1028 lines
30 KiB
Markdown
1028 lines
30 KiB
Markdown
多智能体随机网络的全局知识对其模型收敛性影响的研究
|
||
|
||
|
||
|
||
1. 智能体网络的现状、包括网络结构(和现有互联网、物联网的差异)、通信协议(A2A(agent)、MCP成为主流,为了智能体之间的通信)传统的协议已经慢慢被替代,不止是传统互联网应用-》大模型
|
||
2. 多智能体随机网络与传统互联网不一样,结构基于随机网络(有什么作用,举一些具体的例子),通信协议(没有专门的协议,我们工作的出发点)、应用(联邦学习、图神经网络、强化学习)
|
||
3. 网络模型的收敛性,怎么定义收敛性?收敛速度、收敛效率(考虑代价)、收敛的稳定性(换了个环境变化大),联邦学习、强化学习收敛性的问题,和哪些因素有关,网络全局结构对它的影响;推理阶段也有收敛性,多智能体推理结果是否一致;图神经网络推理结果是否一致。
|
||
4. 多智能体随机网络全局知识的获取(分布式、集中式)
|
||
|
||
|
||
|
||
多智能体随机机会网络、动态谱参数估算、网络重构算法、聚类量化算法、联邦学习、图神经网络
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
如何确定kmeans的簇数?节点之间的流量,空间转为时间的图。
|
||
|
||
压缩感知 函数拟合 采样定理 傅里叶变换
|
||
|
||
|
||
|
||
## **谱分解**与网络重构
|
||
|
||
实对称矩阵性质:
|
||
|
||
对于任意 $n \times n$ 的实对称矩阵 $A$:
|
||
|
||
1. **秩可以小于 $n$**(即存在零特征值,矩阵不可逆)。
|
||
|
||
2. 但仍然有 $n$ 个线性无关的特征向量(即可对角化)。
|
||
|
||
3. 特征值有正有负!!!
|
||
|
||
|
||
|
||
一个实对称矩阵可以通过其特征值和特征向量进行分解。对于一个 $n \times n$ 的**对称矩阵** $A$,
|
||
|
||
**完整谱分解**可以表示为:
|
||
$$
|
||
A = Q \Lambda Q^T \\
|
||
A = \sum_{i=1}^{n} \lambda_i x_i x_i^T
|
||
$$
|
||
|
||
$Q$是$n \times n$的正交矩阵,每一列是一个特征向量;$\Lambda$是$n \times n$的对角矩阵,对角线元素是特征值$\lambda_i$ ,其余为0。
|
||
|
||
其中,$\lambda_i$ 是矩阵 $A$ 的第 $i$ 个特征值,$x_i$ 是对应的特征向量。**(注意!这里的特征向量需要归一化!!!)**
|
||
|
||
|
||
|
||
**如果矩阵 $A$ 的秩为 $r$ ,那么谱分解里恰好有 $r$ 个非零特征值。**
|
||
|
||
用这 $r$ 对特征值/特征向量就能**精确**重构出 $A$,因为零特征值对矩阵重构不提供任何贡献。
|
||
|
||
因此,需要先对所有特征值取绝对值,从大到小排序,取前 $r$ 个!!!
|
||
|
||
|
||
|
||
**截断的谱分解**(取前 $\kappa$ 个特征值和特征向量)
|
||
|
||
如果我们只保留前 $\kappa$ 个绝对值最大的特征值和对应的特征向量,那么:
|
||
|
||
- **特征向量矩阵 $U_\kappa$**:取 $U$ 的前 $\kappa$ 列,维度为 $n \times \kappa$。
|
||
- **特征值矩阵 $\Lambda_\kappa$**:取 $\Lambda$ 的前 $\kappa \times \kappa$ 子矩阵(即前 $\kappa$ 个对角线元素),维度为 $\kappa \times \kappa$。
|
||
|
||
因此,截断后的近似分解为:
|
||
|
||
$$
|
||
A \approx U_\kappa \Lambda_\kappa U_\kappa^T\\
|
||
A \approx \sum_{i=1}^{\kappa} \lambda_i x_i x_i^T
|
||
$$
|
||
|
||
**推导过程**
|
||
|
||
1. **特征值和特征向量的定义**
|
||
对于一个对称矩阵 $A$,其特征值和特征向量满足:
|
||
|
||
$$
|
||
A x_i = \lambda_i x_i
|
||
$$
|
||
|
||
其中,$\lambda_i$ 是特征值,$x_i$ 是对应的特征向量。
|
||
|
||
2. **谱分解**
|
||
将这些特征向量组成一个正交矩阵 $Q$
|
||
|
||
$A = Q \Lambda Q^T$
|
||
|
||
$$
|
||
Q = \begin{bmatrix} x_1 & x_2 & \cdots & x_n \end{bmatrix},
|
||
$$
|
||
|
||
$$
|
||
Q \Lambda = \begin{bmatrix} \lambda_1 x_1 & \lambda_2 x_2 & \cdots & \lambda_n x_n \end{bmatrix}.
|
||
$$
|
||
|
||
$$
|
||
Q \Lambda Q^T = \begin{bmatrix} \lambda_1 x_1 & \lambda_2 x_2 & \cdots & \lambda_n x_n \end{bmatrix} \begin{bmatrix} x_1^T \\ x_2^T \\ \vdots \\ x_n^T \end{bmatrix}.
|
||
$$
|
||
|
||
$$
|
||
Q \Lambda Q^T = \lambda_1 x_1 x_1^T + \lambda_2 x_2 x_2^T + \cdots + \lambda_n x_n x_n^T.
|
||
$$
|
||
|
||
可以写为
|
||
$$
|
||
A = \sum_{i=1}^{n} \lambda_i x_i x_i^T.
|
||
$$
|
||
|
||
|
||
|
||
3. **网络重构**
|
||
在随机网络中,网络的邻接矩阵 $A$ 通常是对称的。利用预测算法得到的谱参数 $\{\lambda_i, x_i\}$ 后,就可以用以下公式重构网络矩阵:
|
||
|
||
$$
|
||
A(G) = \sum_{i=1}^{n} \lambda_i x_i x_i^T
|
||
$$
|
||
|
||
|
||
|
||
| **性质** | **特征分解/谱分解** | **奇异值分解(SVD)** |
|
||
| ------------ | -------------------------------- | ------------------------------------------ |
|
||
| **适用矩阵** | 仅限**方阵**($n \times n$) | **任意矩阵**($m \times n$,包括矩形矩阵) |
|
||
| **分解形式** | $A = P \Lambda P^{-1}$ | $A = U \Sigma V^*$ |
|
||
| **矩阵类型** | 可对角化矩阵(如对称、正规矩阵) | 所有矩阵(包括不可对角化的方阵和非方阵) |
|
||
| **输出性质** | 特征值($\lambda_i$)可能是复数 | 奇异值($\sigma_i$)始终为非负实数 |
|
||
| **正交性** | 仅当 $A$ 正规时 $P$ 是酉矩阵 | $U$ 和 $V$ 始终是酉矩阵(正交) |
|
||
|
||
谱分解的对象为实对称矩阵
|
||
|
||
|
||
|
||
## 奇异值分解
|
||
|
||
### 步骤
|
||
|
||
**步骤 1:验证矩阵对称性**
|
||
|
||
确保 $A$ 是实对称矩阵(即 $A = A^\top$),此时SVD可通过特征分解直接构造。
|
||
|
||
---
|
||
|
||
**步骤 2:计算特征分解**
|
||
|
||
对 $A$ 进行特征分解:
|
||
$$
|
||
A = Q \Lambda Q^\top
|
||
$$
|
||
其中:
|
||
|
||
- $Q$ 是正交矩阵($Q^\top Q = I$),列向量为 $A$ 的特征向量。
|
||
- $\Lambda = \text{diag}(\lambda_1, \lambda_2, \dots, \lambda_n)$,$\lambda_i$ 为 $A$ 的特征值(可能有正、负或零)。
|
||
|
||
---
|
||
|
||
**步骤 3:构造奇异值矩阵 $\Sigma$**
|
||
|
||
- **奇异值**:取特征值的绝对值 $\sigma_i = |\lambda_i|$,得到对角矩阵:
|
||
$$
|
||
\Sigma = \text{diag}(\sigma_1, \sigma_2, \dots, \sigma_n)
|
||
$$
|
||
|
||
- **排列顺序**:通常按 $\sigma_i$ 降序排列(可选,但推荐)。
|
||
|
||
---
|
||
|
||
**步骤 4:处理符号(负特征值)**
|
||
|
||
- **符号矩阵 $S$**:定义对角矩阵 $S = \text{diag}(s_1, s_2, \dots, s_n)$,其中:
|
||
$$
|
||
s_i = \begin{cases}
|
||
1 & \text{if } \lambda_i \geq 0, \\
|
||
-1 & \text{if } \lambda_i < 0.
|
||
\end{cases}
|
||
$$
|
||
|
||
- **左奇异向量矩阵 $U$**:调整特征向量的方向:
|
||
$$
|
||
U = Q S
|
||
$$
|
||
即 $U$ 的列为 $Q$ 的列乘以对应特征值的符号。
|
||
|
||
---
|
||
|
||
**步骤 5:确定右奇异向量矩阵 $V$**
|
||
|
||
由于 $A$ 对称,右奇异向量矩阵 $V$ 直接取特征向量矩阵:
|
||
$$
|
||
V = Q
|
||
$$
|
||
|
||
---
|
||
|
||
**步骤 6:组合得到SVD**
|
||
|
||
最终SVD形式为:
|
||
$$
|
||
A = U \Sigma V^\top
|
||
$$
|
||
验证:
|
||
$$
|
||
U \Sigma V^\top = (Q S) \Sigma Q^\top = Q (S \Sigma) Q^\top = Q \Lambda Q^\top = A
|
||
$$
|
||
(因为 $S \Sigma = \Lambda$,例如 $\text{diag}(-1) \cdot \text{diag}(2) = \text{diag}(-2)$)。
|
||
|
||
### **例子(含正、负、零特征值)**
|
||
|
||
设对称矩阵
|
||
$$
|
||
A = \begin{bmatrix} 1 & 0 & 2 \\ 0 & -1 & 0 \\ 2 & 0 & 1 \end{bmatrix}
|
||
$$
|
||
|
||
1. **特征分解**
|
||
|
||
- 特征值:
|
||
$$ \lambda_1 = 3, \quad \lambda_2 = -1, \quad \lambda_3 = 0 $$
|
||
|
||
- 特征向量矩阵:
|
||
$$
|
||
Q = \begin{bmatrix}
|
||
\frac{1}{\sqrt{2}} & 0 & \frac{1}{\sqrt{2}} \\
|
||
0 & 1 & 0 \\
|
||
\frac{1}{\sqrt{2}} & 0 & -\frac{1}{\sqrt{2}}
|
||
\end{bmatrix}
|
||
$$
|
||
|
||
2. **构造SVD**
|
||
|
||
- 步骤:
|
||
1. 按 $|\lambda_i|$ 降序排列:$3, 1, 0$(取绝对值后排序)。
|
||
2. 奇异值矩阵:
|
||
$$ \Sigma = \text{diag}(3, 1, 0) $$
|
||
3. 符号调整矩阵:
|
||
$$ S = \text{diag}(1, -1, 1) \quad (\lambda_3=0 \text{ 的符号可任选}) $$
|
||
4. 左奇异向量矩阵:
|
||
$$ U = Q S = \begin{bmatrix}
|
||
\frac{1}{\sqrt{2}} & 0 & \frac{1}{\sqrt{2}} \\
|
||
0 & -1 & 0 \\
|
||
\frac{1}{\sqrt{2}} & 0 & -\frac{1}{\sqrt{2}}
|
||
\end{bmatrix} $$
|
||
5. 右奇异向量矩阵:
|
||
$$ V = Q $$
|
||
|
||
- **验证**:
|
||
$$ U \Sigma V^\top = A $$
|
||
|
||
|
||
|
||
## 网络重构分析
|
||
|
||
### 基于扰动理论的特征向量估算方法
|
||
|
||
设原矩阵为 $A$,扰动后矩阵为 $A+\zeta C$(扰动矩阵 $\zeta C$,$\zeta$是小参数),令其第 $i$ 个特征值、特征向量分别为 $\lambda_i,x_i$ 和 $\tilde\lambda_i,\tilde x_i$。
|
||
|
||
**特征向量的一阶扰动公式:**
|
||
$$
|
||
\Delta x_i
|
||
=\tilde x_i - x_i
|
||
\;\approx\;
|
||
\zeta \sum_{k\neq i}
|
||
\frac{x_k^T\,C\,x_i}{\lambda_i - \lambda_k}\;x_k,
|
||
$$
|
||
|
||
- **输出**:对应第 $i$ 个特征向量修正量 $\Delta x_i$。
|
||
|
||
|
||
|
||
**特征值的一阶扰动公式:**
|
||
$$
|
||
\Delta\lambda_i = \tilde\lambda_i - \lambda_i \;\approx\;\zeta\,x_i^T\,C\,x_i
|
||
$$
|
||
**关键假设:**当扰动较小( $\zeta\ll1$) 且各模态近似正交均匀时,常作进一步近似
|
||
$$
|
||
x_k^T\,C\,x_i \;\approx\; x_i^T\,C\,x_i \;
|
||
$$
|
||
正交: $\{x_k\}$ 本身是正交基,这是任何对称矩阵特征向量天然具有的属性。
|
||
|
||
均匀:我们把 $C$ 看作“**不偏向任何特定模态**”的随机小扰动——换句话说,投影到任何两个方向 $(x_i,x_k)$ 上的耦合强度 $x_k^T\,C\,x_i\quad\text{和}\quad x_i^T\,C\,x_i$ 在数值量级上应当差不多,因此可以互相近似。
|
||
|
||
|
||
|
||
因此,将所有的 $x_k^T C x_i$ 替换为 $x_i^T C x_i$:
|
||
$$
|
||
\Delta x_i \approx \zeta \sum_{k\neq i} \frac{x_i^T C x_i}{\lambda_i - \lambda_k} x_k = \zeta (x_i^T C x_i) \sum_{k\neq i} \frac{1}{\lambda_i - \lambda_k} x_k = \sum_{k\neq i} \frac{\Delta \lambda_i}{\lambda_i - \lambda_k} x_k \tag{*}
|
||
$$
|
||
|
||
$$
|
||
\Delta x_i \approx\sum_{k\neq i} \frac{\Delta \lambda_i}{\lambda_i - \lambda_k} x_k \tag{*}
|
||
$$
|
||
|
||
问题:
|
||
|
||
1. **当前时刻的邻接矩阵**
|
||
$$
|
||
A^{(1)}\in\mathbb R^{n\times n},\qquad
|
||
A^{(1)}\,x_i^{(1)}=\lambda_i^{(1)}\,x_i^{(1)},\quad \|x_i^{(1)}\|=1.
|
||
$$
|
||
|
||
2. **下一时刻的邻接矩阵**
|
||
$$
|
||
A^{(2)}\in\mathbb R^{n\times n},
|
||
$$
|
||
**已知**它的第 $i$ 个特征值 $\lambda_i^{(2)}$(卡尔曼滤波得来). **求**当前时刻的特征向量 $x_i^{(2)}$。
|
||
|
||
|
||
|
||
**下一时刻**第 $i$ 个特征向量的预测为
|
||
$$
|
||
\boxed{
|
||
x_i^{(2)}
|
||
\;=\;
|
||
x_i^{(1)}+\Delta x_i
|
||
\;\approx\;
|
||
x_i^{(1)}
|
||
+\sum_{k\neq i}
|
||
\frac{\lambda_i^{(2)}-\lambda_i^{(1)}}
|
||
{\lambda_i^{(1)}-\lambda_k^{(1)}}\;
|
||
x_k^{(1)}.
|
||
}
|
||
$$
|
||
通过该估算方法可以依次求出下一时刻的所有特征向量。
|
||
|
||
### 矩阵符号说明
|
||
|
||
- 原始(真实)邻接矩阵 $A$ ,假设 $A$ 的秩为 $r$: $\lambda_{r+1}=\cdots=\lambda_n=0$
|
||
$$
|
||
A = \sum_{m=1}^n \lambda_m\,x_m x_m^T=\begin{align*}
|
||
\sum_{m=1}^r \lambda_m x_m x_m^T + \sum_{m=r+1}^n \lambda_m x_m x_m^T = \sum_{m=1}^r \lambda_m x_m x_m^T
|
||
\end{align*},
|
||
$$
|
||
|
||
|
||
|
||
- 滤波估计得到的矩阵及谱分解:
|
||
$$
|
||
\widetilde A = \sum_{m=1}^r \widetilde\lambda_m\,\widetilde x_m\widetilde x_m^T,
|
||
\quad \widetilde\lambda_1\ge\cdots\ge\widetilde\lambda_n\;
|
||
$$
|
||
|
||
- 只取前 $\kappa$ 项重构 :
|
||
$$
|
||
A_\kappa \;=\;\sum_{m=1}^\kappa \widetilde\lambda_m\,\widetilde x_m\widetilde x_m^T,
|
||
$$
|
||
|
||
- 对 $A_\kappa$ 进行K-means聚类,得到 $A_{final}$
|
||
|
||
|
||
|
||
目标是让 $A_{final}$ = $A$
|
||
|
||
|
||
|
||
### **0/1矩阵**
|
||
|
||
其中 $\widetilde{\lambda}_i$ 和 $\widetilde{x}_i$ 分别为通过预测得到矩阵 $\widetilde A$ 的第 $i$ 个特征值和对应特征向量。 然而预测值和真实值之间存在误差,直接进行矩阵重构会使得重构误差较大。 对于这个问题,文献提出一种 0/1 矩阵近似恢复算法。
|
||
$$
|
||
a_{ij} =
|
||
\begin{cases}
|
||
1, & \text{if}\ \lvert a_{ij} - 1 \rvert < 0.5 \\
|
||
0, & \text{else}
|
||
\end{cases}
|
||
$$
|
||
只要我们的估计值与真实值之间差距**小于 0.5**,就能保证阈值处理以后准确地恢复原边信息。
|
||
|
||
|
||
|
||
文中提出网络特征值扰动与邻接矩阵扰动具有相同的规律
|
||
|
||
真实矩阵 $A$ 与预测矩阵 $\widetilde{A} $ 之间的差为 (秩为 $r$)
|
||
$$
|
||
A - \widetilde{A}=\sum_{m=1}^r \lambda_m\,x_m x_m^T-\sum_{m=1}^r \widetilde\lambda_m\,\widetilde x_m\widetilde x_m^T
|
||
$$
|
||
**若假设特征向量扰动可忽略,即$\widetilde x_m\approx x_m$ ,扰动可简化为(这里可能有问题,特征向量的扰动也要计算)**
|
||
$$
|
||
A - \widetilde{A} = \sum_{m=1}^r \Delta \lambda_m {x}_m {x}_m^T.
|
||
$$
|
||
对于任意元素 $(i, j)$ 上有
|
||
$$
|
||
|a_{ij} - \widetilde{a}_{ij}|=\left| \sum_{m=1}^r \Delta \lambda_m ({x}_m {x}_m^T)_{ij} \right| < \frac{1}{2}
|
||
$$
|
||
|
||
于一个归一化的特征向量 ${x}_m$,其外积矩阵$ {x}_m {x}_m^T$ 满足
|
||
$$
|
||
|({x}_m {x}_m^T)_{ij}| \leq 1.
|
||
$$
|
||
例:
|
||
$$
|
||
x_m = \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix}\\
|
||
x_m x_m^T = \begin{bmatrix} \frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{bmatrix} \begin{bmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{bmatrix} = \begin{bmatrix} \frac{1}{2} & \frac{1}{2} \\ \frac{1}{2} & \frac{1}{2} \end{bmatrix}
|
||
$$
|
||
每个元素的绝对值$\leq1$
|
||
|
||
|
||
$$
|
||
\left| \sum_{m=1}^r \Delta \lambda_m (x_m x_m^T)_{ij} \right| \leq \sum_{m=1}^r |\Delta \lambda_m| \cdot |(x_m x_m^T)_{ij}| \leq \sum_{m=1}^r |\Delta \lambda_m|.
|
||
$$
|
||
为了确保 $|a_{ij} - \widetilde{a}_{ij}| < \frac{1}{2}$ 对所有 $(i,j)$ 成立,网络精准重构条件为:
|
||
$$
|
||
\sum_{m=1}^r\left| \Delta \lambda_m\right| < \frac{1}{2}
|
||
$$
|
||
|
||
|
||
|
||
0-1 矩阵能够精准重构的容忍上界与网络中的节点数量成反比,网络中节点数量越多,实现精准重构的要求也就越高。
|
||
|
||
|
||
|
||
如果在**高层次**(特征值滤波)的误差累积超过了一定阈值,就有可能在**低层次**(邻接矩阵元素)中出现翻转。公式推导了只要谱参数的误差之和**不超过** 0.5,就可以保证0-1矩阵的精确重构。
|
||
|
||
|
||
|
||
## **非0/1矩阵**
|
||
|
||
### **量化误差**
|
||
|
||
对估计矩阵 $\tilde{A}$ 的所有元素 $\{\tilde{a}_{ij}\}$ 进行 $K$-means 聚类,得到每个簇中心 $\{c_k\}_{k=1}^K$。
|
||
|
||
- **簇内平均偏差**:
|
||
对于第 $k$簇,算该簇所有点到中心的平均绝对偏差:
|
||
$$
|
||
\text{mean}_k = \frac{1}{|\mathcal{S}_k|} \sum_{(i,j)\in\mathcal{S}_k} |\tilde{a}_{ij} - c_k|
|
||
$$
|
||
|
||
- **全局允许误差**:
|
||
$$
|
||
\delta_{\max} = \frac{1}{K} \sum_{k=1}^K \text{mean}_k
|
||
$$
|
||
|
||
|
||
|
||
### 对于归一化向量 $x_m$ 的研究
|
||
|
||
$$
|
||
x_m = \begin{bmatrix} x_{m,1} \\ x_{m,2} \\ \vdots \\ x_{m,d} \end{bmatrix}
|
||
$$
|
||
|
||
$$
|
||
x_m x_m^T =
|
||
\begin{bmatrix}
|
||
x_{m,1}^2 & x_{m,1}x_{m,2} & \cdots & x_{m,1}x_{m,d} \\
|
||
x_{m,2}x_{m,1} & x_{m,2}^2 & \cdots & x_{m,2}x_{m,d} \\
|
||
\vdots & \vdots & \ddots & \vdots \\
|
||
x_{m,d}x_{m,1} & x_{m,d}x_{m,2} & \cdots & x_{m,d}^2
|
||
\end{bmatrix}
|
||
$$
|
||
|
||
$$
|
||
(x_m x_m^T)_{ij}=x_{m,i}\,x_{m,j}\,,
|
||
$$
|
||
|
||
**对于任意元素:**由于 $\|x_m\|_2=1$ 且 $|x_{m,i}|\le1$,必有
|
||
$$
|
||
|x_{m,i}x_{m,j}|\le1\,.
|
||
$$
|
||
|
||
**对于非对角线元素:**
|
||
|
||
对任意 $i\neq j$,由
|
||
$$
|
||
x_{m,i}^2 + x_{m,j}^2 \le \sum_{k=1}^d x_{m,k}^2 = 1
|
||
$$
|
||
|
||
$$
|
||
(|x_{m,i}| - |x_{m,j}|)^2 \geq 0 \implies |x_{m,i}|^2 + |x_{m,j}|^2 \geq 2 |x_{m,i}| |x_{m,j}|.
|
||
$$
|
||
|
||
$$
|
||
|x_{m,i}x_{m,j}| = |x_{m,i}||x_{m,j}| \leq \frac{|x_{m,i}|^2 + |x_{m,j}|^2}{2} = \frac{x_{m,i}^2 + x_{m,j}^2}{2}.
|
||
$$
|
||
|
||
$$
|
||
|(x_m x_m^T)_{ij}|=|x_{m,i}x_{m,j}| \le \frac{x_{m,i}^2 + x_{m,j}^2}{2} \le \frac12\,,
|
||
$$
|
||
|
||
|
||
|
||
|
||
|
||
### 带权重构需控制两类误差:
|
||
|
||
这里暂时忽略特征向量的扰动,即 $x_m=\widetilde x_m$
|
||
|
||
1. **滤波误差**$\eta$:
|
||
|
||
**来源**:滤波器在谱域对真实特征值/向量的估计偏差,包括
|
||
|
||
- 特征值偏差 $\Delta\lambda_m=\lambda_m-\widetilde\lambda_m$
|
||
- **特征向量:矩阵扰动得来**
|
||
- 设矩阵 $A$ 的秩为 $r$
|
||
|
||
$$
|
||
A - \tilde A=\sum_{m=1}^r \lambda_m\,x_m x_m^T-\sum_{m=1}^r \tilde\lambda_m\,\tilde x_m\tilde x_m^T=\sum_{m=1}^r \Delta \lambda_m {x}_m {x}_m^T.
|
||
$$
|
||
|
||
$$
|
||
\eta_F=\Bigl\|\sum_{m=1}^r \Delta\lambda_m\, x_m x_m^T\Bigr\|_F = \sqrt{\sum_{m=1}^r (\Delta\lambda_m)^2}.
|
||
$$
|
||
|
||
|
||
|
||
2. **截断谱分解误差** $\epsilon$:
|
||
只取前 $\kappa$ 个特征对重构
|
||
|
||
$$
|
||
A_\kappa \;=\;\sum_{m=1}^\kappa \widetilde\lambda_m\,\widetilde x_m\widetilde x_m^T=\;\sum_{m=1}^\kappa \widetilde\lambda_m\, x_m x_m^T
|
||
$$
|
||
|
||
$$
|
||
\widetilde A - A_\kappa=\sum_{m=\kappa+1}^r \widetilde\lambda_m\, x_m x_m^T
|
||
$$
|
||
|
||
|
||
$$
|
||
\Bigl\|\sum_{m=\kappa+1}^r \widetilde\lambda_m\, x_m x_m^T\Bigr\|_F=\sqrt{\sum_{m = \kappa + 1}^{r} \widetilde{\lambda}_{m}^{2}}.\epsilon
|
||
= \Bigl\|\sum_{m=\kappa+1}^r \widetilde\lambda_m\, x_m x_m^T\Bigr\|_F=\sqrt{\sum_{m = \kappa + 1}^{r} \widetilde{\lambda}_{m}^{2}}.
|
||
$$
|
||
|
||
|
||
|
||
3. **总的误差**
|
||
$$
|
||
\text{误差矩阵: } A - A_\kappa = \left( A - \tilde{A} \right) + \left( \tilde{A} - A_\kappa \right) = \sum_{m=1}^r \Delta \lambda_m x_m x_m^T + \sum_{m=\kappa+1}^r \tilde{\lambda}_m x_m x_m^T
|
||
$$
|
||
- 研究单个元素误差:
|
||
$$
|
||
\text{元素误差绝对值:}|(A - A_\kappa)_{ij}| \leq \sum_{m=1}^r |\Delta \lambda_m| \cdot |(x_m x_m^T)_{ij}| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m| \cdot |(x_m x_m^T)_{ij}|
|
||
$$
|
||
对于非对角线元素,由于 $|(x_m x_m^T)_{ij}| \leq \frac12$(归一化特征向量):
|
||
$$
|
||
|(A - A_\kappa)_{ij}| \leq \frac{1}{2}\left(\sum_{m=1}^r |\Delta \lambda_m| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m|\right)
|
||
$$
|
||
|
||
- 研究整个矩阵误差:
|
||
$$
|
||
\| A - A_\kappa \|_F^2 = \left\| \sum_{m=1}^r \Delta \lambda_m x_m x_m^T + \sum_{m=\kappa+1}^r \widetilde{\lambda}_m x_m x_m^T \right\|_F^2
|
||
$$
|
||
而 $\| x_m x_m^T \|_F = \sqrt{\text{tr}(x_m x_m^T x_m x_m^T)} = \sqrt{\text{tr}(x_m x_m^T)} = \| x_m \|_2 = 1$,因此:
|
||
$$
|
||
\| A - A_\kappa \|_F^2 = \sum_{m=1}^r \Delta \lambda_m^2 + \sum_{m=\kappa+1}^r \widetilde{\lambda}_m^2
|
||
$$
|
||
最终:
|
||
$$
|
||
\| A - A_\kappa \|_F = \sqrt{ \sum_{m=1}^r |\Delta \lambda_m|^2 + \sum_{m=\kappa+1}^r |\widetilde{\lambda}_m|^2 }
|
||
$$
|
||
|
||
|
||
---
|
||
|
||
4. **最终约束条件**:
|
||
|
||
$$
|
||
|(A - A_\kappa)_{ij}| \leq 容忍误差\tau
|
||
$$
|
||
|
||
$$
|
||
\frac{1}{2}\left(\sum_{m=1}^r |\Delta \lambda_m| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m|\right)\leq 容忍误差\tau
|
||
$$
|
||
|
||
|
||
|
||
|
||
$$
|
||
\delta_F
|
||
= \lVert A - A_k \rVert_F
|
||
= \sqrt{\sum_{i,j} \bigl(A - A_k\bigr)_{ij}^{2}}
|
||
\;\le\; \sqrt{N^{2}\,\tau^{2}}
|
||
\;=\; N\tau
|
||
$$
|
||
|
||
|
||
|
||
|
||
### 容忍误差推导
|
||
|
||
#### **容忍误差**
|
||
|
||
要保证重构矩阵 $A_\kappa$ 在每个位置上“落到”正确的某一 簇而不搞混,就必须让重构误差的最大绝对值严格小于任意两个相邻量化级别之间的半距(half‐spacing)。具体地:
|
||
|
||
1. **量化级别及间距定义**
|
||
设原始矩阵元素只能取 $K$ 个离散值:
|
||
$$
|
||
v_1 < v_2 < \cdots < v_K,
|
||
$$
|
||
相邻级别间距为:
|
||
$$
|
||
d_m = v_{m+1} - v_m,\quad m=1,\dots,K-1.
|
||
$$
|
||
|
||
2. **最小间距确定**
|
||
计算所有相邻级别的最小间距:
|
||
$$
|
||
d_{\min} = \min_{1\le m\le K-1} d_m.
|
||
$$
|
||
|
||
3. **通用容忍误差**
|
||
为确保重构值不会"越界"到相邻级别,取阈值:
|
||
$$
|
||
\boxed{\tau = \frac{d_{\min}}{2}.}
|
||
$$
|
||
|
||
|
||
|
||
|
||
量化误差和数据的分布(不是重构出来的矩阵值)有关,和容忍误差无关。
|
||
|
||
|
||
|
||
**示例:**
|
||
|
||
1. 0-1矩阵,$a=0, b=1,K=2$,容忍误差为0.5。
|
||
2. 量化级别 $\{0,\,0.3,\,0.7,\,1\}$ ,$K=4$ 时:
|
||
- 相邻间距:$0.3, 0.4, 0.3$
|
||
- $d_{\min}=0.3$,故 $\tau=0.15$
|
||
|
||
|
||
|
||
#### **量化误差**
|
||
|
||
量化阈值:重构矩阵与真实矩阵的对应元素误差最大值为 $\tau$ ;
|
||
|
||
量化误差:真实矩阵与经量化之后的对应元素误差最大值为 $\delta$
|
||
|
||
|
||
|
||
当我们把一个数值 $x$ 量化到某个中心 $v_m$ 时,它本身就会产生一个"量化误差":
|
||
$$
|
||
\underbrace{|x - v_m|}_{\text{量化误差}}.
|
||
$$
|
||
|
||
|
||
**1.当 $x$ 落在第 $m$ 个区间时**
|
||
|
||
假设某个实数 $x$ 满足
|
||
|
||
$$ t_{m-1} \leq x < t_{m} $$
|
||
|
||
(其中我们约定 $t_{0} = -\infty$, $t_{K} = +\infty$),这时把 $x$ 量化到中心 $v_{m}$。
|
||
|
||
**2.计算量化误差**
|
||
|
||
由于 $t_{m} = \frac{v_{m} + v_{m+1}}{2}$ 且 $t_{m-1} = \frac{v_{m-1} + v_{m}}{2}$,当 $x \in [t_{m-1}, t_{m})$ 时,离它所在的中心 $v_{m}$ 的最大距离,就是它正好位于这段区间的"最远端"——也就是:
|
||
$$
|
||
\max_{x \in [t_{m-1}, t_{m})} |x - v_{m}| = \max \left\{ |t_{m-1} - v_{m}|, |t_{m} - v_{m}| \right\}.
|
||
$$
|
||
但 $t_{m} - v_{m} = \frac{v_{m+1} - v_{m}}{2} = \frac{d_{m}}{2}$,
|
||
|
||
同理 $v_{m} - t_{m-1} = \frac{v_{m} - v_{m-1}}{2} = \frac{d_{m-1}}{2}$。
|
||
|
||
所以对任意落在第 $m$ 个决策区间里的 $x$,其量化到 $v_{m}$ 时的偏差至多为
|
||
$$
|
||
|x - v_{m}| \leq \max \left( \frac{d_{m-1}}{2}, \frac{d_{m}}{2} \right) \leq \frac{d_{\min}}{2}.
|
||
$$
|
||
综上,对所有可能的 $x$:
|
||
$$
|
||
\max_{x} |x - Q(x)| = \frac{d_{\min}}{2}.
|
||
$$
|
||
于是定义 $\delta = \frac{d_{\min}}{2}$
|
||
|
||
|
||
|
||
### 已知量化误差推导容忍误差和码本
|
||
|
||
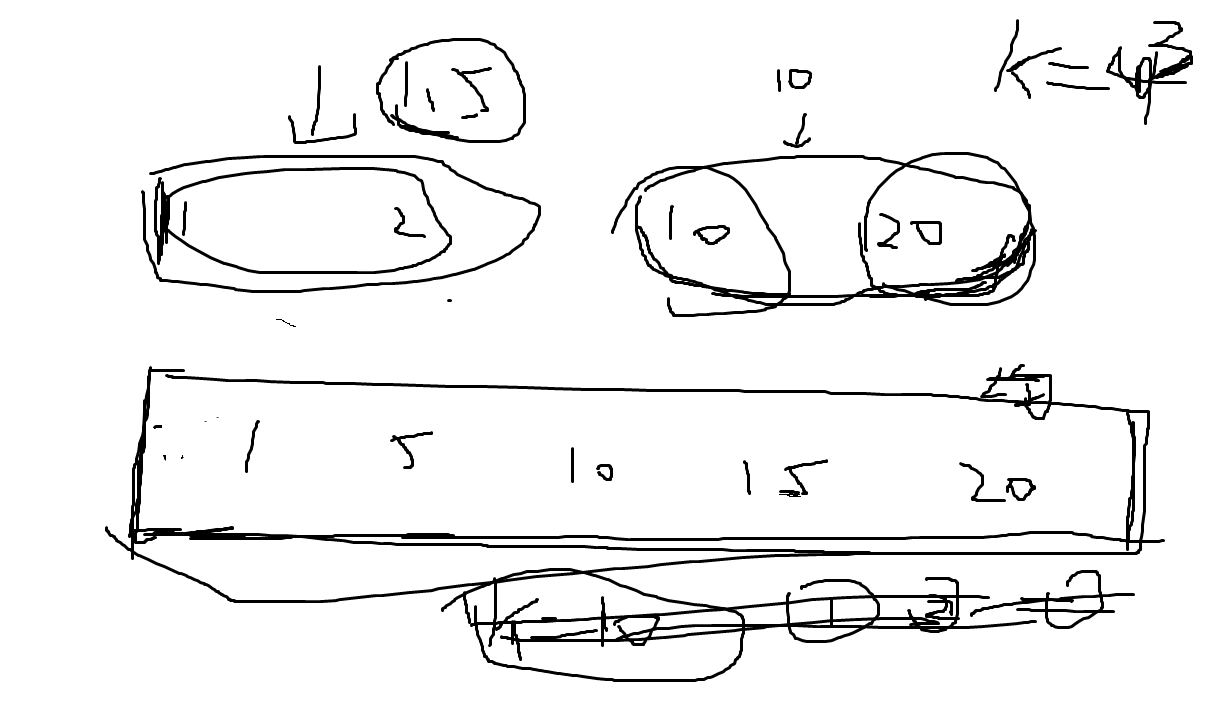
|
||
|
||
#### **推导容忍误差**
|
||
|
||
已知:所有待量化的数都落在 $[X_{\min}, X_{\max}]$
|
||
|
||
:量化误差上限
|
||
|
||
$$
|
||
\delta = \max_{x} |x - Q(x)|.
|
||
$$
|
||
|
||
1.因为对所有落在第 $m$ 个区间的点,都有
|
||
$$
|
||
|x - v_{m}| \leq \delta
|
||
$$
|
||
|
||
由"落在第 $m$ 区间"可推出
|
||
|
||
$$
|
||
|x - v_{m}| \leq \max \left\{\frac{v_{m+1} - v_{m}}{2}, \frac{v_{m} - v_{m-1}}{2}\right\} \leq \delta.
|
||
$$
|
||
|
||
因此
|
||
|
||
$$
|
||
\frac{v_{m+1} - v_{m}}{2} \geq \delta, \quad \frac{v_{m} - v_{m-1}}{2} \geq \delta, \quad \forall m.
|
||
$$
|
||
|
||
2.这意味着"任意相邻中心间距"都不小于 $2\delta$,即
|
||
$$
|
||
v_{m+1} - v_{m} \geq 2 \delta, \quad \forall m \implies d_{\min} = 2 \delta.
|
||
$$
|
||
|
||
3."容忍阈值"定义为使得重构值 $\widehat{x}$ 与真实中心 $v_{m}$ 之间只要偏差在 $\tau$ 以内,量化就不会跳到旁边。显然
|
||
$$
|
||
\tau = \min_{m}\left\{\frac{v_{m+1} - v_{m}}{2}\right\} = \frac{d_{\min}}{2} = \frac{2 \delta}{2} = \delta.
|
||
$$
|
||
|
||
|
||
#### **构造码本:**
|
||
|
||
**1.确定量化间隔**
|
||
|
||
因为"量化误差的最大值"为 $\delta$,在一维的均匀量化里相邻两个中心(码本)中点到中心的距离就是量化误差的上界,所以我们令
|
||
$$
|
||
\Delta = 2\,\delta.
|
||
$$
|
||
相邻两个量化中心之间的距离都取 $\Delta$,这样任何一个点到它最近中心的距离最多是 $\tfrac{\Delta}{2} = \delta$。
|
||
|
||
**2.确定量化级别数 $K$**
|
||
|
||
为了覆盖整个区间 $[X_{\min},\,X_{\max}]$,这些间隔为 $\Delta=2\delta$ 的"窗口"要铺下去。具体来说,如果我们有 $K$ 个中心 $\{v_1,\dots,v_K\}$,并且它们相邻之间都相差 $\Delta$,那么最左边中心的"覆盖下限"是
|
||
|
||
$$
|
||
v_1 - \delta = v_1 - \tfrac{\Delta}{2},
|
||
$$
|
||
|
||
最右边中心的"覆盖上限"是
|
||
|
||
$$
|
||
v_K + \delta = v_K + \tfrac{\Delta}{2}.
|
||
$$
|
||
|
||
要保证所有 $x \in [X_{\min},\,X_{\max}]$ 都能落进这串"区间并覆盖",只要
|
||
|
||
$$
|
||
v_1 - \tfrac{\Delta}{2} \le X_{\min}, \quad v_K + \tfrac{\Delta}{2} \ge X_{\max}.
|
||
$$
|
||
|
||
下面我们令最左侧的中心刚好满足 $v_1 - \tfrac{\Delta}{2} = X_{\min}$,于是
|
||
|
||
$$
|
||
v_1 = X_{\min} + \frac{\Delta}{2} = X_{\min} + \delta.
|
||
$$
|
||
|
||
如果相邻中心间距都为 $\Delta$,那么第 $m$ 个中心就是
|
||
|
||
$$
|
||
v_m = v_1 + (m-1)\,\Delta = \bigl(X_{\min} + \delta\bigr) + (m-1)\cdot(2\delta).
|
||
$$
|
||
|
||
此时,第 $K$ 个中心为
|
||
|
||
$$
|
||
v_K = X_{\min} + \delta + (K-1)\,2\delta = X_{\min} + (2K - 1)\,\delta.
|
||
$$
|
||
|
||
要满足"第 $K$ 个中心加上 $\delta$ 能覆盖到 $X_{\max}$",即
|
||
|
||
$$
|
||
v_K + \delta = X_{\min} + (2K - 1)\,\delta + \delta = X_{\min} + 2K\,\delta \ge X_{\max}.
|
||
$$
|
||
|
||
因此
|
||
|
||
$$
|
||
2\,K\,\delta \ge X_{\max} - X_{\min} \Longleftrightarrow K \ge \frac{X_{\max} - X_{\min}}{2\,\delta}.
|
||
$$
|
||
|
||
我们取最小的整数满足这个不等式:
|
||
|
||
$$
|
||
\boxed{K = \Bigl\lceil \frac{X_{\max} - X_{\min}}{2\,\delta} \Bigr\rceil.}
|
||
$$
|
||
|
||
**3.得到码本 $\{v_m\}$ 和阈值**
|
||
|
||
1. 令
|
||
|
||
$$
|
||
\Delta = 2\,\delta,\quad K = \Bigl\lceil \tfrac{X_{\max} - X_{\min}}{\Delta} \Bigr\rceil.
|
||
$$
|
||
|
||
2. 对 $m = 1,2,\dots,K$,令
|
||
|
||
$$
|
||
v_m = X_{\min} + \delta + (m - 1)\,\Delta = X_{\min} + \delta + (m - 1)\,(2\,\delta) = X_{\min} + \bigl(2m - 1\bigr)\,\delta.
|
||
$$
|
||
|
||
- 此时,第 1 个中心是 $v_1 = X_{\min} + \delta$;
|
||
- 第 $K$ 个中心是 $v_K = X_{\min} + (2K - 1)\,\delta$。
|
||
|
||
3. 中点阈值数组 $\{\,t_m\mid m=1,\dots,K-1\}$ 就是
|
||
|
||
$$
|
||
t_m = \frac{v_m + v_{m+1}}{2} = \frac{\bigl[X_{\min} + (2m-1)\delta\bigr] + \bigl[X_{\min} + (2(m+1)-1)\delta\bigr]}{2} = X_{\min} + 2m\,\delta.
|
||
$$
|
||
|
||
因此,决策规则是:
|
||
|
||
- 如果 $x < t_1 = X_{\min} + 2\delta$,就量化到 $v_1 = X_{\min} + \delta$;
|
||
|
||
- 如果 $t_{m-1} \le x < t_m$ (即 $X_{\min} + 2(m-1)\delta \le x < X_{\min} + 2m\delta$),就量化到
|
||
|
||
$$
|
||
v_m = X_{\min} + (2m-1)\,\delta;
|
||
$$
|
||
|
||
- 如果 $x \ge t_{K-1} = X_{\min} + 2(K-1)\delta$,就量化到
|
||
|
||
$$
|
||
v_K = X_{\min} + (2K-1)\,\delta.
|
||
$$
|
||
|
||
|
||
|
||
|
||
|
||
### 维数选择推导
|
||
|
||
$$
|
||
\frac{1}{2}\left(\sum_{m=1}^r |\Delta \lambda_m| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m|\right)\leq 量化阈值\tau
|
||
$$
|
||
|
||
已知 $\sum_{m=1}^r |\Delta \lambda_m|=\eta$ ,量化阈值 $\tau$ ,令 $s=2\tau-\eta$ ,设截断谱分解误差为 $\epsilon$
|
||
$$
|
||
\epsilon \leq 2\tau-\eta
|
||
$$
|
||
借助**前缀和+二分查找**寻找最小的 $\kappa$ :
|
||
|
||
1. **预处理:计算前缀和**
|
||
|
||
2. 设绝对值降序的估计特征值列表为 $\bigl|\widetilde\lambda_1\bigr| \ge \bigl|\widetilde\lambda_2\bigr| \ge \cdots \ge \bigl|\widetilde\lambda_r\bigr|$,
|
||
计算它们的前缀和:
|
||
$$
|
||
S_k = \sum_{m=1}^k \bigl|\widetilde\lambda_m\bigr|, \quad k=0,1,\dots,r, \quad S_0=0.
|
||
$$
|
||
总和 $S_r = \sum_{m=1}^r \bigl|\widetilde\lambda_m\bigr|$ 对应 $\kappa=0$ 时的最大截断误差。
|
||
|
||
3. **将「尾和 ≤ 预算 $s$」转成前缀和条件**
|
||
记预算 $s = 2\tau - \eta$,尾部累积(截断误差)为:
|
||
$$
|
||
T(k) = \sum_{m=k+1}^r \bigl|\widetilde\lambda_m\bigr| = S_r - S_k.
|
||
$$
|
||
条件 $T(k) \le s$ 等价于:
|
||
$$
|
||
S_k \ge S_r - s.
|
||
$$
|
||
定义阈值:
|
||
$$
|
||
\theta = S_r - s.
|
||
$$
|
||
|
||
4. **二分查找最小 $\kappa$**
|
||
在已排好序的数组 $S_k$(严格单调递增或非减)中,用二分查找找出最小的 $k$ 使得
|
||
$$
|
||
S_k \;\ge\;\theta.
|
||
$$
|
||
此 $k$ 即为所求的最小截断秩 $\kappa$。
|
||
|
||
**伪代码:**
|
||
|
||
```python
|
||
# 输入:绝对值降序的估计特征值列表 |λ̃₁| ≥ |λ̃₂| ≥ ... ≥ |λ̃ᵣ|, 预算 s ≥ 0
|
||
S = [0] * (r+1) # 前缀和数组初始化
|
||
for k in range(1, r+1):
|
||
S[k] = S[k-1] + |λ̃ₖ| # 计算前缀和(实际代码中需替换 |λ̃ₖ| 为具体变量)
|
||
|
||
θ = S[r] - s # 计算查找阈值
|
||
|
||
# 在 S[0..r] 中二分查找最小 k 使得 S[k] ≥ θ
|
||
low, high = 0, r
|
||
while low < high:
|
||
mid = (low + high) // 2
|
||
if S[mid] < θ:
|
||
low = mid + 1
|
||
else:
|
||
high = mid
|
||
κ = low # 最终得到的最小截断
|
||
```
|
||
|
||
|
||
|
||
### 最近邻量化
|
||
|
||
算法思想:
|
||
|
||
1. **已知量化级别**
|
||
先假定你已有 $K$ 个量化级别(或簇中心):
|
||
|
||
$$ v_1 < v_2 < \cdots < v_K $$
|
||
|
||
这些值通常是事先人为设定好的、或者某种优化后得到的最佳码本。
|
||
|
||
2. **计算决策边界(中点阈值)**
|
||
对于一维空间,相邻两个量化级别之间的“分界”很自然就是它们的中点:
|
||
|
||
$$ t_m = \frac{v_m + v_{m+1}}{2}, \quad m = 1,\dots,K-1 $$
|
||
|
||
也就是一旦输入 $x$ 落在 $[t_{m-1},\,t_m)$ 这个区间(约定 $t_0 = -\infty$,$t_K = +\infty$),就映为 $v_m$。
|
||
|
||
3. **最近邻映射**
|
||
对于矩阵 $M$ 中的每个元素 $x = M_{ij}$,只要找到它对应的区间号 $m$,就把 $x$ 替换为 $v_m$。
|
||
由于阈值已经按增序排列,查找时可以用二分搜索(binary search),使得整体复杂度为 $O(\log K)$/次映射。
|
||
|
||
4. **误差保证**
|
||
为了确保“重构误差”不会把重构值落到相邻簇去,需要保证真实误差 $\lvert A_{\kappa}(i,j) - M_{ij} \rvert$ 严格小于任意两个相邻量化级别之间的半距 $\frac{d_{\min}}{2}$。
|
||
这里 $d_m = v_{m+1} - v_m$,取最小间距 $d_{\min} = \min_{m} d_m$,就有误差阈值 $\tau = \frac{d_{\min}}{2}$。
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
```text
|
||
输入:数组 v[1..K](升序排列)
|
||
输出:阈值数组 t[1..(K-1)](对应各区间的分界)
|
||
|
||
function initialize_thresholds(v[1..K]):
|
||
for m = 1 to K-1 do
|
||
t[m] = ( v[m] + v[m+1] ) / 2
|
||
end for
|
||
return t # 长度为 K-1
|
||
|
||
|
||
输入:矩阵 M (尺寸 N×N),量化级别 v[1..K],阈值数组 t[1..(K-1)]
|
||
输出:量化后矩阵 Ḿ(N×N)
|
||
|
||
function quantizeMatrix(M, v, t):
|
||
let N = number_of_rows(M) # 假设 M 是正方阵 N×N
|
||
创建新矩阵 Ḿ,大きさ N×N
|
||
|
||
for i = 1 to N do
|
||
for j = 1 to N do
|
||
x = M[i][j]
|
||
# 在阈值数组 t 中二分查找,找到第一个 t[m] 使得 x < t[m]
|
||
# 如果没有找到(即 x >= t[K-1]),则归到最后一个簇
|
||
idx = binarySearchThreshold(t, x)
|
||
# binarySearchThreshold 的返回:
|
||
# 如果 x < t[1],返回 idx = 1;
|
||
# 如果 t[m-1] <= x < t[m],返回 idx = m;
|
||
# 如果 x >= t[K-1],返回 idx = K。
|
||
Ḿ[i][j] = v[idx]
|
||
end for
|
||
end for
|
||
|
||
return Ḿ
|
||
```
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
如果量化阈值不一样,你需要**预先**知道矩阵的某个元素$|(A - A_\kappa)_{ij}|$的真实值属于哪个类别(1、4、10),以给元素误差不同的量化阈值,而不是默认的 $d_{\min}$
|
||
$$
|
||
\text{误差矩阵: } A - A_\kappa = \left( A - \widetilde{A} \right) + \left( \widetilde{A} - A_\kappa \right) = \sum_{m=1}^r \Delta \lambda_m x_m x_m^T + \sum_{m=\kappa+1}^r \widetilde{\lambda}_m x_m x_m^T
|
||
$$
|
||
而且不能进行放缩:
|
||
$$
|
||
|(A - A_\kappa)_{ij}| \leq \frac{1}{2}\left(\sum_{m=1}^r |\Delta \lambda_m| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m|\right)
|
||
$$
|
||
这个式子会导致误差矩阵每个位置的元素取了同样的上界(即都有同样的误差),不能体现真实的误差。
|
||
|
||
|
||
|
||
方法一:
|
||
|
||
实验法,选取若干组数据做实验,
|
||
|
||
数据包括真实矩阵 $A$ 和重构矩阵 $A_\kappa$ ,选取不同的 $\kappa$ 值计算误差矩阵 $E(\kappa)$ ,根据真实矩阵A,预先知道$E(\kappa)$ 每个位置的量化阈值,若每个位置$E(\kappa)$ 都小于其的量化阈值,那么当前的 $\kappa$ 符合条件。
|
||
|
||
|
||
|
||
方法二:
|
||
$$
|
||
|(A - A_\kappa)_{ij}| \leq \frac{1}{2}\left(\sum_{m=1}^r |\Delta \lambda_m| + \sum_{m=\kappa+1}^r |\widetilde\lambda_m|\right) \leq \min_{1\le m\le K-1} d_m.
|
||
$$
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||

|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
滤波误差:
|
||
|
||
高飞、李镇和都是**实验统计**误差加和获取 + 幂律分布和线性分布 精度预估??
|
||
|
||
|
||
|
||
|
||
|
||
量化的间隔是不是就和分布有关,有无其他影响因素。
|
||
|
||
通信原理,采样量化。
|
||
|
||
压缩感知的话量化分隔不是均匀的。
|
||
|
||
|
||
|
||
假设都是破松分布
|
||
|
||
|
||
|
||
|
||
|
||

|
||
|
||
估计带权邻接矩阵(存在量化误差),比较分布式算法的误差。
|