574 lines
25 KiB
Markdown
574 lines
25 KiB
Markdown
# 拼团交易系统
|
||
|
||
## 系统设计
|
||
|
||
### **功能流程**
|
||
|
||
|
||
|
||
|
||
|
||
### **库表设计**
|
||
|
||
|
||
|
||
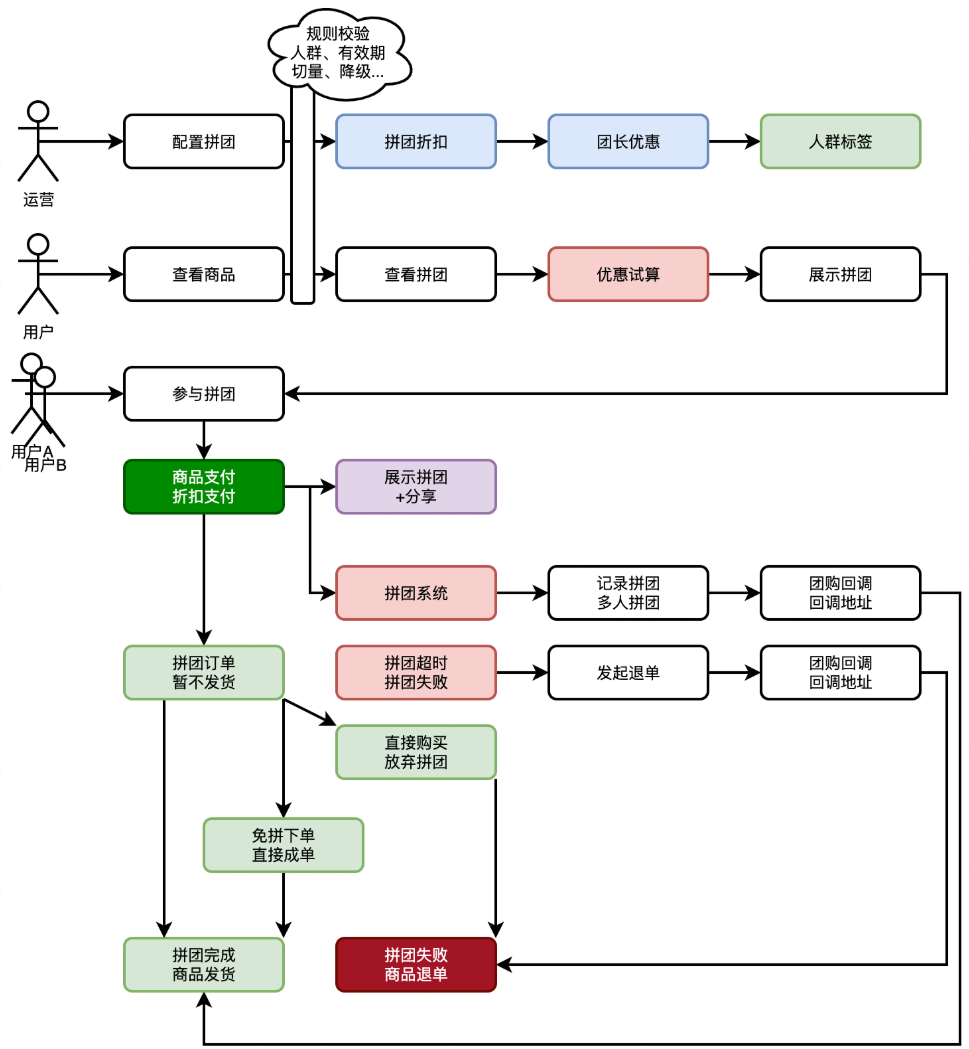
- 首先,站在**运营**的角度,要为这次拼团配置对应的**拼团活动**。那么就会涉及到;给哪个渠道的**什么商品**ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商**品所提供的规则信息**,包括:折扣、起止时间、人数等。还要拿到折扣的一个**试算金额**。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。
|
||
- 之后,站在**用户**的角度,是参与拼团。首次**发起一个拼团**或者**参与已存在的拼团**进行数据的记录,达成拼团约定拼团人数后,开始进行**通知**。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
|
||
- 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Redis,并为这批用户打上可配置的**人群标签**。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。
|
||
- 那么,拼团活动表,为什么会把**折扣拆分**出来呢。因为这里的折扣**可能有多种**迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。
|
||
|
||
|
||
|
||
**(一)拼团配置表**
|
||
|
||
group_buy_activity 拼团活动
|
||
|
||
| 字段名 | 说明 |
|
||
| ---------------- | -------------------------------------------------------- |
|
||
| id | 自增ID |
|
||
| activity_id | 活动ID |
|
||
| source | 来源 |
|
||
| channel | 渠道 |
|
||
| goods_id | 商品ID |
|
||
| discount_id | 折扣ID |
|
||
| group_type | 成团方式【0自动成团(到时间后自动成团)、1达成目标成团】 |
|
||
| take_limit_count | 拼团次数限制 |
|
||
| target | 达成目标(3人单、5人单) |
|
||
| valid_time | 拼单时长(20分钟),未完成拼团则=》自动成功or失败 |
|
||
| status | 活动状态 (活动是否有效,运营可临时设置为失效) |
|
||
| start_time | 活动开始时间 |
|
||
| end_time | 活动结束时间 |
|
||
| tag_id | 人群标签规则标识 |
|
||
| tag_scope | 人群标签规则范围【多选;可见、参与】 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
group_buy_discount 折扣配置
|
||
|
||
| 字段名 | 说明 |
|
||
| ------------- | --------------------------------- |
|
||
| id | 自增ID |
|
||
| discount_id | 折扣ID |
|
||
| discount_name | 折扣标题 |
|
||
| discount_desc | 折扣描述 |
|
||
| discount_type | 类型【base、tag】 |
|
||
| market_plan | 营销优惠计划【直减、满减、N元购】 |
|
||
| market_expr | 营销优惠表达式 |
|
||
| tag_id | 人群标签,特定优惠限定 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags 人群标签
|
||
|
||
| 字段名 | 说明 |
|
||
| ----------- | ----------------------------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| tag_name | 标签名称 |
|
||
| tag_desc | 标签描述 |
|
||
| statistics | 人群标签统计量 200\10万\100万 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags_detail 人群标签明细(写入缓存)
|
||
|
||
| 字段名 | 说明 |
|
||
| ----------- | -------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| user_id | 用户ID |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags_job 人群标签任务
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------- | ---------------------------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| batch_id | 批次ID |
|
||
| tag_type | 标签类型【参与量、消费金额】 |
|
||
| tag_rule | 标签规则【限定参与N次】 |
|
||
| stat_start_time | 统计开始时间 |
|
||
| stat_end_time | 统计结束时间 |
|
||
| status | 计划、重置、完成 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
|
||
|
||
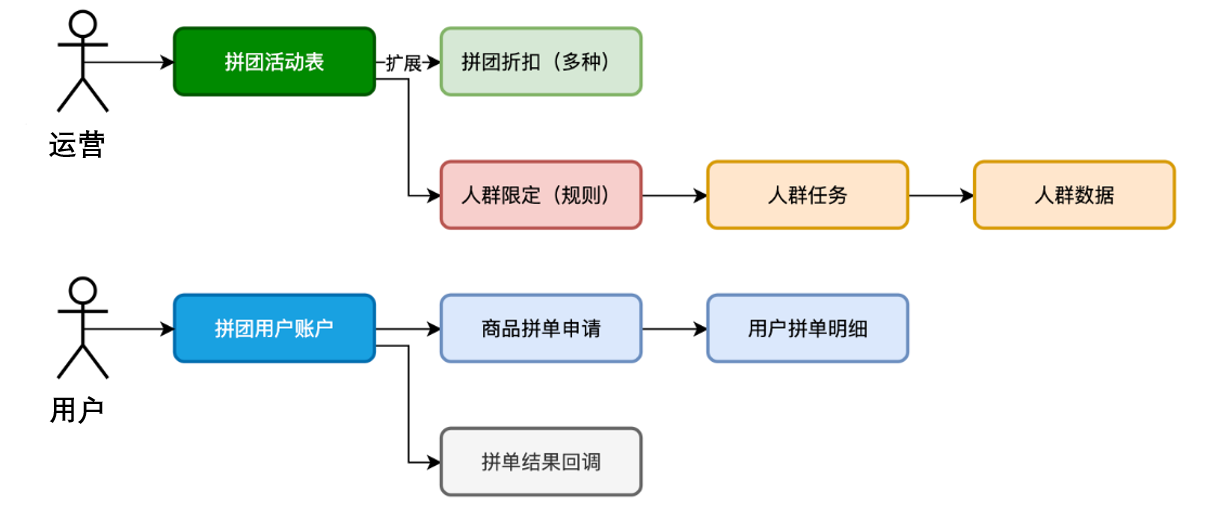
- 拼团活动表:设定了拼团的成团规则,人群标签的使用可以限定哪些人可见,哪些人可参与。
|
||
- 折扣配置表:拆分出拼团优惠到一个新的表进行多条配置。如果折扣还有更多的复杂规则,则可以配置新的折扣规则表进行处理。
|
||
- 人群标签表:专门来做人群设计记录的,这3张表就是为了把符合规则的人群ID,也就是用户ID,全部跑任务到一个记录下进行使用。比如黑玫瑰人群、高净值人群、拼团履约率90%以上的人群等。
|
||
|
||
|
||
|
||
**(二)参与拼团表**
|
||
|
||
group_buy_account 拼团账户
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------------- | ------------ |
|
||
| id | 自增ID |
|
||
| user_id | 用户ID |
|
||
| activity_id | 活动ID |
|
||
| take_limit_count | 拼团次数限制 |
|
||
| take_limit_count_used | 拼团次数消耗 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
group_buy_order 用户拼单
|
||
|
||
| 字段名 | 说明 |
|
||
| ---------------------- | ------------------------ |
|
||
| id | 自增ID |
|
||
| activity_id | 活动ID |
|
||
| group_order_id | 拼单ID 【多少人参与】 |
|
||
| group_order_start_time | 拼单开始时间 |
|
||
| group_order_end_time | 拼单结束时间 |
|
||
| source | 来源 |
|
||
| channel | 渠道 |
|
||
| goods_id | 商品ID |
|
||
| original_price | 原始价格 |
|
||
| deduction_price | 抵扣价格(各类优惠加成) |
|
||
| pay_amount | 实际支付价格 |
|
||
| target_count | 目标数量 |
|
||
| complete_count | 完成数量 |
|
||
| status | 状态(拼单中/完成/失败) |
|
||
| notify_url | 回调接口 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
group_buy_order_list 用户拼单明细
|
||
|
||
| 字段名 | 说明 |
|
||
| -------------- | ---------------------- |
|
||
| id | |
|
||
| activity_id | 活动ID |
|
||
| group_order_id | 拼单ID |
|
||
| user_id | 用户id |
|
||
| user_type | 团长/团员 |
|
||
| source | 来源 |
|
||
| channel | 渠道 |
|
||
| goods_id | 商品ID |
|
||
| out_trade_no | 外部交易单号,唯一幂等 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
notify_task 回调任务
|
||
|
||
| 字段名 | 说明 |
|
||
| -------------- | ---------------------------------- |
|
||
| id | 自增ID |
|
||
| activity_id | 活动ID |
|
||
| order_id | 拼单ID |
|
||
| notify_url | 回调接口 |
|
||
| notify_count | 回调次数(3-5次) |
|
||
| notify_status | 回调状态【初始、完成、重试、失败】 |
|
||
| parameter_json | 参数对象 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
- 拼团账户表:记录用户的拼团参与数据,一个是为了限制用户的参与拼团次数,另外是为了人群标签任务统计数据。
|
||
- 用户拼单表:当有用户发起首次拼单的时候,产生拼单id,并记录所需成团的拼单记录,另外是写上拼团的状态、唯一索引、回调接口等。这样拼团完成就可以回调对接的平台,通知完成了。【微信支付也是这样的设计,回调支付结果,这样的设计可以方便平台化对接】当再有用户参与后,则写入用户拼单明细表。直至达成拼团。
|
||
- 回调任务表:当拼团完成后,要做回调处理。但可能会有失败,所以加入任务的方式进行补偿。如果仍然失败,则需要对接的平台,自己查询拼团结果。
|
||
|
||
|
||
|
||
### 架构设计
|
||
|
||
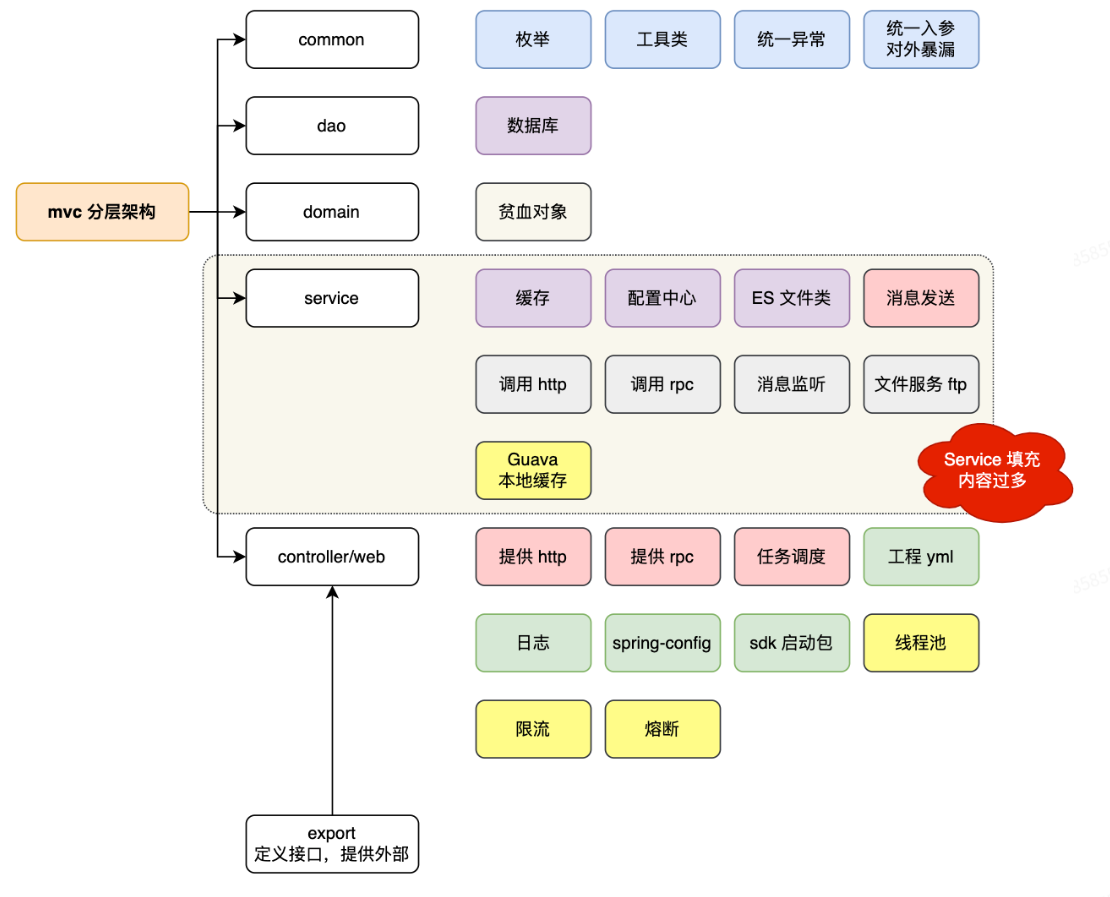
**MVC架构:**
|
||
|
||
|
||
|
||
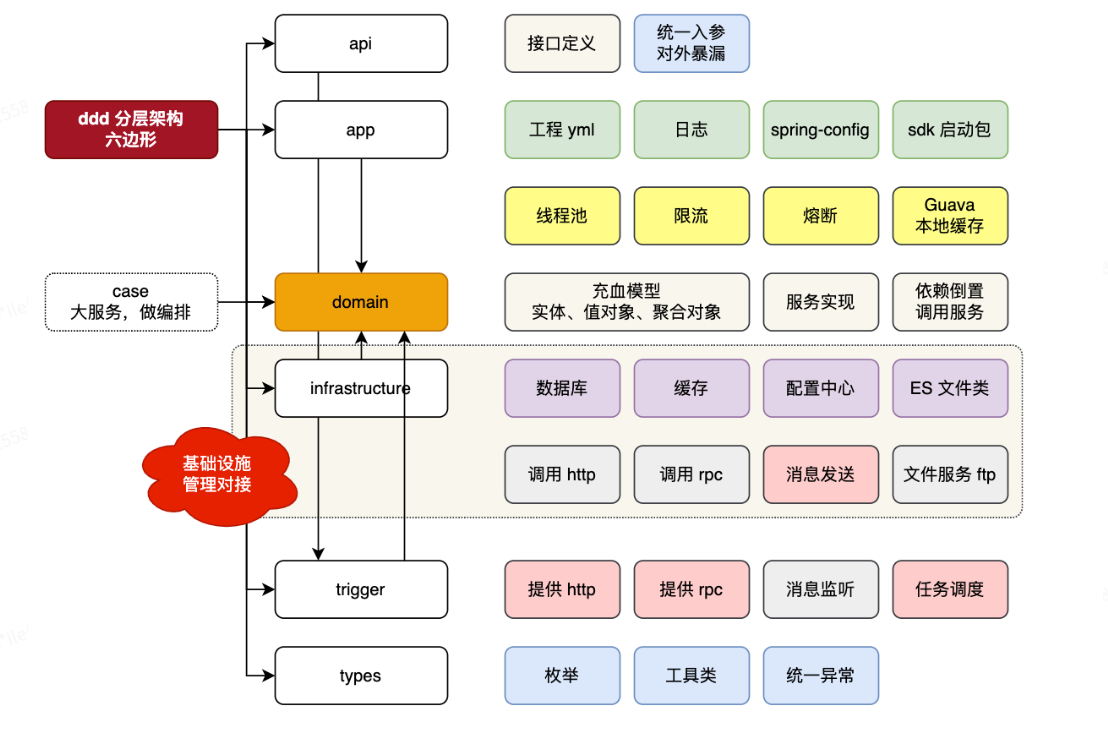
**DDD架构:**
|
||
|
||
|
||
|
||
|
||
|
||
## 价格试算
|
||
|
||
```java
|
||
@Service
|
||
@RequiredArgsConstructor
|
||
public class IndexGroupBuyMarketServiceImpl implements IIndexGroupBuyMarketService {
|
||
|
||
private final DefaultActivityStrategyFactory defaultActivityStrategyFactory;
|
||
|
||
@Override
|
||
public TrialBalanceEntity indexMarketTrial(MarketProductEntity marketProductEntity) throws Exception {
|
||
|
||
StrategyHandler<MarketProductEntity, DefaultActivityStrategyFactory.DynamicContext, TrialBalanceEntity> strategyHandler = defaultActivityStrategyFactory.strategyHandler();
|
||
|
||
TrialBalanceEntity trialBalanceEntity = strategyHandler.apply(marketProductEntity, new DefaultActivityStrategyFactory.DynamicContext());
|
||
|
||
return trialBalanceEntity;
|
||
}
|
||
|
||
}
|
||
```
|
||
|
||
```text
|
||
IndexGroupBuyMarketService
|
||
│
|
||
│ indexMarketTrial()
|
||
▼
|
||
DefaultActivityStrategyFactory
|
||
│ (return rootNode)
|
||
▼
|
||
RootNode.apply()
|
||
│ doApply() (执行)
|
||
│ router() (路由到下一node)
|
||
▼
|
||
SwitchNode.apply()
|
||
│ ...
|
||
▼
|
||
... (可能还有其他节点)
|
||
▼
|
||
EndNode.apply() → 组装结果并返回 TrialBalanceEntity
|
||
▲
|
||
└────────── 最终一路向上 return
|
||
|
||
```
|
||
|
||
`IndexGroupBuyMarketService` 是领域服务,整个价格试算的入口
|
||
|
||
`DefaultActivityStrategyFactory` 帮你拿到 *根节点*,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。
|
||
|
||
`DynamicContext` 是一次性创建的共享上下文:谁需要谁就往里放
|
||
|
||
|
||
|
||
## 人群标签数据采集
|
||
|
||
| 步骤 | 目的 | 说明 |
|
||
| ------------------- | ----------------------------------------------- | ------------------------------------------------------------ |
|
||
| **1. 记录日志** | 标明本次批次任务的开始 | 方便后续排查、链路追踪 |
|
||
| **2. 读取批次配置** | 拿到该批次**统计范围、规则、时间窗**等 | 若返回 `null` 通常代表批次号错误或已被清理 |
|
||
| **3. 采集候选用户** | 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 | 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 |
|
||
| **4. 双写标签明细** | 将每个用户与标签的关系永久化 & 提供实时校验能力 | 方法内部两件事:• 插入 `crowd_tags_detail` 表• <br />在 Redis **BitMap** 中把该用户对应位设为 1(幂等处理冲突) |
|
||
| **5. 更新统计量** | 维护标签当前命中人数,用于运营看板 | 这里简单按“新增条数”累加,也可改为重新 `count(*)` 全量回填 |
|
||
| **6. 结束** | 方法返回 void | 如果过程抛异常,调度系统可重试/报警 |
|
||
|
||
> **一句话总结**
|
||
> 这是一个被定时器或消息触发的**离线批量打标签任务**:
|
||
> 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。
|
||
> 之后业务系统就能用位图做到毫秒级 `isUserInTag(userId, tagId)` 判断,实现精准运营投放。
|
||
|
||
|
||
|
||
### Bitmap(位图)
|
||
|
||
**概念**
|
||
|
||
- Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。
|
||
- 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。
|
||
|
||
**为什么用 Bitmap?**
|
||
|
||
- **超高空间效率**:1000 万个用户,只需要约 10 MB(1000 万 / 8)。
|
||
- **超快操作**:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。
|
||
|
||
**典型场景**
|
||
|
||
- **用户标签 / 权限判断**:把符合某个条件的用户的索引位置设置为 1,以后实时判断“用户 X 是否在标签 A 中?”就只需读一个 bit。
|
||
- **海量去重 / 布隆过滤器**:在超大流量场景下判断“URL 是否已访问过”、“手机号是否已注册”等。
|
||
- **统计分析**:快速统计某个条件下有多少个用户/对象符合(BITCOUNT)。
|
||
|
||
|
||
|
||
## 收获
|
||
|
||
### 模板方法
|
||
|
||
**核心思想**:
|
||
在抽象父类中定义**算法骨架**(固定执行顺序),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。
|
||
|
||
```text
|
||
Client ───▶ AbstractClass
|
||
├─ templateMethod() ←—— 固定流程
|
||
│ step1()
|
||
│ step2() ←—— 抽象,可变
|
||
│ step3()
|
||
└─ hookMethod() ←—— 可选覆盖
|
||
▲
|
||
│ extends
|
||
┌──────────┴──────────┐
|
||
│ ConcreteClassA/B… │
|
||
|
||
```
|
||
|
||
**示例:**
|
||
|
||
```java
|
||
// 1. 抽象模板
|
||
public abstract class AbstractDialog {
|
||
|
||
// 模板方法:固定调用顺序,设为 final 防止子类改流程
|
||
public final void show() {
|
||
initLayout();
|
||
bindEvent();
|
||
beforeDisplay(); // 钩子,可选
|
||
display();
|
||
afterDisplay(); // 钩子,可选
|
||
}
|
||
|
||
// 具体公共步骤
|
||
private void initLayout() {
|
||
System.out.println("加载通用布局文件");
|
||
}
|
||
|
||
// 需要子类实现的抽象步骤
|
||
protected abstract void bindEvent();
|
||
|
||
// 钩子方法,默认空实现
|
||
protected void beforeDisplay() {}
|
||
protected void afterDisplay() {}
|
||
|
||
private void display() {
|
||
System.out.println("弹出对话框");
|
||
}
|
||
}
|
||
|
||
// 2. 子类:登录对话框
|
||
public class LoginDialog extends AbstractDialog {
|
||
@Override
|
||
protected void bindEvent() {
|
||
System.out.println("绑定登录按钮事件");
|
||
}
|
||
@Override
|
||
protected void afterDisplay() {
|
||
System.out.println("focus 到用户名输入框");
|
||
}
|
||
}
|
||
|
||
// 3. 调用
|
||
public class Demo {
|
||
public static void main(String[] args) {
|
||
AbstractDialog dialog = new LoginDialog();
|
||
dialog.show();
|
||
/* 输出:
|
||
加载通用布局文件
|
||
绑定登录按钮事件
|
||
弹出对话框
|
||
focus 到用户名输入框
|
||
*/
|
||
}
|
||
}
|
||
```
|
||
|
||
**要点**
|
||
|
||
- **复用公共流程**:`initLayout()`、`display()` 写一次即可。
|
||
- **限制流程顺序**:`show()` 定为 `final`,防止子类乱改步骤。
|
||
- **钩子方法**:子类可选择性覆盖(如 `beforeDisplay`)。
|
||
|
||
|
||
|
||
### 规则树流程
|
||
|
||
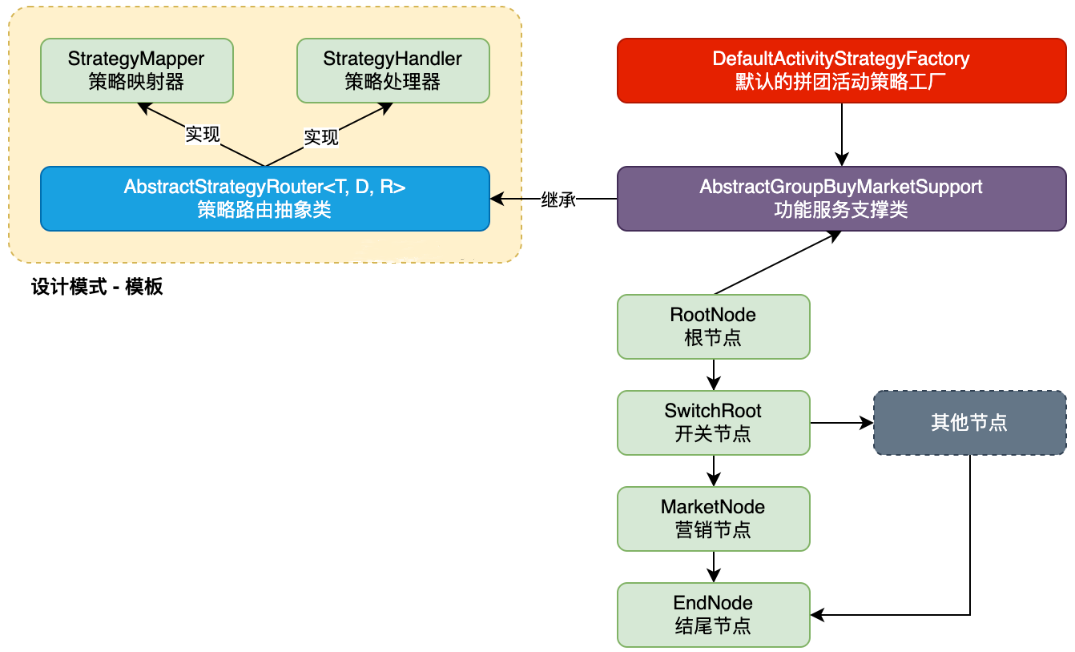
|
||
|
||
**整体分层思路**
|
||
|
||
| 分层 | 作用 | 关键对象 |
|
||
| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||
| **通用模板层** | 抽象出与具体业务无关的「规则树」骨架,解决 *如何找到并执行策略* 的共性问题 | `StrategyMapper`、`StrategyHandler`、`AbstractStrategyRouter<T,D,R>` |
|
||
| **业务装配层** | 基于模板,自由拼装出 *一棵* 贴合业务流程的策略树 | `RootNode / SwitchRoot / MarketNode / EndNode …` |
|
||
| **对外暴露层** | 通过 **工厂 + 服务支持类** 将整棵树封装成一个可直接调用的 `StrategyHandler`,并交给 Spring 整体托管 | `DefaultActivityStrategyFactory`、`AbstractGroupBuyMarketSupport` |
|
||
|
||
**通用模板层:规则树的“骨架”**
|
||
|
||
| 角色 | 职责 | 关系 |
|
||
| ------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||
| `StrategyMapper` | **映射器**:依据 `requestParameter + dynamicContext` 选出 *下一个* 策略节点 | 被 `AbstractStrategyRouter` 调用 |
|
||
| `StrategyHandler` | **处理器**:真正执行业务逻辑;`apply` 结束后可返回结果或继续路由 | 节点本身 / 路由器本身都是它的实现 |
|
||
| `AbstractStrategyRouter<T,D,R>` | **路由模板**:① 调用 `get(...)` 找到合适的 `StrategyHandler`;② 调用该 handler 的 `apply(...)`;③ 若未命中则走 `defaultStrategyHandler` | 同时实现 `StrategyMapper` 与 `StrategyHandler`,但自身保持 *抽象*,把细节延迟到子类 |
|
||
|
||
**业务装配层:一棵可编排的策略树**
|
||
|
||
```text
|
||
RootNode -> SwitchRoot -> MarketNode -> EndNode
|
||
↘︎ OtherNode ...
|
||
```
|
||
|
||
- 每个节点
|
||
|
||
继承 `AbstractStrategyRouter`
|
||
|
||
- 实现 `get(...)`:决定当前节点的下一跳是哪一个节点
|
||
- 实现 `apply(...)`:实现节点自身应做的业务动作(或继续下钻)
|
||
|
||
- 组合方式
|
||
|
||
比责任链更灵活:
|
||
|
||
- 一个节点既可以“继续路由”也可以“自己处理完直接返回”
|
||
- 可以随时插拔 / 替换子节点,形成多分支、循环、早停等复杂流转
|
||
|
||
**对外暴露层:工厂 + 服务支持类**
|
||
|
||
| 组件 | 主要职责 |
|
||
| --------------------------------------------- | ------------------------------------------------------------ |
|
||
| `DefaultActivityStrategyFactory` (`@Service`) | **工厂**:1. 在 Spring 启动时注入根节点 `RootNode`;2. 暴露**统一入口** `strategyHandler()` → 返回整个策略树顶点(一个 `StrategyHandler` 实例) |
|
||
| `AbstractGroupBuyMarketSupport` | **业务服务基类**:封装拼团场景下共用的查询、工具方法;供每个**节点**继承使用 |
|
||
|
||
这样,调用方只需
|
||
|
||
```java
|
||
TrialBalanceEntity result =
|
||
factory.strategyHandler().apply(product, new DynamicContext(vo1, vo2));
|
||
```
|
||
|
||
就能驱动整棵策略树,而**完全不用关心**节点搭建、依赖注入等细节。
|
||
|
||
|
||
|
||
### 策略模式
|
||
|
||
**核心思想**:
|
||
把可互换的算法/行为抽成独立策略类,运行时由“上下文”对象选择合适的策略;对调用方来说,只关心统一接口,而非具体实现。
|
||
|
||
```text
|
||
┌───────────────┐
|
||
│ Client │
|
||
└─────▲─────────┘
|
||
│ has-a
|
||
┌─────┴─────────┐ implements
|
||
│ Context │────────────┐ ┌──────────────┐
|
||
│ (使用者) │ strategy └─▶│ Strategy A │
|
||
└───────────────┘ ├──────────────┤
|
||
│ Strategy B │
|
||
└──────────────┘
|
||
|
||
```
|
||
|
||
#### 集合自动注入
|
||
|
||
常见于策略/工厂/插件场景。
|
||
|
||
```java
|
||
@Autowired
|
||
private Map<String, IDiscountCalculateService> discountCalculateServiceMap;
|
||
```
|
||
|
||
**字段类型**:`Map<String, IDiscountCalculateService>`
|
||
|
||
- key—— Bean 的名字
|
||
- 默认是类名首字母小写 (`mjCalculateService`)
|
||
- 或者你在实现类上显式写的 `@Service("MJ")`
|
||
- **value** —— 那个实现类对应的实例
|
||
- **Spring 机制**:
|
||
1. 启动时扫描所有实现 `IDiscountCalculateService` 的 Bean。
|
||
2. 把它们按 “BeanName → Bean 实例” 的映射注入到这张 `Map` 里。
|
||
3. 你一次性就拿到了“策略字典”。
|
||
|
||
**示例:**
|
||
|
||
```java
|
||
@Service("MJ") // ★ 关键:Bean 名即策略键
|
||
public class MJCalculateService extends IDiscountCalculateService {
|
||
|
||
@Override
|
||
protected BigDecimal Calculate(String userId, BigDecimal originalPrice,
|
||
GroupBuyActivityDiscountVO.GroupBuyDiscount groupBuyDiscount) {
|
||
//忽略实现细节
|
||
}
|
||
|
||
@Component
|
||
@RequiredArgsConstructor // 构造器注入更推荐
|
||
public class DiscountContext {
|
||
|
||
private final Map<String, IDiscountCalculateService> discountServiceMap;
|
||
|
||
public BigDecimal calc(String strategyKey,
|
||
String userId,
|
||
BigDecimal originalPrice,
|
||
GroupBuyActivityDiscountVO.GroupBuyDiscount plan) {
|
||
//strategyKey可以是"MJ" ..
|
||
IDiscountCalculateService strategy = discountServiceMap.get(strategyKey);
|
||
if (strategy == null) {
|
||
throw new IllegalArgumentException("无匹配折扣类型: " + strategyKey);
|
||
}
|
||
return strategy.calculate(userId, originalPrice, plan);
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|
||
|
||
|
||
### 多线程异步调用
|
||
|
||
```java
|
||
// Runnable ➞ 只能 run(),没有返回值
|
||
public interface Runnable {
|
||
void run();
|
||
}
|
||
|
||
// Callable<V> ➞ call() 能返回 V,也能抛检查型异常
|
||
public interface Callable<V> {
|
||
V call() throws Exception;
|
||
}
|
||
```
|
||
|
||
```java
|
||
public class MyTask implements Callable<String> {
|
||
private final String name;
|
||
public MyTask(String name) {
|
||
this.name = name;
|
||
}
|
||
@Override
|
||
public String call() throws Exception {
|
||
// 模拟耗时操作
|
||
TimeUnit.MILLISECONDS.sleep(300);
|
||
return "任务[" + name + "]的执行结果";
|
||
}
|
||
}
|
||
```
|
||
|
||
```java
|
||
public class SimpleAsyncDemo {
|
||
public static void main(String[] args) {
|
||
// 创建大小为 2 的线程池
|
||
ExecutorService pool = Executors.newFixedThreadPool(2);
|
||
|
||
try {
|
||
// 构造两个任务
|
||
MyTask task1 = new MyTask("A");
|
||
MyTask task2 = new MyTask("B");
|
||
|
||
// 用 FutureTask 包装 Callable
|
||
FutureTask<String> future1 = new FutureTask<>(task1);
|
||
FutureTask<String> future2 = new FutureTask<>(task2);
|
||
|
||
// 提交给线程池异步执行
|
||
pool.execute(future1);
|
||
pool.execute(future2);
|
||
|
||
// 主线程可以先做别的事…
|
||
System.out.println("主线程正在做其他事情…");
|
||
|
||
// ③ 在需要的时候再获取结果(可加超时)
|
||
String result1 = future1.get(1, TimeUnit.SECONDS); //设置超时时间1秒
|
||
String result2 = future2.get(); //无超时时间
|
||
|
||
System.out.println("拿到结果1 → " + result1);
|
||
System.out.println("拿到结果2 → " + result2);
|
||
|
||
} catch (InterruptedException e) {
|
||
Thread.currentThread().interrupt();
|
||
} catch (ExecutionException e) {
|
||
System.err.println("任务执行中出错: " + e.getCause());
|
||
} catch (TimeoutException e) {
|
||
System.err.println("等待结果超时");
|
||
} finally {
|
||
pool.shutdown();
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|