项目地址:zy123/zbparse - zbparse - 智标领航代码仓库
git clone地址:http://47.98.59.178:3000/zy123/zbparse.git
选择develop分支,develop-xx 后面的xx越近越新。
正式环境:121.41.119.164:5000
测试环境:47.98.58.178:5000
大解析:指从招标文件解析入口进去,upload.py
小解析:从投标文件生成入口进去,little_zbparse 和get_deviation,两个接口后端一起调
项目结构:
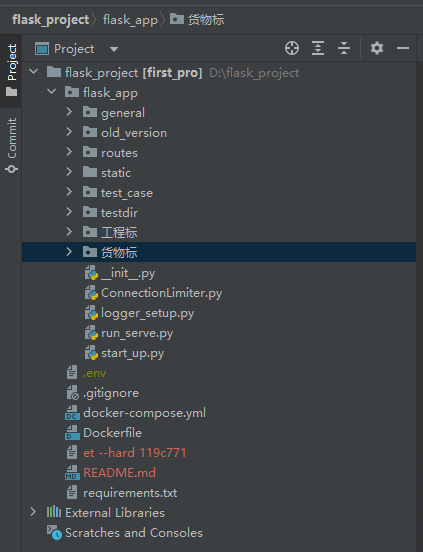
.env存放一些密钥(大模型、textin等),它是gitignore忽略了,因此在服务器上git pull项目的时候,这个文件不会更新(因为密钥比较重要),需要手动维护服务器相应位置的.env。
如何更新服务器上的版本:
- 进入项目文件夹

**注意:**需要确认.env是否存在在服务器,默认是隐藏的 输入cat .env 如果不存在,在项目文件夹下sudo vim .env
将密钥粘贴进去!!!
-
git pull
-
sudo docker-compose up --build -d 更新并重启
或者 sudo docker-compose build 先构建镜像
sudo docker-compose up -d 等空间时再重启
- sudo docker-compose logs flask_app --since 1h 查看最近1h的日志(如果重启后报错也能查看,推荐重启后都运行一下这个)
requirements.txt一般无需变动,除非代码中使用了新的库,也要手动在该文件中添加包名及对应的版本
如何本地启动本项目:
- requirements.txt里的环境要配好 conda create -n zbparse python=3.8 conda activate zbparse pip install -r requirements.txt
- .env环境配好 (一般不需要在电脑环境变量中额外配置了,但是要在Pycharm中安装插件,使得项目能将env中的环境变量配置到系统环境变量中!!!)
- 点击下拉框,Edit configurations

设置run_serve.py为启动脚本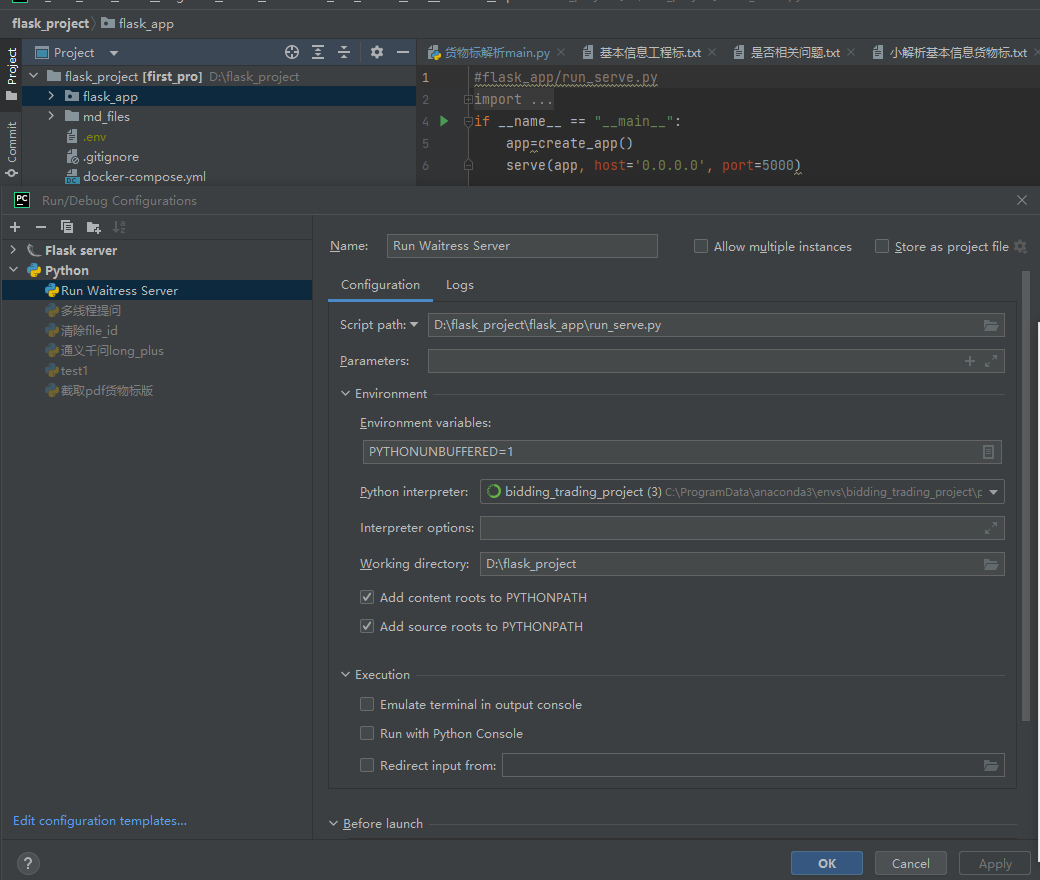 注意这里的working directory要设置到最外层文件夹,而不是flask_app!!!
注意这里的working directory要设置到最外层文件夹,而不是flask_app!!!
- postman打post请求测试:
body:
{
"file_url":"xxxx",
"zb_type":2
} file_url如何获取:OSS管理控制台
bid-assistance/test 里面找个文件的url,推荐'094定稿-湖北工业大学xxx' 注意这里的url地址有时效性,要经常重新获取新的url
flask_app结构介绍
项目中做限制的地方
账号、服务器分流
服务器分流:目前linux服务器和windows服务器主要是硬件上的分流(文件切分需要消耗CPU资源),大模型基底还是调用阿里,共用的tpm qpm。
账号分流:qianwen_plus下的
api_keys = cycle([
os.getenv("DASHSCOPE_API_KEY"),
# os.getenv("DASHSCOPE_API_KEY_BACKUP1"),
# os.getenv("DASHSCOPE_API_KEY_BACKUP2")
])
api_keys_lock = threading.Lock()
def get_next_api_key():
with api_keys_lock:
return next(api_keys)
api_key = get_next_api_key()
只需轮流使用不同的api_key即可。目前没有启用。
大模型的限制
general/llm下的doubao.py 和通义千问long_plus.py 目前是linux和windows各部署一套,因此项目中的qps是对半的,即calls=?
- 这是qianwen-long的限制(针对阿里qpm为1200,每秒就是20,又linux和windows服务器对半,就是10;TPM无上限)
@sleep_and_retry
@limits(calls=10, period=1) # 每秒最多调用10次
def rate_limiter():
pass # 这个函数本身不执行任何操作,只用于限流
-
这是qianwen-plus的限制(针对tpm为1000万,每个请求2万tokens,那么linux和windows总的qps为8时,8x60x2=960<1000。单个为4) 经过2.11号测试,calls=4时最高TPM为800,因此把目前稳定版把calls设为5
2.12,用turbo作为超限后的承载,目前把calls设为7
@sleep_and_retry
@limits(calls=7, period=1) # 每秒最多调用7次
def qianwen_plus(user_query, need_extra=False):
logger = logging.getLogger('model_log') # 通过日志名字获取记录器
- qianwen_turbo的限制(TPM为500万,由于它是plus后的手段,稳妥一点,qps设为6,两个服务器分流即calls=3)
@sleep_and_retry
@limits(calls=3, period=1) # 500万tpm,每秒最多调用6次,两个服务器分流就是3次 (plus超限后的保底手段,稳妥一点)
重点!!后续阿里扩容之后成倍修改这块calls=?
如果不用linux和windows负载均衡,这里的calls也要乘2!!
接口的限制
- start_up.py的def create_app()函数,限制了对每个接口同时100次请求。这里事实上不再限制了(因为100已经足够大了),默认限制做到大模型限制这块。
app.connection_limiters['upload'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['get_deviation'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['default'] = ConnectionLimiter(max_connections=100)
app.connection_limiters['judge_zbfile'] = ConnectionLimiter(max_connections=100)
-
ConnectionLimiter.py以及每个接口上的装饰器,如
@require_connection_limit(timeout=1800) def zbparse():这里限制了每个接口内部执行的时间,暂时设置到了30分钟!(不包括排队时间)超时就是解析失败
后端的限制:
目前后端发起招标请求,如果发送超过100(max_connections=100)个请求,我这边会排队后面的请求,这时后端的计时器会将这些请求也视作正在解析中,事实上它们还在排队等待中,这样会导致在极端情况下,新进的解析文件速度大于解析的速度,排队越来越长,后面的文件会因为等待时间过长而直接失败,而不是'解析失败'。
general
是公共函数存放的文件夹,llm下是各类大模型,读取文件下是docx pdf文件的读取以及文档清理clean_pdf,去页眉页脚页码

general下的llm下的清除file_id.py 需要每周运行至少一次,防止file_id数量超出(我这边对每次请求结束都有file_id记录并清理,向应该还没加)
llm下的model_continue_query是'模型继续回答'脚本,应对超长文本模型一次无法输出完的情况,继续提问,拼接成完整的内容。
general下的file2markdown是textin 文件--》markdown
general下的format_change是pdf-》docx 或doc/docx->pdf
general下的merge_pdfs.py是拼接文件的:1.拼接招标公告+投标人须知 2.拼接评标细则章节+资格审查章节
general中比较重要的!!!
后处理:
general下的post_processing,解析后的后处理部分,包括extract_info、 资格审查、技术偏离 商务偏离 所需提交的证明材料,都在这块生成。
post_processing中的inner_post_processing专门提取extracted_info
post_processing中的process_functions_in_parallel提取
资格审查、技术偏离、 商务偏离、 所需提交的证明材料
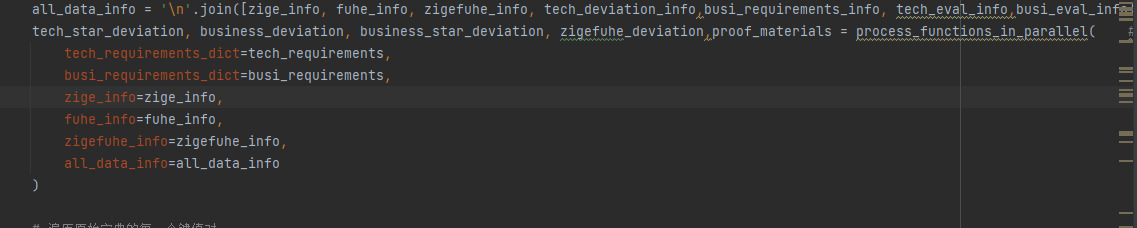
大解析upload用了post_processing完整版,
little_zbparse.py、小解析main.py用了inner_post_processing
get_deviation.py、偏离表数据解析main.py用了process_functions_in_parallel
截取pdf:
截取pdf_main.py是顶级函数,
二级是截取pdf货物标版.py和截取pdf工程标版.py (非general下)
三级是截取pdf通用函数.py
如何判断截取位置是否正确?根据output文件夹中的切分情况(打开各个文件查看是否切分准确,目前的逻辑主要是按大章切分,即'招标公告'章节)
如果切分不准确,如何定位正则表达式?
首先判断当前是工程标解析还是货物标解析,即zb_type=1还是2
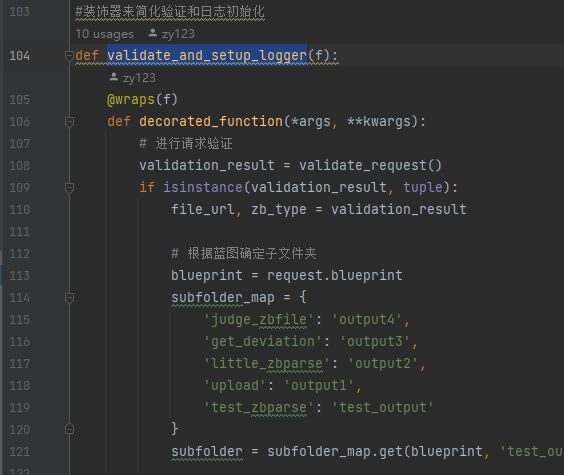
如果是2,那么是货物标解析,那么就是截取pdf_main.py调用截取pdf货物标版.py,如下图,selection=1代表截取'招标公告',那么如果招标公告没有切准,就在这块修改。这里可以发现get_notice是通用函数,即截取pdf通用函数.py中的get_notice函数,那么继续往内部跳转。
若开头没截准,就改begin_pattern,末尾没截准,就改end_pattern
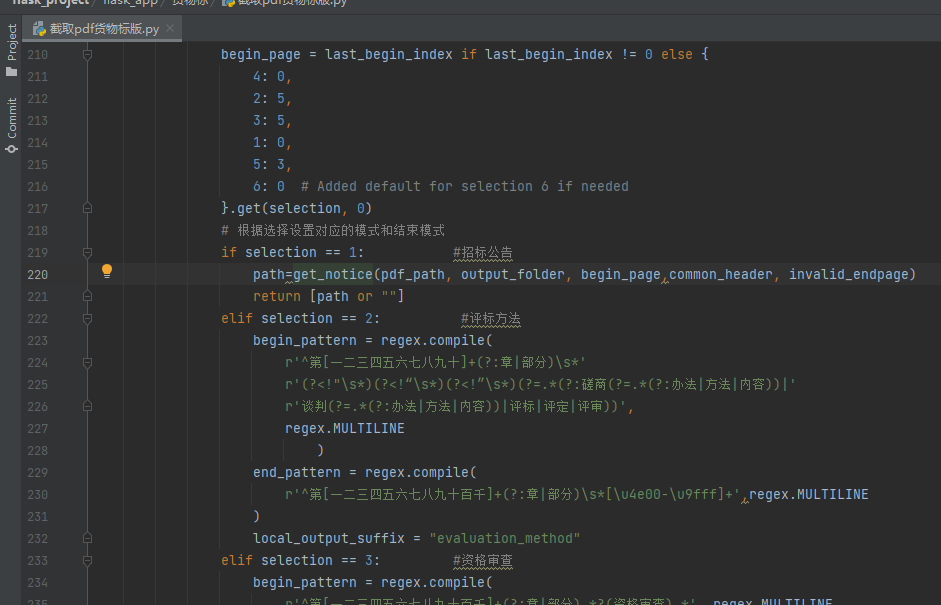
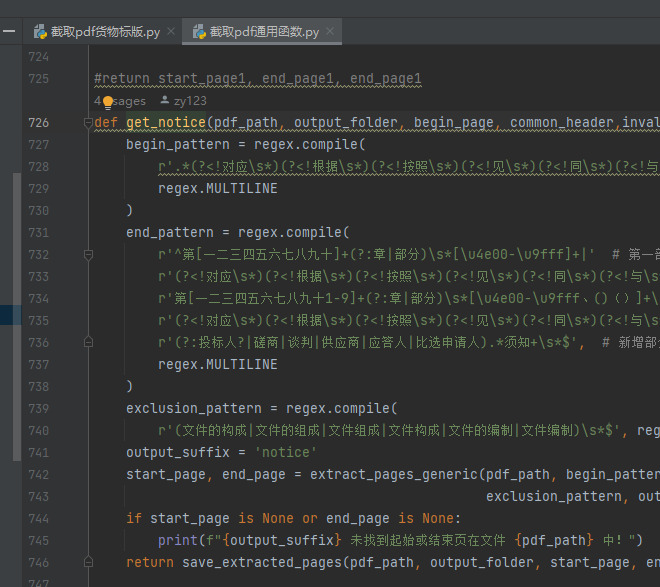
另外:在截取pdf货物标版.py中,还有extract_pages_twice函数,即第一次没有切分到之后,会运行该函数,这边又有一套begin_pattern和end_pattern,即二次提取
如何测试?

输入pdf_path,和你要切分的序号,selection=1代表切公告,依次类推,可以看切出来的效果如何。
无效标和废标公共代码
获取无效标与废标项的主要执行代码。对docx文件进行预处理=》正则=》temp.txt=》大模型筛选 如果提的不全,可能是正则没涵盖到位,也可能是大模型提示词漏选了。
这里:如果段落中既被正则匹配,又被follow_up_keywords中的任意一个匹配,那么不会添加到temp中(即不会被大模型筛选),它会直接添加到最后的返回中!
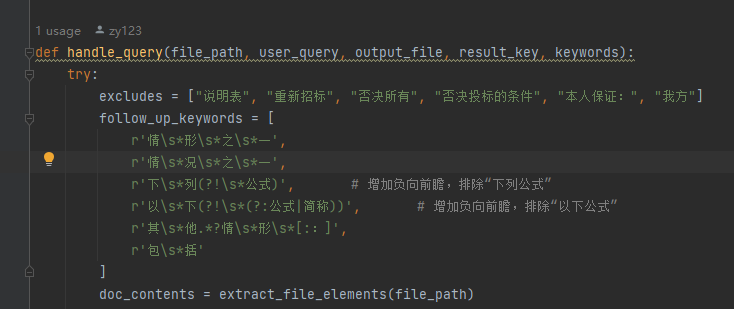
投标人须知正文条款提取成json文件
将截取到的ztbfile_tobidders_notice_part2.pdf ,即须知正文,转为clause1.json 文件,便于后续提取开评定标流程、投标文件要求、重新招标、不再招标和终止招标
这块的主要逻辑就是匹配形如'一、总则'这样的大章节
然后匹配形如'1.1' '1.1.1'这样的序号,由于是按行读取pdf,一个序号后面的内容可能有好几行,因此遇到下一个序号(如'2.1')开头,之前的内容都视为上一个序号的。
old_version
都是废弃文件代码,未在正式、测试环境中使用的,不用管
routes
是接口以及主要实现部分,一一对应
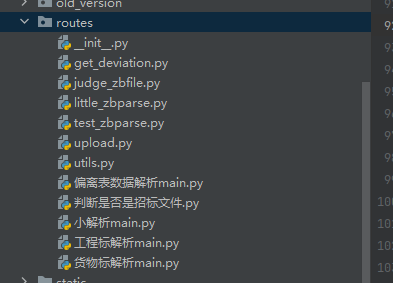
get_deviation对应偏离表数据解析main,获得偏离表数据
judge_zbfile对应判断是否是招标文件
little_zbparse对应小解析main,负责解析extract_info
test_zbparse是测试接口,无对应
upload对应工程标解析和货物标解析,即大解析
混淆澄清:小解析可以指代一个过程,即从'投标文件生成'这个入口进去的解析,后端会同时调用little_zbparse和get_deviation。这个过程称为'小解析'。
但是little_zbparse也叫小解析,命名如此因为最初只需返回这些数据(extract_info),后续才陆续返回商务、技术偏离...
utils是接口这块的公共功能函数。其中validate_and_setup_logger函数对不同的接口请求对应到不同的output文件夹,如upload->output1。后续增加接口也可直接在这里写映射关系。
重点关注大解析:upload.py和货物标解析main.py
static
存放解析的输出和提示词
其中output用gitignore了,git push不会推送这块内容。
各个文件夹(output1 output2..)对应不同的接口请求
test_case&testdir
test_case是测试用例,是对一些函数的测试。好久没更新了
testdir是平时写代码的测试的地方
它们都不影响正式和测试环境的解析
工程标&货物标
是两个解析流程中不一样的地方(一样的都写在general中了)
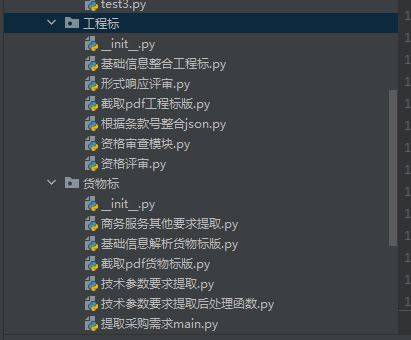
主要是货物标额外解析了采购要求(提取采购需求main+技术参数要求提取+商务服务其他要求提取)
最后:
ConnectionLimiter.py定义了接口超时时间->超时后断开与后端的连接
logger_setup.py 为每个请求创建单独的log,每个log对应一个log.txt
start_up.py是启动脚本,run_serve也是启动脚本,是对start_up.py的简单封装,目前dockerfile定义的直接使用run_serve启动
持续关注
yield sse_format(tech_deviation_response)
yield sse_format(tech_deviation_star_response)
yield sse_format(zigefuhe_deviation_response)
yield sse_format(shangwu_deviation_response)
yield sse_format(shangwu_star_deviation_response)
yield sse_format(proof_materials_response)
- 工程标解析目前仍没有解析采购要求这一块,因此后处理返回的只有'资格审查'和''证明材料"和"extracted_info",没有''商务偏离''及'商务带星偏离',也没有'技术偏离'和'技术带星偏离',而货物标解析是完全版。
其中''证明材料"和"extracted_info"是直接返给后端保存的
- 大解析中返回了技术评分,后端接收后不仅显示给前端,还会返给向,用于生成技术偏离表
- 小解析时,get_deviation.py其实也可以返回技术评分,但是没有返回,因为没人和我对接,暂时注释了。

4.商务评议和技术评议偏离表,即评分细则的偏离表,暂时没做,但是商务评分、技术评分无论大解析还是小解析都解析了,稍微对该数据处理一下返回给后端就行。
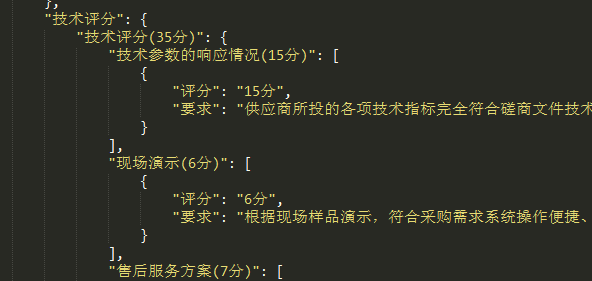
这个是解析得来的结果,适合给前端展示,但是要生成商务技术评议偏离表的话,需要再调一次大模型,对该数据进行重新归纳,以字符串列表为佳。再传给后端。(未做)
如何定位问题
- 查看static下的output文件夹 (upload大解析对应output1)
- docker-compose文件中规定了数据卷挂载的路径:- /home/Z/zbparse_output_dev:/flask_project/flask_app/static/output 也就是说static/output映射到了服务器的Z/zbparse_output_dev文件夹
- 根据时间查找哪个子文件夹(uuid作为子文件名)
- 查看是否有final_result.json文件,如果有,说明解析流程正常结束了,问题可能出在后端(a.后端接口请求超限30分钟 b.后处理存在解析数据的时候出错)
也可能出现在自身解析,可以查看子文件内的log.txt,查看日志。
- 若解析正常(有final_result)但解析不准,可以根据以下定位:
a.查看子文件夹下的文件切分是否准确,例如:如果评标办法不准确,那么查看ztbfile_evaluation_methon,是否正确切到了评分细则。如果切到了,那就改general/商务技术评分提取里的提示词;否则修改截取pdf那块关于'评标办法'的正则表达式。
b.总之是先看切的准不准,再看提示词能否优化,都要定位到对应的代码中!