72 KiB
拼团交易系统
部署
目录结构:
docker-compose:
version: '3.8'
services:
# 1. 前端
group-buy-market-front:
image: nginx:alpine
container_name: group-buy-market-front
restart: unless-stopped
ports:
- '18091:80'
volumes:
- ./nginx/html:/usr/share/nginx/html
- ./nginx/conf/nginx.conf:/etc/nginx/nginx.conf:ro
privileged: true
networks:
- group-buy-network
# 4. Java 后端
group-buying-sys:
build:
context: ../../.. # 从 docs/tag/v2.0 回到项目根
dockerfile: group-buying-sys-app/Dockerfile
image: smile/group-buying-sys:latest
container_name: group-buying-sys
restart: unless-stopped
depends_on:
mysql:
condition: service_healthy
redis:
condition: service_healthy
ports:
- '8091:8091'
environment:
- TZ=Asia/Shanghai
- SPRING_PROFILES_ACTIVE=prod
volumes:
- ./log:/data/log
logging:
driver: json-file
options:
max-size: '10m'
max-file: '3'
networks:
- group-buy-network
mysql:
image: mysql:8.0
container_name: group-buy-mysql
hostname: mysql
command: --default-authentication-plugin=mysql_native_password
restart: unless-stopped
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
ports:
- "13306:3306"
volumes:
- ./mysql/my.cnf:/etc/mysql/conf.d/mysql.cnf:ro
- ./mysql/sql:/docker-entrypoint-initdb.d
healthcheck:
test: [ "CMD", "mysqladmin" ,"ping", "-h", "localhost" ]
interval: 5s
timeout: 10s
retries: 10
start_period: 15s
networks:
- group-buy-network
# Redis
redis:
image: redis:6.2
restart: unless-stopped
container_name: group-buy-redis
hostname: redis
privileged: true
ports:
- 16379:6379
volumes:
- ./redis/redis.conf:/usr/local/etc/redis/redis.conf
command: redis-server /usr/local/etc/redis/redis.conf
networks:
- group-buy-network
healthcheck:
test: [ "CMD", "redis-cli", "ping" ]
interval: 10s
timeout: 5s
retries: 3
# rabbitmq
# 账密 admin/admin
# rabbitmq-plugins enable rabbitmq_management
rabbitmq:
image: rabbitmq:3.8-management
container_name: group-buy-rabbitmq
hostname: rabbitmq
restart: unless-stopped
ports:
- "5672:5672"
- "15672:15672"
environment:
RABBITMQ_DEFAULT_USER: admin
RABBITMQ_DEFAULT_PASS: admin
command: rabbitmq-server
volumes:
- ./rabbitmq/enabled_plugins:/etc/rabbitmq/enabled_plugins
- ./rabbitmq/mq-data:/var/lib/rabbitmq
networks:
- group-buy-network
nacos:
image: nacos/nacos-server:v2.1.0
container_name: group-buy-nacos-server
hostname: nacos
restart: unless-stopped
env_file:
- ./nacos/custom.env
ports:
- "8848:8848"
- "9848:9848"
- "9849:9849"
depends_on:
- mysql
networks:
- group-buy-network
volumes:
- ./nacos/init.d:/docker-entrypoint-init.d
networks:
group-buy-network:
external: true
dockerfile:
# —— 第一阶段:Maven 构建 ——
FROM maven:3.8.7-eclipse-temurin-17-alpine AS builder
WORKDIR /workspace
# 把项目级 settings.xml 复制到容器里
COPY .mvn/settings.xml /root/.m2/settings.xml
# 1. 先只拷贝父 POM 及各模块的 pom.xml,加速依赖下载
COPY pom.xml ./pom.xml
COPY group-buying-sys-api/pom.xml ./group-buying-sys-api/pom.xml
COPY group-buying-sys-domain/pom.xml ./group-buying-sys-domain/pom.xml
COPY group-buying-sys-infrastructure/pom.xml ./group-buying-sys-infrastructure/pom.xml
COPY group-buying-sys-trigger/pom.xml ./group-buying-sys-trigger/pom.xml
COPY group-buying-sys-types/pom.xml ./group-buying-sys-types/pom.xml
COPY group-buying-sys-app/pom.xml ./group-buying-sys-app/pom.xml
# 离线下载所有依赖
RUN mvn dependency:go-offline -B
# 2. 拷贝所有源码
COPY . .
# 3. 只打包 main 应用模块(连带编译它依赖的模块),跳过测试,加速构建
RUN mvn \
-f pom.xml clean package \
-pl group-buying-sys-app -am \
-DskipTests -B
# —— 第二阶段:运行时镜像 ——
FROM openjdk:17-jdk-slim
LABEL maintainer="smile"
# 可选:设置时区
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 把构建产物拷过来
COPY --from=builder \
/workspace/group-buying-sys-app/target/group-buying-sys-app.jar \
app.jar
# 暴露端口,按需改
EXPOSE 8091
ENTRYPOINT ["java", "-jar", "app.jar"]
修改项目后部署的影响:
前端服务 (group-buy-market-front)
-
代码位置:通过卷挂载 (
./nginx/html:/usr/share/nginx/html)。 -
修改影响
- 如果修改的是
./nginx/html下的前端代码(如 HTML/JS/CSS),无需重建,Nginx 会直接读取更新后的文件。 - 如果修改的是 Nginx 配置 (
./nginx/conf/nginx.conf),需重启容器生效:
docker compose restart group-buy-market-front - 如果修改的是
Java 后端服务 (group-buying-sys)
-
代码位置:通过镜像构建(
build指定了 Dockerfile 路径)。 -
修改影响
- 如果修改了 Java 代码或依赖(如
pom.xml),必须重建镜像:
docker compose up -d --build group-buying-sys - 如果修改了 Java 代码或依赖(如
其他服务(MySQL/Redis/RabbitMQ/Nacos)
-
代码位置:均使用官方镜像,无业务代码。
-
修改影响
-
修改配置文件(如 ./redis/redis.conf)需重启容器:
docker compose restart redis -
无需
--build(除非你自定义了它们的镜像)。
-
系统备忘录
本系统涉及微信和支付宝的回调。
1.微信扫码登录,https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index平台上配置了扫描通知地址,如果是本地测试,需要打开frp内网穿透,然后填的地址是frp建立通道的服务器端的ip:端口
2.支付宝,用户付款成功回调,也是同理,本地测试就要开frp。注意frp中的通道,默认是本地端口=远程端口,但是如果在服务器上部署了一套,那么远程的端口就会与frp的端口冲突!!!导致本地测试的时候失效。
流程:
用户锁单-》支付宝付款-》成功后return_url设置了用户支付完毕后跳转回哪个地址是给前端用户看的; alipay_notify_url设置了支付成功后alipay调用你的后端哪个接口。
这里有小商城和拼团系统,notify_url指拼团系统中拼团达到指定人数后,通知小商城的HTTP地址,但是如果notify_type为MQ,则notify_url为空,并且notify_mq非空,指明是拼团成功通知还是用户退单通知。
若为拼团成功通知,小商场将订单中相应拼团的status都设置为deal_done,然后小商场内部也再发一个'支付成功'消息,主要用于通知这些拼团对应的订单进入下一环节:发货(感觉'支付成功'取名不够直观)。
若为用户退单通知,小商场需处理退款业务。
系统设计
库表设计
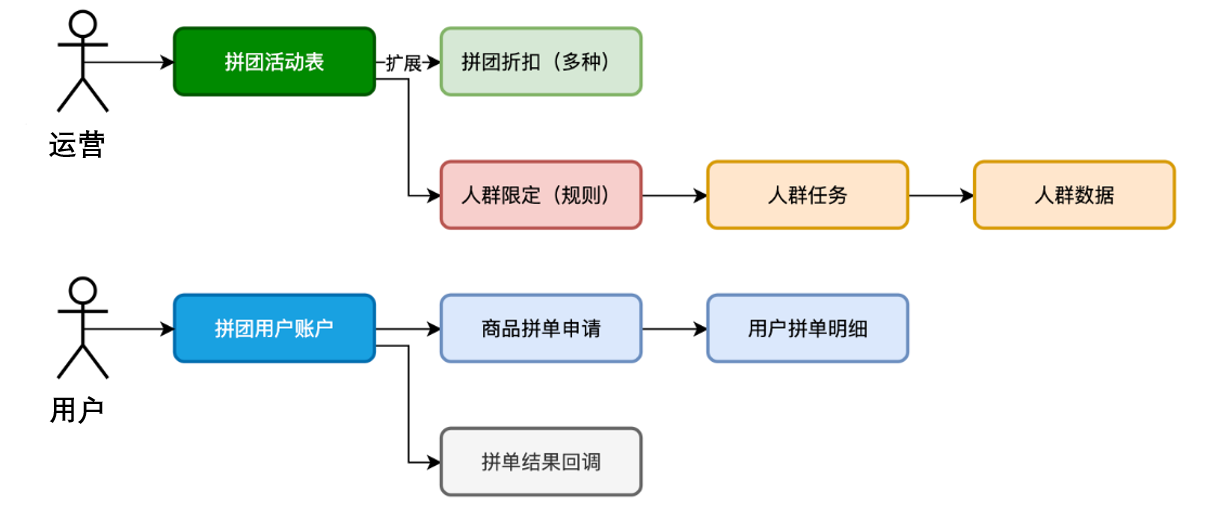
- 首先,站在运营的角度,要为这次拼团配置对应的拼团活动。那么就会涉及到;给哪个渠道的什么商品ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商品所提供的规则信息,包括:折扣、起止时间、人数等。还要拿到折扣的一个试算金额。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格。
- 之后,站在用户的角度,是参与拼团。首次发起一个拼团或者参与已存在的拼团进行数据的记录,达成拼团约定拼团人数后,开始进行通知。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
- 另外,为了支持拼团库表,需要先根据业务规则把符合条件的用户 ID 写入 Redis,并为这批用户打上可配置的人群标签。创建拼团活动时,只需关联对应标签,即可让活动自动面向这部分用户生效,实现精准运营和差异化折扣。
- 那么,拼团活动表,为什么会把折扣拆分出来呢。因为这里的折扣可能有多种迭代到一个拼团上。比如,给一个商品添加了直减10元的优惠,又对符合的人群id的用户,额外打9折,这样就有了2个折扣迭代。所以拆分出来会更好维护。这是对常变的元素和稳定的元素进行设计的思考。
group_buy_activity(拼团活动)
| 字段名 | 说明 |
|---|---|
| id | 自增 |
| activity_id | 活动ID |
| activity_name | 活动名称 |
| discount_id | 折扣ID |
| group_type | 成团方式(0自动成团、1达成目标成团) |
| take_limit_count | 拼团次数限制 |
| target | 拼团目标 |
| valid_time | 拼团时长(分钟) |
| status | 活动状态(0创建、1生效、2过期、3废弃) |
| start_time | 活动开始时间 |
| end_time | 活动结束时间 |
| tag_id | 人群标签规则标识 |
| tag_scope | 人群标签规则范围(多选;1可见限制、2参与限制) |
| create_time | 创建时间 |
| update_time | 更新时间 |
group_buy_discount(折扣配置)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| discount_id | 折扣ID |
| discount_name | 折扣标题 |
| discount_desc | 折扣描述 |
| discount_type | 折扣类型(0:base、1:tag) |
| market_plan | 营销优惠计划(ZJ:直减、MJ:满减、ZK:折扣、N元购) |
| market_expr | 营销优惠表达式 |
| tag_id | 人群标签(特定优惠限定) |
| create_time | 创建时间 |
| update_time | 更新时间 |
group_buy_order(拼团订单表)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| team_id | 拼单组队ID |
| activity_id | 活动ID |
| source | 渠道 |
| channel | 来源 |
| original_price | 原始价格 |
| deduction_price | 折扣金额 |
| pay_price | 支付价格 |
| target_count | 目标数量 |
| complete_count | 完成数量 |
| lock_count | 锁单数量 |
| status | 状态(0拼单中、1完成、2失败、3完成-含退单) |
| valid_start_time | 拼团开始时间 |
| valid_end_time | 拼团结束时间 |
| notify_type | 回调类型(HTTP、MQ) |
| notify_url | 回调地址(HTTP 回调不可为空) |
| create_time | 创建时间 |
| update_time | 更新时间 |
group_buy_order_list(拼团订单明细表)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| user_id | 用户ID |
| team_id | 拼单组队ID |
| order_id | 订单ID |
| activity_id | 活动ID |
| start_time | 锁单时间 |
| end_time | 最晚锁单时间 |
| valid_end_time | 拼团结束时间 |
| goods_id | 商品ID |
| source | 渠道 |
| channel | 来源 |
| original_price | 原始价格 |
| deduction_price | 折扣金额 |
| pay_price | 支付金额 |
| status | 状态(0初始锁定、1消费完成、2用户退单) |
| out_trade_no | 外部交易单号(幂等) |
| create_time | 创建时间 |
| update_time | 更新时间 |
| biz_id | 业务唯一ID |
| out_trade_time | 外部交易时间 |
notify_task(回调任务)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| activity_id | 活动ID |
| team_id | 拼单组队ID |
| notify_category | 回调种类 |
| notify_type | 回调类型(HTTP、MQ) |
| notify_mq | 回调消息 |
| notify_url | 回调接口 |
| notify_count | 回调次数 |
| notify_status | 回调状态(0初始、1完成、2重试、3失败) |
| parameter_json | 参数对象 |
| uuid | 唯一标识 |
| create_time | 创建时间 |
| update_time | 更新时间 |
crowd_tags(人群标签)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| tag_id | 人群ID |
| tag_name | 人群名称 |
| tag_desc | 人群描述 |
| statistics | 人群标签统计量 |
| create_time | 创建时间 |
| update_time | 更新时间 |
crowd_tags_detail(人群标签明细)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| tag_id | 人群ID |
| user_id | 用户ID |
| create_time | 创建时间 |
| update_time | 更新时间 |
crowd_tags_job(人群标签任务)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| tag_id | 标签ID |
| batch_id | 批次ID |
| tag_type | 标签类型(参与量、消费金额) |
| tag_rule | 标签规则(限定类型 N次) |
| stat_start_time | 统计数据开始时间 |
| stat_end_time | 统计数据结束时间 |
| status | 状态(0初始、1计划、2重置、3完成) |
| create_time | 创建时间 |
| update_time | 更新时间 |
sc_sku_activity(渠道商品活动配置关联表)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| source | 渠道 |
| channel | 来源 |
| activity_id | 活动ID |
| goods_id | 商品ID |
| create_time | 创建时间 |
| update_time | 更新时间 |
sku(商品信息)
| 字段名 | 说明 |
|---|---|
| id | 自增ID |
| source | 渠道 |
| channel | 来源 |
| goods_id | 商品ID |
| goods_name | 商品名称 |
| original_price | 商品价格 |
| create_time | 创建时间 |
| update_time | 更新时间 |
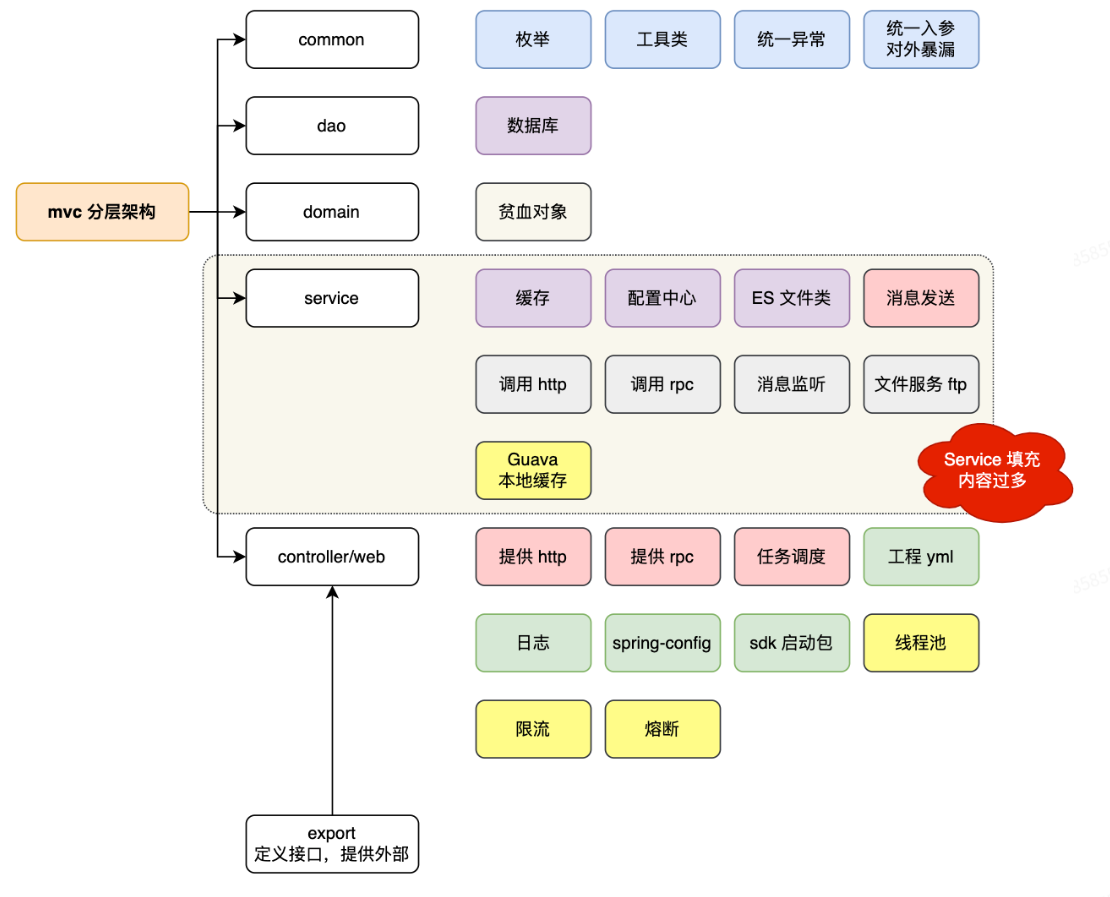
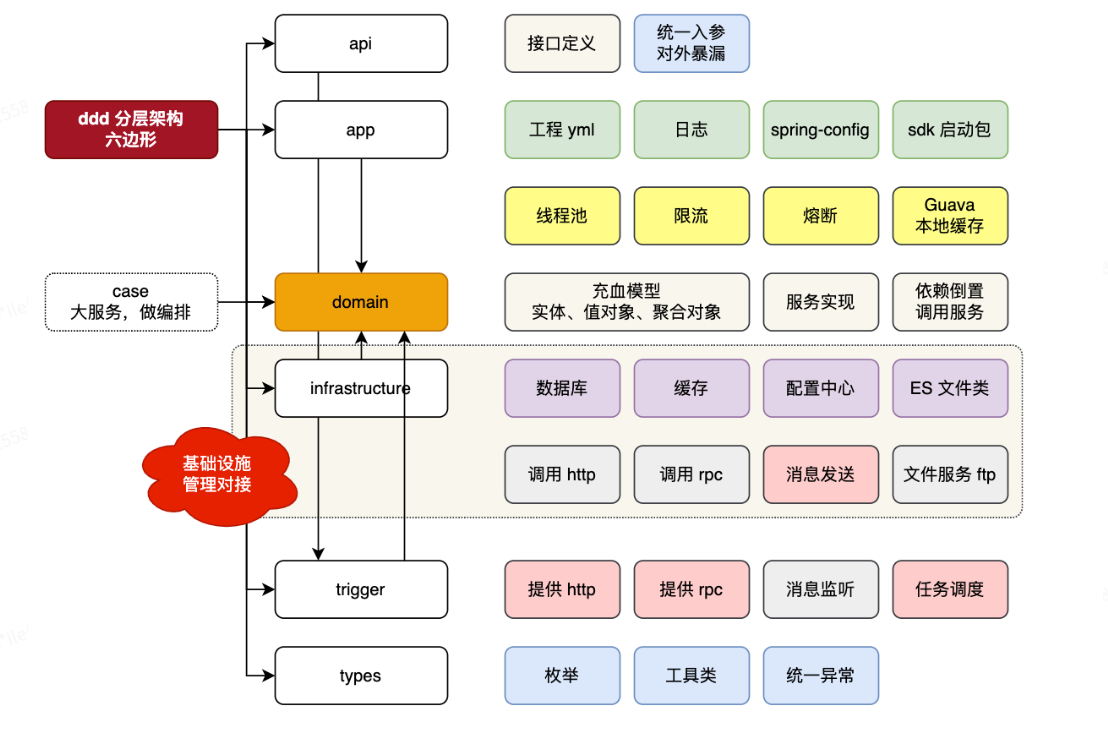
DDD架构设计
MVC架构:
DDD架构:
价格试算
@Service
@RequiredArgsConstructor
public class IndexGroupBuyMarketServiceImpl implements IIndexGroupBuyMarketService {
private final DefaultActivityStrategyFactory defaultActivityStrategyFactory;
@Override
public TrialBalanceEntity indexMarketTrial(MarketProductEntity marketProductEntity) throws Exception {
StrategyHandler<MarketProductEntity, DefaultActivityStrategyFactory.DynamicContext, TrialBalanceEntity> strategyHandler = defaultActivityStrategyFactory.strategyHandler();
TrialBalanceEntity trialBalanceEntity = strategyHandler.apply(marketProductEntity, new DefaultActivityStrategyFactory.DynamicContext());
return trialBalanceEntity;
}
}
IndexGroupBuyMarketService
│
│ indexMarketTrial()
▼
DefaultActivityStrategyFactory
│ (return rootNode)
▼
RootNode.apply()
│ doApply() (执行)
│ router() (路由到下一node)
▼
SwitchNode.apply()
│ ...
▼
... (可能还有其他节点)
▼
EndNode.apply() → 组装结果并返回 TrialBalanceEntity
▲
└────────── 最终一路向上 return
IndexGroupBuyMarketService 是领域服务,整个价格试算的入口
DefaultActivityStrategyFactory 帮你拿到 根节点,真正的“工厂”工作(多线程预处理、分支路由)都在各 Node 里完成。
DynamicContext 是一次性创建的共享上下文:谁需要谁就往里放
人群标签
人群标签采集
| 步骤 | 目的 | 说明 |
|---|---|---|
| 1. 记录日志 | 标明本次批次任务的开始 | 方便后续排查、链路追踪 |
| 2. 读取批次配置 | 拿到该批次统计范围、规则、时间窗等 | 若返回 null 通常代表批次号错误或已被清理 |
| 3. 采集候选用户 | 从业务数仓/模型结果里拉取符合条件的用户 ID 列表 | 真实场景中会:• 调 REST / RPC 拿画像• 或扫离线结果表• 或读 Kafka 流 |
| 4. 双写标签明细 | 将每个用户与标签的关系永久化 & 提供实时校验能力 | 方法内部两件事:• 插入 crowd_tags_detail 表• 在 Redis BitMap 中把该用户对应位设为 1(幂等处理冲突) |
| 5. 更新统计量 | 维护标签当前命中人数,用于运营看板 | 这里简单按“新增条数”累加,也可改为重新 count(*) 全量回填 |
| 6. 结束 | 方法返回 void | 如果过程抛异常,调度系统可重试/报警 |
一句话总结 这是一个被定时器或消息触发的离线批量打标签任务: 拉取任务规则 → (离线)筛出符合条件的用户 → 写库 + 写 Redis 位图 → 更新命中人数。 之后业务系统就能用位图做到毫秒级
isUserInTag(userId, tagId)判断,实现精准运营投放。
Bitmap(位图)
概念
- Bitmap 又称 Bitset,是一种用位(bit)来表示状态的数据结构。
- 它把一个大的“布尔数组”压缩到最小空间:每个元素只占 1 位,要么 0(False)、要么 1(True)。
为什么用 Bitmap?
- 超高空间效率:1000 万个用户,只需要约 10 MB(1000 万 / 8)。
- 超快操作:检查某个索引位是否为 1、计数所有“1”的个数(BITCOUNT)、找出第一个“1”的位置(BITPOS)等,都是 O(1) 或者极快的位运算。
典型场景
- 用户标签 / 权限判断:把符合某个条件的用户的索引位置设置为 1,以后实时判断“用户 X 是否在标签 A 中?”就只需读一个 bit。
- 海量去重 / 布隆过滤器:在超大流量场景下判断“URL 是否已访问过”、“手机号是否已注册”等。
- 统计分析:快速统计某个条件下有多少个用户/对象符合(BITCOUNT)。
人群标签过滤
白名单。
无 tagId(没配标签)→ 不限人群,全部放行(visible=true, enable=true)。
有 tagId 且位图存在 → 位图里的人可以参加(白名单)。
有 tagId 但位图不存在 → 现在的实现是默认全放行(把“未配置位图”当作“不限制”),因为真实场景中由外部系统统计用户行为=>将符合条件的用户放入位图中,这里暂时没有模拟。
拼团交易锁单
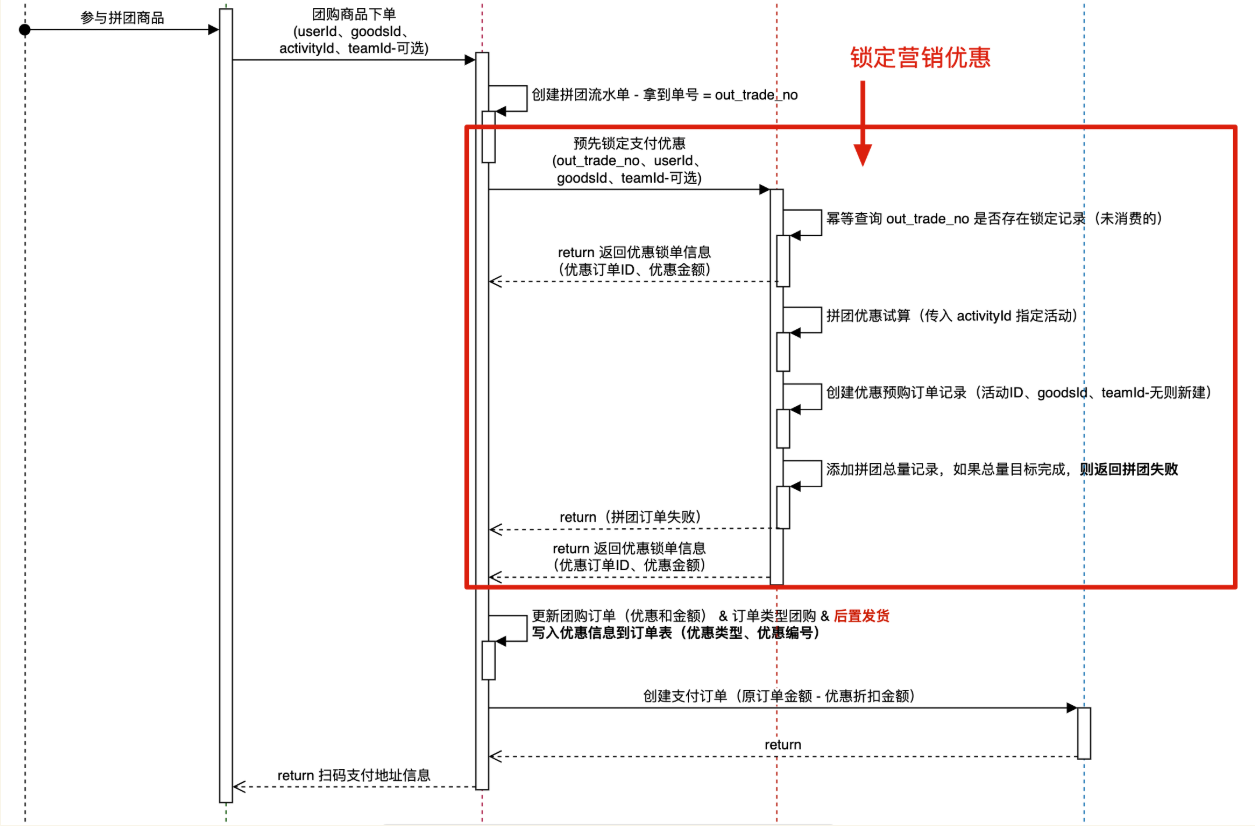
下单到支付中间有一个流程,即锁单,比如淘宝京东中,在这个环节(限定时间内)选择使用优惠券、京豆等,可以得到优惠价,再进行支付;拼团场景同理,先加入拼团,进行锁单,然后优惠试算,最后才付款。
拼团结算
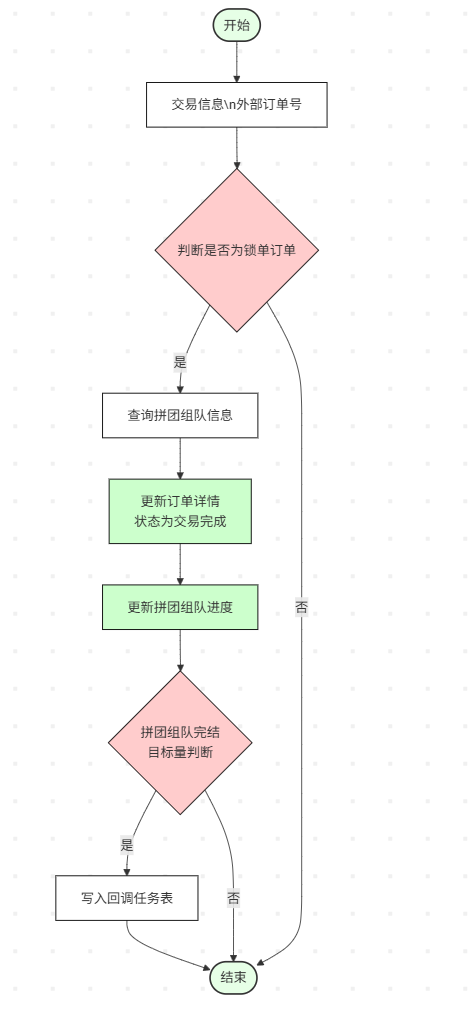
对接商城和拼团系统
拼团锁单
1.用户下单(小型支付商城发起)
- 检查是否存在未支付订单:
- 有
pay_url→ 返回该支付链接 - 无
pay_url→ 进入创建订单流程
- 有
2.创建订单
- 如果存在订单但未支付(无
pay_url)→ 继续创建支付 - 进入 营销锁单(判断是否有营销活动参与,调用拼团系统中的责任链校验:活动有效性、用户参与活动次数、剩余库存数校验,校验通过即可获取营销优惠;否则只能原价购买商品!!!)
- 超时订单关闭(由任务调度触发)
3.营销锁单(调用拼团交易平台接口)
- 请求 Nginx 负载,转发至拼团交易平台的营销锁单模块
- 拼团交易平台内部执行:
- 锁单目标
- 优惠试算
- 规则过滤(活动有效性、用户参与活动次数、剩余库存数校验)
- 写入记录(数据库)
- 返回结果:订单ID、原价、折扣金额、支付金额、订单状态
返回商城
- 小型商城获取优惠后的价格信息
- 创建支付订单
支付完成与组队结算
1.支付回调
- 更新订单状态
- 触发“支付结算并发货”流程
2.组队结算判断
- 调用拼团交易平台组队结算接口,更新当前拼团完成人数
- 判断该拼团是否已完成:
- 是:
- 调用营销结算 HTTP 接口
- 结算完成 N 个用户组成的队伍
- 发送“组队完成回调通知”
- 否:直接结束流程
- 是:
3.后续发货
- 当收到拼团完成(complete_count==target_count)的回调消息时,小型商城执行后续交易结算及发货逻辑(目前是模拟触发的)。
注意
alipay_notify_url
- 作用:支付宝在用户支付成功后,向该地址发起服务器端回调(需公网可访问,或通过内网穿透映射到本地)。
- 调用流程:支付宝 →
pay-mall - 用途:
pay-mall接收到支付成功通知后,可以调用拼团组队结算接口。 - 与之相关的两个地址:
return_url:用户付款后网页自动跳转的地址(通常是返回商城首页),属于前端页面跳转,与业务结算无关。gateway_url:支付宝提供的商户收款页面地址(用户发起付款时访问)。
group-buy-market_notify_url
-
http://127.0.0.1:8092/api/v1/alipay/group_buy_notify 注意!HTTP调用下才使用,MQ这个字段失效!
-
作用:由
pay-mall商城设置,作为拼团平台的回调地址。 -
调用流程:拼团平台(
group-buy-market) →pay-mall -
触发条件:某个
teamId的拼团人数达到目标值,拼团成功。 -
用途:通知
pay-mall对该teamId下所有成员执行后续操作,例如发货。
本地对接
在 group-buying-sys 项目中,对 group-buying-api 模块执行 mvn clean install(或在 IDE 中运行 install)。这会将该模块的 jar 安装到本地 Maven 仓库(~/.m2/repository)。然后在 pay-mall 项目的 pom.xml 中添加依赖,使用相同的 groupId、artifactId 和 version 即可引用该模块,如下所示:
<dependency>
<groupId>edu.whut</groupId>
<artifactId>group-buying-api</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
发包
仅适用于本地,共用一个本地Maven仓库,一旦换台电脑或者在云服务器上部署,无法就这样引入,因此可以进行发包。这里使用阿里云效发包https://packages.aliyun.com/
1)点击制品仓库->生产库
2)下载settings-aliyun.xml文件并保存至本地的Maven的conf文件夹中。
3) 配置项目的Maven仓库为阿里云提供的这个,而不是自己的本地仓库。

4)发包,打开Idea中的Maven,双击deploy
5)验证
6)使用
将公共镜像仓库的settings文件和阿里云效的settings文件合并,可以同时拉取公有依赖和私有包。
逆向工程:退单
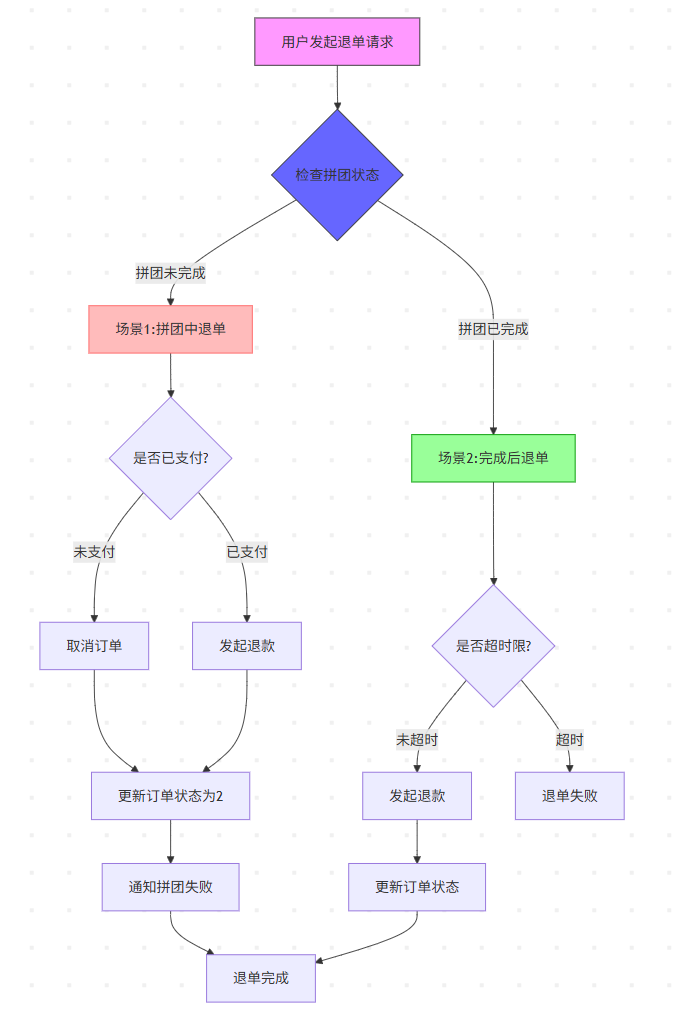
逆向的流程,要分析用户是在哪个流程节点下进行退单行为。包括3个场景;
已锁单、未支付:redis恢复量+1,mysql中锁单量-1
已锁单、已支付,但拼团未成团:redis恢复量+1,mysql中锁单量、完成量-1,退款
已锁单、已支付,且拼团已成团:redis恢复量无需+1,因为成团之后不开放给别人;mysql中锁单量、完成量-1,退款,拼团设置为'已完成含退单'状态,但拼团中所有人都退单,更新为失败!
核心流程说明
阶段一:退单操作流程
-
客户主动提交退单请求
-
通过责任链模式处理:数据加载Node(查询订单) → 重复检查Node(防止重复退单) → 策略执行Node
-
策略选择
根据订单状态和拼团状态选择对应退单策略(三种之一)
-
执行退单
更新数据库操作(锁单量、完成量、拼团状态、订单状态...)
-
消息通知 + 任务补偿
发送MQ退单消息通知(未支付退单、已支付未成团...三种消息 notify_category)
将消息写入notify_task表,定时任务扫描未成功处理的消息,以做补偿兜底。
阶段二:库存恢复流程
-
消息监听
MQ监听器接收退单成功消息
-
服务调用
调用恢复库存服务
-
策略选择
根据退单类型选择对应策略(已成团的无需恢复了,反正新用户也无法再参与该拼团)
-
库存恢复
执行Redis库存恢复操作(带分布式锁保护)
设计模式应用
-
责任链模式
TradeRefundRuleFilterFactory构建的过滤链:
DataNodeFilter→UniqueRefundNodeFilter→RefundOrderNodeFilter -
策略模式
-
策略接口:
RefundOrderStrategy -
实现策略:
Unpaid2RefundStrategy(未付款退单的流程)
Paid2RefundStrategy(已付款退单)
PaidTeam2RefundStrategy(已成团退单)
-
-
工厂模式
TradeRefundRuleFilterFactory负责组装责任链 -
模板方法模式
AbstractRefundOrderStrategy提供:- 公共方法封装 (发送退单MQ消息、库存恢复redis)
- 依赖注入支持
退单触发入口
1)用户主动退单
2)定时任务,定时任务扫描锁单但未结算的订单,若支付时间超过设定值,对这笔订单执行退单操作。

注意:小型支付商城中的订单可能有些是普通订单,有些是拼团订单。
对于普通订单,无需调用拼团系统中的退单接口,自己本地退单,对于CREATE或PAY_WAIT状态的订单,直接修改订单状态为CLOSED;对于PAY_SUCCESS(个人支付完成)、DEAL_DONE,额外调用支付宝退款。
对于拼团订单,RPC调用拼团系统的退单接口,调用成功后设置订单为WAIT_REFUND,然后由MQ消息回调调用支付宝退款。
MQ消息通知
有三种MQ消息:
1.退款成功通知
2.拼团组队成功通知
3.订单支付成功消息
退款成功消息:拼团系统发送,拼团订单。小型商城和拼团系统都接收,各自执行退单流程。
组队成功消息:拼团系统发送,拼团订单。主要是小型商城接收,更新订单状态;拼团系统仅仅是简单的打印一下'通知成功'消息。
订单支付成功消息:小型商城发送,拼团订单+普通订单。小型商城接收,更新订单状态=>模拟发货。
不仅在相关接口完成的时候自动发送MQ消息,同时有兜底,将MQ消息持久化进Mysql,设置定时任务来扫描表,对暂未处理(处理失败)的MQ消息重新投递。
| 字段名 | 类型 | 允许为空 | 默认值 | 约束 / 备注 |
|---|---|---|---|---|
id |
int UNSIGNED | NO | AUTO_INCREMENT | 自增ID,主键 |
activity_id |
bigint | NO | 活动ID | |
team_id |
varchar(8) | NO | 拼单组队ID | |
notify_category |
varchar(64) | YES | NULL | 回调种类 |
notify_type |
varchar(8) | NO | 'HTTP' |
回调类型(HTTP、MQ) |
notify_mq |
varchar(32) | YES | NULL | 回调消息 |
notify_url |
varchar(128) | YES | NULL | 回调接口 |
notify_count |
int | NO | 回调次数 | |
notify_status |
tinyint(1) | NO | 回调状态【0 初始、1 完成、2 重试、3 失败】 | |
parameter_json |
varchar(256) | NO | 参数对象(JSON 字符串) | |
uuid |
varchar(128) | NO | 唯一标识 | |
create_time |
datetime | NO | CURRENT_TIMESTAMP | 创建时间 |
update_time |
datetime | NO | CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP | 更新时间 |
收获
实体对象
实体是指具有唯一标识的业务对象。
在 DDD 分层里,Domain Entity ≠ 数据库 PO。
在 edu.whut.domain.*.model.entity 包下放的是纯粹的业务对象,它们只表达业务语义(团队 ID、活动时间、优惠金额……),对「数据持久化细节」保持无感知。因此它们看起来“字段不全”是正常的:
- 它们不会带
@TableName/@TableId等 MyBatis-Plus 注解; - 也不会出现数据库的技术字段(
id、create_time、update_time、status等); - 只保留聚合根真正需要的业务属性与行为。
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class PayActivityEntity {
/** 拼单组队ID */
private String teamId;
/** 活动ID */
private Long activityId;
/** 活动名称 */
private String activityName;
/** 拼团开始时间 */
private Date startTime;
/** 拼团结束时间 */
private Date endTime;
/** 目标数量 */
private Integer targetCount;
}
这个也是实体对象,因为多个字段的组合: teamId 和 activityId 能唯一标识这个实体。
多线程异步调用
如果某任务比较耗时(如加载大量数据),可以考虑开多线程异步调用。
// Runnable ➞ 只能 run(),没有返回值
public interface Runnable {
void run();
}
// Callable<V> ➞ call() 能返回 V,也能抛检查型异常
public interface Callable<V> {
V call() throws Exception;
}
public class MyTask implements Callable<String> {
private final String name;
public MyTask(String name) {
this.name = name;
}
@Override
public String call() throws Exception {
// 模拟耗时操作
TimeUnit.MILLISECONDS.sleep(300);
return "任务[" + name + "]的执行结果";
}
}
public class SimpleAsyncDemo {
public static void main(String[] args) {
// 创建大小为 2 的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);
try {
// 构造两个任务
MyTask task1 = new MyTask("A");
MyTask task2 = new MyTask("B");
// 用 FutureTask 包装 Callable
FutureTask<String> future1 = new FutureTask<>(task1);
FutureTask<String> future2 = new FutureTask<>(task2);
// 提交给线程池异步执行
pool.execute(future1);
pool.execute(future2);
// 主线程可以先做别的事…
System.out.println("主线程正在做其他事情…");
// 在需要的时候再获取结果(可加超时)
String result1 = future1.get(1, TimeUnit.SECONDS); //设置超时时间1秒
String result2 = future2.get(); //无超时时间
System.out.println("拿到结果1 → " + result1);
System.out.println("拿到结果2 → " + result2);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} catch (ExecutionException e) {
System.err.println("任务执行中出错: " + e.getCause());
} catch (TimeoutException e) {
System.err.println("等待结果超时");
} finally {
pool.shutdown();
}
}
}
动态配置(热更新)
原理:利用 Redis 的发布/订阅(Pub/Sub)机制,在程序运行时动态推送配置变更通知,订阅者接收到消息后更新相应的 Bean 字段。通过 反射(Reflection API) 可以动态修改运行中的对象实例的字段值。
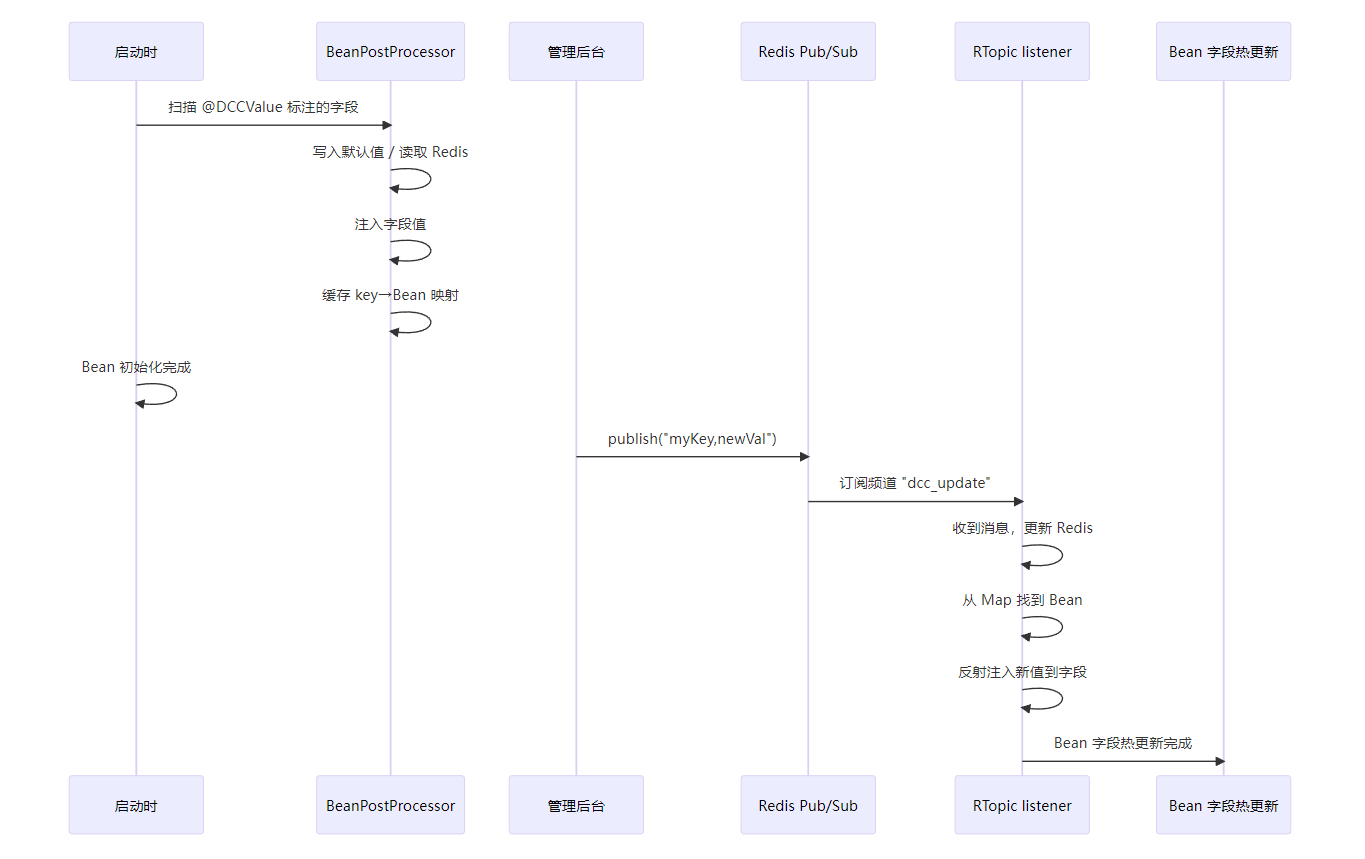
实现步骤
注解标记
用 @DCCValue("key:default") 标注需要动态注入的字段,指定 Redis Key 和默认值。
// 标记要动态注入的字段
@Retention(RUNTIME) @Target(FIELD)
public @interface DCCValue {
String value(); // "key:default"
}
// 业务使用示例
@Service
public class MyFeature {
@DCCValue("myFlag:0") //标注字段,默认值为0
private String myFlag;
public boolean enabled() { return "1".equals(myFlag); }
}
启动时注入
实现 BeanPostProcessor,覆写postProcessAfterInitialization方法,在每个 Spring Bean 初始化后自动执行:
- 扫描标注了
@DCCValue的字段; - 拼接完整 Redis Key,若 Redis 中没有配置,则写入默认值;
- 通过反射将配置值注入到 Bean 的字段;
- 将配置与 Bean 映射关系存入内存,以便后续热更新。
@Override
public Object postProcessAfterInitialization(Object bean, String name) {
Class<?> cls = AopUtils.isAopProxy(bean) ? AopUtils.getTargetClass(bean) : bean.getClass();
for (Field f : cls.getDeclaredFields()) {
DCCValue dccValue = f.getAnnotation(DCCValue.class);
if (dccValue != null) {
String[] parts = dccValue.value().split(":");
String key = PREFIX + parts[0]; // Redis 中存储的 Key
String defaultValue = parts[1]; // 默认值
RBucket<String> bucket = redis.getBucket(key);
String value = bucket.isExists() ? bucket.get() : defaultValue;
bucket.trySet(defaultValue); // 若 Redis 中无配置,则写入默认值
injectField(bean, f, value); // 通过反射注入值
beans.put(key, bean); // 缓存配置与 Bean 映射关系
}
}
return bean; // 返回初始化后的 Bean
}
运行时热更新
-
订阅一个 Redis Topic(频道),比如
"dcc_update"; -
外部通过发布接口
PUBLISH dcc_update "key,newValue"发送更新消息;private final RTopic dccTopic; @GetMapping("/dcc/update") public void update(@RequestParam String key, @RequestParam String value) { // 发布配置更新消息到 Redis 主题,格式为 "configKey,newValue" String message = key + "," + value; dccTopic.publish(message); // 通过 dccTopic 发布更新消息 log.info("配置更新发布成功 - key: {}, value: {}", key, value); } -
订阅者收到后:
- 更新 Redis 中的配置;
- 从映射里取出对应 Bean,使用反射更新字段。
// 发布/订阅配置热更新
@Bean("dccTopic")
public RTopic dccTopic(RedissonClient redis) {
RTopic dccTopic = redis.getTopic("dcc_update");
dccTopic.addListener(String.class, (channel, msg) -> {
String[] parts = msg.split(","); // msg 约定格式:"configKey,newValue"
String key = PREFIX + parts[0]; // 拼接 Redis Key
String newValue = parts[1]; // 新的配置值
RBucket<String> bucket = redis.getBucket(key);
if (!bucket.isExists()) {
return; // 如果不是我们关心的配置,跳过
}
bucket.set(newValue); // 更新 Redis 中的配置
Object bean = beans.get(key); // 从内存中取出 Bean 实例
if (bean != null) {
injectField(bean, parts[0], newValue); // 通过反射更新 Bean 字段
}
});
return dccTopic; // 返回 Redis Topic 实例
}
在 Redis 的发布/订阅模型中,RTopic dccTopic = redis.getTopic("dcc_update"); 这行代码指定了 dccTopic 订阅的主题(也可以理解为一个消息通道)。不同的类可以通过依赖注入来使用这个 RTopic 实例。一些类可以调用 dccTopic.publish(message) 向该通道发送消息;而另一些类则可以通过 dccTopic.addListener() 来订阅该主题,从而接收消息并进行相应的处理。
热更新数据流转过程
1.广播消息(PUBLISH):配置变更会通过 PUBLISH 命令广播到 Redis 中的某个主题。
2.Redis Sub(订阅):订阅该主题的客户端收到消息后,进行处理。
3.更新 Redis 和 Bean 字段:
- 更新 Redis 中的配置(保持一致性)。
- 更新 Bean 实例的对应字段(通过反射,确保配置的实时性)。
OkHttpClient
引入依赖
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp-sse</artifactId>
</dependency>
让Spring 管理 Http客户端
写配置类
@Configuration
public class OKHttpClientConfig {
@Bean
public OkHttpClient httpClient() {
return new OkHttpClient();
}
}
在需要使用的地方注入
@Slf4j
@Service
@RequiredArgsConstructor
public class HttpService {
private final OkHttpClient okHttpClient;
/**
* 发送 JSON POST 请求并返回响应内容
*
* @param apiUrl 接口地址
* @param jsonPayload 请求体 JSON 字符串
*/
public String postJson(String apiUrl, String jsonPayload) throws IOException {
//1.构建参数
MediaType mediaType = MediaType.get("application/json; charset=utf-8");
RequestBody body = RequestBody.create(jsonPayload, mediaType);
Request request = new Request.Builder()
.url(apiUrl)
.post(body)
.addHeader("Content-Type", "application/json")
.build();
//2.调用接口
try (Response response = okHttpClient.newCall(request).execute()) {
if (!response.isSuccessful()) {
log.error("HTTP 请求失败,URL:{},状态码:{}", apiUrl, response.code());
throw new IOException("Unexpected HTTP code " + response.code());
}
ResponseBody responseBody = response.body();
return responseBody != null ? responseBody.string() : "";
} catch (IOException e) {
log.error("调用 HTTP 接口异常:{}", apiUrl, e);
throw e;
}
}
}
优点:
单例复用,性能更优
- Spring 默认将 Bean 作为单例管理,整个应用只创建一次
OkHttpClient。 - 内部的连接池、线程池、缓存等资源可以被复用,避免频繁创建、销毁带来的开销。
统一配置,易于维护
- 超时、拦截器、连接池、SSL、日志等配置集中在一个地方,改动一次全局生效。
- 避免在代码各处手动
new OkHttpClient()、重复配置。
Retrofit
Retrofit 适用于:
- 第三方服务集成:如调用 Web 服务,RESTful API 等。
- API 请求封装:在 Java 或 Android 中,简化 HTTP 请求与响应的处理。
- 灵活的调用方式:支持同步和异步的请求,适用于处理外部接口的调用。
RPC 适用于:
- 微服务架构:内部服务之间需要高效、低延迟的通信。
- 跨语言服务:支持多种编程语言间的通信,特别是采用类似 gRPC 这样的协议。
- 高吞吐量、低延迟:RPC 常常用于对性能要求较高的系统,尤其是微服务通信。
快速入门
// 1. 定义 DTO
public class User {
private String id;
private String name;
// … 省略 getters/setters …
}
// 2. 定义 Retrofit 接口
public interface ApiService {
@GET("users/{id}")
Call<User> getUser(@Path("id") String id);
}
// 3. 配置 Retrofit 并注册为 Spring Bean
@Configuration
public class RetrofitConfig {
private static final String BASE_URL = "https://api.example.com/";
@Bean
public Retrofit retrofit() {
return new Retrofit.Builder()
.baseUrl(BASE_URL) // 公共前缀
.addConverterFactory(JacksonConverterFactory.create()) // 自动 JSON ↔ DTO
.build();
}
@Bean
public ApiService apiService(Retrofit retrofit) {
// 动态生成 ApiService 实现
return retrofit.create(ApiService.class);
}
}
// 4. 在业务层注入并调用
@Service
public class UserService {
private final ApiService apiService;
public UserService(ApiService apiService) {
this.apiService = apiService;
}
/**
* 同步方式获取用户信息
*/
public User getUserById(String userId) {
try {
Call<User> call = apiService.getUser(userId);
Response<User> resp = call.execute();
if (resp.isSuccessful()) {
return resp.body();
} else {
// 根据业务需要抛出异常或返回 null
throw new RuntimeException("请求失败,HTTP " + resp.code());
}
} catch (Exception e) {
throw new RuntimeException("调用用户服务出错", e);
}
}
/**
* 异步方式获取用户信息
*/
public void getUserAsync(String userId) {
apiService.getUser(userId).enqueue(new retrofit2.Callback<User>() {
@Override
public void onResponse(Call<User> call, Response<User> response) {
if (response.isSuccessful()) {
User user = response.body();
// TODO: 处理 user
}
}
@Override
public void onFailure(Call<User> call, Throwable t) {
// TODO: 处理异常
}
});
}
}
Retrofit 在运行时会生成这个接口的实现类,帮你完成:
- 拼 URL(把
{id}换成具体值) - 发起 GET 请求
- 拿到响应的 JSON 并自动反序列化成
User对象
支付宝下单沙箱
https://open.alipay.com/develop/sandbox/app
读取本地配置文件。
@Data
@Component
@ConfigurationProperties(prefix = "alipay", ignoreInvalidFields = true)
public class AliPayConfigProperties {
// 「沙箱环境」应用ID - 您的APPID,收款账号既是你的APPID对应支付宝账号。获取地址;https://open.alipay.com/develop/sandbox/app
private String appId;
// 「沙箱环境」商户私钥,你的PKCS8格式RSA2私钥
private String merchantPrivateKey;
// 「沙箱环境」支付宝公钥
private String alipayPublicKey;
// 「沙箱环境」服务器异步通知页面路径
private String notifyUrl;
// 「沙箱环境」页面跳转同步通知页面路径 需http://格式的完整路径,不能加?id=123这类自定义参数,必须外网可以正常访问
private String returnUrl;
// 「沙箱环境」
private String gatewayUrl;
// 签名方式
private String signType = "RSA2";
// 字符编码格式
private String charset = "utf-8";
// 传输格式
private String format = "json";
}
创建alipay客户端。
@Configuration
public class AliPayConfig {
@Bean("alipayClient")
public AlipayClient alipayClient(AliPayConfigProperties properties) {
return new DefaultAlipayClient(properties.getGatewayUrl(),
properties.getAppId(),
properties.getMerchantPrivateKey(),
properties.getFormat(),
properties.getCharset(),
properties.getAlipayPublicKey(),
properties.getSignType());
}
}
公众号扫码登录流程
https://mp.weixin.qq.com/debug/cgi-bin/sandboxinfo?action=showinfo&t=sandbox/index 微信开发者平台。
微信登录时,需要调用微信提供的接口做验证,使用Retrofit
场景:用微信的能力来替你的网站做“扫码登录”或“社交登录”,代替自己写一整套帐号/密码体系。后台只需要基于 openid 做一次性关联(比如把某个微信号和你系统的用户记录挂钩),后续再次扫码就当作同一用户;
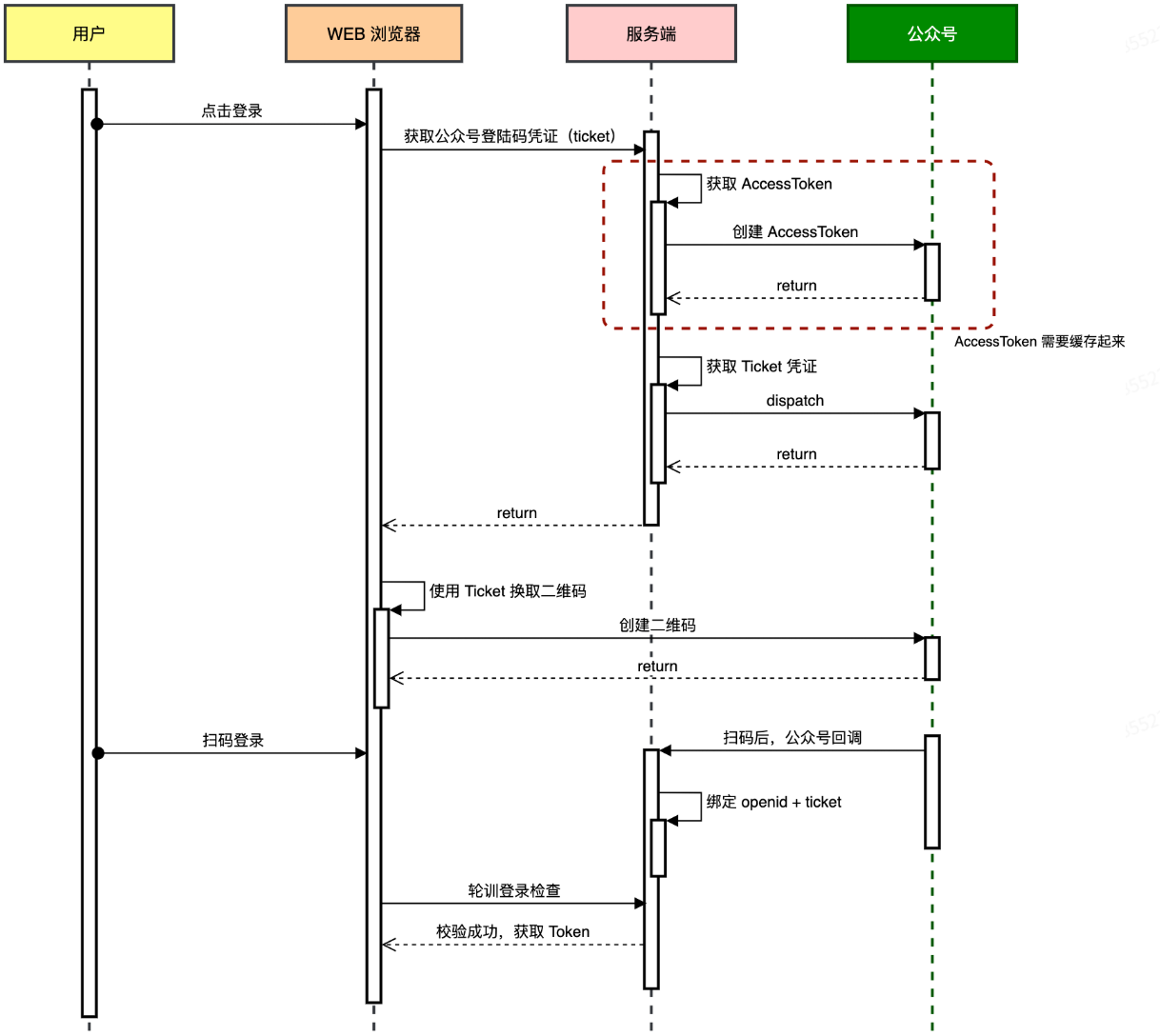
1.前端请求二维码凭证
-
用户点击“扫码登录”,前端向后端发
GET /api/v1/login/weixin_qrcode_ticket。 -
后端获取 access_token 1.先尝试从本地缓存(如 Guava Cache)读取
access_token; 2.若无或已过期,则请求微信接口:GET https://api.weixin.qq.com/cgi-bin/token ?grant_type=client_credential &appid={你的 AppID} &secret={你的 AppSecret}微信返回
{ "access_token":"ACCESS_TOKEN_VALUE", "expires_in":7200 },后端缓存这个值(有效期约 2 小时)。 -
后端利用
access_token创建二维码 ticket,返给前端。(每次调用微信会返回不同的ticket)
2.前端展示二维码
- 前端根据
ticket生成二维码链接:https://mp.weixin.qq.com/cgi-bin/showqrcode?ticket={ticket}
3.微信回调后端
- 用户确认扫描后,微信服务器向你预先配置的回调 URL(如
POST /api/v1/weixin/portal/receive)推送包含ticket和openid的消息。 - 后端:将
ticket → openid存入缓存(openidToken.put(ticket, openid));调用sendLoginTemplate(openid)给用户推送“登录成功”模板消息(手机公众号上推送,非网页)
4.前端获知登录结果
- 轮询方式:生成二维码后,前端每隔几秒向后端
check_login接口发送ticket来验证登录状态,后端查缓存来判断ticket对应用户是否成功登录。 - 推送方式:前端通过 WebSocket/SSE 建立长连接,后端回调处理完成后直接往该连接推送登录成功及 JWT。
浏览器指纹获取登录ticket
在扫码登录流程的基础上改进!!!
目的:把「这张二维码/ticket」严格绑在发起请求的那台浏览器上,防止别的设备或会话拿到同一个 ticket 就能登录。
1.生成指纹
前端在用户打开「扫码登录页」时,先用 JS/浏览器 API(比如 User-Agent、屏幕分辨率、插件列表、Canvas 指纹等)算出一个唯一的浏览器指纹 fp。
2.获取 ticket 时携带指纹
前端发起请求:
GET /api/v1/login/weixin_qrcode_ticket_scene?sceneStr=<fp>
后端执行:
String ticket = loginPort.createQrCodeTicket(sceneStr);
sceneTicketCache.put(sceneStr, ticket); // 把 fp→ticket 映射进缓存
3.扫码后轮询校验
前端轮询:传入 ticket 和 sceneStr 指纹
GET /api/v1/login/check_login_scene?ticket=<ticket>&sceneStr=<fp>
后端逻辑(简化):
// 1) 验证拿到的 sceneStr(fp) 对应的 ticket 是否一致
String cachedTicket = sceneTicketCache.getIfPresent(sceneStr);
if (!ticket.equals(cachedTicket)) {
// fp 不匹配,拒绝
return NO_LOGIN;
}
// 2) 再看 ticket→openid 有没有被写入(扫码并回调后,saveLoginState 会写入)
String openid = ticketOpenidCache.getIfPresent(ticket);
if (openid != null) {
// 同一浏览器,且已扫码确认,返回 openid(或 JWT)
return SUCCESS(openid);
}
return NO_LOGIN;
4.回调时保存登录状态
当用户扫描二维码,微信会回调你预定的接口地址,拿到 ticket、openid 后,调用:
ticketOpenidCache.put(ticket, openid); // 保存 ticket→openid
注意 ticketOpenidCache 和 sceneTicketCache 一般是一个Cache Bean,这里只是为了更清晰。
安全性提升
- 防止“票据劫持”:别人就算截获了这个 ticket,想拿去自己那台机器上轮询也不行,因为指纹对不上。
- 防止多人共用:多个人在不同设备上同时扫同一个码,只有最先发起获取 ticket 的那台浏览器能完成登录。
独占锁和无锁化场景(防超卖)
独占锁
适用场景
- 定时任务互备 多机部署时,确保每天只有一台机器在某个时间点执行同一份任务(如数据清理、报表生成、邮件推送等)。
@Scheduled(cron = "0 0 0 * * ?")
public void exec() {
// 获取锁句柄,并未真正获取锁
RLock lock = redissonClient.getLock("group_buy_market_notify_job_exec");
try {
//尝试获取锁 waitTime = 3:如果当前锁已经被别人持有,调用线程最多等待 3 秒去重试获取;leaseTime = 0:不设过期时间,看门狗机制
boolean isLocked = lock.tryLock(3, 0, TimeUnit.SECONDS);
if (!isLocked) return;
Map<String, Integer> result = tradeSettlementOrderService.execSettlementNotifyJob();
log.info("定时任务,回调通知拼团完结任务 result:{}", JSON.toJSONString(result));
} catch (Exception e) {
log.error("定时任务,回调通知拼团完结任务失败", e);
} finally {
if (lock.isLocked() && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
无锁化场景
“无锁化”设计 的核心思路是不在整个逻辑上加一把全局互斥锁,而是用 Redis 原子操作 + 后置校验/补偿 来完成并发控制。
原子计数(Atomic Counter)
用 Redis 的 INCR(或 Redisson 的 RAtomicLong.incrementAndGet())来保证并发环境下每次调用都能拿到一个唯一、自增的数字。这个数字可以看作“第 N 个占位请求”。
边界校验+补偿回滚(Validation & Compensation)
拿到新数字后,马上与允许的最大值(target + 已回滚补偿数)做比较:
- 如果在范围内,视为占位成功;
- 如果超出范围,则把 Redis 里的计数器重置回
target(即“丢弃”这次多余的自增),并返回失败。
极端兜底锁(Fallback Lock)
虽然 INCR 本身已经原子,但在极端运维或网络抖动下仍有极小几率两次自增同时返回相同值。
因此,针对每个“序号”再做一次最轻量的 SETNX(key:occupySeq):
- 成功
SETNX→ 序号唯一,真正拿到名额; - 失败
SETNX→ 重复抢号,拒绝这次占位。
典型适用场景
- 电商秒杀 & 拼团抢购 万级甚至十万级并发下不适合所有请求都排队,必须让绝大多数请求用原子计数并行处理。
- 抢票系统 票务分配、座位预占,都讲究“先到先得”+“补偿回退”,不能用一把大锁。
public boolean occupyTeamStock(String teamOccupiedStockKey, String recoveryTeamStockKey, Integer target, Integer validTime) {
// 获取失败恢复量(系统异常时记录的可回收库存)
Long recoveryCount = redisService.getAtomicLong(recoveryTeamStockKey);
recoveryCount = (recoveryCount == null) ? 0 : recoveryCount;
// 自增占用量,+1 表示团长开团已占一单
long occupy = redisService.incr(teamOccupiedStockKey) + 1;
// 超出可用库存(目标值 + 恢复量)则失败
if (occupy > target + recoveryCount) {
return false;
}
// 兜底:为每个序号加分布式锁,防止极端情况下序号重复
// 过期时间比 validTime 多 60 分钟,便于排查问题
String lockKey = teamOccupiedStockKey + Constants.UNDERLINE + occupy;
Boolean lock = redisService.setNx(lockKey, validTime + 60, TimeUnit.MINUTES);
if (!lock) {
log.info("组队库存加锁失败 {}", lockKey);
}
return lock;
}
注意,这里的锁单量teamOccupiedStockKey是Redis中的,非mysql中的!!!因此锁单量不会减少!当用户退款后,redis中恢复量recoveryCount会+1。
即这两个量都是递增的,不要与mysql中的lock_count混淆了。
本项目有两层防护:第一层是下单前的人数/库存校验,比较基础,由于前端可能更新不及时,显示还差X人拼团,但用户点进去时已达人数的情况。第二层是真正的并发保证,即Redis 原子操作 + 后置校验/补偿。
生活例子理解
假设你有一个限量商品,每个商品有一个唯一的编号,假设这些商品编号为 1、2、3、4、5(总共 5 个)。这些商品被分配给用户,每个用户会抢一个编号。每个用户成功抢到一个商品后,系统会在库存中占用一个编号。
抢购过程:
- 有 5 个商品编号(1-5),这些编号是库存量。
- 每个用户请求一个商品编号,系统会给用户分配一个编号(这个过程就像是自增占用量的过程)。
- 如果用户请求的编号超过了现有库存的最大编号(5),则说明没有商品可以分配给该用户,用户抢购失败。
- 如果有多个用户抢同一个编号(例如都想抢到编号 1 的商品),系统通过“分布式锁”来保证只有一个用户能成功抢到编号 1,其他用户则失败。
Supplier<T>
Supplier<T> 是 Java 8 提供的一个函数式接口
@FunctionalInterface
public interface Supplier<T> {
/**
* 返回一个 T 类型的结果,参数为空
*/
T get();
}
任何“无参返回一个 T 类型对象”的代码片段(方法引用或 lambda)都可以当成 Supplier<T> 来用。
作用
1.延迟执行
把“取数据库数据”这类开销大的操作,包装成 Supplier<T> 传进去;只有真正需要时(缓存未命中),才调用 supplier.get() 去跑查询。
2.解耦逻辑
缓存逻辑和查询逻辑分离,缓存组件不用知道“怎么查库”,只负责“啥时候要查”,调用方通过 Supplier 把查库方法交给它。
3.重用性高
同一个缓存-回源模板方法可以服务于任何返回 T 的场景,既可以查 User,也可以查 Order、List<Product>……
// 服务方法:它只关心“缓存优先,否则回源”
// dbFallback 是一段延迟执行的查库代码
protected <T> T getFromCacheOrDb(String cacheKey, Supplier<T> dbFallback) {
// 1) 先从缓存拿
T v = cache.get(cacheKey);
if (v != null) return v;
// 2) 缓存没命中,调用 dbFallback.get() 去“回源”拿数据
T fromDb = dbFallback.get();
if (fromDb != null) {
cache.put(cacheKey, fromDb);
}
return fromDb;
}
// 调用时这么写:
User user = getFromCacheOrDb(
"user:42",
() -> userRepository.findById(42) // 这里的 () -> ... 就是一个 Supplier<User>
);
List<Product> list = getFromCacheOrDb(
"hot:products",
() -> productService.queryHotProducts() // Supplier<List<Product>>
);
分布式限流(AOP + Redisson 实现)+黑名单
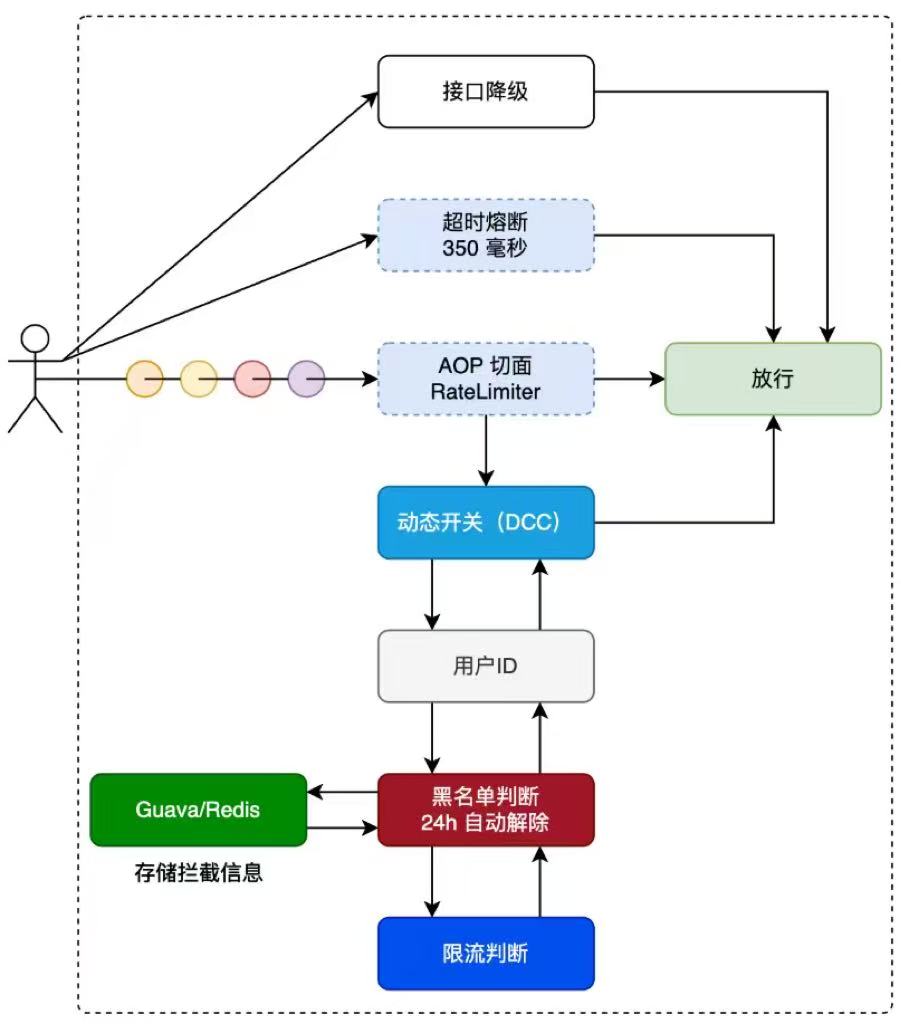
核心思路
动态开关管理
- 使用
@DCCValue("rateLimiterSwitch:open")从配置中心动态注入全局开关,支持热更新。 - 当开关为
"close"时,直接放行所有请求,切面不再执行限流逻辑。
AOP 切面拦截
- 通过自定义注解
@RateLimiterAccessInterceptor标记需要限流的方法。 - 注解参数
key用于指定限流维度(如userId表示按用户限流,all表示全局限流)。 - 切面在运行时解析这个字段的值,动态生成 Redis 限流器 Key,例如:
//添加拦截注解
@RateLimiterAccessInterceptor(key = "userId", permitsPerSecond = 5, fallbackMethod = "fallback")
public void order(String userId) {...}
请求1: userId=U12345 → Redis Key: rl:limiter:U12345
请求2: userId=U67890 → Redis Key: rl:limiter:U67890
限流与黑名单
- 使用
RRateLimiter实现分布式令牌桶,每秒放入permitsPerSecond个令牌。 - 取不到令牌时:
- 如果配置了
blacklistCount,用RAtomicLong记录该 Key 的拒绝次数; - 拒绝次数超限后,将 Key 加入黑名单 24 小时。
- 如果配置了
- 命中黑名单或限流时,调用注解里的
fallbackMethod执行降级逻辑。
令牌桶算法(Token Bucket)
- 工作原理:按固定速率往桶里放“令牌”(tokens),例如每秒放 N 个。每次请求到达时,必须先从桶中“取一个令牌”,才能通过;如果取不到,则拒绝或降级。
- 特点:支持流量平滑释放和突发流量吸纳,桶最多能存储 M 个令牌。
方法调用
↓
AOP 切面拦截(匹配 @RateLimiterAccessInterceptor)
↓
检查全局限流开关(@DCCValue 注入)
↓
解析注解里的 key → 获取对应参数值(如 userId)
↓
黑名单检查(RAtomicLong)
↓
分布式令牌桶限流(RRateLimiter.tryAcquire)
↓
├─ 成功 → 执行目标方法
└─ 失败 → 累加拒绝计数 & 调用 fallbackMethod
| 对比维度 | 本地限流 | 分布式限流 |
|---|---|---|
| 实现复杂度 | 低:直接用 Guava RateLimiter,几行代码即可接入 |
中高:依赖 Redis/Redisson,需要注入客户端并管理限流器 |
| 性能开销 | 极低:全程内存操作,纳秒级延迟 | 中等:每次获取令牌需网络往返,存在 RTT 延迟 |
| 限流范围 | 单实例:仅对当前 JVM 有效,多实例互不影响 | 全局:多实例共享同一套令牌桶,合计速率可控 |
| 状态持久化 & 容错 | 无:服务重启后状态丢失;实例宕机只影响自身 | 有:Redis 存储限流器与黑名单,可持久化;需保证 Redis 可用性 |
目前本项目采用 分布式限流,使用 Redisson 实现跨实例令牌桶,确保全局限流控制。
日志系统
输出流向一览
输出到3个地方:控制台、本地文件、ELK日志(服务器上内存不足无法部署!)
| 日志级别 | 控制台 | 本地文件(异步) | Logstash (TCP) |
|---|---|---|---|
| TRACE/DEBUG | — | — | — |
| INFO | ✔ | log_info.log |
✔ |
| WARN | ✔ | log_info.log``log_error.log |
✔ |
| ERROR/FATAL | ✔ | log_info.log``log_error.log |
✔ |
注意:实际写文件时,都是通过 ASYNC_FILE_INFO/ERROR 两个异步 Appender 执行,以免日志写盘阻塞业务线程。
ELK日志系统
本地文件每台机器都会在自己 /data/log/... 目录下滚动输出自己的日志,互相之间不会合并。
如果你希望跨多台服务器统一管理,就需要把日志推到中央端——ELK日志系统
ELK=Elasticsearch(存储&检索)+ Logstash(采集&处理)+ Kibana(可视化)
docker-compose.yml:
version: '3'
services:
elasticsearch:
image: elasticsearch:7.17.28
ports: ['9201:9200','9300:9300']
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms512m -Xmx512m
volumes:
- ./data:/usr/share/elasticsearch/data
logstash:
image: logstash:7.17.28
ports: ['4560:4560','9600:9600']
volumes:
- ./logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
environment:
- LS_JAVA_OPTS=-Xms1g -Xmx1g
kibana:
image: kibana:7.17.28
ports: ['5601:5601']
environment:
- elasticsearch.hosts=http://elasticsearch:9200
networks:
default:
driver: bridge
kibana配置:
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.host: "0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://elasticsearch:9200" ] # 记得修改ip
monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
logstash配置:
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 4560
codec => json_lines
type => "info"
}
}
filter {}
output {
elasticsearch {
action => "index"
hosts => "es:9200"
index => "group-buy-market-log-%{+YYYY.MM.dd}"
}
}
自己的项目:
<!-- 上报日志;ELK -->
<springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOG_STASH_HOST}:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.3</version>
</dependency>
使用
检查索引:curl http://localhost:9201/_cat/indices?v3
打开 Kibana:浏览器访问 http://localhost:5601,新建 索引模式(如 app-log-*),即可在 Discover/Visualize 中查看与分析日志。
防止重复下单
前端限制
- 点击下单按钮后,将按钮设置为禁用状态
后端限制
即使前端做了按钮禁用,还是可能存在用户通过其他方式发起多个请求。
在高并发支付场景中,确保同一用户对同一商品/活动只生成一条待支付订单,常用以下两种思路:
业务维度复合唯一索引 + 冲突捕获重试
-
利用业务维度字段(
userId+goodId+activityId)创建复合唯一索引,避免重复下单。 -
通过查询数据库检查是否已有未支付订单,若有则直接返回该订单。
-
若并发创建订单导致唯一约束冲突,捕获异常后重新查询返回已创建订单。
-
可选:使用分布式锁来控制高并发环境中的锁操作,确保只有首个请求能够创建订单。
幂等 Key 模式
外部交易单号设计
- 统一跟踪:对接小商城时,将外部交易单号(
out_trade_no)与小商城下单时生成的order_id保持一致,方便全链路追踪。 - 内部独立:拼团系统内部仍保留自己的
order_id,互不冲突。
-
生成幂等 Key
- 前端进入支付流程时调用接口(
GET /api/idempotency-key),后端生成全局唯一 ID(UUID 或雪花 ID)返回给前端; - 或者外部系统(如小商城)传来唯一的外部交易单号(
out_trade_no),天生作为幂等Key。 - 前端将该 Key 存入内存、LocalStorage 或隐藏表单字段,直至支付完成或过期。
- 前端进入支付流程时调用接口(
-
请求携带幂等 Key
- 用户点击“下单”时,调用
/create_pay_order接口,需在请求体中附带idempotencyKey; - 服务端根据该 Key 判断:若数据库中已有相同
idempotency_key,直接返回该订单,否则创建新订单。
- 用户点击“下单”时,调用
-
数据库持久化 & 唯一约束
- 在订单表中新增
idempotency_key列,并对其增加唯一索引; - 双重保障:前端重复发送同一 Key,也仅能插入一条记录,彻底避免重复下单。
- 在订单表中新增
总结:本质上还是通过数据库唯一索引以及分布式锁才能彻底避免重复下单。
RPC微服务调用
1.父Pom统一版本
<!-- 统一锁版本,避免不同模块写不同小版本 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-bom</artifactId>
<version>3.3.5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
2.pay-mall-infrustruct(Consumer)group-buying-sys-trigger (Provider)引入依赖
<dependencies>
<!-- Dubbo 核心 + Spring Boot 自动装配 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
</dependency>
<!-- Nacos 注册中心扩展 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-registry-nacos</artifactId>
</dependency>
</dependencies>
3.部署nacos(详见微服务笔记)
4.配置注册(消费者、生产者都要配)
dubbo:
application:
name: group-buy-market-service # 换成各自服务名
registry:
address: nacos://localhost:8848 # 远程环境写内网地址
# username/password 如果 Nacos 开了鉴权
protocol:
name: dubbo
port: 20880 # 生产者开放端口;消费者可不写
consumer:
timeout: 3000 # 毫秒
check: false # 忽略启动时服务是否可用
5.开启 Dubbo 注解扫描
在消费者、生产者的主启动类上加,设置正确的包名,让 @DubboService 和 @DubboReference 被 Spring+Dubbo 识别和处理
@SpringBootApplication
@EnableDubbo(scanBasePackages = "edu.whut")
public class Application { … }
6.在Dubbo RPC调用中,DTO对象需要在网络中进行传输,因此它们必须实现 java.io.Serializable 接口:
/**
* 用户信息请求对象
*/
@Data
public class UserRequestDTO implements Serializable { // 实现 Serializable
private static final long serialVersionUID = 1L; // 添加 serialVersionUID,用于版本控制
// 用户ID
private String userId;
// 用户名
private String userName;
// 邮箱
private String email;
}
7.定义服务接口:
服务接口定义了服务提供者能够提供的功能以及服务消费者能够调用的方法。这个接口必须是公共的,并且通常放置在一个独立的 api模块中。供服务提供者和消费者共同依赖。
/**
* 用户服务接口
*/
public interface IUserService {
/**
* 根据用户ID获取用户信息
* @param requestDTO 用户请求对象
* @return 用户响应对象
*/
UserResponseDTO getUserInfo(UserRequestDTO requestDTO);
/**
* 创建新用户
* @param requestDTO 用户请求对象
* @return 操作结果
*/
String createUser(UserRequestDTO requestDTO);
}
8.服务提供者 (Provider) 实现并暴露服务
在服务提供者应用中,实现上述定义的服务接口,并使用 @DubboService 注解将其暴露为Dubbo服务。可以放在trigger/rec包下。
/**
* 用户服务实现类
*/
@DubboService(version = "1.0.0", group = "user-service") // 关键注解:暴露Dubbo服务
@Service // 也可以同时是Spring的Service
public class UserServiceImpl implements IUserService {
@Override
public UserResponseDTO getUserInfo(UserRequestDTO requestDTO) {
System.out.println("收到获取用户信息的请求: " + requestDTO.getUserId());
// 模拟业务逻辑
UserResponseDTO response = new UserResponseDTO();
response.setUserId(requestDTO.getUserId());
response.setUserName("TestUser_" + requestDTO.getUserId());
response.setEmail("test_" + requestDTO.getUserId() + "@example.com");
return response;
}
@Override
public String createUser(UserRequestDTO requestDTO) {
System.out.println("收到创建用户的请求: " + requestDTO.getUserName());
// 模拟业务逻辑
return "User " + requestDTO.getUserName() + " created successfully.";
}
}
9.服务消费者 (Consumer) 引用远程服务
在服务消费者应用中,通过 @DubboReference 注解引用远程Dubbo服务。Dubbo 会自动通过注册中心查找并注入对应的服务代理。
/**
* 用户API控制器
*/
@RestController
public class UserController {
@DubboReference(version = "1.0.0", group = "user-service") // 关键注解:引用Dubbo服务
private IUserService userService;
@GetMapping("/user/info")
public UserResponseDTO getUserInfo(@RequestParam String userId) {
UserRequestDTO request = new UserRequestDTO();
request.setUserId(userId);
return userService.getUserInfo(request);
}
@GetMapping("/user/create")
public String createUser(@RequestParam String userName, @RequestParam String email) {
UserRequestDTO request = new UserRequestDTO();
request.setUserName(userName);
request.setEmail(email);
return userService.createUser(request);
}
}