98 KiB
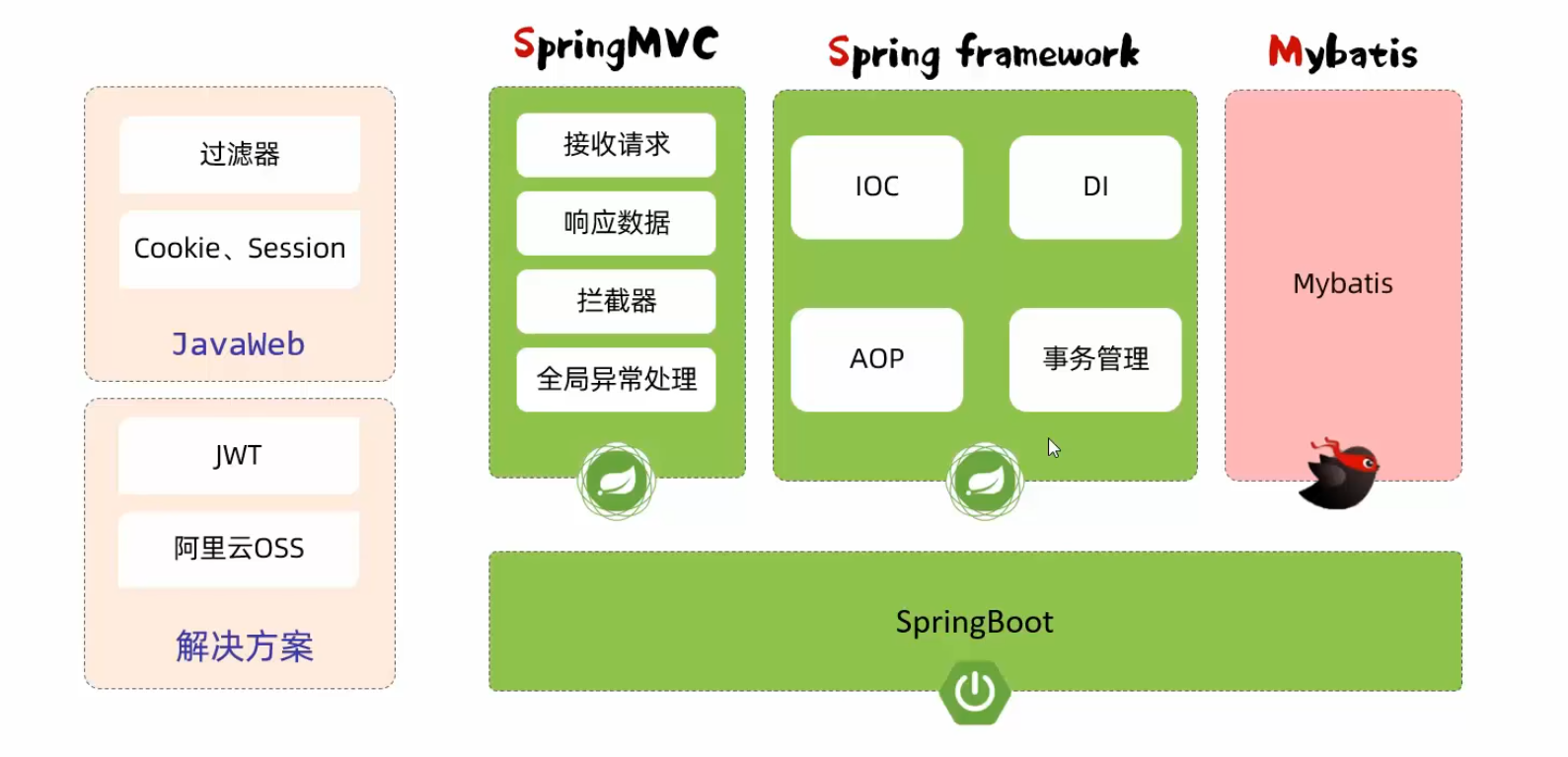
JavaWeb——后端
Java版本解决方案
单个Java文件运行:
Edit Configurations
- 针对单个运行配置:每个 Java 运行配置(如主类、测试类等)可以独立设置其运行环境(如 JRE 版本、程序参数、环境变量等)。
- 不影响全局项目:修改某个运行配置的环境不会影响其他运行配置或项目的全局设置。
如何调整全局项目的环境
- 打开
File -> Project Structure -> Project。 - 在
Project SDK中选择全局的 JDK 版本(如 JDK 17)。 - 在
Project language level中设置全局的语言级别(如 17)。
Java Compiler
File -> Settings -> Build, Execution, Deployment -> Compiler -> Java Compiler
Maven Runner
File -> Settings -> Build, Execution, Deployment -> Build Tools -> Maven -> Runner
三者之间的关系
- 全局项目环境 是基准,决定项目的默认 JDK 和语言级别。
- Java Compiler 控制编译行为,可以覆盖全局的
Project language level。 - Maven Runner 控制 Maven 命令的运行环境,可以覆盖全局的
Project SDK。
Maven 项目:
- 确保
pom.xml中的<maven.compiler.source>和<maven.compiler.target>与Project SDK和Java Compiler的配置一致。 - 确保
Maven Runner中的JRE与Project SDK一致。 - 如果还是不行,pom文件右键点击maven->reload project
Maven
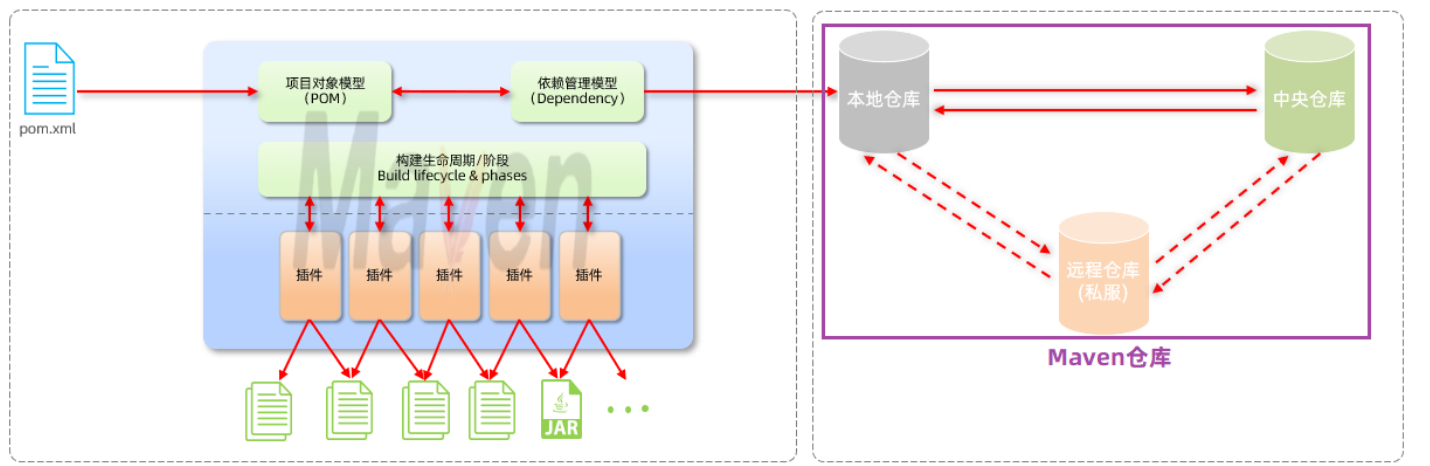
Maven仓库分为:
- 本地仓库:自己计算机上的一个目录(用来存储jar包)
- 中央仓库:由Maven团队维护的全球唯一的。仓库地址:https://repo1.maven.org/maven2/
- 远程仓库(私服):一般由公司团队搭建的私有仓库
POM文件导入依赖的时候,先看本地仓库有没有,没有就看私服,再没有就从中央仓库下载。
Maven创建/导入项目
创建Maven项目

勾选 Create from archetype(可选),也可以选择 maven-archetype-quickstart 等模版。
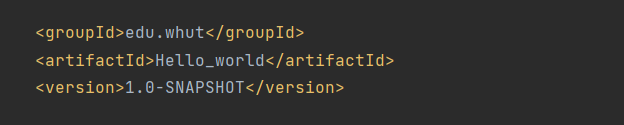
点击 Next,填写 GAV 坐标 。
GroupId:标识组织或公司(通常使用域名反写,如 com.example)
ArtifactId:标识具体项目或模块(如 my-app、spring-boot-starter-web)。
Version:标识版本号(如 1.0-SNAPSHOT、2.7.3)
导入Maven项目
(一)单独的Maven项目
打开 IDEA,在主界面选择 Open(或者在菜单栏选择 File -> Open)。
在文件选择对话框中,定位到已有项目的根目录(包含 pom.xml 的目录)。
选择该目录后,IDEA 会检测到 pom.xml 并询问是否导入为 Maven 项目,点击 OK 或 Import 即可。
IDEA 会自动解析 pom.xml,下载依赖并构建项目结构。
(二)在现有Maven项目中导入独立的Maven项目
在已经打开的 IDEA 窗口中,使用 File -> New -> Module from Existing Sources...
选择待导入项目的根目录(其中包含 pom.xml),IDEA 会将其导入为同一个工程下的另一个模块(Module)。
它们 看起来在一个工程里了,但仍然是两个独立的 Maven 模块。
(三)两个模块有较强的关联
1.新建一个上层目录,如下,MyProject1和MyProject2的内容拷贝过去。
ParentProject/
├── pom.xml <-- 父模块(聚合模块)
├── MyProject1/ <-- 子模块1
│ └── pom.xml
└── MyProject2/ <-- 子模块2
└── pom.xml
2.创建父级pom
父模块 pom.xml 示例:
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>ParentProject</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging> //必写
<modules>
<module>MyProject1</module> //必写
<module>MyProject2</module>
</modules>
</project>
3.修改子模块 pom.xml ,加上:
<parent>
<groupId>com.example</groupId>
<artifactId>ParentProject</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath> <!-- 可省略 -->
</parent>
如果子模块中无需与父级不同的配置,可以不写,就自动继承父级配置;若写了同名配置,则表示你想要覆盖或合并父级配置。
4.File -> Open选择父级的pom,会自动导入其下面两个项目。
(四)通过 Maven 依赖引用(一般导入官方依赖)
如果你的两个项目之间存在依赖关系(例如,第二个项目需要引用第一个项目打包后的 JAR),可以采用以下方式:
在第一个项目(被依赖项目)执行 mvn install
- 这会把打包后的产物安装到本地仓库(默认
~/.m2/repository)。
在第二个项目的 pom.xml 中添加依赖坐标
<dependency>
<groupId>com.example</groupId>
<artifactId>my-first-project</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
Maven 重建
Maven坐标
什么是坐标?
- Maven中的坐标是==资源的唯一标识== , 通过该坐标可以唯一定位资源位置
- 使用坐标来定义项目或引入项目中需要的依赖
依赖管理
可以到mvn的中央仓库(https://mvnrepository.com/)中搜索获取依赖的坐标信息
<dependencies>
<!-- 第1个依赖 : logback -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.11</version>
</dependency>
<!-- 第2个依赖 : junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
更改之后可以在界面上看到一个maven刷新按钮,点击一下就开始联网下载依赖了,成功后可以看到
排除依赖
A依赖B,B依赖C,如果A不想将C依赖进来,可以同时排除C,被排除的资源无需指定版本。
<dependency>
<groupId>com.itheima</groupId>
<artifactId>maven-projectB</artifactId>
<version>1.0-SNAPSHOT</version>
<!--排除依赖, 主动断开依赖的资源-->
<exclusions>
<exclusion>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</exclusion>
</exclusions>
</dependency>
依赖范围
| scope值 | 主程序 | 测试程序 | 打包(运行) | 范例 |
|---|---|---|---|---|
| compile(默认) | Y | Y | Y | log4j |
| test | - | Y | - | junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | jdbc驱动 |
注意!!!这里的scope如果是test,那么它的作用范围在src/test/java下,在src/main/java下无法导包!
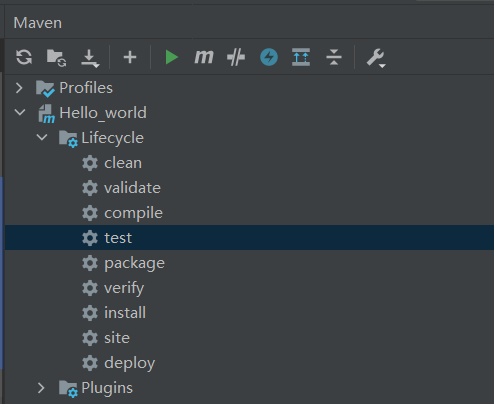
Maven生命周期
主要关注以下几个:
• clean:移除上一次构建生成的文件 (Target文件夹)
• compile:编译 src/main/java 中的 Java 源文件至 target/classes
• test:使用合适的单元测试框架运行测试(junit)
• package:将编译后的文件打包,如:jar、war等
• install:将打包后的产物(如 jar)安装到本地仓库
单元测试
-
导入依赖junit
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> -
在src/test/java下创建DemoTest类(*Test)
-
创建test方法
@Test public void test1(){ System.out.println("hello1"); } @Test public void test2(){ System.out.println("hello2"); } -
双击test生命周期
HTTP协议
响应状态码
| 状态码分类 | 说明 |
|---|---|
| 1xx | 响应中 --- 临时状态码。表示请求已经接受,告诉客户端应该继续请求或者如果已经完成则忽略 |
| 2xx | 成功 --- 表示请求已经被成功接收,处理已完成 |
| 3xx | 重定向 --- 重定向到其它地方,让客户端再发起一个请求以完成整个处理 |
| 4xx | 客户端错误 --- 处理发生错误,责任在客户端,如:客户端的请求一个不存在的资源,客户端未被授权,禁止访问等 |
| 5xx | 服务器端错误 --- 处理发生错误,责任在服务端,如:服务端抛出异常,路由出错,HTTP版本不支持等 |
| 状态码 | 英文描述 | 解释 |
|---|---|---|
| ==200== | OK |
客户端请求成功,即处理成功,这是我们最想看到的状态码 |
| 302 | Found |
指示所请求的资源已移动到由Location响应头给定的 URL,浏览器会自动重新访问到这个页面 |
| 304 | Not Modified |
告诉客户端,你请求的资源至上次取得后,服务端并未更改,你直接用你本地缓存吧。隐式重定向 |
| 400 | Bad Request |
客户端请求有语法错误,不能被服务器所理解 |
| 403 | Forbidden |
服务器收到请求,但是拒绝提供服务,比如:没有权限访问相关资源 |
| ==404== | Not Found |
请求资源不存在,一般是URL输入有误,或者网站资源被删除了 |
| 405 | Method Not Allowed |
请求方式有误,比如应该用GET请求方式的资源,用了POST |
| 429 | Too Many Requests |
指示用户在给定时间内发送了太多请求(“限速”),配合 Retry-After(多长时间后可以请求)响应头一起使用 |
| ==500== | Internal Server Error |
服务器发生不可预期的错误。服务器出异常了,赶紧看日志去吧 |
| 503 | Service Unavailable |
服务器尚未准备好处理请求,服务器刚刚启动,还未初始化好 |
开发规范
REST风格
在前后端进行交互的时候,我们需要基于当前主流的REST风格的API接口进行交互。
什么是REST风格呢?
- REST(Representational State Transfer),表述性状态转换,它是一种软件架构风格。
传统URL风格如下:
http://localhost:8080/user/getById?id=1 GET:查询id为1的用户
http://localhost:8080/user/saveUser POST:新增用户
http://localhost:8080/user/updateUser PUT:修改用户
http://localhost:8080/user/deleteUser?id=1 DELETE:删除id为1的用户
我们看到,原始的传统URL,定义比较复杂,而且将资源的访问行为对外暴露出来了。
基于REST风格URL如下:
http://localhost:8080/users/1 GET:查询id为1的用户
http://localhost:8080/users POST:新增用户
http://localhost:8080/users PUT:修改用户
http://localhost:8080/users/1 DELETE:删除id为1的用户
其中总结起来,就一句话:通过URL定位要操作的资源,通过HTTP动词(请求方式)来描述具体的操作。
REST风格后端代码:
@RestController
@RequestMapping("/depts") //定义当前控制器的请求前缀
public class DeptController {
// GET: 查询资源
@GetMapping("/{id}")
public Dept getDept(@PathVariable Long id) { ... }
// POST: 新增资源
@PostMapping
public void createDept(@RequestBody Dept dept) { ... }
// PUT: 更新资源
@PutMapping
public void updateDept(@RequestBody Dept dept) { ... }
// DELETE: 删除资源
@DeleteMapping("/{id}")
public void deleteDept(@PathVariable Long id) { ... }
}
开发流程
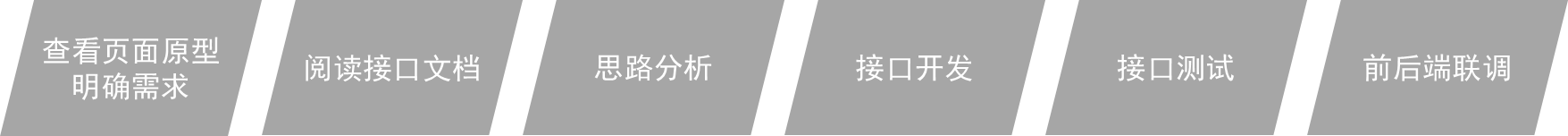
-
查看页面原型明确需求
- 根据页面原型和需求,进行表结构设计、编写接口文档(已提供)
-
阅读接口文档
-
思路分析
-
功能接口开发
- 就是开发后台的业务功能,一个业务功能,我们称为一个接口(Controller 中一个完整的处理请求的方法)
-
功能接口测试
- 功能开发完毕后,先通过Postman进行功能接口测试,测试通过后,再和前端进行联调测试
-
前后端联调测试
- 和前端开发人员开发好的前端工程一起测试
SpringBoot
Servlet 容器 是用于管理和运行 Web 应用的环境,它负责加载、实例化和管理 Servlet 组件,处理 HTTP 请求并将请求分发给对应的 Servlet。常见的 Servlet 容器包括 Tomcat、Jetty、Undertow 等。
SpringBoot的WEB默认内嵌了tomcat服务器,非常方便!!!
浏览器与 Tomcat 之间通过 HTTP 协议进行通信,而 Tomcat 则充当了中间的桥梁,将请求路由到你的 Java 代码,并最终将处理结果返回给浏览器。
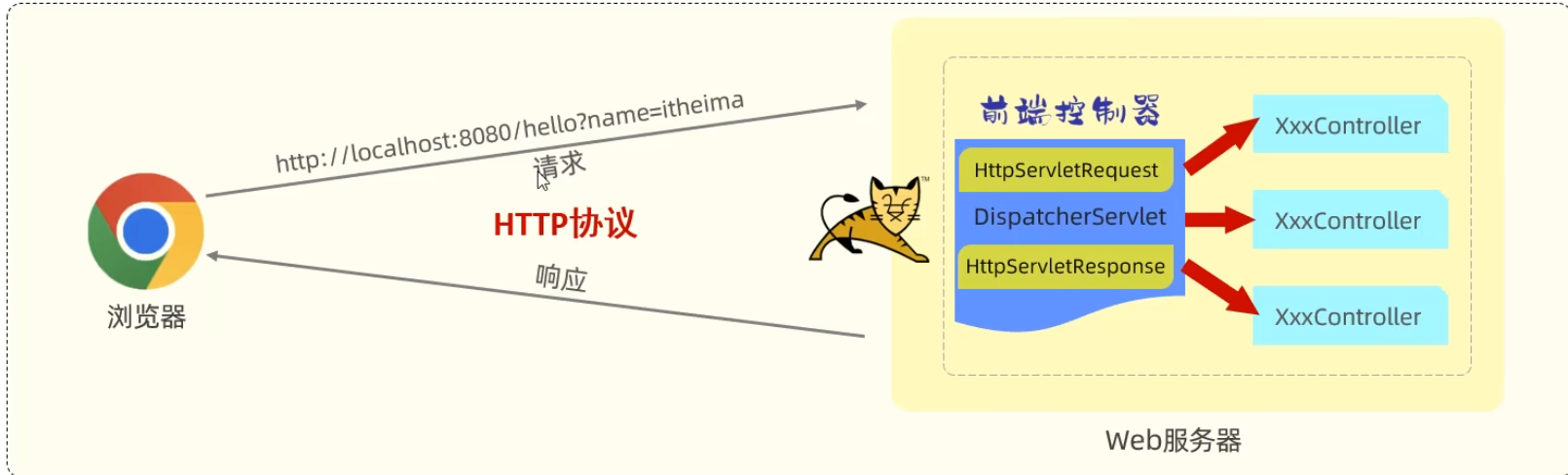
快速启动
- 新建spring initializr project
- 删除以下文件
新建HelloController类
package edu.whut.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String hello(){
System.out.println("hello");
return "hello";
}
}
然后启动服务器,main程序
package edu.whut;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class SprintbootQuickstartApplication {
public static void main(String[] args) {
SpringApplication.run(SprintbootQuickstartApplication.class, args);
}
}
然后浏览器访问 localhost:8080/hello。
SpringBoot请求
简单参数
- 在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=10
// 第1个请求参数: name=Tom 参数名:name,参数值:Tom
// 第2个请求参数: age=10 参数名:age , 参数值:10
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(String name , Integer age ){//形参名和请求参数名保持一致
System.out.println(name+" : "+age);
return "OK";
}
}
- 如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗?
解决方案:可以使用Spring提供的@RequestParam注解完成映射
在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下:
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=20
// 请求参数名:name
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam("name") String username , Integer age ){
System.out.println(username+" : "+age);
return "OK";
}
}
实体参数
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
- User类中有一个Address类型的属性(Address是一个实体类)
复杂实体对象的封装,需要遵守如下规则:
- 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。

注意:这里User前面不能加@RequestBody是因为请求方式是 (表单)或 URL 参数;如果是JSON请求体就必须加。
@RequestMapping("/complexpojo")
public String complexpojo(User user){
System.out.println(user);
return "OK";
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
private Address address;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Address {
private String province;
private String city;
}
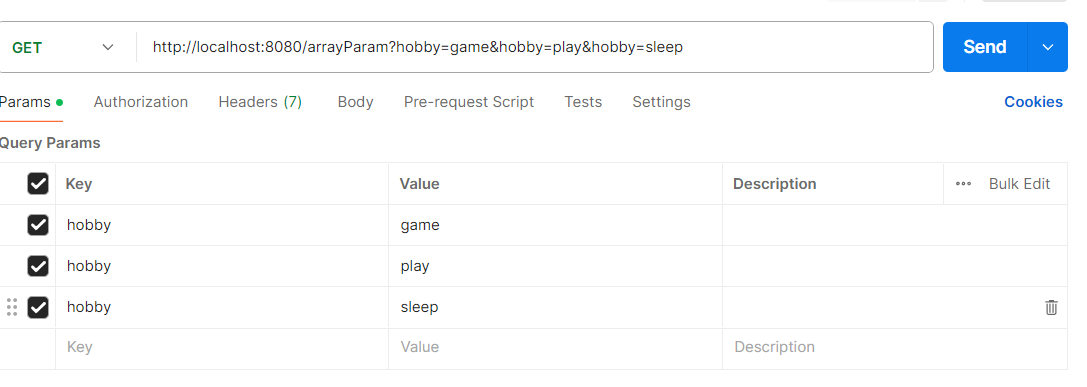
数组参数
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
@RestController
public class RequestController {
//数组集合参数
@RequestMapping("/arrayParam")
public String arrayParam(String[] hobby){
System.out.println(Arrays.toString(hobby));
return "OK";
}
}
路径参数
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
http://localhost:8080/user/1
http://localhost:880/user/1/0
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
注意,路径参数使用大括号 {} 定义
@RestController
public class RequestController {
//路径参数
@RequestMapping("/path/{id}/{name}")
public String pathParam2(@PathVariable Integer id, @PathVariable String name){
System.out.println(id+ " : " +name);
return "OK";
}
}
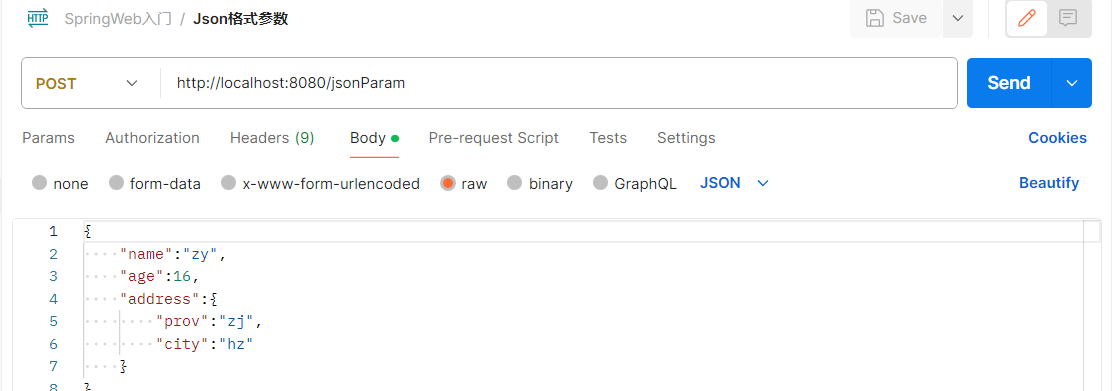
JSON格式参数
{
"backtime": [
"与中标人签订合同后 5日内",
"投标截止时间前撤回投标文件并书面通知招标人的,2日内",
"开标现场投标文件被拒收,开标结束后,2日内"
],
"employees": [
{ "firstName": "John", "lastName": "Doe" },
{ "firstName": "Anna", "lastName": "Smith" },
{ "firstName": "Peter", "lastName": "Jones" }
]
}
JSON 格式的核心特征
- 数据为键值对:数据存储在键值对中,键和值用冒号分隔。在你的示例中,每个对象有两个键值对,如
"firstName": "John"。 - 使用大括号表示对象:JSON 使用大括号
{}包围对象,对象可以包含多个键值对。 - 使用方括号表示数组:JSON 使用方括号
[]表示数组,数组中可以包含多个值,包括数字、字符串、对象等。在该示例中:"employees"是一个对象数组,数组中的每个元素都是一个对象。
Postman如何发送JSON格式数据:
服务端Controller方法如何接收JSON格式数据:
- 传递json格式的参数,在Controller中会使用实体类进行封装。
- 封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用
@RequestBody标识。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class DataDTO {
private List<String> backtime;
private List<Employee> employees;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Employee {
private String firstName;
private String lastName;
}
@RestController
public class DataController {
@PostMapping("/data")
public String receiveData(@RequestBody DataDTO data) {
System.out.println("Backtime: " + data.getBacktime());
System.out.println("Employees: " + data.getEmployees());
return "OK";
}
}
JSON格式工具包
用于高效地进行 JSON 与 Java 对象之间的序列化和反序列化操作。
引入依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
使用:
import com.alibaba.fastjson.JSON;
public class FastJsonDemo {
public static void main(String[] args) {
// 创建一个对象
User user = new User("Alice", 30);
// 对象转 JSON 字符串
String jsonString = JSON.toJSONString(user);
System.out.println("JSON String: " + jsonString);
// JSON 字符串转对象
User parsedUser = JSON.parseObject(jsonString, User.class);
System.out.println("Parsed User: " + parsedUser);
}
}
// JSON String: {"age":30,"name":"Alice"}
// Parsed User: User(name=Alice, age=30)
SpringBoot响应
@ResponseBody注解:
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
@RestController = @Controller + @ResponseBody
统一响应结果:
下图返回值分别是字符串、对象、集合。

定义统一返回结果类
-
响应状态码:当前请求是成功,还是失败
-
状态码信息:给页面的提示信息
-
返回的数据:给前端响应的数据(字符串、对象、集合)
定义在一个实体类Result来包含以上信息。代码如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
private Integer code;//响应码,1 代表成功; 0 代表失败
private String msg; //响应信息 描述字符串
private Object data; //返回的数据
//增删改 成功响应
public static Result success(){
return new Result(1,"success",null);
}
//查询 成功响应
public static Result success(Object data){
return new Result(1,"success",data);
}
//失败响应
public static Result error(String msg){
return new Result(0,msg,null);
}
}
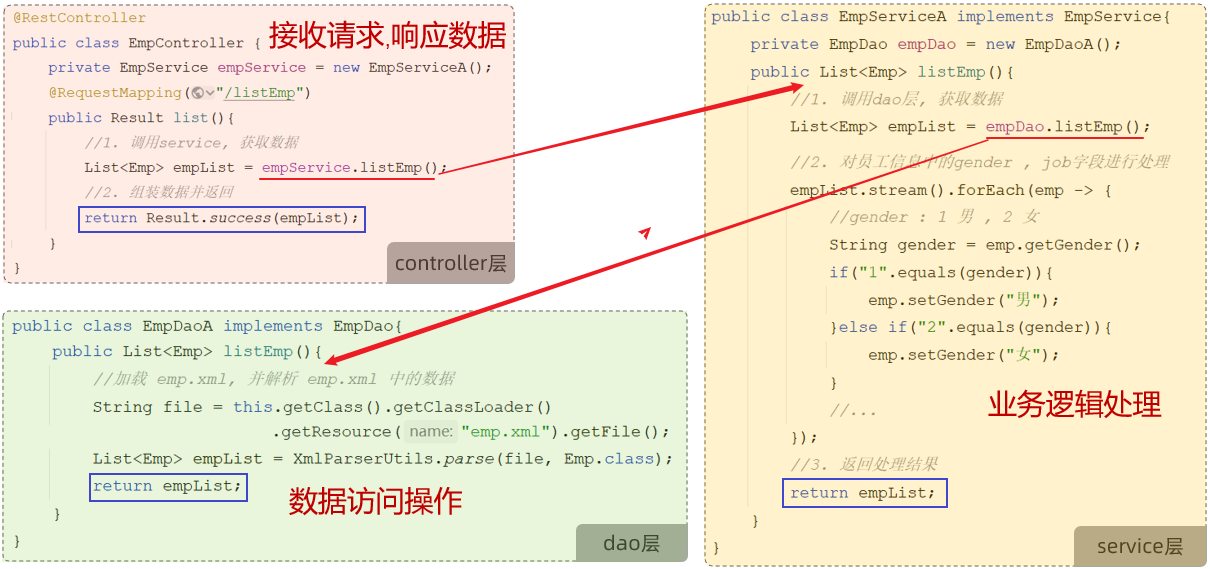
Spring分层架构
三层架构
Controller层接收请求,调用Service层;Service层先调用Dao层获取数据,然后实现自己的业务逻辑处理部分,最后返回给Controller层;Controller层再响应数据。可理解为递归的过程。
传统模式:对象的创建、管理和依赖关系都由程序员手动编写代码完成,程序内部控制对象的生命周期。
例如:
public class A {
private B b;
public A() {
b = new B(); // A 自己创建并管理 B 的实例
}
}
假设有类 A 依赖类 B,在传统方式中,类 A 可能在构造方法或方法内部直接调用 new B() 来创建 B 的实例。
如果 B 的创建方式发生变化,A 也需要修改代码。这就导致了耦合度较高。
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 "高内聚"。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
IOC&DI 分层解耦
外部容器(例如 Spring 容器)是一个负责管理对象创建、配置和生命周期的软件系统。
- 它扫描项目中的类,根据预先配置或注解,将这些类实例化为 Bean。
- 它维护各个 Bean 之间的依赖关系,并在创建 Bean 时把它们所需的依赖“注入”进去。
依赖注入(DI):类 A 不再自己创建 B,而是声明自己需要一个 B,容器在创建 A 时会自动将 B 的实例提供给 A。
public class A {
private B b;
// 通过构造器注入依赖
public A(B b) {
this.b = b;
}
}
Bean 对象:在 Spring 中,被容器管理的对象称为 Bean。通过注解(如 @Component, @Service, @Repository, @Controller),可以将一个普通的 Java 类声明为 Bean,容器会负责它的创建、初始化以及生命周期管理。
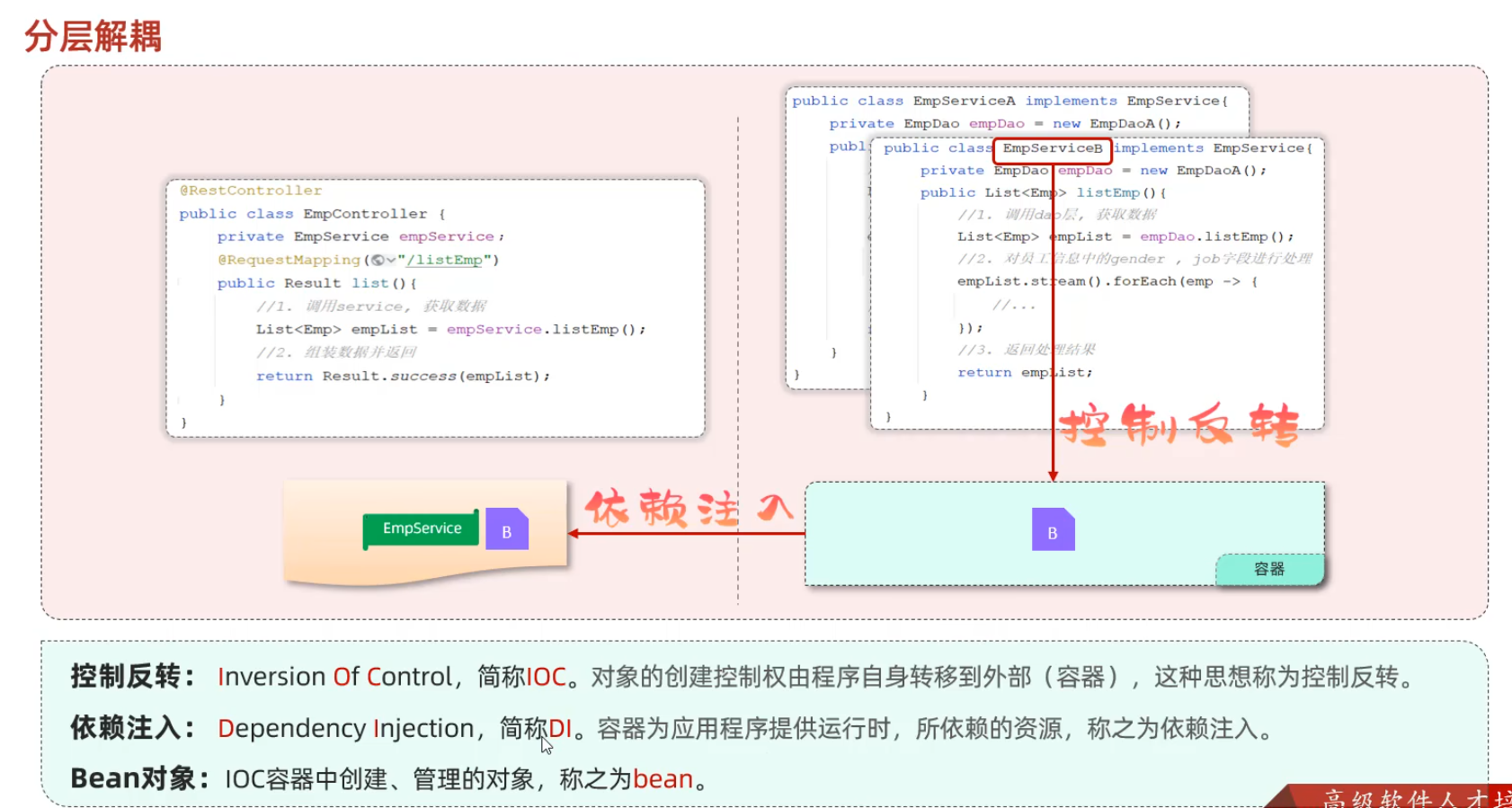
任务:完成Controller层、Service层、Dao层的代码解耦
思路:
- 删除Controller层、Service层中new对象的代码
- Service层及Dao层的实现类,交给IOC容器管理
- 为Controller及Service注入运行时依赖的对象
-
Controller程序中注入依赖的Service层对象
-
Service程序中注入依赖的Dao层对象
-
第1步:删除Controller层、Service层中new对象的代码

第2步:Service层及Dao层的实现类,交给IOC容器管理
使用Spring提供的注解:@Component ,就可以实现类交给IOC容器管理
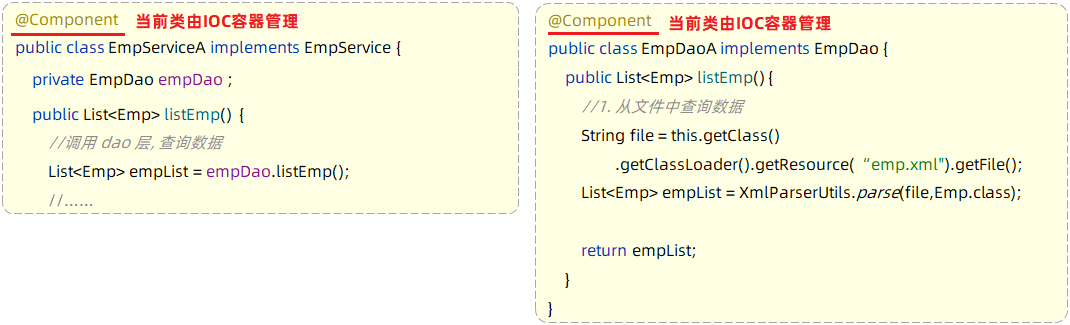
第3步:为Controller及Service注入运行时依赖的对象
使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象

**如果我有多个实现类,eg:EmpServiceA、EmpServiceB,我该如何切换呢?**两种方法
-
只需在需要使用的实现类上加@Component,注释掉不需要用到的类上的@Component。可以把@Component想象成装入盒子,@Autowired想象成拿出来,因此只需改变放入的物品,而不需改变拿出来的这个动作。
// 只启用 EmpServiceA,其他实现类的 @Component 注解被注释或移除 @Component public class EmpServiceA implements EmpService { // 实现细节... } // EmpServiceB 没有被 Spring 管理 // @Component // public class EmpServiceB implements EmpService { ... } -
在@Component上面加上@Primary,表明该类优先生效
// 默认使用 EmpServiceB,其他实现类也在容器中,但未标记为 Primary @Component public class EmpServiceA implements EmpService { // 实现细节... } @Component @Primary // 默认优先注入 public class EmpServiceB implements EmpService { // 实现细节... }
Component衍生注解
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上Controller |
| @Service | @Component的衍生注解 | 标注在业务类上Service |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合,用的少)DAO |
| @Component | 声明bean的基础注解 | 不属于以上三类时,用此注解 |
注:@Mapper 注解本身并不是 Spring 框架提供的,是用于 MyBatis 数据层的接口标识,但效果类似。
SpringBoot原理
容器启动
在 Spring 框架中,“容器启动”指的是 ApplicationContext 初始化过程,主要包括配置解析、加载 Bean 定义、实例化和初始化 Bean 以及完成依赖注入。具体来说,容器启动的时机包括以下几个关键点:
当你启动一个 Spring 应用时,无论是通过直接运行一个包含 main 方法的类,还是部署到一个 Servlet 容器中,Spring 的应用上下文都会被创建和初始化。这个过程包括:
- 读取配置:加载配置文件或注解中指定的信息,确定哪些组件由 Spring 管理。
- 注册 Bean 定义:将所有扫描到的 Bean 定义注册到容器中。
- 实例化 Bean:根据 Bean 定义创建实例。默认情况下,所有单例 Bean在启动时被创建(除非配置为懒加载)。
- 依赖注入:解析 Bean 之间的依赖关系,并自动注入相应的依赖。
配置文件
配置优先级
在SpringBoot项目当中,常见的属性配置方式有5种, 3种配置文件,加上2种外部属性的配置(Java系统属性、命令行参数)。优先级(从低到高):
- application.yaml(忽略)
- application.yml
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(--xxx=xxx)
在 Spring Boot 项目中,通常使用的是 application.yml 或 application.properties 文件,这些文件通常放在项目的 src/main/resources 目录下。
如果项目已经打包上线了,这个时候我们又如何来设置Java系统属性和命令行参数呢?
java -Dserver.port=9000 -jar XXXXX.jar --server.port=10010
在这个例子中,由于命令行参数的优先级高于 Java 系统属性,最终生效的 server.port 是 10010。
properties
位置:src/main/resources/application.properties
将配置信息写在application.properties,用注解@Value获取配置文件中的数据
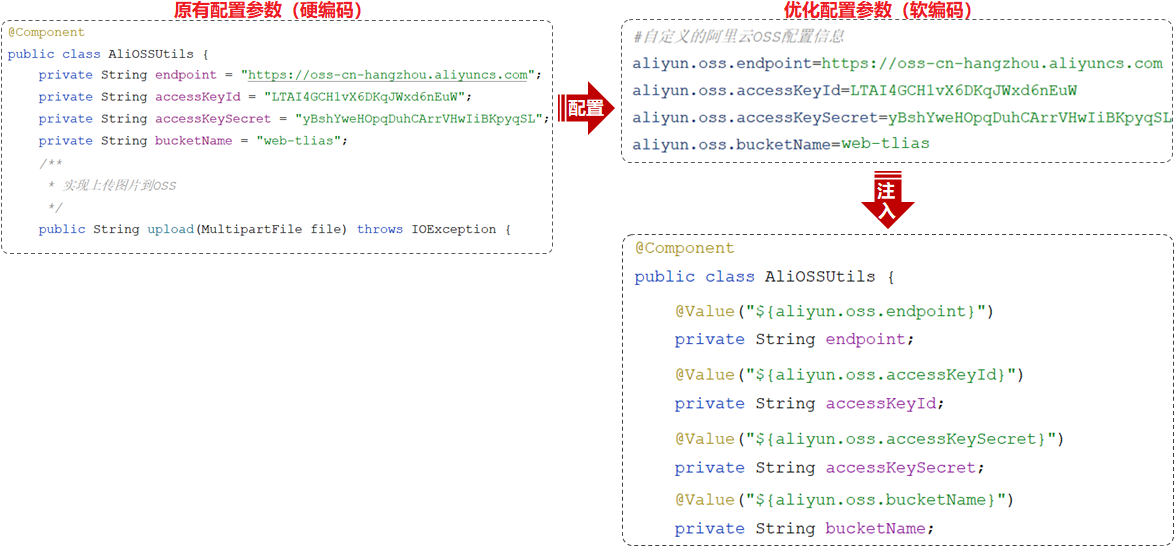
@Value("${aliyun.oss.endpoint}")
yml配置文件(推荐!!!)
位置:src/main/resources/application.yml

了解下yml配置文件的基本语法:
- 大小写敏感
- 数据前边必须有空格,作为分隔符
- 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能用空格(idea中会自动将Tab转换为空格)
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
对象/map集合
user:
name: zhangsan
detail:
age: 18
password: "123456"
数组/List/Set集合
hobby:
- java
- game
- sport
//获取示例
@Value("${hobby}")
private List<String> hobby;
以上获取配置文件中的属性值,需要通过@Value注解,有时过于繁琐!!!
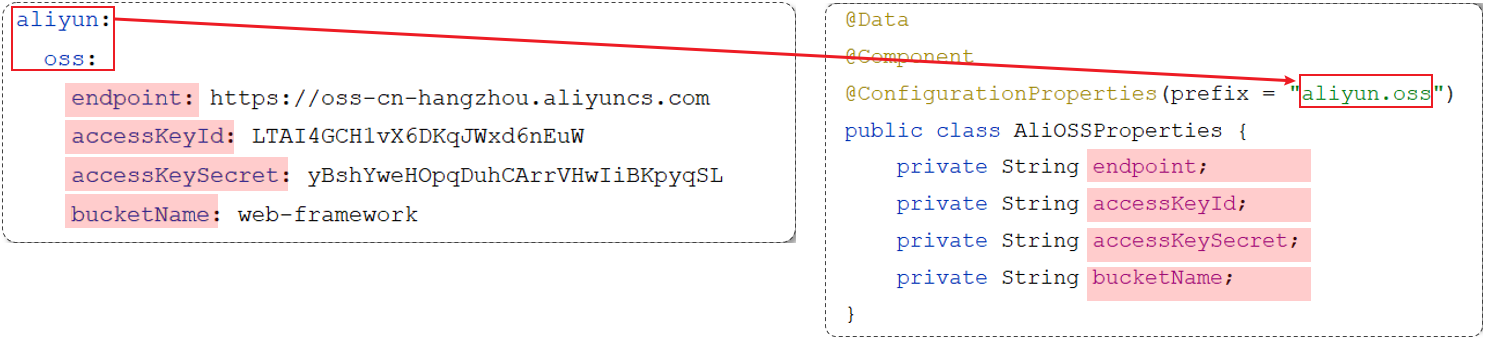
@ConfigurationProperties
是用来将外部配置(如 application.properties / application.yml)映射到一个 POJO 上的。
在 Spring Boot 中,根据 驼峰命名转换规则,自动将 YAML 配置文件中的 键名(例如 user-token-name user_token_name)映射到 Java 类中的属性(例如 userTokenName)。
@Data
@Component
@ConfigurationProperties(prefix = "aliyun.oss")
public class AliOssProperties {
private String endpoint;
private String accessKeyId;
private String accessKeySecret;
private String bucketName;
}
Spring提供的简化方式套路:
-
需要创建一个实现类,且实体类中的属性名和配置文件当中key的名字必须要一致
比如:配置文件当中叫endpoints,实体类当中的属性也得叫endpoints,另外实体类当中的属性还需要提供 getter / setter方法 ==》@Data
-
需要将实体类交给Spring的IOC容器管理,成为IOC容器当中的bean对象 ==>@Component
-
在实体类上添加
@ConfigurationProperties注解,并通过perfix属性来指定配置参数项的前缀
- (可选)引入依赖pom.xml (自动生成配置元数据,让 IDE 能识别并补全你在
application.properties/yml中的自定义配置项,提高开发体验)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</dependency>
Bean 的获取和管理
获取Bean
1.自动装配(@Autowired)
@Service
public class MyService {
@Autowired
private MyRepository myRepository; // 自动注入 MyRepository Bean
}
2.手动获取(ApplicationContext)
-
@Autowired自动将 Spring 创建的ApplicationContext注入到applicationContext字段中, -
再通过
applicationContext.getBean(...)拿到其他 Bean
Spring 会默认采用类名并将首字母小写作为 Bean 的名称。例如,类名为 DeptController 的组件默认名称就是 deptController。
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringbootWebConfig2ApplicationTests {
@Autowired
private ApplicationContext applicationContext; // IoC 容器
@Test
public void testGetBean() {
// 根据 Bean 名称获取
DeptController bean = (DeptController) applicationContext.getBean("deptController");
System.out.println(bean);
}
}
默认情况下,Spring 在容器启动时会创建所有单例 Bean(饿汉模式);使用 @Lazy 注解则可实现延迟加载(懒汉模式)
bean的作用域
| 作用域 | 说明 |
|---|---|
| singleton | 容器内同名称的bean只有一个实例(单例)(默认) |
| prototype | 每次使用该bean时会创建新的实例(非单例) |
在设计单例类时,通常要求它们是无状态的,不仅要确保成员变量不可变,还需要确保成员方法不会对共享的、可变的状态进行不受控制的修改,从而实现整体的线程安全。
@Service
public class CalculationService {
// 不可变的成员变量
private final double factor = 2.0;
// 成员方法仅依赖方法参数和不可变成员变量
public double multiply(double value) {
return value * factor;
}
}
更改作用域方法:
在bean类上加注解@Scope("prototype")(或其他作用域标识)即可。
第三方 Bean配置
- 如果要管理的bean对象来自于第三方(不是自定义的),是无法用@Component 及衍生注解声明bean的,就需要用到**@Bean**注解。
- 如果需要定义第三方Bean时, 通常会单独定义一个配置类
@Configuration // 配置类
public class CommonConfig {
// 定义第三方 Bean,并交给 IoC 容器管理
@Bean // 返回值默认作为 Bean,Bean 名称默认为方法名
public SAXReader reader(DeptService deptService) {
System.out.println(deptService);
return new SAXReader();
}
}
在应用启动时,Spring 会调用配置类中标注 @Bean 的方法,将方法返回值注册为容器中的 Bean 对象。
默认情况下,该 Bean 的名称就是该方法的名字。本例 Bean 名称默认就是 "reader"。
使用:
@Service
public class XmlProcessingService {
// 按类型注入
@Autowired
private SAXReader reader;
public void parse(String xmlPath) throws DocumentException {
Document doc = reader.read(new File(xmlPath));
// ... 处理 Document ...
}
}
SpirngBoot原理
起步依赖
Spring Boot 只需要引入一个起步依赖(例如 springboot-starter-web)就能满足项目开发需求。这是因为:
- Maven 依赖传递: 起步依赖内部已经包含了开发所需的常见依赖(如 JSON 解析、Web、WebMVC、Tomcat 等),无需开发者手动引入其它依赖。
- 结论: 起步依赖的核心原理就是 Maven 的依赖传递机制。
自动配置
Spring Boot 会自动扫描启动类所在包及其子包中的所有带有组件注解(如 @Component, @Service, @Repository, @Controller, @Mapper 等)的类并加载到IOC容器中。
自动配置原理源码入口就是@SpringBootApplication注解,在这个注解中封装了3个注解,分别是:
- @SpringBootConfiguration
- 声明当前类是一个配置类
- @ComponentScan
- 进行组件扫描(SpringBoot中默认扫描的是启动类所在的当前包及其子包)
- @EnableAutoConfiguration
- 内部使用
@Import导入一个ImportSelector实现类,该实现类在其selectImports()方法中读取依赖 jar 包中 META-INF 下的配置文件(如spring.factories),获取自动配置类列表。最终,通过@Import将这些配置类加载到 Spring 的 IoC 容器中。
- 内部使用
自动配置类中的 Bean 加载:
- 自动配置类定义的所有 Bean 不一定全部加载到容器中。
- 通常会配合使用以
@Conditional开头的条件注解,根据环境或依赖条件决定是否装配对应的 Bean,从而实现有选择的配置。
如何让第三方bean以及配置类生效?
如果配置类(如 CommonConfig)不在 Spring Boot 启动类的扫描路径内(即不在启动类所在包或其子包下),那么就需要通过 @Import 手动导入该配置类。如:
com
└── example
└── SpringBootApplication.java // 启动类
src
└── com
└── config
└── CommonConfig.java // 配置类
借助 @Import 注解,我们可以将外部的普通类、配置类或实现了 ImportSelector 的类显式导入到 Spring 容器中。
1.使用@Import导入普通类:
如果某个普通类(如 TokenParser)没有 @Component 注解标识,也可以通过 @Import 导入它,使其成为 Spring 管理的 Bean。
// TokenParser 类没有 @Component 注解
public class TokenParser {
public void parse(){
System.out.println("TokenParser ... parse ...");
}
}
在启动类上使用 @Import 导入:
@Import(TokenParser.class) //导入的类会被Spring加载到IOC容器中
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
2.使用@Import导入配置类:
配置类中可以定义多个 Bean,通过 @Configuration 和 @Bean 注解实现集中管理。
@Configuration
public class HeaderConfig {
@Bean
public HeaderParser headerParser(){
return new HeaderParser();
}
@Bean
public HeaderGenerator headerGenerator(){
return new HeaderGenerator();
}
}
启动类导入配置类:
@Import(HeaderConfig.class) //导入配置类
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
3.使用第三方依赖@EnableXxxx 注解
如果第三方依赖没有提供自动配置支持,
常见方案是第三方依赖提供一个 @EnableXxxx 注解,这个注解内部封装了 @Import,通过它可以一次性导入多个配置或 Bean。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Import(MyImportSelector.class)//指定要导入哪些bean对象或配置类
public @interface EnableHeaderConfig {
}
在应用启动类上添加第三方依赖提供的 @EnableHeaderConfig 注解,即可导入相关的配置和 Bean。
@EnableHeaderConfig //使用第三方依赖提供的Enable开头的注解
@SpringBootApplication
public class SpringbootWebConfig2Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootWebConfig2Application.class, args);
}
}
推荐第三种方式!
常见的注解!!
-
@RequestMapping("/jsonParam"):可以用于控制器级别,也可以用于方法级别。 用于方法:HTTP 请求路径为/jsonParam的请求将调用该方法。@RequestMapping("/jsonParam") public String jsonParam(@RequestBody User user){ System.out.println(user); return "OK"; }用于控制器: 所有方法的映射路径都会以这个前缀开始。
@RestController @RequestMapping("/depts") public class DeptController { @GetMapping("/{id}") public Dept getDept(@PathVariable Long id) { // 实现获取部门逻辑 } @PostMapping public void createDept(@RequestBody Dept dept) { // 实现新增部门逻辑 } } -
@RequestBody:这是一个方法参数级别的注解,用于告诉Spring框架将请求体的内容解析为指定的Java对象。 -
@RestController:这是一个类级别的注解,它告诉Spring框架这个类是一个控制器(Controller),并且处理HTTP请求并返回响应数据。与@Controller注解相比,@RestController注解还会自动将控制器方法返回的数据转换为 JSON 格式,并写入到HTTP响应中,得益于@ResponseBody。@RestController = @Controller + @ResponseBody -
@PathVariable注解用于将路径参数{id}的值绑定到方法的参数id上。当请求的路径是 "/path/123" 时,@PathVariable会将路径中的 "123" 值绑定到方法的参数id上。public String pathParam(@PathVariable Integer id) { System.out.println(id); return "OK"; } //参数名与路径名不同 @GetMapping("/{id}") public ResponseEntity<User> getUserById(@PathVariable("id") Long userId) { } -
@RequestParam,如果方法的参数名与请求参数名不同,需要在@RequestParam注解中指定请求参数的名字。 类似@PathVariable,可以指定参数名称。@RequestMapping("/example") public String exampleMethod(@RequestParam String name, @RequestParam("age") int userAge) { // 在方法内部使用获取到的参数值进行处理 System.out.println("Name: " + name); System.out.println("Age: " + userAge); return "OK"; }还可以设置默认值
@RequestMapping("/greet") public String greet(@RequestParam(defaultValue = "Guest") String name) { return "Hello, " + name; }如果既改请求参数名字,又要设置默认值
@RequestMapping("/greet") public String greet(@RequestParam(value = "age", defaultValue = "25") int userAge) { return "Age: " + userAge; } -
控制反转与依赖注入:
@Component、@Service、@Repository用于标识 bean 并让容器管理它们,从而实现 IoC。@Autowired、@Configuration、@Bean用于实现 DI,通过容器自动装配或配置 bean 的依赖。 -
数据库相关。
@Mapper注解:表示是mybatis中的Mapper接口,程序运行时,框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理@Select注解:代表的就是select查询,用于书写select查询语句 -
@SpringBootTest:它会启动 Spring 应用程序上下文,并在测试期间模拟运行整个 Spring Boot 应用程序。这意味着你可以在集成测试中使用 Spring 的各种功能,例如自动装配、依赖注入、配置加载等。 -
lombok的相关注解。非常实用的工具库。
- 在pom.xml文件中引入依赖
<!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency>- 在实体类上添加以下注解(加粗为常用)
注解 作用 @Getter/@Setter 为所有的属性提供get/set方法 @ToString 会给类自动生成易阅读的 toString 方法 @EqualsAndHashCode 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode 方法 @Data 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) @NoArgsConstructor 为实体类生成无参的构造器方法 @AllArgsConstructor 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 @Slf4j 可以log.info("输出日志信息"); //equals 方法用于比较两个对象的内容是否相同 Address addr1 = new Address("SomeProvince", "SomeCity"); Address addr2 = new Address("SomeProvince", "SomeCity"); System.out.println(addr1.equals(addr2)); // 输出 true -
@Test,Junit测试单元,可在测试类中定义测试函数,一次性执行所有@Test注解下的函数,不用写main方法 -
@Override,当一个方法在子类中覆盖(重写)了父类中的同名方法时,为了确保正确性,可以使用@Override注解来标记这个方法,这样编译器就能够帮助检查是否正确地重写了父类的方法。 -
@DateTimeFormat将日期转化为指定的格式。Spring会尝试将接收到的字符串参数转换为控制器方法参数的相应类型。@RestController public class DateController { // 例如:请求 URL 为 /search?begin=2025-03-28 @GetMapping("/search") public String search(@RequestParam("begin") @DateTimeFormat(pattern = "yyyy-MM-dd") LocalDate begin) { // 此时 begin 已经是 LocalDate 类型,可以直接使用 return "接收到的日期是: " + begin; } } -
@RestControllerAdvice= @ControllerAdvice + @ResponseBody。加上这个注解就代表我们定义了一个全局异常处理器,而且处理异常的方法返回值会转换为json后再响应给前端
@RestControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(Exception.class) @ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR) public String handleException(Exception ex) { // 返回错误提示或错误详情 return "系统发生异常:" + ex.getMessage(); } } -
@Configuration和@Bean配合使用,可以对第三方bean进行集中的配置管理,依赖注入!!@Bean用于方法上。加了@Configuration,当Spring Boot应用启动时,它会执行一系列的自动配置步骤。 -
@ComponentScan指定了Spring应该在哪些包下搜索带有@Component、@Service、@Repository、@Controller等注解的类,以便将这些类自动注册为Spring容器管理的Bean.@SpringBootApplication它是一个便利的注解,组合了@Configuration、@EnableAutoConfiguration和@ComponentScan注解。
Mybatis
快速创建
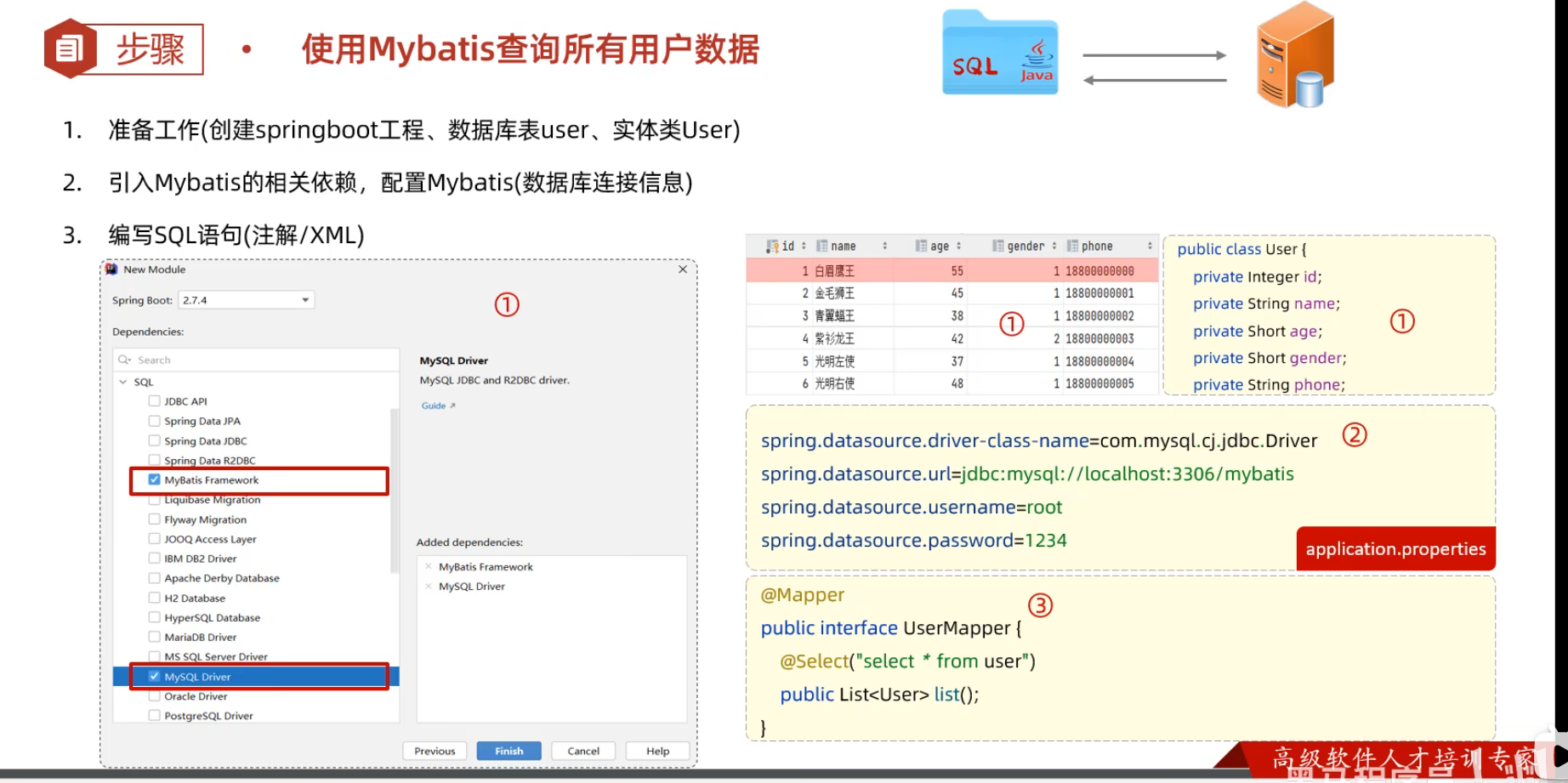
-
创建springboot工程(Spring Initializr),并导入 mybatis的起步依赖、mysql的驱动包。创建用户表user,并创建对应的实体类User
-
在springboot项目中,可以编写main/resources/application.properties文件,配置数据库连接信息。
#驱动类名称 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #数据库连接的url spring.datasource.url=jdbc:mysql://localhost:3306/mybatis #连接数据库的用户名 spring.datasource.username=root #连接数据库的密码 spring.datasource.password=1234 -
在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper
@Mapper注解:表示是mybatis中的Mapper接口
-程序运行时:框架会自动生成接口的实现类对象(代理对象),并交给Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
@Mapper
public interface UserMapper {
//查询所有用户数据
@Select("select * from user")
public List<User> list();
}
数据库连接池
数据库连接池是一个容器,负责管理和分配数据库连接(Connection)。
- 在程序启动时,连接池会创建一定数量的数据库连接。
- 客户端在执行 SQL 时,从连接池获取连接对象,执行完 SQL 后,将连接归还给连接池,以供其他客户端复用。
- 如果连接对象长时间空闲且超过预设的最大空闲时间,连接池会自动释放该连接。
优势:避免频繁创建和销毁连接,提高数据库访问效率。
Druid(德鲁伊)
-
Druid连接池是阿里巴巴开源的数据库连接池项目
-
功能强大,性能优秀,是Java语言最好的数据库连接池之一
把默认的 Hikari 数据库连接池切换为 Druid 数据库连接池:
-
在pom.xml文件中引入依赖
<dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency> -
在application.properties中引入数据库连接配置
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=1234
SQL注入问题
SQL注入:由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。
在Mybatis中提供的参数占位符有两种:${...} 、#{...}
-
#{...}
- 执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值
- 使用时机:参数传递,都使用#{…}
-
${...}
- 拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
- 使用时机:如果对表名、列表进行动态设置时使用
日志输出
只建议开发环境使用:在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果
-
打开application.properties文件
-
开启mybatis的日志,并指定输出到控制台
#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
驼峰命名法
在 Java 项目中,数据库表字段名一般使用 下划线命名法(snake_case),而 Java 中的变量名使用 驼峰命名法(camelCase)。
-
小驼峰命名(lowerCamelCase):
-
第一个单词的首字母小写,后续单词的首字母大写。
-
例子:
firstName,userName,myVariable
大驼峰命名(UpperCamelCase):
- 每个单词的首字母都大写,通常用于类名或类型名。
- 例子:
MyClass,EmployeeData,OrderDetails
表中查询的数据封装到实体类中
- 实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。
- 如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。

解决方法:
- 起别名
- 结果映射
- 开启驼峰命名
- 属性名和表中字段名保持一致
开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
驼峰命名规则: abc_xyz => abcXyz
- 表中字段名:abc_xyz
- 类中属性名:abcXyz
# 在application.properties中添加:
mybatis.configuration.map-underscore-to-camel-case=true
增删改
- 增删改通用!:返回值为int时,表示影响的记录数,一般不需要可以设置为void!
作用于单个字段
@Mapper
public interface EmpMapper {
//SQL语句中的id值不能写成固定数值,需要变为动态的数值
//解决方案:在delete方法中添加一个参数(用户id),将方法中的参数,传给SQL语句
/**
* 根据id删除数据
* @param id 用户id
*/
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
public void delete(Integer id);
}

上图参数值分离,有效防止SQL注入
作用于多个字段
@Mapper
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}
在 @Insert 注解中使用 #{} 来引用 Emp 对象的属性,MyBatis 会自动从 Emp 对象中提取相应的字段并绑定到 SQL 语句中的占位符。
@Options(useGeneratedKeys = true, keyProperty = "id") 这行配置表示,插入时自动生成的主键会赋值给 Emp 对象的 id 属性。
// 调用 mapper 执行插入操作
empMapper.insert(emp);
// 现在 emp 对象的 id 属性会被自动设置为数据库生成的主键值
System.out.println("Generated ID: " + emp.getId());
查
查询案例:
- 姓名:要求支持模糊匹配
- 性别:要求精确匹配
- 入职时间:要求进行范围查询
- 根据最后修改时间进行降序排序
重点在于模糊查询时where name like '%#{name}%' 会报错。
解决方案:
使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%')
CONCAT() 如果其中任何一个参数为 NULL,CONCAT() 返回 NULL,Like NULL会导致查询不到任何结果!
NULL和''是完全不同的
@Mapper
public interface EmpMapper {
@Select("select * from emp " +
"where name like concat('%',#{name},'%') " +
"and gender = #{gender} " +
"and entrydate between #{begin} and #{end} " +
"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDate begin, LocalDate end);
}
XML配置文件规范
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:
-
XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)
-
XML映射文件的namespace属性为Mapper接口全限定名一致
-
XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。
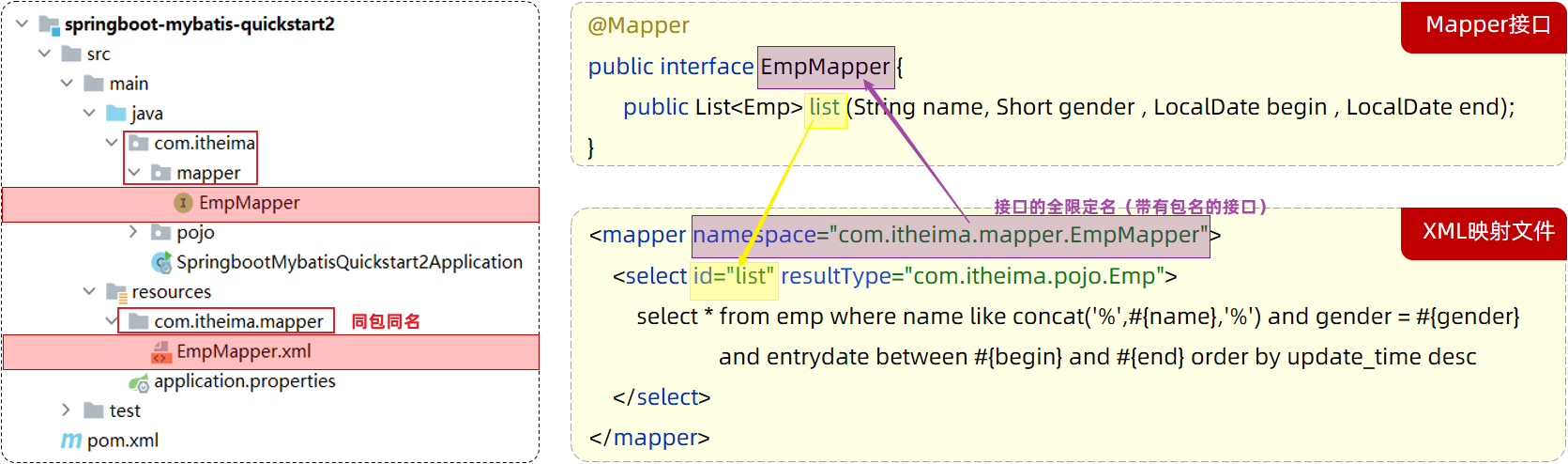
<select>标签:就是用于编写select查询语句的。
resultType属性,指的是查询返回的单条记录所封装的类型。
实现过程:
-
resources下创与java下一样的包,即edu/whut/mapper,新建xx.xml文件
-
配置Mapper文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="edu.whut.mapper.EmpMapper"> <!-- SQL 查询语句写在这里 --> </mapper>namespace属性指定了 Mapper 接口的全限定名(即包名 + 类名)。 -
编写查询语句
<select id="list" resultType="edu.whut.pojo.Emp"> select * from emp where name like concat('%',#{name},'%') and gender = #{gender} and entrydate between #{begin} and #{end} order by update_time desc </select>id="list":指定查询方法的名称,应该与 Mapper 接口中的方法名称一致。resultType="edu.whut.pojo.Emp":resultType只在 查询操作 中需要指定。指定查询结果映射的对象类型,这里是Emp类。
这里有bug!!!
concat('%',#{name},'%')这里应该用<where> <if>标签对name是否为NULL或''进行判断
动态SQL
SQL-if,where
<if>:用于判断条件是否成立。使用test属性进行条件判断,如果条件为true,则拼接SQL。
<if test="条件表达式">
要拼接的sql语句
</if>
<where>只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR,加了总比不加好
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
<where>
<!-- if做为where标签的子元素 -->
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>
SQL-foreach
Mapper 接口
@Mapper
public interface EmpMapper {
//批量删除
public void deleteByIds(List<Integer> ids);
}
XML 映射文件
<foreach> 标签用于遍历集合,常用于动态生成 SQL 语句中的 IN 子句、批量插入、批量更新等操作。
<foreach collection="集合名称" item="集合遍历出来的元素/项" separator="每一次遍历使用的分隔符"
open="遍历开始前拼接的片段" close="遍历结束后拼接的片段">
</foreach>
open="(":这个属性表示,在生成的 SQL 语句开始时添加一个 左括号 (。
close=")":这个属性表示,在生成的 SQL 语句结束时添加一个 右括号 )。
例:批量删除实现
<delete id="deleteByIds">
DELETE FROM emp WHERE id IN
<foreach collection="ids" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
实现效果类似:DELETE FROM emp WHERE id IN (1, 2, 3);
案例实战
分页查询
传统员工分页查询分析:

采用分页插件PageHelper:
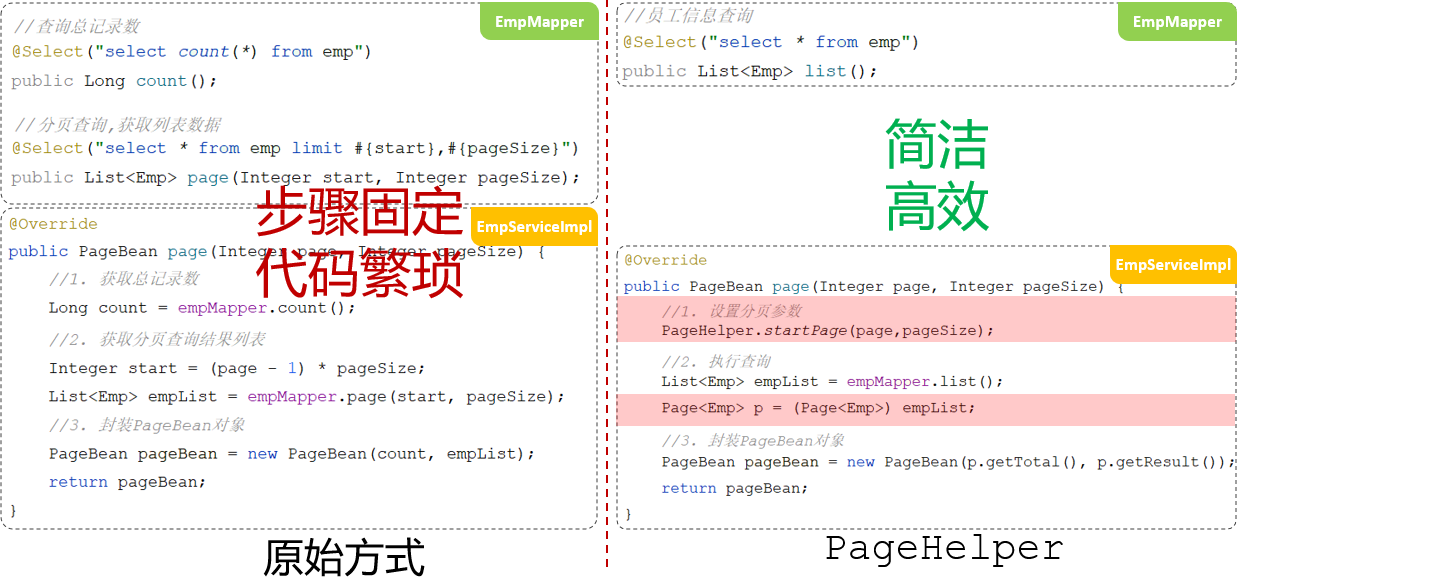
在执行empMapper.list()方法时,就是执行:select * from emp 语句,怎么能够实现分页操作呢?
分页插件帮我们完成了以下操作:
-
先获取到要执行的SQL语句:
select * from emp -
为了实现分页,第一步是获取符合条件的总记录数。分页插件将原始 SQL 查询中的
SELECT *改成SELECT count(*)select count(*) from emp; -
一旦知道了总记录数,分页插件会将
SELECT *的查询语句进行修改,加入LIMIT关键字,限制返回的记录数。select * from emp limit ?, ?第一个参数(
?)是 起始位置,通常是(当前页 - 1) * 每页显示的记录数,即从哪一行开始查询。第二个参数(
?)是 每页显示的记录数,即返回多少条数据。 -
执行分页查询,例如,假设每页显示 10 条记录,你请求第 2 页数据,那么 SQL 语句会变成:
select * from emp limit 10, 10;
使用方法:
当使用 PageHelper 分页插件时,无需在 Mapper 中手动处理分页。只需在 Mapper 中编写常规的列表查询。
- 在 Service 层,调用 Mapper 方法之前,设置分页参数。
- 调用 Mapper 查询后,自动进行分页,并将结果封装到
PageBean对象中返回。
1、在pom.xml引入依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.2</version>
</dependency>
2、EmpMapper
@Mapper
public interface EmpMapper {
//获取当前页的结果列表
@Select("select * from emp")
public List<Emp> list();
}
3、EmpServiceImpl
当调用 PageHelper.startPage(page, pageSize) 时,PageHelper 插件会拦截随后的 SQL 查询,自动修改查询,加入 LIMIT 子句来实现分页功能。
@Override
public PageBean page(Integer page, Integer pageSize) {
// 设置分页参数
PageHelper.startPage(page, pageSize); //page是页号,不是起始索引
// 执行分页查询
List<Emp> empList = empMapper.list();
// 获取分页结果
Page<Emp> p = (Page<Emp>) empList;
//封装PageBean
PageBean pageBean = new PageBean(p.getTotal(), p.getResult());
return pageBean;
}
4、Controller
@Slf4j
@RestController
@RequestMapping("/emps")
public class EmpController {
@Autowired
private EmpService empService;
//条件分页查询
@GetMapping
public Result page(@RequestParam(defaultValue = "1") Integer page,
@RequestParam(defaultValue = "10") Integer pageSize) {
//记录日志
log.info("分页查询,参数:{},{}", page, pageSize);
//调用业务层分页查询功能
PageBean pageBean = empService.page(page, pageSize);
//响应
return Result.success(pageBean);
}
}
条件分页查询
思路分析:

<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
and name like concat('%',#{name},'%')
</if>
</where>
order by create_time desc
/select>
文件上传
本地存储
文件上传时在服务端会产生一个临时文件,请求响应完成之后,这个临时文件被自动删除,并没有进行保存。下面呢,我们就需要完成将上传的文件保存在服务器的本地磁盘上。
代码实现:
- 在服务器本地磁盘上创建images目录,用来存储上传的文件(例:E盘创建images目录)
- 使用MultipartFile类提供的API方法,把临时文件转存到本地磁盘目录下
MultipartFile 常见方法:
- String getOriginalFilename(); //获取原始文件名
- void transferTo(File dest); //将接收的文件转存到磁盘文件中
- long getSize(); //获取文件的大小,单位:字节
- byte[] getBytes(); //获取文件内容的字节数组
- InputStream getInputStream(); //获取接收到的文件内容的输入流
@Slf4j
@RestController
public class UploadController {
@PostMapping("/upload")
public Result upload(String username, Integer age, MultipartFile image) throws IOException {
log.info("文件上传:{},{},{}",username,age,image);
//获取原始文件名
String originalFilename = image.getOriginalFilename();
//构建新的文件名
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String newFileName = UUID.randomUUID().toString()+extname;//随机名+文件扩展名
//将文件存储在服务器的磁盘目录
image.transferTo(new File("E:/images/"+newFileName));
return Result.success();
}
}
在SpringBoot中,文件上传时默认单个文件最大大小为1M
那么如果需要上传大文件,可以在application.properties进行如下配置:
#配置单个文件最大上传大小
spring.servlet.multipart.max-file-size=10MB
#配置单个请求最大上传大小(一次请求可以上传多个文件)
spring.servlet.multipart.max-request-size=100MB
不推荐!
阿里云OSS存储
pom文件中添加如下依赖:
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>3.15.1</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
</dependency>
<!-- no more than 2.3.3-->
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
上传文件的工具类
package edu.whut.utils;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.common.auth.CredentialsProviderFactory;
import com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider;
import com.aliyun.oss.model.PutObjectRequest;
import com.aliyun.oss.model.PutObjectResult;
import com.aliyuncs.exceptions.ClientException;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.*;
import java.util.UUID;
/**
* 阿里云 OSS 工具类
*/
@Component
public class AliOSSUtils {
private String endpoint = "https://oss-cn-hangzhou.aliyuncs.com";
private String bucketName = "zyjavaweb";
/**
* 实现上传图片到OSS
*/
public String upload(MultipartFile file) throws IOException, ClientException {
InputStream inputStream = file.getInputStream();
// 避免文件覆盖
String originalFilename = file.getOriginalFilename();
String extname = originalFilename.substring(originalFilename.lastIndexOf("."));//文件扩展名
String fileName = UUID.randomUUID().toString() + extname;
//上传文件到 OSS
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider);
PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, fileName, inputStream);
PutObjectResult result = ossClient.putObject(putObjectRequest);
//文件访问路径
String url = endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + fileName;
// 关闭ossClient
ossClient.shutdown();
return url;// 把上传到oss的路径返回
}
}
使用时传入MultipartFile类型的文件
登录校验
会话技术
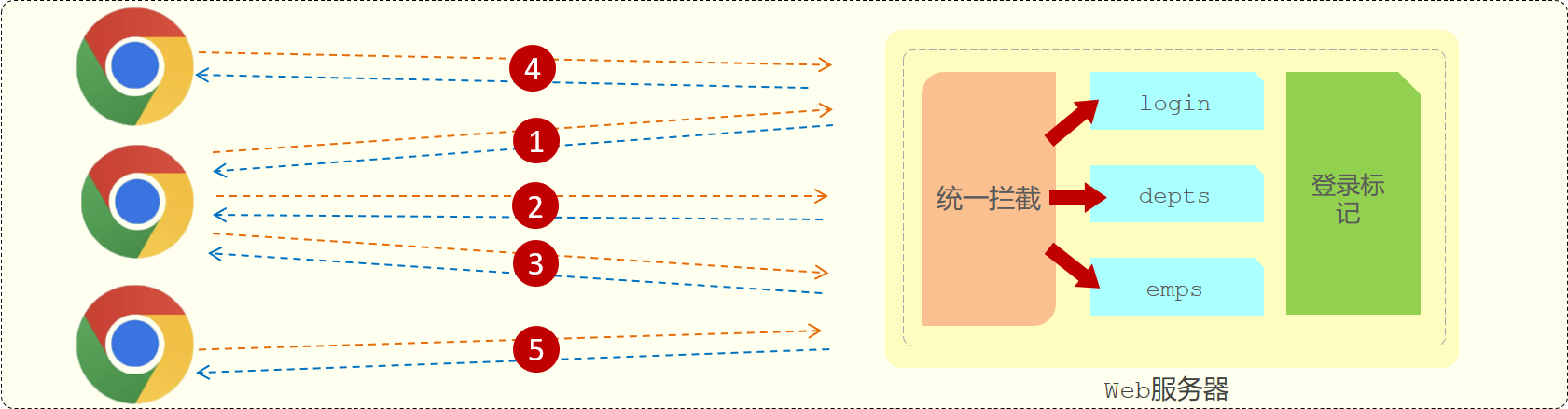
会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。
会话跟踪技术有三种:
- Cookie(客户端会话跟踪技术)
- Session(服务端会话跟踪技术)
- 令牌技术
Cookie
原理:会话数据存储在客户端浏览器中,通过浏览器自动管理。
- 优点:HTTP协议中支持的技术(像Set-Cookie 响应头的解析以及 Cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的)
- 缺点:
- 移动端APP(Android、IOS)中无法使用Cookie
- 不安全,用户可以自己禁用Cookie
- Cookie不能跨域传递
Session
原理:服务端存储会话数据(如内存、Redis),客户端只保存会话 ID。
Session 底层是基于Cookie实现的会话跟踪,因此Cookie的缺点他也有。
- 优点:Session是存储在服务端的,安全。会话数据存在客户端有篡改的风险。
- 缺点:
- 在分布式服务器集群环境下,Session 无法自动共享
- 如果客户端禁用 Cookie,Session 会失效。
- 需要在服务器端存储会话信息,可能带来性能压力,尤其是在高并发环境下。
流程解析
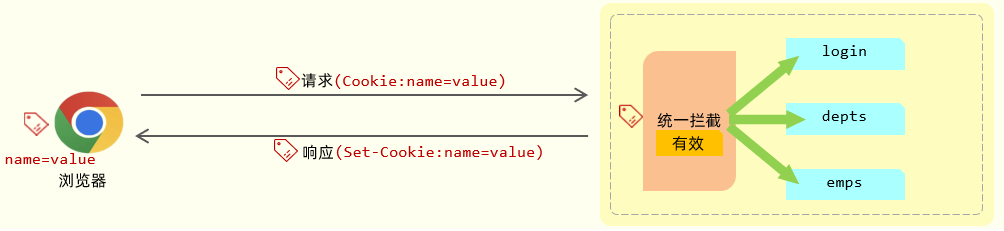
1.当用户登录时,客户端(浏览器)向服务器发送请求(如用户名和密码)。
服务器验证用户身份,如果身份验证成功,服务器会生成一个 唯一标识符(例如 userId 或 authToken),并将其存储在 Cookie 中。服务器会通过 Set-Cookie HTTP 响应头将这个信息发送到浏览器:如:
Set-Cookie: userId=12345; Path=/; HttpOnly; Secure; Max-Age=3600;
userId=12345 是服务器返回的标识符。
Path=/ 表示此 Cookie 对整个网站有效。
HttpOnly 限制客户端 JavaScript 访问该 Cookie,提高安全性。
Secure 指示该 Cookie 仅通过 HTTPS 协议传输。
Max-Age=3600 设置 Cookie 的有效期为一小时。
2.浏览器存储 Cookie:
- 浏览器收到
Set-Cookie响应头后,会自动将userId存储在客户端的 Cookie 中。 userId会在 本地存储,并在浏览器的后续请求中自动携带。
3.后续请求发送 Cookie
- 当浏览器再次向服务器发送请求时,它会自动在 HTTP 请求头中附带之前存储的 Cookie。
4.服务器识别用户
- 服务器通过读取请求中的
Cookie,获取userId(或其他标识符),然后可以从数据库或缓存中获取对应的用户信息。
令牌(推荐)
- 优点:
- 支持PC端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
跨域问题
跨域问题指的是在浏览器中,一个网页试图去访问另一个域下的资源时,浏览器出于安全考虑,默认会阻止这种操作。这是浏览器的同源策略(Same-Origin Policy)导致的行为。
同源策略(Same-Origin Policy)
同源策略是浏览器的一种安全机制,它要求:
- 协议(如
http、https) - 域名/IP(如
example.com) - 端口(如
80或443)
这三者必须完全相同,才能被视为同源。
举例:
http://192.168.150.200/login.html ----------> https://192.168.150.200/login [协议不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.100/login [IP不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login [端口不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200/login [不跨域]
解决跨域问题的方法:
CORS(Cross-Origin Resource Sharing)是解决跨域问题的标准机制。它允许服务器在响应头中加上特定的 CORS 头部信息,明确表示允许哪些外域访问其资源。
服务器端配置:服务器返回带有 Access-Control-Allow-Origin 头部的响应,告诉浏览器允许哪些域访问资源。
Access-Control-Allow-Origin: *(表示允许所有域访问)Access-Control-Allow-Origin: http://site1.com(表示只允许http://site1.com访问)
全局统一配置
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class WebCorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/api/**") // 匹配所有 /api/** 路径
.allowedOrigins("http://allowed-domain.com") // 允许的域名
.allowedMethods("GET","POST","PUT","DELETE","OPTIONS")
.allowedHeaders("Content-Type","Authorization")
.allowCredentials(true) // 是否允许携带 Cookie
.maxAge(3600); // 预检请求缓存 1 小时
}
}
总结
普通的跨域请求依然会送达服务器,服务器并不主动拦截;它只是通过响应头声明哪些来源被允许访问,而真正的拦截与安全检查,则由浏览器根据同源策略来完成。
JWT令牌
| 特性 | Session | JWT(JSON Web Token) |
|---|---|---|
| 存储方式 | 服务端存储会话数据(如内存、Redis) | 客户端存储完整的令牌(通常在 Header 或 Cookie) |
| 标识方式 | 客户端持有一个 Session ID | 客户端持有一个自包含的 Token |
| 状态管理 | 有状态(Stateful),服务器要维护会话 | 无状态(Stateless),服务器不存会话 |
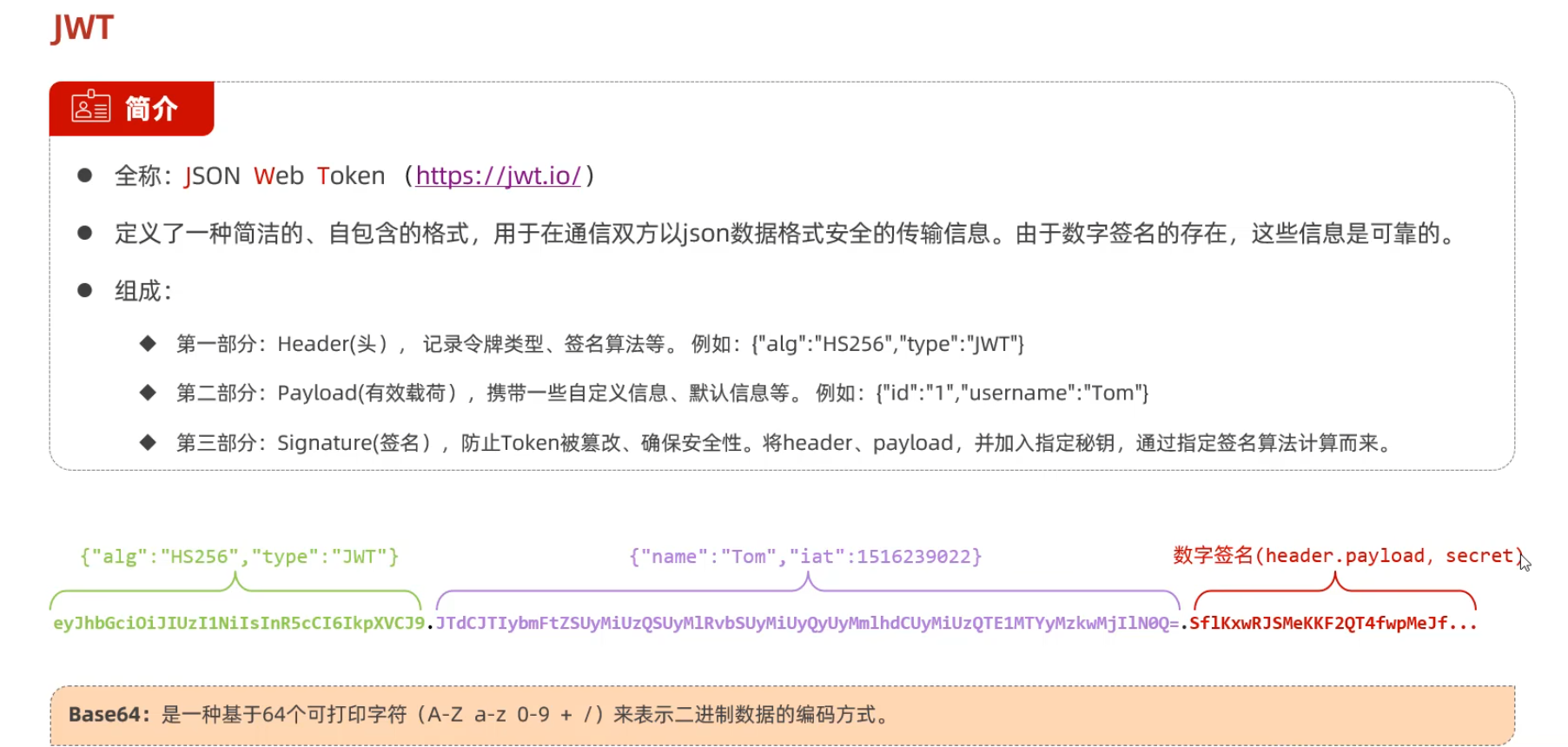
生成和校验
引入依赖
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
生成令牌与解析令牌:
public class JwtUtils {
private static String signKey = "zy123";
private static Long expire = 43200000L; //单位毫秒 12小时
/**
* 生成JWT令牌
* @param claims JWT第二部分负载 payload 中存储的内容
* @return
*/
public static String generateJwt(Map<String, Object> claims){
String jwt = Jwts.builder()
.addClaims(claims)
.signWith(SignatureAlgorithm.HS256, signKey)
.setExpiration(new Date(System.currentTimeMillis() + expire))
.compact();
return jwt;
}
/**
* 解析JWT令牌
* @param jwt JWT令牌
* @return JWT第二部分负载 payload 中存储的内容
*/
public static Claims parseJWT(String jwt){
Claims claims = Jwts.parser()
.setSigningKey(signKey)
.parseClaimsJws(jwt)
.getBody();
return claims;
}
}
令牌可以存储当前登录用户的信息:id、username等等,传入claims
Object 类型能够容纳字符串、数字等各种对象。
Map<String, Object> claims = new HashMap<>();
claims.put("id", emp.getId()); // 假设 emp.getId() 返回一个数字(如 Long 类型)
claims.put("name", e.getName()); // 假设 e.getName() 返回一个字符串
claims.put("username", e.getUsername()); // 假设 e.getUsername() 返回一个字符串
String jwt = JwtUtils.generateJwt(claims);
解析令牌:
@Autowired
private HttpServletRequest request;
String jwt = request.getHeader("token");
Claims claims = JwtUtils.parseJWT(jwt); // 解析 JWT 令牌
// 获取存储的 id, name, username
Long id = (Long) claims.get("id"); // 如果 "id" 是 Long 类型
String name = (String) claims.get("name");
String username = (String) claims.get("username");
JWT 登录认证流程
-
用户登录 用户发起登录请求,登录成功后,生成 JWT 令牌,并将其返回给前端。
-
前端存储令牌 前端接收到 JWT 令牌,存储在浏览器中(通常存储在 LocalStorage 或 Cookie 中)。
// 登录成功后,存储 JWT 令牌到 LocalStorage const token = response.data.token; // 从响应中获取令牌 localStorage.setItem('token', token); // 存储到 LocalStorage // 在后续请求中获取令牌并附加到请求头 const storedToken = localStorage.getItem('token'); fetch("https://your-api.com/protected-endpoint", { method: "GET", headers: { "token": storedToken // 添加 token 到请求头 } }) .then(response => response.json()) .then(data => console.log(data)) .catch(error => console.log('Error:', error)); -
请求带上令牌 后续的每次请求,前端将 JWT 令牌携带上。
-
服务端校验令牌 服务端接收到请求后,拦截请求并检查是否携带令牌。若没有令牌,拒绝访问;若令牌存在,校验令牌的有效性(包括有效期),若有效则放行,进行请求处理。
拦截器(Interceptor)
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带JWT令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
快速入门
- 定义拦截器,实现HandlerInterceptor接口,并重写其所有方法
//自定义拦截器
@Component
public class JwtTokenUserInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}
注意:
preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
postHandle方法:目标资源方法执行后执行
afterCompletion方法:视图渲染完毕后执行,最后执行
- 注册配置拦截器,实现WebMvcConfigurer接口,并重写addInterceptors方法
@Configuration
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
@Autowired
private JwtTokenUserInterceptor jwtTokenUserInterceptor;
@Override
protected void addInterceptors(InterceptorRegistry registry) {
log.info("开始注册自定义拦截器...");
registry.addInterceptor(jwtTokenUserInterceptor)
.addPathPatterns("/user/**")
.excludePathPatterns("/user/user/login")
.excludePathPatterns("/user/shop/status");
}
}
拦截路径
addPathPatterns指定拦截路径;
调用excludePathPatterns("不拦截的路径")方法,指定哪些资源不需要拦截。
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
登录校验
主要在preHandle中写逻辑
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断当前拦截到的是Controller的方法还是其他资源
if (!(handler instanceof HandlerMethod)) {
//当前拦截到的不是动态方法,直接放行
return true;
}
//1、从请求头中获取令牌
String token = request.getHeader(jwtProperties.getUserTokenName());
//2、校验令牌
try {
log.info("jwt校验:{}", token);
Claims claims = JwtUtil.parseJWT(jwtProperties.getUserSecretKey(), token);
Long userId = Long.valueOf(claims.get(JwtClaimsConstant.USER_ID).toString());
log.info("当前用户id:", userId);
BaseContext.setCurrentId(userId);
//3、通过,放行
return true;
} catch (Exception ex) {
//4、不通过,响应401状态码
response.setStatus(401);
return false;
}
}
全局异常处理
**当前问题:**如果程序因不知名原因报错,响应回来的数据是一个JSON格式的数据,但这种JSON格式的数据不符合开发规范当中所提到的统一响应结果Result吗,导致前端不能解析出响应的JSON数据。

当我们没有做任何的异常处理时,我们三层架构处理异常的方案:
- Mapper接口在操作数据库的时候出错了,此时异常会往上抛(谁调用Mapper就抛给谁),会抛给service。
- service 中也存在异常了,会抛给controller。
- 而在controller当中,我们也没有做任何的异常处理,所以最终异常会再往上抛。最终抛给框架之后,框架就会返回一个JSON格式的数据,里面封装的就是错误的信息,但是框架返回的JSON格式的数据并不符合我们的开发规范。
如何解决:
-
方案一:在所有Controller的所有方法中进行try…catch处理
- 缺点:代码臃肿(不推荐)
-
方案二:全局异常处理器
- 好处:简单、优雅(推荐)
全局异常处理
- 定义全局异常处理器非常简单,就是定义一个类,在类上加上一个注解**@RestControllerAdvice**,加上这个注解就代表我们定义了一个全局异常处理器。
- 在全局异常处理器当中,需要定义一个方法来捕获异常,在这个方法上需要加上注解**@ExceptionHandler**。通过@ExceptionHandler注解当中的value属性来指定我们要捕获的是哪一类型的异常。
@RestControllerAdvice
public class GlobalExceptionHandler {
//处理 RuntimeException 异常
@ExceptionHandler(RuntimeException.class)
public Result handleRuntimeException(RuntimeException e) {
e.printStackTrace();
return Result.error("系统错误,请稍后再试");
}
// 处理 NullPointerException 异常
@ExceptionHandler(NullPointerException.class)
public Result handleNullPointerException(NullPointerException e) {
e.printStackTrace();
return Result.error("空指针异常,请检查代码逻辑");
}
//处理异常
@ExceptionHandler(Exception.class) //指定能够处理的异常类型,Exception.class捕获所有异常
public Result ex(Exception e){
e.printStackTrace();//打印堆栈中的异常信息
//捕获到异常之后,响应一个标准的Result
return Result.error("对不起,操作失败,请联系管理员");
}
}
模拟NullPointerException
String str = null;
// 调用 null 对象的方法会抛出 NullPointerException
System.out.println(str.length()); // 这里会抛出 NullPointerException
模拟RuntimeException
int res=10/0;
事务
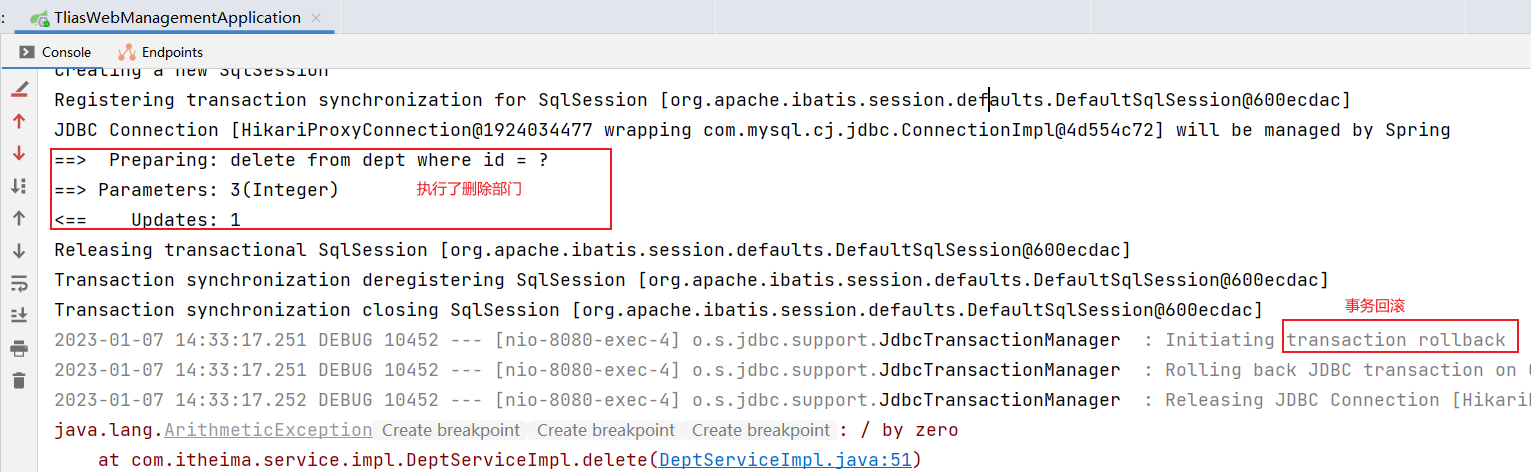
问题分析:
@Slf4j
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Autowired
private EmpMapper empMapper;
//根据部门id,删除部门信息及部门下的所有员工
@Override
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int i = 1/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
}
即使程序运行抛出了异常,部门依然删除了,但是部门下的员工却没有删除,造成了数据的不一致。
因此,需要事务来控制这组操作,让这组操作同时成功或同时失败。
Transactional注解
@Transactional作用:就是在当前这个方法执行开始之前来开启事务,方法执行完毕之后提交事务。如果在这个方法执行的过程当中出现了异常,就会进行事务的回滚操作。一般会在**业务层(Service)**当中来控制事务。
@Transactional注解书写位置:
- 方法:当前方法交给spring进行事务管理
- 类:当前类中所有的方法都交由spring进行事务管理
- 接口:接口下所有的实现类当中所有的方法都交给spring 进行事务管理
@Transactional注解当中的两个常见的属性:
- 异常回滚的属性:rollbackFor
- 事务传播行为:propagation
默认情况下,只有出现RuntimeException(运行时异常)才会回滚事务。假如我们想让所有的异常都回滚,需要来配置@Transactional注解当中的rollbackFor属性,通过rollbackFor这个属性可以指定出现何种异常类型回滚事务。
@Transactional(rollbackFor=Exception.class)
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int num = id/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
在@Transactional注解的后面指定一个属性propagation,通过 propagation 属性来指定事务的传播行为。
什么是事务的传播行为呢?
- 就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行事务控制。A方法运行的时候,首先会开启一个事务,在A方法当中又调用了B方法, B方法自身也具有事务,那么B方法在运行的时候,到底是加入到A方法的事务当中来,还是B方法在运行的时候新建一个事务?
| 属性值 | 含义 |
|---|---|
| REQUIRED | 【默认值】有父事务则加入,父子有异常则一起回滚;无父事务则创建新事务 |
| REQUIRES_NEW | 需要新事务,无论有无,总是创建新事务 |
-
REQUIRED :大部分情况下都是用该传播行为即可。
-
REQUIRES_NEW :当我们不希望事务之间相互影响时,可以使用该传播行为。比如:下订单前需要记录日志,不论订单保存成功与否,都需要保证日志记录能够记录成功。
@Transactional(propagation = Propagation.REQUIRES_NEW)
Spring事务日志开关
logging:
level:
org.springframework.jdbc.support.JdbcTransactionManager: debug
当你设置 debug 级别日志时,Spring 会打印出关于事务的详细信息,例如事务的开启、提交、回滚以及数据库操作。
总结
当 Service 层发生异常 时,Spring 会按照以下顺序处理:
- 事务的回滚:如果 Service 层抛出了一个异常(如
RuntimeException),并且这个方法是@Transactional注解标注的,Spring 会在方法抛出异常时 回滚事务。Spring 事务管理器会自动触发回滚操作。 - 异常传播到 Controller 层:如果异常在 Service 层处理后未被捕获,它会传播到 Controller 层(即调用
Service方法的地方)。 - 全局异常处理器:当异常传播到 Controller 层时,全局异常处理器(
@RestControllerAdvice或@ControllerAdvice)会捕获并处理该异常,返回给前端一个标准的错误响应。
AOP
AOP(Aspect-Oriented Programming,面向切面编程)是一种编程思想,旨在将横切关注点(如日志、性能监控等)从核心业务逻辑中分离出来。简单来说,AOP 是通过对特定方法的增强(如统计方法执行耗时)来实现代码复用和关注点分离。
实现业务方法执行耗时统计的步骤
- 定义模板方法:将记录方法执行耗时的公共逻辑提取到模板方法中。
- 记录开始时间:在方法执行前记录开始时间。
- 执行原始业务方法:中间部分执行实际的业务方法。
- 记录结束时间:在方法执行后记录结束时间,计算并输出执行时间。
通过 AOP,我们可以在不修改原有业务代码的情况下,完成对方法执行耗时的统计。
快速入门
实现步骤:
- 导入依赖:在pom.xml中导入AOP的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
- 编写AOP程序:针对于特定方法根据业务需要进行编程
@Component
@Aspect //当前类为切面类
@Slf4j
public class TimeAspect {
////第一个星号表示任意返回值,第二个星号表示类/接口,第三个星号表示所有方法。
@Around("execution(* edu.whut.zy123.service.*.*(..))")
public Object recordTime(ProceedingJoinPoint pjp) throws Throwable {
//记录方法执行开始时间
long begin = System.currentTimeMillis();
//执行原始方法
Object result = pjp.proceed();
//记录方法执行结束时间
long end = System.currentTimeMillis();
//计算方法执行耗时,pjp.getSignature()获得函数名
log.info(pjp.getSignature()+"执行耗时: {}毫秒",end-begin);
return result;
}
}
我们通过AOP入门程序完成了业务方法执行耗时的统计,那其实AOP的功能远不止于此,常见的应用场景如下:
- 记录系统的操作日志
- 权限控制
- 事务管理:我们前面所讲解的Spring事务管理,底层其实也是通过AOP来实现的,只要添加@Transactional注解之后,AOP程序自动会在原始方法运行前先来开启事务,在原始方法运行完毕之后提交或回滚事务
核心概念
1. 连接点:JoinPoint,可以被AOP控制的方法,代表方法的执行位置
2. 通知:Advice,指对目标方法的“增强”操作 (体现为额外的代码)
3. 切入点:PointCut,是一个表达式,匹配连接点的条件,它指定了 在目标方法的哪些位置插入通知,比如在哪些方法调用之前、之后、或者哪些方法抛出异常时进行增强。
4. 切面:Aspect,通知与切入点的结合
5.目标对象:Target,被 AOP 代理的对象,通知会作用到目标对象的对应方法上。
示例:
@Slf4j
@Component
@Aspect
public class MyAspect {
@Before("execution(* edu.whut.zy123.service.MyService.doSomething(..))")
public void beforeMethod(JoinPoint joinPoint) {
// 连接点:目标方法执行位置
System.out.println("Before method: " + joinPoint.getSignature().getName());
}
}
joinPoint 代表的是 doSomething() 方法执行的连接点。
beforeMethod() 方法就是一个前置通知
"execution(* com.example.service.MyService.doSomething(..))"是切入点
MyAspect是切面。
com.example.service.MyService 类的实例是目标对象
通知类型
- @Around:环绕通知。此通知会在目标方法前后都执行。
- @Before:前置通知。此通知在目标方法执行之前执行。
- @After :后置通知。此通知在目标方法执行后执行,无论方法是否抛出异常。
- @AfterReturning : 返回后通知。此通知在目标方法正常返回后执行,发生异常时不会执行。
- @AfterThrowing : 异常后通知。此通知在目标方法抛出异常后执行。
在使用通知时的注意事项:
- @Around 通知必须调用
ProceedingJoinPoint.proceed()才能执行目标方法,其他通知不需要。 - @Around 通知的返回值必须是
Object类型,用于接收原始方法的返回值。
通知执行顺序
-
默认情况下,不同切面类的通知执行顺序由类名的字母顺序决定。
-
可以通过
@Order注解指定切面类的执行顺序,数字越小,优先级越高。例如:
@Order(1)表示该切面类的通知优先执行。
@Aspect
@Order(1) // 优先级1
@Component
public class AspectOne {
@Before("execution(* edu.whut.zy123.service.MyService.*(..))")
public void beforeMethod() {
System.out.println("AspectOne: Before method");
}
}
@Aspect
@Order(2) // 优先级2
@Component
public class AspectTwo {
@Before("execution(* edu.whut.zy123.service.MyService.*(..))")
public void beforeMethod() {
System.out.println("AspectTwo: Before method");
}
}
如果调用 MyService 中的某个方法,AspectOne切面类中的通知会先执行。
结论:目标方法前的通知方法,Order小的或者类名的字母顺序在前的先执行。
目标方法后的通知方法,Order小的或者类名的字母顺序在前的后执行。
相对于显式设置(Order)的通知,默认通知的优先级最低。
切入点表达式
-
作用:主要用来决定项目中的哪些方法需要加入通知
-
常见形式:
- execution(……):根据方法的签名来匹配
- @annotation(……) :根据注解匹配
公共表示@Pointcut
使用 @Pointcut 注解可以将切点表达式提取到一个独立的方法中,提高代码复用性和可维护性。
@Aspect
@Component
public class LoggingAspect {
// 定义一个切点,匹配com.example.service包下 UserService 类的所有方法
@Pointcut("execution(public * com.example.service.UserService.*(..))")
public void userServiceMethods() {
// 该方法仅用来作为切点标识,无需实现任何内容
}
// 在目标方法执行前执行通知,引用上面的切点
@Before("userServiceMethods()")
public void beforeUserServiceMethods() {
System.out.println("【日志】即将执行 UserService 中的方法");
}
}
execution
execution主要根据方法的返回值、包名、类名、方法名、方法参数等信息来匹配,语法为:
execution(访问修饰符? 返回值 包名.类名.?方法名(方法参数) throws 异常?)
其中带?的表示可以省略的部分
-
访问修饰符:可省略(比如: public、protected)
-
包名.类名.: 可省略,但不建议
-
throws 异常:可省略(注意是方法上声明抛出的异常,不是实际抛出的异常)
示例:
//如果希望匹配 public void delete(Integer id)
@Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(java.lang.Integer))")
//如果希望匹配 public void delete(int id)
@Before("execution(void edu.whut.zy123.service.impl.DeptServiceImpl.delete(int))")
在 Pointcut 表达式中,为了确保匹配准确,通常建议对非基本数据类型使用全限定名。这意味着,对于像 Integer 这样的类,最好写成 java.lang.Integer
可以使用通配符描述切入点
*:单个独立的任意符号,可以通配任意返回值、包名、类名、方法名、任意类型的一个参数,也可以通配包、类、方法名的一部分
execution(* edu.*.service.*.update*(*))
这里update后面的'星'即通配方法名的一部分,()中的'星'表示有且仅有一个任意参数
可以匹配:
package edu.zju.service;
public class UserService {
public void updateUser(String username) {
// 方法实现
}
}
..:多个连续的任意符号,可以通配任意层级的包,或任意类型、任意个数的参数
execution(* com.example.service.UserService.*(..))
annotation
那么如果我们要匹配多个无规则的方法,比如:list()和 delete()这两个方法。我们可以借助于另一种切入点表达式annotation来描述这一类的切入点,从而来简化切入点表达式的书写。
实现步骤:
- 新建anno包,在这个包下编写自定义注解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
// 定义注解
@Retention(RetentionPolicy.RUNTIME) // 定义注解的生命周期
@Target(ElementType.METHOD) // 定义注解可以应用的Java元素类型
public @interface MyLog {
// 定义注解的元素(属性)
String description() default "This is a default description";
int value() default 0;
}
- 在业务类要做为连接点的方法上添加自定义注解
@MyLog //自定义注解(表示:当前方法属于目标方法)
public void delete(Integer id) {
//1. 删除部门
deptMapper.delete(id);
}
- AOP切面类上使用类似如下的切面表达式:
@Before("@annotation(edu.whut.anno.MyLog)")
连接点JoinPoint
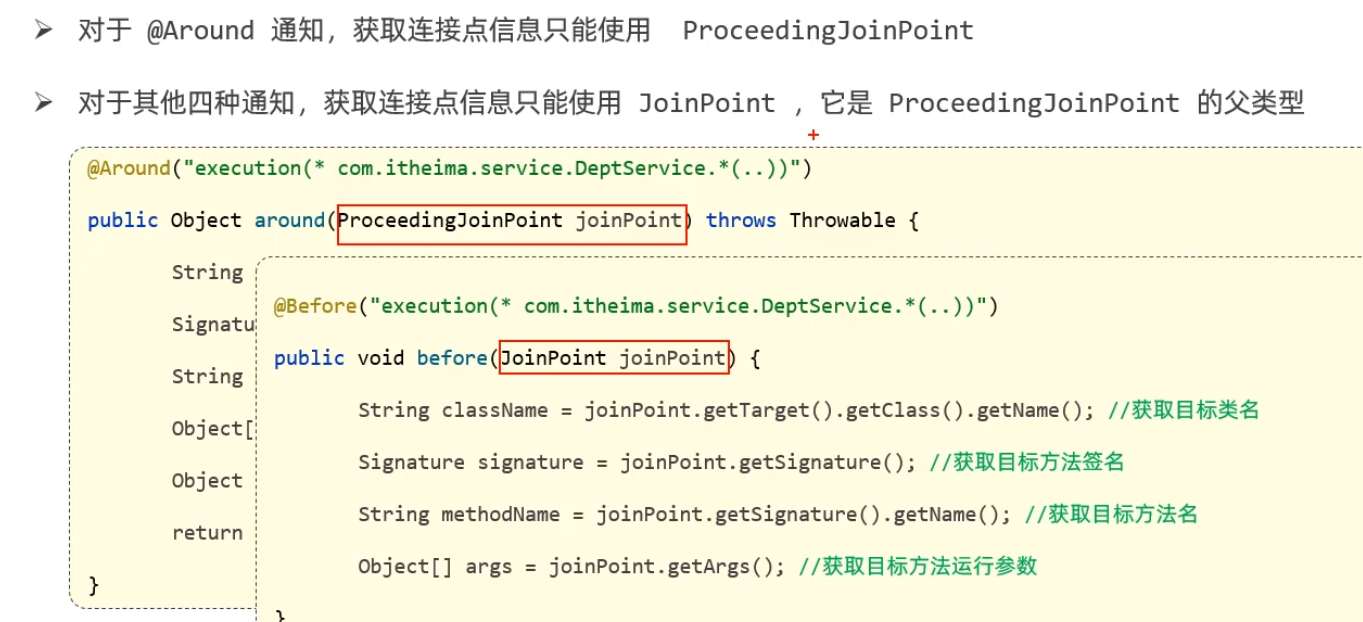
执行: ProceedingJoinPoint和 JoinPoint 都是调用 proceed() 就会执行被代理的方法
Object result = joinPoint.proceed();
获取调用方法时传递的参数,即使只有一个参数,也以数组形式返回:
Object[] args = joinPoint.getArgs();
getSignature(): 返回一个Signature类型的对象,这个对象包含了被拦截点的签名信息。在方法调用的上下文中,这包括了方法的名称、声明类型等信息。
- 方法名称:可以通过调用
getName()方法获得。 - 声明类型:方法所在的类或接口的完全限定名,可以通过
getDeclaringTypeName()方法获取。 - 返回类型(对于方法签名):可以通过将
Signature对象转换为更具体的MethodSignature类型,并调用getReturnType()方法获取。
WEB开发总体图