8.0 KiB
智能协同云图库
待完善功能:
用户模块扩展功能:
2.JWT校验,可能要同时改前端,把userId保存到ThreadLocal中
3.目前这些标签写死了,可以用redis、数据库进行动态设置。(根据点击次数)
@GetMapping("/tag_category")
public BaseResponse<PictureTagCategory> listPictureTagCategory() {
PictureTagCategory pictureTagCategory = new PictureTagCategory();
List<String> tagList = Arrays.asList("热门", "搞笑", "生活", "高清", "艺术", "校园", "背景", "简历", "创意");
List<String> categoryList = Arrays.asList("模板", "电商", "表情包", "素材", "海报");
pictureTagCategory.setTagList(tagList);
pictureTagCategory.setCategoryList(categoryList);
return ResultUtils.success(pictureTagCategory);
}
4.图片审核扩展

5.爬图扩展
2)记录从哪里爬的
4)bing直接搜可能也是缩略图,可能模拟手点一次图片,再爬会清晰一点

6.缓存扩展


图片压缩

文件秒传,md5校验,如果已有,直接返回url,不用重新上传(图片场景不必使用)
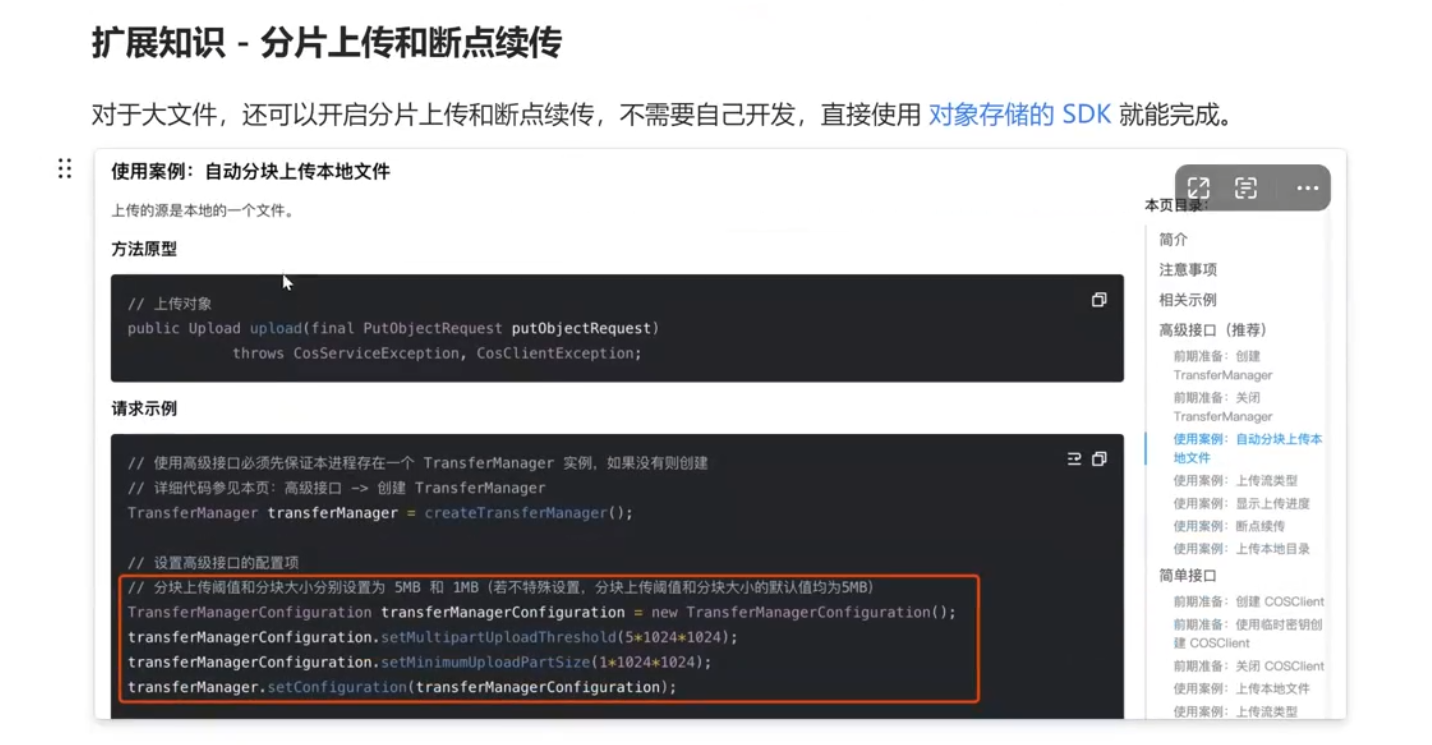
分片上传和断点续传:对象存储 上传对象_腾讯云
CDN内容分发,后期项目上线之后搞一下。
浏览器缓存
是服务器(或 CDN/静态文件服务器)在返回资源时下发给浏览器的。

用户空间扩展:


图片编辑

AI扩图

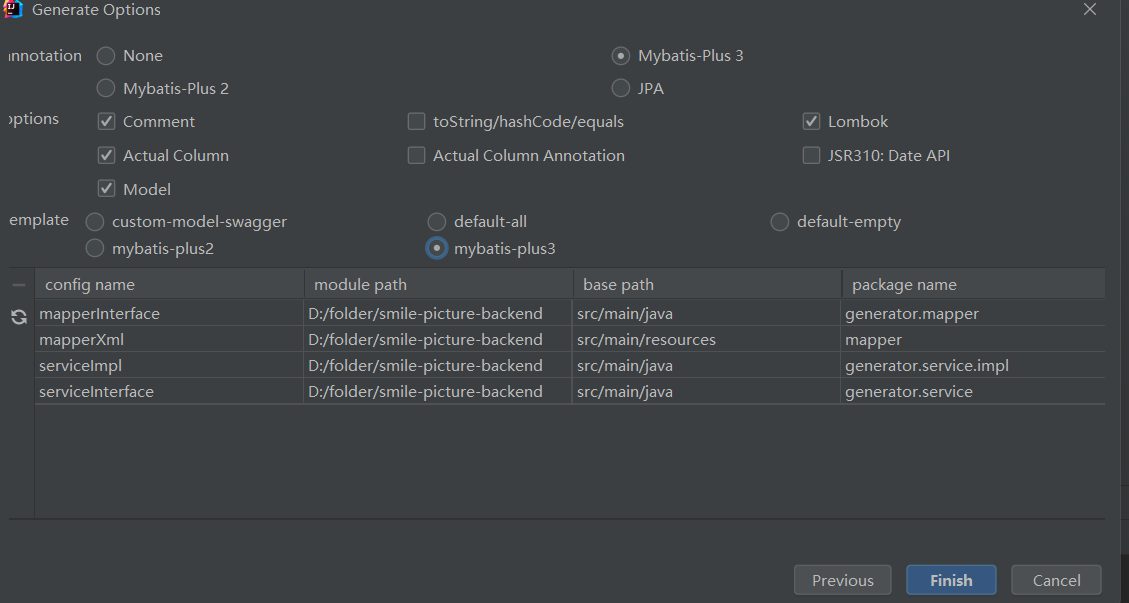
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
注意,勾选Actual Column生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即user_name->userName

下载GenerateSerailVersionUID插件,可以右键->generate->生成序列ID:
private static final long serialVersionUID = -1321880859645675653L;
创建图片的业务流程 创建图片主要是包括两个过程:第一个过程是上传图片文件本身,第二个过程是将图片信息上传到数据库。
有两种常见的处理方式:
1.先上传再提交数据(大多数的处理方式):用户直接上传图片,系统自动生成图片的url存储地址;然后在用户填写其它相关信息并提交后才将图片记录保存到数据库中。 2.上传图片时直接记录图片信息:云图库平台中图片作为核心资源,只要用户将图片上传成功就应该把这个图片上传到数据库中(即用户上传图片后系统应该立即生成图片的完整数据记录和其它元信息,这里元信息指的是图片的一些基础信息,这些信息应该是在图片上传成功后就能够解析出来),无需等待用户上传提交图片信息就会立即存入数据库中,这样会使整个交互过程更加轻量。这样的话用户只需要再上传图片的其它信息即可,这样就相当于用户对已有的图片信息进行编辑。 当然我们也可以对用户进行一些限制,比如说当用户上传过多的图片资源时就禁止该用户继续上传图片资源。
优化

多级缓存
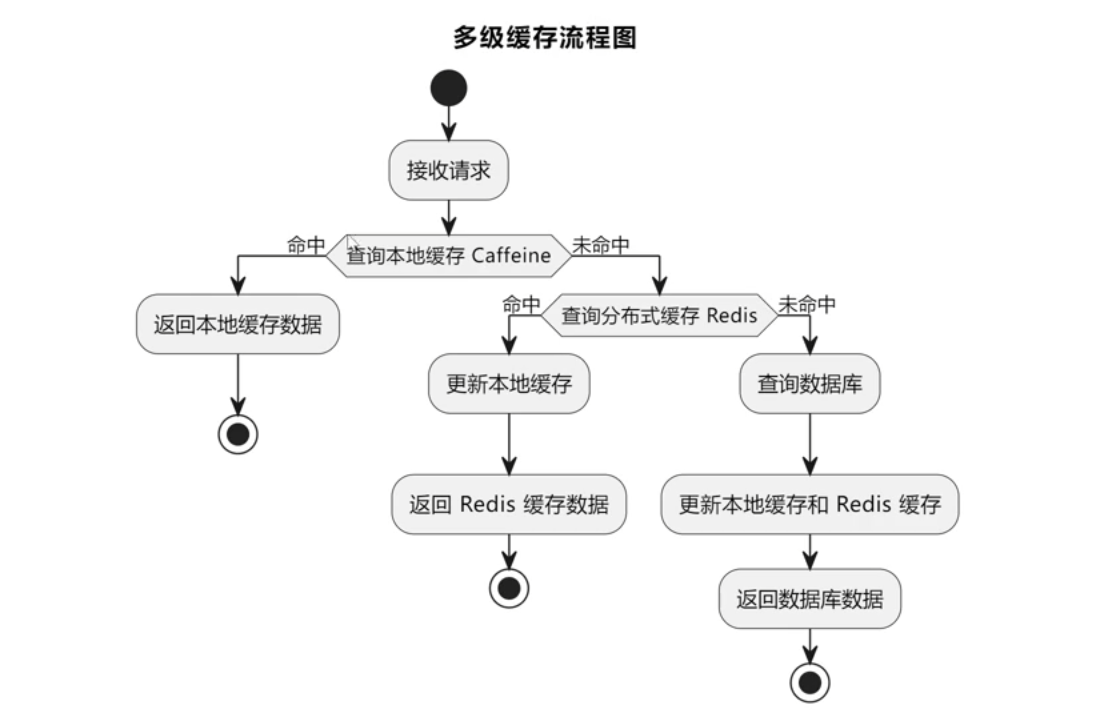
目前貌似没有使用缓存、@deprecated
收获
Redis+Session
之前我们每次重启服务器都要重新登陆,既然已经整合了 Redis,不妨使用 Redis 管理 Session,更好地维护登录态。
1)先在 Maven 中引入 spring-session-data-redis 库:
<!-- Spring Session + Redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2)修改 application.yml 配置文件,更改Session的存储方式和过期时间:
既要设置redis能存30天,发给前端的cookie也要30天有效期。
spring:
# session 配置
session:
store-type: redis
# session 30 天过期
timeout: 2592000
server:
port: 8123
servlet:
context-path: /api
# cookie 30 天过期
session:
cookie:
max-age: 2592000
为什么用 ConcurrentHashMap<Long,Object> 管理锁更优?
- 避免污染常量池
String.intern()会把每一个不同的userId字符串都放到 JVM 的字符串常量池里,随着用户量增长,常量池里的内容会越来越多,可能导致元空间(MetaSpace)/永久代(PermGen)压力过大。 - 显式可控的锁生命周期
- 用
ConcurrentHashMap明确地管理——「只要 map 里有这个 key,就有对应的锁对象;不需要时可以删掉。」 - 相比之下,
intern()后的字符串对象由 JVM 常量池管理,代码里很难清理,存在内存泄漏风险。
- 用
- 高并发性能更好
ConcurrentHashMap内部采用分段锁或 Node 锁定(取决于 JDK 版本),即便高并发下往 map 里computeIfAbsent也能保持较高吞吐。synchronized (lock)本身只锁定单个用户对应的那把锁,不影响其他用户;结合ConcurrentHashMap的高并发特性,整体性能比直接在一个全局HashMap+synchronized好得多。
锁+事务可能出现的问题
@Transactional(声明式)
- 事务在方法入口打开,很可能在拿锁前就占用连接/数据库资源,导致“空跑事务”+“资源耗尽”。
- 依赖代理,存在自调用失效的坑。
transactionTemplate.execute()(编程式)
- 锁先行→事务后发,确保高并发下只有一个连接/事务进数据库,极大降低资源竞争。
- 全程显式,放到哪儿就是哪儿,杜绝自调用/代理链带来的隐患。
锁+事务@Transactional一起可能出现问题:
线程 A
- 进入方法,Spring AOP 拦截,立即开启事务
- 走到
synchronized(lock),拿到锁 - 在锁里执行
exists→save(但真正的 “提交” 要等到方法返回后才做) - 退出
synchronized块,方法继续执行(其实已经没别的逻辑了) - 方法返回,事务拦截器这时才 提交
线程 B(并发进来)
- 等待 AOP 代理,进入同一个方法,也会马上开启自己的事务
- 在入口就拿到一个新的连接/事务上下文
- 然后遇到
synchronized(lock),在这里阻塞 等 A 释放锁 - A 一旦走出
synchronized,B 立刻拿到锁——但此时 A 还没真正提交(提交在方法尾被拦截器做) - B 在锁里执行
exists:因为 A 的改动还在 A 的未提交事务里,默认隔离级别(READ_COMMITTED)下看不到,所以exists会返回false - B 就继续
save,结果就可能插入重复记录,或者引发唯一索引冲突