35 KiB
苍穹外卖
开发环境搭建
后端项目结构
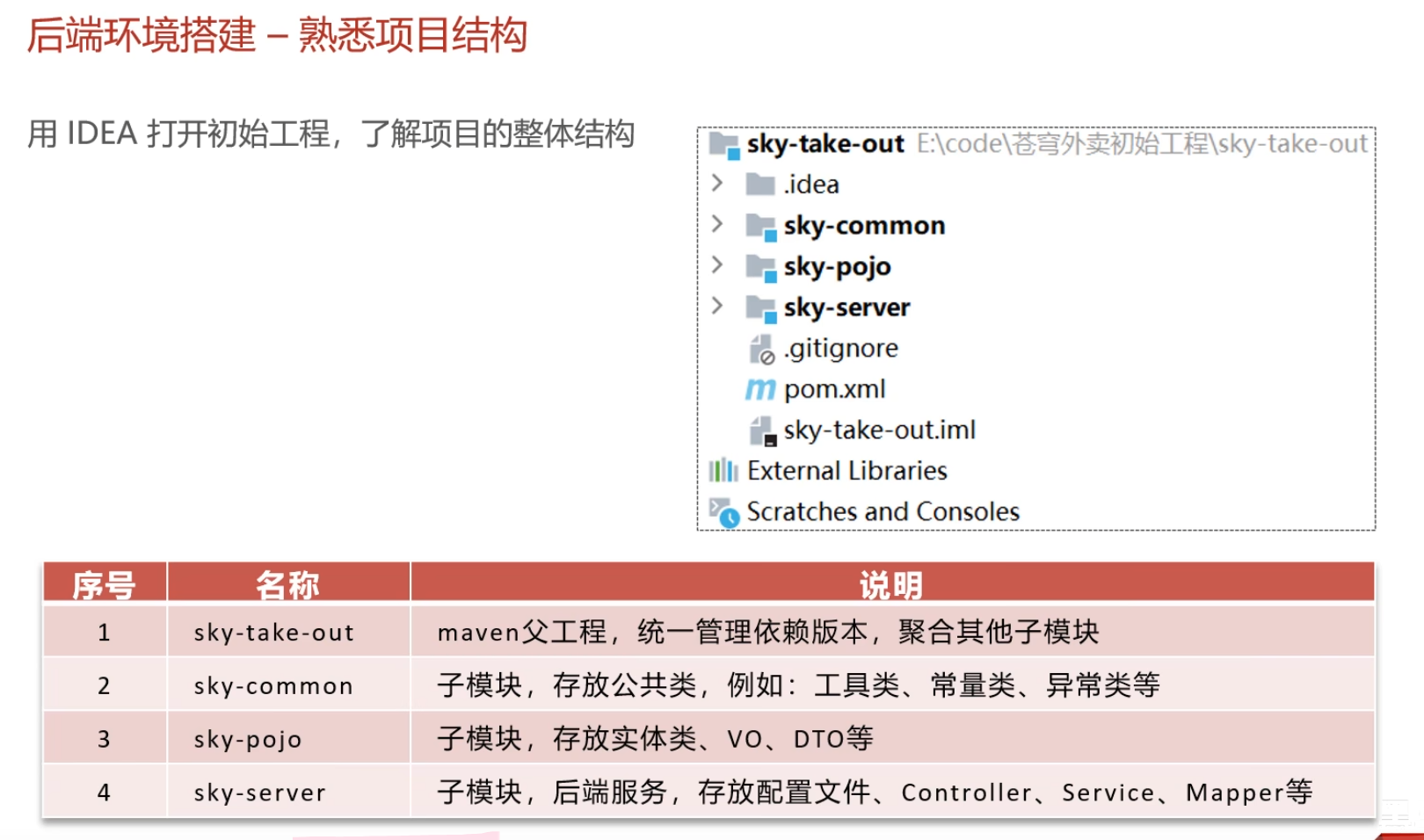
分析sky-pojo模块的每个包的作用:
| 名称 | 说明 |
|---|---|
| Entity | 实体,通常和数据库中的表对应 |
| DTO | 数据传输对象,通常用于程序中各层之间传递数据(接收从web来的数据) |
| VO | 视图对象,为前端展示数据提供的对象(响应给web) |
| POJO | 普通Java对象,只有属性和对应的getter和setter |
数据库设计文档
| 序号 | 数据表名 | 中文名称 |
|---|---|---|
| 1 | employee | 员工表 |
| 2 | category | 分类表 |
| 3 | dish | 菜品表 |
| 4 | dish_flavor | 菜品口味表 |
| 5 | setmeal | 套餐表 |
| 6 | setmeal_dish | 套餐菜品关系表 |
| 7 | user | 用户表 |
| 8 | address_book | 地址表 |
| 9 | shopping_cart | 购物车表 |
| 10 | orders | 订单表 |
| 11 | order_detail | 订单明细表 |
@TableName("user")public class User { @TableId private Long id; private String name; private Integer age; @TableField("isMarried") private Boolean isMarried; @TableField("order") private String order;}Java
1.nginx 反向代理的好处:
-
提高访问速度
因为nginx本身可以进行缓存,如果访问的同一接口,并且做了数据缓存,nginx就直接可把数据返回,不需要真正地访问服务端,从而提高访问速度。
-
进行负载均衡
所谓负载均衡,就是把大量的请求按照我们指定的方式均衡的分配给集群中的每台服务器。
-
保证后端服务安全
因为一般后台服务地址不会暴露,所以使用浏览器不能直接访问,可以把nginx作为请求访问的入口,请求到达nginx后转发到具体的服务中,从而保证后端服务的安全。
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://localhost:8080/admin/; #反向代理
}
}
2.负载均衡配置(有两个后端服务器)
upstream webservers{
server 192.168.100.128:8080;
server 192.168.100.129:8080;
}
server{
listen 80;
server_name localhost;
location /api/{
proxy_pass http://webservers/admin;#负载均衡
}
}
Swagger
-
使得前后端分离开发更加方便,有利于团队协作
-
接口的文档在线自动生成,降低后端开发人员编写接口文档的负担
-
功能测试
使用:
- 导入 knife4j 的maven坐标
在pom.xml中添加依赖
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-boot-starter</artifactId>
</dependency>
- 在配置类中加入 knife4j 相关配置
WebMvcConfiguration.java
/**
* 通过knife4j生成接口文档
* @return
*/
@Bean
public Docket docket() {
ApiInfo apiInfo = new ApiInfoBuilder()
.title("苍穹外卖项目接口文档")
.version("2.0")
.description("苍穹外卖项目接口文档")
.build();
Docket docket = new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo)
.select()
.apis(RequestHandlerSelectors.basePackage("com.sky.controller"))
.paths(PathSelectors.any())
.build();
return docket;
}
- 设置静态资源映射,否则接口文档页面无法访问
WebMvcConfiguration.java
/**
* 设置静态资源映射
* @param registry
*/
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/doc.html").addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");
}
常用注解
通过注解可以控制生成的接口文档,使接口文档拥有更好的可读性,常用注解如下:
| 注解 | 说明 |
|---|---|
| @Api | 用在类上,例如Controller,表示对类的说明 |
| @ApiModel | 用在类上,例如entity、DTO、VO |
| @ApiModelProperty | 用在属性上,描述属性信息 |
| @ApiOperation | 用在方法上,例如Controller的方法,说明方法的用途、作用 |
EmployeeLoginDTO.java
@Data
@ApiModel(description = "员工登录时传递的数据模型")
public class EmployeeLoginDTO implements Serializable {
@ApiModelProperty("用户名")
private String username;
@ApiModelProperty("密码")
private String password;
}

开发
加密算法
存放在数据表中的密码不能以明文存储,需对前端传来的密码进行加密。
spring security中提供了一个加密类BCryptPasswordEncoder。
它采用哈希算法 SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种可逆的算法,而哈希算法是一种不可逆的算法。
因为有随机盐的存在,所以相同的明文密码经过加密后的密码是不一样的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
- 添加配置
@Configuration
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().permitAll() // 允许所有请求
.and()
.csrf().disable(); // 禁用CSRF保护
}
@Bean
public BCryptPasswordEncoder encoder(){
return new BCryptPasswordEncoder();
}
}
- 使用
@Autowired
private BCryptPasswordEncoder bCryptPasswordEncoder;
// 加密
String encodedPassword=bCryptPasswordEncoder.encode(PasswordConstant.DEFAULT_PASSWORD);
employee.setPassword(encodedPassword);
// 比较
bCryptPasswordEncoder.matches(明文,密文);
新增员工的两个问题
问题1:
录入的用户名已存,抛出的异常后没有处理。
法一:每次新增员工前查询一遍数据库,保证无重复username再插入。
法二:插入后系统报“Duplicate entry”再处理。
推荐法二,因为发生异常的概率是很小的,每次新增前查询一遍数据库不划算。
问题2:
如何获得当前登录的管理员id==》拦截器中解析的token中的id怎么传入controller里?
方法:ThreadLocal
ThreadLocal为每个线程提供单独一份存储空间,具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问。
每次请求代表一个线程!!!注:请求可以先经过拦截器,再经过controller=>service=>mapper,都是在一个线程里。
public class BaseContext {
public static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
public static void removeCurrentId() {
threadLocal.remove();
}
}
实现方式:登录的时候BaseContext.setCurrentId(id);
要用的时候直接BaseContext.getCurrentId();
SpringMVC的消息转换器(处理日期)
1). 方式一
在属性上加上注解,对日期进行格式化

但这种方式,需要在每个时间属性上都要加上该注解,使用较麻烦,不能全局处理。
2). 方式二(推荐 )
在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对日期类型进行格式处理
作用:
- 请求数据转换(反序列化):当服务器接收到一个HTTP请求时,消息转换器将请求体中的数据(如JSON、XML等格式)转换成控制器(Controller)方法参数所期望的Java对象。这个过程称为反序列化。
- 响应数据转换(序列化):当控制器处理完业务逻辑后,需要将结果数据返回给客户端。消息转换器此时将Java对象序列化为客户端可识别的格式(如JSON、XML等),并包装在HTTP响应体中发送。
/**
* 扩展Spring MVC框架的消息转化器
* @param converters
*/
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
log.info("扩展消息转换器...");
//创建一个消息转换器对象
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
//需要为消息转换器设置一个对象转换器,对象转换器可以将Java对象序列化为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转化器加入容器中
converters.add(0,converter);
}
JacksonObjectMapper()文件:
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
// public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
构造实体对象的两种方法
public void startOrStop(Integer status, Long id) {
//法一
Employee employee = Employee.builder()
.status(status)
.id(id)
.build();
//法二
//Employee employee=new Employee();
//employee.setStatus(status);
//employee.setId(id);
}
还有一种:把源对象source的属性值赋给目标对象target中与源对象source的中有着同属性名的属性
BeanUtils.copyProperties(source,target);
修改员工信息(复用update方法)
代码能复用尽量复用!在mapper类里定义一个通用的update接口,即mybatis操作数据库时修改员工信息都调用这个接口。启用/禁用员工可能只要修改status,修改员工可能大面积修改属性,在mapper类中定义一个通用的update方法,但是controller层和service层的函数命名可以不一样,以区分两种业务。
在 EmployeeMapper 接口中声明 update 方法:
/**
* 根据主键动态修改属性
* @param employee
*/
void update(Employee employee);
在 EmployeeMapper.xml 中编写SQL:
<update id="update" parameterType="Employee">
update employee
<set>
<if test="name != null">name = #{name},</if>
<if test="username != null">username = #{username},</if>
<if test="password != null">password = #{password},</if>
<if test="phone != null">phone = #{phone},</if>
<if test="sex != null">sex = #{sex},</if>
<if test="idNumber != null">id_Number = #{idNumber},</if>
<if test="updateTime != null">update_Time = #{updateTime},</if>
<if test="updateUser != null">update_User = #{updateUser},</if>
<if test="status != null">status = #{status},</if>
</set>
where id = #{id}
</update>
公共字段自动填充——AOP编程
在实现公共字段自动填充,也就是在插入或者更新的时候为指定字段赋予指定的值,使用它的好处就是可以统一对这些字段进行处理,避免了重复代码。在上述的问题分析中,我们提到有四个公共字段,需要在新增/更新中进行赋值操作, 具体情况如下:
| 序号 | 字段名 | 含义 | 数据类型 | 操作类型 |
|---|---|---|---|---|
| 1 | create_time | 创建时间 | datetime | insert |
| 2 | create_user | 创建人id | bigint | insert |
| 3 | update_time | 修改时间 | datetime | insert、update |
| 4 | update_user | 修改人id | bigint | insert、update |
实现步骤:
1). 自定义注解 AutoFill,用于标识需要进行公共字段自动填充的方法
2). 自定义切面类 AutoFillAspect,统一拦截加入了 AutoFill 注解的方法,通过反射为公共字段赋值
3). 在 Mapper 的方法上加入 AutoFill 注解
若要实现上述步骤,需掌握以下知识(之前课程内容都学过)
**技术点:**枚举、注解、AOP、反射
Java中操作Redis
环境搭建
进入到sky-server模块
1). 导入Spring Data Redis的maven坐标(已完成)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2). 配置Redis数据源
在application-dev.yml中添加
sky:
redis:
host: localhost
port: 6379
password: 123456
database: 10
解释说明:
database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。
可以通过修改Redis配置文件来指定数据库的数量。
在application.yml中添加读取application-dev.yml中的相关Redis配置
spring:
profiles:
active: dev
redis:
host: ${sky.redis.host}
port: ${sky.redis.port}
password: ${sky.redis.password}
database: ${sky.redis.database}
3). 编写配置类,创建RedisTemplate对象
package com.sky.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
log.info("开始创建redis模板对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis的连接工厂对象 连接工厂负责创建与 Redis 服务器的连接
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置redis key的序列化器 这意味着所有通过这个RedisTemplate实例存储的键都将被转换为字符串格式存储在Redis中
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
解释说明:
当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为
JdkSerializationRedisSerializer,导致我们存到Redis中后的数据和原始数据有差别,故设置为
StringRedisSerializer序列化器。
功能测试
通过RedisTemplate对象操作Redis
在test下新建测试类
字符串测试
@SpringBootTest
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate(){
System.out.println(redisTemplate);
}
@Test
public void testString(){
//set get setex setnx
redisTemplate.opsForValue().set("city","北京");
String city= (String) redisTemplate.opsForValue().get("city");
System.out.println(city);
redisTemplate.opsForValue().set("code","1234",3, TimeUnit.MINUTES); //设置code的值为1234,过期时间3min
redisTemplate.opsForValue().setIfAbsent("lock","1"); //如果不存在该key则创建
redisTemplate.opsForValue().setIfAbsent("lock","2");
}
}
哈希测试
/**
* 操作哈希类型的数据
*/
@Test
public void testHash(){
//hset hget hdel hkeys hvals
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("100","name","tom");
hashOperations.put("100","age","20");
String name = (String) hashOperations.get("100", "name");
System.out.println(name);
Set keys = hashOperations.keys("100");
System.out.println(keys);
List values = hashOperations.values("100");
System.out.println(values);
hashOperations.delete("100","age");
}
get获得的是Object类型,keys获得的是set类型,values获得的是List
3). 操作列表类型数据
/**
* 操作列表类型的数据
*/
@Test
public void testList(){
//lpush lrange rpop llen
ListOperations listOperations = redisTemplate.opsForList();
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
List mylist = listOperations.range("mylist", 0, -1);
System.out.println(mylist);
listOperations.rightPop("mylist");
Long size = listOperations.size("mylist");
System.out.println(size);
}
4). 操作集合类型数据
/**
* 操作集合类型的数据
*/
@Test
public void testSet(){
//sadd smembers scard sinter sunion srem
SetOperations setOperations = redisTemplate.opsForSet();
setOperations.add("set1","a","b","c","d");
setOperations.add("set2","a","b","x","y");
Set members = setOperations.members("set1");
System.out.println(members);
Long size = setOperations.size("set1");
System.out.println(size);
Set intersect = setOperations.intersect("set1", "set2");
System.out.println(intersect);
Set union = setOperations.union("set1", "set2");
System.out.println(union);
setOperations.remove("set1","a","b");
}
5). 操作有序集合类型数据
/**
* 操作有序集合类型的数据
*/
@Test
public void testZset(){
//zadd zrange zincrby zrem
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset1","b",12);
zSetOperations.add("zset1","c",9);
Set zset1 = zSetOperations.range("zset1", 0, -1);
System.out.println(zset1);
zSetOperations.incrementScore("zset1","c",10);
zSetOperations.remove("zset1","a","b");
}
6). 通用命令操作
*匹配零个或多个字符。?匹配任何单个字符。[abc]匹配方括号内的任一字符(本例中为 'a'、'b' 或 'c')。[^abc]或[!abc]匹配任何不在方括号中的单个字符。
/**
* 通用命令操作
*/
@Test
public void testCommon(){
//keys exists type del
Set keys = redisTemplate.keys("*");
System.out.println(keys);
Boolean name = redisTemplate.hasKey("name");
Boolean set1 = redisTemplate.hasKey("set1");
for (Object key : keys) {
DataType type = redisTemplate.type(key);
System.out.println(type.name());
}
redisTemplate.delete("mylist");
}
HttpClient
HttpClient作用:
- 在Java程序中发送HTTP请求
- 接收响应数据
HttpClient发送请求步骤:
- 创建HttpClient对象
- 创建Http请求对象
- 调用HttpClient的execute方法发送请求
public static String doGet(String url,Map<String,String> paramMap){
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
String result = "";
CloseableHttpResponse response = null;
try{
URIBuilder builder = new URIBuilder(url);
if(paramMap != null){
for (String key : paramMap.keySet()) {
builder.addParameter(key,paramMap.get(key)); //将传入的参数 `paramMap` 中的每一个键值对转换为 URL 的查询字符串形式
}
}
URI uri = builder.build();
//创建GET请求
HttpGet httpGet = new HttpGet(uri);
//发送请求
response = httpClient.execute(httpGet);
//判断响应状态
if(response.getStatusLine().getStatusCode() == 200){
result = EntityUtils.toString(response.getEntity(),"UTF-8");
}
}catch (Exception e){
e.printStackTrace();
}finally {
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
微信小程序
缓存功能
用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大。
实现思路
通过Redis来缓存菜品数据,减少数据库查询操作。
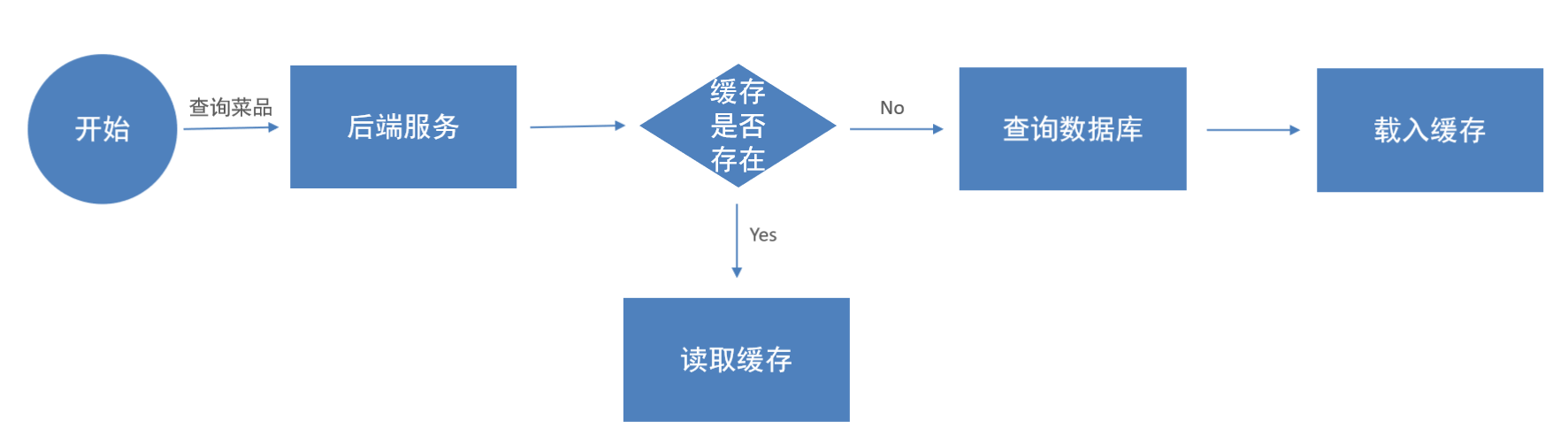
经典缓存实现代码
缓存逻辑分析:
- 每个分类下的菜品保存一份缓存数据
- 数据库中菜品数据有变更时清理缓存数据
@Autowired
private RedisTemplate redisTemplate;
/**
* 根据分类id查询菜品
*
* @param categoryId
* @return
*/
@GetMapping("/list")
@ApiOperation("根据分类id查询菜品")
public Result<List<DishVO>> list(Long categoryId) {
//构造redis中的key,规则:dish_分类id
String key = "dish_" + categoryId;
//查询redis中是否存在菜品数据
List<DishVO> list = (List<DishVO>) redisTemplate.opsForValue().get(key);
if(list != null && list.size() > 0){
//如果存在,直接返回,无须查询数据库
return Result.success(list);
}
////////////////////////////////////////////////////////
Dish dish = new Dish();
dish.setCategoryId(categoryId);
dish.setStatus(StatusConstant.ENABLE);//查询起售中的菜品
//如果不存在,查询数据库,将查询到的数据放入redis中
list = dishService.listWithFlavor(dish);
////////////////////////////////////////////////////////
redisTemplate.opsForValue().set(key, list);
return Result.success(list);
}
为了保证数据库和Redis中的数据保持一致,修改管理端接口 DishController 的相关方法,加入清理缓存逻辑。
需要改造的方法:
- 新增菜品
- 修改菜品
- 批量删除菜品
- 起售、停售菜品
清理缓冲方法:
private void cleanCache(String pattern){
Set keys = redisTemplate.keys(pattern);
redisTemplate.delete(keys);
}
Spring Cache框架实现缓存
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId> <version>2.7.3</version>
</dependency>
在SpringCache中提供了很多缓存操作的注解,常见的是以下的几个:
| 注解 | 说明 |
|---|---|
| @EnableCaching | 开启缓存注解功能,通常加在启动类上 |
| @Cacheable | 在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据(取);如果没有缓存数据,调用方法并将方法返回值放到缓存中 |
| @CachePut | 将方法的返回值放到缓存中 |
| @CacheEvict | 将一条或多条数据从缓存中删除 |
@CachePut 说明:
作用: 将方法返回值,放入缓存
value: 缓存的名称, 每个缓存名称下面可以有很多key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
value 和 cacheNames 属性在用法上是等效的。它们都用来指定缓存区的名称
在Redis中并没有直接的“缓存名”概念,而是通过键(key)来访问数据。Spring Cache通过cacheNames属性来模拟不同的“缓存区”,实际上这是通过将这些名称作为键的一部分来实现的。例如,如果你有一个缓存名为 userCache,那么所有相关的缓存条目的键可能以 "userCache::" 开头。
@PostMapping
@CachePut(value = "userCache", key = "#user.id")//key的生成:userCache::1
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}
**说明:**key的写法如下
#user.id : #user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ;
#result.id : #result代表方法返回值,该表达式 代表以返回对象的id属性作为key ;
@Cacheable 说明:
作用: 在方法执行前,spring先查看缓存中是否有指定的key的数据,如果有数据,则直接返回缓存数据,不执行后续sql操作;若没有数据,调用方法并将方法返回值放到缓存中。
所以,@Cacheable(cacheNames = "userCache",key="#id")中的#id表示的是函数形参中的id,而不能是返回值中的user.id
@GetMapping
@Cacheable(cacheNames = "userCache",key="#id")
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}
@CacheEvict 说明:
作用: 清理指定缓存
@DeleteMapping
@CacheEvict(cacheNames = "userCache",key = "#id")//删除某个key对应的缓存数据
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache",allEntries = true)//删除userCache下所有的缓存数据
public void deleteAll(){
userMapper.deleteAll();
}
微信支付
小程序支付
https://pay.weixin.qq.com/static/product/product_index.shtml
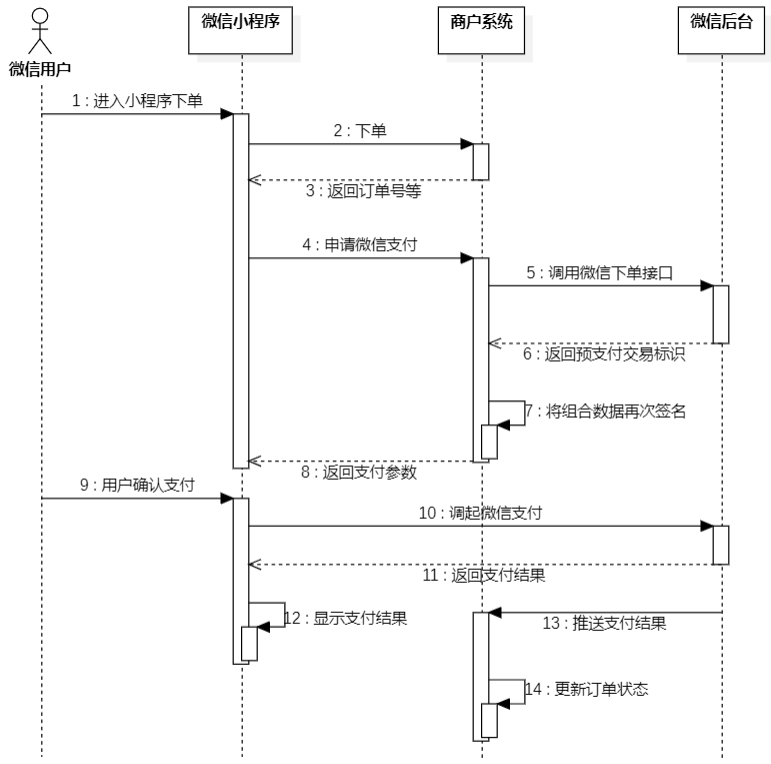
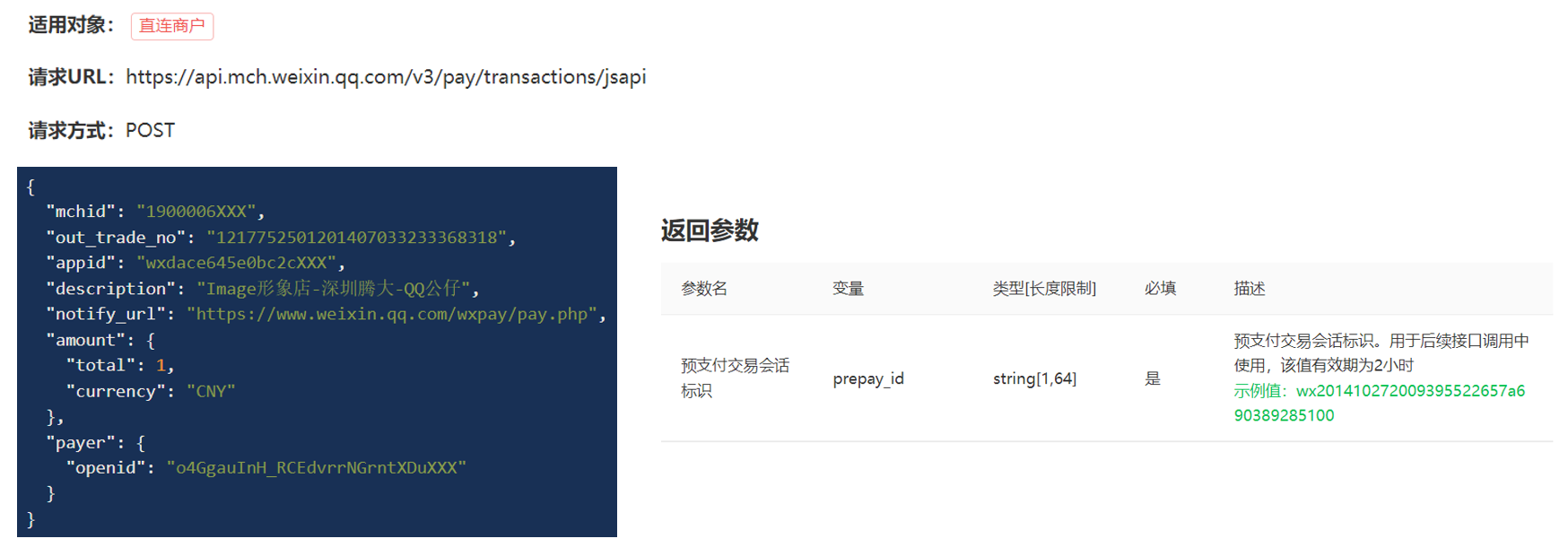
5.商户系统调用微信后台:
10.用户调起微信支付

内网穿透
微信后台会调用到商户系统给推送支付的结果,在这里我们就会遇到一个问题,就是微信后台怎么就能调用到我们这个商户系统呢?因为这个调用过程,其实本质上也是一个HTTP请求。
目前,商户系统它的ip地址就是当前自己电脑的ip地址,只是一个局域网内的ip地址,微信后台无法调用到。
解决:内网穿透。通过cpolar软件可以获得一个临时域名,而这个临时域名是一个公网ip,这样,微信后台就可以请求到商户系统了。
1)下载地址:https://dashboard.cpolar.com/get-started
2). cpolar指定authtoken
复制authtoken:
执行命令:
注意,cd到cpolar.exe所在的目录打开cmd
输入代码:
cpolar.exe authtoken ZmIwMmQzZDYtZDE2ZS00ZGVjLWE2MTUtOGQ0YTdhOWI2M2Q1
3)获取临时域名
cpolar.exe http 8080
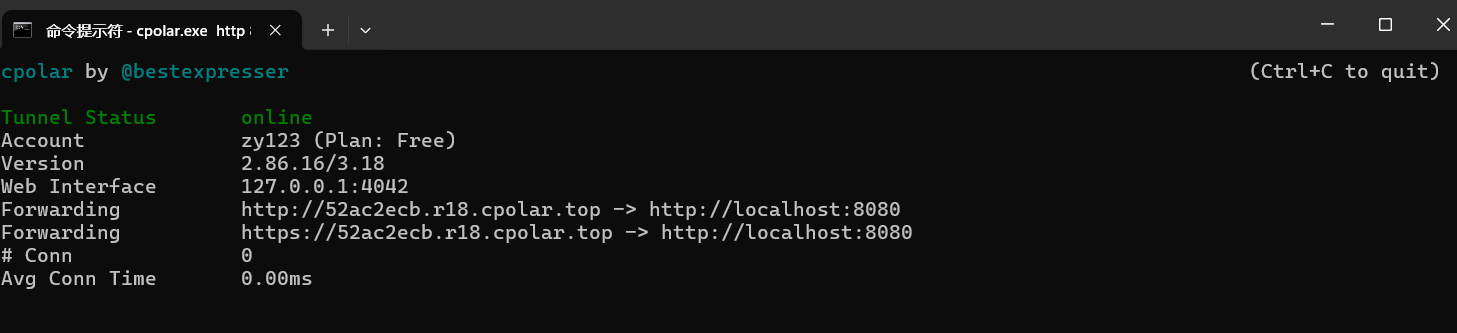
这里的 https://52ac2ecb.r18.cpolar.top 就是与http://localhost:8080对应的临时域名。
Spring Task
Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑。
**定位:**定时任务框架
**作用:**定时自动执行某段Java代码
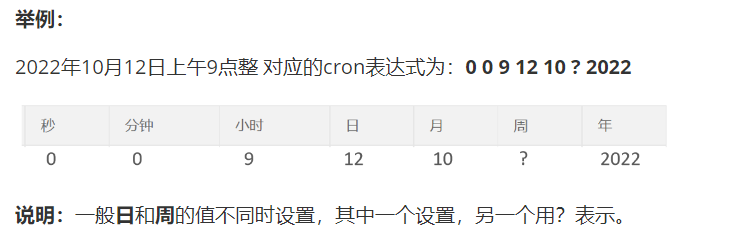
1.2 cron表达式
cron表达式其实就是一个字符串,通过cron表达式可以定义任务触发的时间
**构成规则:**分为6或7个域,由空格分隔开,每个域代表一个含义
每个域的含义分别为:秒、分钟、小时、日、月、周、年(可选)
cron表达式在线生成器:https://cron.qqe2.com/
1.3 入门案例
1.3.1 Spring Task使用步骤
1). 导入maven坐标 spring-context(已存在)
2). 启动类添加注解 @EnableScheduling 开启任务调度
3). 自定义定时任务类
2.订单状态定时处理
2.1 需求分析
用户下单后可能存在的情况:
- 下单后未支付,订单一直处于**“待支付”**状态
- 用户收货后管理端未点击完成按钮,订单一直处于**“派送中”**状态
对于上面两种情况需要通过定时任务来修改订单状态,具体逻辑为:
- 通过定时任务每分钟检查一次是否存在支付超时订单(下单后超过15分钟仍未支付则判定为支付超时订单),如果存在则修改订单状态为“已取消”
- 通过定时任务每天凌晨1点(打烊后)检查一次是否存在“派送中”的订单,如果存在则修改订单状态为“已完成”
@Component
@Slf4j
public class OrderTask {
/**
* 处理下单之后未15分组内支付的超时订单
*/
@Autowired
private OrderMapper orderMapper;
@Scheduled(cron = "0 * * * * ? ")
public void processTimeoutOrder(){
log.info("定时处理支付超时订单:{}", LocalDateTime.now());
LocalDateTime time = LocalDateTime.now().plusMinutes(-15);
// select * from orders where status = 1 and order_time < 当前时间-15分钟
List<Orders> ordersList = orderMapper.getByStatusAndOrdertimeLT(Orders.PENDING_PAYMENT, time);
if(ordersList != null && ordersList.size() > 0){
ordersList.forEach(order -> {
order.setStatus(Orders.CANCELLED);
order.setCancelReason("支付超时,自动取消");
order.setCancelTime(LocalDateTime.now());
orderMapper.update(order);
});
}
}
@Scheduled(cron = "0 0 1 * * ?")
public void processDeliveryOrder() {
log.info("处理派送中订单:{}", new Date());
// select * from orders where status = 4 and order_time < 当前时间-1小时
LocalDateTime time = LocalDateTime.now().plusMinutes(-60);
List<Orders> ordersList = orderMapper.getByStatusAndOrdertimeLT(Orders.DELIVERY_IN_PROGRESS, time);
if (ordersList != null && ordersList.size() > 0) {
ordersList.forEach(order -> {
order.setStatus(Orders.COMPLETED);
orderMapper.update(order);
});
}
}
}
Websocket
WebSocket 是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接, 并进行双向数据传输。
HTTP协议和WebSocket协议对比:
- HTTP是短连接
- WebSocket是长连接
- HTTP通信是单向的,基于请求响应模式
- WebSocket支持双向通信
- HTTP和WebSocket底层都是TCP连接
入门案例
实现步骤:
1). 直接使用websocket.html页面作为WebSocket客户端
2). 导入WebSocket的maven坐标
3). 导入WebSocket服务端组件WebSocketServer,用于和客户端通信(比较固定,建立连接、接收消息、关闭连接、发送消息)
4). 导入配置类WebSocketConfiguration,注册WebSocket的服务端组件
它通过Spring的 ServerEndpointExporter 将使用 @ServerEndpoint 注解的类自动注册为WebSocket端点。这样,当应用程序启动时,所有带有 @ServerEndpoint 注解的类就会被Spring容器自动扫描并注册为WebSocket服务器端点,使得它们能够接受和处理WebSocket连接。
5). 导入定时任务类WebSocketTask,定时向客户端推送数据
来单提醒
设计思路:
- 通过WebSocket实现管理端页面和服务端保持长连接状态
- 当客户支付后,调用WebSocket的相关API实现服务端向客户端推送消息
- 客户端浏览器解析服务端推送的消息,判断是来单提醒还是客户催单,进行相应的消息提示和语音播报
- 约定服务端发送给客户端浏览器的数据格式为JSON,字段包括:type,orderId,content
- type 为消息类型,1为来单提醒 2为客户催单
- orderId 为订单id
- content 为消息内容