1831 lines
69 KiB
Markdown
1831 lines
69 KiB
Markdown
# 拼团交易系统
|
||
|
||
## 系统备忘录
|
||
|
||
本系统涉及微信和支付宝的回调。
|
||
|
||
1.微信扫码登录,*https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index*平台上配置了扫描通知地址,如果是本地测试,需要打开frp内网穿透,然后填的地址是frp建立通道的服务器端的ip:端口
|
||
|
||
2.支付宝,用户付款成功回调,也是同理,本地测试就要开frp。注意frp中的通道,默认是本地端口=远程端口,但是如果在服务器上部署了一套,那么远程的端口就会与frp的端口冲突!!!导致本地测试的时候失效。
|
||
|
||
|
||
|
||
流程:
|
||
|
||
用户锁单-》支付宝付款-》成功后return_url设置了用户支付完毕后跳转回哪个地址是给前端用户看的; alipay_notify_url设置了支付成功后alipay调用你的后端哪个接口。
|
||
|
||
这里有小商城和拼团系统,notify_url指拼团系统中拼团达到指定人数后,通知小商城的地址,这里用rabbitmq。然后小商场将订单中相应拼团的status都设置为deal_done。然后小商场内部也再发一个'支付成功'消息,主要用于通知这些拼团对应的订单进入下一环节:发货(感觉'支付成功'取名不够直观)。
|
||
|
||
|
||
|
||
|
||
|
||
## 系统设计
|
||
|
||
### **功能流程**
|
||
|
||
|
||
|
||
|
||
|
||
### **库表设计**
|
||
|
||
|
||
|
||
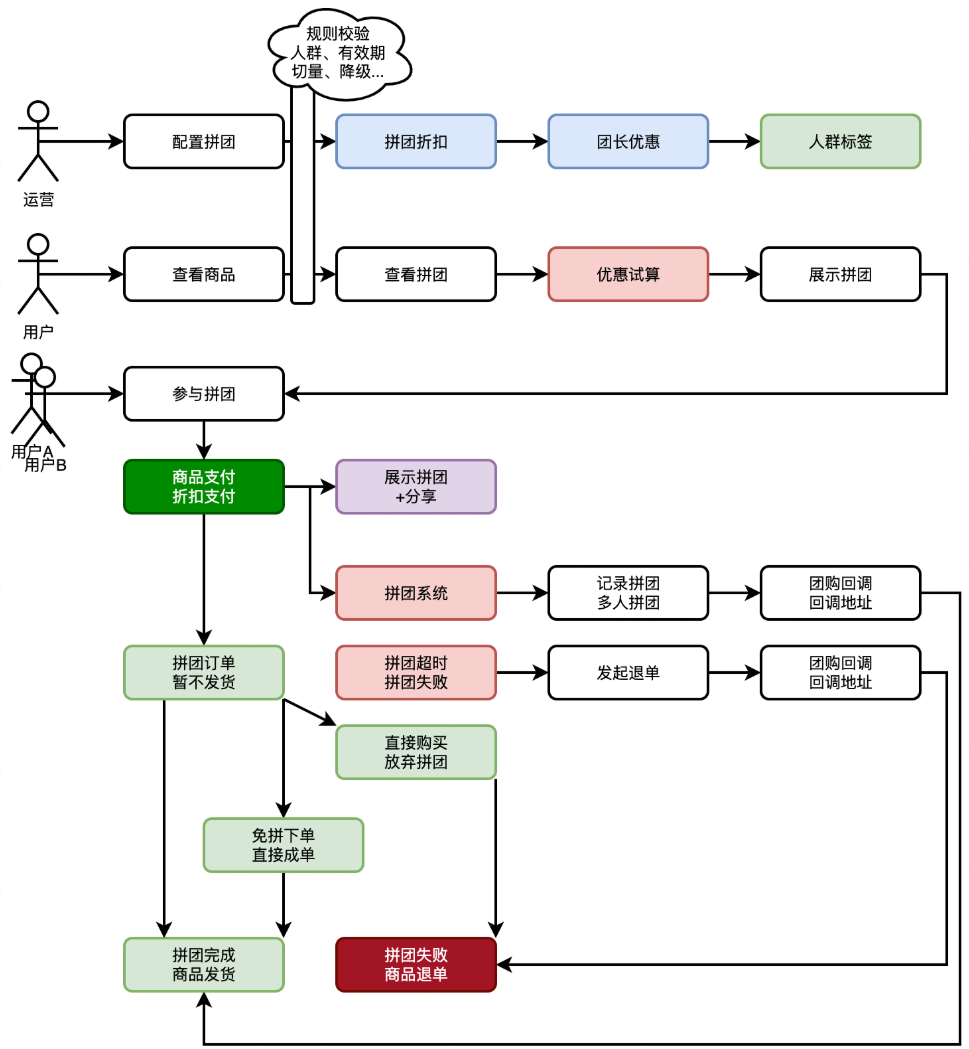
- 首先,站在**运营**的角度,要为这次拼团配置对应的**拼团活动**。那么就会涉及到;给哪个渠道的**什么商品**ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商**品所提供的规则信息**,包括:折扣、起止时间、人数等。还要拿到折扣的一个**试算金额**。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。
|
||
- 之后,站在**用户**的角度,是参与拼团。首次**发起一个拼团**或者**参与已存在的拼团**进行数据的记录,达成拼团约定拼团人数后,开始进行**通知**。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
|
||
- 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Redis,并为这批用户打上可配置的**人群标签**。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。
|
||
- 那么,拼团活动表,为什么会把**折扣拆分**出来呢。因为这里的折扣**可能有多种**迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。
|
||
|
||
|
||
|
||
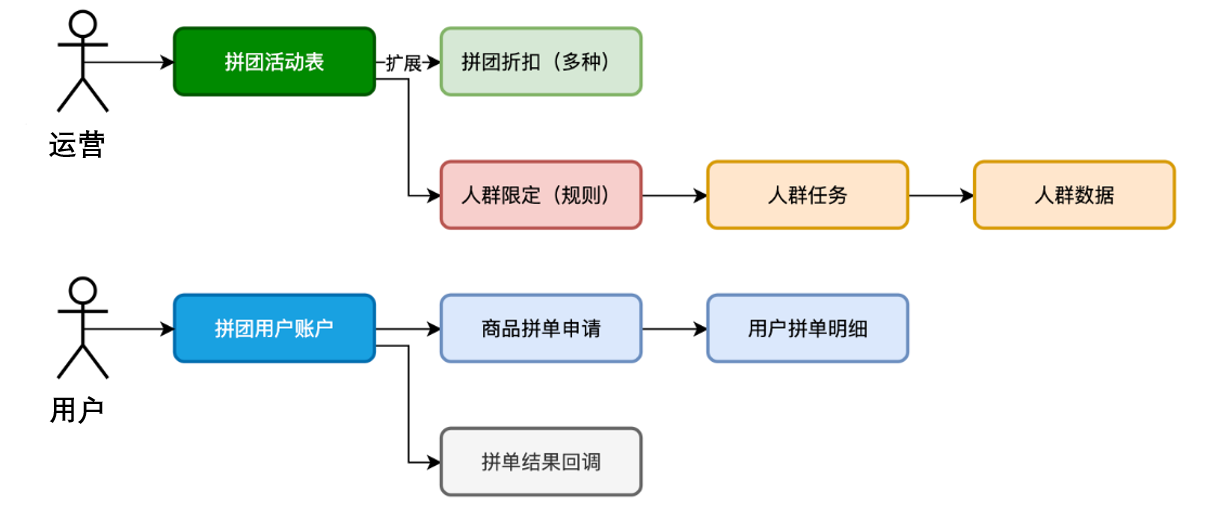
**(一)拼团配置表**
|
||
|
||
group_buy_activity 拼团活动
|
||
|
||
| 字段名 | 说明 |
|
||
| ---------------- | -------------------------------------------------------- |
|
||
| id | 自增ID |
|
||
| activity_id | 活动ID |
|
||
| source | 来源 |
|
||
| channel | 渠道 |
|
||
| goods_id | 商品ID |
|
||
| discount_id | 折扣ID |
|
||
| group_type | 成团方式【0自动成团(到时间后自动成团)、1达成目标成团】 |
|
||
| take_limit_count | 拼团次数限制 |
|
||
| target | 达成目标(3人单、5人单) |
|
||
| valid_time | 拼单时长(20分钟),未完成拼团则=》自动成功or失败 |
|
||
| status | 活动状态 (活动是否有效,运营可临时设置为失效) |
|
||
| start_time | 活动开始时间 |
|
||
| end_time | 活动结束时间 |
|
||
| tag_id | 人群标签规则标识 |
|
||
| tag_scope | 人群标签规则范围【多选;可见、参与】 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
group_buy_discount 折扣配置
|
||
|
||
| 字段名 | 说明 |
|
||
| ------------- | --------------------------------- |
|
||
| id | 自增ID |
|
||
| discount_id | 折扣ID |
|
||
| discount_name | 折扣标题 |
|
||
| discount_desc | 折扣描述 |
|
||
| discount_type | 类型【base、tag】 |
|
||
| market_plan | 营销优惠计划【直减、满减、N元购】 |
|
||
| market_expr | 营销优惠表达式 |
|
||
| tag_id | 人群标签,特定优惠限定 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags 人群标签
|
||
|
||
| 字段名 | 说明 |
|
||
| ----------- | ----------------------------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| tag_name | 标签名称 |
|
||
| tag_desc | 标签描述 |
|
||
| statistics | 人群标签统计量 200\10万\100万 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags_detail 人群标签明细(写入缓存)
|
||
|
||
| 字段名 | 说明 |
|
||
| ----------- | -------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| user_id | 用户ID |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
crowd_tags_job 人群标签任务
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------- | ---------------------------- |
|
||
| id | 自增ID |
|
||
| tag_id | 标签ID |
|
||
| batch_id | 批次ID |
|
||
| tag_type | 标签类型【参与量、消费金额】 |
|
||
| tag_rule | 标签规则【限定参与N次】 |
|
||
| stat_start_time | 统计开始时间 |
|
||
| stat_end_time | 统计结束时间 |
|
||
| status | 计划、重置、完成 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
- 拼团活动表:设定了拼团的成团规则,人群标签的使用可以限定哪些人可见,哪些人可参与。
|
||
- 折扣配置表:拆分出拼团优惠到一个新的表进行多条配置。如果折扣还有更多的复杂规则,则可以配置新的折扣规则表进行处理。
|
||
- 人群标签表:专门来做人群设计记录的,这3张表就是为了把符合规则的人群ID,也就是用户ID,全部跑任务到一个记录下进行使用。比如黑玫瑰人群、高净值人群、拼团履约率90%以上的人群等。
|
||
|
||
|
||
|
||
**(二)参与拼团表**
|
||
|
||
**group_buy_account 拼团账户**
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------------- | ------------ |
|
||
| id | 自增ID |
|
||
| user_id | 用户ID |
|
||
| activity_id | 活动ID |
|
||
| take_limit_count | 拼团次数限制 |
|
||
| take_limit_count_used | 拼团次数消耗 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
**group_buy_order 用户拼单**
|
||
|
||
一条记录 = 一个拼团**团队**(`team_id` 唯一)
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------- | -------------------------------- |
|
||
| id | 自增ID |
|
||
| team_id | 拼单组队ID |
|
||
| activity_id | 活动ID |
|
||
| source | 渠道 |
|
||
| channel | 来源 |
|
||
| original_price | 原始价格 |
|
||
| deduction_price | 折扣金额 |
|
||
| pay_price | 支付价格 |
|
||
| target_count | 目标数量 |
|
||
| complete_count | 完成数量 |
|
||
| status | 状态(0-拼单中、1-完成、2-失败) |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
**group_buy_order_list 用户拼单明细**
|
||
|
||
一条记录 = **某用户**在该团队里锁的一笔单
|
||
|
||
| 字段名 | 说明 |
|
||
| --------------- | ------------------------------------ |
|
||
| id | 自增ID |
|
||
| user_id | 用户ID |
|
||
| team_id | 拼单组队ID |
|
||
| order_id | 订单ID |
|
||
| activity_id | 活动ID |
|
||
| start_time | 活动开始时间 |
|
||
| end_time | 活动结束时间 |
|
||
| goods_id | 商品ID |
|
||
| source | 渠道 |
|
||
| channel | 来源 |
|
||
| original_price | 原始价格 |
|
||
| deduction_price | 折扣金额 |
|
||
| status | 状态;0 初始锁定、1 消费完成 |
|
||
| out_trade_no | 外部交易单号(确保外部调用唯一幂等) |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
**notify_task 回调任务**
|
||
|
||
| 字段名 | 说明 |
|
||
| -------------- | ---------------------------------- |
|
||
| id | 自增ID |
|
||
| activity_id | 活动ID |
|
||
| order_id | 拼单ID |
|
||
| notify_url | 回调接口 |
|
||
| notify_count | 回调次数(3-5次) |
|
||
| notify_status | 回调状态【初始、完成、重试、失败】 |
|
||
| parameter_json | 参数对象 |
|
||
| create_time | 创建时间 |
|
||
| update_time | 更新时间 |
|
||
|
||
- 拼团账户表:记录用户的拼团参与数据,一个是为了限制用户的参与拼团次数,另外是为了人群标签任务统计数据。
|
||
- 用户拼单表:当有用户发起首次拼单的时候,产生拼单id,并记录所需成团的拼单记录,另外是写上拼团的状态、唯一索引、回调接口等。这样拼团完成就可以回调对接的平台,通知完成了。【微信支付也是这样的设计,回调支付结果,这样的设计可以方便平台化对接】当再有用户参与后,则写入用户拼单明细表。直至达成拼团。
|
||
- 回调任务表:当拼团完成后,要做回调处理。但可能会有失败,所以加入任务的方式进行补偿。如果仍然失败,则需要对接的平台,自己查询拼团结果。
|
||
|
||
|
||
|
||
### 架构设计
|
||
|
||
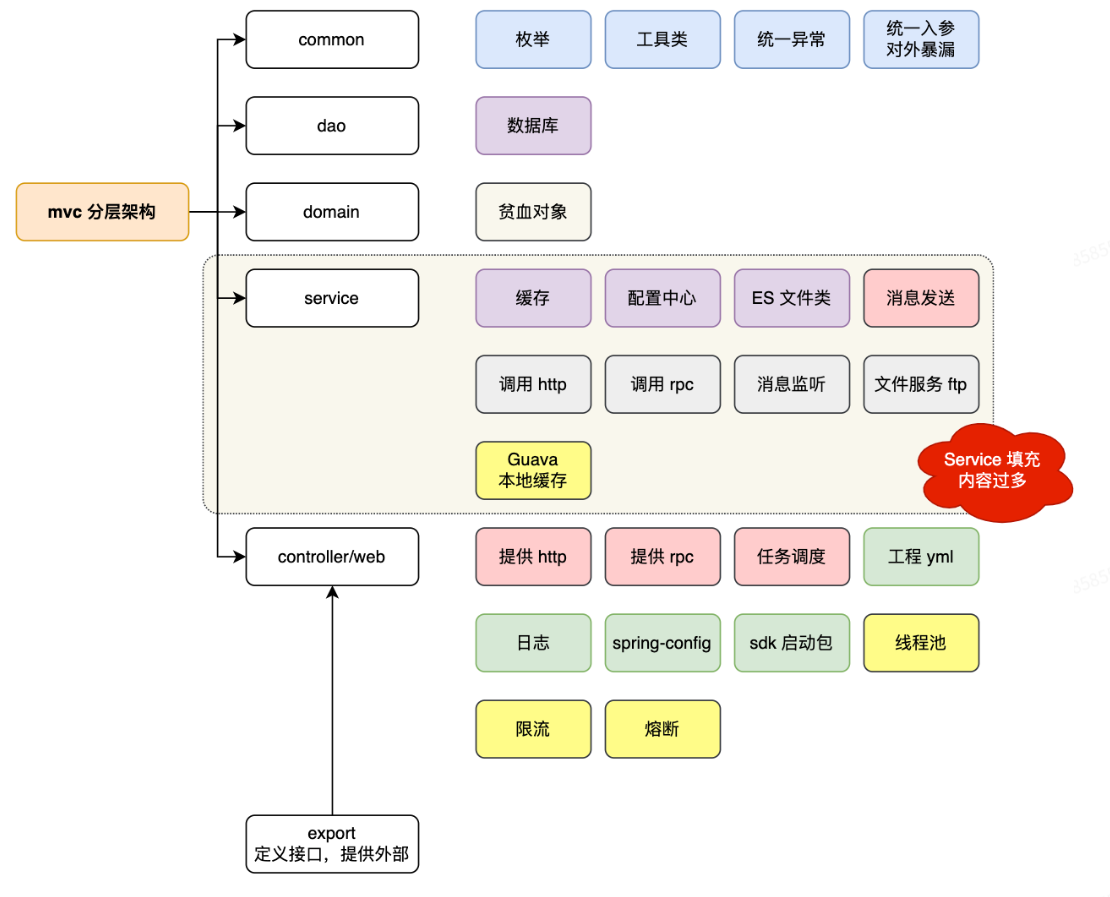
**MVC架构:**
|
||
|
||
|
||
|
||
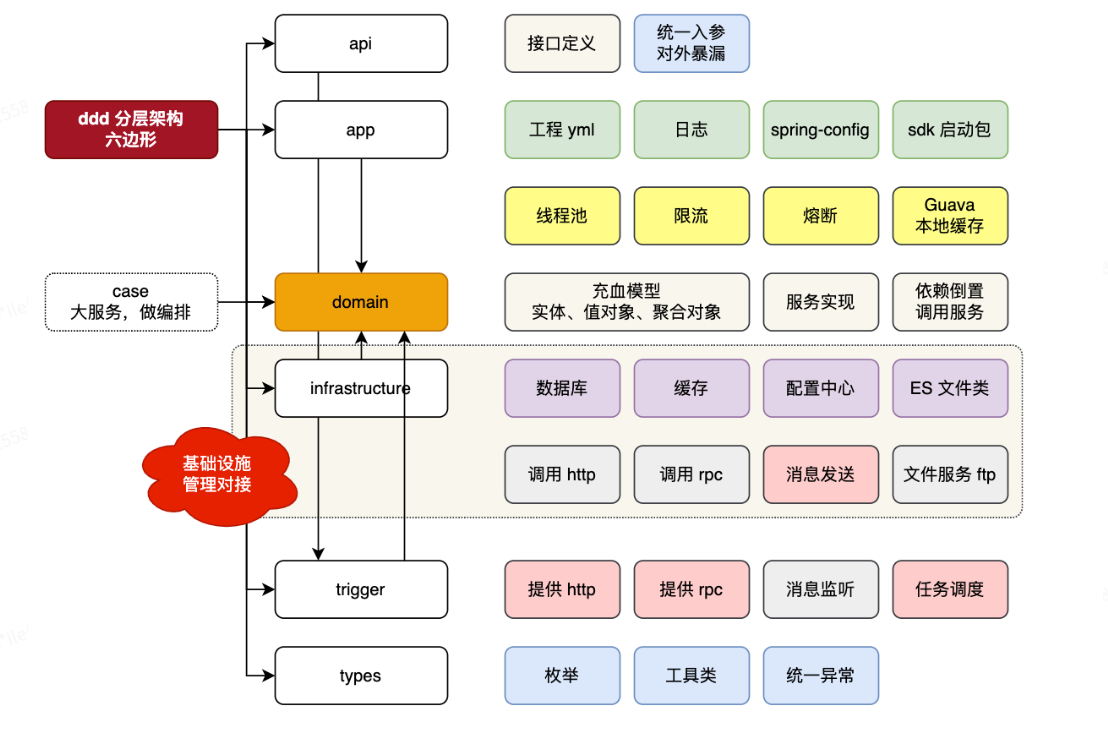
**DDD架构:**
|
||
|
||
|
||
|
||
|
||
|
||
## 价格试算
|
||
|
||
```java
|
||
@Service
|
||
@RequiredArgsConstructor
|
||
public class IndexGroupBuyMarketServiceImpl implements IIndexGroupBuyMarketService {
|
||
|
||
private final DefaultActivityStrategyFactory defaultActivityStrategyFactory;
|
||
|
||
@Override
|
||
public TrialBalanceEntity indexMarketTrial(MarketProductEntity marketProductEntity) throws Exception {
|
||
|
||
StrategyHandler<MarketProductEntity, DefaultActivityStrategyFactory.DynamicContext, TrialBalanceEntity> strategyHandler = defaultActivityStrategyFactory.strategyHandler();
|
||
|
||
TrialBalanceEntity trialBalanceEntity = strategyHandler.apply(marketProductEntity, new DefaultActivityStrategyFactory.DynamicContext());
|
||
|
||
return trialBalanceEntity;
|
||
}
|
||
|
||
}
|
||
```
|
||
|
||
```text
|
||
IndexGroupBuyMarketService
|
||
│
|
||
│ indexMarketTrial()
|
||
▼
|
||
DefaultActivityStrategyFactory
|
||
│ (return rootNode)
|
||
▼
|
||
RootNode.apply()
|
||
│ doApply() (执行)
|
||
│ router() (路由到下一node)
|
||
▼
|
||
SwitchNode.apply()
|
||
│ ...
|
||
▼
|
||
... (可能还有其他节点)
|
||
▼
|
||
EndNode.apply() → 组装结果并返回 TrialBalanceEntity
|
||
▲
|
||
└────────── 最终一路向上 return
|
||
|
||
```
|
||
|
||
`IndexGroupBuyMarketService` 是领域服务,整个价格试算的入口
|
||
|
||
`DefaultActivityStrategyFactory` 帮你拿到 *根节点*,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。
|
||
|
||
`DynamicContext` 是一次性创建的共享上下文:谁需要谁就往里放
|
||
|
||
|
||
|
||
## 人群标签数据采集
|
||
|
||
| 步骤 | 目的 | 说明 |
|
||
| ------------------- | ----------------------------------------------- | ------------------------------------------------------------ |
|
||
| **1. 记录日志** | 标明本次批次任务的开始 | 方便后续排查、链路追踪 |
|
||
| **2. 读取批次配置** | 拿到该批次**统计范围、规则、时间窗**等 | 若返回 `null` 通常代表批次号错误或已被清理 |
|
||
| **3. 采集候选用户** | 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 | 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 |
|
||
| **4. 双写标签明细** | 将每个用户与标签的关系永久化 & 提供实时校验能力 | 方法内部两件事:• 插入 `crowd_tags_detail` 表• <br />在 Redis **BitMap** 中把该用户对应位设为 1(幂等处理冲突) |
|
||
| **5. 更新统计量** | 维护标签当前命中人数,用于运营看板 | 这里简单按“新增条数”累加,也可改为重新 `count(*)` 全量回填 |
|
||
| **6. 结束** | 方法返回 void | 如果过程抛异常,调度系统可重试/报警 |
|
||
|
||
> **一句话总结**
|
||
> 这是一个被定时器或消息触发的**离线批量打标签任务**:
|
||
> 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。
|
||
> 之后业务系统就能用位图做到毫秒级 `isUserInTag(userId, tagId)` 判断,实现精准运营投放。
|
||
|
||
|
||
|
||
### Bitmap(位图)
|
||
|
||
**概念**
|
||
|
||
- Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。
|
||
- 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。
|
||
|
||
**为什么用 Bitmap?**
|
||
|
||
- **超高空间效率**:1000 万个用户,只需要约 10 MB(1000 万 / 8)。
|
||
- **超快操作**:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。
|
||
|
||
**典型场景**
|
||
|
||
- **用户标签 / 权限判断**:把符合某个条件的用户的索引位置设置为 1,以后实时判断“用户 X 是否在标签 A 中?”就只需读一个 bit。
|
||
- **海量去重 / 布隆过滤器**:在超大流量场景下判断“URL 是否已访问过”、“手机号是否已注册”等。
|
||
- **统计分析**:快速统计某个条件下有多少个用户/对象符合(BITCOUNT)。
|
||
|
||
|
||
|
||
## 拼团交易锁单
|
||
|
||
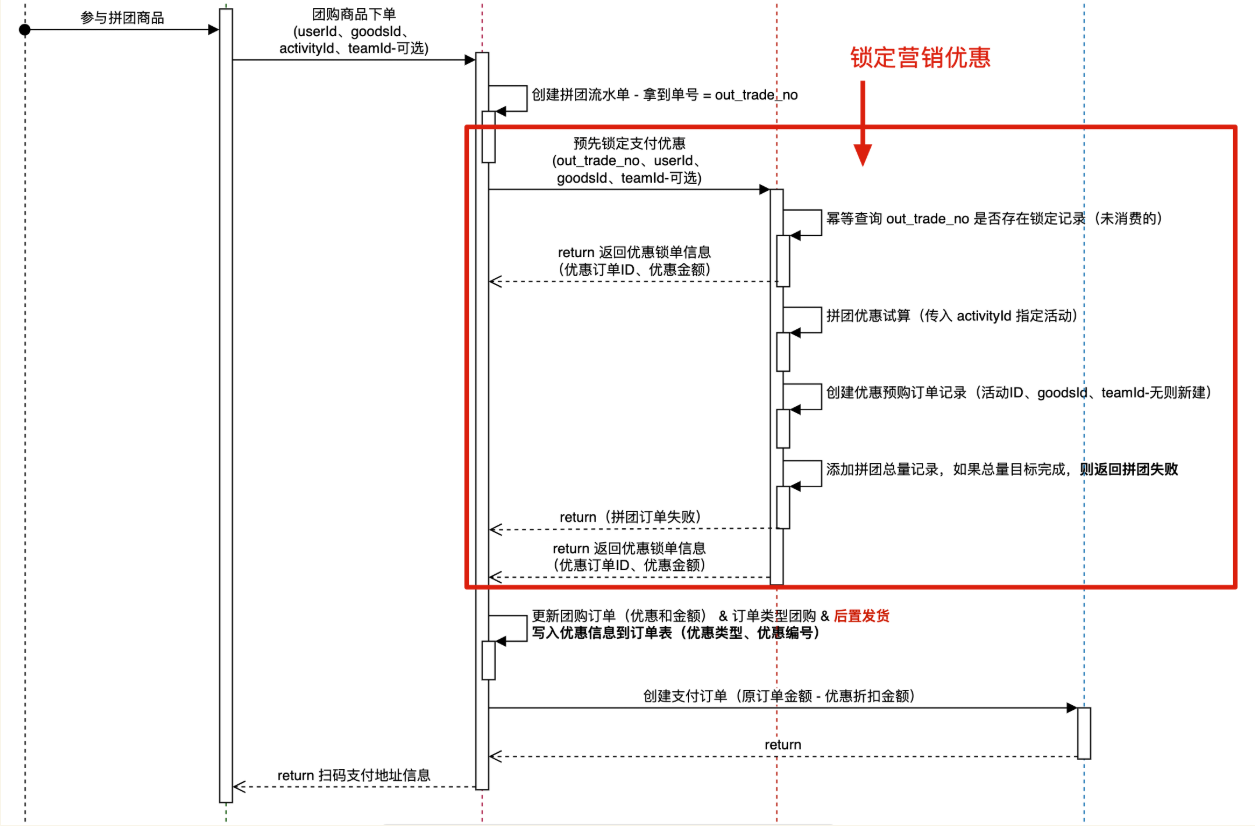
|
||
|
||
下单到支付中间有一个流程,即锁单,比如淘宝京东中,在这个环节(限定时间内)选择使用优惠券、京豆等,可以得到优惠价,再进行支付;拼团场景同理,先加入拼团,进行锁单,然后优惠试算,最后才付款。
|
||
|
||
|
||
|
||
## 拼团结算
|
||
|
||
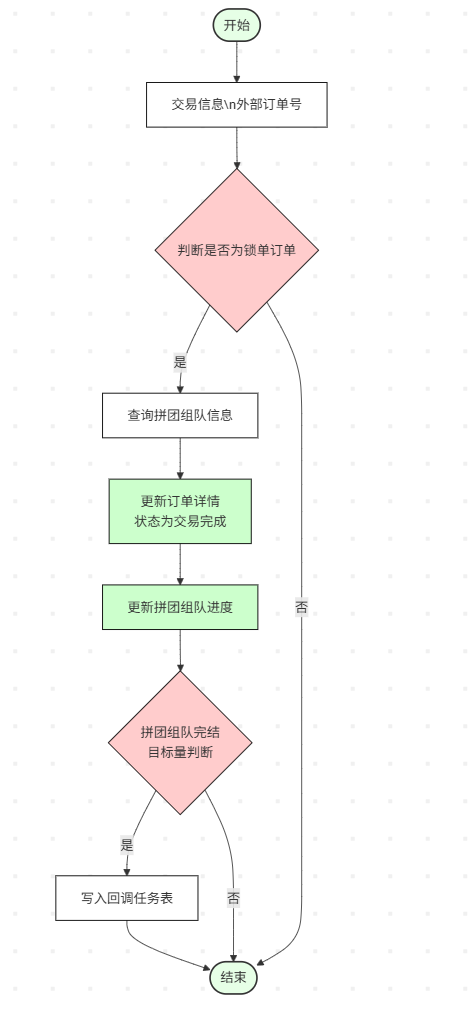
|
||
|
||
|
||
|
||
## 对接商城和拼团系统
|
||
|
||
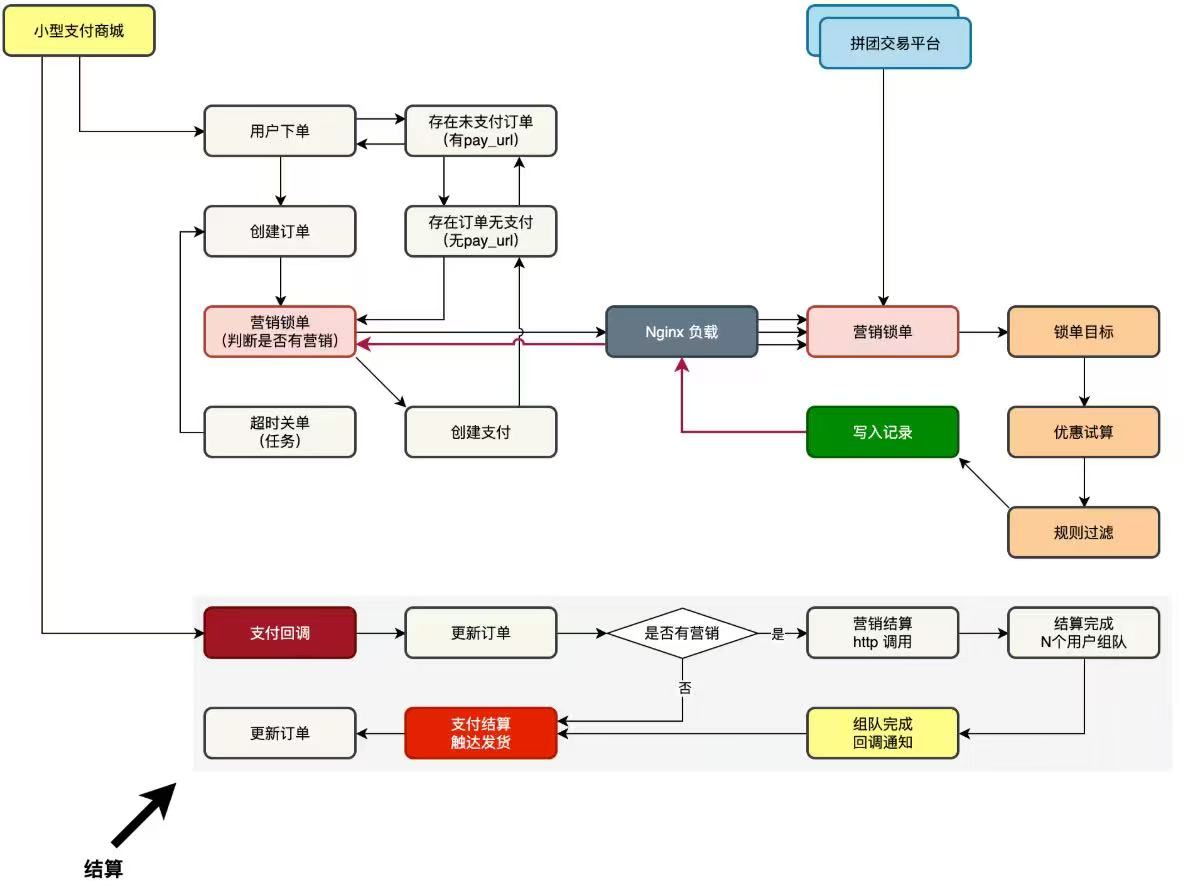
|
||
|
||
上面左侧,小型支付商城,用户下单过程。增加一个营销锁单,从营销锁单中获取拼团营销拿到的优惠价格。之后小型商城继续往下走,创建支付订单。右侧,拼团交易平台,提供营销锁单流程,锁单目标、优惠试算,规则过滤,最终落库和返回结果(订单ID、原始价格、折扣金额、支付金额、订单状态)。
|
||
|
||
下面小型支付商城在用户完成支付后,调用拼团**组队结算**,更新当前xx拼团完成人数,当拼团完成后**接收**回调消息执行后续交易结算发货(暂时模拟的)。
|
||
|
||
|
||
|
||
**注意**两个回调函数不要搞混:1:alipay_notify_url,用户支付成功后支付宝的回调,为后端服务设定的回调地址,支付宝告诉pay-mall当前用户支付完毕,可以调用拼团**组队结算**。return_rul,用户付款后自动跳转到的地址,即跳转回首页,和前端跳转有关。gateway-url,支付宝提供的本商家的用户付款地址。
|
||
|
||
2:group-buy-market_notify-url,由pay-mall商城设置的回调,某teamId拼团达到目标人数时,拼团成功会触发该回调,告诉pay-mall可以进行下一步动作,比如给该teamId下的所有人发货。
|
||
|
||
|
||
|
||
### 本地对接
|
||
|
||
在 `group-buying-sys` 项目中,对 `group-buying-api` 模块执行 `mvn clean install`(或在 IDE 中运行 install)。这会将该模块的 jar 安装到本地 Maven 仓库(`~/.m2/repository`)。然后在 `pay-mall` 项目的 `pom.xml` 中添加依赖,使用相同的 `groupId`、`artifactId` 和 `version` 即可引用该模块,如下所示:
|
||
|
||
```xml
|
||
<dependency>
|
||
<groupId>edu.whut</groupId>
|
||
<artifactId>group-buying-api</artifactId>
|
||
<version>1.0.0-SNAPSHOT</version>
|
||
</dependency>
|
||
|
||
```
|
||
|
||
### 发包
|
||
|
||
仅适用于本地,共用一个本地Maven仓库,一旦换台电脑或者在云服务器上部署,无法就这样引入,因此可以进行发包。这里使用阿里云效发包https://packages.aliyun.com/
|
||
|
||
1)点击制品仓库->生产库
|
||
|
||
|
||
|
||
2)下载settings-aliyun.xml文件并保存至本地的Maven的conf文件夹中。
|
||
|
||
|
||
|
||
3) 配置项目的Maven仓库为阿里云提供的这个,而不是自己的本地仓库。
|
||
|
||

|
||
|
||
4)发包,打开Idea中的Maven,双击deploy
|
||
|
||
|
||
|
||
5)验证
|
||
|
||
|
||
|
||
6)使用
|
||
|
||
将公共镜像仓库的settings文件和阿里云效的settings文件合并,可以同时拉取公有依赖和私有包。
|
||
|
||
|
||
|
||
## 逆向工程:退单
|
||
|
||
<img src="https://pic.bitday.top/i/2025/07/25/hgggjo-0.png" alt="image-20250725105608390" style="zoom:67%;" />
|
||
|
||
逆向的流程,要分析用户是在哪个流程节点下进行中断行为。包括3个场景;
|
||
|
||
**已锁单、未支付**
|
||
|
||
- **用户行为**:完成锁单后未发起支付。
|
||
- **结果**:订单超时自动关单。
|
||
- 补偿
|
||
- 若用户在临界时刻支付,则需执行“逆向退款”流程——退还支付金额并告知“优惠已过期,请重新参与”。
|
||
- 否则该订单自动失效,释放拼团名额给后续用户。
|
||
|
||
**已锁单、已支付,但拼团未成团**
|
||
|
||
- **用户行为**:完成支付,组团人数不足暂未成团。
|
||
|
||
- 补偿策略
|
||
|
||
(可配置优先级):
|
||
|
||
1. **先退拼团,再退款,**
|
||
2. **先退款,再退拼团**
|
||
|
||
- 具体执行哪种方式,可由拼团活动策略决定——“优先保障个人”或“优先保障成团”。
|
||
|
||
**已锁单、已支付,且拼团已成团**
|
||
|
||
- **用户行为**:支付成功,且组团人数已凑齐。
|
||
- 补偿流程
|
||
- 先退还用户支付金额;
|
||
- 再撤销对应的拼团完成量。
|
||
- **注意**:已成团订单视为“已完成含退单”,仍然成团、不再开放新用户参与,确保团队成团状态一致。
|
||
|
||
|
||
|
||
### 策略模板应用
|
||
|
||
根据订单状态和拼团状态动态选择退单策略。
|
||
|
||
|
||
|
||
|
||
|
||
## 收获
|
||
|
||
### 实体对象
|
||
|
||
实体是指具有唯一标识的业务对象。
|
||
|
||
在 DDD 分层里,**Domain Entity ≠ 数据库 PO**。
|
||
在 `edu.whut.domain.*.model.entity` 包下放的是**纯粹的业务对象**,它们只表达业务语义(团队 ID、活动时间、优惠金额……),对「数据持久化细节」保持**无感知**。因此它们看起来“字段不全”是正常的:
|
||
|
||
- 它们不会带 `@TableName` / `@TableId` 等 MyBatis-Plus 注解;
|
||
- 也不会出现数据库的技术字段(`id`、`create_time`、`update_time`、`status` 等);
|
||
- 只保留聚合根真正**需要的**业务属性与行为。
|
||
|
||
```java
|
||
@Data
|
||
@Builder
|
||
@AllArgsConstructor
|
||
@NoArgsConstructor
|
||
public class PayActivityEntity {
|
||
|
||
/** 拼单组队ID */
|
||
private String teamId;
|
||
/** 活动ID */
|
||
private Long activityId;
|
||
/** 活动名称 */
|
||
private String activityName;
|
||
/** 拼团开始时间 */
|
||
private Date startTime;
|
||
/** 拼团结束时间 */
|
||
private Date endTime;
|
||
/** 目标数量 */
|
||
private Integer targetCount;
|
||
|
||
}
|
||
```
|
||
|
||
这个也是实体对象,因为多个字段的组合:teamId和activityId能唯一标识这个实体。
|
||
|
||
|
||
|
||
### 模板方法
|
||
|
||
**核心思想**:
|
||
在抽象父类中定义**算法骨架**(固定执行顺序),把某些可变步骤留给子类重写;调用方只用模板方法,保证流程一致。
|
||
|
||
```text
|
||
Client ───▶ AbstractClass
|
||
├─ templateMethod() ←—— 固定流程
|
||
│ step1()
|
||
│ step2() ←—— 抽象,可变
|
||
│ step3()
|
||
└─ hookMethod() ←—— 可选覆盖
|
||
▲
|
||
│ extends
|
||
┌──────────┴──────────┐
|
||
│ ConcreteClassA/B… │
|
||
|
||
```
|
||
|
||
**示例:**
|
||
|
||
```java
|
||
// 1. 抽象模板
|
||
public abstract class AbstractDialog {
|
||
|
||
// 模板方法:固定调用顺序,设为 final 防止子类改流程
|
||
public final void show() {
|
||
initLayout();
|
||
bindEvent();
|
||
beforeDisplay(); // 钩子,可选
|
||
display();
|
||
afterDisplay(); // 钩子,可选
|
||
}
|
||
|
||
// 具体公共步骤
|
||
private void initLayout() {
|
||
System.out.println("加载通用布局文件");
|
||
}
|
||
|
||
// 需要子类实现的抽象步骤
|
||
protected abstract void bindEvent();
|
||
|
||
// 钩子方法,默认空实现
|
||
protected void beforeDisplay() {}
|
||
protected void afterDisplay() {}
|
||
|
||
private void display() {
|
||
System.out.println("弹出对话框");
|
||
}
|
||
}
|
||
|
||
// 2. 子类:登录对话框
|
||
public class LoginDialog extends AbstractDialog {
|
||
@Override
|
||
protected void bindEvent() {
|
||
System.out.println("绑定登录按钮事件");
|
||
}
|
||
@Override
|
||
protected void afterDisplay() {
|
||
System.out.println("focus 到用户名输入框");
|
||
}
|
||
}
|
||
|
||
// 3. 调用
|
||
public class Demo {
|
||
public static void main(String[] args) {
|
||
AbstractDialog dialog = new LoginDialog();
|
||
dialog.show();
|
||
/* 输出:
|
||
加载通用布局文件
|
||
绑定登录按钮事件
|
||
弹出对话框
|
||
focus 到用户名输入框
|
||
*/
|
||
}
|
||
}
|
||
```
|
||
|
||
**要点**
|
||
|
||
- **复用公共流程**:`initLayout()`、`display()` 写一次即可。
|
||
- **限制流程顺序**:`show()` 定为 `final`,防止子类乱改步骤。
|
||
- **钩子方法**:子类可选择性覆盖(如 `beforeDisplay`)。
|
||
|
||
|
||
|
||
### 责任链
|
||
|
||
应用场景:日志系统、审批流程、权限校验——任何需要将请求按阶段传递、并由某一环节决定是否继续或终止处理的地方,都非常适合职责链模式。
|
||
|
||
#### 单例链
|
||
|
||
典型的责任链模式要点:
|
||
|
||
- **解耦请求发送者和处理者**:调用者只持有链头,不关心中间环节。
|
||
- **动态组装**:通过 `appendNext` 可以灵活地增加、删除或重排链上的节点。
|
||
- **可扩展**:新增处理逻辑只需继承 `AbstractLogicLink` 并实现 `apply`,不用改动已有代码。
|
||
|
||
接口定义:`ILogicChainArmory<T, D, R>` 提供添加节点方法和获取节点
|
||
|
||
```java
|
||
//定义了责任链的组装接口:
|
||
public interface ILogicChainArmory<T, D, R> {
|
||
|
||
ILogicLink<T, D, R> next(); //在当前节点中获取下一个节点
|
||
|
||
ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next); //把下一个处理节点挂接上来
|
||
|
||
}
|
||
```
|
||
|
||
`ILogicLink<T, D, R>` 继承自 `ILogicChainArmory<T, D, R>`,并额外声明了核心方法 `apply`
|
||
|
||
```java
|
||
public interface ILogicLink<T, D, R> extends ILogicChainArmory<T, D, R> {
|
||
|
||
R apply(T requestParameter, D dynamicContext) throws Exception; //处理请求
|
||
|
||
}
|
||
```
|
||
|
||
抽象基类:`AbstractLogicLink`
|
||
|
||
```java
|
||
public abstract class AbstractLogicLink<T, D, R> implements ILogicLink<T, D, R> {
|
||
|
||
private ILogicLink<T, D, R> next;
|
||
|
||
@Override
|
||
public ILogicLink<T, D, R> next() {
|
||
return next;
|
||
}
|
||
|
||
@Override
|
||
public ILogicLink<T, D, R> appendNext(ILogicLink<T, D, R> next) {
|
||
this.next = next;
|
||
return next;
|
||
}
|
||
|
||
protected R next(T requestParameter, D dynamicContext) throws Exception {
|
||
return next.apply(requestParameter, dynamicContext); //交给下一节点处理
|
||
}
|
||
|
||
}
|
||
```
|
||
|
||
子类只需继承它,重写 `apply(...)`,在合适的条件下要么直接处理并返回,要么调用 `next(requestParameter, dynamicContext)` 继续传递。
|
||
|
||
**使用示例:**
|
||
|
||
```java
|
||
public class AuthLink extends AbstractLogicLink<Request, Context, Response> {
|
||
@Override
|
||
public Response apply(Request req, Context ctx) throws Exception {
|
||
if (!ctx.isAuthenticated()) {
|
||
throw new UnauthorizedException();
|
||
}
|
||
// 认证通过,继续下一个环节
|
||
return next(req, ctx);
|
||
}
|
||
}
|
||
|
||
public class LoggingLink extends AbstractLogicLink<Request, Context, Response> {
|
||
@Override
|
||
public Response apply(Request req, Context ctx) throws Exception {
|
||
System.out.println("Request received: " + req);
|
||
Response resp = next(req, ctx);
|
||
System.out.println("Response sent: " + resp);
|
||
return resp;
|
||
}
|
||
}
|
||
|
||
// 组装责任链 放工厂类factory中实现
|
||
ILogicLink<Request, Context, Response> chain =
|
||
new AuthLink()
|
||
.appendNext(new LoggingLink())
|
||
.appendNext(new BusinessLogicLink());
|
||
|
||
//客户端使用
|
||
Request req = new Request(...);
|
||
Context ctx = new Context(...);
|
||
Response resp = chain.apply(req, ctx);
|
||
```
|
||
|
||
示例图:
|
||
|
||
```text
|
||
AuthLink.apply
|
||
└─▶ LoggingLink.apply
|
||
└─▶ BusinessLogicLink.apply
|
||
└─▶ 返回 Response
|
||
```
|
||
|
||
这种模式链上的每个节点都手动 `next()`到下一节点。
|
||
|
||
|
||
|
||
#### 多例链
|
||
|
||
```java
|
||
/**
|
||
* 通用逻辑处理器接口 —— 责任链中的「节点」要实现的核心契约。
|
||
*/
|
||
public interface ILogicHandler<T, D, R> {
|
||
|
||
/**
|
||
* 默认的 next占位实现,方便节点若不需要向后传递时直接返回 null。
|
||
*/
|
||
default R next(T requestParameter, D dynamicContext) {
|
||
return null;
|
||
}
|
||
|
||
/**
|
||
* 节点的核心处理方法。
|
||
*/
|
||
R apply(T requestParameter, D dynamicContext) throws Exception;
|
||
|
||
}
|
||
|
||
```
|
||
|
||
```java
|
||
/**
|
||
* 业务链路容器 —— 双向链表实现,同时实现 ILogicHandler,从而可以被当作单个节点使用。
|
||
*/
|
||
public class BusinessLinkedList<T, D, R> extends LinkedList<ILogicHandler<T, D, R>> implements ILogicHandler<T, D, R>{
|
||
|
||
public BusinessLinkedList(String name) {
|
||
super(name);
|
||
}
|
||
|
||
/**
|
||
* BusinessLinkedList是头节点,它的apply方法就是循环调用后面的节点,直至返回。
|
||
* 遍历并执行链路。
|
||
*/
|
||
@Override
|
||
public R apply(T requestParameter, D dynamicContext) throws Exception {
|
||
Node<ILogicHandler<T, D, R>> current = this.first;
|
||
// 顺序执行,直到链尾或返回结果
|
||
while (current != null) {
|
||
ILogicHandler<T, D, R> handler = current.item;
|
||
R result = handler.apply(requestParameter, dynamicContext);
|
||
if (result != null) {
|
||
// 节点命中,立即返回
|
||
return result;
|
||
}
|
||
//result==null,则交给那一节点继续处理
|
||
current = current.next;
|
||
}
|
||
// 全链未命中
|
||
return null;
|
||
}
|
||
}
|
||
```
|
||
|
||
```java
|
||
/**
|
||
* 链路装配工厂 —— 负责把一组 ILogicHandler 顺序注册到 BusinessLinkedList 中。
|
||
*/
|
||
public class LinkArmory<T, D, R> {
|
||
|
||
private final BusinessLinkedList<T, D, R> logicLink;
|
||
|
||
/**
|
||
* @param linkName 链路名称,便于日志排查
|
||
* @param logicHandlers 节点列表,按传入顺序链接
|
||
*/
|
||
@SafeVarargs
|
||
public LinkArmory(String linkName, ILogicHandler<T, D, R>... logicHandlers) {
|
||
logicLink = new BusinessLinkedList<>(linkName);
|
||
for (ILogicHandler<T, D, R> logicHandler: logicHandlers){
|
||
logicLink.add(logicHandler);
|
||
}
|
||
}
|
||
|
||
/** 返回组装完成的链路 */
|
||
public BusinessLinkedList<T, D, R> getLogicLink() {
|
||
return logicLink;
|
||
}
|
||
|
||
}
|
||
|
||
//工厂类,可以定义多条责任链,每条有自己的Bean名称区分。
|
||
@Bean("tradeRuleFilter")
|
||
public BusinessLinkedList<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> tradeRuleFilter(ActivityUsabilityRuleFilter activityUsabilityRuleFilter, UserTakeLimitRuleFilter userTakeLimitRuleFilter) {
|
||
// 1. 组装链
|
||
LinkArmory<TradeRuleCommandEntity, DynamicContext, TradeRuleFilterBackEntity> linkArmory =
|
||
new LinkArmory<>("交易规则过滤链", activityUsabilityRuleFilter, userTakeLimitRuleFilter);
|
||
|
||
// 2. 返回链容器(即可作为责任链使用)
|
||
return linkArmory.getLogicLink();
|
||
}
|
||
```
|
||
|
||
示例图:
|
||
|
||
```text
|
||
BusinessLinkedList.apply ←─ 只有这一层在栈里
|
||
while 循环:
|
||
├─▶ 调用 ActivityUsability.apply → 返回 null → 继续
|
||
├─▶ 调用 UserTakeLimit.apply → 返回 null → 继续
|
||
└─▶ 调用 ... → 返回 Result → break
|
||
|
||
```
|
||
|
||
链头拿着“游标”一个个跑,节点只告诉“命中 / 未命中”。
|
||
|
||
|
||
|
||
### 规则树流程
|
||
|
||
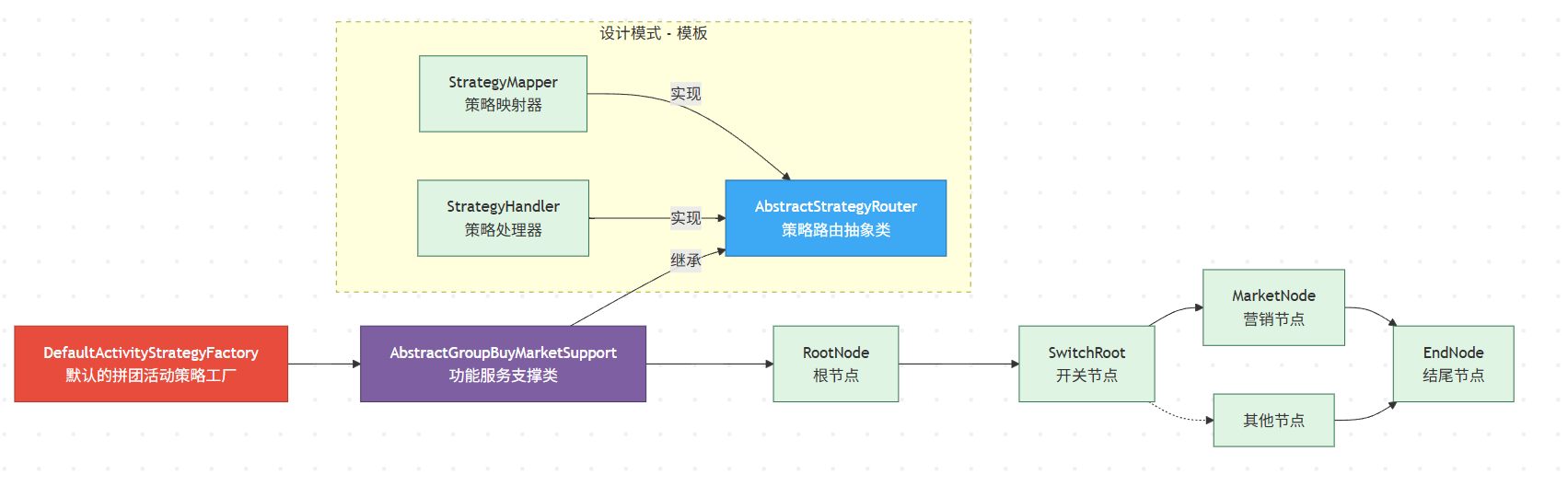
!
|
||
|
||
**整体分层思路**
|
||
|
||
| 分层 | 作用 | 关键对象 |
|
||
| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||
| **通用模板层** | 抽象出与具体业务无关的「规则树」骨架,解决 *如何找到并执行策略* 的共性问题 | `StrategyMapper`、`StrategyHandler`、`AbstractStrategyRouter<T,D,R>` |
|
||
| **业务装配层** | 基于模板,自由拼装出 *一棵* 贴合业务流程的策略树 | `RootNode / SwitchRoot / MarketNode / EndNode …` |
|
||
| **对外暴露层** | 通过 **工厂 + 服务支持类** 将整棵树封装成一个可直接调用的 `StrategyHandler`,并交给 Spring 整体托管 | `DefaultActivityStrategyFactory`、`AbstractGroupBuyMarketSupport` |
|
||
|
||
**通用模板层:规则树的“骨架”**
|
||
|
||
| 角色 | 职责 | 关系 |
|
||
| ------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||
| `StrategyMapper` | **映射器**:依据 `requestParameter + dynamicContext` 选出 *下一个* 策略节点 | 被 `AbstractStrategyRouter` 调用 |
|
||
| `StrategyHandler` | **处理器**:真正执行业务逻辑;`apply` 结束后可返回结果或继续路由 | 节点本身 / 路由器本身都是它的实现 |
|
||
| `AbstractStrategyRouter<T,D,R>` | **路由模板**:① 调用 `get(...)` 找到合适的 `StrategyHandler`;② 调用该 handler 的 `apply(...)`;③ 若未命中则走 `defaultStrategyHandler` | 同时实现 `StrategyMapper` 与 `StrategyHandler`,但自身保持 *抽象*,把细节延迟到子类 |
|
||
|
||
**业务装配层:一棵可编排的策略树**
|
||
|
||
```text
|
||
RootNode -> SwitchRoot -> MarketNode -> EndNode
|
||
↘︎ OtherNode ...
|
||
```
|
||
|
||
- 每个节点
|
||
|
||
继承 `AbstractStrategyRouter`
|
||
|
||
- 实现 `get(...)`:决定当前节点的下一跳是哪一个节点
|
||
- 实现 `apply(...)`:实现节点自身应做的业务动作(或继续下钻)
|
||
|
||
- 组合方式
|
||
|
||
比责任链更灵活:
|
||
|
||
- 一个节点既可以“继续路由”也可以“自己处理完直接返回”
|
||
- 可以随时插拔 / 替换子节点,形成多分支、循环、早停等复杂流转
|
||
|
||
**对外暴露层:工厂 + 服务支持类**
|
||
|
||
| 组件 | 主要职责 |
|
||
| --------------------------------------------- | ------------------------------------------------------------ |
|
||
| `DefaultActivityStrategyFactory` (`@Service`) | **工厂**:1. 在 Spring 启动时注入根节点 `RootNode`;2. 暴露**统一入口** `strategyHandler()` → 返回整个策略树顶点(一个 `StrategyHandler` 实例) |
|
||
| `AbstractGroupBuyMarketSupport` | **业务服务基类**:封装拼团场景下共用的查询、工具方法;供每个**节点**继承使用 |
|
||
|
||
这样,调用方只需
|
||
|
||
```java
|
||
TrialBalanceEntity result =
|
||
factory.strategyHandler().apply(product, new DynamicContext(vo1, vo2));
|
||
```
|
||
|
||
就能驱动整棵策略树,而**完全不用关心**节点搭建、依赖注入等细节。
|
||
|
||
|
||
|
||
### 策略模式
|
||
|
||
**核心思想**:
|
||
把可互换的算法/行为抽成独立策略类,运行时由“上下文”对象选择合适的策略;对调用方来说,只关心统一接口,而非具体实现。
|
||
|
||
```text
|
||
┌───────────────┐
|
||
│ Client │
|
||
└─────▲─────────┘
|
||
│ has-a
|
||
┌─────┴─────────┐ implements
|
||
│ Context │────────────┐ ┌──────────────┐
|
||
│ (使用者) │ strategy └─▶│ Strategy A │
|
||
└───────────────┘ ├──────────────┤
|
||
│ Strategy B │
|
||
└──────────────┘
|
||
|
||
```
|
||
|
||
#### 集合自动注入
|
||
|
||
常见于策略/工厂/插件场景。
|
||
|
||
```java
|
||
@Autowired
|
||
private Map<String, IDiscountCalculateService> discountCalculateServiceMap;
|
||
```
|
||
|
||
**字段类型**:`Map<String, IDiscountCalculateService>`
|
||
|
||
- key—— **Bean 的名字**
|
||
- 默认是类名首字母小写 (`mjCalculateService`)
|
||
- 或者你在实现类上显式写的 `@Service("MJ")`
|
||
- **value** —— 那个实现类对应的**实例**
|
||
- **Spring 机制**:
|
||
1. 启动时扫描所有实现 `IDiscountCalculateService` 的 Bean。
|
||
2. 把它们按 “BeanName → Bean 实例” 的映射注入到这张 `Map` 里。
|
||
3. 你一次性就拿到了“策略字典”。
|
||
|
||
**示例:**
|
||
|
||
```java
|
||
@Service("MJ") // ★ 关键:Bean 名即策略键
|
||
public class MJCalculateService extends IDiscountCalculateService {
|
||
|
||
@Override
|
||
protected BigDecimal Calculate(String userId, BigDecimal originalPrice,
|
||
GroupBuyActivityDiscountVO.GroupBuyDiscount groupBuyDiscount) {
|
||
//忽略实现细节
|
||
}
|
||
|
||
@Component
|
||
@RequiredArgsConstructor // 构造器注入更推荐
|
||
public class DiscountContext {
|
||
|
||
private final Map<String, IDiscountCalculateService> discountServiceMap;
|
||
|
||
public BigDecimal calc(String strategyKey,
|
||
String userId,
|
||
BigDecimal originalPrice,
|
||
GroupBuyActivityDiscountVO.GroupBuyDiscount plan) {
|
||
//strategyKey可以是"MJ" ..
|
||
IDiscountCalculateService strategy = discountServiceMap.get(strategyKey);
|
||
if (strategy == null) {
|
||
throw new IllegalArgumentException("无匹配折扣类型: " + strategyKey);
|
||
}
|
||
return strategy.calculate(userId, originalPrice, plan);
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|
||
|
||
|
||
### 多线程异步调用
|
||
|
||
如果某任务比较耗时(如加载大量数据),可以考虑开多线程异步调用。
|
||
|
||
```java
|
||
// Runnable ➞ 只能 run(),没有返回值
|
||
public interface Runnable {
|
||
void run();
|
||
}
|
||
|
||
// Callable<V> ➞ call() 能返回 V,也能抛检查型异常
|
||
public interface Callable<V> {
|
||
V call() throws Exception;
|
||
}
|
||
```
|
||
|
||
```java
|
||
public class MyTask implements Callable<String> {
|
||
private final String name;
|
||
public MyTask(String name) {
|
||
this.name = name;
|
||
}
|
||
@Override
|
||
public String call() throws Exception {
|
||
// 模拟耗时操作
|
||
TimeUnit.MILLISECONDS.sleep(300);
|
||
return "任务[" + name + "]的执行结果";
|
||
}
|
||
}
|
||
```
|
||
|
||
```java
|
||
public class SimpleAsyncDemo {
|
||
public static void main(String[] args) {
|
||
// 创建大小为 2 的线程池
|
||
ExecutorService pool = Executors.newFixedThreadPool(2);
|
||
|
||
try {
|
||
// 构造两个任务
|
||
MyTask task1 = new MyTask("A");
|
||
MyTask task2 = new MyTask("B");
|
||
|
||
// 用 FutureTask 包装 Callable
|
||
FutureTask<String> future1 = new FutureTask<>(task1);
|
||
FutureTask<String> future2 = new FutureTask<>(task2);
|
||
|
||
// 提交给线程池异步执行
|
||
pool.execute(future1);
|
||
pool.execute(future2);
|
||
|
||
// 主线程可以先做别的事…
|
||
System.out.println("主线程正在做其他事情…");
|
||
|
||
// 在需要的时候再获取结果(可加超时)
|
||
String result1 = future1.get(1, TimeUnit.SECONDS); //设置超时时间1秒
|
||
String result2 = future2.get(); //无超时时间
|
||
|
||
System.out.println("拿到结果1 → " + result1);
|
||
System.out.println("拿到结果2 → " + result2);
|
||
|
||
} catch (InterruptedException e) {
|
||
Thread.currentThread().interrupt();
|
||
} catch (ExecutionException e) {
|
||
System.err.println("任务执行中出错: " + e.getCause());
|
||
} catch (TimeoutException e) {
|
||
System.err.println("等待结果超时");
|
||
} finally {
|
||
pool.shutdown();
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### 动态配置(热更新)
|
||
|
||
原理:借助 Redis 的发布/订阅(Pub/Sub)能力,在程序跑起来以后,动态地往某个频道推送一条消息,然后所有订阅了该频道的 Bean 都会收到通知,进而反射更新它们身上的对应字段。
|
||
|
||
```text
|
||
启动时 ────────────────────────────────────▶ BeanPostProcessor
|
||
│ 扫描 @DCCValue 写入默认 / 读取 Redis
|
||
│ 注入字段值 缓存 key→Bean
|
||
─────────────────────────────────────────────────────────────────
|
||
运行时
|
||
管理后台调用 ───▶ publish("myKey,newVal") ───▶ Redis Pub/Sub
|
||
│ │
|
||
│ ▼
|
||
│ RTopic listener 收到消息
|
||
│ └─ ▸ 写回 Redis
|
||
│ └─ ▸ 从 Map 找到 Bean
|
||
│ └─ ▸ 反射注入新值到字段
|
||
▼
|
||
Bean 字段热更新完成
|
||
|
||
```
|
||
|
||
#### 实现步骤
|
||
|
||
**注解标记**
|
||
用 `@DCCValue("key:default")` 标注需要动态注入的字段,指定对应的 Redis Key(带前缀)及默认值。
|
||
|
||
```java
|
||
// 标记要动态注入的字段
|
||
@Retention(RUNTIME) @Target(FIELD)
|
||
public @interface DCCValue {
|
||
String value(); // "key:default"
|
||
}
|
||
```
|
||
|
||
```java
|
||
// 业务使用示例
|
||
@Service
|
||
public class MyFeature {
|
||
@DCCValue("myFlag:0")
|
||
private String myFlag;
|
||
public boolean enabled() { return "1".equals(myFlag); }
|
||
}
|
||
```
|
||
|
||
**启动时注入**
|
||
实现一个 `BeanPostProcessor`,在每个 Spring Bean 初始化后:
|
||
|
||
- 扫描带 `@DCCValue` 的字段;
|
||
- 拼出完整 Redis Key(如 `dcc_prefix_key`),若不存在则写入默认值,否则读最新值;
|
||
- **反射把值注入到该 Bean 的私有字段**;
|
||
- 将 `(redisKey → Bean 实例)` 记录到内存映射,用于后续热更新。
|
||
|
||
```java
|
||
@Override
|
||
public Object postProcessAfterInitialization(Object bean, String name) {
|
||
// 确定真实的目标类:处理代理 Bean 或普通 Bean
|
||
Class<?> cls = AopUtils.isAopProxy(bean)
|
||
? AopUtils.getTargetClass(bean)
|
||
: bean.getClass();
|
||
|
||
// 遍历所有字段,寻找标注了 @DCCValue 的配置字段
|
||
for (Field f : cls.getDeclaredFields()) {
|
||
DCCValue dv = f.getAnnotation(DCCValue.class);
|
||
if (dv == null) {
|
||
continue; // 如果该字段未被 @DCCValue 注解标注,则跳过
|
||
}
|
||
|
||
// 注解值格式为 "key:default",拆分获取配置项的 key 和默认值
|
||
String[] parts = dv.value().split(":");
|
||
String key = PREFIX + parts[0]; // Redis 中存储该配置的完整 Key
|
||
String defaultValue = parts[1]; // 默认值
|
||
|
||
// 从 Redis 获取配置,如果不存在则使用默认值,并同步写入 Redis
|
||
RBucket<String> bucket = redis.getBucket(key);
|
||
String val = bucket.isExists() ? bucket.get() : defaultValue;
|
||
bucket.trySet(defaultValue); // 如果 Redis 中没有该 Key,则写入默认值
|
||
|
||
// 反射方式将值注入到 Bean 的字段上(即动态替换该字段的值)
|
||
injectField(bean, f, val);
|
||
|
||
// 将该 Bean 注册到映射表,以便后续热更新时找到实例并更新字段
|
||
beans.put(key, bean);
|
||
}
|
||
|
||
return bean; // 返回处理后的 Bean
|
||
}
|
||
|
||
```
|
||
|
||
**运行时热更新**
|
||
|
||
- 在同一个组件里,订阅一个 Redis Topic(频道),比如 `"dcc_update"`;
|
||
|
||
- 外部调用发布接口 `PUBLISH dcc_update "key,newValue"`;
|
||
|
||
```java
|
||
//更新配置
|
||
@GetMapping("/dcc/update")
|
||
public void update(@RequestParam String key, @RequestParam String value) {
|
||
dccTopic().publish(key + "," + value);
|
||
}
|
||
```
|
||
|
||
- 订阅者收到后:
|
||
|
||
1. 同步把新值写回 Redis;
|
||
2. 从映射里取出对应 Bean,反射更新它的字段。
|
||
|
||
```java
|
||
// 发布/订阅频道,用于接收 DCC 配置的热更新消息
|
||
@Bean
|
||
public RTopic dccTopic() {
|
||
// 1. 从 RedissonClient 中获取名为 "dcc_update" 的主题(Topic),后续会订阅这个频道
|
||
RTopic t = redis.getTopic("dcc_update");
|
||
|
||
// 2. 为该主题添加监听器,消息格式为 String
|
||
t.addListener(String.class, (channel, msg) -> {
|
||
// 3. msg 约定格式:"configKey,newValue",先按逗号分割出 key 和 value
|
||
String[] a = msg.split(",");
|
||
String key = PREFIX + a[0]; // 拼出完整的 Redis Key
|
||
String val = a[1]; // 新的配置值
|
||
|
||
// 4. 检查 Redis 中是否已存在该 Key(只对已注册的配置生效)
|
||
RBucket<String> bucket = redis.getBucket(key);
|
||
if (!bucket.isExists()) {
|
||
return; // 如果不是我们关心的配置,跳过
|
||
}
|
||
|
||
// 5. 把新值同步写回 Redis,保证持久化
|
||
bucket.set(val);
|
||
|
||
// 6. 从内存缓存中取出当初注入该 key 的 Bean 实例
|
||
Object bean = beans.get(key);
|
||
if (bean != null) {
|
||
// 7. 通过反射把新的配置值重新注入到 Bean 的字段上,完成热更新
|
||
injectField(bean, a[0], val);
|
||
}
|
||
});
|
||
|
||
// 8. 返回这个 RTopic Bean,让 Spring 容器管理
|
||
return t;
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### OkHttpClient
|
||
|
||
**引入依赖**
|
||
|
||
```xml
|
||
<dependency>
|
||
<groupId>com.squareup.okhttp3</groupId>
|
||
<artifactId>okhttp-sse</artifactId>
|
||
</dependency>
|
||
```
|
||
|
||
**让Spring 管理 Http客户端**
|
||
|
||
- 写配置类
|
||
|
||
```java
|
||
@Configuration
|
||
public class OKHttpClientConfig {
|
||
|
||
@Bean
|
||
public OkHttpClient httpClient() {
|
||
return new OkHttpClient();
|
||
}
|
||
}
|
||
```
|
||
|
||
- 在需要使用的地方注入
|
||
|
||
```java
|
||
@Slf4j
|
||
@Service
|
||
@RequiredArgsConstructor
|
||
public class HttpService {
|
||
|
||
private final OkHttpClient okHttpClient;
|
||
|
||
/**
|
||
* 发送 JSON POST 请求并返回响应内容
|
||
*
|
||
* @param apiUrl 接口地址
|
||
* @param jsonPayload 请求体 JSON 字符串
|
||
*/
|
||
public String postJson(String apiUrl, String jsonPayload) throws IOException {
|
||
//1.构建参数
|
||
MediaType mediaType = MediaType.get("application/json; charset=utf-8");
|
||
RequestBody body = RequestBody.create(jsonPayload, mediaType);
|
||
Request request = new Request.Builder()
|
||
.url(apiUrl)
|
||
.post(body)
|
||
.addHeader("Content-Type", "application/json")
|
||
.build();
|
||
//2.调用接口
|
||
try (Response response = okHttpClient.newCall(request).execute()) {
|
||
if (!response.isSuccessful()) {
|
||
log.error("HTTP 请求失败,URL:{},状态码:{}", apiUrl, response.code());
|
||
throw new IOException("Unexpected HTTP code " + response.code());
|
||
}
|
||
ResponseBody responseBody = response.body();
|
||
return responseBody != null ? responseBody.string() : "";
|
||
} catch (IOException e) {
|
||
log.error("调用 HTTP 接口异常:{}", apiUrl, e);
|
||
throw e;
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
- 优点:
|
||
|
||
单例复用,性能更优
|
||
|
||
- Spring 默认将 Bean 作为单例管理,整个应用只创建一次 `OkHttpClient`。
|
||
- 内部的连接池、线程池、缓存等资源可以被复用,**避免频繁创建、销毁**带来的开销。
|
||
|
||
统一配置,易于维护
|
||
|
||
- 超时、拦截器、连接池、SSL、日志等配置集中在一个地方,改动一次全局生效。
|
||
- 避免在代码各处手动 `new OkHttpClient()`、重复配置。
|
||
|
||
|
||
|
||
### Retrofit
|
||
|
||
微信登录时,需要调用微信提供的接口做验证。
|
||
|
||
#### 快速入门
|
||
|
||
// 1. 定义 DTO
|
||
|
||
```java
|
||
public class User {
|
||
private String id;
|
||
private String name;
|
||
// … 省略 getters/setters …
|
||
}
|
||
```
|
||
|
||
// 2. 定义 Retrofit 接口
|
||
|
||
```java
|
||
public interface ApiService {
|
||
@GET("users/{id}")
|
||
Call<User> getUser(@Path("id") String id);
|
||
}
|
||
```
|
||
|
||
// 3. 配置 Retrofit 并注册为 Spring Bean
|
||
|
||
```java
|
||
@Configuration
|
||
public class RetrofitConfig {
|
||
|
||
private static final String BASE_URL = "https://api.example.com/";
|
||
|
||
@Bean
|
||
public Retrofit retrofit() {
|
||
return new Retrofit.Builder()
|
||
.baseUrl(BASE_URL) // 公共前缀
|
||
.addConverterFactory(JacksonConverterFactory.create()) // 自动 JSON ↔ DTO
|
||
.build();
|
||
}
|
||
|
||
@Bean
|
||
public ApiService apiService(Retrofit retrofit) {
|
||
// 动态生成 ApiService 实现
|
||
return retrofit.create(ApiService.class);
|
||
}
|
||
}
|
||
```
|
||
|
||
// 4. 在业务层注入并调用
|
||
|
||
```java
|
||
@Service
|
||
public class UserService {
|
||
|
||
private final ApiService apiService;
|
||
|
||
public UserService(ApiService apiService) {
|
||
this.apiService = apiService;
|
||
}
|
||
|
||
/**
|
||
* 同步方式获取用户信息
|
||
*/
|
||
public User getUserById(String userId) {
|
||
try {
|
||
Call<User> call = apiService.getUser(userId);
|
||
Response<User> resp = call.execute();
|
||
if (resp.isSuccessful()) {
|
||
return resp.body();
|
||
} else {
|
||
// 根据业务需要抛出异常或返回 null
|
||
throw new RuntimeException("请求失败,HTTP " + resp.code());
|
||
}
|
||
} catch (Exception e) {
|
||
throw new RuntimeException("调用用户服务出错", e);
|
||
}
|
||
}
|
||
|
||
/**
|
||
* 异步方式获取用户信息
|
||
*/
|
||
public void getUserAsync(String userId) {
|
||
apiService.getUser(userId).enqueue(new retrofit2.Callback<User>() {
|
||
@Override
|
||
public void onResponse(Call<User> call, Response<User> response) {
|
||
if (response.isSuccessful()) {
|
||
User user = response.body();
|
||
// TODO: 处理 user
|
||
}
|
||
}
|
||
@Override
|
||
public void onFailure(Call<User> call, Throwable t) {
|
||
// TODO: 处理异常
|
||
}
|
||
});
|
||
}
|
||
}
|
||
```
|
||
|
||
Retrofit 在运行时会生成这个接口的实现类,帮你完成:
|
||
|
||
- 拼 URL(把 `{id}` 换成具体值)
|
||
- 发起 GET 请求
|
||
- 拿到响应的 JSON 并自动反序列化成 `User` 对象
|
||
|
||
|
||
|
||
| 核心点 | Apache HttpClient | Retrofit |
|
||
| --------------- | ----------------------------------------- | ------------------------------------------------------------ |
|
||
| 编程模型 | 细粒度调用,手动构造 `HttpGet`/`HttpPost` | 注解驱动接口方法,声明式调用 |
|
||
| 请求定义 | 手动拼接 URL、参数 | 用 `@GET`/`@POST`、`@Path`、`@Query`、`@Body` 注解 |
|
||
| 序列化/反序列化 | 手动调用 `ObjectMapper`/`Gson` | 自动通过 `ConverterFactory`(Jackson/Gson 等) |
|
||
| 同步/异步 | 以同步为主,异步需自行管理线程和回调 | 同一个 `Call<T>` 即可 `execute()`(同步)或 `enqueue()`(异步) |
|
||
| 扩展性与拦截器 | 可配置拦截器,但需手动集成 | 底层基于 OkHttp,天然支持拦截器、连接池、缓存、重试和取消 |
|
||
|
||
|
||
|
||
### 公众号扫码登录流程
|
||
|
||
场景:用微信的能力来替你的网站做“扫码登录”或“社交登录”,代替自己写一整套帐号/密码体系。后台只需要基于 `openid` 做一次性关联(比如把某个微信号和你系统的用户记录挂钩),后续再次扫码就当作同一用户;
|
||
|
||
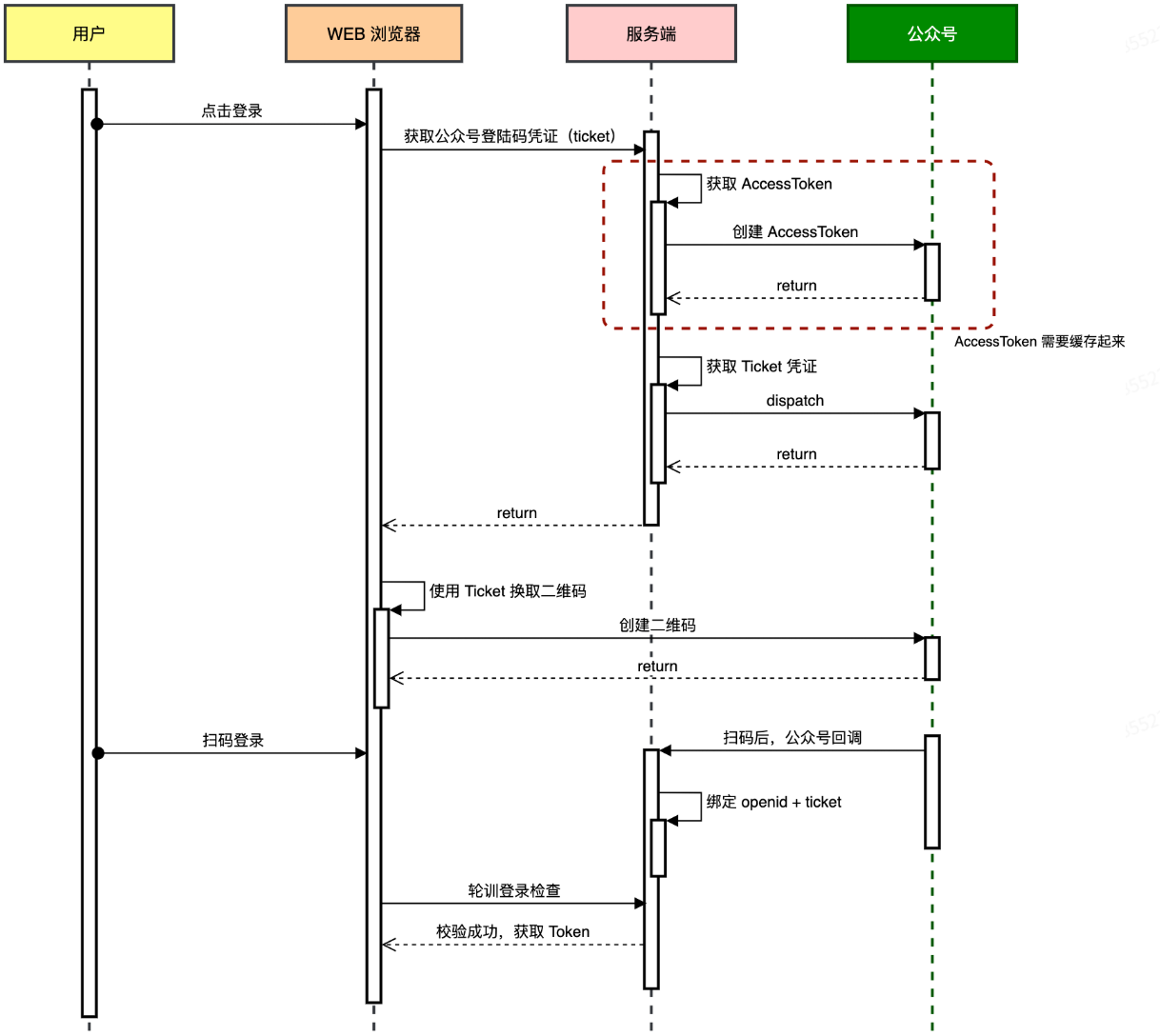
|
||
|
||
**1.前端请求二维码凭证**
|
||
|
||
- 用户点击“扫码登录”,前端向后端发 `GET /api/v1/login/weixin_qrcode_ticket`。
|
||
|
||
- 后端获取 access_token
|
||
1.先尝试从本地缓存(如 Guava Cache)读取 `access_token`;
|
||
2.若无或已过期,则请求微信接口:
|
||
|
||
```ruby
|
||
GET https://api.weixin.qq.com/cgi-bin/token
|
||
?grant_type=client_credential
|
||
&appid={你的 AppID}
|
||
&secret={你的 AppSecret}
|
||
```
|
||
|
||
微信返回 `{ "access_token":"ACCESS_TOKEN_VALUE", "expires_in":7200 }`,后端缓存这个值(有效期约 2 小时)。
|
||
|
||
- 后端利用 `access_token` 创建二维码 ticket,返给前端。(**每次调用微信会返回不同的ticket**)
|
||
|
||
**2.前端展示二维码**
|
||
|
||
- 前端根据 `ticket` 生成二维码链接:`https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket={ticket}`
|
||
|
||
**3.微信回调后端**
|
||
|
||
- 用户确认**扫描后**,微信服务器向你预先配置的**回调 URL**(如 `POST /api/v1/weixin/portal/receive`)推送包含 `ticket` 和 `openid` 的消息。
|
||
- 后端:将 `ticket → openid` **存入缓存**(`openidToken.put(ticket, openid)`);调用 `sendLoginTemplate(openid)` 给用户推送“登录成功”模板消息(手机公众号上推送,非网页)
|
||
|
||
**4.前端获知登录结果**
|
||
|
||
- **轮询方式**:生成二维码后,前端每隔几秒向后端 `check_login` 接口发送 `ticket`来验证登录状态,后端**查缓存**来判断 `ticket` 对应用户是否成功登录。
|
||
- **推送方式**:前端通过 WebSocket/SSE 建立长连接,后端回调处理完成后直接往该连接推送登录成功及 JWT。
|
||
|
||
|
||
|
||
### 浏览器指纹获取登录ticket
|
||
|
||
在扫码登录流程的基础上改进!!!
|
||
|
||
**目的:**把「这张二维码/ticket」严格绑在发起请求的那台浏览器上,防止别的设备或会话**拿到同一个 ticket** 就能登录。
|
||
|
||
**1.生成指纹**
|
||
前端在用户打开「扫码登录页」时,先用 JS/浏览器 API(比如 User-Agent、屏幕分辨率、插件列表、Canvas 指纹等)算出一个唯一的浏览器指纹 `fp`。
|
||
|
||
**2.获取 ticket 时携带指纹**
|
||
|
||
前端发起请求:
|
||
|
||
```bash
|
||
GET /api/v1/login/weixin_qrcode_ticket_scene?sceneStr=<fp>
|
||
```
|
||
|
||
后端执行:
|
||
|
||
```java
|
||
String ticket = loginPort.createQrCodeTicket(sceneStr);
|
||
sceneTicketCache.put(sceneStr, ticket); // 把 fp→ticket 映射进缓存
|
||
```
|
||
|
||
**3.扫码后轮询校验**
|
||
|
||
前端轮询:传入 `ticket` 和 `sceneStr` 指纹
|
||
|
||
```bash
|
||
GET /api/v1/login/check_login_scene?ticket=<ticket>&sceneStr=<fp>
|
||
```
|
||
|
||
后端逻辑(简化):
|
||
|
||
```java
|
||
// 1) 验证拿到的 sceneStr(fp) 对应的 ticket 是否一致
|
||
String cachedTicket = sceneTicketCache.getIfPresent(sceneStr);
|
||
if (!ticket.equals(cachedTicket)) {
|
||
// fp 不匹配,拒绝
|
||
return NO_LOGIN;
|
||
}
|
||
|
||
// 2) 再看 ticket→openid 有没有被写入(扫码并回调后,saveLoginState 会写入)
|
||
String openid = ticketOpenidCache.getIfPresent(ticket);
|
||
if (openid != null) {
|
||
// 同一浏览器,且已扫码确认,返回 openid(或 JWT)
|
||
return SUCCESS(openid);
|
||
}
|
||
return NO_LOGIN;
|
||
```
|
||
|
||
**4.回调时保存登录状态**
|
||
|
||
当用户扫描二维码,微信会回调你预定的接口地址,拿到 `ticket`、`openid` 后,调用:
|
||
|
||
```java
|
||
ticketOpenidCache.put(ticket, openid); // 保存 ticket→openid
|
||
```
|
||
|
||
注意 `ticketOpenidCache `和 `sceneTicketCache` 一般是一个Cache Bean,这里只是为了更清晰。
|
||
|
||
|
||
|
||
**安全性提升**
|
||
|
||
- **防止“票据劫持”**:别人就算截获了这个 ticket,想拿去自己那台机器上轮询也不行,因为指纹对不上。
|
||
- **防止多人共用**:多个人在不同设备上**同时扫同一个码**,只有最先发起获取 ticket 的那台浏览器能完成登录。
|
||
|
||
|
||
|
||
### 无痕登录
|
||
|
||
“无痕登录”(又称“免扫码登录”或“静默登录”)的核心思想,是在用户首次通过二维码/授权完成登录后,给这台设备发放一份**长期信任凭证**,以后再访问就能悄无声息地登录,不再需要人为地再扫码或输入密码。
|
||
|
||
#### 典型流程
|
||
|
||
**1.初次登录(扫码授权)**
|
||
|
||
即前面**"浏览器指纹获取登录ticket"**的流程
|
||
|
||
**2.后续“无痕”自动登录**
|
||
|
||
1)前端再次打开页面,重新生成指纹
|
||
|
||
2)前端调用“免扫码”接口,仅传递指纹
|
||
|
||
3)后端校验 fingerprint → openid
|
||
|
||
```java
|
||
String openid = sceneLoginCache.getIfPresent(sceneStr);
|
||
if (openid != null) {
|
||
// 直接返回登录态(Session / JWT)
|
||
return SUCCESS(openid);
|
||
} else {
|
||
// 指纹过期或未绑定,返回未登录,前端再走扫码流程
|
||
return NO_LOGIN;
|
||
}
|
||
```
|
||
|
||
4)**成功后**,前端拿到 openid/JWT,直接进入应用,无需用户任何操作。
|
||
|
||
|
||
|
||
### 独占锁和无锁化场景(防超卖)
|
||
|
||
#### 独占锁
|
||
|
||
**适用场景**
|
||
|
||
- **定时任务互备**
|
||
多机部署时,确保每天只有一台机器在某个时间点执行同一份任务(如数据清理、报表生成、邮件推送等)。
|
||
|
||
```java
|
||
@Scheduled(cron = "0 0 0 * * ?")
|
||
public void exec() {
|
||
// 获取锁句柄,并未真正获取锁
|
||
RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec");
|
||
try {
|
||
//尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取;leaseTime = 0:不设过期时间,看门狗机制
|
||
boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS);
|
||
if (!isLocked) return;
|
||
Map<String, Integer> result = tradeSettlementOrderService.execSettlementNotifyJob();
|
||
log.info("定时任务,回调通知拼团完结任务 result:{}", JSON.toJSONString(result));
|
||
} catch (Exception e) {
|
||
log.error("定时任务,回调通知拼团完结任务失败", e);
|
||
} finally {
|
||
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
|
||
lock.unlock();
|
||
}
|
||
}
|
||
}
|
||
```
|
||
|
||
#### 无锁化场景
|
||
|
||
“无锁化”设计 的核心思路是不在整个逻辑上加一把全局互斥锁,而是用 **Redis 原子操作** + **后置校验/补偿** 来完成并发控制。
|
||
|
||
**原子计数(Atomic Counter)**
|
||
用 Redis 的 `INCR`(或 Redisson 的 `RAtomicLong.incrementAndGet()`)来保证并发环境下每次调用都能拿到一个唯一、自增的数字。这个数字可以看作“第 N 个占位请求”。
|
||
|
||
**边界校验+补偿回滚(Validation & Compensation)**
|
||
拿到新数字后,马上与允许的最大值(`target + 已回滚补偿数`)做比较:
|
||
|
||
- 如果在范围内,视为占位成功;
|
||
- 如果超出范围,则把 Redis 里的计数器重置回 `target`(即“丢弃”这次多余的自增),并返回失败。
|
||
|
||
**极端兜底锁(Fallback Lock)**
|
||
虽然 `INCR` 本身已经原子,但在极端运维或网络抖动下仍有极小几率两次自增同时返回相同值。
|
||
因此,针对每个“序号”再做一次最轻量的 `SETNX(key:occupySeq)`:
|
||
|
||
- 成功 `SETNX` → 序号唯一,真正拿到名额;
|
||
- 失败 `SETNX` → 重复抢号,拒绝这次占位。
|
||
|
||
**典型适用场景**
|
||
|
||
- **电商秒杀 & 拼团抢购**
|
||
万级甚至十万级并发下不适合所有请求都排队,必须让绝大多数请求用原子计数并行处理。
|
||
- **抢票系统**
|
||
票务分配、座位预占,都讲究“先到先得”+“补偿回退”,不能用一把大锁。
|
||
|
||
```java
|
||
@Override
|
||
public boolean tryOccupy(String counterKey,
|
||
String recoveryKey,
|
||
int target,
|
||
int ttlMinutes) {
|
||
|
||
// 1) 读取“补偿”次数(退款/回滚补偿)
|
||
Long recovery = redisService.getAtomicLong(recoveryKey);
|
||
int recovered = (recovery == null ? 0 : recovery.intValue());
|
||
|
||
// 2) 原子自增,拿到当前序号
|
||
long seq = redisService.incr(counterKey);
|
||
long occupySeq = seq;
|
||
|
||
// 3) 超出“目标 + 补偿池” → 回滚主计数器,失败
|
||
if (occupySeq > target + recovered) {
|
||
redisService.setAtomicLong(counterKey, target);
|
||
return false;
|
||
}
|
||
|
||
// 4) 如果用到了补偿名额(序号已经 > target),就从补偿池里减掉一个
|
||
//if (occupySeq > target) {
|
||
// redisService.decr(recoveryKey);
|
||
//}
|
||
|
||
// 5) 兜底锁:针对每个序号做一次 SETNX,防止极端重复
|
||
String lockKey = counterKey + ":lock:" + occupySeq;
|
||
boolean locked = redisService.setNx(lockKey, ttlMinutes, TimeUnit.MINUTES);
|
||
if (!locked) {
|
||
return false;
|
||
}
|
||
|
||
// 6) 成功占位
|
||
return true;
|
||
}
|
||
```
|
||
|
||
|
||
|
||
### `Supplier<T>`
|
||
|
||
`Supplier<T>` 是 Java 8 提供的一个函数式接口
|
||
|
||
```java
|
||
@FunctionalInterface
|
||
public interface Supplier<T> {
|
||
/**
|
||
* 返回一个 T 类型的结果,参数为空
|
||
*/
|
||
T get();
|
||
}
|
||
```
|
||
|
||
任何“无参返回一个 T 类型对象”的代码片段(方法引用或 lambda)都可以当成 `Supplier<T>` 来用。
|
||
|
||
#### **作用**
|
||
|
||
**1.延迟执行**
|
||
把“取数据库数据”这类开销大的操作,包装成 `Supplier<T>` 传进去;只有真正需要时(缓存未命中),才调用 `supplier.get()` 去跑查询。
|
||
|
||
**2.解耦逻辑**
|
||
缓存逻辑和查询逻辑分离,缓存组件不用知道“怎么查库”,只负责“啥时候要查”,调用方通过 `Supplier` 把查库方法交给它。
|
||
|
||
**3.重用性高**
|
||
同一个缓存-回源模板方法可以服务于任何返回 `T` 的场景,既可以查 `User`,也可以查 `Order`、`List<Product>`……
|
||
|
||
```java
|
||
// 服务方法:它只关心“缓存优先,否则回源”
|
||
// dbFallback 是一段延迟执行的查库代码
|
||
protected <T> T getFromCacheOrDb(String cacheKey, Supplier<T> dbFallback) {
|
||
// 1) 先从缓存拿
|
||
T v = cache.get(cacheKey);
|
||
if (v != null) return v;
|
||
|
||
// 2) 缓存没命中,调用 dbFallback.get() 去“回源”拿数据
|
||
T fromDb = dbFallback.get();
|
||
if (fromDb != null) {
|
||
cache.put(cacheKey, fromDb);
|
||
}
|
||
return fromDb;
|
||
}
|
||
|
||
// 调用时这么写:
|
||
User user = getFromCacheOrDb(
|
||
"user:42",
|
||
() -> userRepository.findById(42) // 这里的 () -> ... 就是一个 Supplier<User>
|
||
);
|
||
|
||
List<Product> list = getFromCacheOrDb(
|
||
"hot:products",
|
||
() -> productService.queryHotProducts() // Supplier<List<Product>>
|
||
);
|
||
|
||
```
|
||
|
||
|
||
|
||
### 动态限流+黑名单
|
||
|
||
<img src="https://pic.bitday.top/i/2025/07/24/rbw21x-0.jpg" alt="ce1092e98bdb7d396589a46376b872a4" style="zoom:67%;" />
|
||
|
||
**令牌桶算法(Token Bucket)**
|
||
|
||
- 按固定速率往桶里放“令牌”(tokens),比如每秒放 N 个;
|
||
- 每次请求来临时“取一个令牌”才能通过,取不到就拒绝或降级;
|
||
- 可以做到“流量平滑释放”、“突发流量吸纳”(桶里最多能积攒 M 个令牌)。
|
||
|
||
**核心限流思路**
|
||
|
||
- **注解驱动拦截**:对标记了 `@RateLimiterAccessInterceptor` 的方法统一进行限流。
|
||
- **分布式限流**:基于 Redisson 的 `RRateLimiter`,可在多实例环境下共享令牌桶。
|
||
- **黑名单机制**:对超限用户计数,达到阈值后加入黑名单(24 h 后自动解禁)。
|
||
- **动态开关**:通过 DCC 配置中心开关(`rateLimiterSwitch`)可随时启用或关闭限流。
|
||
- **降级回调**:限流或黑名单命中时,通过注解指定的方法反射调用,返回自定义响应。
|
||
|
||
```text
|
||
请求到达
|
||
↓
|
||
检查限流开关(DCC)
|
||
↓
|
||
解析限流维度(key,如 userId)
|
||
↓
|
||
黑名单校验(RAtomicLong 计数,24h 过期)
|
||
↓
|
||
分布式令牌桶限流(RRateLimiter.tryAcquire)
|
||
↓
|
||
├─ 通过 → 执行目标方法
|
||
└─ 拒绝 → 调用 fallback 方法,记录黑名单次数
|
||
```
|
||
|
||
|
||
|
||
| 对比维度 | 本地限流 | 分布式限流 |
|
||
| ----------------- | ---------------------------------------------------- | ------------------------------------------------------------ |
|
||
| 实现复杂度 | **低**:直接用 Guava `RateLimiter`,几行代码即可接入 | **中高**:依赖 Redis/Redisson,需要注入客户端并管理限流器 |
|
||
| 性能开销 | **极低**:全程内存操作,纳秒级延迟 | **中等**:每次获取令牌需网络往返,存在 RTT 延迟 |
|
||
| 限流范围 | **单实例**:仅对当前 JVM 有效,多实例互不影响 | **全局**:多实例共享同一套令牌桶,合计速率可控 |
|
||
| 状态持久化 & 容错 | **无**:服务重启后状态丢失;实例宕机只影响自身 | **有**:Redis 存储限流器与黑名单,可持久化;需保证 Redis 可用性 |
|
||
| 监控 & 可观测 | **弱**:需额外上报或埋点才能集中监控 | **强**:可直接查看 Redis Key、TTL、计数等,易做报警与可视化 |
|
||
| 运维依赖 | **无**:不依赖外部组件 | **有**:需维护高可用的 Redis 集群,增加运维成本 |
|
||
|
||
目前本项目使用的是分布式限流,用Redisson
|
||
|
||
|
||
|
||
### 日志系统
|
||
|
||
#### 输出流向一览
|
||
|
||
输出到3个地方:控制台、本地文件、ELK日志(服务器上内存不足无法部署!)
|
||
|
||
| 日志级别 | 控制台 | 本地文件(异步) | Logstash (TCP) |
|
||
| ----------- | ------ | ----------------------------- | -------------- |
|
||
| TRACE/DEBUG | — | — | — |
|
||
| INFO | ✔ | `log_info.log` | ✔ |
|
||
| WARN | ✔ | `log_info.log``log_error.log` | ✔ |
|
||
| ERROR/FATAL | ✔ | `log_info.log``log_error.log` | ✔ |
|
||
|
||
> 注意:实际写文件时,都是通过 ASYNC_FILE_INFO/ERROR 两个异步 Appender 执行,以免日志写盘阻塞业务线程。
|
||
|
||
#### ELK日志系统
|
||
|
||
本地文件每台机器都会在自己 `/data/log/...` 目录下滚动输出自己的日志,互相之间不会合并。
|
||
|
||
如果你希望跨多台服务器**统一管理**,就需要把日志推到中央端——ELK日志系统
|
||
|
||
ELK=Elasticsearch(存储&检索)+ Logstash(采集&处理)+ Kibana(可视化)
|
||
|
||
docker-compose.yml:
|
||
|
||
```yml
|
||
version: '3'
|
||
services:
|
||
elasticsearch:
|
||
image: elasticsearch:7.17.28
|
||
ports: ['9201:9200','9300:9300']
|
||
environment:
|
||
- discovery.type=single-node
|
||
- ES_JAVA_OPTS=-Xms512m -Xmx512m
|
||
volumes:
|
||
- ./data:/usr/share/elasticsearch/data
|
||
logstash:
|
||
image: logstash:7.17.28
|
||
ports: ['4560:4560','9600:9600']
|
||
volumes:
|
||
- ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
|
||
environment:
|
||
- LS_JAVA_OPTS=-Xms1g -Xmx1g
|
||
kibana:
|
||
image: kibana:7.17.28
|
||
ports: ['5601:5601']
|
||
environment:
|
||
- elasticsearch.hosts=http://elasticsearch:9200
|
||
networks:
|
||
default:
|
||
driver: bridge
|
||
|
||
```
|
||
|
||
kibana配置:
|
||
|
||
```yml
|
||
#
|
||
# ** THIS IS AN AUTO-GENERATED FILE **
|
||
#
|
||
|
||
# Default Kibana configuration for docker target
|
||
server.host: "0"
|
||
server.shutdownTimeout: "5s"
|
||
elasticsearch.hosts: [ "http://elasticsearch:9200" ] # 记得修改ip
|
||
monitoring.ui.container.elasticsearch.enabled: true
|
||
i18n.locale: "zh-CN"
|
||
```
|
||
|
||
logstash配置:
|
||
|
||
```conf
|
||
input {
|
||
tcp {
|
||
mode => "server"
|
||
host => "0.0.0.0"
|
||
port => 4560
|
||
codec => json_lines
|
||
type => "info"
|
||
}
|
||
}
|
||
filter {}
|
||
output {
|
||
elasticsearch {
|
||
action => "index"
|
||
hosts => "es:9200"
|
||
index => "group-buy-market-log-%{+YYYY.MM.dd}"
|
||
}
|
||
}
|
||
```
|
||
|
||
自己的项目:
|
||
|
||
```java
|
||
<!-- 上报日志;ELK -->
|
||
<springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/>
|
||
|
||
<!--输出到logstash的appender-->
|
||
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
|
||
<!--可以访问的logstash日志收集端口-->
|
||
<destination>${LOG_STASH_HOST}:4560</destination>
|
||
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
|
||
</appender>
|
||
```
|
||
|
||
```xml
|
||
<dependency>
|
||
<groupId>net.logstash.logback</groupId>
|
||
<artifactId>logstash-logback-encoder</artifactId>
|
||
<version>7.3</version>
|
||
</dependency>
|
||
```
|
||
|
||
**使用**
|
||
|
||
检查索引:curl http://localhost:9201/_cat/indices?v3
|
||
|
||
打开 Kibana:浏览器访问 `http://localhost:5601`,新建 索引模式(如 `app-log-*`),即可在 Discover/Visualize 中查看与分析日志。
|
||
|
||
|
||
|
||
### 防止重复下单
|
||
|
||
**外部交易单号设计**
|
||
|
||
- **统一跟踪**:对接小商城时,将外部交易单号(`out_trade_no`)与小商城下单时生成的 `order_id` 保持一致,方便全链路追踪。
|
||
- **内部独立**:拼团系统内部仍保留自己的 `order_id`,互不冲突。
|
||
|
||
在高并发支付场景中,确保同一用户对同一商品/活动只生成一条待支付订单,常用以下两种思路:
|
||
|
||
#### 业务维度复合唯一索引 + 冲突捕获重试
|
||
|
||
1. **查询未支付订单**
|
||
- 在创建订单时,先根据业务维度(如 `userId + goodId + activityId`)查询“已下单但未支付”的订单;
|
||
- 若存在,则直接返回该订单,避免二次创建。
|
||
2. **复合唯一索引约束**
|
||
- 在订单表中对业务维度字段(`userId`、`goodId`、`activityId` 等)添加**复合唯一索引**;
|
||
- 高并发下若出现并行插入,后续请求因违反唯一约束抛出异常;
|
||
- 捕获异常后,再次查询并返回已创建的订单,实现幂等。
|
||
3. **分布式锁保障(可选)**
|
||
- 针对同一用户加分布式锁(例如 `lock:userId:{userId}`),确保只有**首个请求能获取锁**并创建订单;
|
||
- 后续请求等待锁释放或直接返回“订单处理中”,随后再次查询订单状态。
|
||
|
||
#### 幂等 Key 模式
|
||
|
||
1. **生成幂等 Key**
|
||
- 前端进入支付流程时调用接口(`GET /api/idempotency-key`),后端生成全局唯一 ID(UUID 或雪花 ID)返回给前端;
|
||
- 或者外部系统(如小商城)传来唯一的外部交易单号(`out_trade_no`),**天生作为幂等Key。**
|
||
- 前端将该 Key 存入内存、LocalStorage 或隐藏表单字段,直至支付完成或过期。
|
||
2. **请求携带幂等 Key**
|
||
- 用户点击“下单”时,调用 `/create_pay_order` 接口,需在请求体中附带 `idempotencyKey`;
|
||
- 服务端根据该 Key 判断:若数据库中已有相同 `idempotency_key`,直接返回该订单,否则创建新订单。
|
||
3. **数据库持久化 & 唯一约束**
|
||
- 在订单表中新增 `idempotency_key` 列,并对其增加唯一索引;
|
||
- 双重保障:前端重复发送同一 Key,也仅能插入一条记录,彻底避免重复下单。
|
||
|
||
|
||
|