62 KiB
Smile云图库
待完善功能
缓存相关
1. 手动刷新缓存
在某些情况下,数据更新较为频繁,但自动刷新缓存的机制可能存在延迟,这时可以通过手动刷新来解决。例如:
- 提供一个刷新缓存的接口,仅供管理员调用。
- 在管理后台提供入口,允许管理员手动刷新指定缓存。
2. 解决缓存常见问题
使用缓存时,一般需要注意以下几个典型问题:
- 缓存击穿
某些热点数据在缓存过期后,会导致大量请求直接打到数据库。
解决方案:
- 延长热点数据的过期时间;
- 使用互斥锁(如 Redisson)控制缓存刷新。
- 缓存穿透
用户频繁请求不存在的数据,导致请求直接落到数据库进行查询。
解决方案:
- 对无效查询结果也进行缓存(例如缓存空值);
- 使用布隆过滤器拦截无效请求。
- 缓存雪崩
大量缓存同时过期,导致瞬时请求集中打到数据库,造成系统压力骤增甚至崩溃。
解决方案:
- 给缓存的过期时间加上随机值,避免集中失效;
- 使用多级缓存,减少对数据库的依赖。
系统安全
限流、黑名单,降级返回逻辑都未完善,而系统中存在爬虫搜图、AI扩图功能,需要补充这块逻辑。
上传图片体验优化
目前仅有公共图库支持管理员批量搜图并上传,私人空间和团队空间都只能一张张上传,或许可以前端优化一下显示,支持批量上传,然后有一个类似扑克卡片那张叠加,每次顶上显示一个图片以及它的基本信息,确认无误点击确认可处理下一张。
目前只有管理员界面显示所有图片的管理;用户这边可以记录一个自己上传的图片列表,记录自己什么时候上传了什么图片,是否正在审核中...
图片展示优化
可以使用CDN内容分发网络、浏览器缓存提高图片的加载速度。
协同编辑
1、为防止消息丢失,可以使用 Redis 等高性能存储保存执行的操作记录。目前如果图片已经被编辑了,新用户加入编辑时没办法查看到已编
辑的状态,这一点也可以利用 Redis 保存操作记录来解决,新用户加入编辑时读取 Redis 的操作记录即可。
2、每种类型的消息处理可以封装为独立的 Handler 处理器类,也就是采用策略模式。
3、支持分布式 WebSocket。实现思路很简单,只需要保证要编辑同一图片的用户连接的是相同的服务器即可,和游戏分服务器大区、聊天
室分房间是类似的原理。
踩坑
精度损失和日期格式转换问题
前端 → 后端
日期
前端把日期格式化成后端期待的纯日期字符串,例如 "2025-08-14",后端 DTO 用 LocalDate 接收(配合 @JsonFormat(pattern="yyyy-MM-dd")),Jackson 反序列化成 LocalDate。
精度:
JavaScript 的 number 类型只能安全地表示到 2^53−1(约 9×10^15)的整数,超过这个范围就会丢失精度,用 number 传给后端时末尾只能补0;
解决办法:前端 ID 当做字符串传给后端。
Spring MVC 会自动调用 Long.parseLong("1951619197178556418") 并赋值给你方法签名里的 long id(即还是写作long来接收,不变)
后端 → 前端
日期:
后端用 LocalDate / LocalDateTime 之类的 Java 8 类型,经过 Jackson 序列化为指定格式的字符串(比如 "yyyy-MM-dd" / "yyyy-MM-dd HH:mm:ss")供前端消费,避免时间戳或默认格式的不一致。
精度:
Java 的 long 可能超过 JavaScript number 的安全范围(2^53−1),直接以数字输出会丢失精度。必须把 long/Long 序列化成字符串(例如 ID 输出为 "1951648800160399362"),前端拿到字符串再展示。
对 Jackson 用作 Spring 的 HTTP 消息转换器的 ObjectMapper 进行配置(日期格式、Java 8 时间支持、Long 转字符串等)示例代码:
@Configuration
public class JacksonConfig {
private static final String DATE_FORMAT = "yyyy-MM-dd";
private static final String DATETIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
private static final String TIME_FORMAT = "HH:mm:ss";
@Bean
public Jackson2ObjectMapperBuilderCustomizer jacksonCustomizer() {
return builder -> {
builder.featuresToDisable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
builder.simpleDateFormat(DATETIME_FORMAT);
builder.featuresToDisable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
JavaTimeModule javaTime = new JavaTimeModule();
javaTime.addSerializer(LocalDateTime.class,
new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT)));
javaTime.addSerializer(LocalDate.class,
new LocalDateSerializer(DateTimeFormatter.ofPattern(DATE_FORMAT)));
javaTime.addSerializer(LocalTime.class,
new LocalTimeSerializer(DateTimeFormatter.ofPattern(TIME_FORMAT)));
javaTime.addDeserializer(LocalDateTime.class,
new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DATETIME_FORMAT)));
javaTime.addDeserializer(LocalDate.class,
new LocalDateDeserializer(DateTimeFormatter.ofPattern(DATE_FORMAT)));
javaTime.addDeserializer(LocalTime.class,
new LocalTimeDeserializer(DateTimeFormatter.ofPattern(TIME_FORMAT)));
SimpleModule longToString = new SimpleModule();
longToString.addSerializer(Long.class, ToStringSerializer.instance);
longToString.addSerializer(Long.TYPE, ToStringSerializer.instance);
builder.modules(javaTime, longToString);
};
}
}
序列化操作是通过 Jackson 的 ObjectMapper 完成的,它并不依赖于 Serializable 接口。Serializable 接口更多的是用于对象的 Java 原生序列化,例如将对象写入文件或通过网络传输时的序列化,而 Jackson 处理的是 Java 对象和 JSON 之间的序列化与反序列化。
数据库密码加密
加密存储确保即使数据库泄露,攻击者也不能轻易获取用户原始密码。
spring security中提供了一个加密类BCryptPasswordEncoder。
它采用哈希算法 SHA-256 +随机盐+密钥对密码进行加密。加密算法是一种可逆的算法,而哈希算法是一种不可逆的算法。
因为有随机盐的存在,所以相同的明文密码经过加密后的密码是不一样的,盐在加密的密码中是有记录的,所以需要对比的时候,springSecurity是可以从中获取到盐的
验证密码 matches
// 使用 matches 方法来对比明文密码和存储的哈希密码
boolean judge= passwordEncoder.matches(rawPassword, user.getPassword());
注意,matches的第一个参数必须 是 “原始明文”,第二个参数 必须 是 “已经加密过的密文”!!!顺序不能反!!!
Websocket连接问题
前端请求地址:
const protocol = location.protocol === 'https:' ? 'wss' : 'ws'
// 线上地址
const host = location.host;
const url = `${protocol}://${host}/api/ws/picture/edit?pictureId=${this.pictureId}`
this.socket = new WebSocket(url)
nginx配置:
# ---------- WebSocket 代理 ----------
location /api/ws/ {
proxy_pass http://picture_backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_buffering off;
proxy_read_timeout 86400s;
}
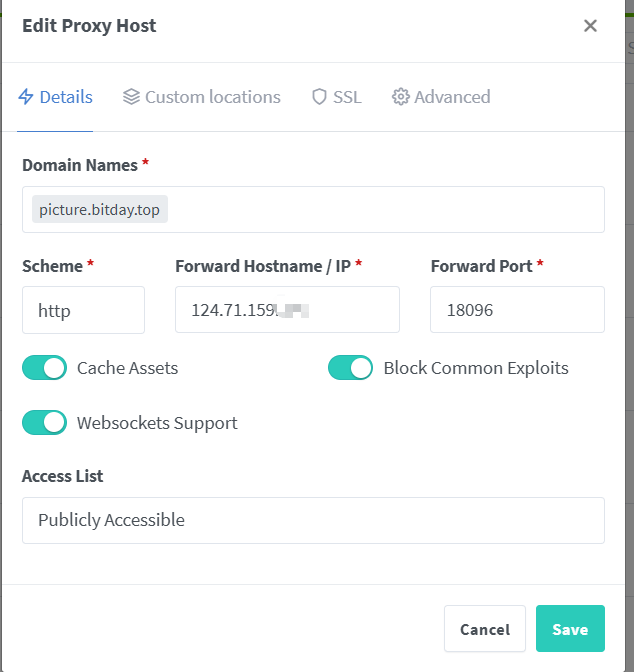
坑点在这:由于本项目采用NPM做域名管理,124.71.159.xxx:18096 ->https://picture.bitday.top/
要把这里的Websockets Supports勾上,不然无法建立连接!排查了很久!
循环依赖问题
PictureController
↓ 注入 PictureServiceImpl
PictureServiceImpl
↓ 注入 SpaceServiceImpl
SpaceServiceImpl
↓ 注入 SpaceUserServiceImpl
SpaceUserServiceImpl
↓ 注入 SpaceServiceImpl ←—— 又回到 SpaceServiceImpl
解决办法:将一方改成 setter 注入并加上 @Lazy注解
如在SpaceUserServiceImpl中
@Resource
@Lazy // 必须使用 Spring 的 @Lazy,而非 Groovy 的!
private SpaceService spaceService;
@Lazy为懒加载,直到真正第一次使用它时才去创建或注入。且这里不能用构造器注入的方式!!!
❌ 构造器注入会立即触发依赖加载,无法解决循环依赖
收获
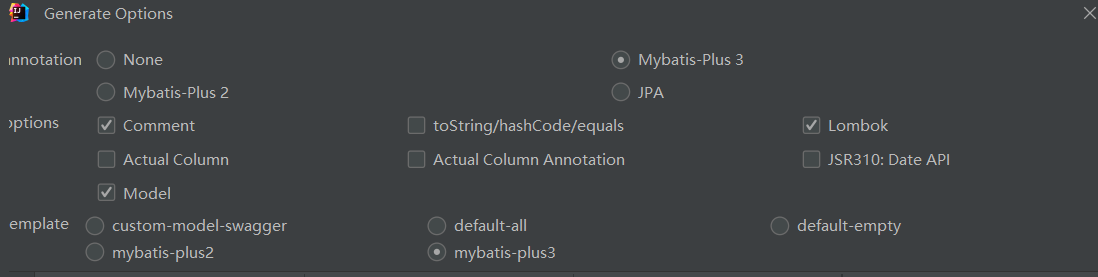
MybatisX插件简化开发
下载MybatisX插件,可以从数据表直接生成Bean、Mapper、Service,选项设置如下:
注意,勾选 Actual Column 生成的Bean和表中字段一模一样,取消勾选会进行驼峰转换,即
user_name—>userName

下载GenerateSerailVersionUID插件,可以右键->generate->生成序列ID:
private static final long serialVersionUID = -1321880859645675653L;
胡图工具类hutool
引入依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.26</version>
</dependency>
ObjUtil.isNotNull(Object obj),仅判断对象是否 不为 null,不关心对象内容是否为空,比如空字符串 ""、空集合 []、数字 0 等都算是“非 null”。
ObjUtil.isNotEmpty(Object obj) 判断对象是否 不为 null 且非“空”
- 对不同类型的对象判断逻辑不同:
CharSequence(String):长度大于 0Collection:size > 0Map:非空Array:长度 > 0- 其它对象:只判断是否为 null(默认不认为“空”)
StrUtil.isNotEmpty(String str) 只要不是 null 且长度大于 0 就算“非空”。
StrUtil.isNotBlank(String str) 不仅要非 null,还要不能只包含空格、换行、Tab 等空白字符
StrUtil.hasBlank(CharSequence... strs)只要 **至少一个字符串是 blank(空或纯空格)**就返回 true,底层其实就是对每个参数调用 StrUtil.isBlank(...)
CollUtil.isNotEmpty(Collection<?> coll)用于判断 集合(Collection)是否非空,功能类似于 ObjUtil.isNotEmpty(...)
BeanUtil.toBean :用来把一个 Map、JSONObject 或者另一个对象快速转换成你的目标 JavaBean
public class BeanUtilExample {
public static class User {
private String name;
private Integer age;
// 省略 getter/setter
}
public static void main(String[] args) {
// 1. 从 Map 转 Bean
Map<String, Object> data = new HashMap<>();
data.put("name", "Alice");
data.put("age", 30);
User user1 = BeanUtil.toBean(data, User.class);
System.out.println(user1.getName()); // Alice
// 2. 从另一个对象转 Bean
class Temp { public String name = "Bob"; public int age = 25; }
Temp temp = new Temp();
User user2 = BeanUtil.toBean(temp, User.class);
System.out.println(user2.getAge()); // 25
}
}
创建图片的业务流程
方式 1:先上传文件,再提交表单数据
流程:
- 用户先把图片上传到云存储,系统生成一个
url。 - 系统不急着写数据库,只是记住这个
url。 - 用户继续在前端填写图片的标题、描述、标签等信息。
- 用户点击“提交”后,才把 url + 其它信息 一起存进数据库,生成一条完整记录。
优点:
- 数据库里不会出现“用户传了文件,但没填写信息”的垃圾数据。
缺点:
- 如果用户传了文件但中途关掉页面,文件虽然已经占了存储空间,但数据库里没有记录,这个文件可能变成“孤儿文件”,需要后台定期清理。
方式 2:上传文件时就立即建数据库记录
流程:
- 用户一旦上传成功,后端立即在数据库里生成完整的图片记录(包含能直接解析出来的元信息,如宽高、大小、格式、URL、上传者等)。
- 后续用户只是在编辑已有的图片记录(补充标题、描述、标签等),而不是新建。
优点:
- 数据库里能实时反映出当前所有文件的存在状态,方便管理。
- 即使用户中途不编辑,也能有一条图片记录存在。
缺点:
- 可能会有很多“不完整”的记录(缺少标题等),需要做清理或状态标记。
- 可能侵害用户隐私
**针对方式1,**可能存在孤儿文件的问题,解决办法:
上传阶段(放临时区)
- 用户选图 → 前端调用后端接口拿一个临时上传地址(key 类似
/temp/{userId}/{uuid}.png)。 - 前端直接把文件上传到 COS 的 temp 文件夹。
- 这时只是文件存在 COS,数据库里还没有正式的图片记录。
提交阶段(转正)
- 用户在网页里填写标题、描述等信息后点击提交。
- 后端接收到提交请求后:
- 在数据库里创建图片记录(生成 pictureId 等信息)
- 把 COS 中的文件从
/temp/...复制(Copy)到正式目录/prod/{spaceId}/{pictureId}.png - 删除
/temp/...的原文件(节省空间) - 把正式文件 URL 保存到数据库中
针对方式2:
-
新上传的图片记录默认设置为
status = DRAFT,表示草稿状态,仅对上传者可见。 -
当用户确认并提交(实际是编辑补充信息后)时,将该记录的状态更新为
PUBLISHED,即正式发布。 -
如果用户在上传后未点击提交而是选择取消,则应立即删除该记录,并同时从 COS 中移除对应的文件。
-
另外,后端应配置定时任务,定期清理超过 N 小时/天仍处于
DRAFT状态的记录,并同步删除 COS 上的文件,以避免无效数据和存储浪费。
本项目采取的是方式2!!!
登录校验
Session登录校验
1.基本原理
服务端:存储会话数据(内存、Redis 等)。
客户端:仅保存会话 ID(如 JSESSIONID),通常通过 Cookie 传递。
2.数据结构
服务端会话存储(Map 或 Redis)
{ "abc123" -> HttpSession 实例 }
HttpSession 结构:
HttpSession
├─ id = "abc123"
├─ creationTime = ...
├─ lastAccessedTime = ...
└─ attributes
└─ "USER_LOGIN_STATE" -> user 实体对象
3.请求流程
首次请求
- 浏览器没有
JSESSIONID,服务端调用createSession()创建一个新会话(ID 通常是 UUID)。 - 服务端返回响应头
Set-Cookie: JSESSIONID=<新ID>; Max-Age=2592000(30 天有效期)。 - 浏览器将
JSESSIONID写入本地 Cookie(持久化保存)。
后续请求
- 浏览器自动在请求头中附带
Cookie: JSESSIONID=<ID>。 - 服务端用该 ID 在会话存储中查找对应的
HttpSession实例,恢复用户状态。
┌───────────────┐ (带 Cookie JSESSIONID=abc123)
│ Browser │ ───────►│ Tomcat │
└───────────────┘ └──────────┘
│
│ 用 abc123 做 key
▼
{abc123 → HttpSession} ← 找到
│
▼
取 attributes["USER_LOGIN_STATE"] → 得到
userrequest.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
4.后端使用示例
保存登录状态:
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
request.getSession() 会自动获取当前请求关联的 HttpSession 实例。
获取登录状态:
User user = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE);
退出登录:
request.getSession().removeAttribute(UserConstant.USER_LOGIN_STATE);
相当于清空当前会话中的用户信息。浏览器本地的 JSESSIONID 依然存在,只不过后端啥也没了。
优点
- 会话数据保存在服务端,相比直接将数据存储在客户端更安全(防篡改)。
缺点
-
分布式集群下 Session 无法自动共享(需借助 Redis 等集中存储)。
-
客户端禁用 Cookie 时,Session 会失效。
-
服务端需要维护会话数据,高并发环境下可能带来内存或性能压力。
Redis+Session
前面每次重启服务器都要重新登陆,既然已经整合了 Redis,不妨使用 Redis 管理 Session,更好地维护登录态,且能多实例(集群)共享。
1)先在 Maven 中引入 spring-session-data-redis 库:
<!-- Spring Session + Redis -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
2)修改 application.yml 配置文件,更改Session的存储方式和过期时间:
既要设置redis能存30天,发给前端的cookie也要30天有效期。
spring:
session:
store-type: redis
timeout: 30d # 会话不活动超时(maxInactiveInterval)
redis:
host: 127.0.0.1
port: 6379
server:
servlet:
session:
cookie:
max-age: 30d # 发给前端 Cookie 的保存时长
# name: JSESSIONID # 如想保持原名,见下文“Cookie 名称”
存储结构展示:
普通用户与管理员权限控制
使用AOP切面!
1)定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AuthCheck {
/**
* 必须具有某个角色
**/
String mustRole() default "";
}
2)写切片类
@Aspect
@Component
@RequiredArgsConstructor
public class AuthInterceptor {
private final UserService userService;
/**
* 执行拦截
*
* @param joinPoint 切入点
* @param authCheck 权限校验注解
*/
@Around("@annotation(authCheck)")
public Object doInterceptor(ProceedingJoinPoint joinPoint, AuthCheck authCheck) throws Throwable {
String mustRole = authCheck.mustRole();
RequestAttributes requestAttributes = RequestContextHolder.currentRequestAttributes();
HttpServletRequest request = ((ServletRequestAttributes) requestAttributes).getRequest();
// 获取当前登录用户
User loginUser = userService.getLoginUser(request);
UserRoleEnum mustRoleEnum = UserRoleEnum.getEnumByValue(mustRole);
// 如果不需要权限,放行
if (mustRoleEnum == null) {
return joinPoint.proceed();
}
// 以下的代码:必须有权限,才会通过
UserRoleEnum userRoleEnum = UserRoleEnum.getEnumByValue(loginUser.getUserRole());
if (userRoleEnum == null) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR);
}
// 要求必须有管理员权限,但用户没有管理员权限,拒绝
if (UserRoleEnum.ADMIN.equals(mustRoleEnum) && !UserRoleEnum.ADMIN.equals(userRoleEnum)) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR);
}
// 通过权限校验,放行
return joinPoint.proceed();
}
}
3)使用
/**
* 分页获取图片列表(仅管理员可用)
*/
@PostMapping("/list/page")
@AuthCheck(mustRole = UserConstant.ADMIN_ROLE)
public BaseResponse<Page<Picture>> listPictureByPage(@RequestBody PictureQueryRequest pictureQueryRequest) {
long current = pictureQueryRequest.getCurrent();
long size = pictureQueryRequest.getPageSize();
// 查询数据库
Page<Picture> picturePage = pictureService.page(new Page<>(current, size),
pictureService.getQueryWrapper(pictureQueryRequest));
return ResultUtils.success(picturePage);
}
上传图片
使用模板方法的设计模式,在抽象类中定义一个算法骨架(固定流程),并将某些步骤延迟到子类中实现。
有两种上传方式:
1.网络URL上传
2.文件上传
抽象类:PictureUploadTemplate
模板方法uploadPicture()
固定了上传图片的整体流程:
- 校验图片 →
validPicture() - 生成上传路径 →
getOriginFilename() - 创建临时文件 →
processFile() - 上传到对象存储
- 封装返回结果
- 删除临时文件
多级缓存
多级缓存是指结合本地缓存和分布式缓存的优点,在同一业务场景下构建两级缓存系统,这样可以兼顾本地缓存的高性能、以及分布式缓存的数据一致性和可靠性。
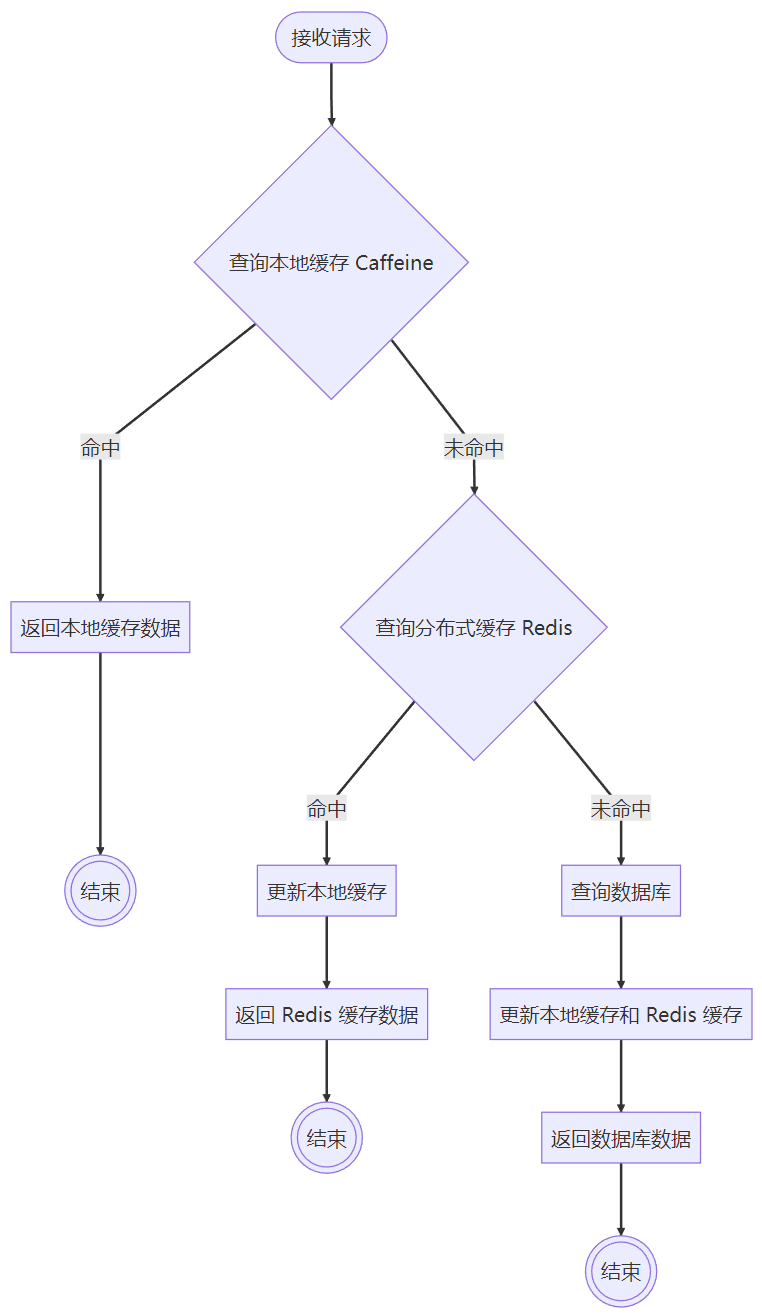
目前,对图片列表的查询进行了缓存处理,包括公共图库(public)以及私有和团队空间。缓存的 key 由 空间 ID(spaceId)+ 当前页码(current)+ 每页显示数量(size)组成。具体生成方式如下:
String cacheKey = "smilepicture:listPictureVOByPage:spaceId:" +
(spaceId == null ? "public" : spaceId) +
":current:" + current +
":size:" + size;
构建缓存代码:
空值防缓存穿透:如果查询结果为空(例如查询到的数据集为空),我们会缓存一个空的 JSON({}),防止频繁的空查询穿透到数据库。
随机过期时间:为了防止缓存雪崩,我们设置了缓存的过期时间为 300-600 秒之间的随机时间。这样可以确保缓存的失效时间不会同时过期,提升缓存的稳定性。
public <T> T getFromCacheOrDatabase(
String cacheKey,
TypeReference<T> typeRef,
Supplier<T> dbSupplier,
int redisExpireSeconds) {
// 1) 本地缓存
String cachedValue = localCache.getIfPresent(cacheKey);
if (cachedValue != null) {
try {
return mapper.readValue(cachedValue, typeRef);
} catch (Exception ignore) {}
}
// 2) Redis 缓存
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
cachedValue = ops.get(cacheKey);
if (cachedValue != null) {
localCache.put(cacheKey, cachedValue);
try {
return mapper.readValue(cachedValue, typeRef);
} catch (Exception ignore) {}
}
// 3) 从数据库获取数据
T dbValue = dbSupplier.get();
// ===== 空值防穿透 =====
if (isEmptyValue(dbValue)) {
String emptyJson = "{}";
ops.set(cacheKey, emptyJson, 60, TimeUnit.SECONDS); // 缓存60秒
localCache.put(cacheKey, emptyJson);
return dbValue;
}
try {
String json = mapper.writeValueAsString(dbValue);
ops.set(cacheKey, json, redisExpireSeconds, TimeUnit.SECONDS);
localCache.put(cacheKey, json);
} catch (Exception ignore) {}
return dbValue;
}
删除逻辑:
目前,缓存的删除是基于 spaceId 来进行的。具体逻辑是,当某个图片发生变化时,删除与该空间相关的所有缓存。但是,目前的删除逻辑比较粗糙,直接清空了所有该空间下的缓存,而没有进一步细分到具体的分页。
public void clearCacheBySpaceId(Long spaceId) {
// 构造命名空间,公共图库使用 "public",其他空间使用 spaceId
String namespace = (spaceId == null) ? "public" : String.valueOf(spaceId);
// Redis SCAN 模式匹配的前缀
String pattern = "smilepicture:listPictureVOByPage:spaceId:" + namespace + ":*";
// 使用 SCAN 命令进行遍历,查找所有相关的缓存 key
ScanOptions options = ScanOptions.scanOptions().match(pattern).count(100).build();
Cursor<byte[]> cursor = stringRedisTemplate.execute(
(redisConnection) -> redisConnection.scan(options),
true
);
// 删除匹配的缓存
while (cursor.hasNext()) {
byte[] rawKey = cursor.next();
String cacheKey = new String(rawKey, StandardCharsets.UTF_8); // 转换 byte[] 为 String
stringRedisTemplate.delete(cacheKey); // 删除 Redis 缓存
}
// 删除本地缓存 Caffeine
for (int current = 1; current <= 100; current++) { // 假设最多查询100页
for (int size = 10; size <= 100; size += 10) {
String cacheKey = "smilepicture:listPictureVOByPage:spaceId:" + namespace + ":current:" + current + ":size:" + size;
localCache.invalidate(cacheKey); // 清除本地缓存
}
}
}
图片压缩优化
项目中存储了三种图片url:
1.原图,仅供下载的时候提供
2.使用腾讯云的数据万象将原图转为Webp格式,作为一般的网页内图片的展示图
3.使用腾讯云的数据万象将原图转为缩略图格式,作为网页中小图的展示(点开图片前)
以图搜图
法一:使用百度 AI 提供的图片搜索 API 或者 Bing以图搜图API
法二:爬虫
以百度搜图网站为例,先体验一遍流程,并且对接口进行分析:
1)进到百度图片搜索百度识图搜索结果,通过 url 上传图片,发现接口:https://graph.baidu.com/upload?uptime= ,该接口的返回值为 “以图搜图的页面地址”
2)访问上一步得到的页面地址,可以在返回值中找到 firstUrl:
3)访问 firstUrl,就能得到 JSON 格式的相似图片列表,里面包含了图片的缩略图和原图地址:
本项目采用法二。
外观模式
目的:简化系统的复杂性,提供一个统一的接口,隐藏系统内部的细节。
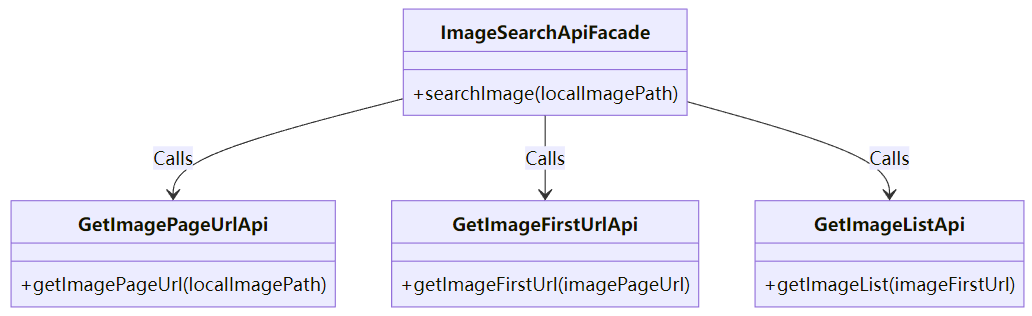
实现方式:创建了一个 ImageSearchApiFacade 类,它对外提供了 searchImage 方法,通过这个方法,外部调用者不需要关心图片搜索的具体步骤(如获取页面 URL、获取图片列表等),只需要调用这个简洁的接口即可。
searchImage(String localImagePath):外部调用者通过该方法传入图片路径,ImageSearchApiFacade 会依次调用子系统中的方法获取图片列表,并返回结果。
子系统:GetImagePageUrlApi、GetImageFirstUrlApi、GetImageListApi 等是实现细节,分别负责不同的任务:
getImagePageUrl(String localImagePath):该方法向百度的「以图搜图」API 发起上传请求,并获取返回的结果页面 URL。
getImageFirstUrl(String imagePageUrl):根据传入的页面 URL,该方法会请求页面并解析其 HTML 内容,从中找到 firstUrl,即第一张图片的 URL。
getImageList(String imageFirstUrl):该方法使用传入的第一张图片 URL,发起请求到获取图片列表的 API,处理返回的 JSON 数据,提取出图片列表,并将其转换为 ImageSearchResult 对象。
@Slf4j
public class ImageSearchApiFacade {
/**
* 搜索图片
*/
public static List<ImageSearchResult> searchImage(String localImagePath) {
String imagePageUrl = GetImagePageUrlApi.getImagePageUrl(localImagePath);
String imageFirstUrl = GetImageFirstUrlApi.getImageFirstUrl(imagePageUrl);
List<ImageSearchResult> imageList = GetImageListApi.getImageList(imageFirstUrl);
return imageList;
}
}
图片功能扩展
按颜色搜图
为了提高性能并避免每次搜索时都进行实时计算,我们建议在图片上传成功后,立即提取图片的主色调并将其存储在数据库中的独立字段中。
完整流程如下:
- 提取图片颜色: 通过图像处理技术(如云服务 API 或 OpenCV 图像处理库),我们可以提取图片的颜色特征。我们采用主色调作为图片颜色的代表,简单明了,便于后续处理。此处,使用腾讯云提供的 数据万象接口 来获取每张图片的主色调:数据万象 获取图片主色调_腾讯云。
- 存储颜色特征: 提取到的颜色特征会被存储在数据库中,以便后续快速检索。通过这种方式,我们可以避免每次查询时重新计算图片的颜色特征,提高系统的响应速度。
- 用户查询输入: 用户可以通过不同的方式来指定颜色查询条件:
- 颜色选择器:用户可以通过直观的界面选择颜色。
- RGB 值输入:用户可以直接输入颜色的 RGB 值。
- 预定义颜色名称:用户也可以选择常见的颜色名称(如红色、蓝色等)。
- 计算相似度: 在收到用户的查询条件后,系统会根据用户指定的颜色与数据库中存储的颜色特征进行相似度计算。常用的相似度计算方法包括 欧氏距离、余弦相似度 等,目的是找出与用户要求颜色最接近的图片。
- 返回结果: 由于每个空间内的图片数量相对较少,我们可以通过计算图片与目标颜色的相似度,对图片进行排序,优先返回最符合用户要求的图片。这种方法不仅提高了用户的搜索体验,也避免了仅返回完全符合指定色调的图片,拓宽了搜索结果的范围。
AI扩图
使用大模型服务平台百炼控制台提供的扩图功能。
异步任务 + 轮询查询模式
当调用的接口处理逻辑较为耗时(如 AI 图像生成、文档转换等),服务端通常不会立即返回最终结果。
为了避免 HTTP 请求长时间占用连接,接口会设计成先提交任务,再异步获取结果。
思想流程
发起任务
- 调用
create类型接口,传入任务参数。 - 返回
taskId(任务唯一标识)以及任务的初始状态(如pending、processing)。
延迟查询
- 等待一段时间(几秒或按服务端建议的间隔)。
- 使用
taskId调用get类型接口查询状态。
轮询直到完成
- 如果状态为
processing或pending,继续间隔查询。 - 如果状态为
success或failed,结束轮询并处理结果。
轮询一般会在前端(或调用方)用定时器来触发,如每隔X秒查一次。
私有空间创建
在业务中,每个用户只能创建一个私人空间,但还允许创建团队空间,所以不能直接在 space 表的 userId 上加唯一索引来限制。需要加锁确保在并发情况下同一用户的创建操作安全且互不干扰。
为什么用 ConcurrentHashMap<Long,Object> 管理锁更优?
1. 避免污染常量池
- 如果用
String.intern()作为锁对象,会将不同的userId字符串放入 JVM 字符串常量池。 - 随着用户量增长,常量池(位于元空间/永久代)会不断膨胀,带来 内存压力 和 垃圾回收开销。
ConcurrentHashMap存储的锁对象是普通堆对象,可控且可回收,不会污染常量池。
2. 锁生命周期可控
- ConcurrentHashMap可以显式增删:
computeIfAbsent:仅当不存在锁对象时才创建。remove(userId, lock):业务完成后立即移除,防止内存占用过大。
- 而
intern()生成的字符串常驻常量池,生命周期由 JVM 管理,无法手动清理,存在内存泄漏风险。
3.支持高并发下的高性能
ConcurrentHashMap 在 JDK8 及以上采用CAS + 分段锁(或节点锁,多线程 computeIfAbsent 性能优于 HashMap + 全局 synchronized。
为什么这里用编程式事务而不是 @Transactional
问题背景
- 声明式事务(
@Transactional)是由 Spring AOP 代理在方法进入前就开启事务,在方法返回后才提交。 - 如果锁(
synchronized)在方法内部,事务会比锁早开启、晚提交。
并发风险
- 线程 A
- 进入方法 → 事务已开启
- 进入
synchronized,执行exists → save,退出锁 - 事务还没提交(提交在方法返回时)
- 线程 B
- 等 A 释放锁后进入 → 此时 A 的事务未提交
- B 查询
exists看不到 A 的未提交数据(READ_COMMITTED 下) - 误以为不存在 → 也执行
save - 最终可能产生重复记录或唯一索引冲突。
编程式事务的好处
- 事务开启和提交的时机完全可控,可以放在
synchronized内部。 - 保证加锁期间事务已提交或回滚,避免并发读取“看不到未提交数据”的问题。
private static final ConcurrentHashMap<Long, Object> USER_LOCKS = new ConcurrentHashMap<>();
Object lock = USER_LOCKS.computeIfAbsent(userId, id -> new Object());
synchronized (lock) {
try {
// 2. 在事务内检查并创建空间
Long newSpaceId = transactionTemplate.execute(status -> {
boolean exists = this.lambdaQuery()
.eq(Space::getUserId, userId)
.eq(Space::getSpaceType, space.getSpaceType())
.exists();
ThrowUtils.throwIf(exists, ErrorCode.OPERATION_ERROR, "每个用户每类空间只能创建一个");
boolean result = this.save(space);
ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "保存空间到数据库失败");
// 创建成功后,如果是团队空间,默认将创建人加入团队且视为管理员
if (SpaceTypeEnum.TEAM.getValue() == space.getSpaceType()) {
SpaceUser spaceUser = new SpaceUser();
spaceUser.setSpaceId(space.getId());
spaceUser.setUserId(userId);
spaceUser.setSpaceRole(SpaceRoleEnum.ADMIN.getValue());
result = spaceUserService.save(spaceUser);
ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "创建团队成员记录失败");
}
//创建分表(仅对团队空间生效)为方便部署,暂时不使用
// dynamicShardingManager.createSpacePictureTable(space);
return space.getId();
});
return Optional.ofNullable(newSpaceId).orElse(-1L);
} finally {
// 3. 可选:移除锁对象,防止 Map 膨胀(仅当你确定没有并发需求时才移除)
USER_LOCKS.remove(userId, lock);
}
}
空间成员权限控制
空间和用户是多对多的关系,还要同时记录用户在某空间的角色,所以需要新建关联表 空间成员表
| 字段名 | 类型 | 默认值 | 允许为空 | 注释 |
|---|---|---|---|---|
| id | bigint | auto_increment | 否 | id |
| spaceId | bigint | — | 否 | 空间 id |
| userId | bigint | — | 否 | 用户 id |
| spaceRole | varchar(128) | 'viewer' | 是 | 空间角色:viewer / editor / admin |
| createTime | datetime | CURRENT_TIMESTAMP | 否 | 创建时间 |
| updateTime | datetime | CURRENT_TIMESTAMP | 否 | 更新时间 |
RBAC模型
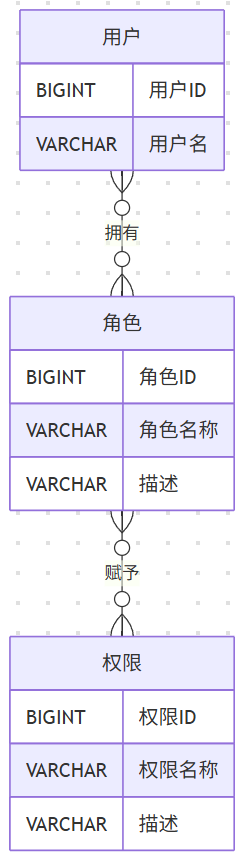
一般来说,标准的 RBAC 实现需要 5 张表:用户表、角色表、权限表、用户角色关联表、角色权限关联表,还是有一定开发成本的。由于我们的项目中,团队空间不需要那么多角色,可以简化RBAC 的实现方式,比如将 角色 和 权限 直接定义到配置文件中。
本项目角色:
| 角色 | 描述 |
|---|---|
| 浏览者 | 仅可查看空间中的图片内容 |
| 编辑者 | 可查看、上传和编辑图片内容 |
| 管理员 | 拥有管理空间和成员的所有权限 |
本项目权限:
| 权限键 | 功能名称 | 描述 |
|---|---|---|
| spaceUser:manage | 成员管理 | 管理空间成员,添加或移除成员 |
| picture:view | 查看图片 | 查看空间中的图片内容 |
| picture:upload | 上传图片 | 上传图片到空间中 |
| picture:edit | 修改图片 | 编辑已上传的图片信息 |
| picture:delete | 删除图片 | 删除空间中的图片 |
角色权限映射:
| 角色 | 对应权限键 | 可执行功能 |
|---|---|---|
| 浏览者 | picture:view | 查看图片 |
| 编辑者 | picture:view, picture:upload, picture:edit, picture:delete | 查看图片、上传图片、修改图片、删除图片 |
| 管理员 | spaceUser:manage, picture:view, picture:upload, picture:edit, picture:delete | 成员管理、查看图片、上传图片、修改图片、删除图片 |
RBAC 只是一种权限设计模型,我们在 Java 代码中如何实现权限校验呢?
1)最直接的方案是像之前校验私有空间权限一样,封装个团队空间的权限校验方法;或者类似用户权限校验一样,写个注解 + AOP 切面。
2)对于复杂的角色和权限管理,可以选用现成的第三方权限校验框架来实现,编写一套权限校验规则代码后,就能整体管理系统的权限校验逻辑了。( Sa-Token)
Sa-Token
快速入门
1)引入:
<!-- Sa-Token 权限认证 -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-spring-boot-starter</artifactId>
<version>1.39.0</version>
</dependency>
2)让 Sa-Token 整合 Redis,将用户的登录态等内容保存在 Redis 中。
<!-- Sa-Token 整合 Redis (使用 jackson 序列化方式) -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-redis-jackson</artifactId>
<version>1.39.0</version>
</dependency>
<!-- 提供Redis连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
3)基本用法
StpUtil 是 Sa-Token 提供的全局静态工具。
用户登录时调用 login 方法,产生一个新的会话:
StpUtil.login(10001);
还可以给会话保存一些信息,比如登录用户的信息:
StpUtil.getSession().set("user", user)
接下来就可以判断用户是否登录、获取用户信息了,可以通过代码进行判断:
// 检验当前会话是否已经登录, 如果未登录,则抛出异常:`NotLoginException`
StpUtil.checkLogin();
// 获取用户信息
StpUtil.getSession().get("user");
也可以参考 官方文档,使用注解进行鉴权:
// 登录校验:只有登录之后才能进入该方法
@SaCheckLogin
@RequestMapping("info")
public String info() {
return "查询用户信息";
}
passwordEncoder多账号体系
本项目中存在两套权限校验体系。一套是 user 表的,分为普通用户和管理员;另一套是对团队空间的权限进行校
验。
为了更轻松地扩展项目,减少对原有代码的改动,我们原有的 user 表权限校验依然使用自定义注解 + AOP 的方式实
现。而团队空间权限校验,采用 Sa-Token 来管理。
这种同一项目有多账号体系的情况下,不建议使用 Sa-Token 默认的账号体系,而是使用 Sa-Token 提供的多账号认
证特性,可以将多套账号的授权给区分开,让它们互不干扰。
使用 Kit 模式 实现多账号认证
/**
* StpLogic 门面类,管理项目中所有的 StpLogic 账号体系
* 添加 @Component 注解的目的是确保静态属性 DEFAULT 和 SPACE 被初始化
*/
@Component
public class StpKit {
public static final String SPACE_TYPE = "space";
/**
* 默认原生会话对象,项目中目前没使用到
*/
public static final StpLogic DEFAULT = StpUtil.stpLogic;
/**
* Space 会话对象,管理 Space 表所有账号的登录、权限认证
*/
public static final StpLogic SPACE = new StpLogic(SPACE_TYPE);
}
修改用户服务的 userLogin 方法,用户登录成功后,保存登录态到 Sa-Token 的空间账号体系中:
//记录用户的登录态
request.getSession().setAttribute(USER_LOGIN_STATE, user);
//记录用户登录态到 Sa-token,便于空间鉴权时使用,注意保证该用户信息与 SpringSession 中的信息过期时间一致
StpKit.SPACE.login(user.getId());
StpKit.SPACE.getSession().set(USER_LOGIN_STATE, user);
return this.getLoginUserVO(user);
之后就可以在代码中使用账号体系
// 检测当前会话是否以 Space 账号登录,并具有 picture:edit 权限
StpKit.SPACE.checkPermission("picture:edit");
// 获取当前 Space 会话的 Session 对象,并进行写值操作
StpKit.SPACE.getSession().set("user", "zy123");
Sa-Token 权限认证
1.核心:实现 StpInterface
Sa-Token 需要知道某个用户 ID 拥有哪些角色和权限,这就要在项目中实现 StpInterface:
参考 官方文档,示例权限认证类如下:
@Component
public class StpInterfaceImpl implements StpInterface {
// 根据用户 ID 查询权限列表
@Override
public List<String> getPermissionList(Object loginId, String loginType) {
// 实际项目里这里需要查数据库或缓存
return List.of("user.add", "user.update", "art.*");
}
// 根据用户 ID 查询角色列表
@Override
public List<String> getRoleList(Object loginId, String loginType) {
return List.of("admin", "super-admin");
}
}
项目权限较少时,可以只做角色校验;权限较多时,建议权限校验;二选一,不建议混用。
本项目 基于权限校验。
2.两种使用方式
方式一:注解式
使用 注解合并 简化代码。
@SaCheckPermission("picture.upload")
public void uploadPicture() { ... }
调用接口时,Sa-Token 会在进入方法前自动校验权限(调用你实现的 StpInterface),并强制要求用户已登录。
特点:
- 优点:写法简洁,声明式安全。
- 缺点:参数必须通过
HttpServletRequest获取;无法在方法内部灵活决定是否鉴权。
方式二:编程式
-
在方法内部的任意位置手动调用权限校验:
if (!StpUtil.hasPermission("picture.view")) { throw new BusinessException(ErrorCode.NO_AUTH_ERROR); } -
可以先做一些逻辑判断,再决定是否需要权限校验(更灵活)。
-
适合场景:接口对未登录用户也开放,比如查看公共图片:
用编程式可以先判断是否需要鉴权,比如:
-
如果资源是公开的 → 不检查权限,直接返回。
-
如果资源属于某个空间 → 再做
hasPermission校验。
-
@GetMapping("/doc/{id}")
public BaseResponse<DocumentVO> getDoc(@PathVariable Long id) {
// 查询文档
Document doc = docService.getById(id);
ThrowUtils.throwIf(doc == null, ErrorCode.NOT_FOUND_ERROR);
// 编程式鉴权逻辑
if (doc.isPrivate()) {
// 先判断是否已登录
if (!StpUtil.isLogin()) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "请先登录");
}
// 再判断是否有查看权限
if (!StpUtil.hasPermission("doc.view")) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "没有查看权限");
}
}
// 返回数据
return ResultUtils.success(docService.toVO(doc));
}
3. 注解式的登录强制性
注意:只要加了
Sa-Token的权限/角色注解(例如@SaCheckPermission),框架就会先检查用户是否已登录。 如果用户未登录,会直接抛异常(比如NotLoginException),请求不会进入你的方法体。
原因:
- Sa-Token 的权限注解是在 进入方法前 执行的 AOP 切面逻辑。
- 在执行权限比对前,它必须知道“当前用户是谁”,所以会强制做登录状态校验。
如果你用的是 @SaSpaceCheckPermission(...),Sa-Token 就会走你 StpInterface#getPermissionList() 的实
现,然后去匹配注解里写的权限码。
如果你改成基于角色的鉴权(比如 @SaCheckRole("admin")),那 Sa-Token 就会调用
StpInterface#getRoleList(),再用角色去匹配注解里的值。
鉴权背后流程
- 拦截请求 → 注解触发 Sa-Token 的 AOP 切面。
- 获取 Token → 从 Cookie/Header/Param 读取,查 Redis 找到 loginId。
- 登录校验 → 未登录直接抛异常。
- 数据加载 → 调用你实现的
getPermissionList()或getRoleList()。 - 匹配比对 → 注解要求的权限/角色 vs 你返回的列表。
- 放行或拒绝 → 匹配成功执行方法,否则抛鉴权异常。
分库分表
如果某团队空间的图片数量比较多,可以对其数据进行单独的管理。
1、图片信息数据 可以给每个团队空间单独创建一张图片表 picture_{spaceId},也就是分库分表中的分表,而不是和公共图库、私有空间的图片混在一起。这样不仅查询空间内的图片效率更高,还便于整体管理和清理空间。但是要注意,仅对旗舰版空间生效,否则分表的数量会特别多,反而可能影响性能。
要实现的是会随着新增空间不断增加分表数量的动态分表,使用分库分表框架 Apache ShardingSphere 。
2、图片文件数据
已经实现隔离,存到COS上的不同桶内。
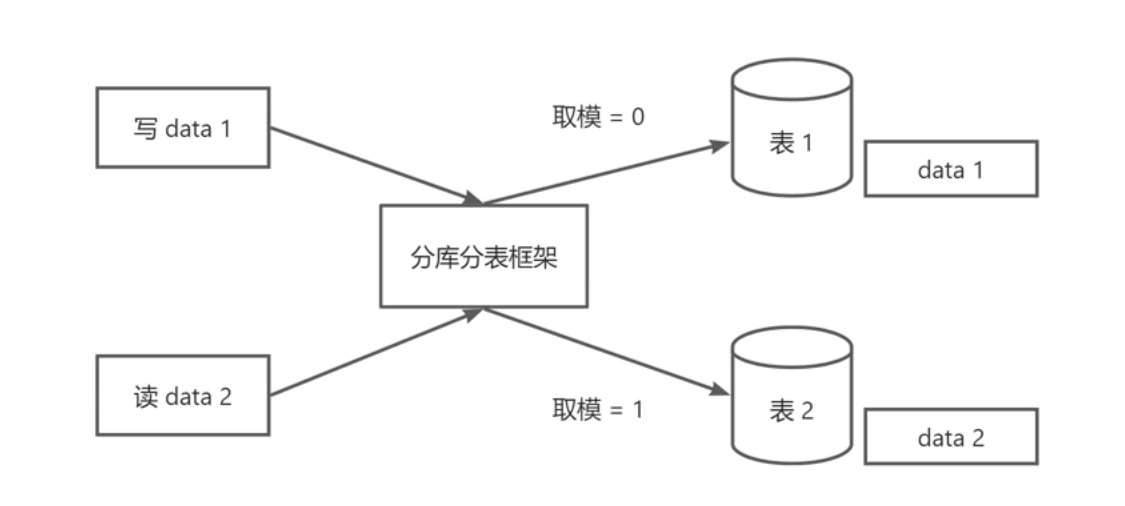
思路主要是基于业务需求设计数据分片规则,将数据按一定策略(如取模、哈希、范围或时间)分散存储到多个库或表中,同时开发路由逻辑来决定查询或写入操作的目标库表。
ShardingSphere 分库分表
<!-- 分库分表 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
分库分表的策略总体分为 2 类:静态分表和动态分表
分库分表策略 - 静态分表
静态分表:在设计阶段,分表的数量和规则就是固定的,不会根据业务增长动态调整,比如 picture_0、picture_1。
分片规则通常基于某一字段(如图片 id)通过简单规则(如取模、范围)来决定数据存储在哪个表或库中。
这种方式的优点是简单、好理解;缺点是不利于扩展,随着数据量增长,可能需要手动调整分表数量并迁移数据。
举个例子,图片表按图片 id 对 3 取模拆分:
String tableName = "picture_" + (picture_id % 3) // picture_0 ~ picture_2
静态分表的实现很简单,直接在 application.yml 中编写 ShardingSphere 的配置就能完成分库分表,比如:
rules:
sharding:
tables:
picture: # 逻辑表名
actualDataNodes: ds0.picture_${0..2} # 3张物理表:picture_0, picture_1, picture_2
tableStrategy:
standard:
shardingColumn: picture_id # 按 pictureId 分片
shardingAlgorithmName: pictureIdMod
shardingAlgorithms:
pictureIdMod:
type: INLINE #内置实现,直接在配置类中写规则,即下面的algorithm-expression
props:
algorithm-expression: picture_${pictureId % 3} # 分片表达式
查询逻辑表 picture 时,ShardingSphere 会根据分片规则自动路由到 picture_0 ~ picture_2。
分库分表策略 - 动态分表
动态分表是指分表的数量可以根据业务需求或数据量动态增加,表的结构和规则是运行时动态生成的。举个例子,根
据时间动态创建 picture_2025_03、picture_2025_04。
String tableName = "picture_" + LocalDate.now().format(
DateTimeFormatter.ofPattern("yyyy_MM")
);
spring:
shardingsphere:
datasource:
names: smile-picture
smile-picture:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/smile-picture
username: root
password: 123456
rules:
sharding:
tables:
picture: #逻辑表名(业务层永远只写 picture)
actual-data-nodes: smile-picture.picture # 逻辑表对应的真实节点
table-strategy:
standard:
sharding-column: space_id #分片列(字段)
sharding-algorithm-name: picture_sharding_algorithm # 使用自定义分片算法
sharding-algorithms:
picture_sharding_algorithm:
type: CLASS_BASED
props:
strategy: standard
algorithmClassName: edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm
props:
sql-show: true
需要实现自定义算法类:
edu.whut.smilepicturebackend.manager.sharding.PictureShardingAlgorithm 全类名。
public class PictureShardingAlgorithm implements StandardShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> preciseShardingValue) {
// 编写分表逻辑,返回实际要查询的表名
// picture_0 物理表,picture 逻辑表
}
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return new ArrayList<>();
}
@Override public Properties getProps() { return null; }
@Override public void init(Properties properties) { }
}
本项目分表总体思路:
对 picture 进行分表
一张 逻辑表 picture
- 业务代码永远只写
picture,不用关心落到哪张真实表。
两类真实表
| 类型 | 存谁的数据 | 例子 |
|---|---|---|
| 公共表 | 普通 / 进阶 / 专业版 空间 | picture |
| 分片表 | 旗舰版 空间(每个空间一张) | picture_<spaceId>,如 picture_30001 |
什么是分片键
table-strategy:
standard:
sharding-column: space_id #分片键
自定义分片算法:
-
传入 space_id 时
- 如果是旗舰,会自动路由到
picture_<spaceId>;否则回落到公共表picture。
- 如果是旗舰,会自动路由到
-
没有 space_id 时
(例如后台批量报表):
- 广播到 所有
picture_<spaceId>+picture并做汇聚。
- 广播到 所有
因此,项目中的业务代码中,对Picture表进行增删查改时,必须确保space_id非空。
协同编辑
事件驱动模型的优势
与生产者直接调用消费者不同,事件驱动模型的核心优势在于 解耦 和 异步性:
- 解耦:生产者与消费者之间不需要直接依赖彼此的实现。生产者只需触发事件并交由事件分发器处理,消费者则根据事件类型执行相应逻辑。
- 异步性:通过引入事件分发器这一“中介”,系统可以实现异步消息传递,减少阻塞与等待,提高并发处理能力。
- 高并发与实时性:事件驱动可以在同一时间处理多个并发任务,更高效地响应实时请求。
如何解决协同冲突?
方案一:单用户编辑锁定:
业务上约定 同一时刻仅允许一位用户进入编辑状态。
其他用户在此期间只能实时查看修改效果,不能直接编辑。当该用户退出编辑后,其他用户才可进入编辑状态。
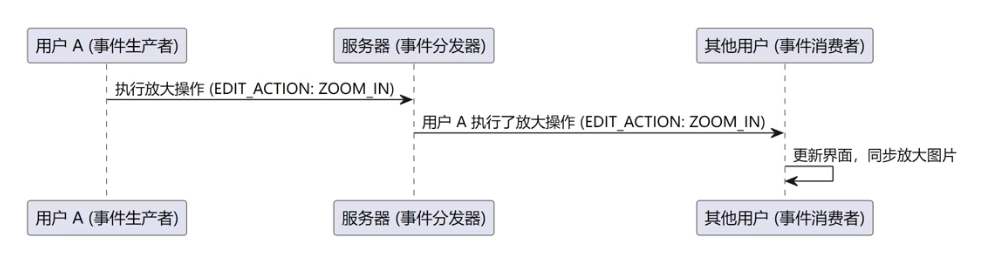
| 事件触发者(用户 A 的动作) | 事件类型(发送消息) | 事件消费者(其他用户的处理) |
|---|---|---|
| 用户 A 建立连接,加入编辑 | INFO | 显示"用户 A 加入编辑"的通知 |
| 用户 A 进入编辑状态 | ENTER_EDIT | 其他用户界面显示"用户 A 开始编辑图片",锁定编辑状态 |
| 用户 A 执行编辑操作 | EDIT_ACTION | 放大/缩小/左旋/右旋当前图片 |
| 用户 A 退出编辑状态 | EXIT_EDIT | 解锁编辑状态,提示其他用户可以进入编辑状态 |
| 用户 A 断开连接,离开编辑 | INFO | 显示"用户 A 离开编辑"的通知,并释放编辑状态 |
| 用户 A 发送了错误的消息 | ERROR | 显示错误消息的通知 |
方案二:实时协同编辑(OT 算法)
OT(Operational Transformation)是在线协作中常用的一种算法(例如 Google Docs、石墨文档)。
-
操作 (Operation):用户对协作内容的修改,例如插入字符、删除字符等。
-
转化 (Transformation):当多个用户同时修改时,OT 会根据上下文调整操作位置或内容,保证不同顺序执行的结果一致。
-
因果一致性:保证每个用户的操作都基于他们所看到的最新状态。
举一个简单的例子,假设初始内容是 "abc",用户 A 和 B 同时进行编辑:
- 用户 A 在位置 1 插入
"x" - 用户 B 在位置 2 删除
"b"
如果不使用 OT:
- A 执行后 →
"axbc" - B 执行后 →
"ac"(直接应用会导致 A 的结果被覆盖)
使用 OT:
- A 执行后 →
"axbc" - B 的删除操作经过转化 → 删除
"b"在"axbc"中的新位置 - 最终结果 →
"axc",A 和 B 看到的内容保持一致
OT 的关键难点在于设计合适的操作转化规则,以确保在不同编辑顺序下,最终结果仍然一致。本项目采取方案一!!!
WebSocket
业务流程图

引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
WebSocket 配置类
@Configuration
@EnableWebSocket
@RequiredArgsConstructor
public class WebSocketConfig implements WebSocketConfigurer {
private final PictureEditHandler pictureEditHandler;
private final WsHandshakeInterceptor wsHandshakeInterceptor;
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
////当客户端在浏览器中执行new WebSocket("ws://<你的域名或 IP>:<端口>/ws/picture/edit?pictureId=123");就会由 Spring 把这个请求路由到你的 PictureEditHandler 实例。
registry.addHandler(pictureEditHandler, "/ws/picture/edit")
.addInterceptors(wsHandshakeInterceptor)
.setAllowedOrigins("*");
}
}
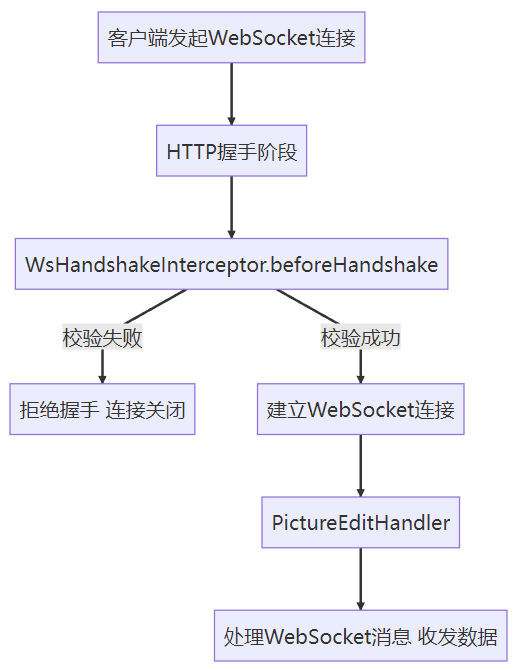
任何客户端连接 ws://<host>:<port>/ws/picture/edit 都会交给 pictureEditHandler 处理(PictureEditHandler 负责收发消息)
在连接建立前,会先走 WsHandshakeInterceptor 做验证(请求参数是否缺失、用户是否登录、用户是否有编辑权
限、图片是否存在、图片所在空间是否存在)
验证通过后,将 当前请求信息 user pictureId 存到 Sesssion中:
attributes.put("user", loginUser);
后续取数据:
User user = (User) session.getAttributes().get("user");
协同编辑原理
在协同编辑场景中,我们使用 WebSocket 实现实时通讯。每个图片编辑操作由用户发起,WebSocket 会话(WebSocketSession)则承载每个用户的连接。下面是实现原理:
// key: pictureId,value: 这张图下所有活跃的 Session(即各个用户的连接)
Map<Long, Set<WebSocketSession>> pictureSessions;
WebSocketSession 与用户
- 当用户 A 在浏览器中打开
pictureId=123的编辑页面时,会产生一个 WebSocketSession(不同于HttpSession)。 - 如果用户 A 在同一浏览器打开了新的标签页,或者在不同的浏览器/设备上再次打开编辑页面,那么每个新的连接都会产生一个 新的 WebSocketSession。
假设系统中有两张图片,pictureId 分别为 123 和 200,当前活跃的 WebSocket 会话(连接)如下:
| pictureId | pictureSessions.get(pictureId) |
|---|---|
| 123 | { sessionA, sessionB } (用户 A、B 的连接) |
| 200 | { sessionC } (只有用户 C 的连接) |
当 某个 WebSocketSession 发消息时,所有与该图片相关的 WebSocketSession(即同一 pictureId 下的所有连接)都会收到这条消息。
Disruptor 优化
在 Spring MVC / WebSocket 场景里,如果接口(或消息处理)内部存在耗时操作,请求线程会被长时间占用,最终可能把 Tomcat 的请求
线程/连接池耗尽(默认 200)。
实践中,绝大多数请求是“快请求”(毫秒级),可在请求线程内直接完成;少量“慢请求”(秒级)应当切到异步线程执行,做到**快速返回 + **
后台处理。
Disruptor 是一套高性能并发框架,核心是无锁(或低锁)的环形队列 RingBuffer,为高吞吐/低延迟场景而生。相较常规队列,Disruptor
通过序号(sequence)、缓存命中和内存屏障等机制,实现了极低延迟与有序消费。
工作流程(直观理解):
1)环形队列初始化:创建固定大小的 RingBuffer(如 8),底层是可复用的事件对象数组,全局使用递增的序号标记事件顺序。
2)生产者写入数据:申请一个可写序号 → 将数据写入事件对象 → 发布(publish)成功后,序号递增。
3)消费者读取数据:按序检查可读序号 → 取出对应事件 → 处理 → 提交后继续下一个序号。
4)环形队列循环使用:写到末尾回到起点(环形),但序号持续递增保证先后顺序。
5)防止数据覆盖:若生产速度追上了消费速度,生产者会等待,确保未处理的数据不会被覆盖。
6)解耦与异步:WebSocket 收到消息后直接投递到 RingBuffer,由 Disruptor 的消费者按序处理,实现快速入队 + 后台串行/并行消费。
引入 Disruptor 的主要作用:
1.就是把耗时的业务处理从 WebSocket / Tomcat 请求线程中解耦出来,交给一个高性能的异步消息通道去处理,从而让前端请求能尽快返
回,不会因为几个慢操作就把服务器的请求线程全堵死。
2.同一条事件流在 RingBuffer 中按序号消费,避免多线程乱序导致的业务问题(比如图片编辑步骤错乱)。
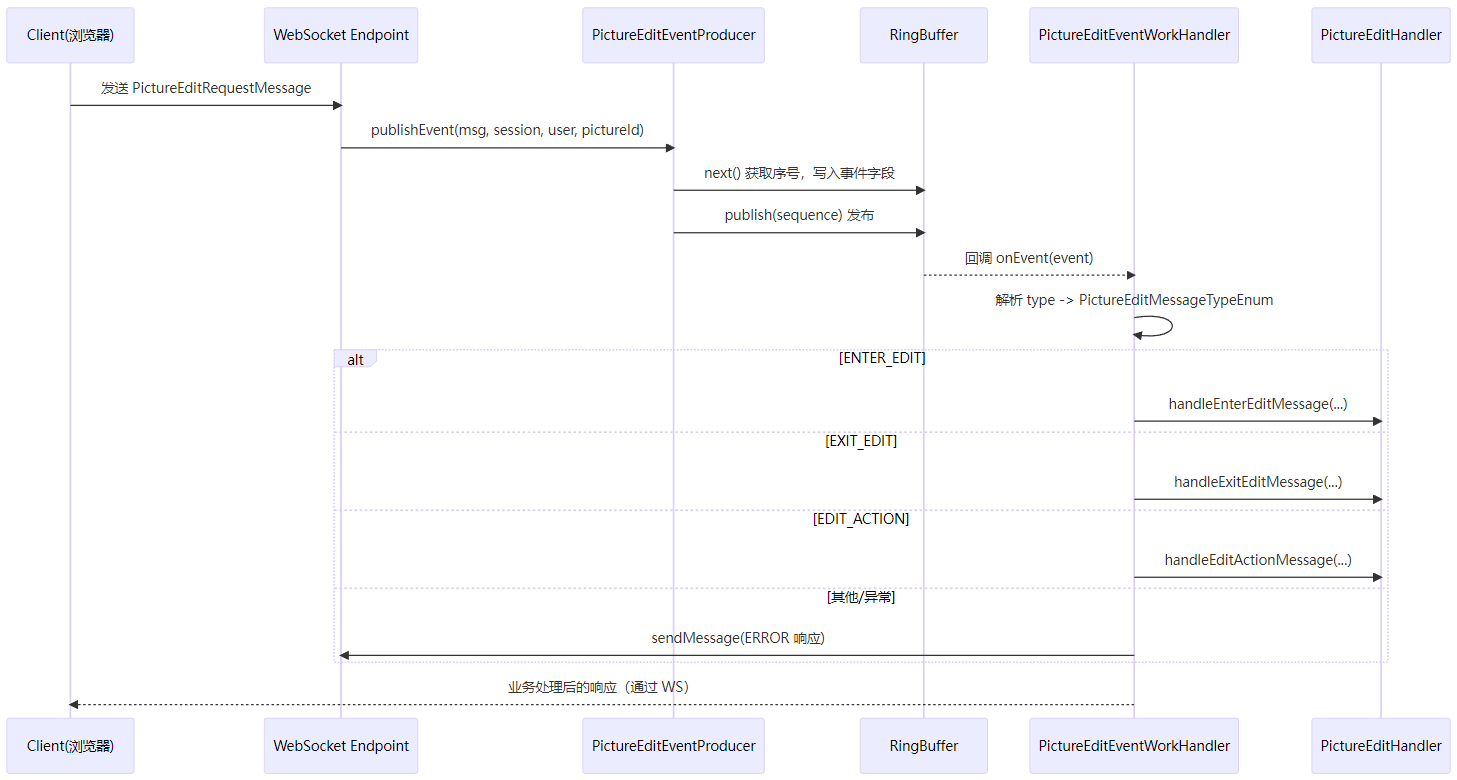
WebSocket+Disruptor完整流程
用户 A 通过 WebSocket 发送编辑消息(如旋转图片)。
后端:接收消息、解析并将消息投递到 Disruptor。
Disruptor 消费者:消费事件并调用相应处理逻辑(如执行编辑操作)。
后端广播:向所有正在编辑该图片的 WebSocket 会话广播消息。
{
"type": "EDIT_ACTION",
"message": "用户 A 执行了编辑操作: rotate",
"user": { "userName": "A" },
"editAction": "rotate"
}
前端接收并更新 UI:所有用户(如用户 B)接收到编辑操作的通知,并在界面上实时更新编辑状态。
广播消息 是由 服务器端 通过 WebSocket 发送的,确保所有参与编辑的用户(前端)都能收到最新的编辑状态。