295 lines
14 KiB
Markdown
295 lines
14 KiB
Markdown
# DDD领域驱动设计
|
||
|
||
## 什么是 DDD?
|
||
|
||
DDD(领域驱动设计,Domain-Driven Design)是一种软件开发方法论和设计思想。**为了确定业务和应用的边界**,保证业务模型和代码模型的一致性。
|
||
|
||
**DDD 与微服务架构的关系**
|
||
|
||
因为 DDD **主要应用在微服务架构**场景,所以想要更好的理解 DDD 的概念,需要结合微服务架构来看:
|
||
|
||
- DDD 是一种设计思想,确定业务和应用的边界
|
||
- 微服务架构需要 **将系统拆分为多个小而独立的服务**
|
||
|
||
**DDD 的价值**
|
||
|
||
1. 根据领域模型确定业务的边界
|
||
2. 划分出应用的边界
|
||
3. 最终落实成服务的边界、代码的边界
|
||
|
||
## DDD概念理论
|
||
|
||
### 充血模型 vs 贫血模型
|
||
|
||
**定义**
|
||
|
||
- **贫血模型**:对象仅包含数据属性和简单的 `getter/setter`,业务逻辑由外部服务处理。
|
||
- **充血模型**:对象既包含数据,也封装相关业务逻辑,符合面向对象设计原则。
|
||
|
||
| 特点 | 贫血模型 | 充血模型 |
|
||
| ------------ | -------------------------------- | -------------------------------- |
|
||
| 封装性 | 数据和逻辑分离 | 数据和逻辑封装在同一对象内 |
|
||
| 职责分离 | 服务类负责业务逻辑,对象负责数据 | 对象同时负责数据和自身的业务逻辑 |
|
||
| 适用场景 | 简单的增删改查、DTO 传输对象 | 复杂的领域逻辑和业务建模 |
|
||
| 优点 | 简单易用,职责清晰 | 高内聚,符合面向对象设计思想 |
|
||
| 缺点 | 服务层臃肿,领域模型弱化 | 复杂度增加,不适合简单场景 |
|
||
| 面向对象原则 | 违反封装原则 | 符合封装原则 |
|
||
|
||
充血模型:
|
||
|
||
```java
|
||
public class Order {
|
||
private String orderId;
|
||
private double totalAmount;
|
||
private boolean isPaid;
|
||
|
||
public Order(String orderId, double totalAmount) {
|
||
this.orderId = orderId;
|
||
this.totalAmount = totalAmount;
|
||
this.isPaid = false;
|
||
}
|
||
|
||
public void pay() {
|
||
if (this.isPaid) {
|
||
throw new IllegalStateException("Order is already paid");
|
||
}
|
||
this.isPaid = true;
|
||
}
|
||
|
||
public void cancel() {
|
||
if (this.isPaid) {
|
||
throw new IllegalStateException("Cannot cancel a paid order");
|
||
}
|
||
// Perform cancellation logic
|
||
}
|
||
|
||
public boolean isPaid() {
|
||
return isPaid;
|
||
}
|
||
|
||
public double getTotalAmount() {
|
||
return totalAmount;
|
||
}
|
||
}
|
||
```
|
||
|
||
但不要只是把充血模型,仅限于一个类的设计和一个类内的方法设计。充血还可以是整个包结构,一个包下包括了用于实现此包 Service 服务所需的各类零部件(模型、仓储、工厂),也可以被看做充血模型。
|
||
|
||
|
||
|
||
### 限界上下文
|
||
|
||
限界上下文是指一个明确的边界,规定了某个子领域的业务模型和语言,确保在该上下文内的术语、规则、模型不与其他上下文混淆。
|
||
|
||
| 表达 | 语义环境 | 实际含义 |
|
||
| -------------------------------- | -------- | ---------------------- |
|
||
| "我吃得很饱,现在不能动了" | 日常用餐 | 字面意思:吃到肚子很满 |
|
||
| "我吃得很饱,今天的演讲让人充实" | 知识分享 | 比喻:得到了很大满足 |
|
||
|
||
**限界上下文的作用**
|
||
|
||
1. **定义业务边界**:类似于语义环境,为通用语言划定范围
|
||
2. **消除歧义**:确保团队对领域对象、事件的认知一致
|
||
3. **领域转换**:同一对象在不同上下文有不同名称(goods在电商称"商品",运输称"货物")
|
||
4. **模型隔离**:防止不同业务领域的模型相互干扰
|
||
|
||
|
||
|
||
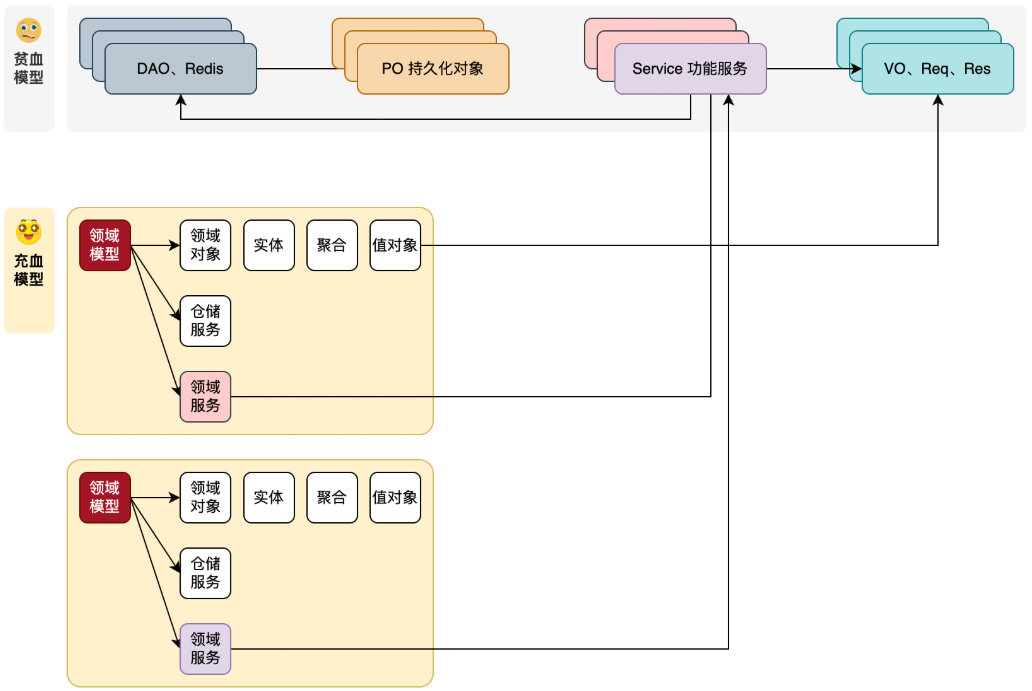
### 领域模型
|
||
|
||
指特定业务领域内,业务规则、策略以及业务流程的抽象和封装。在设计手段上,通过风暴模型拆分领域模块,形成界限上下文。最大的区别在于把原有的`众多 Service + 数据模型`的方式,拆分为独立的有边界的领域模块。每个领域内创建自身所属的;领域对象(实体、聚合、值对象)、仓储服务(DAO 操作)、工厂、端口适配器Port(调用外部接口的手段)等。
|
||
|
||
|
||
|
||
- 在原本的 Service + 贫血的数据模型开发指导下,Service 串联调用每一个功能模块。这些基础设施(对象、方法、接口)是被相互调用的。这也是因为贫血模型并没有面向对象的设计,所有的需求开发只有详细设计。
|
||
- 换到充血模型下,现在我们以一个领域功能为聚合,拆分一个领域内所需的 Service 为领域服务,VO、Req、Res 重新设计为领域对象,DAO、Redis 等持久化操作为仓储等。举例:一套账户服务中的,授信认证、开户、提额降额等,每一个都是一个独立的领域,在每个独立的领域内,创建自身领域所需的各项信息。
|
||
- 领域模型还有一个特点,它自身只关注业务功能实现,不与外部任何接口和服务直连。如;不会直接调用 DAO 操作库,也不会调用缓存操作 Redis,更不会直接引入 RPC 连接其他微服务。而是通过仓库和端口适配器,定义调用外部数据的含有出入参对象的接口标准,让基础设施层做具体的调用实现——通过这样的方式让领域只关心业务实现,同时做好防腐。
|
||
|
||
|
||
|
||
### 领域服务
|
||
|
||
**一组**无状态**的业务操作,封装那些“不属于任何单个实体/聚合”的领域逻辑。**
|
||
|
||
**职责**
|
||
|
||
- 执行**跨聚合**、跨实体的业务场景——比如“为多个订单一次性计算优惠”、“在用户和仓库之间做一次库存预占”。
|
||
- 协调仓储接口、调用多个聚合根的方法,但本身不持有长期状态,也不了解持久化细节。
|
||
|
||
**典型示例**
|
||
|
||
**订单支付功能**:
|
||
涉及订单、用户账户、支付信息等**多个实体**,适合放在领域服务中实现
|
||
|
||
```java
|
||
public class PaymentService {
|
||
public void processPayment(Order order, PaymentDetails paymentDetails, Account account) {
|
||
// 处理支付逻辑
|
||
// 调用多个实体方法来处理支付过程
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### 领域对象
|
||
|
||
#### 实体
|
||
|
||
实体是指具有唯一标识的业务对象。在代码中,唯一标识通常表现为ID属性,例如:
|
||
|
||
- 订单实体:订单ID
|
||
- 用户实体:用户ID
|
||
|
||
**核心特征**
|
||
|
||
- 实体的属性可以随时间变化
|
||
- 唯一标识(ID)始终保持不变
|
||
|
||
实体映射到代码中就是实体类,通常采用**充血模型**实现,即与这个实体相关的所有业务逻辑都写在实体类中。
|
||
|
||
|
||
|
||
#### 值对象
|
||
|
||
值对象是没有唯一标识的业务对象,具有以下特征:
|
||
|
||
1. 创建后不可修改(immutable)
|
||
2. 只能通过**整体替换**来更新
|
||
3. 通常用于描述实体的属性和特征
|
||
|
||
在开发值对象的时候,通常**不会提供 setter 方法**,而是提供构造函数或者 Builder 方法来实例化对象。这个对象通常不会独立作为方法的入参对象,但做可以独立**作为出参对象**使用。
|
||
|
||
|
||
|
||
#### 聚合与聚合根(Aggregate & Aggregate Root)
|
||
|
||
在 DDD 中,**聚合**是一组相关的实体(Entity)和值对象(Value Object)的集合,它们共同承担一个业务功能,并作为一个**事务与一致性边界**被一起管理;而**聚合根**则是这整个聚合对外的唯一入口和“带头人”。
|
||
|
||
**聚合(Aggregate)**
|
||
|
||
- **一致性边界**:聚合内的所有变更要么全部成功,要么全部失败,保证内部数据始终保持不变式(Invariant)。
|
||
- **事务边界**:一次事务只能跨越一个聚合,聚合内部的操作在同一事务中完成。
|
||
- **边界保护**:禁止外部直接操作聚合内除根实体之外的对象,所有访问和变更都必须通过聚合根。
|
||
|
||
**聚合根(Aggregate Root)**
|
||
|
||
- **唯一入口**:每个聚合只能有一个根实体;外部只能通过它来查找、添加、修改或删除聚合内的对象。
|
||
- **实体身份**:聚合根本身是一个拥有全局唯一标识(ID)的实体,封装聚合内部所有业务逻辑与校验。
|
||
- **操作封装**:聚合根提供方法(如 `addItem()`、`updateAddress()`)来维护内部实体和值对象的一致性,不暴露内部结构。
|
||
- **跨聚合关联**:与其他聚合交互时,仅通过 ID 或专门的领域服务进行,无直接对象引用,防止耦合越界。
|
||
|
||
```java
|
||
public class Order { // ← 聚合根(Aggregate Root)
|
||
private final OrderId id; // 根实体,带全局唯一 ID
|
||
private List<OrderItem> items; // 聚合内实体
|
||
private ShippingAddress address; // 聚合内值对象
|
||
|
||
public void addItem(Product p, int qty) {
|
||
// 校验库存、价格等业务规则
|
||
items.add(new OrderItem(p.getId(), p.getPrice(), qty));
|
||
// 校验聚合不变式:总金额 = 明细之和
|
||
}
|
||
|
||
public List<OrderItem> getItems() {
|
||
return Collections.unmodifiableList(items);
|
||
}
|
||
|
||
public void updateAddress(ShippingAddress addr) {
|
||
// 校验地址合法性
|
||
this.address = addr;
|
||
}
|
||
// … 其它业务方法 …
|
||
}
|
||
|
||
```
|
||
|
||
**聚合**:订单聚合**包含** `OrderItem`(实体)和 `ShippingAddress`(值对象),它们在同一事务中一起保存或回滚。
|
||
|
||
**聚合根**:即`Order` 类,对外暴露操作接口,封装内部状态与一致性,不允许直接操作 `OrderItem` 或地址。
|
||
|
||
|
||
|
||
### 仓储服务
|
||
|
||
**特征**
|
||
|
||
- 封装持久化操作:Repository负责封装所有与数据源交互的操作,如**创建、读取、更新和删除(CRUD)操作**。这样,领域层的代码就可以避免直接处理数据库或其他存储机制的复杂性。
|
||
- 领域对象的集合管理:Repository通常被视为领域对象的集合,提供了查询和过滤这些对象的方法,使得领域对象的获取和管理更加方便。
|
||
- 抽象接口:Repository定义了一个与持久化机制无关的接口,这使得领域层的代码可以在不同的持久化机制之间切换,而不需要修改业务逻辑。
|
||
|
||
|
||
|
||
**职责分离**
|
||
|
||
- **领域层** 只定义 **Repository 接口**,关注“需要做哪些数据操作”(增删改查、复杂查询),不关心具体实现。
|
||
- **基础设施层** 实现这些接口(ORM、JDBC、Redis、ES、RPC、HTTP、MQ 推送等),封装所有外部资源的访问细节。
|
||
|
||
仓储解耦的手段使用了依赖倒置的设计。
|
||
|
||
<img src="https://pic.bitday.top/i/2025/06/25/qt4nbs-0.png" alt="image-20250625162115367" style="zoom: 80%;" />
|
||
|
||
**示例:** 只定义接口,由基础设施层来实现。
|
||
|
||
```java
|
||
public interface IActivityRepository {
|
||
|
||
GroupBuyActivityDiscountVO queryGroupBuyActivityDiscountVO(String source, String channel);
|
||
|
||
SkuVO querySkuByGoodsId(String goodsId);
|
||
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### 聚合和领域服务的区别
|
||
|
||
| 特性 | 聚合(Aggregate) | 领域服务(Domain Service) |
|
||
| ------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||
| **本质** | **一组相关**实体和值对象的组合,形成一个事务与一致性边界 | 无状态的业务逻辑单元,封装**跨实体或跨聚合**的操作 |
|
||
| **状态** | 有状态——包含实体/值对象,维护自身的数据和不变式 | 无状态——只定义行为,不保存对象状态 |
|
||
| **职责** | 1. 维护内部对象的一致性2. 提供对外唯一入口(聚合根)3. 定义事务边界 | 1. 执行不适合归入任何单一聚合的方法2. 协调多个聚合或实体完成一段业务流程 |
|
||
| **边界** | 聚合边界内的所有操作要么全部成功要么全部失败 | 没有一致性边界,只是一段可复用的业务流程 |
|
||
| **典型用法** | `Order.addItem()`、`Order.updateAddress()` 等,操作聚合根来修改内部状态 | `PricingService.calculateFinalPrice(order, coupons)`<br />`InventoryService.reserveStock(order)` |
|
||
|
||
|
||
|
||
**总结:**可以通过“开公司”的比喻来帮助大家理解 DDD。领域就像公司的行业,决定了公司所从事的核心业务;限界上下文是公司内部的各个部门,每个部门有独立的职责和规则;实体是公司中的员工,具有唯一标识和生命周期;值对象是员工的地址或电话等属性,只有值的意义,没有独立的身份;聚合是部门,由多个实体和值对象组成,聚合根(如部门经理)是部门的入口,确保部门内部的一致性;领域服务则是跨部门的职能服务,比如 HR 或 IT 服务,为各部门提供支持和协作。
|
||
|
||
|
||
|
||
## DDD架构设计
|
||
|
||
### 四层架构
|
||
|
||
1. **用户接口层interface**:处理用户交互和展示
|
||
2. **应用层application**:协调领域对象完成业务用例
|
||
3. **领域层domain**:包含核心业务逻辑和领域模型
|
||
4. **基础设施层infrastructure**:提供技术实现支持
|
||
|
||
<img src="https://pic.bitday.top/i/2025/06/23/rg25k3-0.png" alt="image-20250623170005859" style="zoom:67%;" />
|
||
|
||
**如何从MVC架构映射到DDD架构?**
|
||
|
||
<img src="https://pic.bitday.top/i/2025/06/23/s68hcx-0.png" alt="image-20250623170403189" style="zoom:67%;" />
|
||
|
||
|
||
|
||
### 六边形架构
|
||
|
||
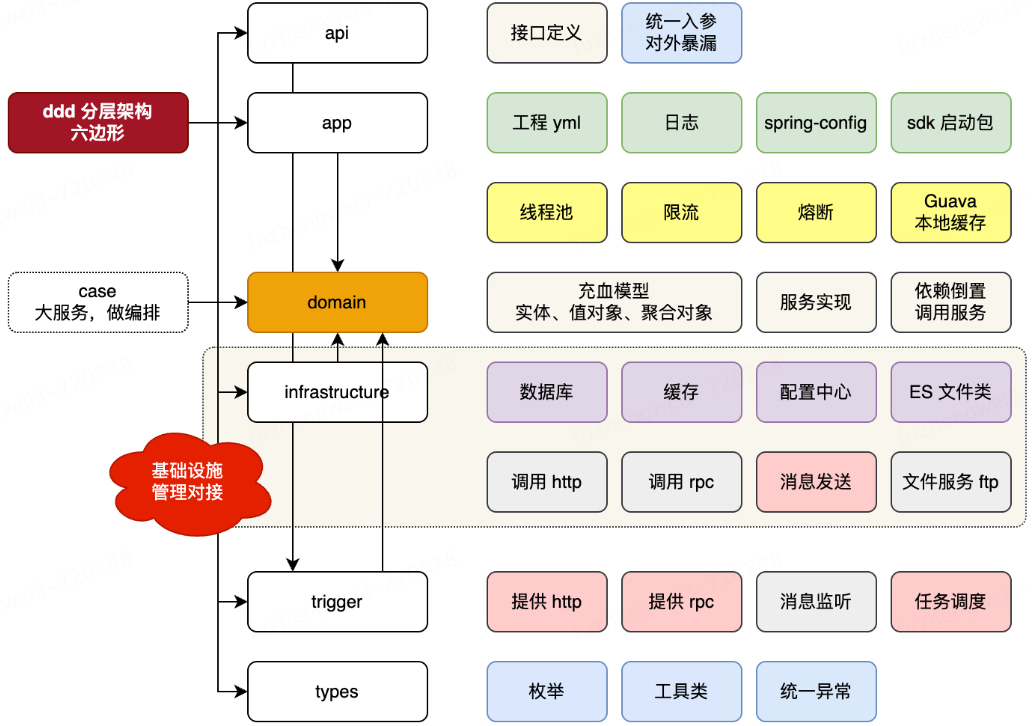
|
||
|
||
|
||
|
||
### 领域模型设计
|
||
|
||
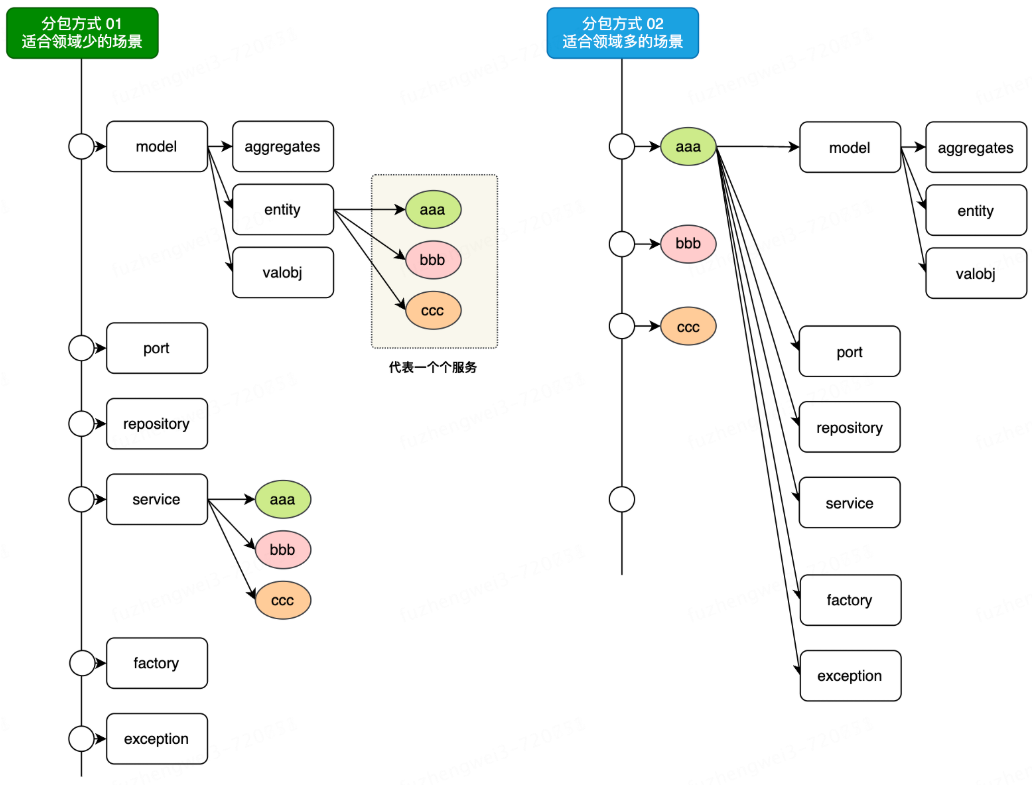
|
||
|
||
- 方式1;DDD 领域科目类型分包,类型之下写每个业务逻辑。
|
||
- 方式2;业务领域分包,每个业务领域之下有自己所需的 DDD 领域科目。
|
||
|
||
|
||
|
||
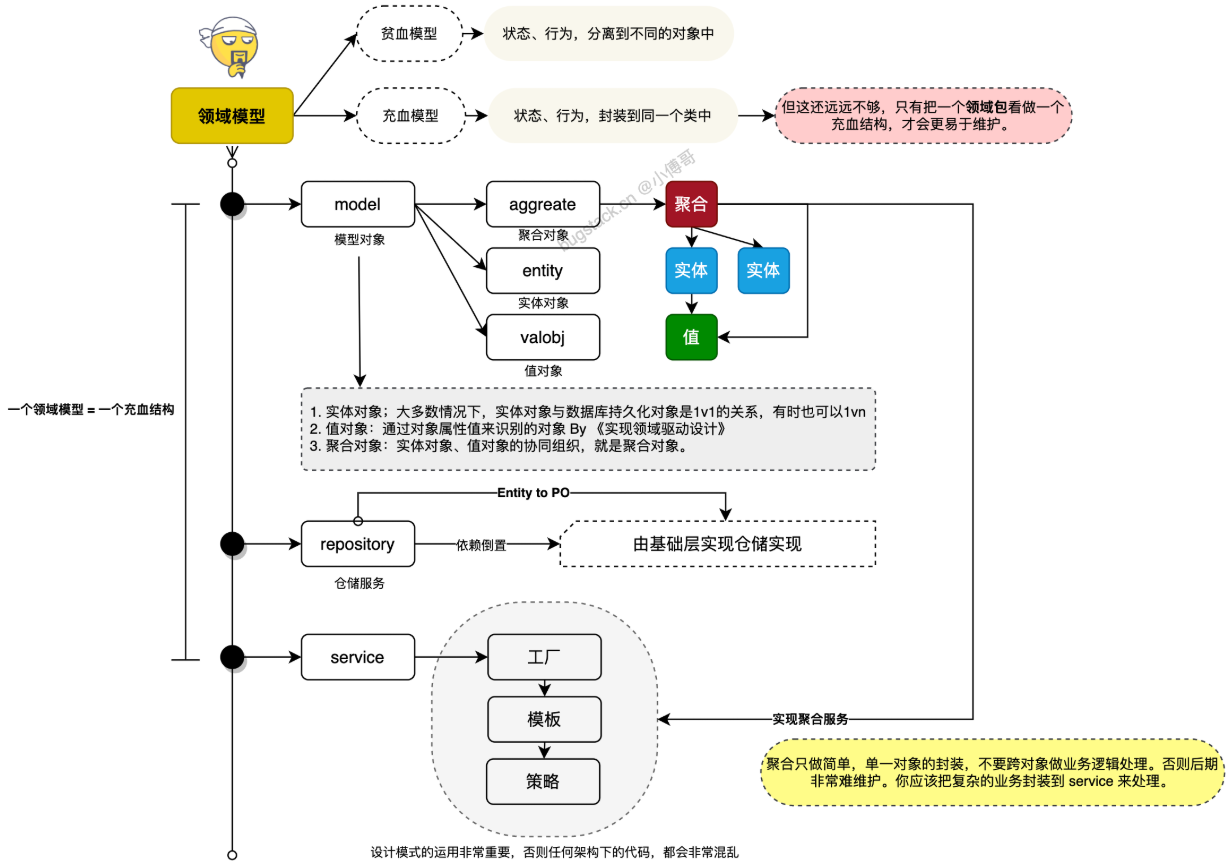
|