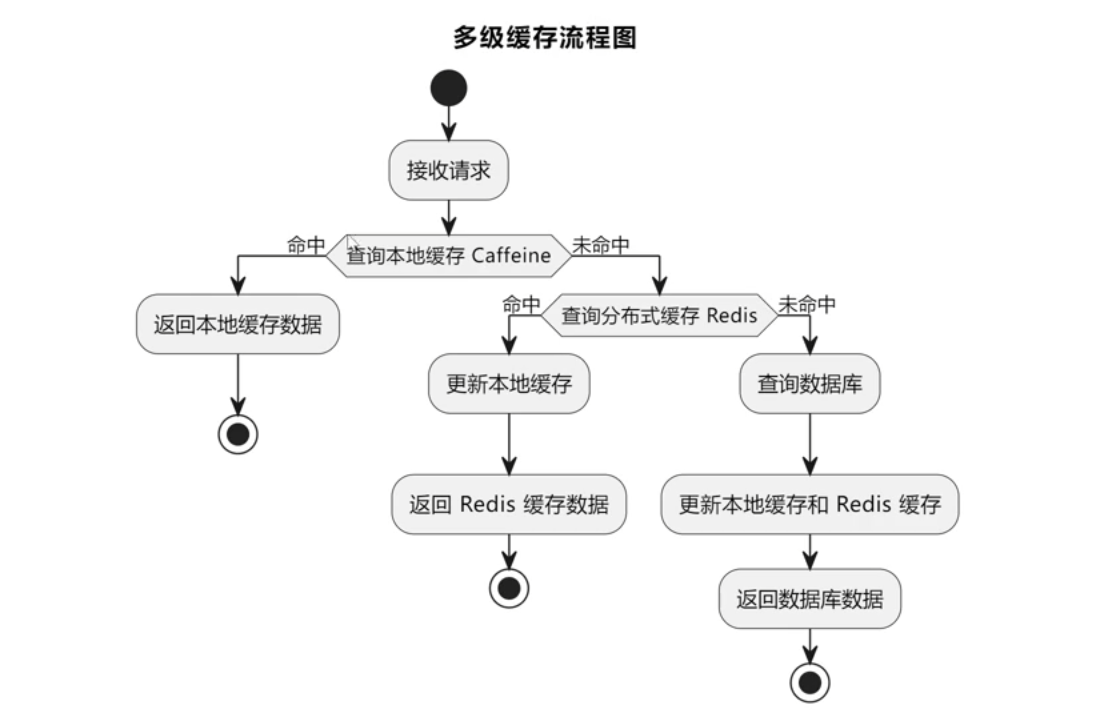
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Redis+Session
|
|
||||||
|
|
||||||
之前我们每次重启服务器都要重新登陆,既然已经整合了 `Redis`,不妨使用 `Redis` 管理` Session`,更好地维护登录态。
|
|
||||||
|
|
||||||
1)先在 `Maven `中引入 `spring-session-data-redis` 库:
|
|
||||||
|
|
||||||
```xml
|
|
||||||
<!-- Spring Session + Redis -->
|
|
||||||
<dependency>
|
|
||||||
<groupId>org.springframework.session</groupId>
|
|
||||||
<artifactId>spring-session-data-redis</artifactId>
|
|
||||||
</dependency>
|
|
||||||
```
|
|
||||||
|
|
||||||
2)修改 `application.yml` 配置文件,更改`Session`的存储方式和过期时间:
|
|
||||||
|
|
||||||
既要设置redis能存30天,发给前端的cookie也要30天有效期。
|
|
||||||
|
|
||||||
```
|
|
||||||
spring:
|
|
||||||
# session 配置
|
|
||||||
session:
|
|
||||||
store-type: redis
|
|
||||||
# session 30 天过期
|
|
||||||
timeout: 2592000
|
|
||||||
server:
|
|
||||||
port: 8123
|
|
||||||
servlet:
|
|
||||||
context-path: /api
|
|
||||||
# cookie 30 天过期
|
|
||||||
session:
|
|
||||||
cookie:
|
|
||||||
max-age: 2592000
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 为什么用 `ConcurrentHashMap<Long,Object>` 管理锁更优?
|
|
||||||
|
|
||||||
1. **避免污染常量池**
|
|
||||||
`String.intern()` 会把每一个不同的 `userId` 字符串都放到 JVM 的字符串常量池里,随着用户量增长,常量池里的内容会越来越多,可能导致元空间(MetaSpace)/永久代(PermGen)压力过大。
|
|
||||||
2. **显式可控的锁生命周期**
|
|
||||||
- 用 `ConcurrentHashMap` 明确地管理——「只要 map 里有这个 key,就有对应的锁对象;不需要时可以删掉。」
|
|
||||||
- 相比之下,`intern()` 后的字符串对象由 JVM 常量池管理,代码里很难清理,存在内存泄漏风险。
|
|
||||||
3. **高并发性能更好**
|
|
||||||
- `ConcurrentHashMap` 内部采用分段锁或 Node 锁定(取决于 JDK 版本),即便高并发下往 map 里 `computeIfAbsent` 也能保持较高吞吐。
|
|
||||||
- `synchronized (lock)` 本身只锁定单个用户对应的那把锁,不影响其他用户;结合 `ConcurrentHashMap` 的高并发特性,整体性能比直接在一个全局 `HashMap` + `synchronized` 好得多。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 锁+事务可能出现的问题
|
|
||||||
|
|
||||||
**`@Transactional`(声明式)**
|
|
||||||
|
|
||||||
- 事务在方法入口打开,很可能在拿锁前就占用连接/数据库资源,导致“空跑事务”+“资源耗尽”。
|
|
||||||
- 依赖代理,存在自调用失效的坑。
|
|
||||||
|
|
||||||
**`transactionTemplate.execute()`(编程式)**
|
|
||||||
|
|
||||||
- 锁先行→事务后发,确保高并发下只有一个连接/事务进数据库,极大降低资源竞争。
|
|
||||||
- 全程显式,放到哪儿就是哪儿,杜绝自调用/代理链带来的隐患。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**锁+事务`@Transactional`一起可能出现问题:**
|
|
||||||
|
|
||||||
**线程 A**
|
|
||||||
|
|
||||||
- 进入方法,Spring AOP 拦截,**立即开启事务**
|
|
||||||
- 走到 `synchronized(lock)`,拿到锁
|
|
||||||
- 在锁里执行 `exists` → `save`(但真正的 “提交” 要等到方法返回后才做)
|
|
||||||
- 退出 `synchronized` 块,方法继续执行(其实已经没别的逻辑了)
|
|
||||||
- 方法返回,事务拦截器这时才 **提交**
|
|
||||||
|
|
||||||
**线程 B**(并发进来)
|
|
||||||
|
|
||||||
- 等待 AOP 代理,进入同一个方法,**也会马上开启自己的事务**
|
|
||||||
- 在入口就拿到一个新的连接/事务上下文
|
|
||||||
- 然后遇到 `synchronized(lock)`,**在这里阻塞** 等 A 释放锁
|
|
||||||
- A 一旦走出 `synchronized`,B 立刻拿到锁——但此时 A **还没真正提交**(提交在方法尾被拦截器做)
|
|
||||||
- B 在锁里执行 `exists`:因为 A 的改动还在 A 的未提交事务里,**默认隔离级别(READ_COMMITTED)下看不到**,所以 `exists` 会返回 `false`
|
|
||||||
- B 就继续 `save`,结果就可能插入重复记录,或者引发唯一索引冲突
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
团队空间
|
|
||||||
|
|
||||||
空间和用户是多对多的关系,还要同时记录用户在某空间的角色,所以需要新建关联表
|
|
||||||
|
|
||||||
```sql
|
|
||||||
-- 空间成员表
|
|
||||||
create table if not exists space_user
|
|
||||||
(
|
|
||||||
id bigint auto_increment comment 'id' primary key,
|
|
||||||
spaceId bigint not null comment '空间 id',
|
|
||||||
userId bigint not null comment '用户 id',
|
|
||||||
spaceRole varchar(128) default 'viewer' null comment '空间角色:viewer/editor/admin',
|
|
||||||
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
|
|
||||||
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
|
|
||||||
-- 索引设计
|
|
||||||
UNIQUE KEY uk_spaceId_userId (spaceId, userId), -- 唯一索引,用户在一个空间中只能有一个角色
|
|
||||||
INDEX idx_spaceId (spaceId), -- 提升按空间查询的性能
|
|
||||||
INDEX idx_userId (userId) -- 提升按用户查询的性能
|
|
||||||
) comment '空间用户关联' collate = utf8mb4_unicode_ci;
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### RBAC模型
|
|
||||||
|
|
||||||
团队空间:
|
|
||||||
|
|
||||||
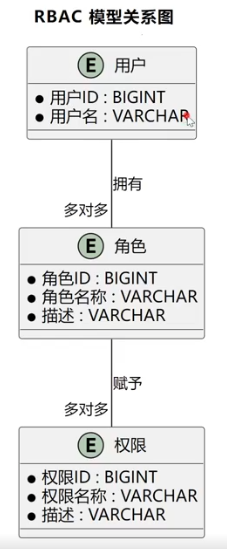
|
|
||||||
|
|
||||||
一般来说,标准的` RBAC` 实现需要 5 张表:用户表、角色表、权限表、用户角色关联表、角色权限关联表,还是有一定开发成本的。由于我们的项目中,团队空间不需要那么多角色,可以简化`RBAC` 的实现方式,比如将角色和权限直接定义到配置文件中。
|
|
||||||
|
|
||||||
本项目角色:
|
|
||||||
|
|
||||||
| 角色 | 描述 |
|
|
||||||
| ------ | ---------------------------- |
|
|
||||||
| 浏览者 | 仅可查看空间中的图片内容 |
|
|
||||||
| 编辑者 | 可查看、上传和编辑图片内容 |
|
|
||||||
| 管理员 | 拥有管理空间和成员的所有权限 |
|
|
||||||
|
|
||||||
本项目权限:
|
|
||||||
|
|
||||||
| 权限键 | 功能名称 | 描述 |
|
|
||||||
| -------------- | -------- | ---------------------------- |
|
|
||||||
| spaceUsername | 成员管理 | 管理空间成员,添加或移除成员 |
|
|
||||||
| picture:view | 查看图片 | 查看空间中的图片内容 |
|
|
||||||
| picture:upload | 上传图片 | 上传图片到空间中 |
|
|
||||||
| picture:edit | 修改图片 | 编辑已上传的图片信息 |
|
|
||||||
| picture:delete | 删除图片 | 删除空间中的图片 |
|
|
||||||
|
|
||||||
角色权限映射:
|
|
||||||
|
|
||||||
| 角色 | 对应权限键 | 可执行功能 |
|
|
||||||
| ------ | ------------------------------------------------------------ | ------------------------------------------------ |
|
|
||||||
| 浏览者 | picture:view | 查看图片 |
|
|
||||||
| 编辑者 | picture:view, picture:upload, picture:edit, picture:delete | 查看图片、上传图片、修改图片、删除图片 |
|
|
||||||
| 管理员 | spaceUsername, picture:view, picture:upload, picture:edit, picture:delete | 成员管理、查看图片、上传图片、修改图片、删除图片 |
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限校验呢?
|
|
||||||
|
|
||||||
1)最直接的方案是像之前校验私有空间权限一样,封装个团队空间的权限校验方法;或者类似用户权限校验一样,写个注解 + AOP 切面。
|
|
||||||
|
|
||||||
2)对于复杂的角色和权限管理,可以选用现成的第三方权限校验框架来实现,编写一套权限校验规则代码后,就能整体管理系统的权限校验逻辑了。( Sa-Token)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Sa-Token
|
|
||||||
|
|
||||||
#### 快速入门
|
|
||||||
|
|
||||||
1)引入:
|
|
||||||
|
|
||||||
```xml
|
|
||||||
<!-- Sa-Token 权限认证 -->
|
|
||||||
<dependency>
|
|
||||||
<groupId>cn.dev33</groupId>
|
|
||||||
<artifactId>sa-token-spring-boot-starter</artifactId>
|
|
||||||
<version>1.39.0</version>
|
|
||||||
</dependency>
|
|
||||||
```
|
|
||||||
|
|
||||||
2)让 `Sa-Token` 整合 `Redis`,将用户的登录态等内容保存在` Redis` 中。
|
|
||||||
|
|
||||||
```xml
|
|
||||||
<!-- Sa-Token 整合 Redis (使用 jackson 序列化方式) -->
|
|
||||||
<dependency>
|
|
||||||
<groupId>cn.dev33</groupId>
|
|
||||||
<artifactId>sa-token-redis-jackson</artifactId>
|
|
||||||
<version>1.39.0</version>
|
|
||||||
</dependency>
|
|
||||||
<!-- 提供Redis连接池 -->
|
|
||||||
<dependency>
|
|
||||||
<groupId>org.apache.commons</groupId>
|
|
||||||
<artifactId>commons-pool2</artifactId>
|
|
||||||
</dependency>
|
|
||||||
```
|
|
||||||
|
|
||||||
3)基本用法
|
|
||||||
|
|
||||||
`StpUtil` 是 Sa-Token 提供的全局静态工具。
|
|
||||||
|
|
||||||
用户登录时调用 `login `方法,产生一个新的会话:
|
|
||||||
|
|
||||||
```java
|
|
||||||
StpUtil.login(10001);
|
|
||||||
```
|
|
||||||
|
|
||||||
还可以给会话保存一些信息,比如登录用户的信息:
|
|
||||||
|
|
||||||
```java
|
|
||||||
StpUtil.getSession().set("user", user)
|
|
||||||
```
|
|
||||||
|
|
||||||
接下来就可以判断用户是否登录、获取用户信息了,可以通过代码进行判断:
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 检验当前会话是否已经登录, 如果未登录,则抛出异常:`NotLoginException`
|
|
||||||
StpUtil.checkLogin();
|
|
||||||
// 获取用户信息
|
|
||||||
StpUtil.getSession().get("user");
|
|
||||||
```
|
|
||||||
|
|
||||||
也可以参考 [官方文档](https://sa-token.cc/doc.html#/use/at-check),使用注解进行鉴权:
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 登录校验:只有登录之后才能进入该方法
|
|
||||||
@SaCheckLogin
|
|
||||||
@RequestMapping("info")
|
|
||||||
public String info() {
|
|
||||||
return "查询用户信息";
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### passwordEncoder多账号体系
|
|
||||||
|
|
||||||
若项目中存在两套权限校验体系。一套是 user 表的,分为普通用户和管理员;另一套是对团队空间的权限进行校验。
|
|
||||||
|
|
||||||
为了更轻松地扩展项目,减少对原有代码的改动,我们原有的 user 表权限校验依然使用自定义注解 + AOP 的方式实现。而团队空间权限校验,采用 Sa-Token 来管理。
|
|
||||||
|
|
||||||
这种同一项目有多账号体系的情况下,不建议使用 Sa-Token 默认的账号体系,而是使用 Sa-Token 提供的多账号认证特性,可以将多套账号的授权给区分开,让它们互不干扰。
|
|
||||||
|
|
||||||
使用 [Kit 模式](https://sa-token.cc/doc.html#/up/many-account?id=_5、kit模式) 实现多账号认证
|
|
||||||
|
|
||||||
```java
|
|
||||||
/**
|
|
||||||
* StpLogic 门面类,管理项目中所有的 StpLogic 账号体系
|
|
||||||
* 添加 @Component 注解的目的是确保静态属性 DEFAULT 和 SPACE 被初始化
|
|
||||||
*/
|
|
||||||
@Component
|
|
||||||
public class StpKit {
|
|
||||||
|
|
||||||
public static final String SPACE_TYPE = "space";
|
|
||||||
|
|
||||||
/**
|
|
||||||
* 默认原生会话对象,项目中目前没使用到
|
|
||||||
*/
|
|
||||||
public static final StpLogic DEFAULT = StpUtil.stpLogic;
|
|
||||||
|
|
||||||
/**
|
|
||||||
* Space 会话对象,管理 Space 表所有账号的登录、权限认证
|
|
||||||
*/
|
|
||||||
public static final StpLogic SPACE = new StpLogic(SPACE_TYPE);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
修改用户服务的` userLogin` 方法,用户登录成功后,保存登录态到` Sa-Token` 的空间账号体系中:
|
|
||||||
|
|
||||||
```java
|
|
||||||
//记录用户的登录态
|
|
||||||
request.getSession().setAttribute(USER_LOGIN_STATE, user);
|
|
||||||
//记录用户登录态到 Sa-token,便于空间鉴权时使用,注意保证该用户信息与 SpringSession 中的信息过期时间一致
|
|
||||||
StpKit.SPACE.login(user.getId());
|
|
||||||
StpKit.SPACE.getSession().set(USER_LOGIN_STATE, user);
|
|
||||||
return this.getLoginUserVO(user);
|
|
||||||
```
|
|
||||||
|
|
||||||
之后就可以在代码中使用账号体系
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 检测当前会话是否以 Space 账号登录,并具有 picture:edit 权限
|
|
||||||
StpKit.SPACE.checkPermission("picture:edit");
|
|
||||||
|
|
||||||
// 获取当前 Space 会话的 Session 对象,并进行写值操作
|
|
||||||
StpKit.SPACE.getSession().set("user", "zy123");
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 权限认证逻辑
|
|
||||||
|
|
||||||
`Sa-Token` 开发的核心是**编写权限认证类**,我们需要在该类中实现 “如何根据登录**用户 `id`** 获取到用户**已有的角色和权限列表**” 方法。当要判断某用户是否有某个角色或权限时,`Sa-Token` 会先执行我们编写的方法,得到该用户的角色或权限列表,然后跟需要的角色权限进行**比对**。
|
|
||||||
|
|
||||||
参考 [官方文档](https://sa-token.cc/doc.html#/use/jur-auth),示例权限认证类如下:
|
|
||||||
|
|
||||||
```java
|
|
||||||
/**
|
|
||||||
* 自定义权限加载接口实现类
|
|
||||||
*/
|
|
||||||
@Component // 保证此类被 SpringBoot 扫描,完成 Sa-Token 的自定义权限验证扩展
|
|
||||||
public class StpInterfaceImpl implements StpInterface {
|
|
||||||
|
|
||||||
/**
|
|
||||||
* 返回一个账号所拥有的权限码集合
|
|
||||||
*/
|
|
||||||
@Override
|
|
||||||
public List<String> getPermissionList(Object loginId, String loginType) {
|
|
||||||
// 本 list 仅做模拟,实际项目中要根据具体业务逻辑来查询权限
|
|
||||||
List<String> list = new ArrayList<String>();
|
|
||||||
list.add("user.add");
|
|
||||||
list.add("user.update");
|
|
||||||
list.add("user.get");
|
|
||||||
list.add("art.*");
|
|
||||||
return list;
|
|
||||||
}
|
|
||||||
|
|
||||||
/**
|
|
||||||
* 返回一个账号所拥有的角色标识集合 (权限与角色可分开校验)
|
|
||||||
*/
|
|
||||||
@Override
|
|
||||||
public List<String> getRoleList(Object loginId, String loginType) {
|
|
||||||
// 本 list 仅做模拟,实际项目中要根据具体业务逻辑来查询权限
|
|
||||||
List<String> list = new ArrayList<String>();
|
|
||||||
list.add("admin");
|
|
||||||
list.add("super-admin");
|
|
||||||
return list;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
`Sa-Token` 支持按照角色和权限校验,对于权限不多的项目,基于角色校验即可;对于权限较多的项目,建议根据权限校验。二选一即可,最好不要混用!
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
关键问题:如何在 `Sa-Token `中获取当前请求操作的参数?
|
|
||||||
|
|
||||||
使用 Sa-Token 有 2 种方式 —— **注解式和编程式** ,但**都要实现**上面的StpInterface接口。
|
|
||||||
|
|
||||||
如果使用**注解式**,那么在接口被调用时就会立刻触发 Sa-Token 的权限校验,此时参数只能通过 Servlet 的**请求对象**传递,必须具有指定权限才能进入该方法!
|
|
||||||
|
|
||||||
使用[ 注解合并](https://sa-token.cc/doc.html#/up/many-account?id=_7、使用注解合并简化代码) 简化代码。
|
|
||||||
|
|
||||||
```java
|
|
||||||
@SaSpaceCheckPermission(value = SpaceUserPermissionConstant.PICTURE_UPLOAD)
|
|
||||||
public BaseResponse<PictureVO> uploadPicture() {
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
如果使用**编程式**,可以在函数内的任意位置执行权限校验,只要在执行前将参数放到当前线程的上下文 ThreadLocal 对象中,就能在鉴权时获取到了。
|
|
||||||
|
|
||||||
**注意,只要加上了` Sa-Token` 注解,框架就会强制要求用户登录,未登录会抛出异常。**所以针对未登录也可以调用的接口,需要改为编程式权限校验
|
|
||||||
|
|
||||||
```java
|
|
||||||
@GetMapping("/get/vo")
|
|
||||||
public BaseResponse<PictureVO> getPictureVOById(long id, HttpServletRequest request) {
|
|
||||||
ThrowUtils.throwIf(id <= 0, ErrorCode.PARAMS_ERROR);
|
|
||||||
// 查询数据库
|
|
||||||
Picture picture = pictureService.getById(id);
|
|
||||||
ThrowUtils.throwIf(picture == null, ErrorCode.NOT_FOUND_ERROR);
|
|
||||||
// 空间的图片,需要校验权限
|
|
||||||
Space space = null;
|
|
||||||
Long spaceId = picture.getSpaceId();
|
|
||||||
if (spaceId != null) {
|
|
||||||
boolean hasPermission = StpKit.SPACE.hasPermission(SpaceUserPermissionConstant.PICTURE_VIEW);
|
|
||||||
ThrowUtils.throwIf(!hasPermission, ErrorCode.NO_AUTH_ERROR);
|
|
||||||
}
|
|
||||||
PictureVO pictureVO = pictureService.getPictureVO(picture, request);
|
|
||||||
// 获取封装类
|
|
||||||
return ResultUtils.success(pictureVO);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 循环依赖问题
|
|
||||||
|
|
||||||
```text
|
|
||||||
PictureController
|
|
||||||
↓ 注入 PictureServiceImpl
|
|
||||||
PictureServiceImpl
|
|
||||||
↓ 注入 SpaceServiceImpl
|
|
||||||
SpaceServiceImpl
|
|
||||||
↓ 注入 SpaceUserServiceImpl
|
|
||||||
SpaceUserServiceImpl
|
|
||||||
↓ 注入 SpaceServiceImpl ←—— 又回到 SpaceServiceImpl
|
|
||||||
```
|
|
||||||
|
|
||||||
解决办法:将一方改成 setter 注入并加上 `@Lazy`注解
|
|
||||||
|
|
||||||
如在`SpaceUserServiceImpl`中
|
|
||||||
|
|
||||||
```java
|
|
||||||
import org.springframework.context.annotation.Lazy;
|
|
||||||
|
|
||||||
@Resource
|
|
||||||
@Lazy
|
|
||||||
private SpaceService spaceService;
|
|
||||||
```
|
|
||||||
|
|
||||||
@Lazy为懒加载,直到真正第一次使用它时才去创建或注入。且这里**不能用构造器注入**的方式!!!
|
|
||||||
|
|
||||||
这里有个坑: `import groovy.lang.Lazy;` 导入这个包的@lazy注解就无效!
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 分库分表
|
|
||||||
|
|
||||||
如果某团队空间的图片数量比较多,可以对其数据进行单独的管理。
|
|
||||||
|
|
||||||
1、图片信息数据
|
|
||||||
可以给每个团队空间单独创建一张图片表 picture_{spaceId},也就是分库分表中的分表,而不是和公共图库、私有空间的图片混在一起。这样不仅查询空间内的图片效率更高,还便于整体管理和清理空间。但是要注意,仅对**旗舰版**空间生效,**否则分表的数量会特别多**,反而可能影响性能。
|
|
||||||
|
|
||||||
要实现的是会随着新增空间不断增加分表数量的**动态分表**,会使用分库分表框架 **Apache ShardingSphere** 带大家实现。
|
|
||||||
2、图片文件数据
|
|
||||||
|
|
||||||
已经实现隔离,存到COS上的不同桶内。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
思路主要是基于业务需求设计**数据分片规则**,将数据按一定策略(如取模、哈希、范围或时间)分散存储到多个库或表中,同时开发路由逻辑来决定查询或写入操作的目标库表。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### ShardingSphere 分库分表
|
|
||||||
|
|
||||||
```xml
|
|
||||||
<!-- 分库分表 -->
|
|
||||||
<dependency>
|
|
||||||
<groupId>org.apache.shardingsphere</groupId>
|
|
||||||
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
|
|
||||||
<version>5.2.0</version>
|
|
||||||
</dependency>
|
|
||||||
```
|
|
||||||
|
|
||||||
分库分表的策略总体分为 2 类:静态分表和动态分表
|
|
||||||
|
|
||||||
#### 分库分表策略 - 静态分表
|
|
||||||
|
|
||||||
静态分表:在设计阶段,分表的数量和规则就是固定的,不会根据业务增长动态调整,比如 picture_0、picture_1。
|
|
||||||
|
|
||||||
分片规则通常基于某一字段(如图片 id)通过简单规则(如取模、范围)来决定数据存储在哪个表或库中。
|
|
||||||
|
|
||||||
这种方式的优点是简单、好理解;缺点是不利于扩展,随着数据量增长,可能需要手动调整分表数量并迁移数据。
|
|
||||||
|
|
||||||
举个例子,图片表按图片` id` 对 3 取模拆分:
|
|
||||||
|
|
||||||
```java
|
|
||||||
String tableName = "picture_" + (picture_id % 3) // picture_0 ~ picture_2
|
|
||||||
```
|
|
||||||
|
|
||||||
静态分表的实现很简单,直接在 `application.yml `中编写 `ShardingSphere` 的配置就能完成分库分表,比如:
|
|
||||||
|
|
||||||
```yml
|
|
||||||
rules:
|
|
||||||
sharding:
|
|
||||||
tables:
|
|
||||||
picture:
|
|
||||||
actualDataNodes: ds0.picture_${0..2} # 3张分表:picture_0, picture_1, picture_2
|
|
||||||
tableStrategy:
|
|
||||||
standard:
|
|
||||||
shardingColumn: picture_id # 按 pictureId 分片
|
|
||||||
shardingAlgorithmName: pictureIdMod
|
|
||||||
shardingAlgorithms:
|
|
||||||
pictureIdMod:
|
|
||||||
type: INLINE #内置实现,直接在配置类中写规则,即下面的algorithm-expression
|
|
||||||
props:
|
|
||||||
algorithm-expression: picture_${pictureId % 3} # 分片表达式
|
|
||||||
```
|
|
||||||
|
|
||||||
甚至不需要修改任何业务代码,在查询`picture`表(一般叫逻辑表)时,框架会自动帮你修改 `SQL`,根据 `pictureId `将查询请求路由到不同的表中。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 分库分表策略 - 动态分表
|
|
||||||
|
|
||||||
动态分表是指分表的数量可以根据业务需求或数据量动态增加,表的结构和规则是运行时动态生成的。举个例子,根据时间动态创建 `picture_2025_03、picture_2025_04`。
|
|
||||||
|
|
||||||
```java
|
|
||||||
String tableName = "picture_" + LocalDate.now().format(
|
|
||||||
DateTimeFormatter.ofPattern("yyyy_MM")
|
|
||||||
);
|
|
||||||
```
|
|
||||||
|
|
||||||
```yml
|
|
||||||
spring:
|
|
||||||
shardingsphere:
|
|
||||||
datasource:
|
|
||||||
names: smile-picture
|
|
||||||
smile-picture:
|
|
||||||
type: com.zaxxer.hikari.HikariDataSource
|
|
||||||
driver-class-name: com.mysql.cj.jdbc.Driver
|
|
||||||
url: jdbc:mysql://localhost:3306/smile-picture
|
|
||||||
username: root
|
|
||||||
password: 123456
|
|
||||||
rules:
|
|
||||||
sharding:
|
|
||||||
tables:
|
|
||||||
picture: #逻辑表名(业务层永远只写 picture)
|
|
||||||
actual-data-nodes: smile-picture.picture # 逻辑表对应的真实节点
|
|
||||||
table-strategy:
|
|
||||||
standard:
|
|
||||||
sharding-column: space_id #分片列(字段)
|
|
||||||
sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法
|
|
||||||
sharding-algorithms:
|
|
||||||
picture_sharding_algorithm:
|
|
||||||
type: CLASS_BASED
|
|
||||||
props:
|
|
||||||
strategy: standard
|
|
||||||
algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm
|
|
||||||
props:
|
|
||||||
sql-show: true
|
|
||||||
```
|
|
||||||
|
|
||||||
**需要实现自定义算法类:**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> {
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) {
|
|
||||||
// 编写分表逻辑,返回实际要查询的表名
|
|
||||||
// picture_0 物理表,picture 逻辑表
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
|
|
||||||
return new ArrayList<>();
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public Properties getProps() {
|
|
||||||
return null;
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void init(Properties properties) {
|
|
||||||
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### **本项目分表总体思路:**
|
|
||||||
|
|
||||||
对 `picture` 进行分表
|
|
||||||
|
|
||||||
**一张 逻辑表 `picture`**
|
|
||||||
|
|
||||||
- 业务代码永远只写 `picture`,不用关心落到哪张真实表。
|
|
||||||
|
|
||||||
**两类真实表**
|
|
||||||
|
|
||||||
| 类型 | 存谁的数据 | 例子 |
|
|
||||||
| ---------- | ----------------------------- | --------------------------------------- |
|
|
||||||
| **公共表** | 普通 / 进阶 / 专业版空间 | `picture` |
|
|
||||||
| **分片表** | *旗舰版* 空间(每个空间一张) | `picture_<spaceId>`,如 `picture_30001` |
|
|
||||||
|
|
||||||
**自定义分片算法**:
|
|
||||||
|
|
||||||
- 传入 space_id 时
|
|
||||||
|
|
||||||
- 如果是旗舰,会自动路由到 `picture_<spaceId>`;否则回落到公共表 `picture`。
|
|
||||||
|
|
||||||
- 没有 space_id 时
|
|
||||||
|
|
||||||
(例如后台批量报表):
|
|
||||||
|
|
||||||
- 广播到 **所有** `picture_<spaceId>` + `picture` 并做汇聚。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
| 操作 | **必须**带分片键? | 若缺少分片键会发生什么 |
|
|
||||||
| ---------- | ------------------ | ------------------------------------------------------------ |
|
|
||||||
| **INSERT** | **是** | - 中间件不知道该落到哪张实际表- **直接抛异常**:`Could not determine actual data nodes` / `Table xxx route result is empty` |
|
|
||||||
| **UPDATE** | **强烈建议** | - ShardingSphere 会把 SQL **广播到所有分表** ,再分别执行- 表越多、数据越大,锁持有时间越长,性能急剧下降- 若所有表都无匹配行,会返回 0,但成本已付出 |
|
|
||||||
| **DELETE** | 同上 | 同 UPDATE,且更危险:一次误写可能删光全部分表的数据 |
|
|
||||||
| **SELECT** | 同上 | 没分片键就会全表扫描后聚合,数据量大时查询极慢、内存占用高 |
|
|
||||||
|
|
||||||
因此,项目中的业务代码中,对Picture表进行增删查改时,必须确保space_id非空。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 协同编辑
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
相比于生产者直接调用消费者,事件驱动模型的主要优点在于**解耦和异步性**。在事件驱动模型中,生产者和消费者不需要直接依赖于彼此的实现,生产者只需触发事件并将其发送到事件分发器,消费者则根据事件类型处理逻辑。此外,事件驱动还可以**提升系统的 并发性 和 实时性**,可以理解为多引入了一个中介来帮忙,通过异步消息传递,**减少了阻塞和等待**,能够更高效地处理多个并发任务。
|
|
||||||
|
|
||||||
#### **如何解决协同冲突?**
|
|
||||||
|
|
||||||
法一:约定 **同一时刻只允许一位用户进入编辑图片的状态**,此时其他用户只能实时浏览到修改效果,但不能参与编辑;进入编辑状态的用户可以退出编辑,其他用户才可以进入编辑状态。
|
|
||||||
|
|
||||||
| 事件触发者(用户 A 的动作) | 事件类型(发送消息) | 事件消费者(其他用户的处理) |
|
|
||||||
| --------------------------- | -------------------- | --------------------------------------------------- |
|
|
||||||
| 用户 A 建立连接,加入编辑 | INFO | 显示"用户 A 加入编辑"的通知 |
|
|
||||||
| 用户 A 进入编辑状态 | ENTER_EDIT | 其他用户界面显示"用户 A 开始编辑图片",锁定编辑状态 |
|
|
||||||
| 用户 A 执行编辑操作 | EDIT_ACTION | 放大/缩小/左旋/右旋当前图片 |
|
|
||||||
| 用户 A 退出编辑状态 | EXIT_EDIT | 解锁编辑状态,提示其他用户可以进入编辑状态 |
|
|
||||||
| 用户 A 断开连接,离开编辑 | INFO | 显示"用户 A 离开编辑"的通知,并释放编辑状态 |
|
|
||||||
| 用户 A 发送了错误的消息 | ERROR | 显示错误消息的通知 |
|
|
||||||
|
|
||||||
法二:实时协同 `OT `算法(`Operational Transformation`),广泛应用于在线文档协作等场景。
|
|
||||||
|
|
||||||
**操作** (Operation):表示用户对协作内容的修改,比如插入字符、删除字符等。
|
|
||||||
|
|
||||||
**转化 (Transformation)**:当多个用户同时编辑内容时,OT 会根据操作的上下文将它们转化,使得这些操作可以按照不同的顺序应用而结果保持一致。
|
|
||||||
|
|
||||||
**因果一致性**:OT 算法确保操作按照用户看到的顺序被正确执行,即每个用户的操作基于最新的内容状态。
|
|
||||||
|
|
||||||
**举一个简单的例子**,假设初始内容是 "abc",用户 A 和 B 同时进行编辑:
|
|
||||||
|
|
||||||
用户 A 在位置 1 插入 "x"
|
|
||||||
|
|
||||||
用户 B 在位置 2 删除 "b" 如果不使用 OT 算法,结果是:
|
|
||||||
|
|
||||||
用户 A 操作后,内容变为 "axbc"
|
|
||||||
|
|
||||||
用户 B 操作后,内容变为 "ac" 如果直接应用 B 的操作到 A 的结果,得到的是 "ac",对于 A 来说,相当于删除了 "b",A 会感到一脸懵逼。
|
|
||||||
|
|
||||||
如果使用 `OT` 算法,结果是:
|
|
||||||
|
|
||||||
1. 用户 A 的操作,应用后内容为 "axbc"
|
|
||||||
2. 用户 B 的操作经过 OT 转化为删除 "b" 在 "axbc" 中的新位置 最终用户 `A` 和 `B` 的内容都一致为 "axc",符合预期。`OT` 算法确保无论用户编辑的顺序如何,**最终内容是一致的**。
|
|
||||||
|
|
||||||
`OT `算法的难点在于设计如何转化各个用户的操作。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 业务流程图
|
|
||||||
|
|
||||||
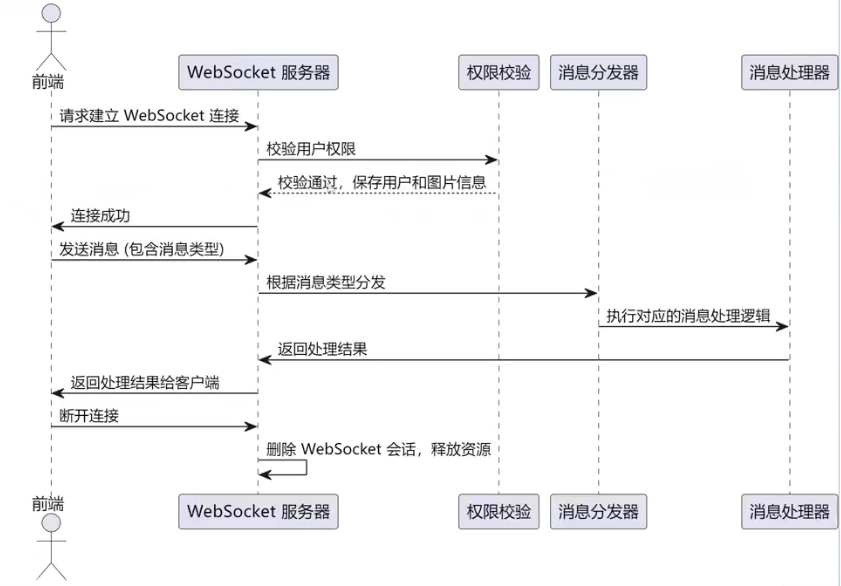
|
|
||||||
|
|
||||||
```java
|
|
||||||
// key: pictureId,value: 这张图下所有活跃的 Session(即各个用户的连接)
|
|
||||||
Map<Long, Set<WebSocketSession>> pictureSessions;
|
|
||||||
```
|
|
||||||
|
|
||||||
当用户 A 在浏览器里打开了 pictureId=123 的编辑页面,就产生了一个 Session;
|
|
||||||
如果同一个浏览器又开了一个标签页编辑同一张图,或者不同的浏览器/设备打开,同样又会分别产生新的 Session。
|
|
||||||
|
|
||||||
假设有两张图,ID 是 100 和 200:
|
|
||||||
|
|
||||||
| pictureId | pictureSessions.get(pictureId) |
|
|
||||||
| --------- | ------------------------------------------- |
|
|
||||||
| 100 | { sessionA, sessionB } (用户 A、B 的连接) |
|
|
||||||
| 200 | { sessionC } (只有用户 C 的连接) |
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Disruptor 优化
|
|
||||||
|
|
||||||
调用 `Spring MVC `的某个接口时,如果该接口内部的耗时较长,请求线程就会一直阻塞,最终导致` Tomcat` 请求连接数耗尽(默认值 **200**)。
|
|
||||||
|
|
||||||
大多数请求是快请求,毫秒级别,直接在请求线程里完成;若有个慢请求,执行一次需要几秒,那么必须将它放入异步线程中执行。
|
|
||||||
|
|
||||||
`Disruptor` 是一种高性能的并发框架,它是一种 **无锁的环形队列** 数据结构,用于解决高吞吐量和低延迟场景中的并发问题。
|
|
||||||
|
|
||||||
Disruptor 的工作流程:
|
|
||||||
|
|
||||||
1)环形队列初始化:创建一个固定大小为 8 的 RingBuffer(索引范围 0-7),每个格子存储一个可复用的事件对象,序号初始为 0。
|
|
||||||
|
|
||||||
2)生产者写入数据:生产者申请索引 0(序号 0),将数据 "A" 写入事件对象,提交后序号递增为 1,下一个写入索引变为 1。
|
|
||||||
|
|
||||||
3)消费者读取数据:消费者检查索引 0(序号 0),读取数据 "A",处理后提交,序号递增为 1,下一个读取索引变为 1。
|
|
||||||
|
|
||||||
4)环形队列循环使用:当生产者写入到索引 7(序号 7)后,索引回到 0(序号 8),形成循环存储,但序号会持续自增以区分数据的先后顺序。
|
|
||||||
|
|
||||||
5)防止数据覆盖:如果生产者追上消费者,消费者尚未处理完数据,生产者会等待,确保数据不被覆盖。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
基于 `Disruptor` 的异步消息处理机制,可以将原有的同步消息分发逻辑改造为高效解耦的异步处理模型。因为websockt接收到请求,直接往队列里面提交任务,Disruptor的消费者来负责按顺序进行处理。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -1847,7 +1847,7 @@ public class HttpClientTest {
|
|||||||
|
|
||||||
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
|
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
|
||||||
|
|
||||||
```java
|
```xml
|
||||||
<dependency>
|
<dependency>
|
||||||
<groupId>org.springframework.boot</groupId>
|
<groupId>org.springframework.boot</groupId>
|
||||||
<artifactId>spring-boot-starter-cache</artifactId> <version>2.7.3</version>
|
<artifactId>spring-boot-starter-cache</artifactId> <version>2.7.3</version>
|
||||||
|
|||||||
30
项目/草稿.md
30
项目/草稿.md
@ -1,9 +1,23 @@
|
|||||||
核心比较如下:
|
好的,我帮你把 `space_user` 表整理成一个更直观的表格:
|
||||||
|
|
||||||
| 核心点 | Apache HttpClient | Retrofit |
|
| 字段名 | 类型 | 默认值 | 允许为空 | 注释 | 备注 |
|
||||||
| --------------- | ----------------------------------------- | ------------------------------------------------------------ |
|
| ---------- | ------------ | ----------------- | -------- | --------------------------------- | --------------------------- |
|
||||||
| 编程模型 | 细粒度调用,手动构造 `HttpGet`/`HttpPost` | 注解驱动接口方法,声明式调用 |
|
| id | bigint | auto_increment | 否 | id | 主键 |
|
||||||
| 请求定义 | 手动拼接 URL、参数 | 用 `@GET`/`@POST`、`@Path`、`@Query`、`@Body` 注解 |
|
| spaceId | bigint | — | 否 | 空间 id | — |
|
||||||
| 序列化/反序列化 | 手动调用 `ObjectMapper`/`Gson` | 自动通过 `ConverterFactory`(Jackson/Gson 等) |
|
| userId | bigint | — | 否 | 用户 id | — |
|
||||||
| 同步/异步 | 以同步为主,异步需自行管理线程和回调 | 同一个 `Call<T>` 即可 `execute()`(同步)或 `enqueue()`(异步) |
|
| spaceRole | varchar(128) | 'viewer' | 是 | 空间角色:viewer / editor / admin | — |
|
||||||
| 扩展性与拦截器 | 可配置拦截器,但需手动集成 | 底层基于 OkHttp,天然支持拦截器、连接池、缓存、重试和取消 |
|
| createTime | datetime | CURRENT_TIMESTAMP | 否 | 创建时间 | — |
|
||||||
|
| updateTime | datetime | CURRENT_TIMESTAMP | 否 | 更新时间 | on update CURRENT_TIMESTAMP |
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
**索引设计:**
|
||||||
|
|
||||||
|
| 索引名 | 类型 | 字段 | 说明 |
|
||||||
|
| ----------------- | ------ | ----------------- | ---------------------------------------- |
|
||||||
|
| uk_spaceId_userId | UNIQUE | (spaceId, userId) | 唯一索引,用户在一个空间中只能有一个角色 |
|
||||||
|
| idx_spaceId | INDEX | (spaceId) | 提升按空间查询的性能 |
|
||||||
|
| idx_userId | INDEX | (userId) | 提升按用户查询的性能 |
|
||||||
|
|
||||||
|
这样结构和约束就一目了然了。
|
||||||
|
如果你愿意,我还可以帮你画一个 **ER 图** 来可视化这个表和用户、空间的关系。这样关联会更直观。你要加吗?
|
||||||
Loading…
x
Reference in New Issue
Block a user