78 KiB
JavaWeb——后端
Java版本解决方案
单个Py文件运行:Edit Configurations
- 针对单个运行配置:每个 Java 运行配置(如主类、测试类等)可以独立设置其运行环境(如 JRE 版本、程序参数、环境变量等)。
- 不影响全局项目:修改某个运行配置的环境不会影响其他运行配置或项目的全局设置。
如何调整全局项目的环境
- 打开
File -> Project Structure -> Project。 - 在
Project SDK中选择全局的 JDK 版本(如 JDK 17)。 - 在
Project language level中设置全局的语言级别(如 17)。
Java Compiler
File -> Settings -> Build, Execution, Deployment -> Compiler -> Java Compiler
Maven Runner
File -> Settings -> Build, Execution, Deployment -> Build Tools -> Maven -> Runner
. 三者之间的关系
- 全局项目环境 是基准,决定项目的默认 JDK 和语言级别。
- Java Compiler 控制编译行为,可以覆盖全局的
Project language level。 - Maven Runner 控制 Maven 命令的运行环境,可以覆盖全局的
Project SDK。
Maven 项目:
- 确保
pom.xml中的<maven.compiler.source>和<maven.compiler.target>与Project SDK和Java Compiler的配置一致。 - 确保
Maven Runner中的JRE与Project SDK一致。 - 如果还是不行,pom文件右键点击maven->reload project
Maven
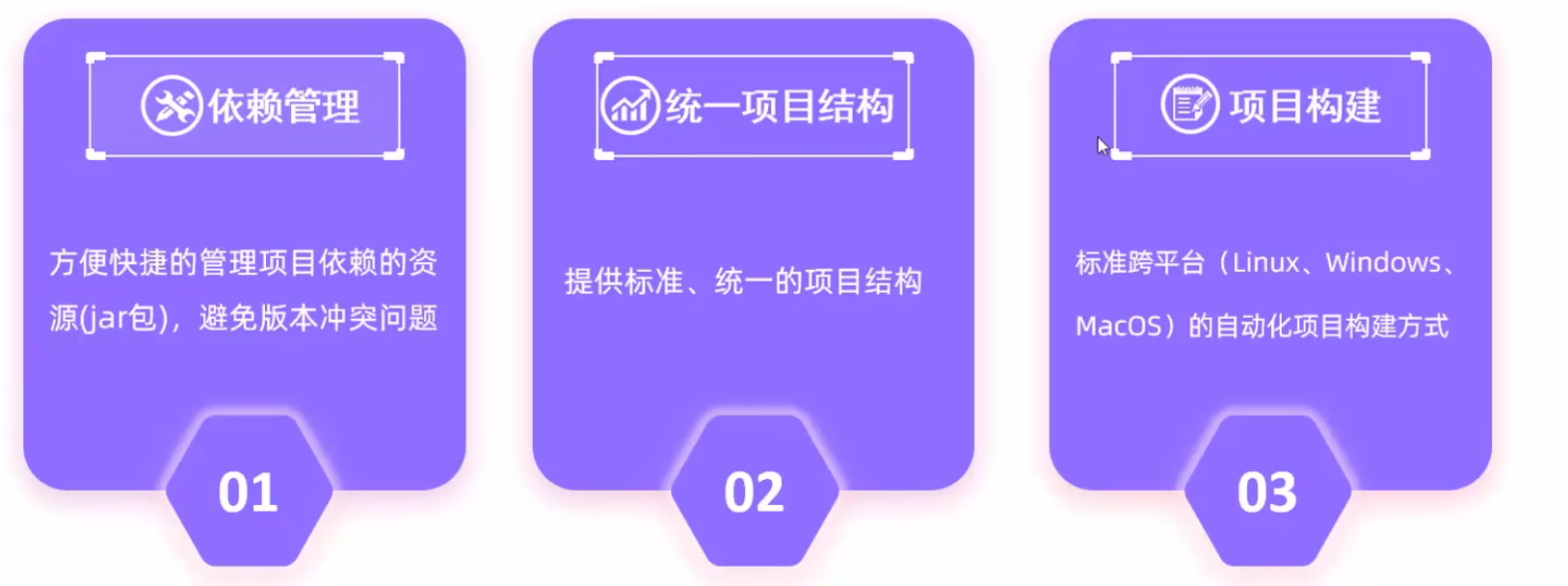
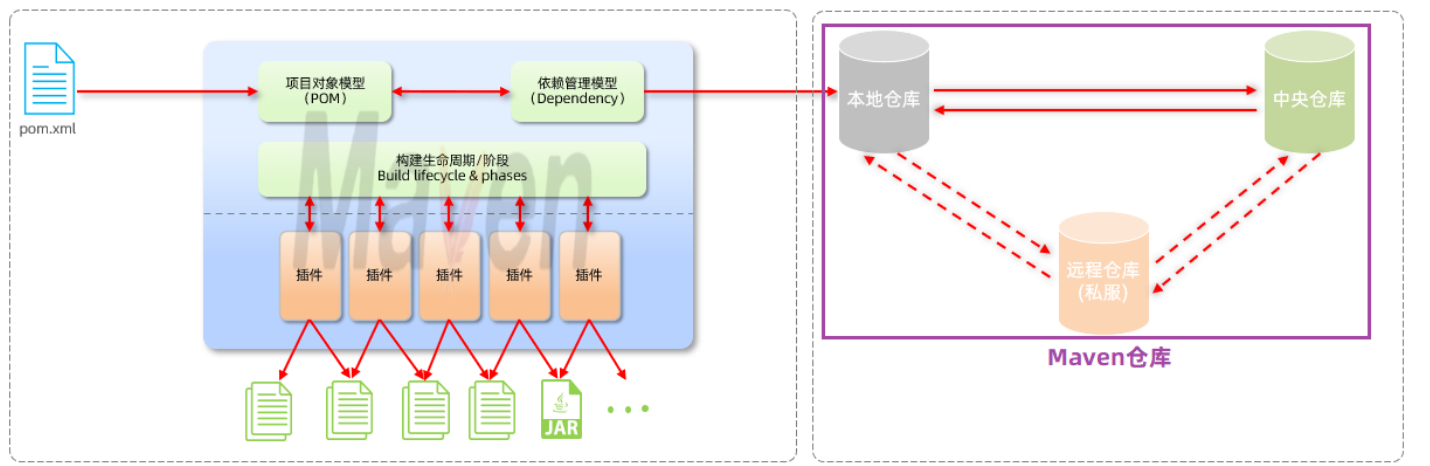
Maven仓库分为:
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
- 远程仓库(私服):一般由公司团队搭建的私有仓库
POM文件导入依赖的时候,先看本地仓库有没有,没有就看私服,再没有就从中央仓库下载。
Maven创建/导入项目
创建Maven项目

勾选 Create from archetype(可选),也可以选择 maven-archetype-quickstart 等模版。
点击 Next,填写 GAV 坐标 。
GroupId:标识组织或公司(通常使用域名反写,如 com.example)
ArtifactId:标识具体项目或模块(如 my-app、spring-boot-starter-web)。
Version:标识版本号(如 1.0-SNAPSHOT、2.7.3)
导入Maven项目
(一)单独的Maven项目
打开 IDEA,在主界面选择 Open(或者在菜单栏选择 File -> Open)。
在文件选择对话框中,定位到已有项目的根目录(包含 pom.xml 的目录)。
选择该目录后,IDEA 会检测到 pom.xml 并询问是否导入为 Maven 项目,点击 OK 或 Import 即可。
IDEA 会自动解析 pom.xml,下载依赖并构建项目结构。
(二)在现有Maven项目中导入独立的Maven项目
在已经打开的 IDEA 窗口中,使用 File -> New -> Module from Existing Sources...
选择待导入项目的根目录(其中包含 pom.xml),IDEA 会将其导入为同一个工程下的另一个模块(Module)。
(三)两个模块有较强的关联
1.新建一个上层目录,如下,MyProject1和MyProject2的内容拷贝过去。
ParentProject/
├── pom.xml <-- 父模块(聚合模块)
├── MyProject1/ <-- 子模块1
│ └── pom.xml
└── MyProject2/ <-- 子模块2
└── pom.xml
2.创建父级pom
父模块 pom.xml 示例:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>ParentProject</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging> //必写
<modules>
<module>MyProject1</module> //必写
<module>MyProject2</module>
</modules>
</project>
3.修改子模块 pom.xml ,加上:
<parent>
<groupId>com.example</groupId>
<artifactId>ParentProject</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath> <!-- 可省略 -->
</parent>
如果子模块中无需与父级不同的配置,可以不写,就自动继承父级配置;若写了同名配置,则表示你想要覆盖或合并父级配置。
4.File -> Open选择父级的pom,会自动导入其下面两个项目。
(四)通过 Maven 依赖引用(一般导入官方依赖)
如果你的两个项目之间存在依赖关系(例如,第二个项目需要引用第一个项目打包后的 JAR),可以采用以下方式:
在第一个项目(被依赖项目)执行 mvn install
- 这会把打包后的产物安装到本地仓库(默认
~/.m2/repository)。
在第二个项目的 pom.xml 中添加依赖坐标
<dependency>
<groupId>com.example</groupId>
<artifactId>my-first-project</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
Maven 重建
Maven坐标
什么是坐标?
- Maven中的坐标是==资源的唯一标识== , 通过该坐标可以唯一定位资源位置
- 使用坐标来定义项目或引入项目中需要的依赖
依赖管理
可以到mvn的中央仓库(https://mvnrepository.com/)中搜索获取依赖的坐标信息
<dependencies>
<!-- 第1个依赖 : logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.11</version>
</dependency>
<!-- 第2个依赖 : junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
更改之后可以在界面上看到一个maven刷新按钮,点击一下就开始联网下载依赖了,成功后可以看到
排除依赖
A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被排除的资源无需指定版本。
<dependency>
<groupId>com.itheima</groupId>
<artifactId>maven-projectB</artifactId>
<version>1.0-SNAPSHOT</version>
<!--排除依赖, 主动断开依赖的资源-->
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>
依赖范围
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
注意!!!这里的scope如果是test,那么它的作用范围在src/test/java下,在src/main/java下无法导包!
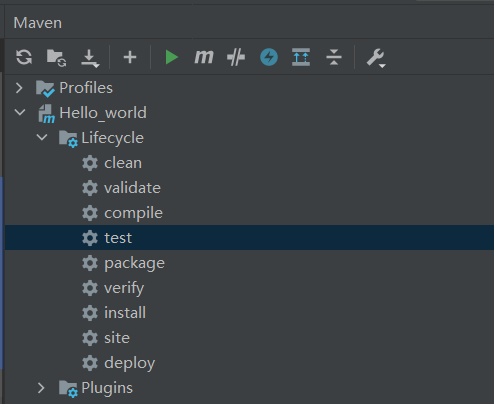
Maven生命周期
主要关注以下几个:
• clean:移除上一次构建生成的文件 (Target文件夹)
• compile:编译 src/main/java 中的 Java 源文件至 target/classes
• test:使用合适的单元测试框架运行测试(junit)
• package:将编译后的文件打包,如:jar、war等
• install:将打包后的产物(如 jar)安装到本地仓库
单元测试
-
导入依赖junit
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> -
在src/test/java下创建DemoTest类(*Test)
-
创建test方法
@Test public void test1(){ System.out.println("hello1"); } @Test public void test2(){ System.out.println("hello2"); } -
双击test生命周期
HTTP协议
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 --- 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| ==200== | OK |
客户端请求成功,即处理成功,这是我们最想看到的状态码 |
| 302 | Found |
指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified |
告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 |
| 400 | Bad Request |
客户端请求有语法错误,不能被服务器所理解 |
| 403 | Forbidden |
服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 |
| ==404== | Not Found |
请求资源不存在,一般是URL输入有误,或者网站资源被删除了 |
| 405 | Method Not Allowed |
请求方式有误,比如应该用GET请求方式的资源,用了POST |
| 429 | Too Many Requests |
指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 |
| ==500== | Internal Server Error |
服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 |
| 503 | Service Unavailable |
服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 |
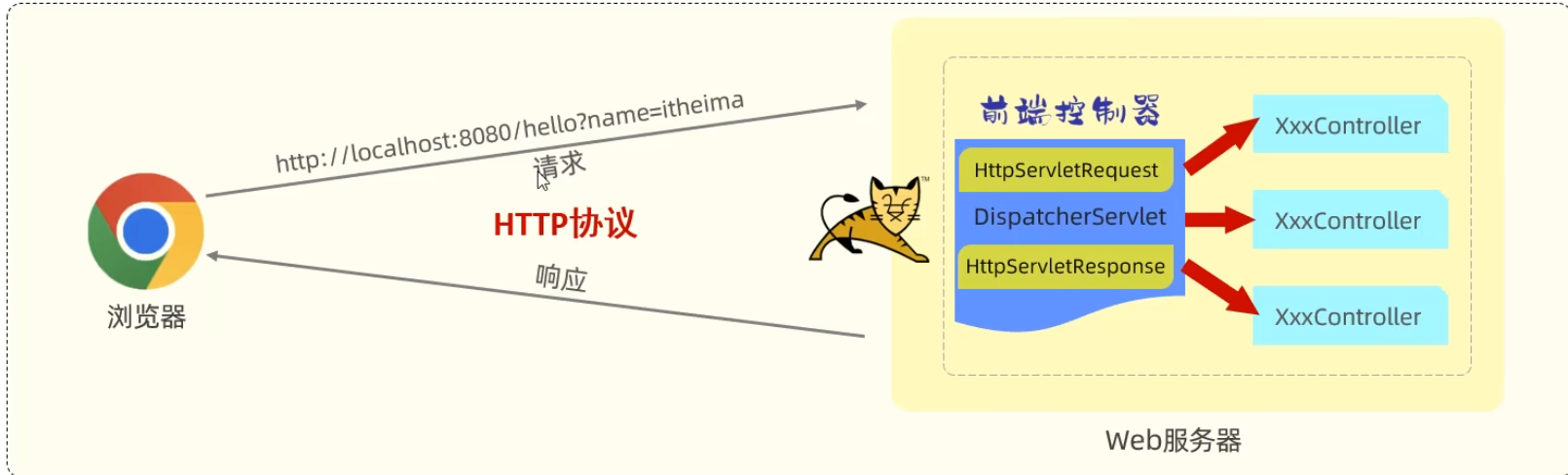
SpringBoot
SpringBoot的WEB默认内嵌了tomcat服务器,非常方便!!!
浏览器与 Tomcat 之间通过 HTTP 协议进行通信,而 Tomcat 则充当了中间的桥梁,将请求路由到你的 Java 代码,并最终将处理结果返回给浏览器。
快速启动
- 新建spring initializr module
- 删除以下文件
新建HelloController类
package edu.whut.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String hello(){
System.out.println("hello");
return "hello";
}
}
然后启动服务器,main程序
package edu.whut;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SprintbootQuickstartApplication {
public static void main(String[] args) {
SpringApplication.run(SprintbootQuickstartApplication.class, args);
}
}
然后浏览器访问 localhost:8080/hello。
SpringBoot请求
简单参数
- 在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=10
// 第1个请求参数: name=Tom 参数名:name,参数值:Tom
// 第2个请求参数: age=10 参数名:age , 参数值:10
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致
System.out.println(name+" : "+age);
return "OK";
}
}
- 如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗?
解决方案:可以使用Spring提供的@RequestParam注解完成映射
在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下:
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=20
// 请求参数名:name
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam("name") String username , Integer age ){
System.out.println(username+" : "+age);
return "OK";
}
}
实体参数
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
- User类中有一个Address类型的属性(Address是一个实体类)
复杂实体对象的封装,需要遵守如下规则:
- 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。

@RequestMapping("/complexpojo")
public String complexpojo(User user){
System.out.println(user);
return "OK";
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
private Address address;
}
package edu.whut.pojo;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Address {
private String province;
private String city;
}
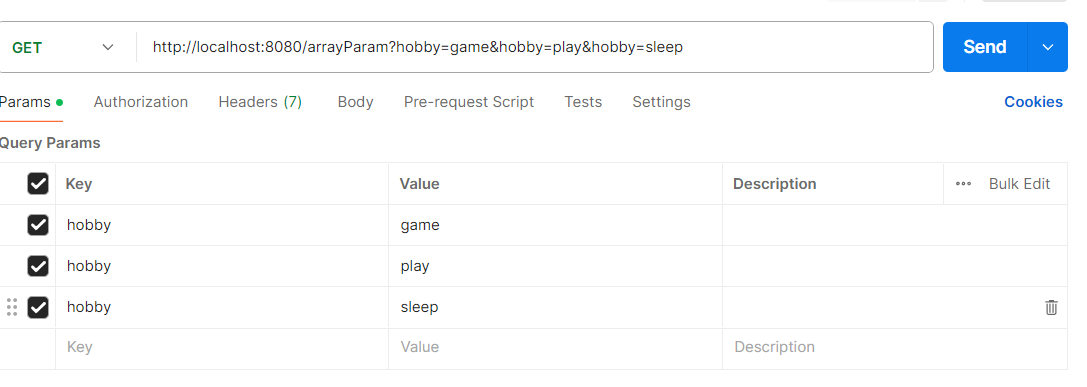
数组参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
@RestController
public class RequestController {
//数组集合参数
@RequestMapping("/arrayParam")
public String arrayParam(String[] hobby){
System.out.println(Arrays.toString(hobby));
return "OK";
}
}
JSON格式参数
json数组:
{
"退还时间点": [
"与中标人签订合同后 5日内",
"投标截止时间前撤回投标文件并书面通知招标人的,2日内",
"开标现场投标文件被拒收,开标结束后,2日内",
"招标项目评标结果公示后,2日内退还未进入中标候选人排名的投标人",
"招标失败需重新组织招标或不再招标的,评标结束后,2日内",
"招标人与中标人签订书面合同并报市公共资源交易监督管理局备案后,2日内退还中标人及未中标候选人的"
],
"employees": [
{ "firstName": "John", "lastName": "Doe" },
{ "firstName": "Anna", "lastName": "Smith" },
{ "firstName": "Peter", "lastName": "Jones" }
]
}
JSON 格式的核心特征
- 数据为键值对:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如
"firstName": "John"。 - 使用大括号表示对象:JSON 使用大括号
{}包围对象,对象可以包含多个键值对。 - 使用方括号表示数组:JSON 使用方括号
[]表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在你的示例中,"employees"是一个数组,数组中的每个元素都是一个对象。
我们学习JSON格式参数,主要从以下两个方面着手:
- Postman在发送请求时,如何传递json格式的请求参数
- 在服务端的controller方法中,如何接收json格式的请求参数
Postman发送JSON格式数据:
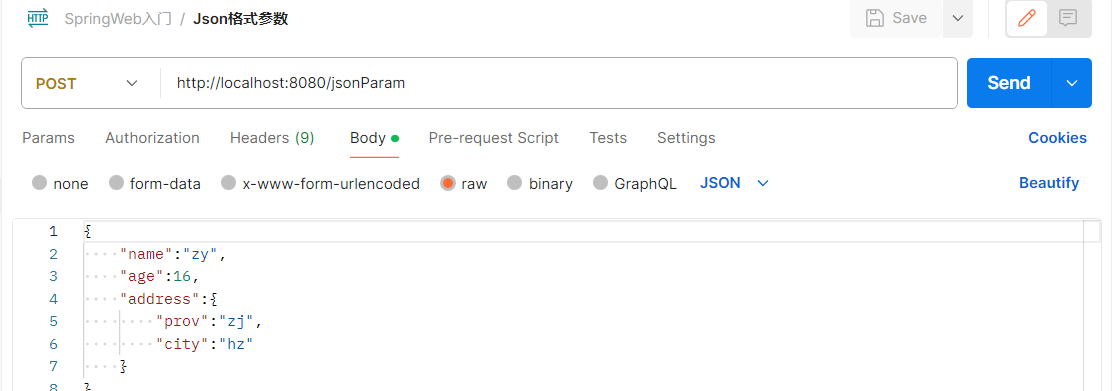
服务端Controller方法接收JSON格式数据:
- 传递json格式的参数,在Controller中会使用实体类进行封装。
- 封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
@RestController
public class RequestController {
//JSON参数
@RequestMapping("/jsonParam")
public String jsonParam(@RequestBody User user){
System.out.println(user);
return "OK";
}
}
JSON格式工具包
//把Result对象转换为JSON格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类) String json = JSONObject.toJSONString(responseResult);
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
http://localhost:8080/user/1
http://localhost:880/user/1/0
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
@RestController
public class RequestController {
//路径参数
@RequestMapping("/path/{id}/{name}")
public String pathParam2(@PathVariable Integer id, @PathVariable String name){
System.out.println(id+ " : " +name);
return "OK";
}
}
SpringBoot响应
@ResponseBody注解:
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
@RestController = @Controller + @ResponseBody
统一响应结果:
下图返回值分别是字符串、对象、集合。

统一的返回结果使用类来描述,在这个结果中包含:
-
响应状态码:当前请求是成功,还是失败
-
状态码信息:给页面的提示信息
-
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息。代码如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Integer code;//响应码,1 代表成功; 0 代表失败
private String msg; //响应信息 描述字符串
private Object data; //返回的数据
//增删改 成功响应
public static Result success(){
return new Result(1,"success",null);
}
//查询 成功响应
public static Result success(Object data){
return new Result(1,"success",data);
}
//失败响应
public static Result error(String msg){
return new Result(0,msg,null);
}
}
Spring分层架构
三层架构
Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程
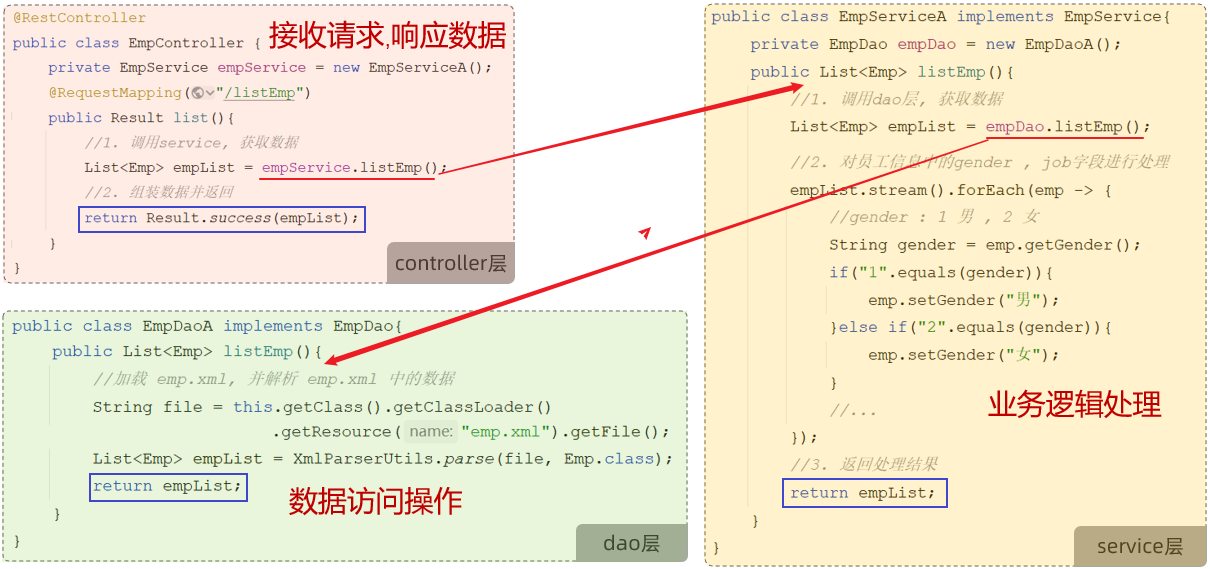
但是,这样每次要更换ServiceA->ServiceB时,需要修改Controller层的代码!
private EmpService empService=new EmpServiceA(); //原来
private EmpService empService=new EmpServiceB(); //现在
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
IOC&DI 分层解耦
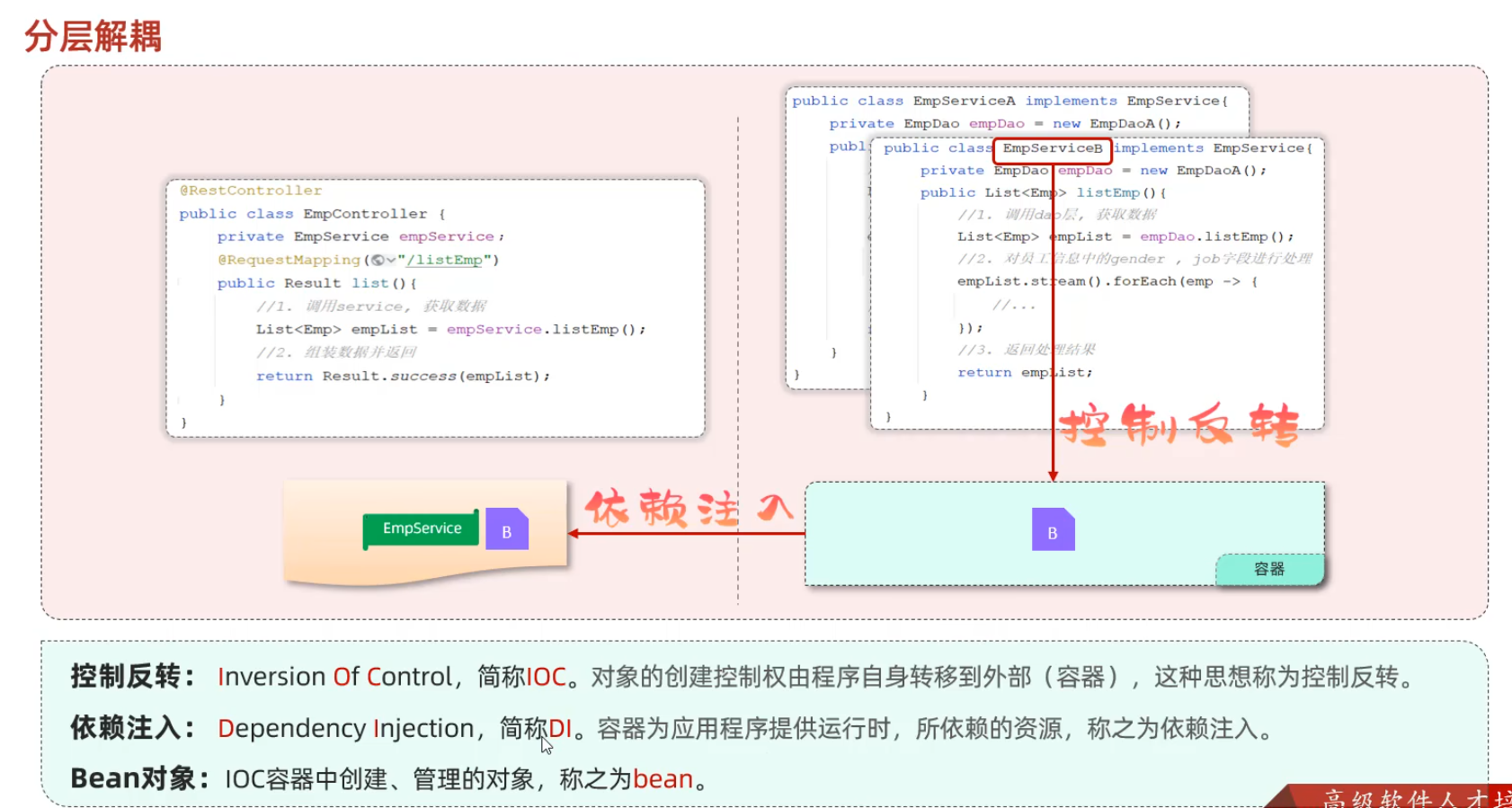
任务:完成Controller层、Service层、Dao层的代码解耦
- 思路:
- 删除Controller层、Service层中new对象的代码
- Service层及Dao层的实现类,交给IOC容器管理
- 为Controller及Service注入运行时依赖的对象
- Controller程序中注入依赖的Service层对象
- Service程序中注入依赖的Dao层对象
第1步:删除Controller层、Service层中new对象的代码

第2步:Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
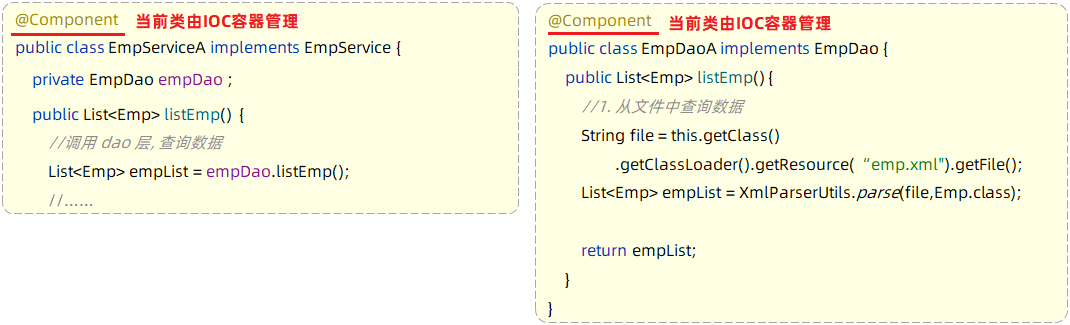
第3步:为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象

**如果我有多个实现类,eg:EmpServiceA、EmpServiceB、EmpServiceC,我该如何切换呢?**两种方法
- 只需在需要使用的实现类上加@Component,注释掉不需要用到的类上的@Component。可以把@Component想象成装入盒子,@Autowired想象成拿出来,因此只需改变放入的物品,而不需改变拿出来的这个动作。
- 在@Component上面加上@Primary,表明该类优先生效
Component衍生注解
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上Controller |
| @Service | @Component的衍生注解 | 标注在业务类上Service |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少)DAO |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
常见的注解!!
-
@RequestMapping("/jsonParam"):这是一个控制器方法级别的注解,用于将HTTP请求映射到相应的处理方法上。在这个例子中,它表示当收到路径为 "/jsonParam" 的HTTP请求时,应该调用这个方法来处理请求。@RequestMapping注解可以用来指定路径、HTTP方法、请求参数等信息,以便Spring框架能够正确地将请求分发到对应的处理方法上。@RequestMapping("/jsonParam") public String jsonParam(@RequestBody User user){ System.out.println(user); return "OK"; } -
@RestController:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与@Controller注解相比,@RestController注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于**@ResponseBody** 。因此,@RestController注解通常用于编写 RESTful Web 服务。@RestController = @Controller + @ResponseBody -
@RequestBody:这是一个方法参数级别的注解,用于告诉Spring框架将请求体的内容解析为指定的Java对象。在这个例子中,@RequestBody注解告诉Spring框架将HTTP请求的主体(即请求体)中的JSON数据解析为一个User对象,并传递给方法的参数user。这样,在方法体内就可以直接使用这个User对象来处理请求中的数据了。 -
@PathVariable注解用于将路径变量{id}的值绑定到方法的参数id上。当请求的路径是 "/path/123" 时,@PathVariable会将路径中的 "123" 值绑定到方法的参数id上,使得方法能够获取到这个值。在这个例子中,方法的参数id的值将会是整数值 123。public String pathParam(@PathVariable Integer id) { System.out.println(id); return "OK"; } 参数名与路径名不同 @GetMapping("/{id}") public ResponseEntity<User> getUserById(@PathVariable("id") Long userId) { } -
@RequestParam,如果方法的参数名与请求参数名不同,需要在@RequestParam注解中指定请求参数的名字。@RequestParam(defaultValue = "1" Integer page) //若page为null,可以设置page的默认值为1@RequestMapping("/example") public String exampleMethod(@RequestParam String name, @RequestParam("age") int userAge) { // 在方法内部使用获取到的参数值进行处理 System.out.println("Name: " + name); System.out.println("Age: " + userAge); return "OK"; } -
控制反转与依赖注入:
@Component ,控制反转
@Autowired,依赖注入
-
数据库相关。@Mapper注解:表示是mybatis中的Mapper接口
- 程序运行时:框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
-
@SpringBootTest:它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等。
-
lombok的相关注解。非常实用的工具库。
注解 作用 @Getter/@Setter 为所有的属性提供get/set方法 @ToString 会给类自动生成易阅读的 toString 方法 @EqualsAndHashCode 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 @Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) @NoArgsConstructor 为实体类生成无参的构造器方法 @AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 @Slf4j 可以log.info("输出日志信息"); //equals 方法用于比较两个对象的内容是否相同 Address addr1 = new Address("SomeProvince", "SomeCity"); Address addr2 = new Address("SomeProvince", "SomeCity"); System.out.println(addr1.equals(addr2)); // 输出 true -
@Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法
-
@Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用
@Override注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。 -
@DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin,
将日期转化为指定的格式。Spring会尝试将接收到的字符串参数转换为控制器方法参数的相应类型。
- @RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端
- @Configuration和@Bean配合使用,可以对第三方bean进行集中的配置管理,依赖注入!!@Bean用于方法上
加了@Configuration,当Spring Boot应用启动时,它会执行一系列的自动配置步骤。
@ComponentScan指定了Spring应该在哪些包下搜索带有@Component、@Service、@Repository、@Controller等注解的类,以便将这些类自动注册为Spring容器管理的Bean.@SpringBootApplication它是一个便利的注解,组合了@Configuration、@EnableAutoConfiguration和@ComponentScan注解。
开发规范
REST风格
在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
什么是REST风格呢?
- REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
传统URL风格如下:
http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
http://localhost:8080/user/saveUser POST:新增用户
http://localhost:8080/user/updateUser PUT:修改用户
http://localhost:8080/user/deleteUser?id=1 GET:删除id为1的用户
我们看到,原始的传统URL呢,定义比较复杂,而且将资源的访问行为对外暴露出来了。
基于REST风格URL如下:
http://localhost:8080/users/1 GET:查询id为1的用户
http://localhost:8080/users POST:新增用户
http://localhost:8080/users PUT:修改用户
http://localhost:8080/users/1 DELETE:删除id为1的用户
其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
在JAVA代码中如何区别不同的请求方式?
传统的是@RequestMapping("/depts"),现在:
@GetMapping("/depts") =>GET请求
@PostMapping("/depts") =》POST
@PutMapping("/depts") =>PUT
@DeleteMapping("/depts") =>DELETE
开发流程
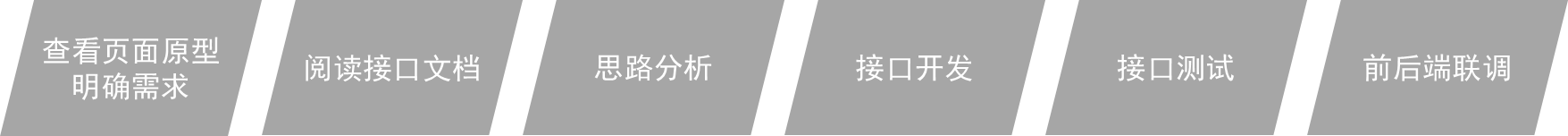
-
查看页面原型明确需求
- 根据页面原型和需求,进行表结构设计、编写接口文档(已提供)
-
阅读接口文档
-
思路分析
-
功能接口开发
- 就是开发后台的业务功能,一个业务功能,我们称为一个接口
-
功能接口测试
- 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试
-
前后端联调测试
- 和前端开发人员开发好的前端工程一起测试
Mybatis
快速创建
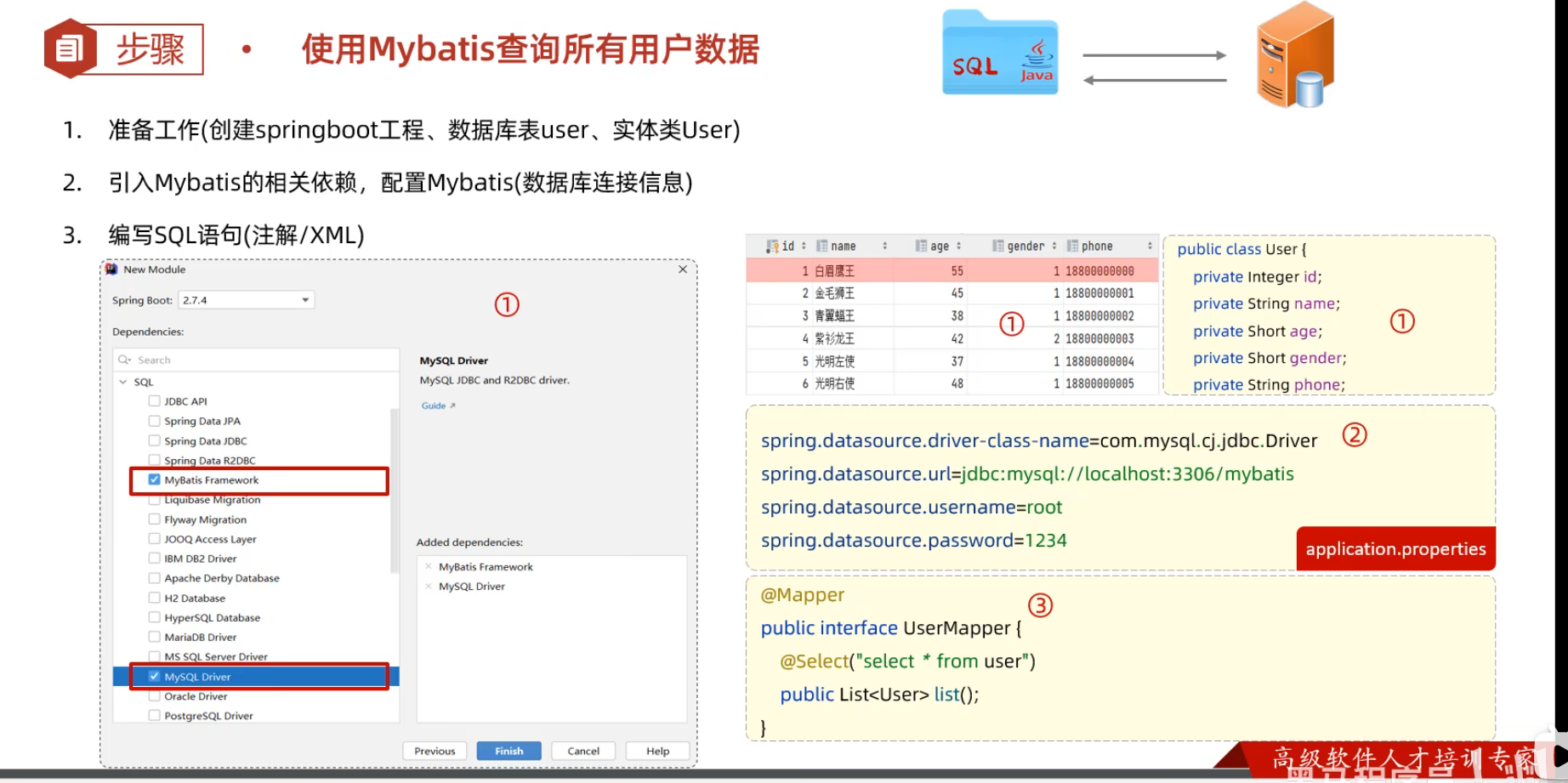
- 创建springboot工程,并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User
- 在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=1234
- 在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper
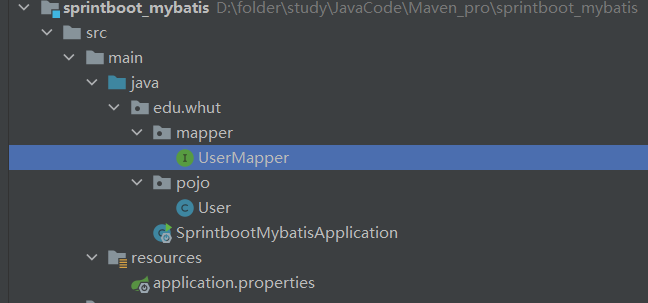
@Mapper注解:表示是mybatis中的Mapper接口
- 程序运行时:框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
@Mapper
public interface UserMapper {
//查询所有用户数据
@Select("select * from user")
public List<User> list();
}
数据库连接池
数据库连接池是个容器,负责分配、管理数据库连接(Connection)
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
-
客户端在执行SQL时,先从连接池中获取一个Connection对象,然后在执行SQL语句,SQL语句执行完之后,释放Connection时就会把Connection对象归还给连接池(Connection对象可以复用)
-
客户端获取到Connection对象了,但是Connection对象并没有去访问数据库(处于空闲),数据库连接池发现Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动释放掉这个连接对象
lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码。
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
使用
import lombok.Data;
@Data
public class User {
private Integer id;
private String name;
private Short age;
private Short gender;
private String phone;
}
日志输出
在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果。
-
打开application.properties文件
-
开启mybatis的日志,并指定输出到控制台
#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
增删改
- 增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void!
- #{} 表示占位符,执行SQL时,生成预编译SQL,会自动设置参数值
- ${} 也是占位符,但直接将参数拼接在SQL语句中,存在SQL注入问题
作用于单个字段
@Mapper
public interface EmpMapper {
//SQL语句中的id值不能写成固定数值,需要变为动态的数值
//解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
/**
* 根据id删除数据
* @param id 用户id
*/
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
public void delete(Integer id);
}

上图参数值分离,有效防止SQL注入
作用于多个字段
@Mapper
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}
说明:#{...} 里面写的名称是对象的属性名!,函数内的参数是Emp对象
useGeneratedKeys = true表示获取返回的主键值,keyProperty = "id"表示主键值存在Emp对象的id属性中,添加这句可以直接获取主键值
查/驼峰命名法
表中查询的数据封装到实体类中
- 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。

解决方法:
- 起别名
- 结果映射
- 开启驼峰命名
- 属性名和表中字段名保持一致
开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
驼峰命名规则: abc_xyz => abcXyz
- 表中字段名:abc_xyz
- 类中属性名:abcXyz
# 在application.properties中添加:
mybatis.configuration.map-underscore-to-camel-case=true
要使用驼峰命名前提是 实体类的属性 与 数据库表中的字段名严格遵守驼峰命名。
eg:通过页面原型以及需求描述我们要实现的查询:
- 姓名:要求支持模糊匹配
- 性别:要求精确匹配
- 入职时间:要求进行范围查询
- 根据最后修改时间进行降序排序
重点在于模糊查询时where name like '%#{name}%' 会报错。
解决方案:
@Mapper
public interface EmpMapper {
@Select("select * from emp " +
"where name like concat('%',#{name},'%') " +
"and gender = #{gender} " +
"and entrydate between #{begin} and #{end} " +
"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
}
使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%')
XML配置文件规范
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
-
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
-
XML映射文件的namespace属性为Mapper接口全限定名一致
-
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
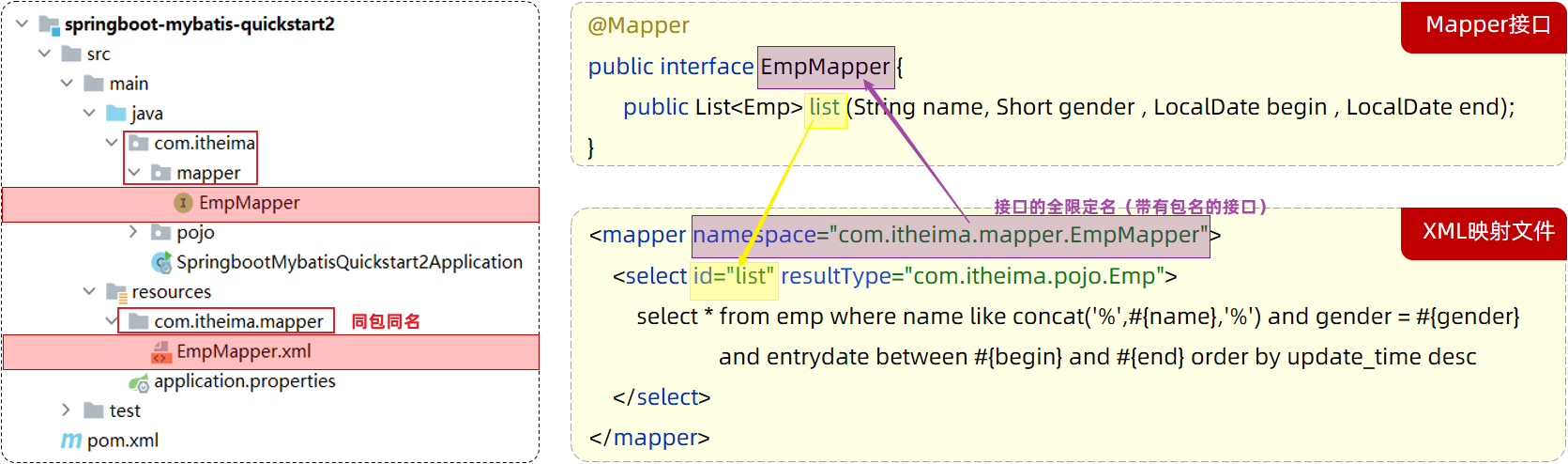
<select>标签:就是用于编写select查询语句的。
- resultType属性,指的是查询返回的单条记录所封装的类型。
实现过程:
-
resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
-
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="edu.whut.mapper.EmpMapper"> </mapper> ```text XML映射文件的namespace属性为Mapper接口**全限定名**(包+类名) -
<select id="list" resultType="edu.whut.pojo.Emp"> select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end} order by update_time desc </select>XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致(也是全限定名!!).里面的查询语句与之前的一模一样,仅仅单独写到一个xml文件中罢了。
**注意:**返回类型指的是单挑记录的类型,是Emp,不是list
这里有bug!!!concat('%',#{name},'%')这里应该用 标签对name是否为''或null进行判断
''和null虽然在某些上下文中可能看起来相似,但它们代表了不同的概念:一个是具有明确的(虽然是空的)值,另一个是完全没有值。
动态SQL
SQL-if,where
<if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
<if test="条件表达式">
要拼接的sql语句
</if>
<where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,加了总比不加好
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
<where>
<!-- if做为where标签的子元素 -->
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
SQL-foreach
mapper接口:
@Mapper
public interface EmpMapper {
//批量删除
public void deleteByIds(List<Integer> ids);
}
xml:
语法:
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
</foreach>
<delete id="deleteByIds">
delete from emp where id in
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
案例实战
分页查询
传统员工分页查询分析:

采用分页插件PageHelper:
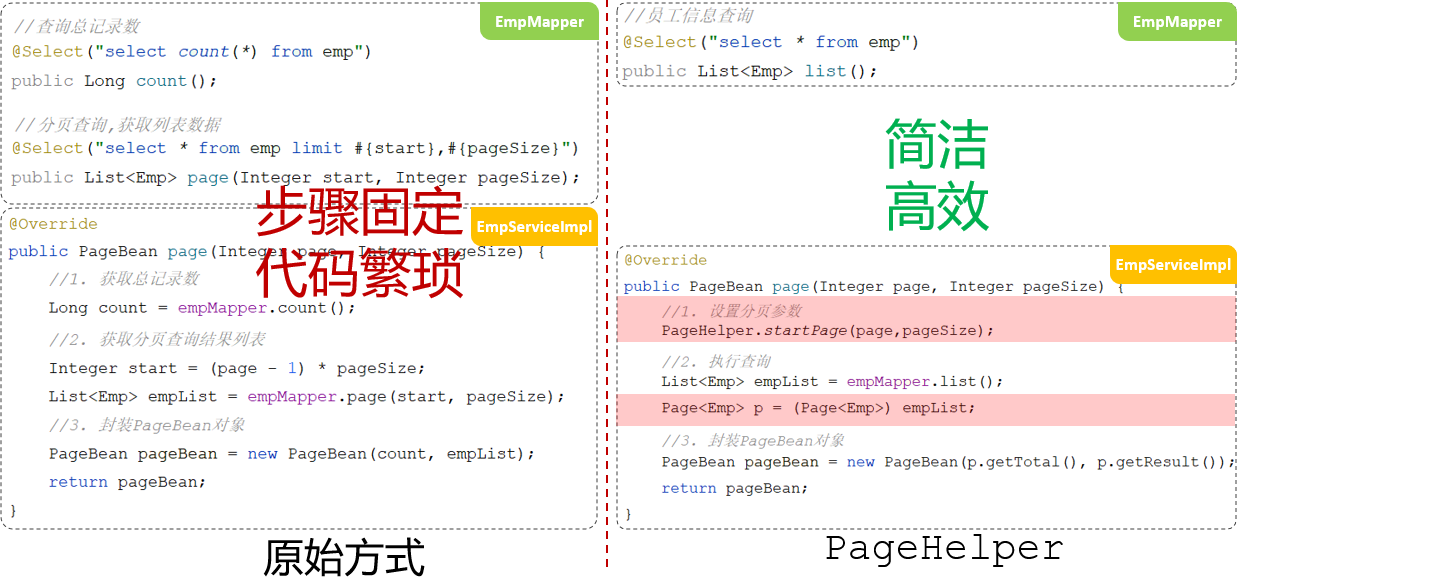
在执行empMapper.list()方法时,就是执行:select * from emp 语句,怎么能够实现分页操作呢?
分页插件帮我们完成了以下操作:
- 先获取到要执行的SQL语句:select * from emp
- 把SQL语句中的字段列表,变为:count(*)
- 执行SQL语句:select count(*) from emp //获取到总记录数
- 再对要执行的SQL语句:select * from emp 进行改造,在末尾添加 limit ? , ?
- 执行改造后的SQL语句:select * from emp limit ? , ?
使用方法:
当使用了PageHelper分页插件进行分页,就无需再Mapper中进行手动分页了。 在Mapper中我们只需要进行正常的列表查询即可。在Service层中,调用Mapper的方法之前设置分页参数,在调用Mapper方法执行查询之后,解析分页结果,并将结果封装到PageBean对象中返回。
1、在pom.xml引入依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.2</version>
</dependency>
2、EmpMapper
@Mapper
public interface EmpMapper {
//获取当前页的结果列表
@Select("select * from emp")
public List<Emp> list();
}
3、EmpServiceImpl
@Override
public PageBean page(Integer page, Integer pageSize) {
// 设置分页参数
PageHelper.startPage(page, pageSize); //page是页号,不是起始索引
// 执行分页查询
List<Emp> empList = empMapper.list();
// 获取分页结果
Page<Emp> p = (Page<Emp>) empList;
//封装PageBean
PageBean pageBean = new PageBean(p.getTotal(), p.getResult());
return pageBean;
}
4、Controller
@Slf4j
@RestController
@RequestMapping("/emps")
public class EmpController {
@Autowired
private EmpService empService;
//条件分页查询
@GetMapping
public Result page(@RequestParam(defaultValue = "1") Integer page,
@RequestParam(defaultValue = "10") Integer pageSize) {
//记录日志
log.info("分页查询,参数:{},{}", page, pageSize);
//调用业务层分页查询功能
PageBean pageBean = empService.page(page, pageSize);
//响应
return Result.success(pageBean);
}
}
条件分页查询
思路分析:

<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
</where>
order by create_time desc
</select>
文件上传
本地存储
文件上传时在服务端会产生一个临时文件,请求响应完成之后,这个临时文件被自动删除,并没有进行保存。下面呢,我们就需要完成将上传的文件保存在服务器的本地磁盘上。
代码实现:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
@Slf4j
@RestController
public class UploadController {
@PostMapping("/upload")
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//构建新的文件名
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String newFileName = UUID.randomUUID().toString()+extname;//随机名+文件扩展名
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+newFileName));
return Result.success();
}
}
在SpringBoot中,文件上传时默认单个文件最大大小为1M
那么如果需要上传大文件,可以在application.properties进行如下配置:
#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MB
不推荐!
云存储
pom文件中添加如下依赖:
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.15.1</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
上传文件的工具类
package edu.whut.utils;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.model.PutObjectRequest;
import com.aliyun.oss.model.PutObjectResult;
import com.aliyuncs.exceptions.ClientException;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.*;
import java.util.UUID;
/**
* 阿里云 OSS 工具类
*/
@Component
public class AliOSSUtils {
private String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
private String bucketName = "zyjavaweb";
/**
* 实现上传图片到OSS
*/
public String upload(MultipartFile file) throws IOException, ClientException {
InputStream inputStream = file.getInputStream();
// 避免文件覆盖
String originalFilename = file.getOriginalFilename();
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String fileName = UUID.randomUUID().toString() + extname;
//上传文件到 OSS
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider);
PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, fileName, inputStream);
PutObjectResult result = ossClient.putObject(putObjectRequest);
//文件访问路径
String url = endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + fileName;
// 关闭ossClient
ossClient.shutdown();
return url;// 把上传到oss的路径返回
}
}
使用时传入MultipartFile类型的文件
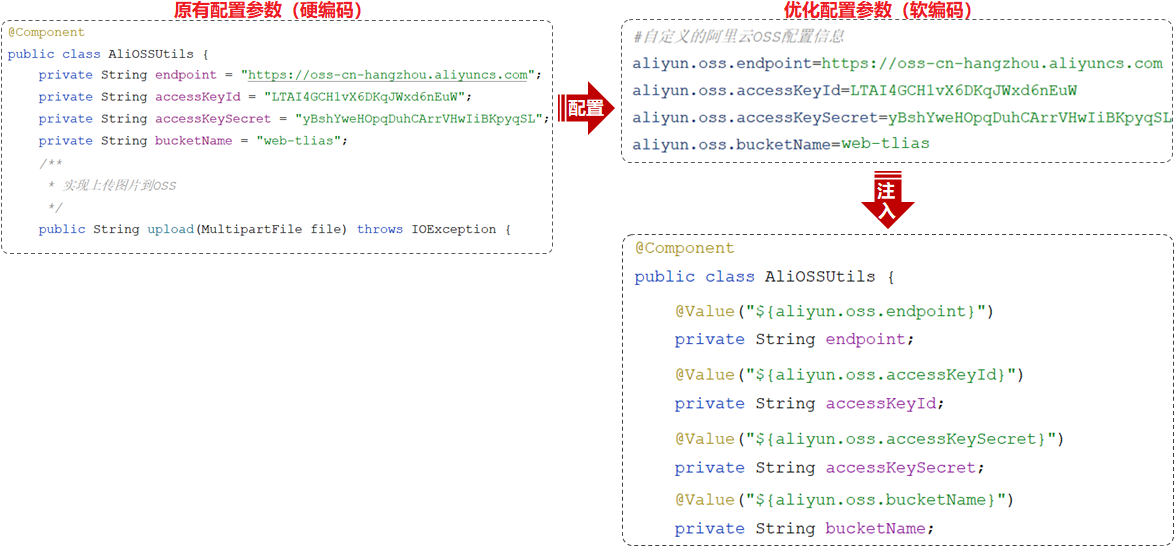
配置文件
properties
将配置信息写在application.properties,用注解@Value获取配置文件中的数据
@Value("${aliyun.oss.endpoint}")
yml配置文件

了解下yml配置文件的基本语法:
- 大小写敏感
- 数据前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
对象/map集合
user:
name: zhangsan
age: 18
password: 123456
数组/List/Set集合
hobby:
- java
- game
- sport
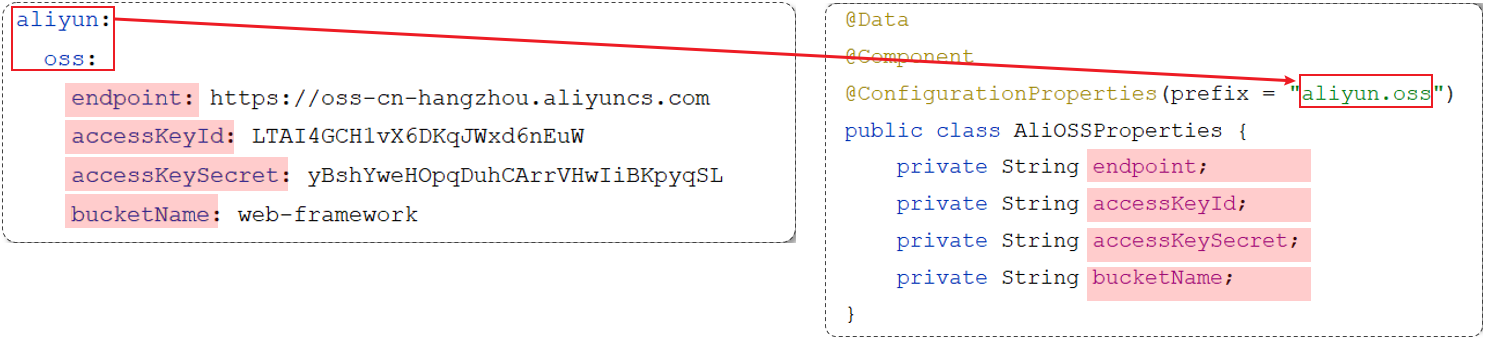
@ConfigurationProperties
前面获取配置项中的属性值,需要通过@Value注解,有时过于繁琐!!!
@Component
public class AliOSSUtils {
@Value("${aliyun.oss.endpoint}")
private String endpoint;
@Value("${aliyun.oss.accessKeyId}")
private String accessKeyId;
@Value("${aliyun.oss.accessKeySecret}")
private String accessKeySecret;
@Value("${aliyun.oss.bucketName}")
private String bucketName;
//省略其他代码...
}
Spring提供的简化方式套路:
-
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法 ==》@Data
-
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象 ==>@Component
-
在实体类上添加
@ConfigurationProperties注解,并通过perfix属性来指定配置参数项的前缀
- (可选)引入依赖pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
使用:

登录校验
会话技术
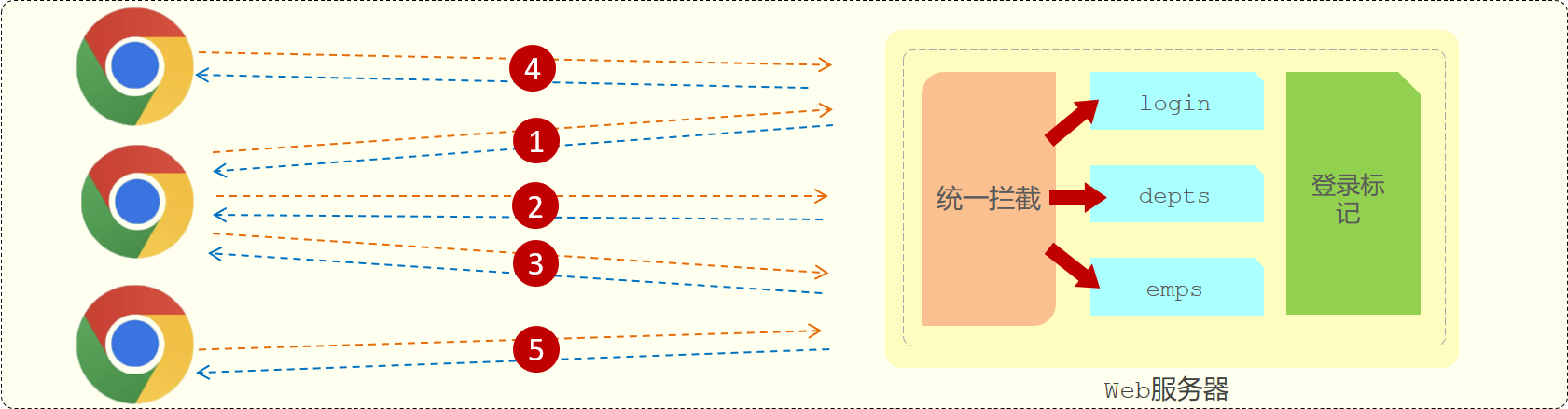
会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。
会话跟踪技术有两种:
- Cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- Session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
Cookie
- 优点:HTTP协议中支持的技术(像Set-Cookie 响应头的解析以及 Cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的)
- 缺点:
- 移动端APP(Android、IOS)中无法使用Cookie
- 不安全,用户可以自己禁用Cookie
- Cookie不能跨域
Session
- 优点:Session是存储在服务端的,安全
- 缺点:
- 服务器集群环境下无法直接使用Session
- 移动端APP(Android、IOS)中无法使用Cookie
- 用户可以自己禁用Cookie
- Cookie不能跨域
令牌(推荐)
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
JWT令牌
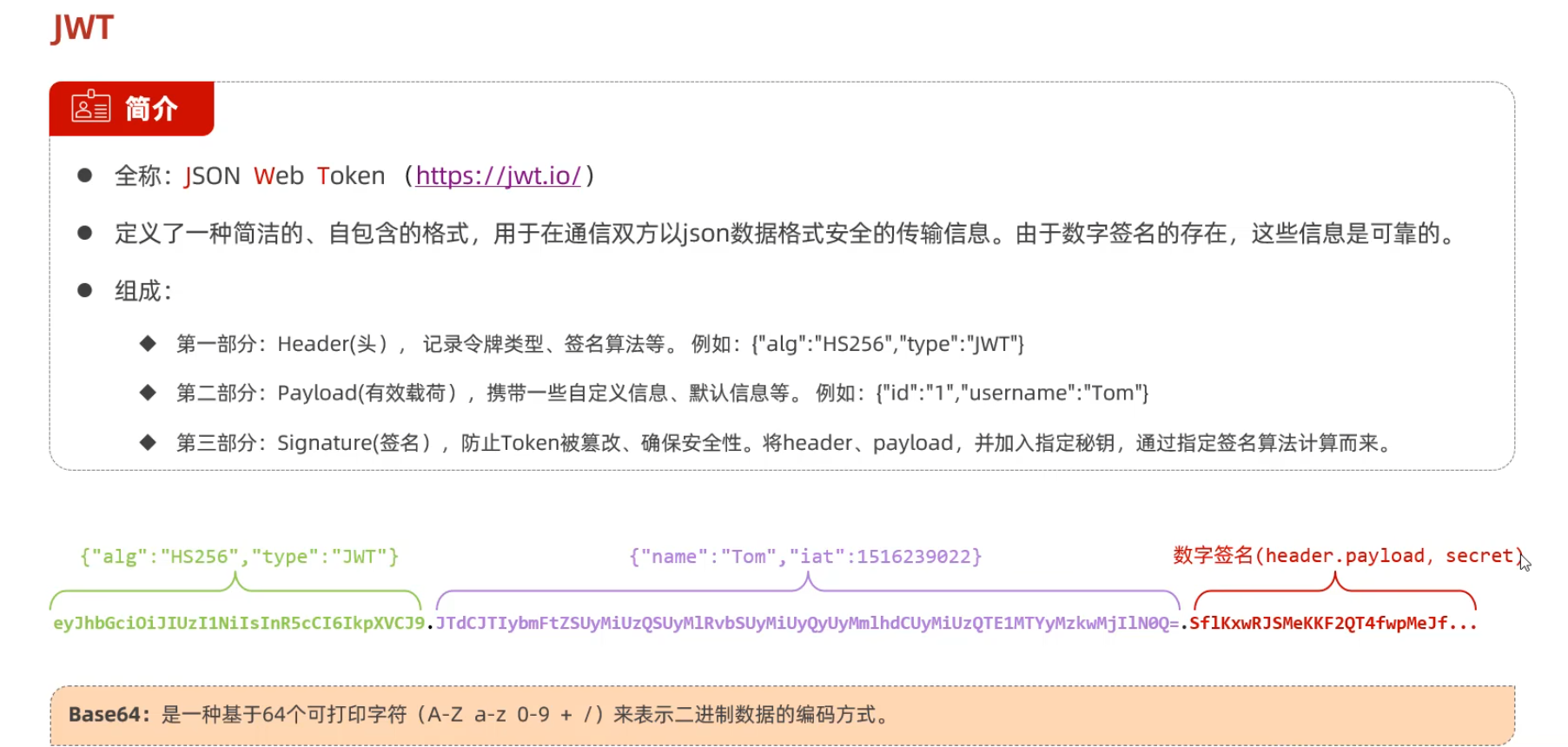
生成和校验
引入依赖
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
生成与解析:
public class JwtUtils {
private static String signKey = "itheima";
private static Long expire = 43200000L;
/**
* 生成JWT令牌
* @param claims JWT第二部分负载 payload 中存储的内容
* @return
*/
public static String generateJwt(Map<String, Object> claims){
String jwt = Jwts.builder()
.addClaims(claims)
.signWith(SignatureAlgorithm.HS256, signKey)
.setExpiration(new Date(System.currentTimeMillis() + expire))
.compact();
return jwt;
}
/**
* 解析JWT令牌
* @param jwt JWT令牌
* @return JWT第二部分负载 payload 中存储的内容
*/
public static Claims parseJWT(String jwt){
Claims claims = Jwts.parser()
.setSigningKey(signKey)
.parseClaimsJws(jwt)
.getBody();
return claims;
}
}
**注意:**一旦生成token,在有效期内,关闭浏览器再重新打开,仍然可以通过登录校验,因为token仍然存在浏览器的“storage里面”。
在有效期内,发送的每个请求头部都会带上token
令牌可以存储当前登录用户的信息:id、username等等,传入claims
Map<String, Object> claims = new HashMap<>();
claims.put("id",emp.getId());
claims.put("name",e.getName());
claims.put("username",e.getUsername());
String jwt=JwtUtils.generateJwt(claims);
解析令牌:
@Autowired
private HttpServletRequest request;
String jwt = request.getHeader("token");
Claims claims = JwtUtils.parseJWT(jwt);
拦截器(Interceptor)
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
1.定义工具类:生成、解析JWT令牌
2.登录时生成JWT令牌
3.定义拦截器,要实现怎样的功能
4.注册配置拦截器,哪些方法前要加拦截器=》校验JWT
快速入门
- 定义拦截器,实现HandlerInterceptor接口,并重写其所有方法
//自定义拦截器
@Component
public class LoginCheckInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}
注意:
preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
postHandle方法:目标资源方法执行后执行
afterCompletion方法:视图渲染完毕后执行,最后执行
- 注册配置拦截器,实现WebMvcConfigurer接口,并重写addInterceptors方法
@Configuration
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
@Autowired
private LoginCheckInterceptor loginCheckInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(loginCheckInterceptor).addPathPatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}
拦截路径
addPathPatterns指定拦截路径;
调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
登录校验
主要在preHandle中写逻辑
@Override //目标资源方法执行前执行。 返回true:放行 返回false:不放行
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
//1.获取请求url
//2.判断请求url中是否包含login,如果包含,说明是登录操作,放行
//3.获取请求头中的令牌(token)
String token = request.getHeader("token");
log.info("从请求头中获取的令牌:{}",token);
//4.判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(!StringUtils.hasLength(token)){
log.info("Token不存在");
//创建响应结果对象
Result responseResult = Result.error("NOT_LOGIN");
//把Result对象转换为JSON格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
String json = JSONObject.toJSONString(responseResult);
//设置响应头(告知浏览器:响应的数据类型为json、响应的数据编码表为utf-8)
response.setContentType("application/json;charset=utf-8");
//响应
response.getWriter().write(json);
return false;//不放行
}
//5.解析token,如果解析失败,返回错误结果(未登录)
try {
JwtUtils.parseJWT(token);
}catch (Exception e){
log.info("令牌解析失败!");
//创建响应结果对象
Result responseResult = Result.error("NOT_LOGIN");
//把Result对象转换为JSON格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
String json = JSONObject.toJSONString(responseResult);
//设置响应头
response.setContentType("application/json;charset=utf-8");
//响应
response.getWriter().write(json);
return false;
}
//6.放行
return true;
}
拦截器&&全局异常处理
执行时机不同:拦截器 (HandlerInterceptor) 主要在请求处理的前后进行拦截和处理,而全局异常处理器在控制器方法抛出异常后进行捕获和处理。
作用不同:拦截器用于拦截请求,可以进行权限验证、日志记录等预处理操作;全局异常处理器专注于异常的统一处理和返回错误信息,确保异常不会导致程序崩溃或未处理的异常信息泄露给客户端。
全局异常处理
- 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解**@RestControllerAdvice**,加上这个注解就代表我们定义了一个全局异常处理器。
- 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解**@ExceptionHandler**。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
@RestControllerAdvice
public class GlobalExceptionHandler {
//处理异常
@ExceptionHandler(Exception.class) //指定能够处理的异常类型,Exception.class捕获所有异常
public Result ex(Exception e){
e.printStackTrace();//打印堆栈中的异常信息
//捕获到异常之后,响应一个标准的Result
return Result.error("对不起,操作失败,请联系管理员");
}
}
事务
Spring事务日志开关
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
Transactional注解
@Transactional作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。一般会在**业务层(Service)**当中来控制事务
@Transactional注解书写位置:
- 方法
- 当前方法交给spring进行事务管理
- 类
- 当前类中所有的方法都交由spring进行事务管理
- 接口
- 接口下所有的实现类当中所有的方法都交给spring 进行事务管理
默认情况下,只有出现RuntimeException(运行时异常)才会回滚事务。假如我们想让所有的异常都回滚,需要来配置@Transactional注解当中的rollbackFor属性,通过rollbackFor这个属性可以指定出现何种异常类型回滚事务。
@Transactional(rollbackFor=Exception.class)
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int num = id/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定传播行为。可以在嵌套的子事务上加入。
@Transactional(propagation = Propagation.REQUIRES_NEW)
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】有父事务则加入,若父事务报异常则一起回滚;无父事务则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
-
REQUIRED :大部分情况下都是用该传播行为即可。
-
REQUIRES_NEW :当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
AOP
AOP英文全称:Aspect Oriented Programming(面向切面编程、面向方面编程),其实说白了,面向切面编程就是面向特定方法编程。
我们要想完成统计各个业务方法执行耗时的需求,我们只需要定义一个模板方法,将记录方法执行耗时这一部分公共的逻辑代码,定义在模板方法当中,在这个方法开始运行之前,来记录这个方法运行的开始时间,在方法结束运行的时候,再来记录方法运行的结束时间,中间就来运行原始的业务方法。
快速入门
实现步骤:
- 导入依赖:在pom.xml中导入AOP的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
- 编写AOP程序:针对于特定方法根据业务需要进行编程
@Component
@Aspect //当前类为切面类
@Slf4j
public class TimeAspect {
////第一个星号表示任意返回值,第二个星号表示类/接口,第三个星号表示所有方法。
@Around("execution(* com.itheima.service.*.*(..))")
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
//记录方法执行开始时间
long begin = System.currentTimeMillis();
//执行原始方法
Object result = pjp.proceed();
//记录方法执行结束时间
long end = System.currentTimeMillis();
//计算方法执行耗时,pjp.getSignature()获得函数名
log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin);
return result;
}
}
我们通过AOP入门程序完成了业务方法执行耗时的统计,那其实AOP的功能远不止于此,常见的应用场景如下:
- 记录系统的操作日志
- 权限控制
- 事务管理:我们前面所讲解的Spring事务管理,底层其实也是通过AOP来实现的,只要添加@Transactional注解之后,AOP程序自动会在原始方法运行前先来开启事务,在原始方法运行完毕之后提交或回滚事务
核心概念
1. 连接点:JoinPoint,可以被AOP控制的方法
2. 通知:Advice,指哪些重复的逻辑,也就是共性功能 (必须的)
3. 切入点表达式:PointCut,匹配连接点的条件,通知仅会在切入点方法执行时被应用 (必须的)
4. 切面:Aspect,描述通知与切入点的对应关系(通知+切入点表达式)
5.目标对象:Target,通知所应用的对象
通知类型
Spring中AOP的通知类型:
- @Around:环绕通知,此注解标注的通知方法在目标方法前、后都被执行
- @Before:前置通知,此注解标注的通知方法在目标方法前被执行
- @After :后置通知,此注解标注的通知方法在目标方法后被执行,无论是否有异常都会执行
- @AfterReturning : 返回后通知,此注解标注的通知方法在目标方法后被执行,有异常不会执行
- @AfterThrowing : 异常后通知,此注解标注的通知方法发生异常后执行
在使用通知时的注意事项:
- @Around环绕通知需要自己调用 ProceedingJoinPoint.proceed() 来让原始方法执行,其他通知不需要考虑目标方法执行
- @Around环绕通知方法的返回值,必须指定为Object,来接收原始方法的返回值,否则原始方法执行完毕,是获取不到返回值的。
通知的执行顺序大家主要知道两点即可:
- 不同的切面类当中,默认情况下通知的执行顺序是与切面类的类名字母排序是有关系的
- 可以在切面类上面加上**@Order注解**,来控制不同的切面类通知的执行顺序。切面类的执行顺序(前置通知:数字越小先执行; 后置通知:数字越小越后执行)
eg:@Order(1)
切入点表达式
公共表示
先定义一个公共的pt(),然后可以直接引用。
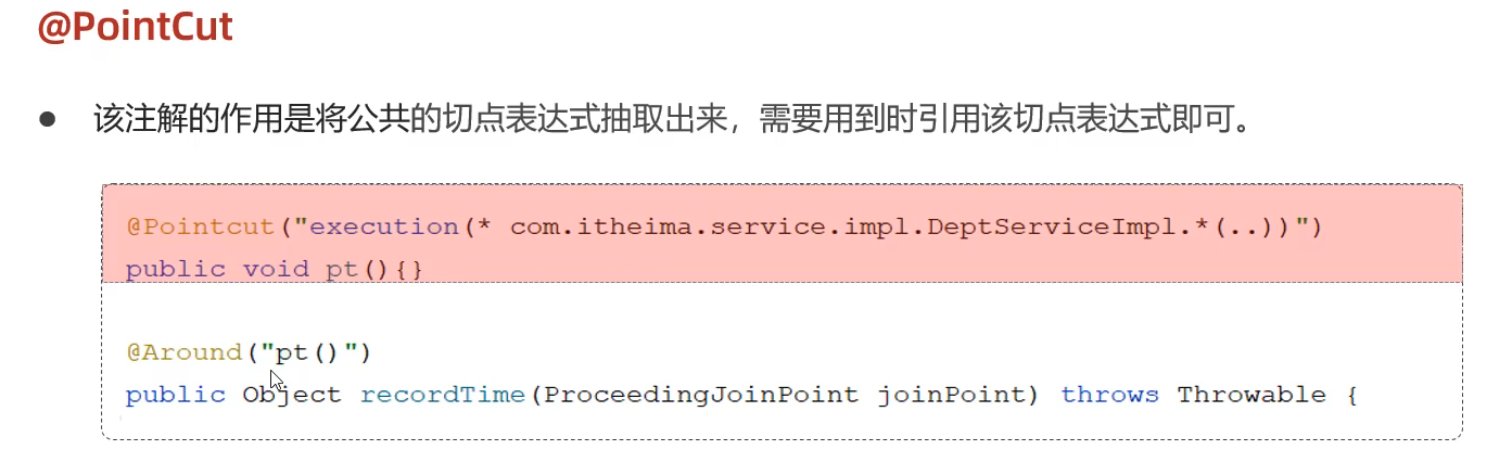
切入点表达式:
-
描述切入点方法的一种表达式
-
作用:主要用来决定项目中的哪些方法需要加入通知
-
常见形式:
- execution(……):根据方法的签名来匹配
- @annotation(……) :根据注解匹配
execution
execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)
其中带?的表示可以省略的部分
-
访问修饰符:可省略(比如: public、protected)
-
包名.类名: 可省略,但不建议
-
throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
eg:
@Before("execution(void com.itheima.service.impl.DeptServiceImpl.delete(java.lang.Integer))")
可以使用通配符描述切入点
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分
execution(* edu.*.service.*.update*(*))
这里update后面的'星'即通配方法名的一部分,()中的'星'表示有且仅有一个任意参数
..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
annotation
那么如果我们要匹配多个无规则的方法,比如:list()和 delete()这两个方法。我们可以借助于另一种切入点表达式annotation来描述这一类的切入点,从而来简化切入点表达式的书写。
实现步骤:
- 新建anno包,在这个包下编写自定义注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
// 定义注解
@Retention(RetentionPolicy.RUNTIME) // 定义注解的生命周期
@Target(ElementType.METHOD) // 定义注解可以应用的Java元素类型
public @interface MyLog {
// 定义注解的元素(属性)
String description() default "This is a default description";
int value() default 0;
}
- 在业务类要做为连接点的方法上添加自定义注解
@MyLog //自定义注解(表示:当前方法属于目标方法)
public void delete(Integer id) {
//1. 删除部门
deptMapper.delete(id);
}
- aop切面类上使用类似如下的切面表达式:
@Before("@annotation(edu.whut.anno.MyLog)")
连接点
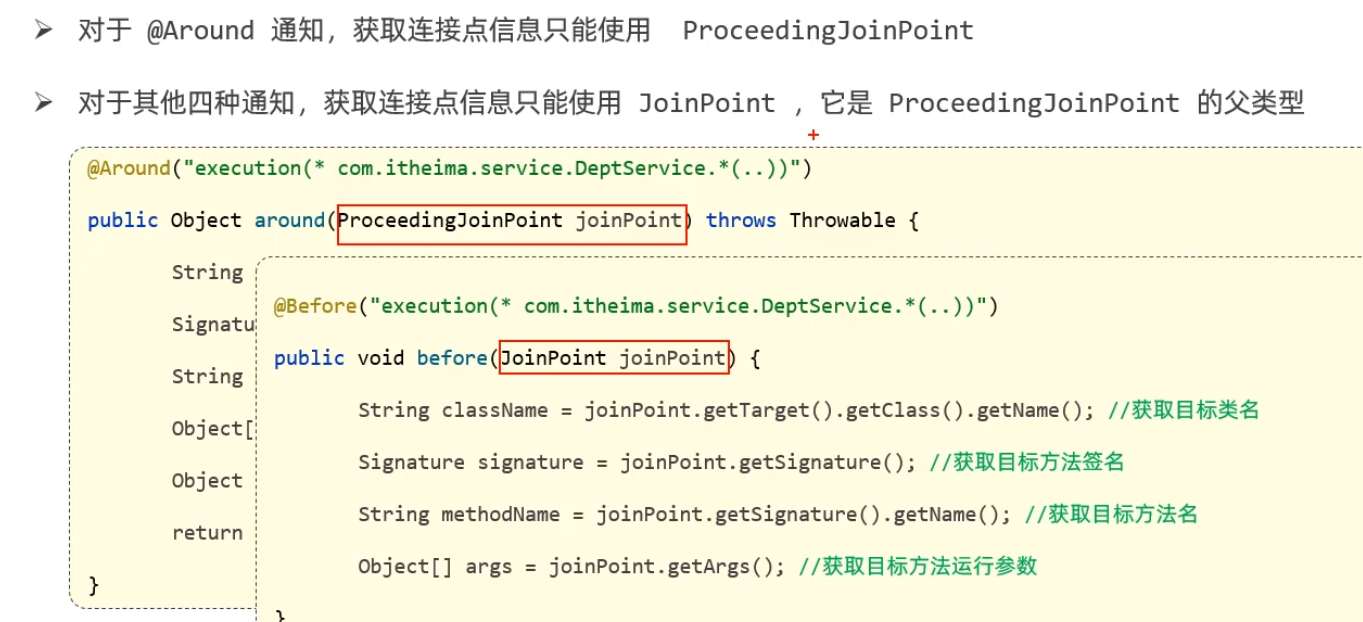
getSignature(): 返回一个Signature类型的对象,这个对象包含了被拦截点的签名信息。在方法调用的上下文中,这包括了方法的名称、声明类型等信息。
- 方法名称:可以通过调用
getName()方法获得。 - 声明类型:方法所在的类或接口的完全限定名,可以通过
getDeclaringTypeName()方法获取。 - 返回类型(对于方法签名):可以通过将
Signature对象转换为更具体的MethodSignature类型,并调用getReturnType()方法获取。
Object[] args = joinPoint.getArgs(); 可以获取调用方法时传递的参数数组
SpringBoot原理
容器启动
在 Spring 框架的上下文中,提到的“容器启动”通常指的是 Spring 应用上下文(ApplicationContext)的初始化和启动过程。这个过程涉及到多个关键步骤,其中包括配置解析、Bean 定义的加载、Bean 的实例化和初始化以及依赖注入等。具体来说,容器启动的时机包括以下几个关键点:
1. 应用启动时
当你启动一个 Spring 应用时,无论是通过直接运行一个包含 main 方法的类,还是部署到一个 Servlet 容器中,Spring 的应用上下文都会被创建和初始化。这个过程包括:
- 读取配置:加载配置文件或注解指定的配置信息,这些配置指定了哪些组件需要被 Spring 管理。
- Bean 定义的注册:Spring 将在配置中找到的所有 Bean 定义加载到容器中。
- Bean 的实例化:Spring 根据 Bean 的定义创建实例。默认情况下(非懒加载),所有的单例 Bean 在容器启动时即被创建。
- 依赖注入:Spring 解析 Bean 之间的依赖关系,并将相应的依赖注入到 Bean 中。
配置优先级
在SpringBoot项目当中,常见的属性配置方式有5种, 3种配置文件,加上2种外部属性的配置(Java系统属性、命令行参数)。通过以上的测试,我们也得出了优先级(从低到高):
- application.yaml(忽略)
- application.yml
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(--xxx=xxx)
如果项目已经打包上线了,这个时候我们又如何来设置Java系统属性和命令行参数呢?
java -Dserver.port=9000 -jar XXXXX.jar --server.port=10010
Bean
获取bean
如何从Spring IoC容器中获取Bean
- @Autowired注解:最常见的方式是使用@Autowired注解自动装配Bean。Spring会自动在其容器中查找匹配类型的Bean并注入到被@Autowired标注的字段或方法中。
@Service
public class MyService {
@Autowired
private MyRepository myRepository; // 自动装配MyRepository Bean
}
- ApplicationContext获取:你也可以通过Spring的ApplicationContext来手动获取Bean。ApplicationContext是Spring的IoC容器,通过它你可以访问容器中的任何Bean。
class SpringbootWebConfig2ApplicationTests {
@Autowired
private ApplicationContext applicationContext; //IOC容器对象
//获取bean对象
@Test
public void testGetBean(){
//根据bean的名称获取
DeptController bean1 = (DeptController) applicationContext.getBean("deptController");
System.out.println(bean1);
}
}
默认是饿汉模式,通过依赖注入设置的类,会在容器启动时自动初始化,除非设置了@Lazy注解,懒汉模式,第一次使用bean对象时,才会创建bean对象并交给ioc容器管理。
bean的作用域
| 作用域 | 说明 |
|---|---|
| singleton | 容器内同名称的bean只有一个实例(单例)(默认) |
| prototype | 每次使用该bean时会创建新的实例(非单例) |
使用方法:
在bean类上加注解
@Scope("prototype")
第三方bean
那么我们应该怎样使用并定义第三方的bean呢?
- 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component 及衍生注解声明bean的,就需要用到**@Bean**注解。
- 如果需要定义第三方Bean时, 通常会单独定义一个配置类
@Configuration //配置类 (在配置类当中对第三方bean进行集中的配置管理)
public class CommonConfig {
//声明第三方bean
@Bean //将当前方法的返回值对象交给IOC容器管理, 成为IOC容器bean
//通过@Bean注解的name/value属性指定bean名称, 如果未指定, 默认是方法名
public SAXReader reader(DeptService deptService){
System.out.println(deptService);
return new SAXReader();
}
}
在方法上加上一个@Bean注解,Spring 容器在启动的时候,它会自动的调用这个方法,并将方法的返回值声明为Spring容器当中的Bean对象。
SpirngBoot原理
起步依赖
如果我们使用了SpringBoot,我们只需要引入一个依赖就可以了,那就是web开发的起步依赖:springboot-starter-web。
为什么我们只需要引入一个web开发的起步依赖?
- 因为Maven的依赖传递。
在SpringBoot给我们提供的这些起步依赖当中,已提供了当前程序开发所需要的所有的常见依赖(官网地址:https://docs.spring.io/spring-boot/docs/2.7.7/reference/htmlsingle/#using.build-systems.starters)。
比如:springboot-starter-web,这是web开发的起步依赖,在web开发的起步依赖当中,就集成了web开发中常见的依赖:json、web、webmvc、tomcat等。我们只需要引入这一个起步依赖,其他的依赖都会自动的通过Maven的依赖传递进来。
结论:起步依赖的原理就是Maven的依赖传递。
自动配置
SpringBoot的自动配置就是当Spring容器启动后,一些配置类、bean对象就自动存入到了IOC容器中,不需要我们手动去声明。
如何让第三方bean以及配置类生效?
@Import导入
- 导入形式主要有以下几种:
- 导入普通类
- 导入配置类
- 导入ImportSelector接口实现类
导入普通类:
@Component
public class TokenParser {
public void parse(){
System.out.println("TokenParser ... parse ...");
}
}
@Import(TokenParser.class) //导入的类会被Spring加载到IOC容器中
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
导入配置类:
- 配置类
@Configuration
public class HeaderConfig {
@Bean
public HeaderParser headerParser(){
return new HeaderParser();
}
@Bean
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}
- 启动类
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
怎么让第三方依赖自己指定bean对象和配置类?
- 比较常见的方案就是第三方依赖给我们提供一个注解,这个注解一般都以@EnableXxxx开头的注解,注解中封装的就是@Import注解
使用第三方依赖提供的 @EnableXxxxx注解
- 第三方依赖中提供的注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Import(MyImportSelector.class)//指定要导入哪些bean对象或配置类
public @interface EnableHeaderConfig {
}
- 在使用时只需在启动类上加上@EnableXxxxx注解即可
@EnableHeaderConfig //使用第三方依赖提供的Enable开头的注解
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
Springboot自动配置
自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是:
- @SpringBootConfiguration
- 声明当前类是一个配置类
- @ComponentScan
- 进行组件扫描(SpringBoot中默认扫描的是启动类所在的当前包及其子包)
- @EnableAutoConfiguration
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
- 在实现类重写的selectImports()方法,读取当前项目下所有依赖jar包中META-INF/spring.factories、META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports两个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)。
- 封装了@Import注解(Import注解中指定了一个ImportSelector接口的实现类)
当SpringBoot程序启动时,就会加载配置文件当中所定义的配置类,并将这些配置类信息(类的全限定名)封装到String类型的数组中,最终通过@Import注解将这些配置类全部加载到Spring的IOC容器中,交给IOC容器管理。
那么所有自动配置类的中声明的bean都会加载到Spring的IOC容器中吗?
其实并不会,因为这些配置类中在声明bean时,通常都会添加@Conditional开头的注解,这个注解就是进行条件装配。而Spring会根据Conditional注解有选择性的进行bean的创建。
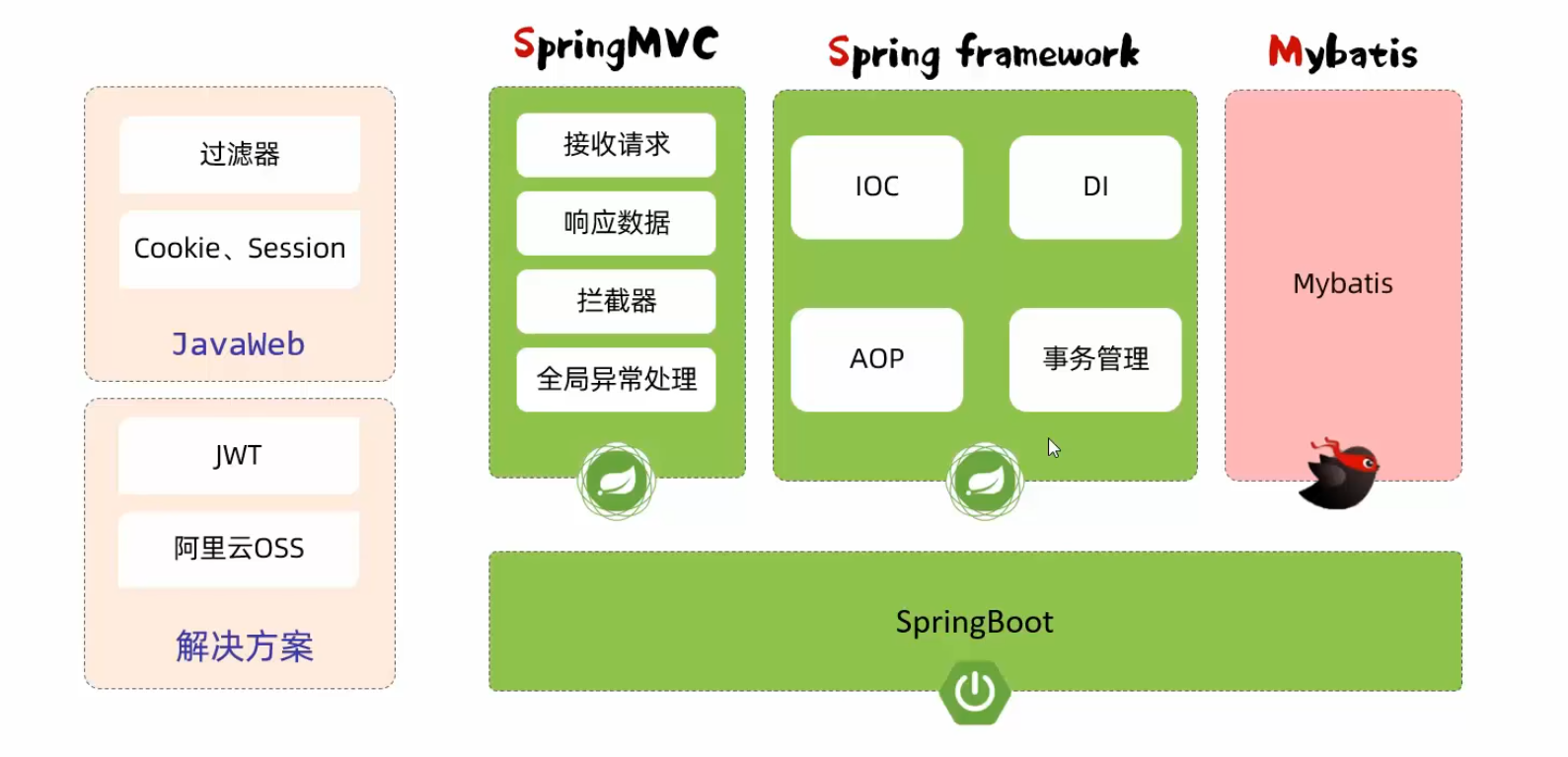
WEB开发总体图